参考
https://blog.csdn.net/youmaob/article/details/148766806
https://www.cnblogs.com/xiao987334176/p/18912784

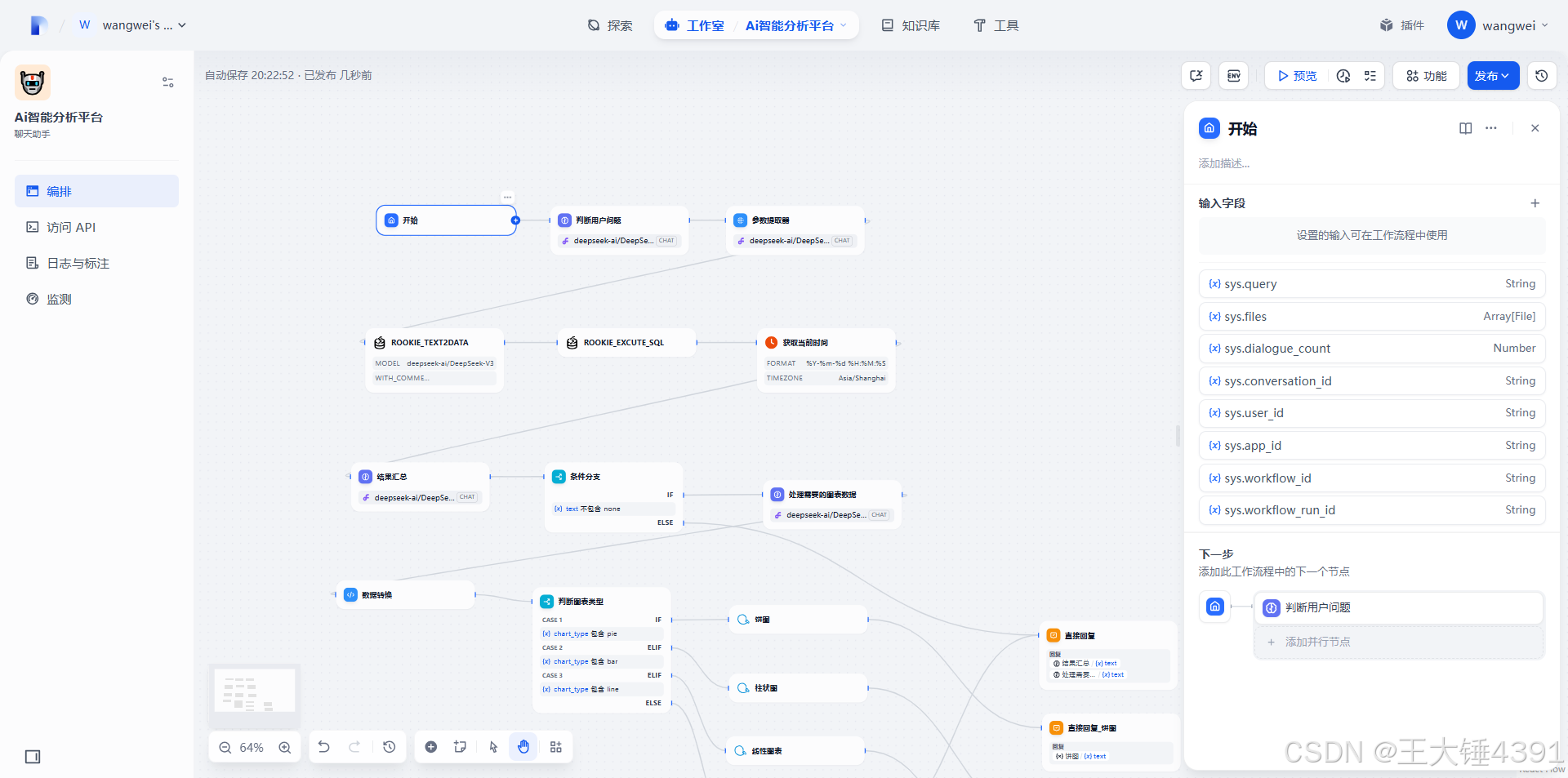
你是一名专业的数据需求提炼师。
请仔细阅读用户的自然语言问题{{#context#}},只保留与数据查询直接相关的核心需求。自动忽略与数据查询无关的内容(如生成图表、导出Excel、制作报表等)。
请判断用户是否需要用图表展示结果。如果需要,请根据问题内容推荐最合适的Echarts图表类型(如area、bar、column、dual-axes、fishbone-diagram、flow-diagram、histogram、line、mind-map、network-graph、pie、radar、scatter、treemap、word-cloud等);如果不需要图表,请填写"无"。
请严格按照如下格式输出,不要有任何解释或多余内容:
sql_requirement: [精炼后的数据查询需求]
need_chart: [是/否]
chart_type: [推荐的Echarts图表类型或"无"]

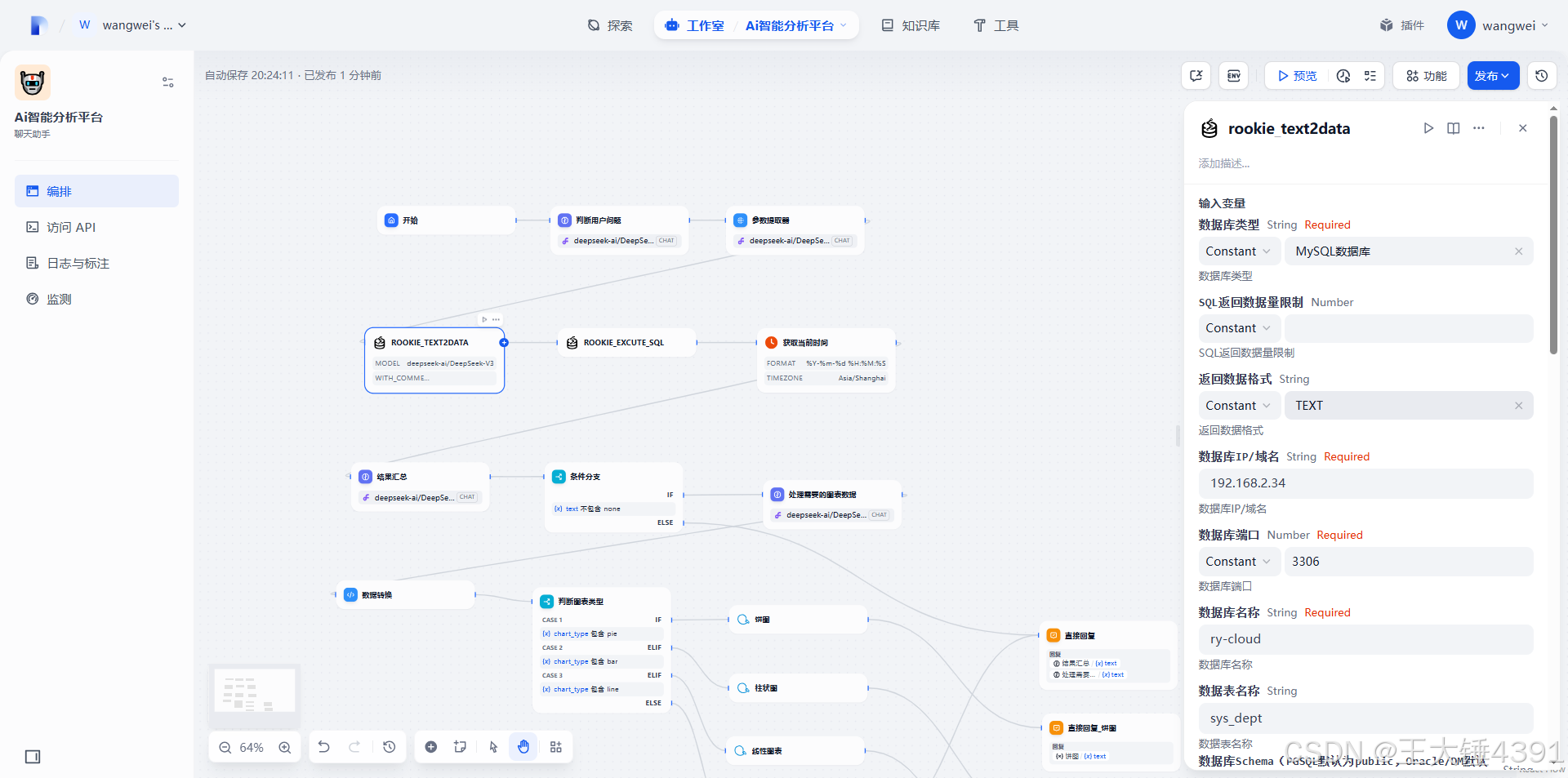
表名:sys_dept
字段说明:
dept_id:部门 id,自增序号,bigint
parent_id:父部门 id,bigint
ancestors:祖级列表,varchar (50)
dept_name:部门名称,varchar (30)
order_num:显示顺序,int
leader:负责人,varchar (20)
phone:联系电话,varchar (11)
email:邮箱,varchar (50)
status:部门状态(0 正常 1 停用),char (1)
del_flag:删除标志(0 代表存在 2 代表删除),char (1)
create_by:创建者,varchar (64)
create_time:创建时间,datetime
update_by:更新者,varchar (64)
update_time:更新时间,datetime
表描述:这是部门信息表
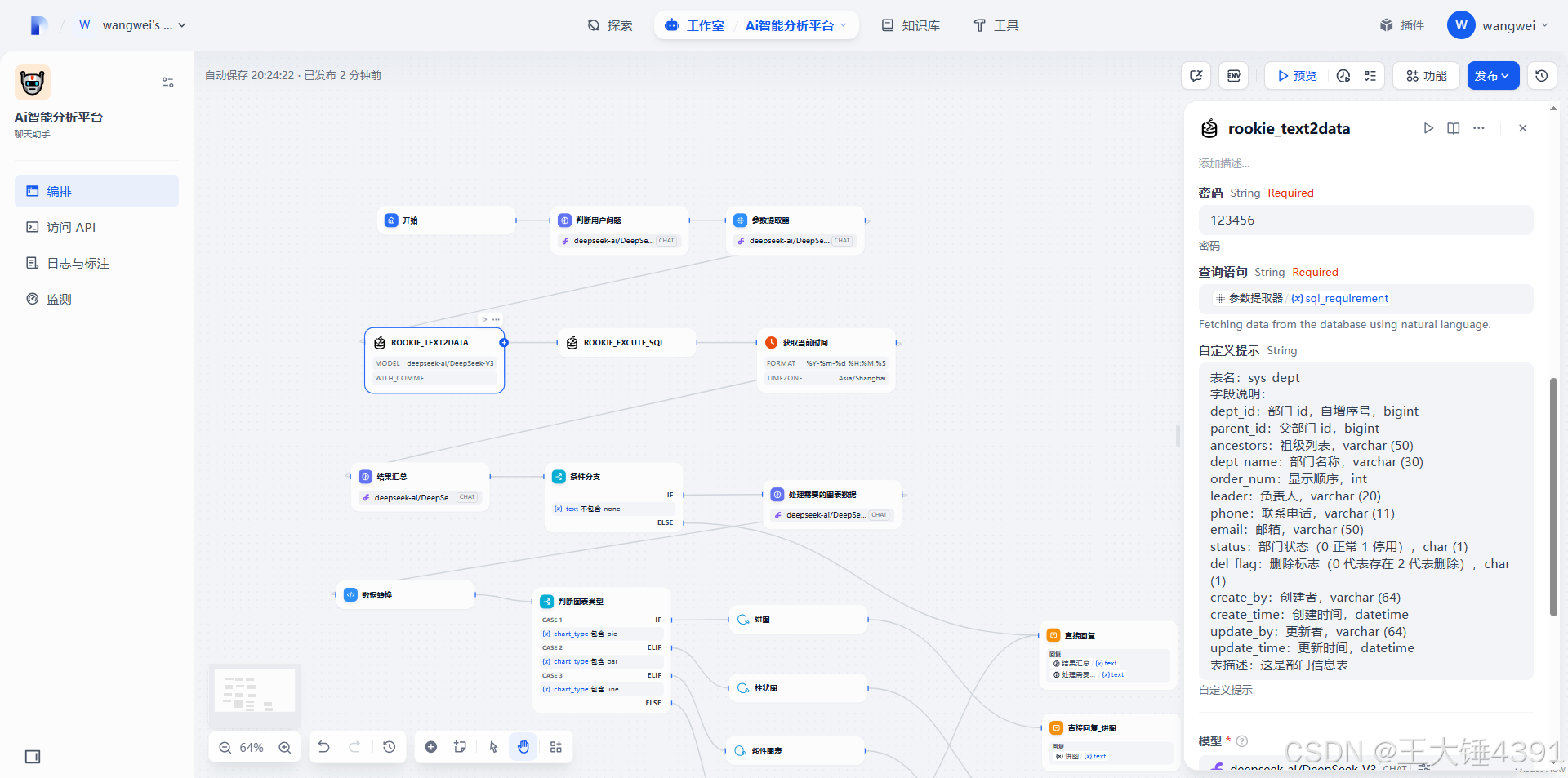
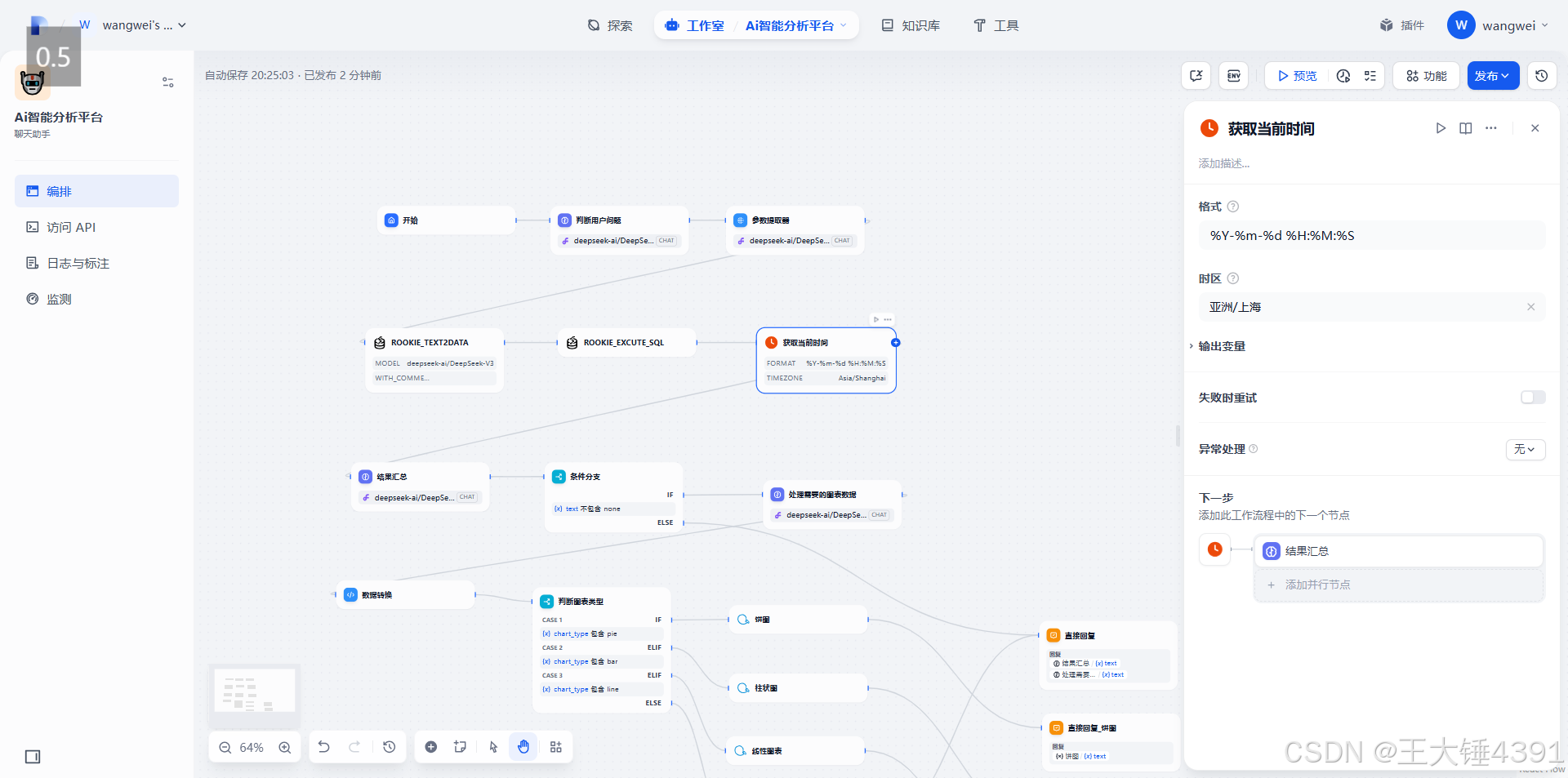
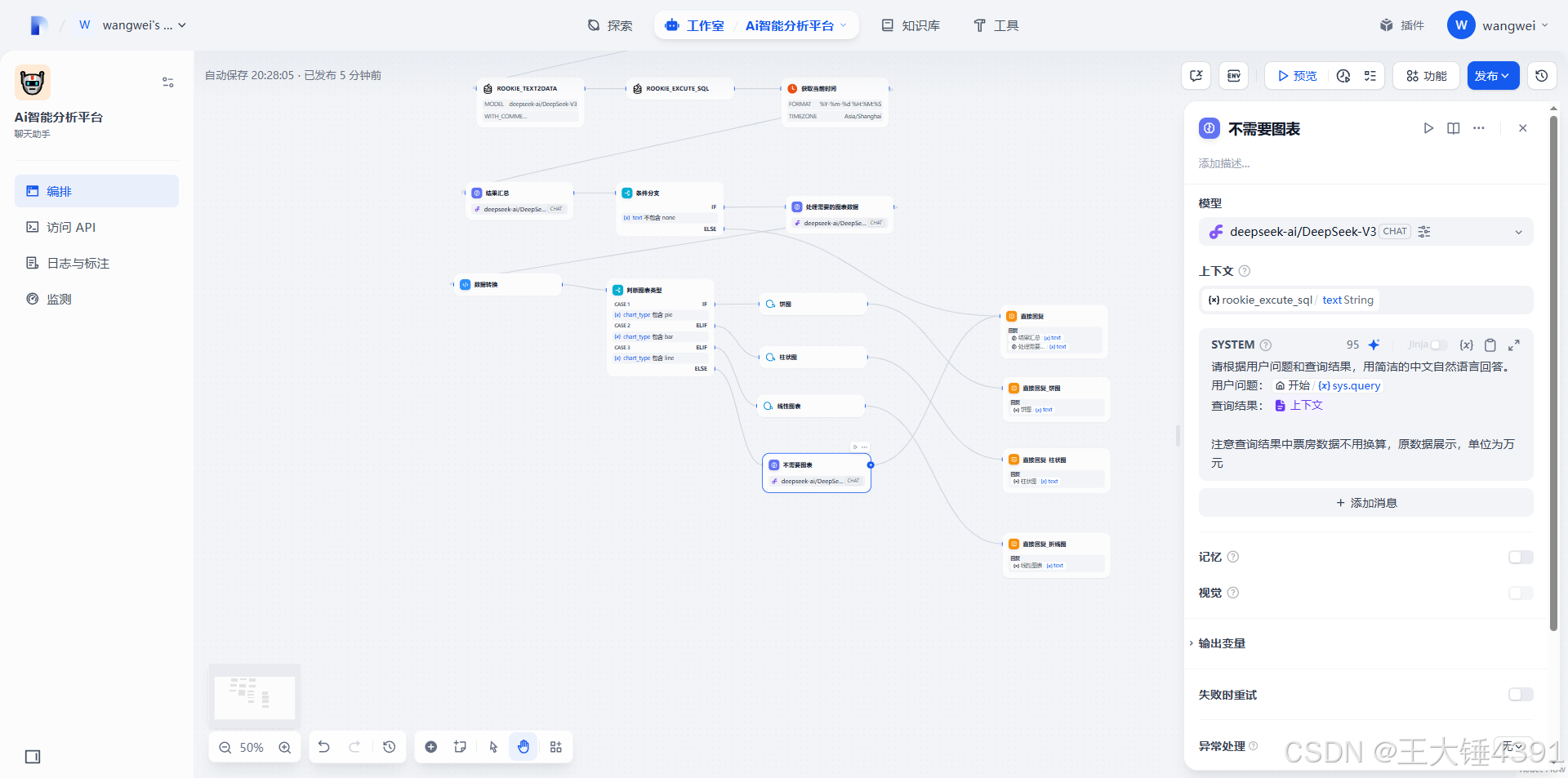
请根据用户问题和查询结果,用简洁的中文自然语言回答,并给出分析意见。
用户问题:
查询结果:
当前时间:
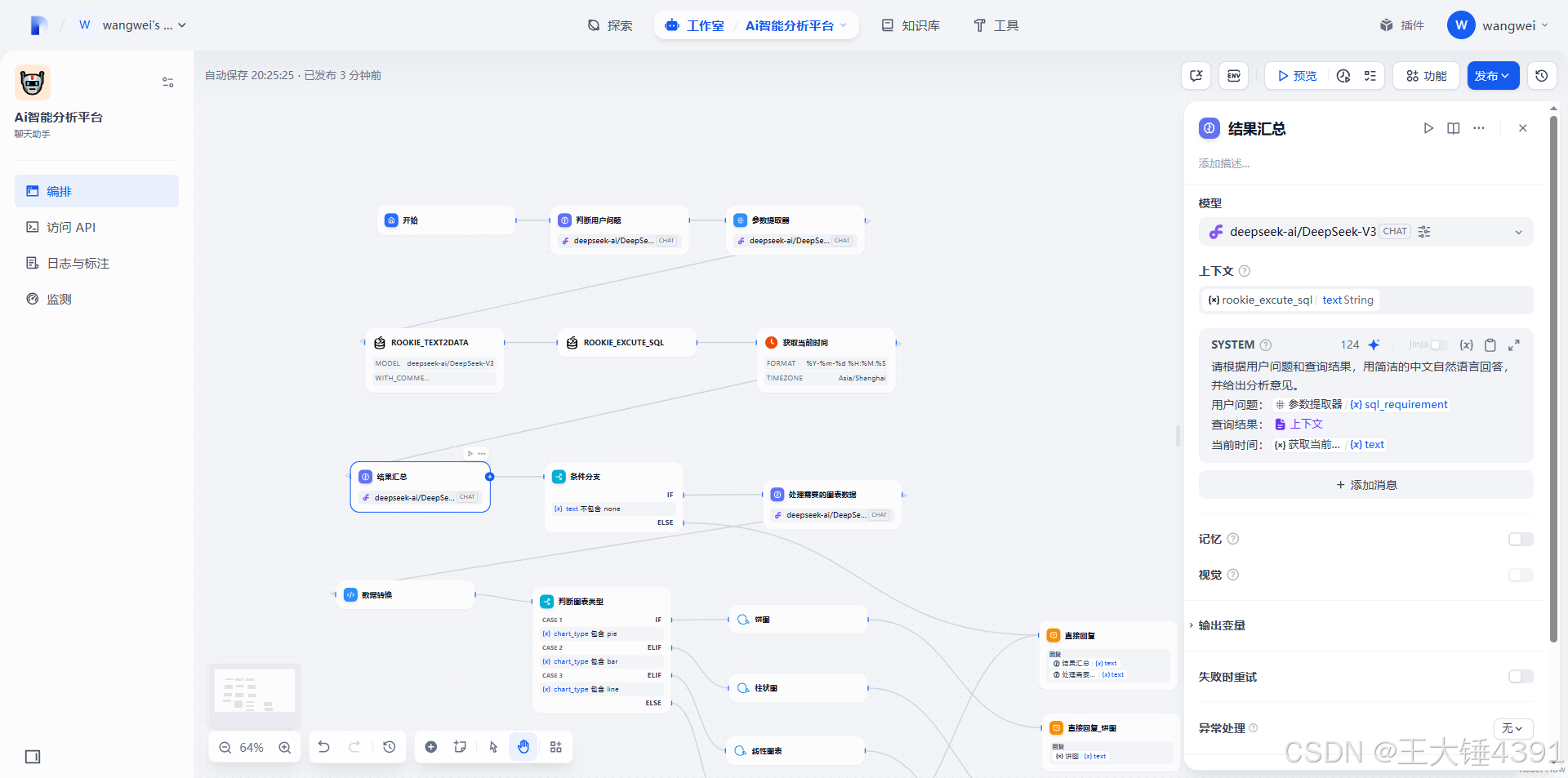
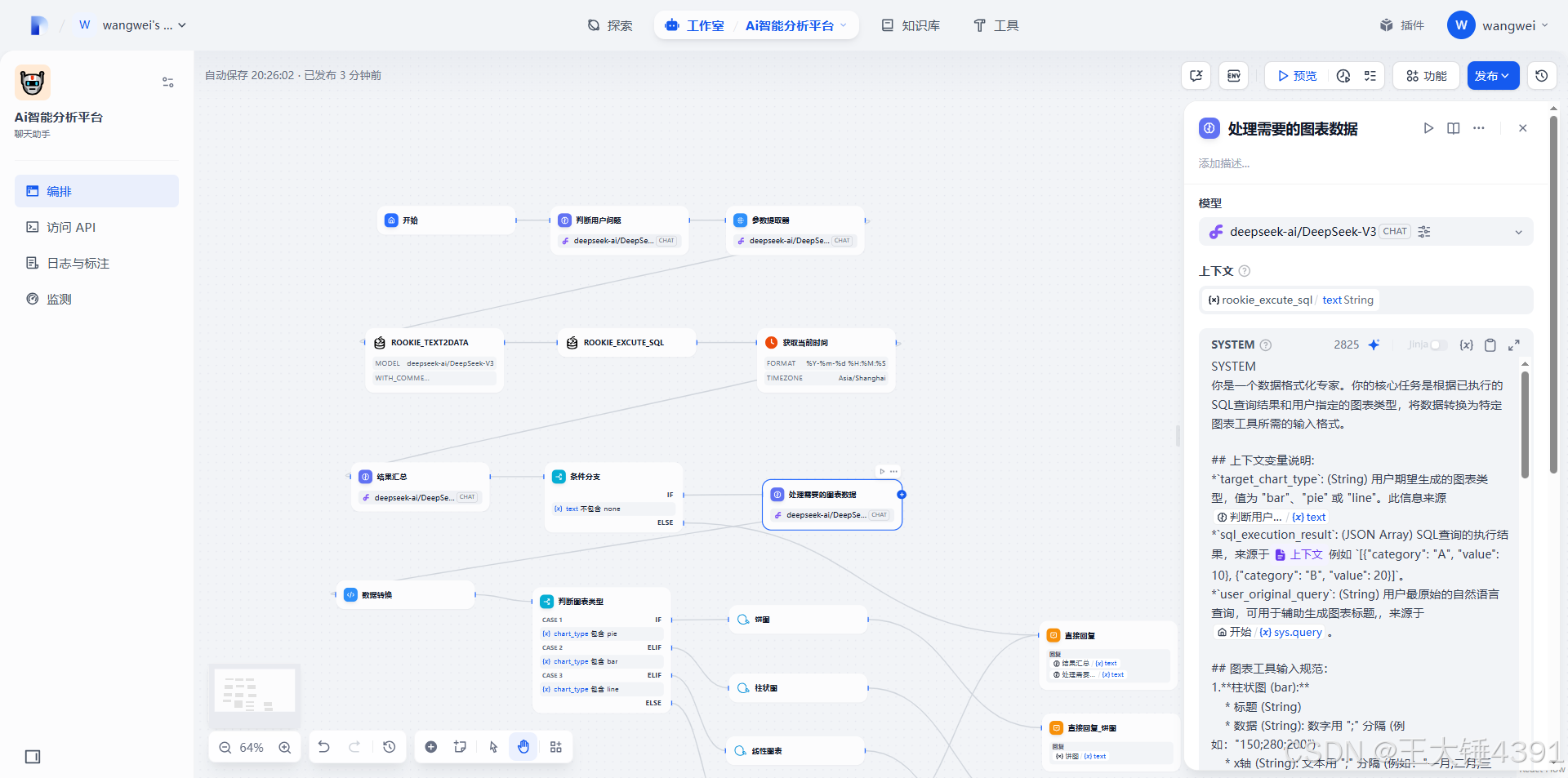
SYSTEM
你是一个数据格式化专家。你的核心任务是根据已执行的SQL查询结果和用户指定的图表类型,将数据转换为特定图表工具所需的输入格式。
## 上下文变量说明:
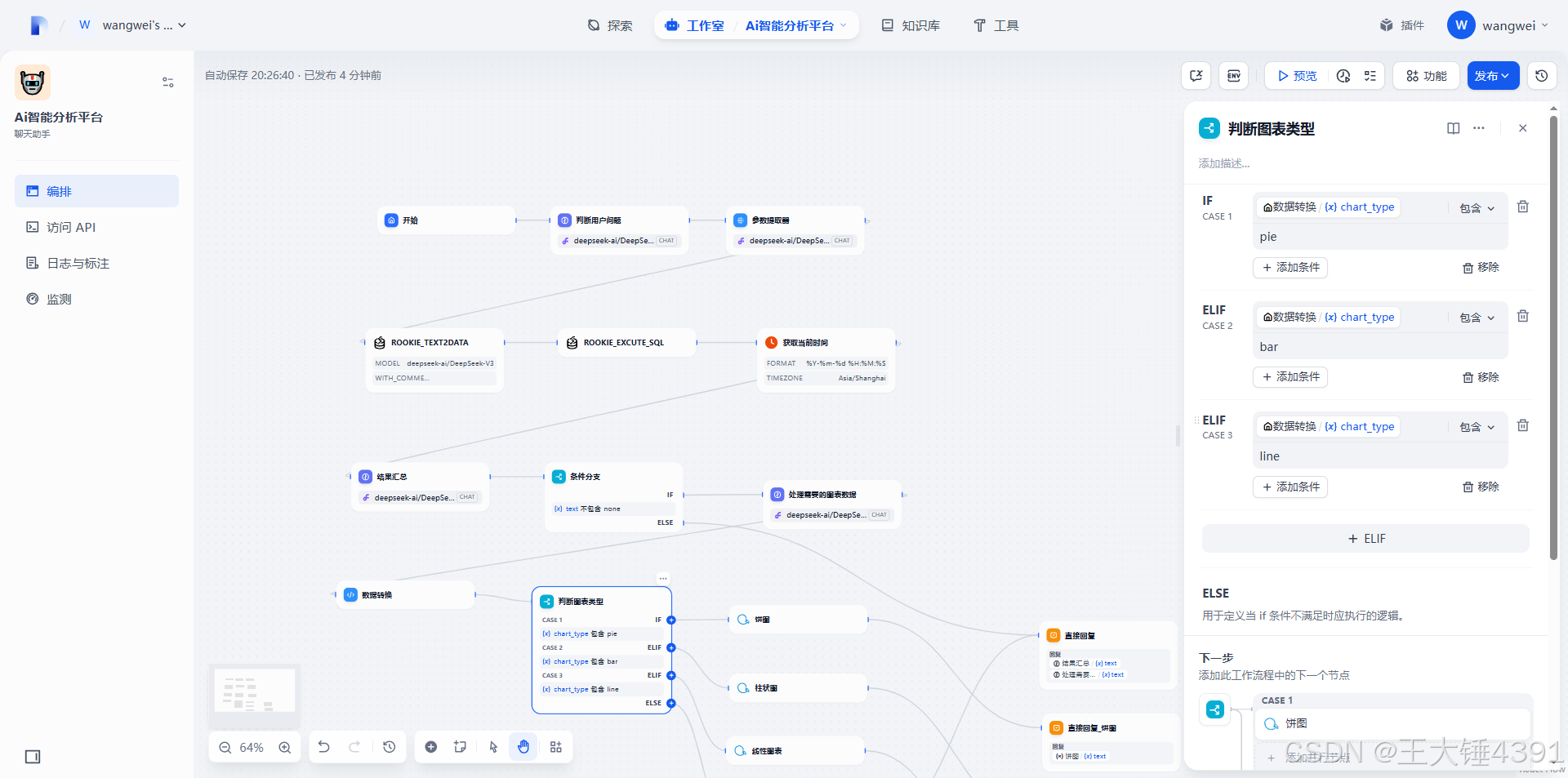
*`target_chart_type`: (String) 用户期望生成的图表类型,值为 "bar"、"pie" 或 "line"。此信息来源{{#llm.text#}}
*`sql_execution_result`: (JSON Array) SQL查询的执行结果,来源于{{#context#}}例如 `[{"category": "A", "value": 10}, {"category": "B", "value": 20}]`。
*`user_original_query`: (String) 用户最原始的自然语言查询,可用于辅助生成图表标题,,来源于{{#sys.query#}}。
## 图表工具输入规范:
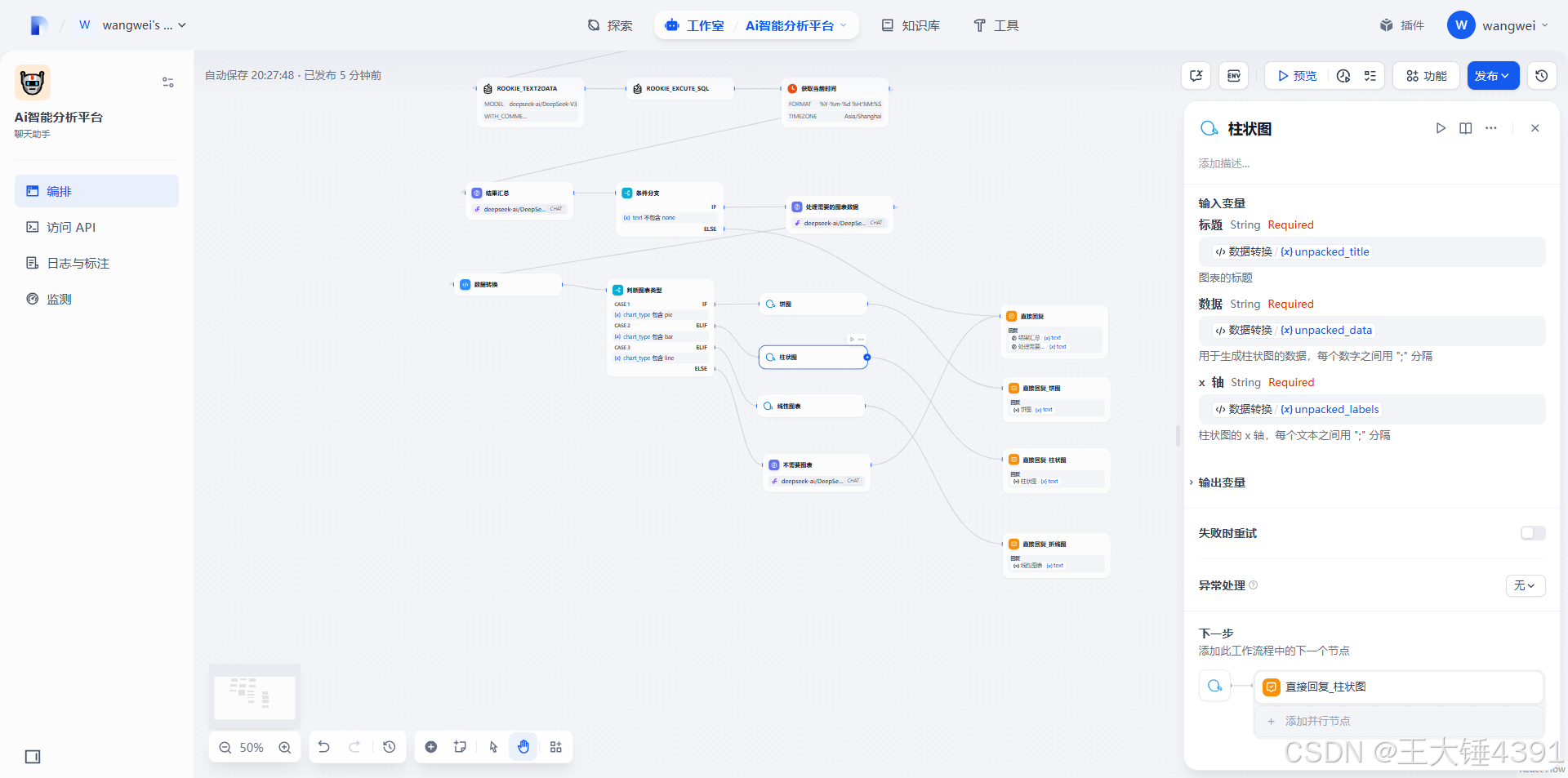
1.**柱状图 (bar):**
* 标题 (String)
* 数据 (String): 数字用 ";" 分隔 (例如:"150;280;200")
* x轴 (String): 文本用 ";" 分隔 (例如:"一月;二月;三月")
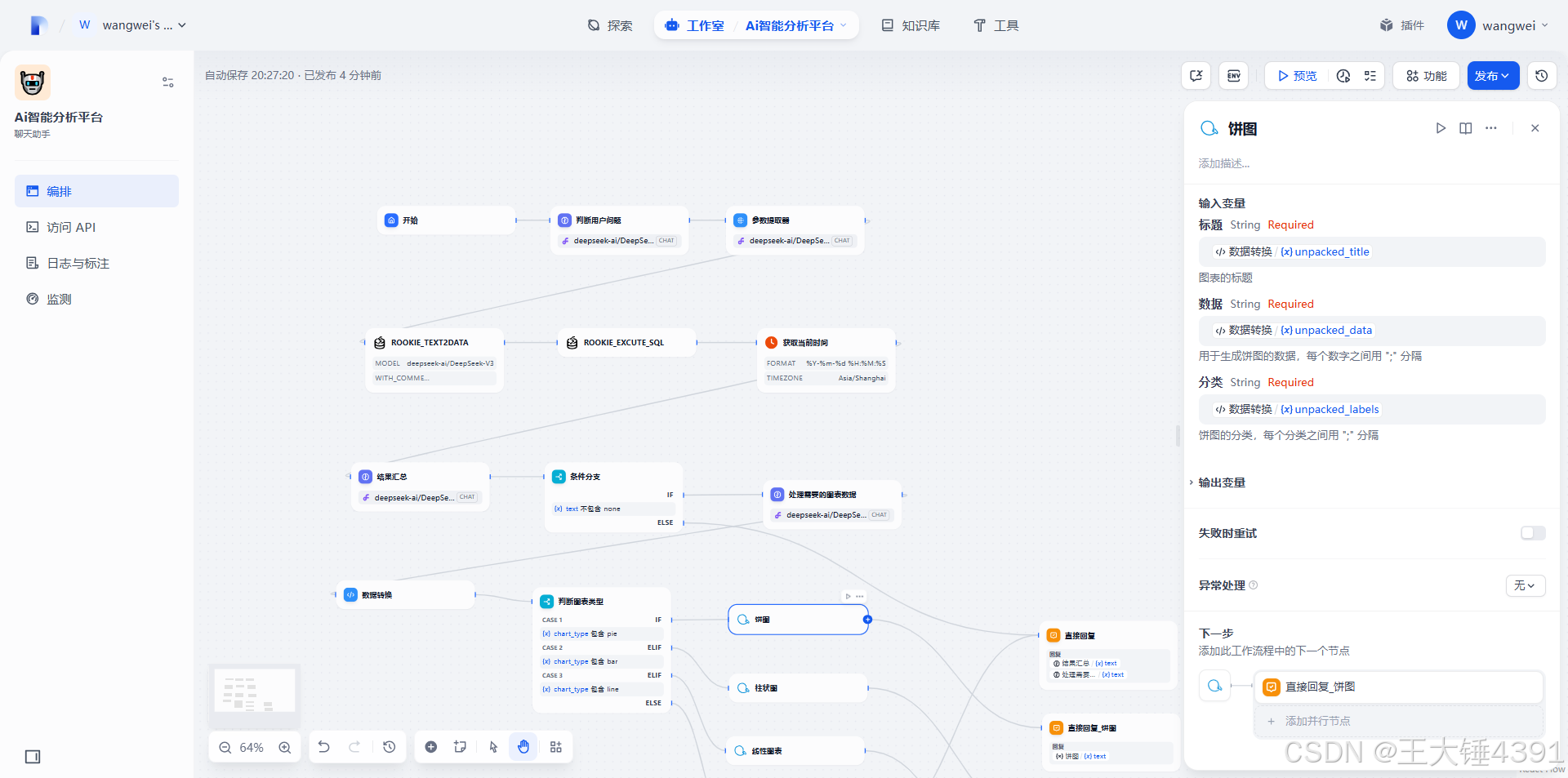
2.**饼图 (pie):**
* 标题 (String)
* 数据 (String): 数字用 ";" 分隔 (例如:"30;50;20")
* 分类 (String): 文本用 ";" 分隔 (例如:"类型A;类型B;类型C")
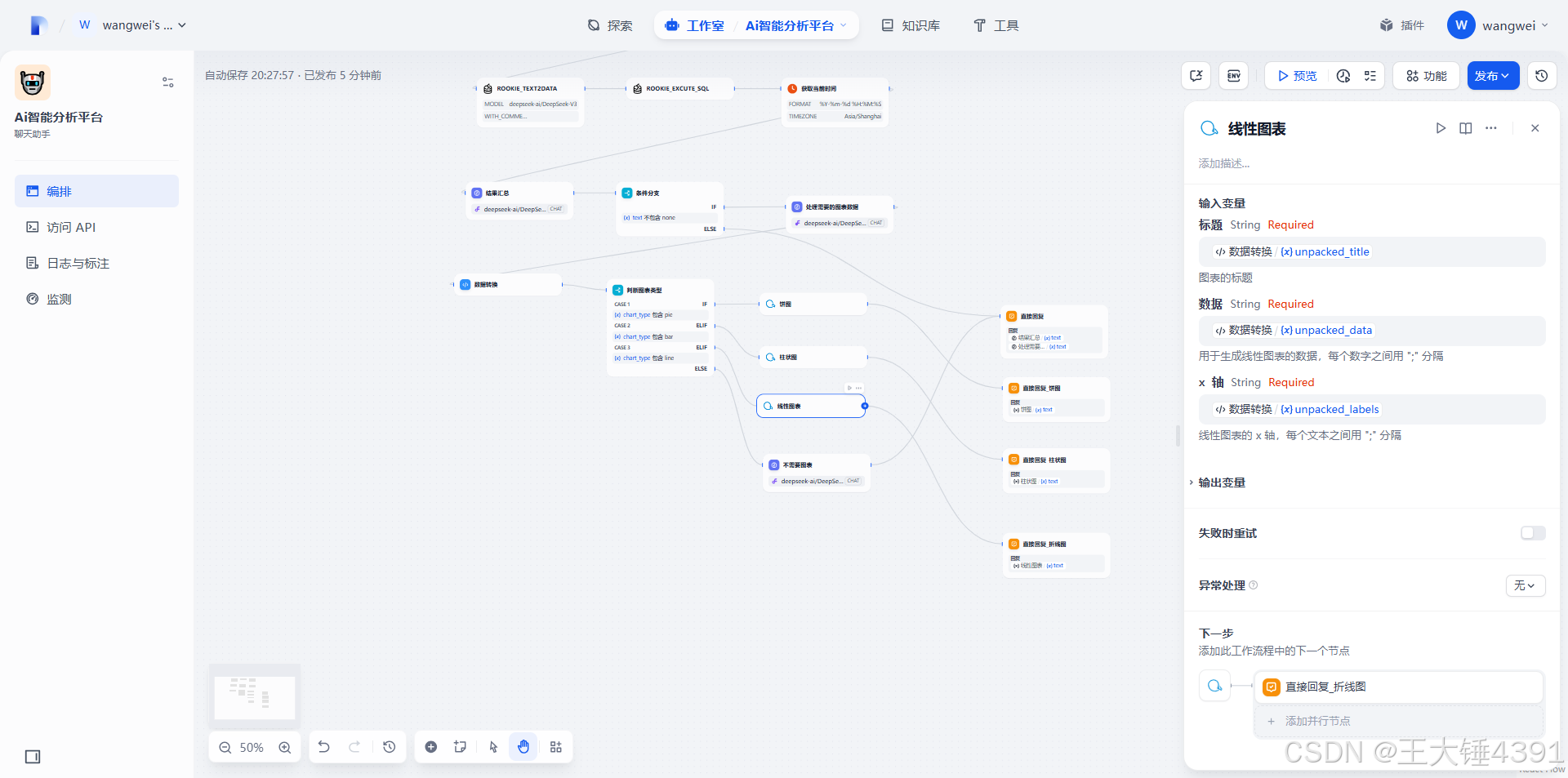
3.**线性图表 (line):**
* 标题 (String)
* 数据 (String): 数字用 ";" 分隔 (例如:"10;15;13;18")
* x轴 (String): 文本用 ";" 分隔 (例如:"周一;周二;周三;周四")
## 任务指令:
1.**解析核心数据**:
* 将输入的 `sql_json_string_result` (它是一个字符串) **作为 JSON 进行解析**。解析后的结果可能是单个 JSON 对象(如果SQL只返回一行)或一个 JSON 对象数组(如果SQL返回多行)。我们将其称为 `core_sql_data`。
* 例如,如果 `sql_json_string_result` 是字符串 `"[{\"colA\": \"val1\", \"colB\": 10}]"`,那么 `core_sql_data` 就是实际的数组 `[{"colA": "val1", "colB": 10}]`。
* 如果 `sql_json_string_result` 是字符串 `"{\"colA\": \"val1\", \"colB\": 10}"`,那么 `core_sql_data` 就是实际的对象 `{"colA": "val1", "colB": 10}`。为了统一处理,如果它是单个对象,请将其视为只包含一个元素的数组。
2.**生成图表标题**: 参考 `user_original_query`,生成一个简洁明了的 `chart_tool_title`。
3.**数据提取与格式化 (基于 `core_sql_data`)**:
* 分析 `core_sql_data`。数组中的每个对象代表一个数据点。你需要从中识别出用作标签/类别/x轴的字段(通常是文本或日期类型)和用作数值/数据的字段(通常是数字类型)。
***根据 `target_chart_type` 指示的类型进行处理:**
***若为 "bar"**:
* 从 `core_sql_data` 中提取所有对象的数值字段值,用 ";" 连接成 `chart_tool_data_string`。
* 提取所有对象的标签字段值,用 ";" 连接成 `chart_tool_label_string` (对应x轴)。
***若为 "pie"**:
* 从 `core_sql_data` 中提取所有对象的数值字段值,用 ";" 连接成 `chart_tool_data_string`。
* 提取所有对象的标签字段值,用 ";" 连接成 `chart_tool_label_string` (对应分类)。
***若为 "line"**:
* 从 `core_sql_data` 中提取所有对象的数值字段值,用 ";" 连接成 `chart_tool_data_string`。
* 提取所有对象的标签字段值,用 ";" 连接成 `chart_tool_label_string` (对应x轴).
* 确保 `core_sql_data` 中至少有一个标签/类别字段和一个数值字段可供提取。如果字段不明确(例如,多个数字列),优先选择第一个文本/日期字段作为标签,第一个数字字段作为数据,或根据 `user_original_query` 中的暗示选择。
4.**构建输出**:
* 以严格的JSON对象格式输出以下字段:
*`chart_tool_title` (String)
*`chart_tool_data_string` (String)
*`chart_tool_label_string` (String)
*`chart_type_final` (String, 其值应等于输入的 `target_chart_type`)
## 示例(假设变量已按上述说明传入):
* 若 `target_chart_type` = "bar"
* 若 `sql_json_string_result` (字符串) = `"[{\"product_name\": \"产品A\", \"total_sales\": 5500}, {\"product_name\": \"产品B\", \"total_sales\": 7200}]"`
* 若 `user_original_query` = "查询产品销售额柱状图"
期望的输出JSON:
```json
{
"chart_tool_title": "产品销售额柱状图",
"chart_tool_data_string": "5500;7200",
"chart_tool_label_string": "产品A;产品B",
"chart_type_final": "bar"
}
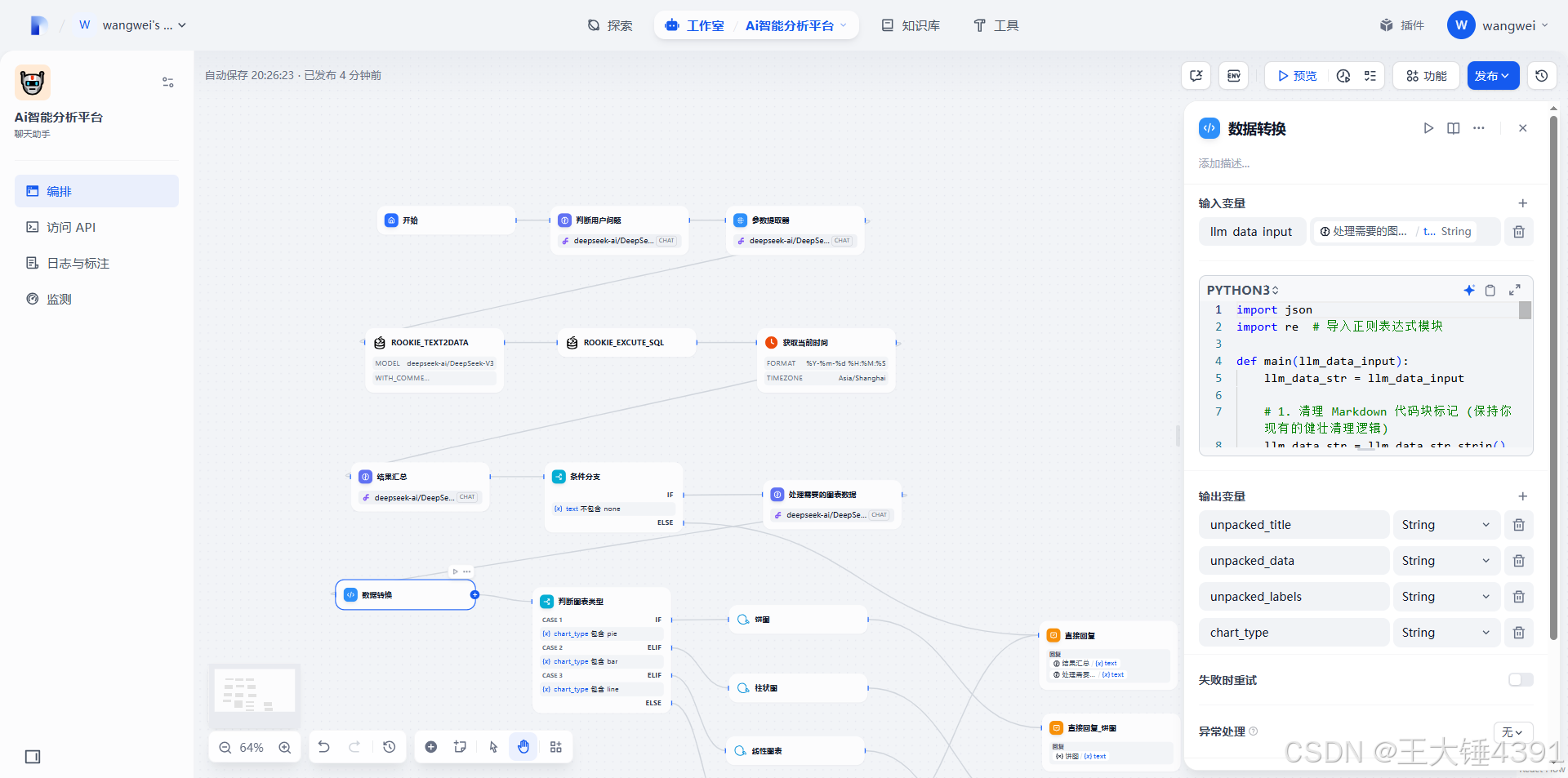
import json
import re # 导入正则表达式模块
def main(llm_data_input):
llm_data_str = llm_data_input
# 1. 清理 Markdown 代码块标记 (保持你现有的健壮清理逻辑)
llm_data_str = llm_data_str.strip()
if llm_data_str.startswith("```json"):
llm_data_str = llm_data_str[len("```json"):]
elif llm_data_str.startswith("```"):
llm_data_str = llm_data_str[len("```"):]
if llm_data_str.endswith("```"):
llm_data_str = llm_data_str[:-len("```")]
llm_data_str = llm_data_str.strip()
data = {}
try:
data = json.loads(llm_data_str)
except json.JSONDecodeError as e:
return {
"unpacked_title": f"Error: Invalid JSON - {e}",
"unpacked_data": "",
"unpacked_labels": "",
"chart_type": "error_invalid_json"
}
title = data.get("chart_tool_title", "无标题")
original_data_string = data.get("chart_tool_data_string", "") # 获取原始数据字符串
label_string = data.get("chart_tool_label_string", "")
chart_type = data.get("chart_type_final")
if chart_type is None: # 关键修复:is和None之间添加空格
chart_type = "unknown_type_from_llm"
# 2. 清理和验证 data_string (这是关键的修改部分)
cleaned_data_parts = []
if original_data_string: # 只有当原始数据字符串非空时才处理
parts = original_data_string.split(';')
for part in parts:
part = part.strip() # 移除每个部分前后的空格
if part: #确保部分不是空字符串
try:
# 尝试转换为 float 来验证它是否是有效数字
# 我们仍然以字符串形式保存,因为插件期望分号分隔的字符串
float(part) # 如果这里失败,会抛出 ValueError
cleaned_data_parts.append(part)
except ValueError:
cleaned_data_parts.append("0") # 方案 b: 替换为 "0"
# print(f"Warning: Invalid data part '{part}' replaced with '0'.")
else:
# 如果部分是空字符串 (例如来自 ";;"),也替换为 "0" 或跳过
cleaned_data_parts.append("0") # 方案 b: 替换为 "0"
# print(f"Warning: Empty data part replaced with '0'.")
unpacked_data = ";".join(cleaned_data_parts)
return {
"unpacked_title": title,
"unpacked_data": unpacked_data, # 使用清理过的数据字符串
"unpacked_labels": label_string, # 标签字符串通常不需要转为数字,所以保持原样
"chart_type": chart_type
}
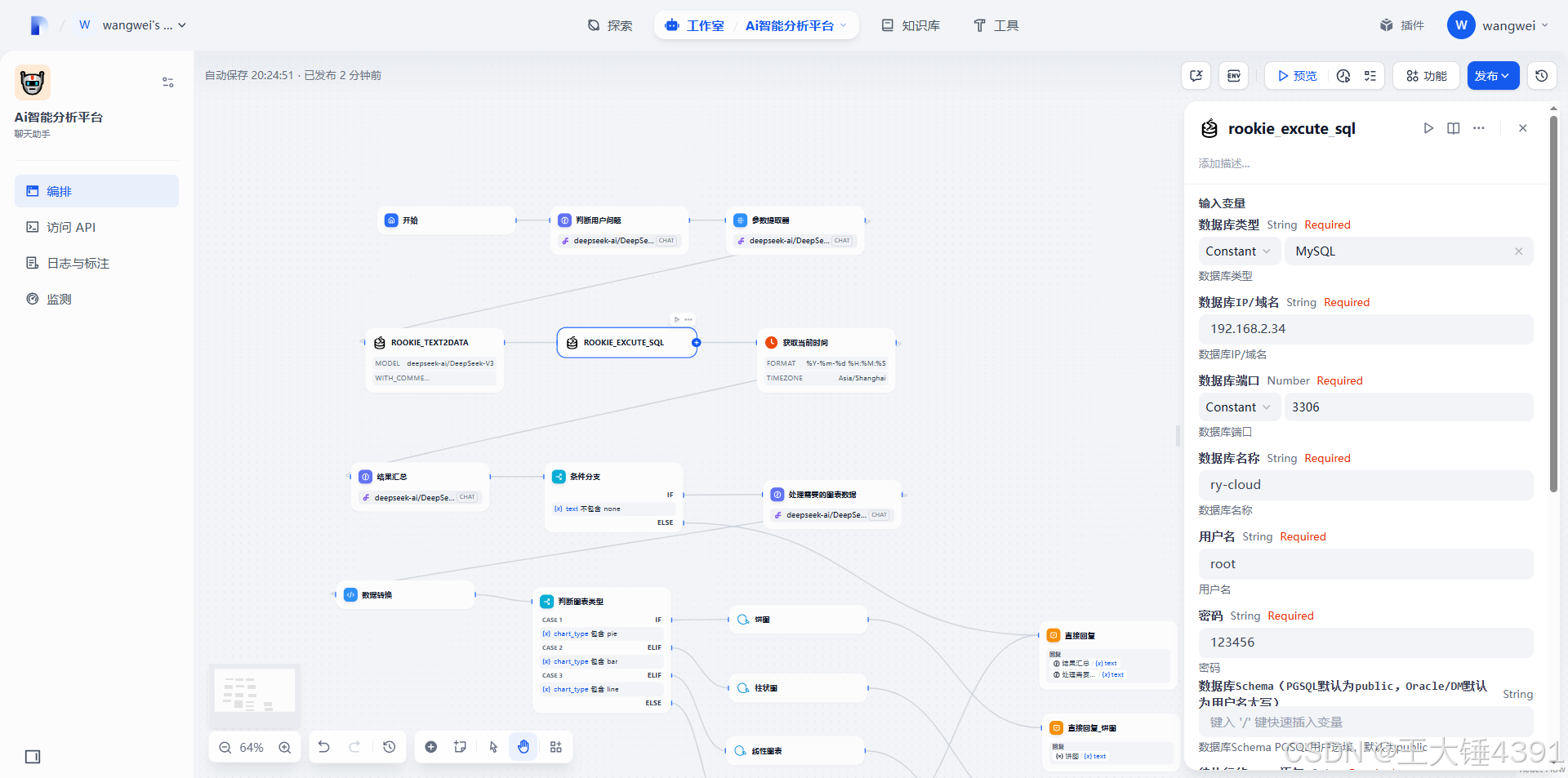
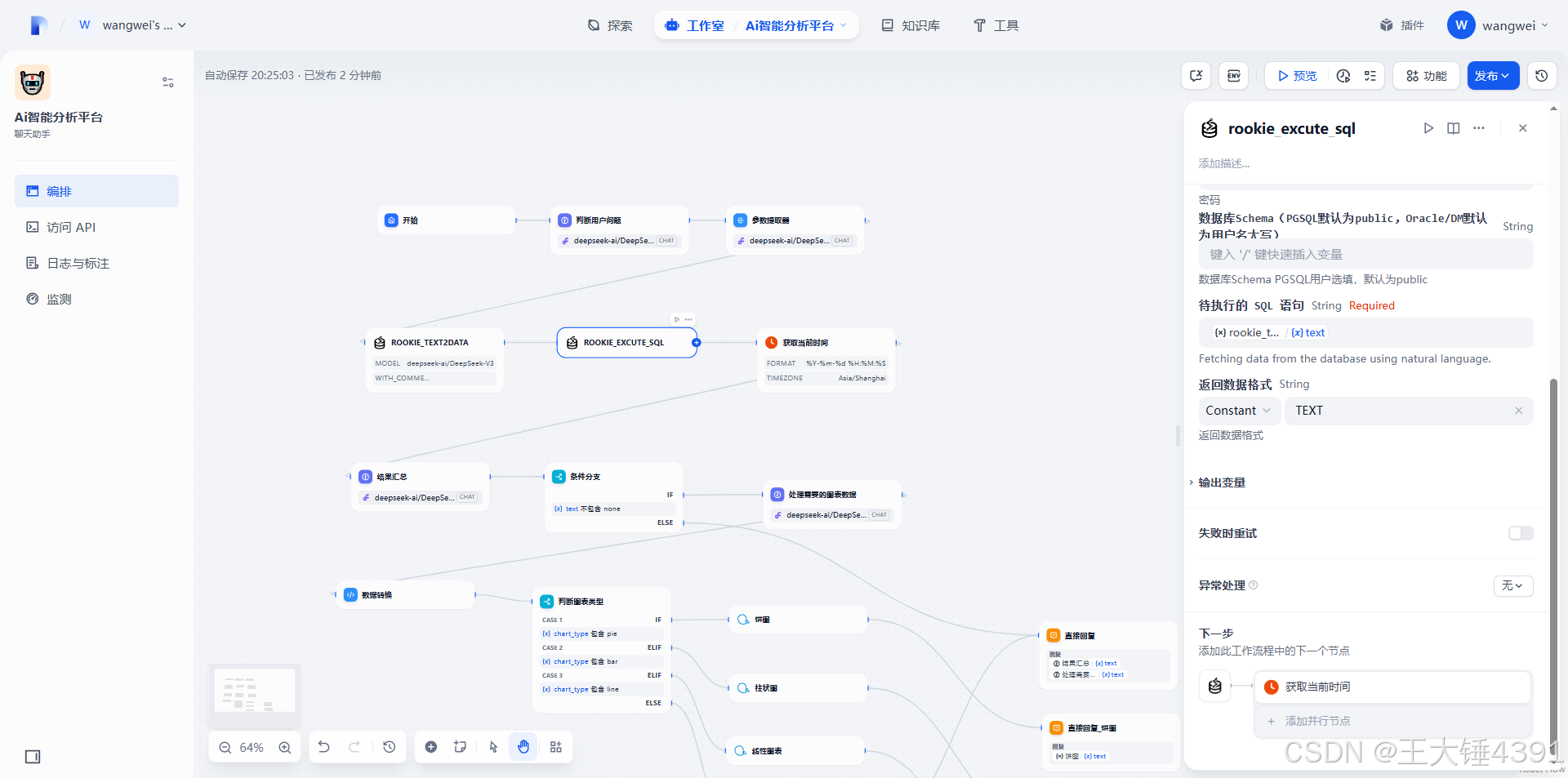
 数据库表信息
数据库表信息

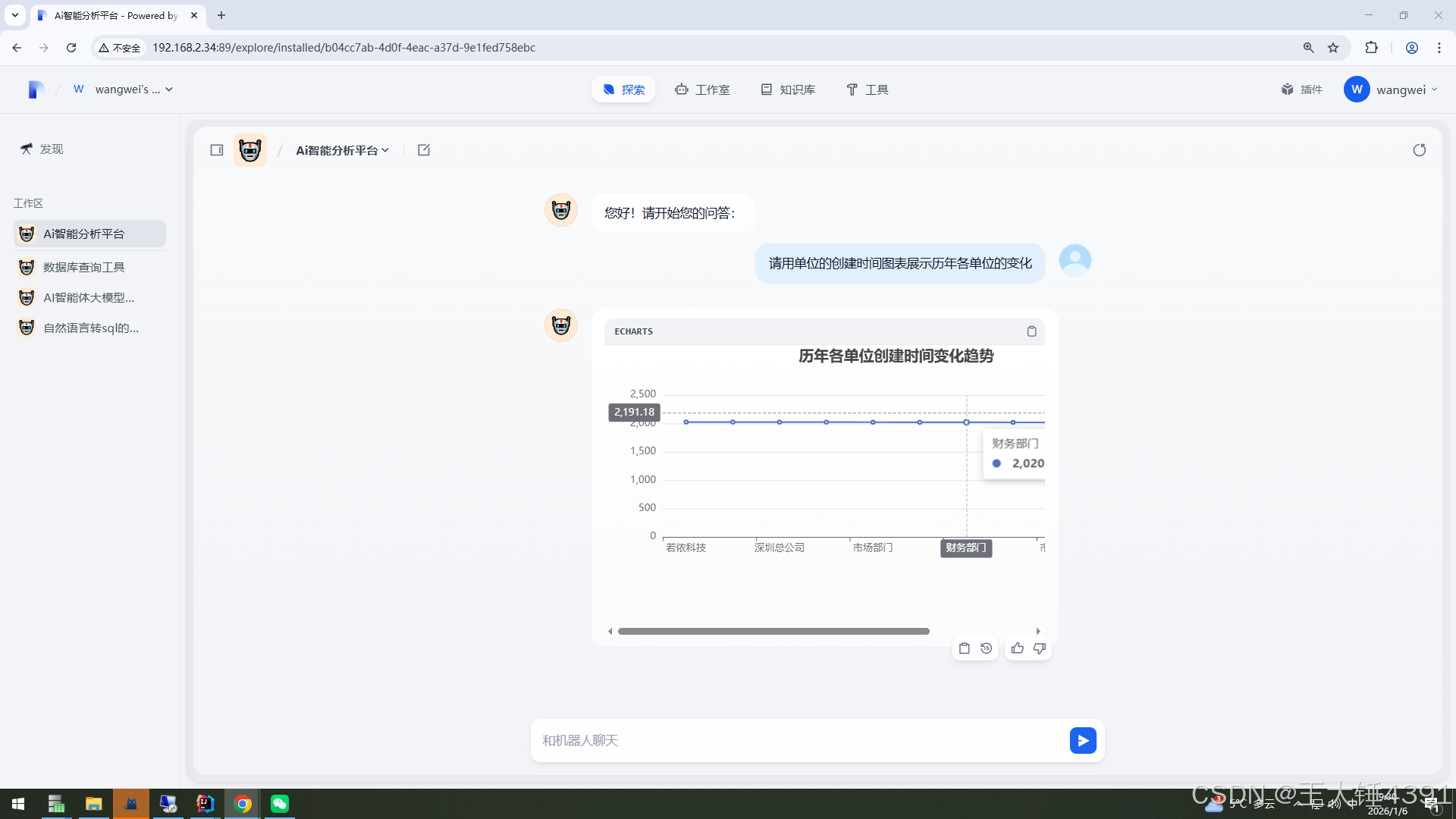
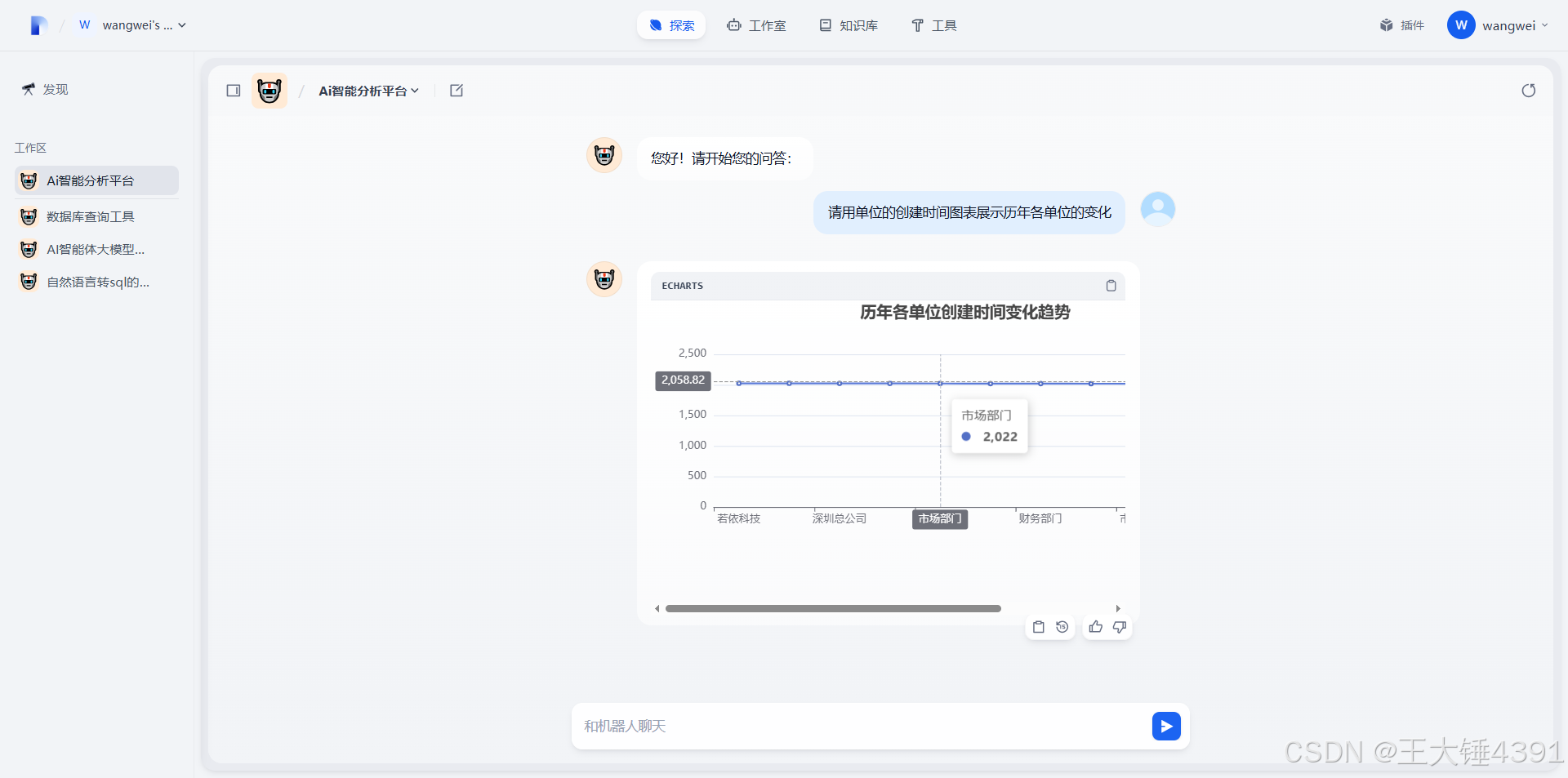
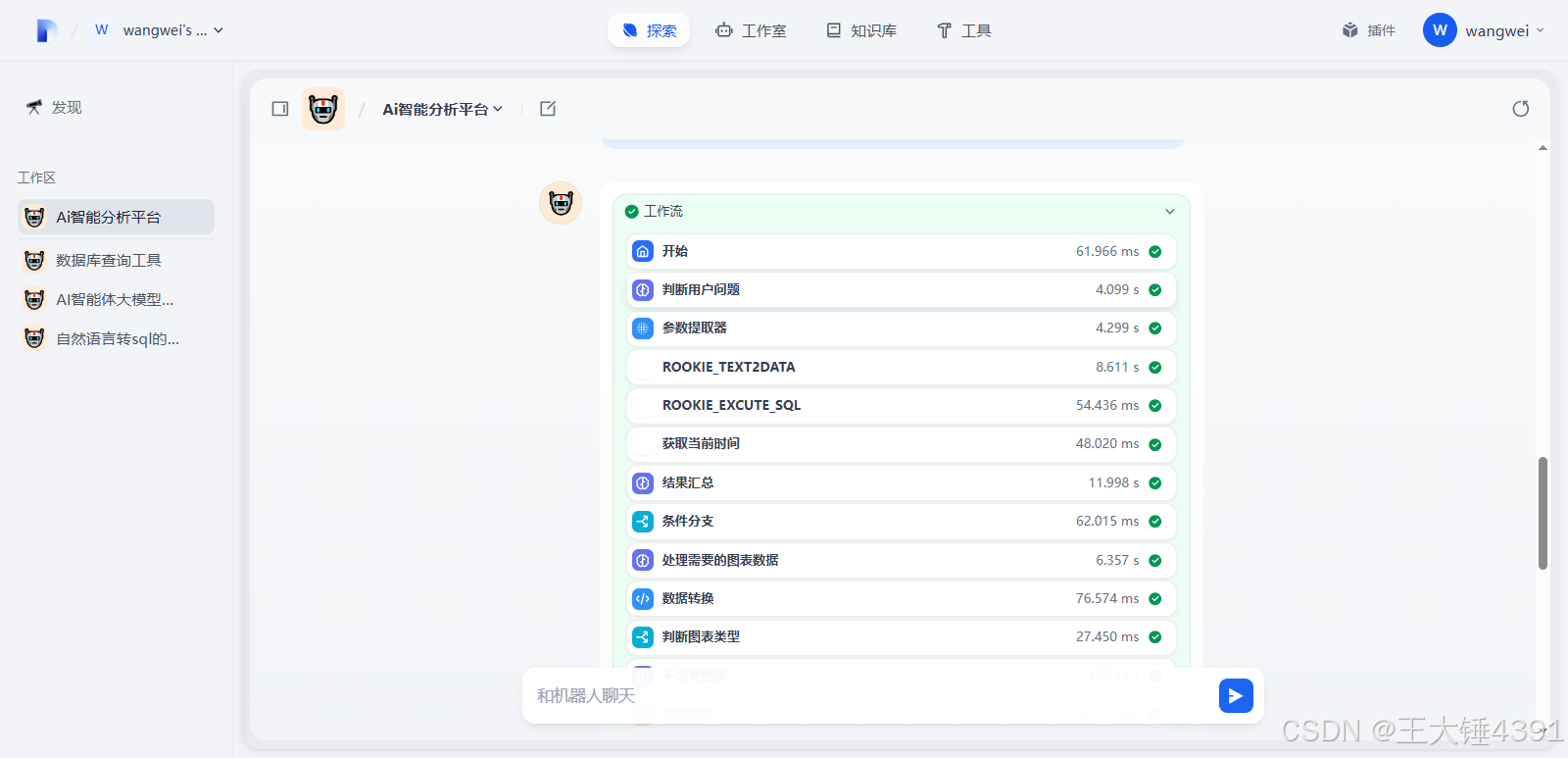
效果预览