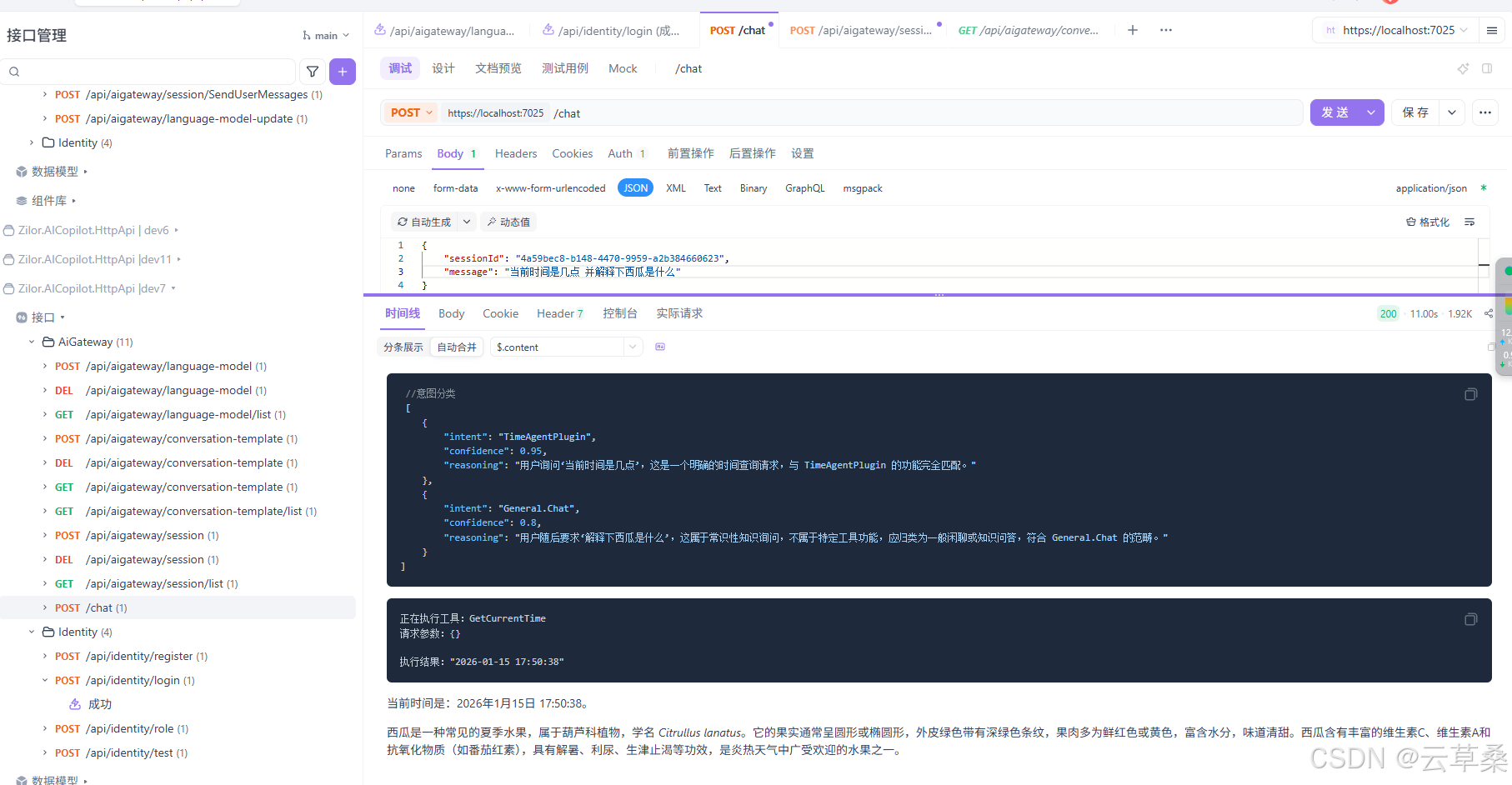
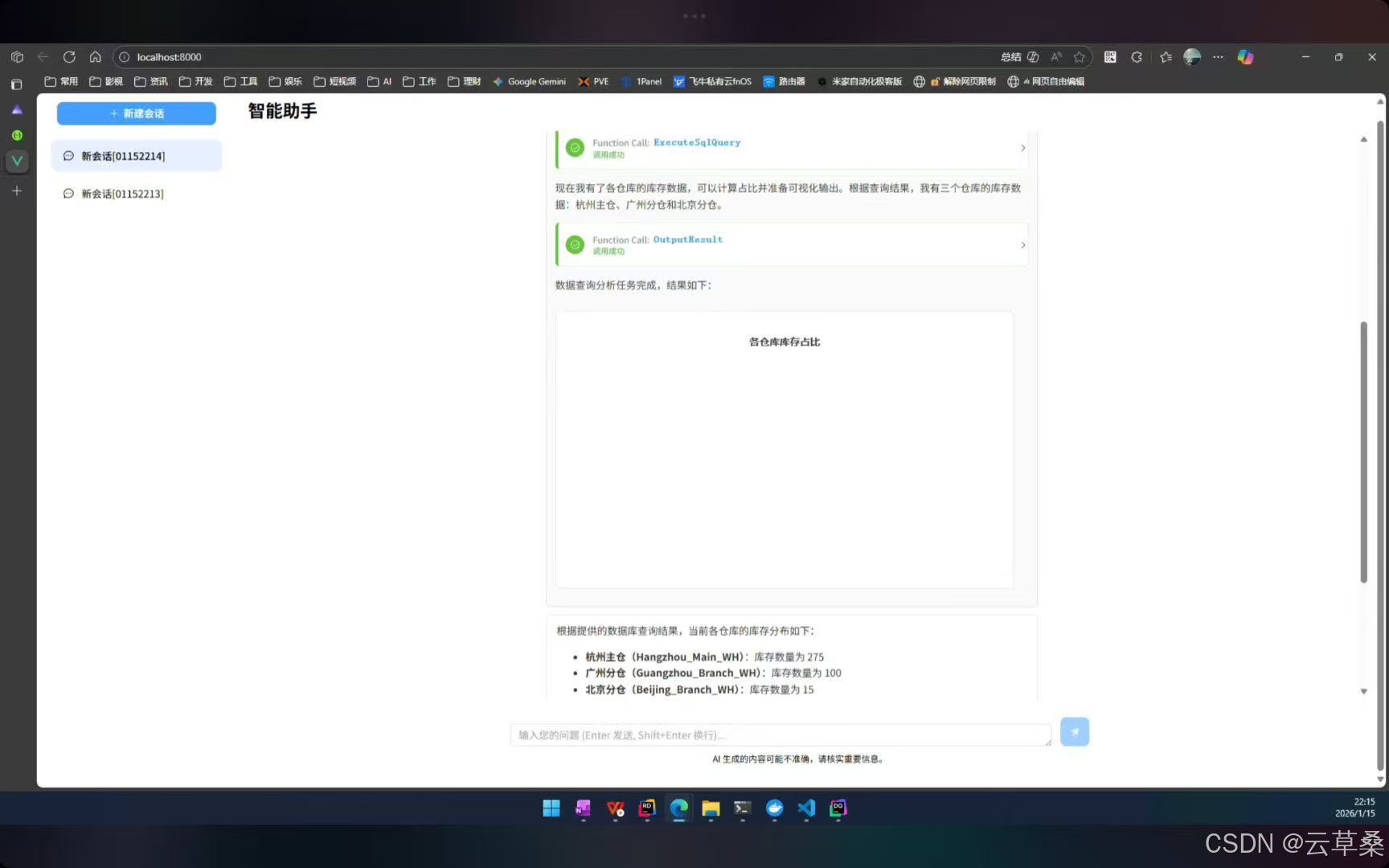
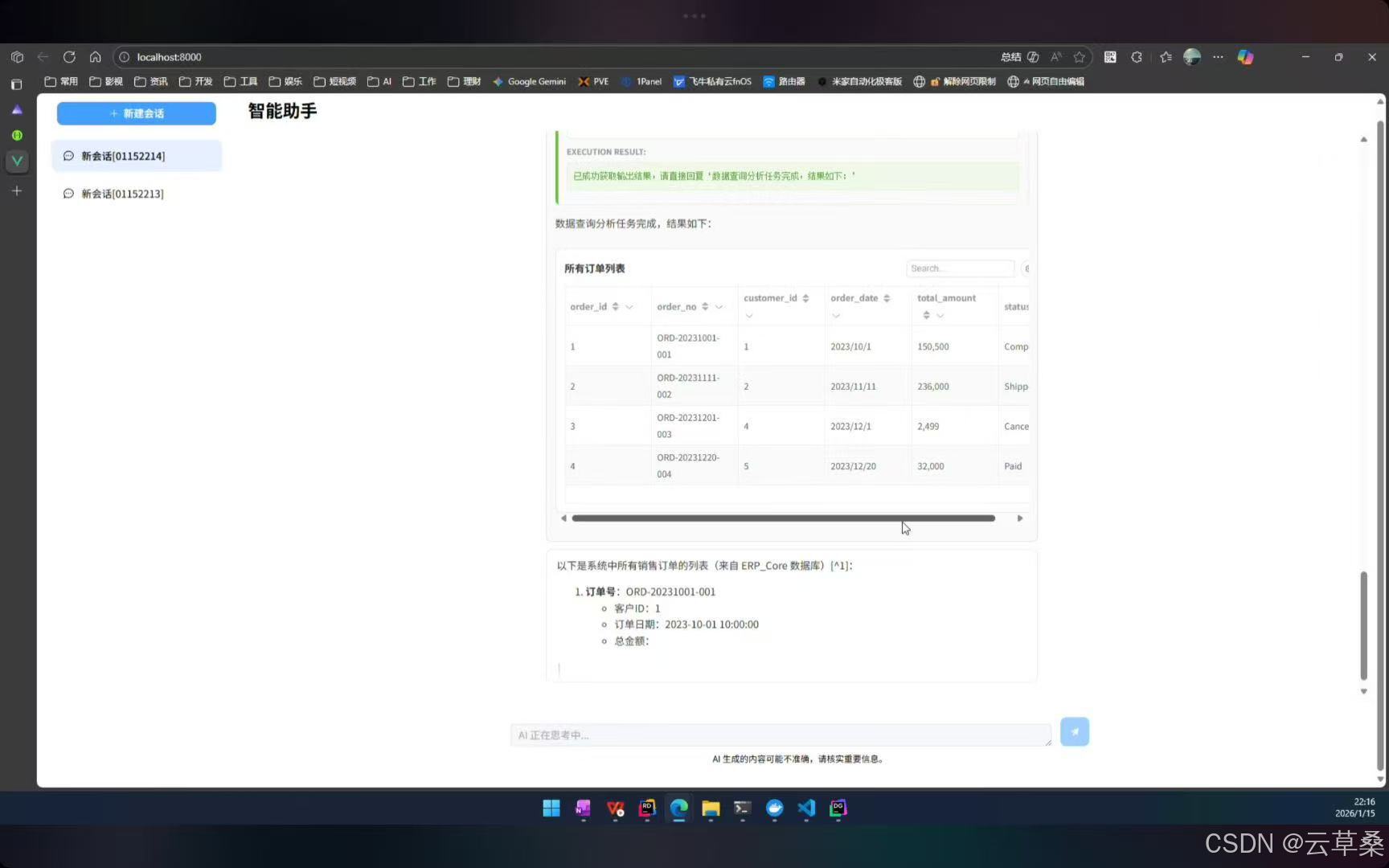
前言:本项目聚焦企业级AI助理系统升级,融合数据分析与MCP集成,完善前后端可视化能力,实现AI Copilot"数据分析(Text-to-SQL)"全链路功能,支持多数据源自动发现、安全SQL执行及数据可视化呈现,同时扩展Agent工作流与插件系统,优化数据库结构,新增MCP Server动态接入及插件桥接机制,升级Vue 3前端聊天应用,实现流式对话、审批流等功能全覆盖;该系统采用分层架构设计,构建智能体交互、知识中枢(RAG)、数据分析(NL2SQL)及工具调用(MCP)三大核心模块,可高效支撑自然语言查询、跨系统操作与可视化报表生成,技术选型上选用ASP.NET Core、Semantic Kernel AI框架及Qdrant向量数据库,支持私有化部署,以权限控制保障安全,通过容器化云原生方案搭建企业现有系统的智能化交互层,显著提升全栈一体化能力,为企业级场景落地与多智能体扩展奠定基础。 **--长期找工作,找长期工作
前面章节
.AI开发 1后端框架: ASP.NET Core2.AI框架: Semantic Kernerl (SK)、Agent Framework3.知识库:向量数据库(Qdrant)+关系型数据库(Post
https://blog.csdn.net/cao919/article/details/155895060
.net AI开发02 1后端框架: ASP.NET Core2.AI框架: Semantic Kernerl (SK)、Agent Framework3.知识库:向量数据库(Qdrant)+关系型数据库(Post
.net AI开发03 新增意图识别与工具选择工作流(IntentWorkflow),支持多智能体协作; 插件体系升级,支持多项目插件自动注册与工具发现; 对话历史与消息存储解耦,采用 Med
https://blog.csdn.net/cao919/article/details/156065076
.net AI开发04 第八章 引入RAG知识库与文档管理核心能力及事件总线
https://blog.csdn.net/cao919/article/details/156990895

第九章 新增 RAG 文档处理后台服务 RagWorker 及核心流程
.NETAI项目实战-09
1.构建RAG后台服务
2.实现文档上传消费程序
3.实现多格式文档解析
4.实现智能文本分割
4.动态嵌入模型实现文本嵌入
5.使用Qdrant 实现向量存储
本文介绍了一个企业级AI助理系统的升级项目,重点实现了RAG文档处理后台服务。该系统采用分层架构设计,包含文档上传、解析、分割、嵌入和向量存储等完整流程。技术栈包括ASP.NET Core、Semantic Kernel、Qdrant向量数据库等组件,支持多格式文档处理。核心功能包括:1) 文档解析器工厂实现PDF等格式解析;2) 文本分割服务处理语义连贯性;3) 嵌入生成器批量处理文本向量化;4) Qdrant向量存储管理。系统通过RabbitMQ实现异步处理,采用容器化部署方案,为企业提供智能化文档处理
星:这种pdf的文档的解析,是不是使用langchain会比较好?嵌入用python来做?
星:提取出来是不是应该是md格式,不应该是文本,要不图片、表格之类的处理不好?
提取文本(文档转文本)文本分割(引入)
1.模型上下文限制(Qwen3-4B 32K)==》2560维度,300~500 Token最佳的短文本块
2.语义的完整性:我最喜欢的编程/语言是C#
txt==》段落结构、句号、换行符==》自然语义边界
3.重叠窗口
Semantic Kernel==》提供文本处理工具库
分词库(GPT分词库)=》长度估算
11111
文本嵌入==》自然语言转换为数值向量的过程
苹果
香蕉
手机的向量==电话的向量
MEAI扩展库
OpenAl
1111
Qdrant+SK=向量存储
Qdrant ==Rust、过滤机制、Aspire集成包
PGsQL+Pgvector
2560维==》坐标
给出一个问题(用户的输入)的坐标Q,在数据点集合V中,找出距离Q最近的K个点
2091段落==》2091坐标点
KNN(K-最近邻)
暴力计算==》坐标Q和每一个点对比距离
(N)===》O(1ogN)
近似搜索算法==》HNSW算法==》地图导航
最顶层关键节点(快速跨越长距离)、最底层所有的数据点
顶层(高速公路)=》中层(主干道)=》底层(小街道)
66666
粉丝爽过就好用pgvector 和用qdrant有什:
6666
编码 code 新增 RAG 文档处理后台服务 RagWorker 及核心流程
本次提交引入 AICopilot.RagWorker Worker Service,实现了文档上传事件消费、解析、分割、嵌入生成与向量存储的完整 RAG 流程。集成 Qdrant、Semantic Kernel、OpenAI 等组件,支持多格式文档解析与批量嵌入,提升了系统的智能文档处理能力。同步完善了服务注册、依赖配置、超时策略及本地开发配置。
构建 aspire rag-worker
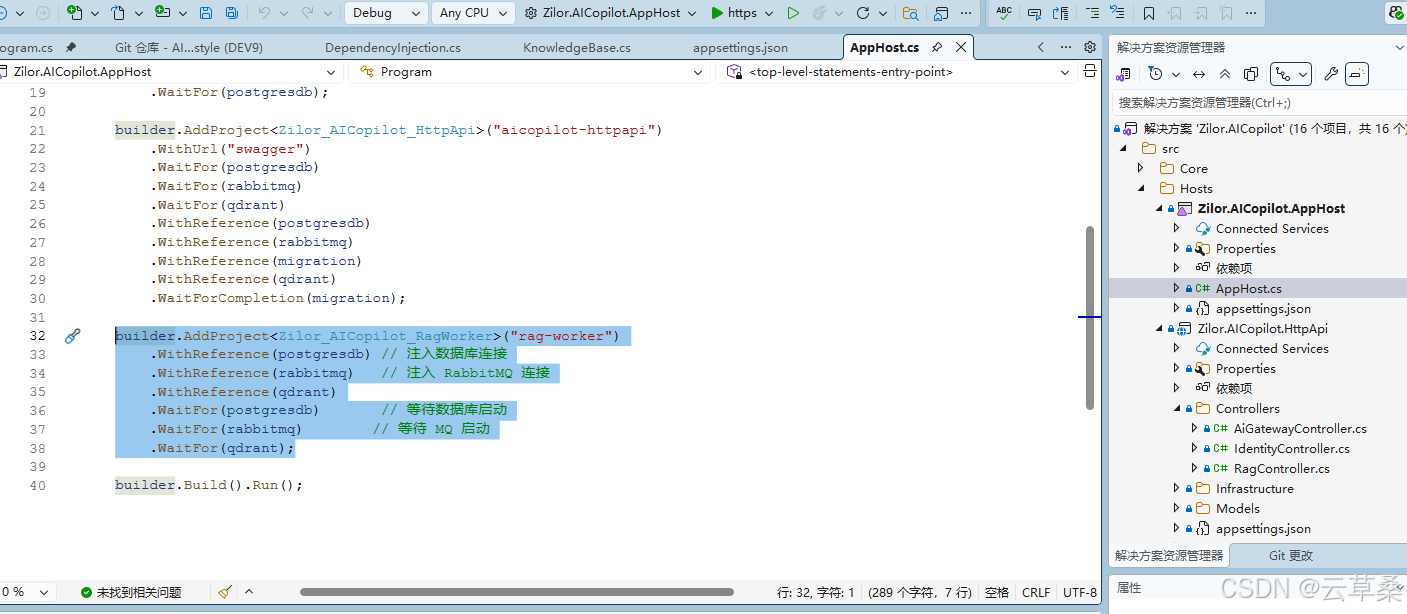
cs
builder.AddProject<Zilor_AICopilot_RagWorker>("rag-worker")
.WithReference(postgresdb) // 注入数据库连接
.WithReference(rabbitmq) // 注入 RabbitMQ 连接
.WithReference(qdrant)
.WaitFor(postgresdb) // 等待数据库启动
.WaitFor(rabbitmq) // 等待 MQ 启动
.WaitFor(qdrant);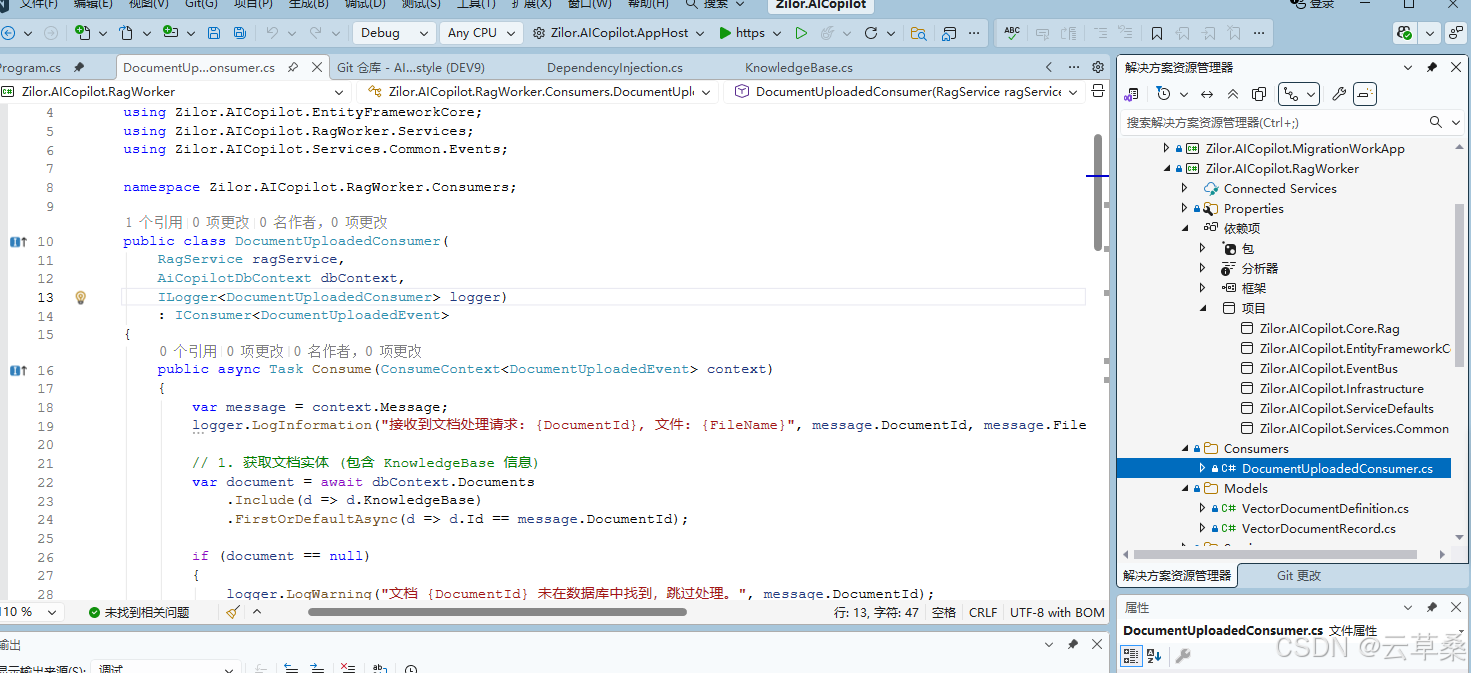
cs
using MassTransit;
using Microsoft.EntityFrameworkCore;
using Zilor.AICopilot.Core.Rag.Aggregates.KnowledgeBase;
using Zilor.AICopilot.EntityFrameworkCore;
using Zilor.AICopilot.RagWorker.Services;
using Zilor.AICopilot.Services.Common.Events;
namespace Zilor.AICopilot.RagWorker.Consumers;
public class DocumentUploadedConsumer(
RagService ragService,
AiCopilotDbContext dbContext,
ILogger<DocumentUploadedConsumer> logger)
: IConsumer<DocumentUploadedEvent>
{
public async Task Consume(ConsumeContext<DocumentUploadedEvent> context)
{
var message = context.Message;
logger.LogInformation("接收到文档处理请求: {DocumentId}, 文件: {FileName}", message.DocumentId, message.FileName);
// 1. 获取文档实体 (包含 KnowledgeBase 信息)
var document = await dbContext.Documents
.Include(d => d.KnowledgeBase)
.FirstOrDefaultAsync(d => d.Id == message.DocumentId);
if (document == null)
{
logger.LogWarning("文档 {DocumentId} 未在数据库中找到,跳过处理。", message.DocumentId);
return;
}
// 2. 幂等性与状态检查
// 如果文档已经处理成功(Indexed)或正在处理中(Parsing/Splitting/Embedding),则忽略
// 除非是 Failed 状态,才允许重试
if (document.Status != DocumentStatus.Pending && document.Status != DocumentStatus.Failed)
{
logger.LogInformation("文档 {DocumentId} 当前状态为 {Status},无需重复处理。", message.DocumentId, document.Status);
return;
}
try
{
// 3. 开始处理 - 状态流转
document.StartParsing();
await dbContext.SaveChangesAsync();
// TODO: 调用核心 ETL 流程 (Parse -> Split -> Embed -> Store)
await ragService.IndexDocumentAsync(document);
// 模拟处理成功
logger.LogInformation("文档 {DocumentId} 索引流程执行完毕。", message.DocumentId);
}
catch (Exception ex)
{
logger.LogError(ex, "文档 {DocumentId} 处理失败。", message.DocumentId);
// 4. 异常处理 - 记录错误状态
// 重新从数据库获取最新状态(防止并发冲突),标记为失败
var errorDoc = await dbContext.Documents.FindAsync(message.DocumentId);
if (errorDoc != null)
{
errorDoc.MarkAsFailed(ex.Message);
await dbContext.SaveChangesAsync();
}
// 根据业务需求,决定是否抛出异常以触发 RabbitMQ 的重试机制
// 这里我们选择吞掉异常,因为已经记录了 Failed 状态,避免死信队列堆积
}
}
}注意

处理

服务 索引构建
Step 1: 加载
Step 2: 解析
Step 3: 分割
Step 4: 嵌入
Step 5: 存储
源码Step 1: 加载Step 2: 解析Step 3: 分割Step 4: 嵌入Step 5: 存储
cs
using Microsoft.EntityFrameworkCore;
using Microsoft.Extensions.AI;
using Microsoft.Extensions.VectorData;
using Zilor.AICopilot.Core.Rag.Aggregates.KnowledgeBase;
using Zilor.AICopilot.EntityFrameworkCore;
using Zilor.AICopilot.RagWorker.Models;
using Zilor.AICopilot.RagWorker.Services.Embeddings;
using Zilor.AICopilot.RagWorker.Services.Parsers;
using Zilor.AICopilot.Services.Common.Contracts;
namespace Zilor.AICopilot.RagWorker.Services;
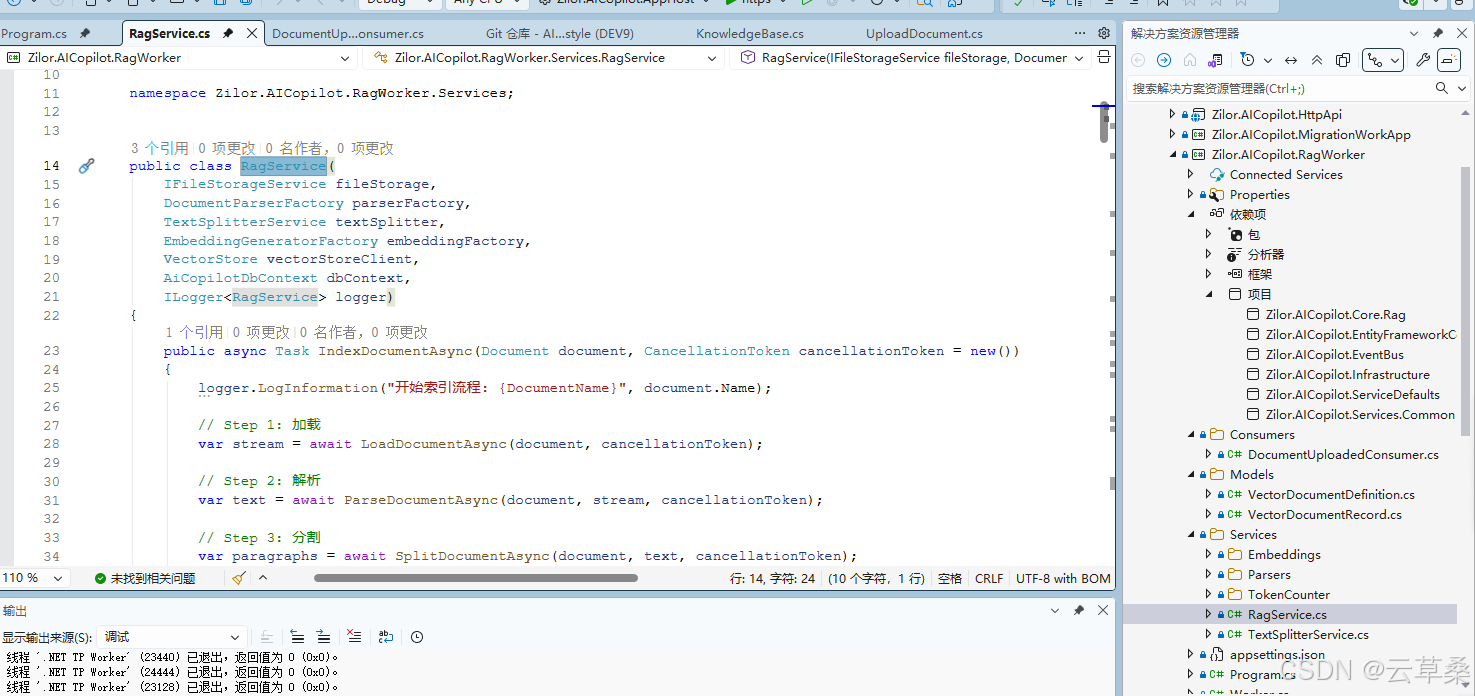
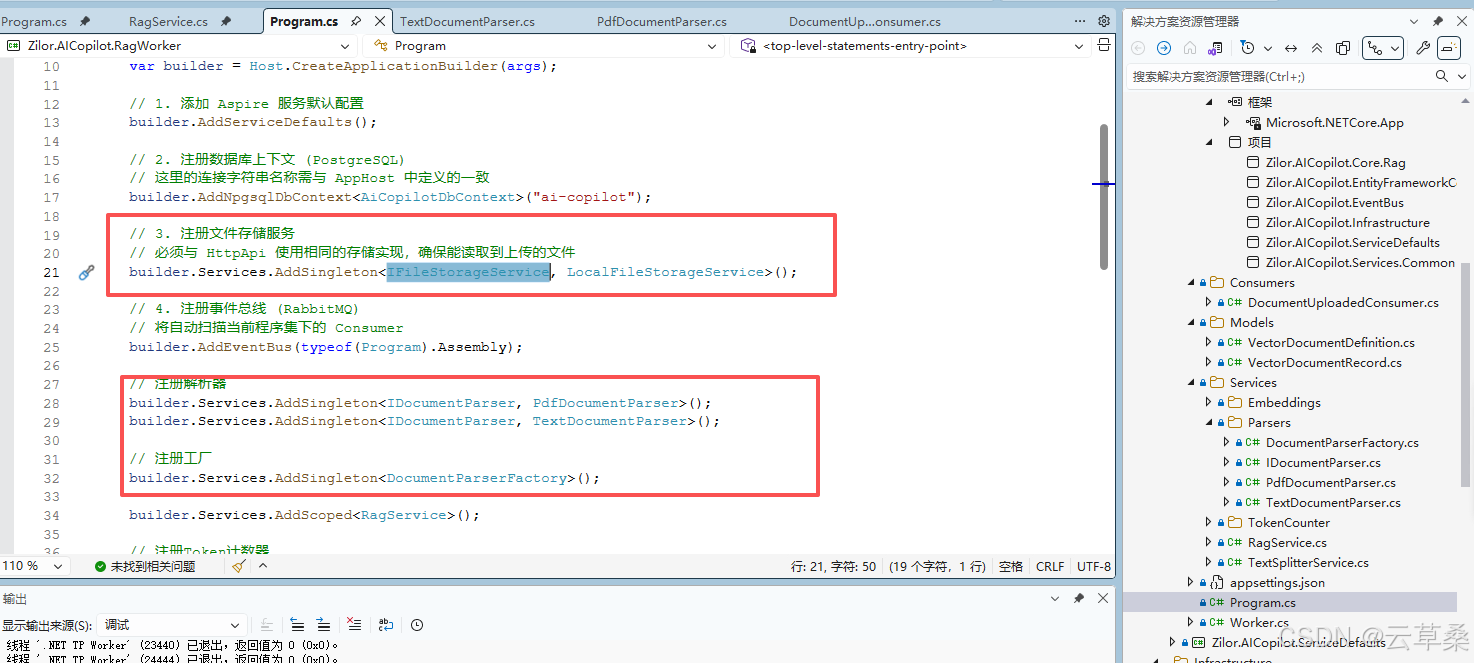
public class RagService(
IFileStorageService fileStorage,
DocumentParserFactory parserFactory,
TextSplitterService textSplitter,
EmbeddingGeneratorFactory embeddingFactory,
VectorStore vectorStoreClient,
AiCopilotDbContext dbContext,
ILogger<RagService> logger)
{
public async Task IndexDocumentAsync(Document document, CancellationToken cancellationToken = new())
{
logger.LogInformation("开始索引流程: {DocumentName}", document.Name);
// Step 1: 加载
var stream = await LoadDocumentAsync(document, cancellationToken);
// Step 2: 解析
var text = await ParseDocumentAsync(document, stream, cancellationToken);
// Step 3: 分割
var paragraphs = await SplitDocumentAsync(document, text, cancellationToken);
// Step 4: 嵌入
var (embeddings, dimensions) = await GenerateEmbeddingsAsync(document, paragraphs, cancellationToken);
// Step 5: 存储
await SaveVectorAsync(document, paragraphs, embeddings, dimensions, cancellationToken);
logger.LogInformation("文档索引完成: {DocumentName}", document.Name);
}
// ================================================================
// Step 1: 加载
// ================================================================
private async Task<Stream> LoadDocumentAsync(Document document, CancellationToken ct)
{
logger.LogInformation("加载文档...");
// 从存储中获取文件流
var stream = await fileStorage.GetAsync(document.FilePath, ct);
return stream ?? throw new FileNotFoundException($"文件未找到: {document.FilePath}");
}
// ================================================================
// Step 2: 解析
// ================================================================
private async Task<string> ParseDocumentAsync(Document document, Stream stream, CancellationToken ct)
{
logger.LogInformation("解析文档...");
// 根据扩展名获取解析器
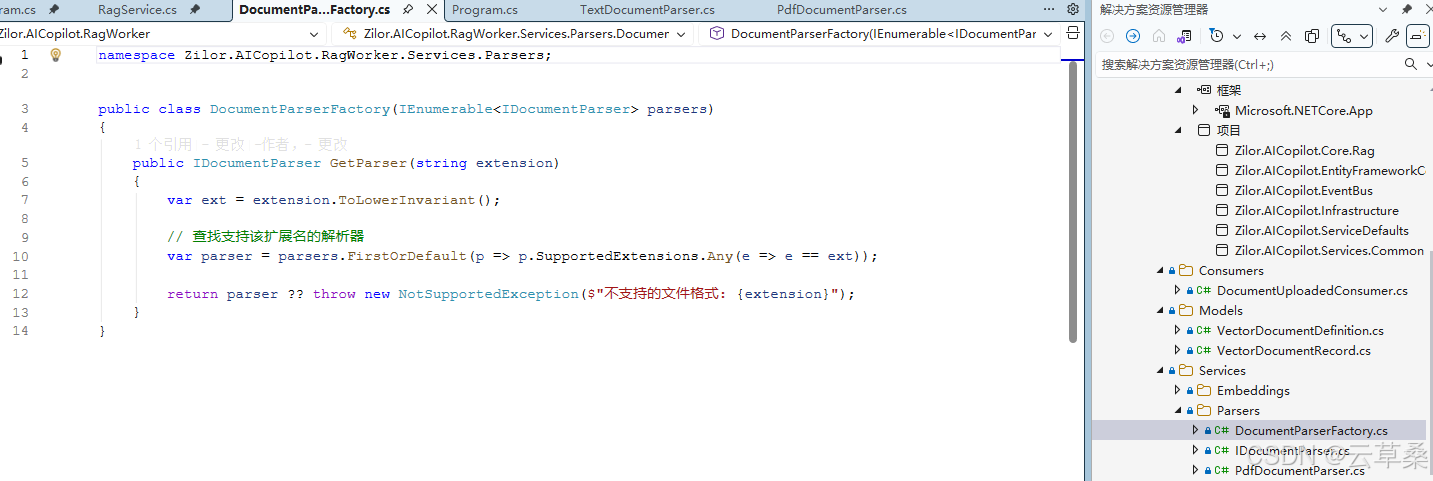
var parser = parserFactory.GetParser(document.Extension);
// 提取文本
var text = await parser.ParseAsync(stream, ct);
if (string.IsNullOrWhiteSpace(text))
throw new InvalidOperationException("文档内容为空或无法提取文本。");
logger.LogInformation("文本提取完成,长度: {Length} 字符", text.Length);
// 更新状态:解析完成 -> 准备切片
document.CompleteParsing();
await dbContext.SaveChangesAsync(ct);
return text;
}
// ================================================================
// Step 3: 切片
// ================================================================
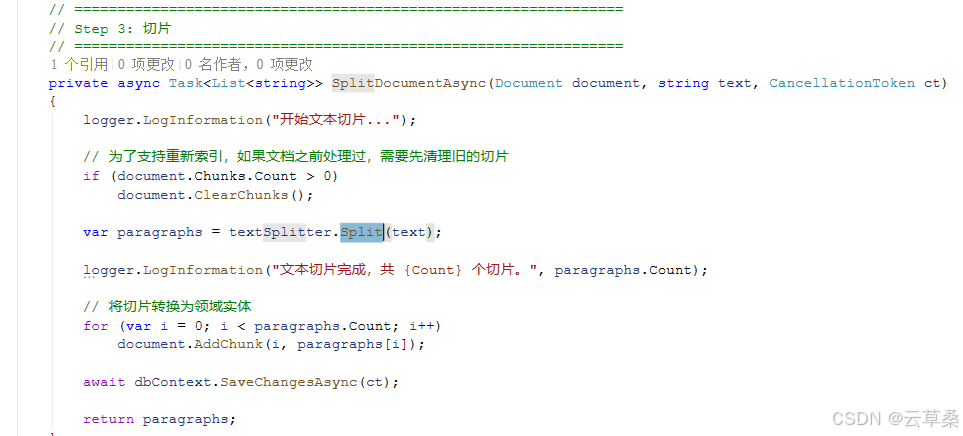
private async Task<List<string>> SplitDocumentAsync(Document document, string text, CancellationToken ct)
{
logger.LogInformation("开始文本切片...");
// 为了支持重新索引,如果文档之前处理过,需要先清理旧的切片
if (document.Chunks.Count > 0)
document.ClearChunks();
var paragraphs = textSplitter.Split(text);
logger.LogInformation("文本切片完成,共 {Count} 个切片。", paragraphs.Count);
// 将切片转换为领域实体
for (var i = 0; i < paragraphs.Count; i++)
document.AddChunk(i, paragraphs[i]);
await dbContext.SaveChangesAsync(ct);
return paragraphs;
}
// ================================================================
// Step 4: 嵌入
// ================================================================
private async Task<(List<Embedding<float>>, int)> GenerateEmbeddingsAsync(
Document document,
List<string> paragraphs,
CancellationToken ct)
{
logger.LogInformation("开始生成嵌入向量...");
// 获取嵌入模型配置
var embeddingModelConfig = await dbContext.EmbeddingModels.AsNoTracking()
.FirstOrDefaultAsync(em => em.Id == document.KnowledgeBase.EmbeddingModelId,
cancellationToken: ct);
if (embeddingModelConfig == null)
{
throw new InvalidOperationException($"未找到 ID 为 {document.KnowledgeBase.EmbeddingModelId} 的嵌入模型配置");
}
// 创建嵌入生成器
using var generator = embeddingFactory.CreateGenerator(embeddingModelConfig);
// 准备分批
// [配置建议]
// - 本地模型: 建议 20 ~ 50 (取决于显卡)
// - 云端模型: 建议 50 ~ 100
const int batchSize = 50;
// 用于收集所有生成的向量结果
var allEmbeddings = new List<Embedding<float>>();
// 将段落切分为多个批次
var batches = paragraphs.Chunk(batchSize).ToArray();
logger.LogInformation("共 {Paragraphs} 个段落,将分为 {Batches} 批处理", paragraphs.Count, batches.Length);
// 循环处理每一批
for (var i = 0; i < batches.Length; i++)
{
logger.LogInformation("正在处理第 {Current}/{Total} 批...", i + 1, batches.Length);
try
{
var batch = batches[i];
// 调用模型生成当前批次的向量
var result = await generator.GenerateAsync(batch, cancellationToken: ct);
// 将结果添加到总列表中
allEmbeddings.AddRange(result);
}
catch (Exception ex)
{
logger.LogError(ex, "第 {Batch} 批次向量化失败", i + 1);
throw;
}
}
var dimensions = allEmbeddings.First().Vector.Length;
logger.LogInformation("向量化完成,共生成 {Count} 个向量,维度: {Dim}", allEmbeddings.Count, dimensions);
return (allEmbeddings, dimensions);
}
// ================================================================
// Step 5: 保存向量
// ================================================================
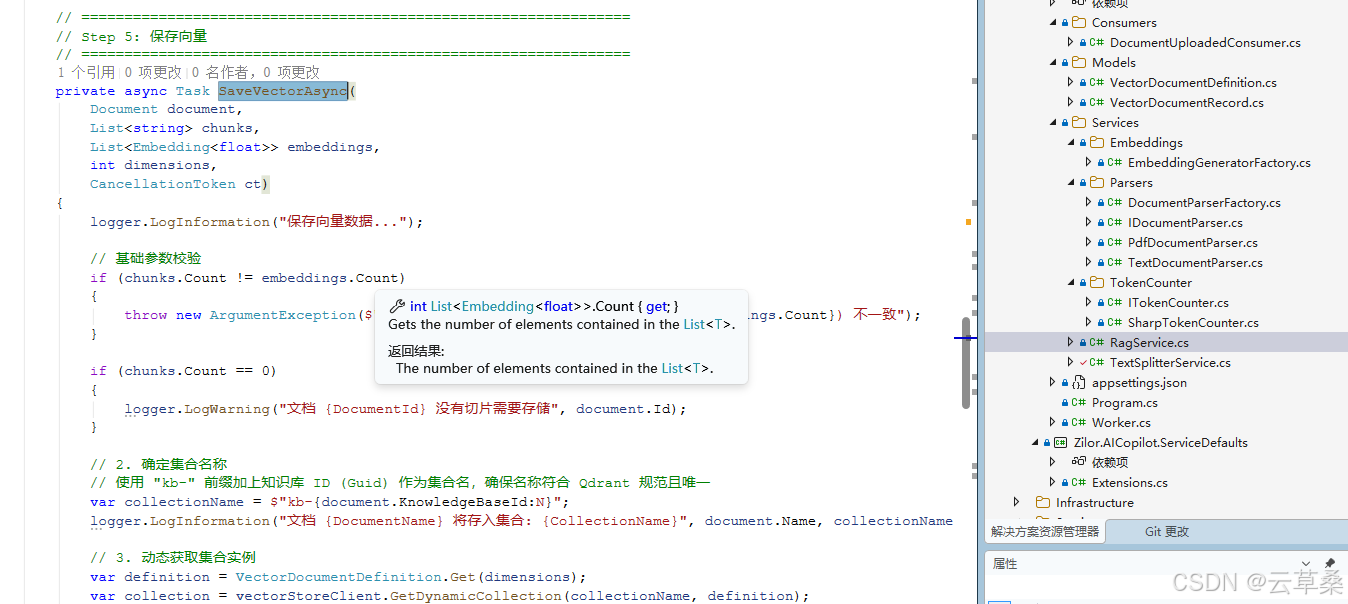
private async Task SaveVectorAsync(
Document document,
List<string> chunks,
List<Embedding<float>> embeddings,
int dimensions,
CancellationToken ct)
{
logger.LogInformation("保存向量数据...");
// 基础参数校验
if (chunks.Count != embeddings.Count)
{
throw new ArgumentException($"切片数量 ({chunks.Count}) 与向量数量 ({embeddings.Count}) 不一致");
}
if (chunks.Count == 0)
{
logger.LogWarning("文档 {DocumentId} 没有切片需要存储", document.Id);
}
// 2. 确定集合名称
// 使用 "kb-" 前缀加上知识库 ID (Guid) 作为集合名,确保名称符合 Qdrant 规范且唯一
var collectionName = $"kb-{document.KnowledgeBaseId:N}";
logger.LogInformation("文档 {DocumentName} 将存入集合: {CollectionName}", document.Name, collectionName);
// 3. 动态获取集合实例
var definition = VectorDocumentDefinition.Get(dimensions);
var collection = vectorStoreClient.GetDynamicCollection(collectionName, definition);
// 4. 确保集合存在
// 第一次向该知识库上传文档时,会自动创建集合
await collection.EnsureCollectionExistsAsync(ct);
// 5. 组装存储记录
try
{
for (var i = 0; i < chunks.Count; i++)
{
// 生成一个唯一的记录键值
var recordKey = (ulong)document.Id.GetHashCode() << 32 | (uint)i;
await collection.UpsertAsync(new Dictionary<string, object?>
{
{ "Key", recordKey },
{ "Text", chunks[i] },
{ "DocumentId", document.Id.ToString() },
{ "KnowledgeBaseId", document.KnowledgeBaseId.ToString() },
{ "ChunkIndex", i },
{ "Embedding", embeddings[i].Vector }
}, ct);
}
logger.LogInformation("成功向集合 {Collection} 写入 {Count} 条向量记录。", collectionName, chunks.Count);
}
catch (Exception ex)
{
logger.LogError(ex, "写入向量数据库失败。Collection: {Collection}", collectionName);
throw;
}
document.MarkAsIndexed();
await dbContext.SaveChangesAsync(ct);
}
}.pdf 处理
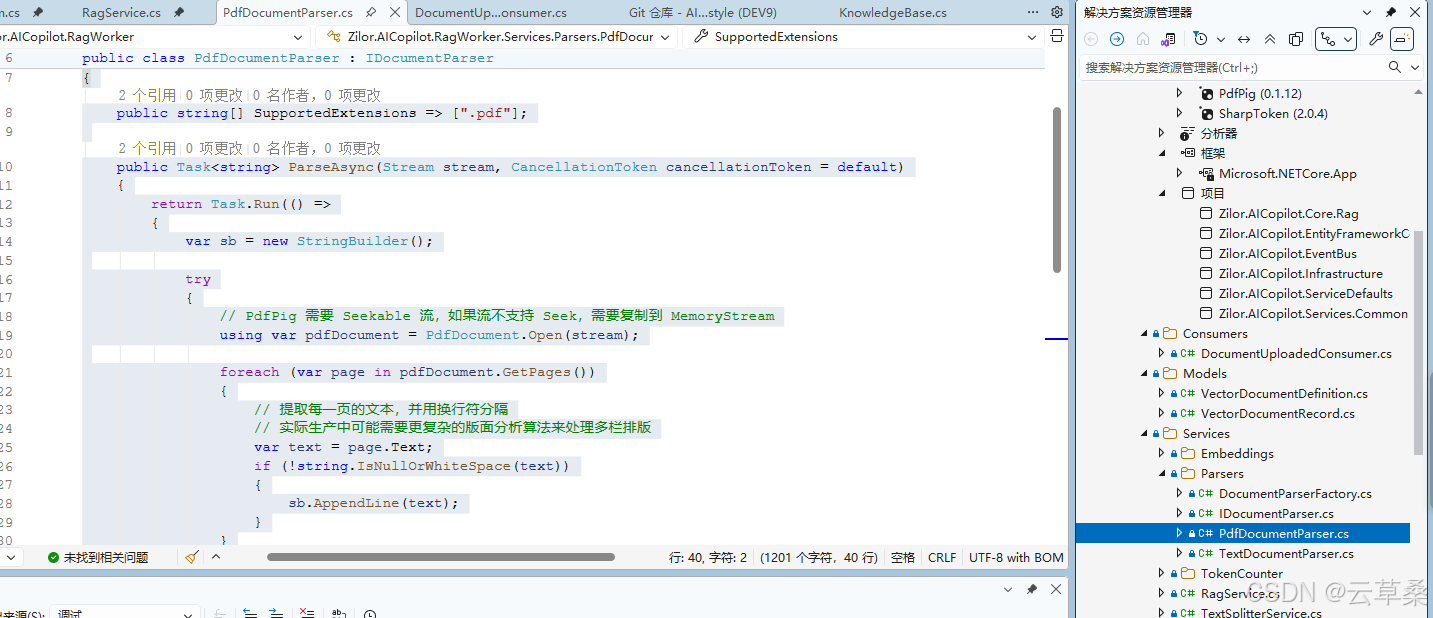
cs
using System.Text;
using UglyToad.PdfPig;
namespace Zilor.AICopilot.RagWorker.Services.Parsers;
public class PdfDocumentParser : IDocumentParser
{
public string[] SupportedExtensions => [".pdf"];
public Task<string> ParseAsync(Stream stream, CancellationToken cancellationToken = default)
{
return Task.Run(() =>
{
var sb = new StringBuilder();
try
{
// PdfPig 需要 Seekable 流,如果流不支持 Seek,需要复制到 MemoryStream
using var pdfDocument = PdfDocument.Open(stream);
foreach (var page in pdfDocument.GetPages())
{
// 提取每一页的文本,并用换行符分隔
// 实际生产中可能需要更复杂的版面分析算法来处理多栏排版
var text = page.Text;
if (!string.IsNullOrWhiteSpace(text))
{
sb.AppendLine(text);
}
}
}
catch (Exception ex)
{
throw new InvalidOperationException("PDF 解析失败,文件可能已损坏或加密。", ex);
}
return sb.ToString();
}, cancellationToken);
}
}DI
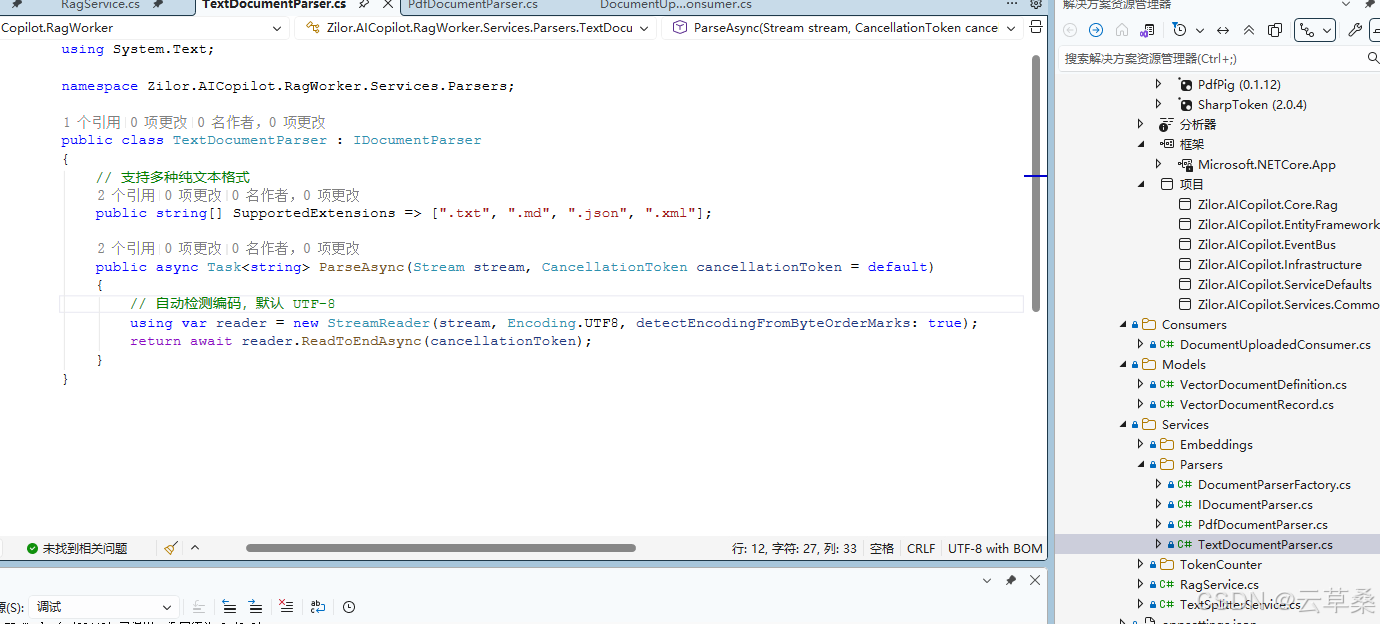
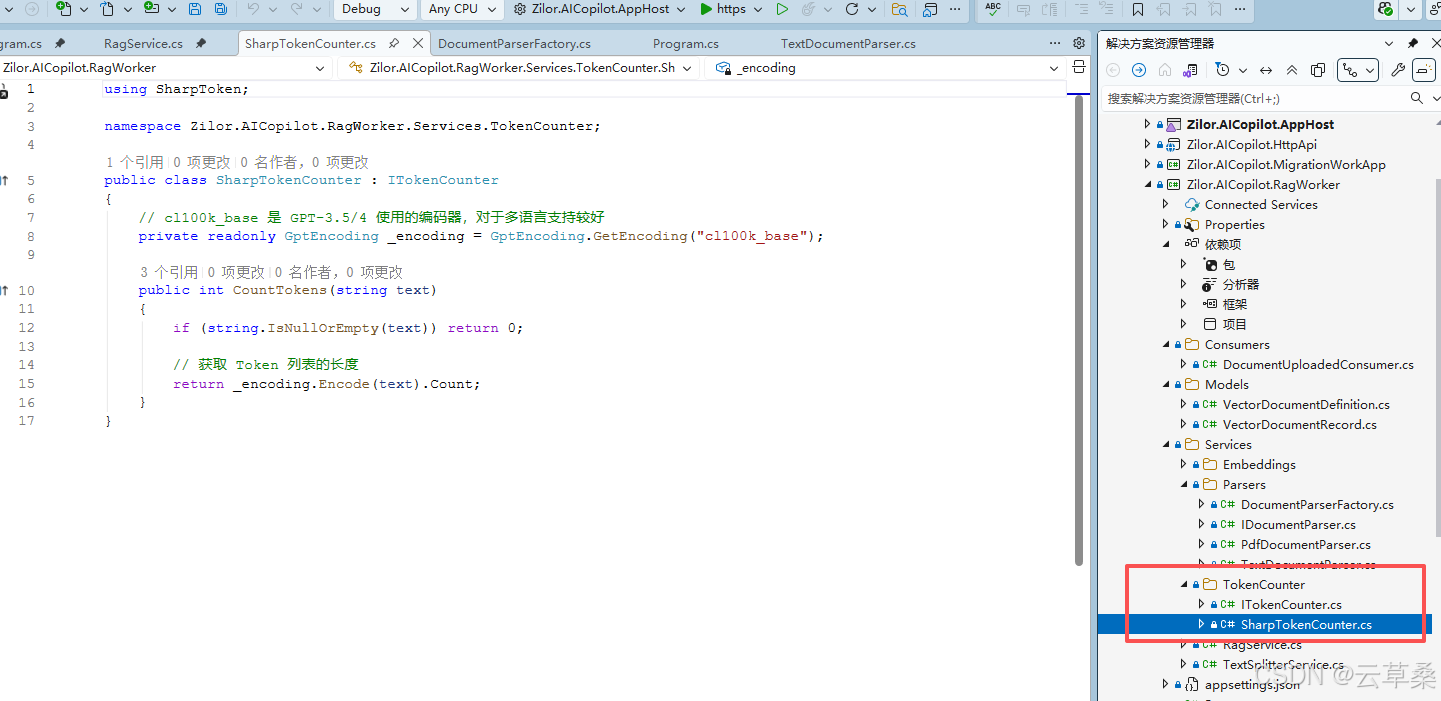
token 处理估算
cs
using SharpToken;
namespace Zilor.AICopilot.RagWorker.Services.TokenCounter;
public class SharpTokenCounter : ITokenCounter
{
// cl100k_base 是 GPT-3.5/4 使用的编码器,对于多语言支持较好
private readonly GptEncoding _encoding = GptEncoding.GetEncoding("cl100k_base");
public int CountTokens(string text)
{
if (string.IsNullOrEmpty(text)) return 0;
// 获取 Token 列表的长度
return _encoding.Encode(text).Count;
}
}03token切片和组合
cs
using Microsoft.SemanticKernel.Text;
using Zilor.AICopilot.RagWorker.Services.TokenCounter;
#pragma warning disable SKEXP0050
namespace Zilor.AICopilot.RagWorker.Services;
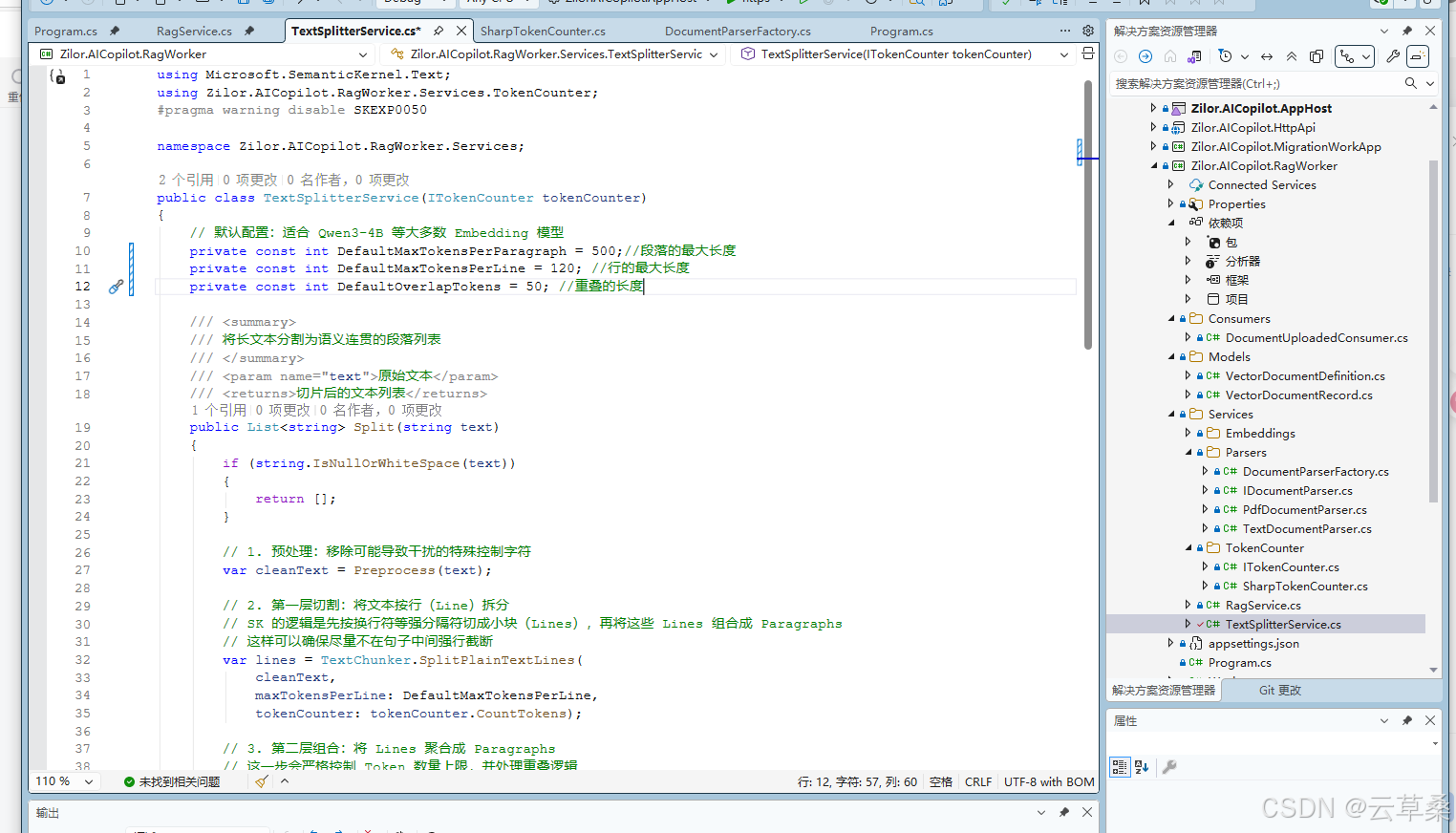
public class TextSplitterService(ITokenCounter tokenCounter)
{
// 默认配置:适合 Qwen3-4B 等大多数 Embedding 模型
private const int DefaultMaxTokensPerParagraph = 500;//段落的最大长度
private const int DefaultMaxTokensPerLine = 120; //行的最大长度
private const int DefaultOverlapTokens = 50; //重叠的长度
/// <summary>
/// 将长文本分割为语义连贯的段落列表
/// </summary>
/// <param name="text">原始文本</param>
/// <returns>切片后的文本列表</returns>
public List<string> Split(string text)
{
if (string.IsNullOrWhiteSpace(text))
{
return [];
}
// 1. 预处理:移除可能导致干扰的特殊控制字符
var cleanText = Preprocess(text);
// 2. 第一层切割:将文本按行(Line)拆分
// SK 的逻辑是先按换行符等强分隔符切成小块(Lines),再将这些 Lines 组合成 Paragraphs
// 这样可以确保尽量不在句子中间强行截断
var lines = TextChunker.SplitPlainTextLines(
cleanText,
maxTokensPerLine: DefaultMaxTokensPerLine,
tokenCounter: tokenCounter.CountTokens);
// 3. 第二层组合:将 Lines 聚合成 Paragraphs
// 这一步会严格控制 Token 数量上限,并处理重叠逻辑
var paragraphs = TextChunker.SplitPlainTextParagraphs(
lines,
maxTokensPerParagraph: DefaultMaxTokensPerParagraph,
overlapTokens: DefaultOverlapTokens,
tokenCounter: tokenCounter.CountTokens);
return paragraphs;
}
private static string Preprocess(string text)
{
// 替换掉 Windows 的 \r\n 为 \n,统一换行符
// 移除 NULL 字符等
return text.Replace("\r\n", "\n").Trim();
}
}
04文本嵌入 自然语言转换为数值向量的过程
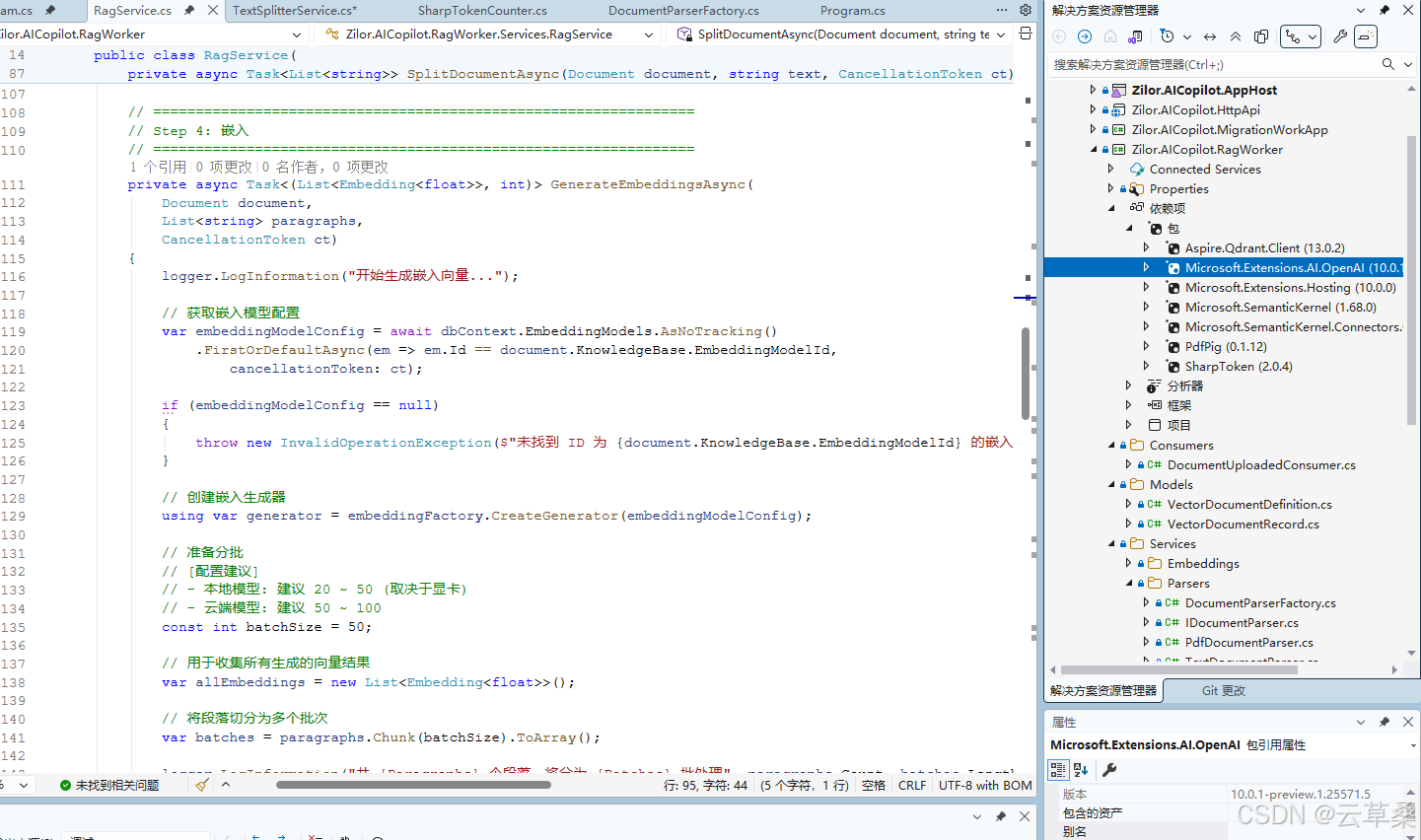
cs
using System.ClientModel;
using System.ClientModel.Primitives;
using Microsoft.Extensions.AI;
using OpenAI;
using Zilor.AICopilot.Core.Rag.Aggregates.EmbeddingModel;
namespace Zilor.AICopilot.RagWorker.Services.Embeddings;
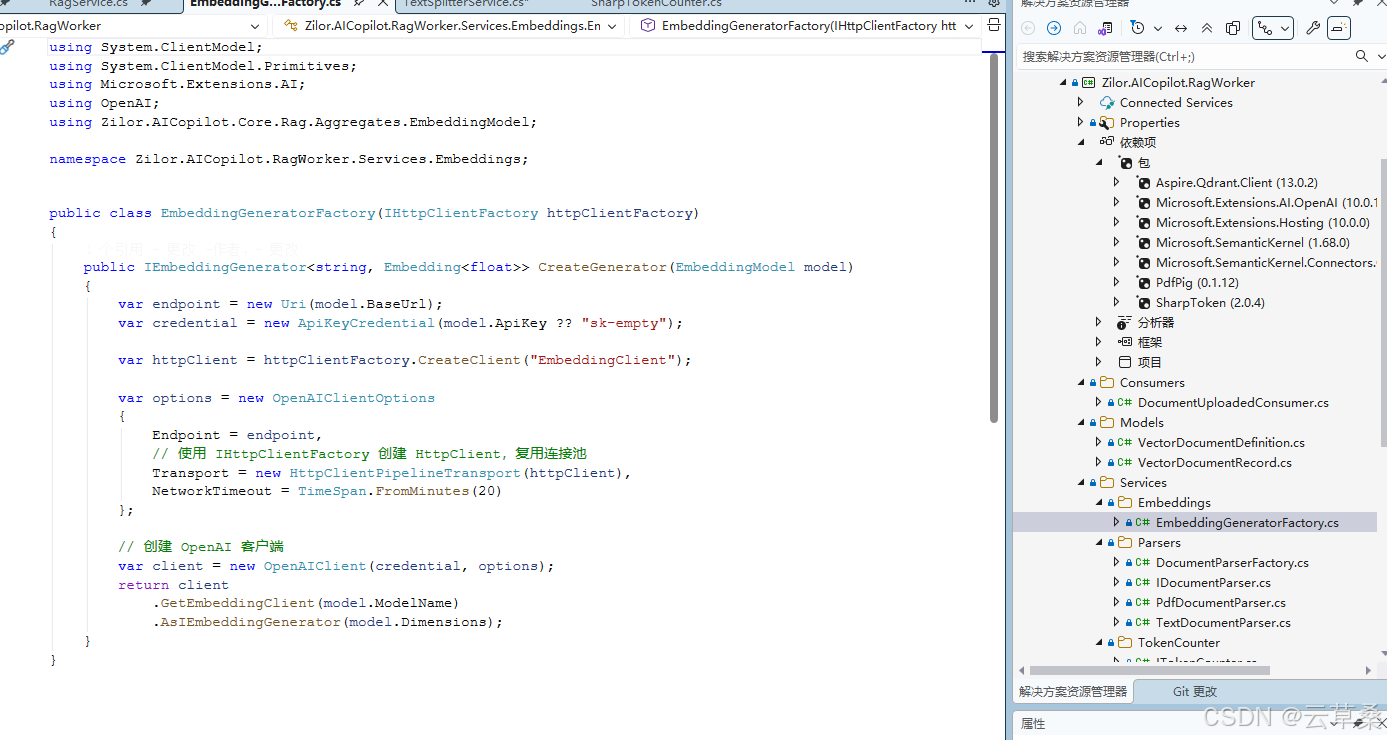
public class EmbeddingGeneratorFactory(IHttpClientFactory httpClientFactory)
{
public IEmbeddingGenerator<string, Embedding<float>> CreateGenerator(EmbeddingModel model)
{
var endpoint = new Uri(model.BaseUrl);
var credential = new ApiKeyCredential(model.ApiKey ?? "sk-empty");
var httpClient = httpClientFactory.CreateClient("EmbeddingClient");
var options = new OpenAIClientOptions
{
Endpoint = endpoint,
// 使用 IHttpClientFactory 创建 HttpClient,复用连接池
Transport = new HttpClientPipelineTransport(httpClient),
NetworkTimeout = TimeSpan.FromMinutes(20)
};
// 创建 OpenAI 客户端
var client = new OpenAIClient(credential, options);
return client
.GetEmbeddingClient(model.ModelName)
.AsIEmbeddingGenerator(model.Dimensions);
}
}注意
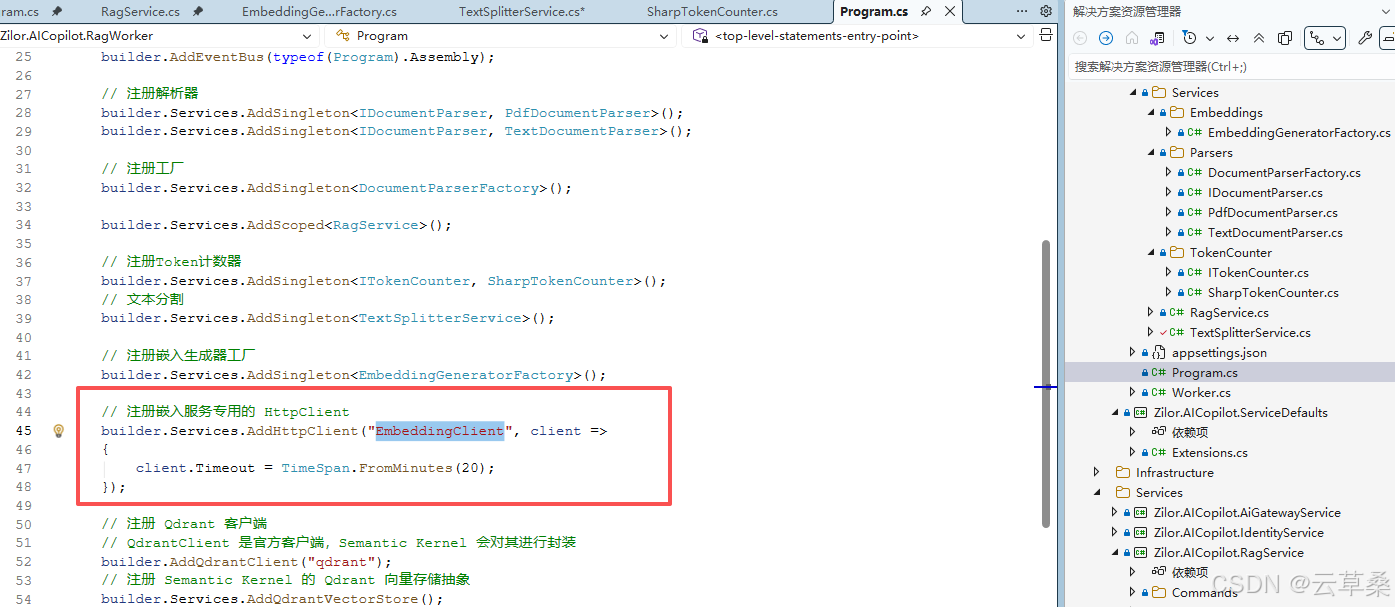

cs
// 将默认的 10秒 延长到 5分钟,这对大多数 AI 场景都更友好
options.AttemptTimeout.Timeout = TimeSpan.FromMinutes(5);
options.TotalRequestTimeout.Timeout = TimeSpan.FromMinutes(10);
options.CircuitBreaker.SamplingDuration = TimeSpan.FromMinutes(10);
cs
// ================================================================
// Step 4: 嵌入
// ================================================================
private async Task<(List<Embedding<float>>, int)> GenerateEmbeddingsAsync(
Document document,
List<string> paragraphs,
CancellationToken ct)
{
logger.LogInformation("开始生成嵌入向量...");
// 获取嵌入模型配置
var embeddingModelConfig = await dbContext.EmbeddingModels.AsNoTracking()
.FirstOrDefaultAsync(em => em.Id == document.KnowledgeBase.EmbeddingModelId,
cancellationToken: ct);
if (embeddingModelConfig == null)
{
throw new InvalidOperationException($"未找到 ID 为 {document.KnowledgeBase.EmbeddingModelId} 的嵌入模型配置");
}
// 创建嵌入生成器
using var generator = embeddingFactory.CreateGenerator(embeddingModelConfig);
// 准备分批
// [配置建议]
// - 本地模型: 建议 20 ~ 50 (取决于显卡)
// - 云端模型: 建议 50 ~ 100
const int batchSize = 50;
// 用于收集所有生成的向量结果
var allEmbeddings = new List<Embedding<float>>();
// 将段落切分为多个批次
var batches = paragraphs.Chunk(batchSize).ToArray();
logger.LogInformation("共 {Paragraphs} 个段落,将分为 {Batches} 批处理", paragraphs.Count, batches.Length);
// 循环处理每一批
for (var i = 0; i < batches.Length; i++)
{
logger.LogInformation("正在处理第 {Current}/{Total} 批...", i + 1, batches.Length);
try
{
var batch = batches[i];
// 调用模型生成当前批次的向量
var result = await generator.GenerateAsync(batch, cancellationToken: ct);
// 将结果添加到总列表中
allEmbeddings.AddRange(result);
}
catch (Exception ex)
{
logger.LogError(ex, "第 {Batch} 批次向量化失败", i + 1);
throw;
}
}
var dimensions = allEmbeddings.First().Vector.Length;
logger.LogInformation("向量化完成,共生成 {Count} 个向量,维度: {Dim}", allEmbeddings.Count, dimensions);
return (allEmbeddings, dimensions);
}向量存储 持久化
codefirst Qdrant 向量实体
cs
using Microsoft.Extensions.VectorData;
namespace Zilor.AICopilot.RagWorker.Models;
/// <summary>
/// 对应向量数据库中的一条记录
/// </summary>
public class VectorDocumentRecord
{
/// <summary>
/// 记录的唯一标识符
/// </summary>
/// <remarks>
/// 使用 ulong 类型,因为 Qdrant 内部 ID 支持 64 位无符号整数或 UUID。
/// 这里我们不使用 Guid,而是为了与语义对齐,将在存储时生成唯一 ID。
/// </remarks>
[VectorStoreKey]
public ulong Key { get; set; }
/// <summary>
/// 原始文本内容
/// </summary>
[VectorStoreData(IsFullTextIndexed = true)]
public string Text { get; set; } = string.Empty;
/// <summary>
/// 关联的文档 ID (元数据)
/// </summary>
/// <remarks>
/// IsFilterable = true 允许我们在检索时按 DocumentId 过滤,
/// 例如:只查询特定文档的内容。
/// </remarks>
[VectorStoreData(IsIndexed = true)]
public string DocumentId { get; set; } = string.Empty;
/// <summary>
/// 关联的知识库 ID (元数据)
/// </summary>
[VectorStoreData(IsIndexed = true)]
public string KnowledgeBaseId { get; set; } = string.Empty;
/// <summary>
/// 原始切片在文档中的索引顺序
/// </summary>
[VectorStoreData]
public int ChunkIndex { get; set; }
/// <summary>
/// 嵌入向量
/// </summary>
/// <remarks>
/// Dimensions 必须与我们使用的模型(Qwen3-4B)一致,否则插入会报错。
/// DistanceFunction 定义了相似度计算方式,Cosine (余弦相似度) 是文本检索的标准选择。
/// </remarks>
[VectorStoreVector(Dimensions: 2560, DistanceFunction = DistanceFunction.CosineSimilarity, IndexKind = IndexKind.Hnsw)]
public ReadOnlyMemory<float> Embedding { get; set; }
}
cs
using Microsoft.Extensions.VectorData;
namespace Zilor.AICopilot.RagWorker.Models;
public static class VectorDocumentDefinition
{
public static VectorStoreCollectionDefinition Get(int dimensions)
{
VectorStoreCollectionDefinition definition = new()
{
Properties = new List<VectorStoreProperty>
{
new VectorStoreKeyProperty("Key", typeof(ulong)),
new VectorStoreDataProperty("Text", typeof(string)) { IsFullTextIndexed = true },
new VectorStoreDataProperty("DocumentId", typeof(string)){ IsIndexed = true },
new VectorStoreDataProperty("KnowledgeBaseId", typeof(string)){ IsIndexed = true },
new VectorStoreDataProperty("ChunkIndex", typeof(int)),
new VectorStoreVectorProperty("Embedding", typeof(ReadOnlyMemory<float>),
dimensions: dimensions)
{
DistanceFunction = DistanceFunction.CosineSimilarity,
IndexKind = IndexKind.Hnsw
}
}
};
return definition;
}
}注册抽象的向量存储服务
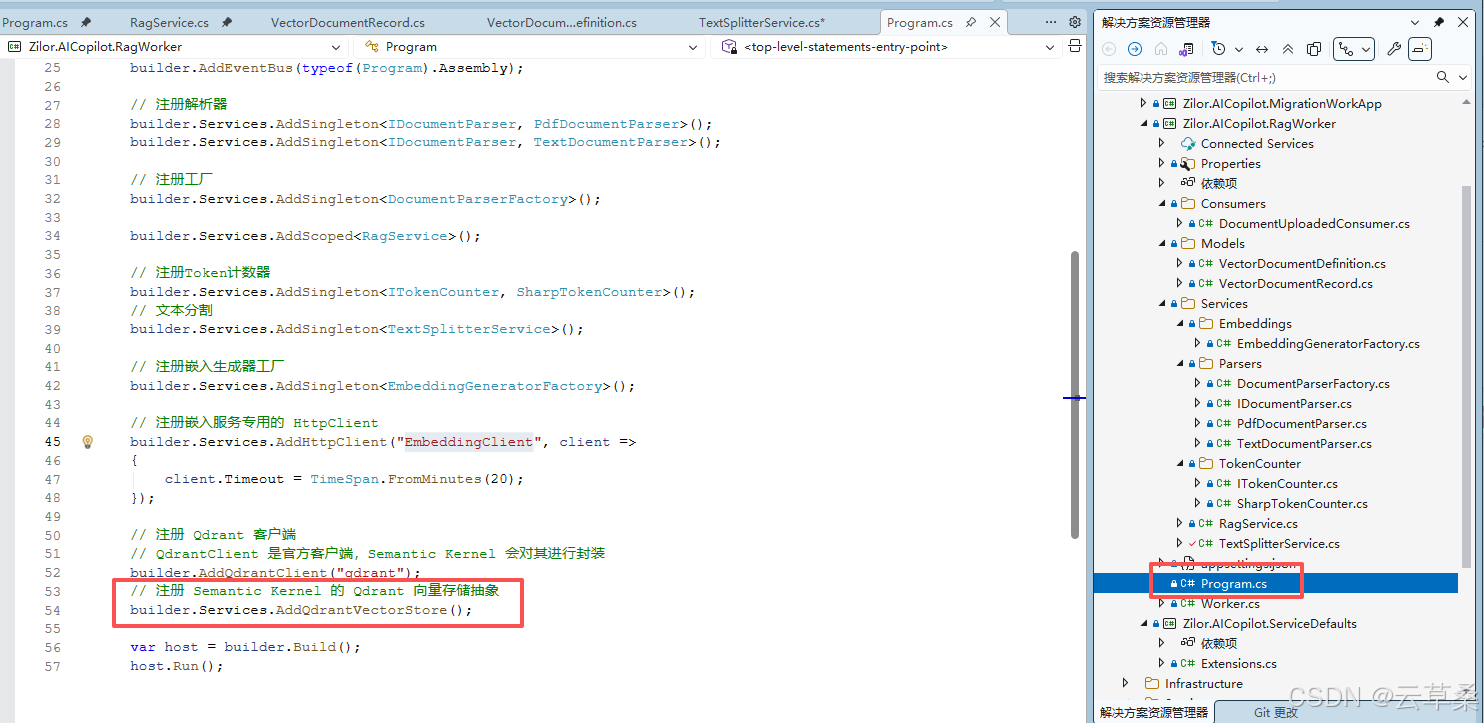
cs
// 注册 Qdrant 客户端
// QdrantClient 是官方客户端,Semantic Kernel 会对其进行封装
builder.AddQdrantClient("qdrant");
// 注册 Semantic Kernel 的 Qdrant 向量存储抽象
builder.Services.AddQdrantVectorStore();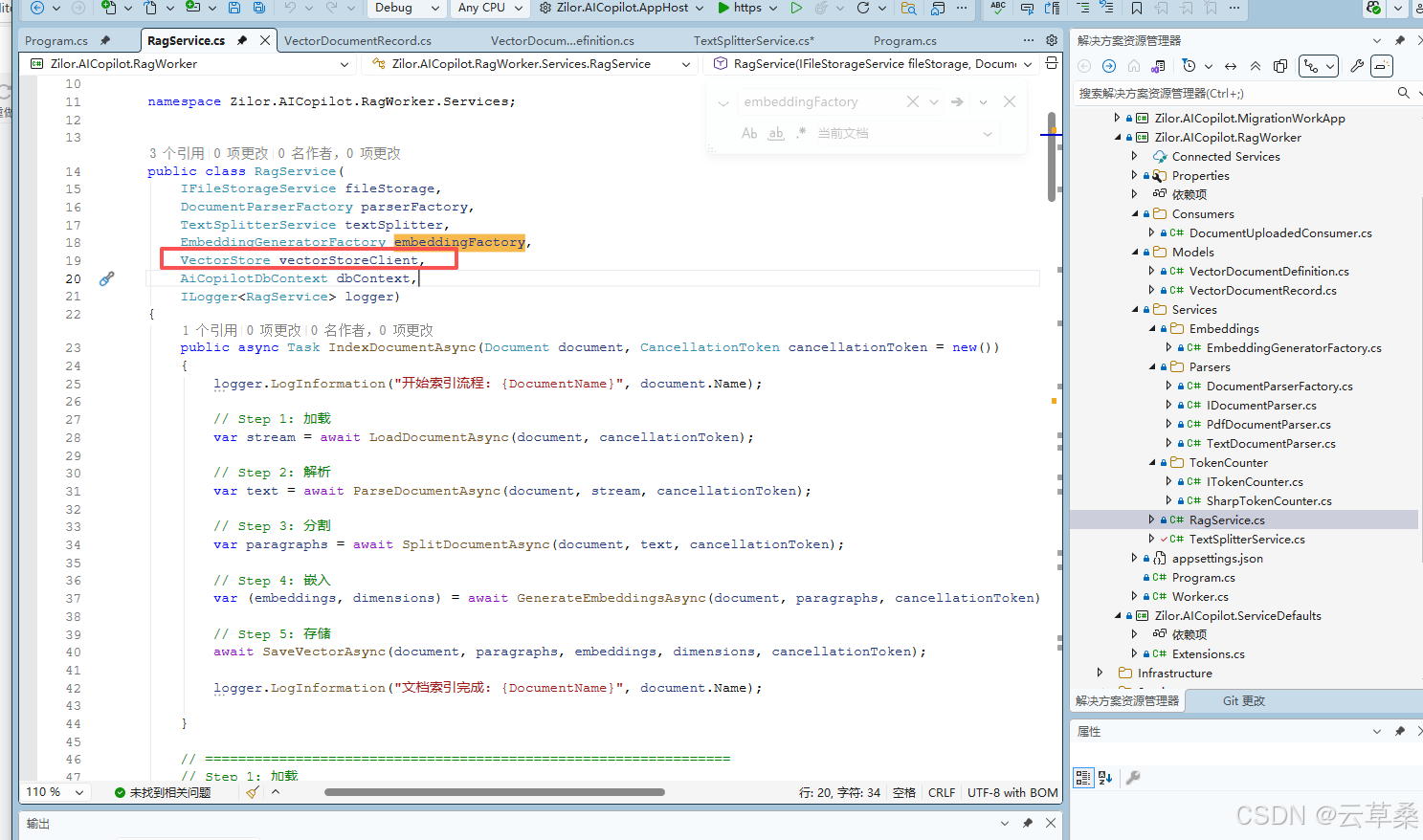
Step 5: 保存向量
标记索引完成
document.MarkAsIndexed();
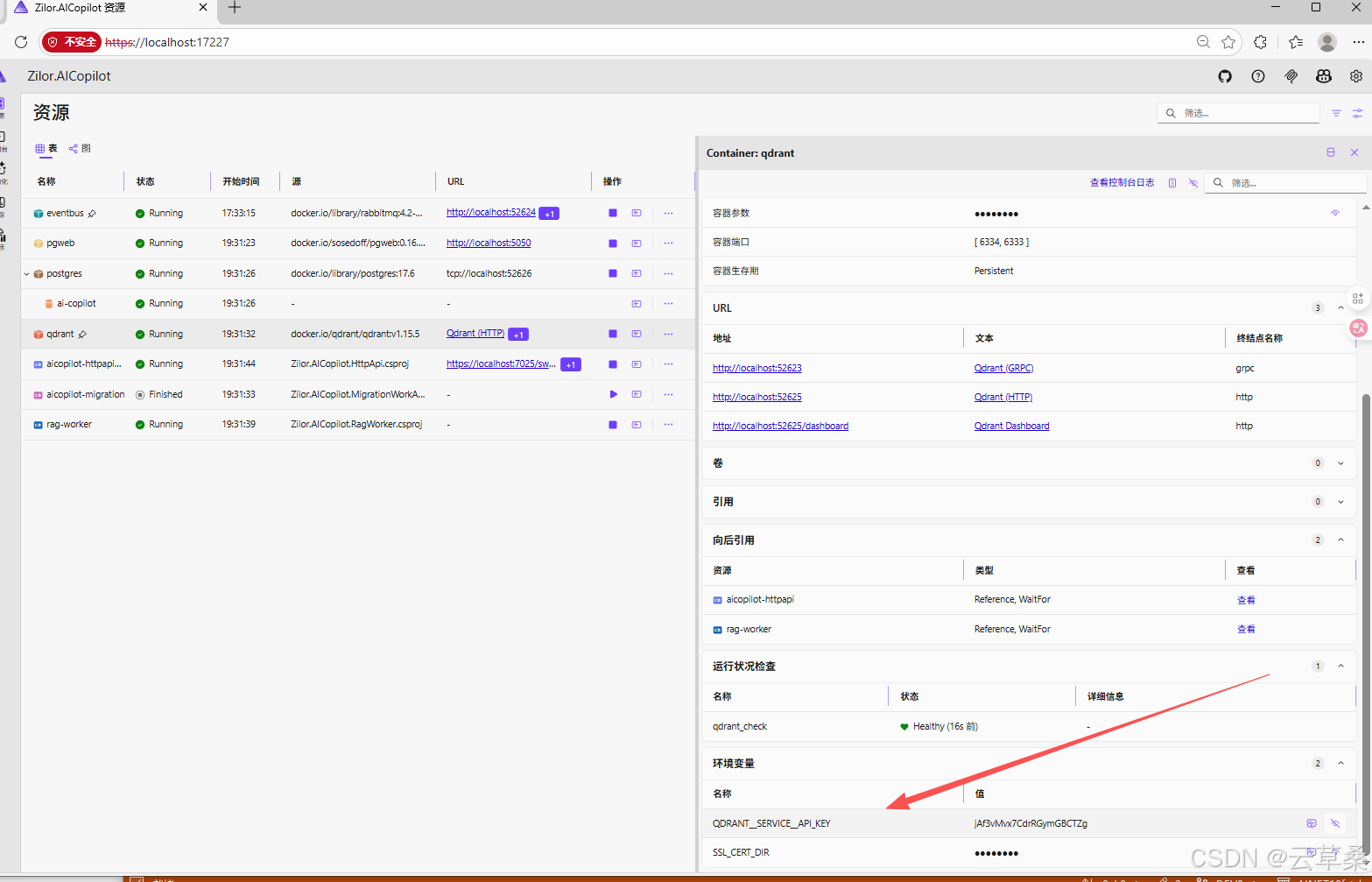
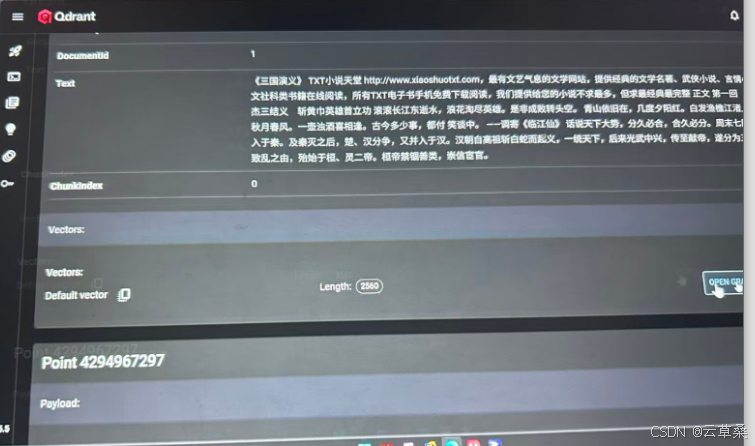
Qdrant 仪表盘使用
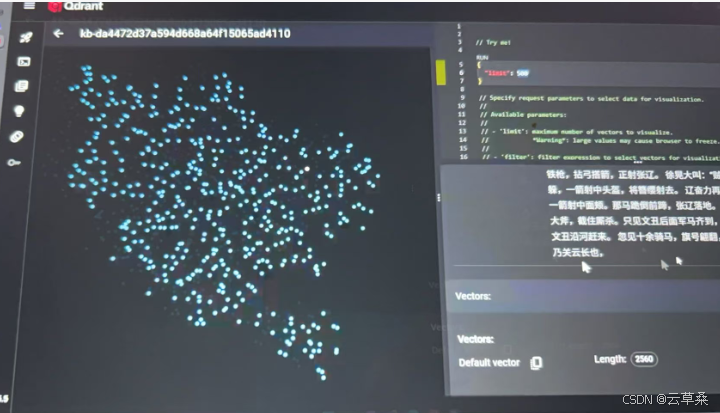
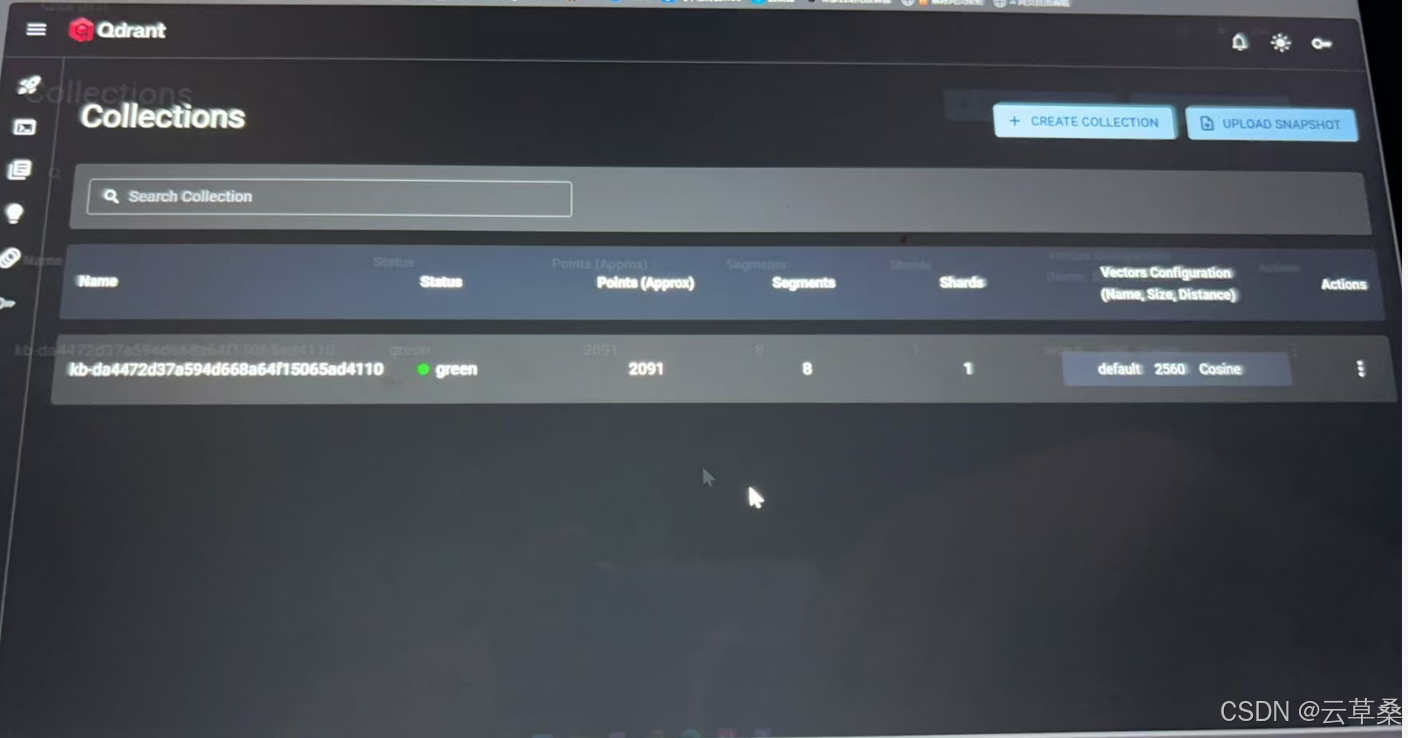
源码地址
代码https://gitcode.com/cao9prc/AINET10fstyle
其他专题
AI开发01 1后端框架: ASP.NET Core2.AI框架: Semantic Kernerl (SK)、Agent Framework3.知识库:向量数据库(Qdrant)+关系型数据库(Post
https://blog.csdn.net/cao919/article/details/155895060
.net AI开发02 1后端框架: ASP.NET Core2.AI框架: Semantic Kernerl (SK)、Agent Framework3.知识库:向量数据库(Qdrant)+关系型数据库(Post
.net AI开发03 新增意图识别与工具选择工作流(IntentWorkflow),支持多智能体协作; 插件体系升级,支持多项目插件自动注册与工具发现; 对话历史与消息存储解耦,采用 Med
https://blog.csdn.net/cao919/article/details/156065076
.net AI开发04 第八章 引入RAG知识库与文档管理核心能力及事件总线
https://blog.csdn.net/cao919/article/details/156990895
在C# .net中RabbitMQ的核心类型和属性,除了交换机,队列关键的类型 / 属性,影响其行为
https://blog.csdn.net/cao919/article/details/157254797
.net AI MCP 入门 适用于模型上下文协议的 C# SDK 简介(MCP)
https://blog.csdn.net/cao919/article/details/147915384
C# .net ai Agent AI视觉应用 写代码 改作业 识别屏幕 简历处理 标注等
https://blog.csdn.net/cao919/article/details/146504537
.net AI API应用 客户发的信息提取对接上下游系统报价
https://blog.csdn.net/cao919/article/details/156656526
C# net deepseek RAG AI开发 全流程 介绍
https://blog.csdn.net/cao919/article/details/147915384