计算机网络体系结构(1.7)
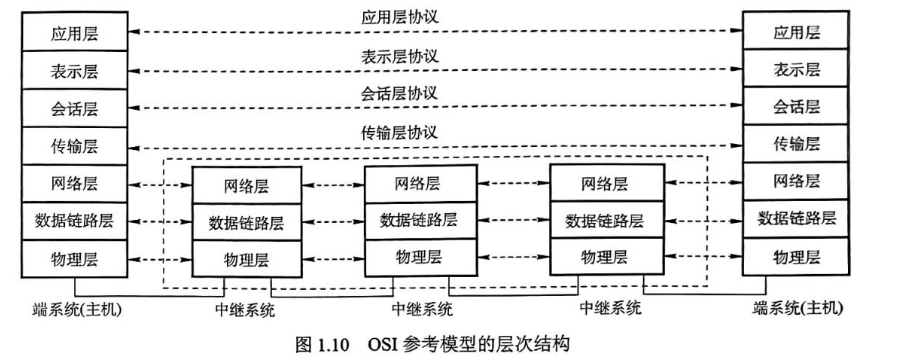
ios七层协议(了解即可),重复冗余,不在实际中用
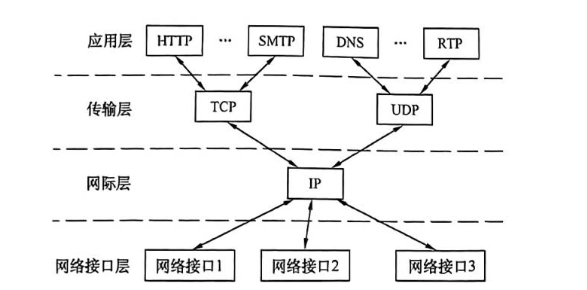
tcp/ip协议的各层层次结构和主要协议
🌠五层协议
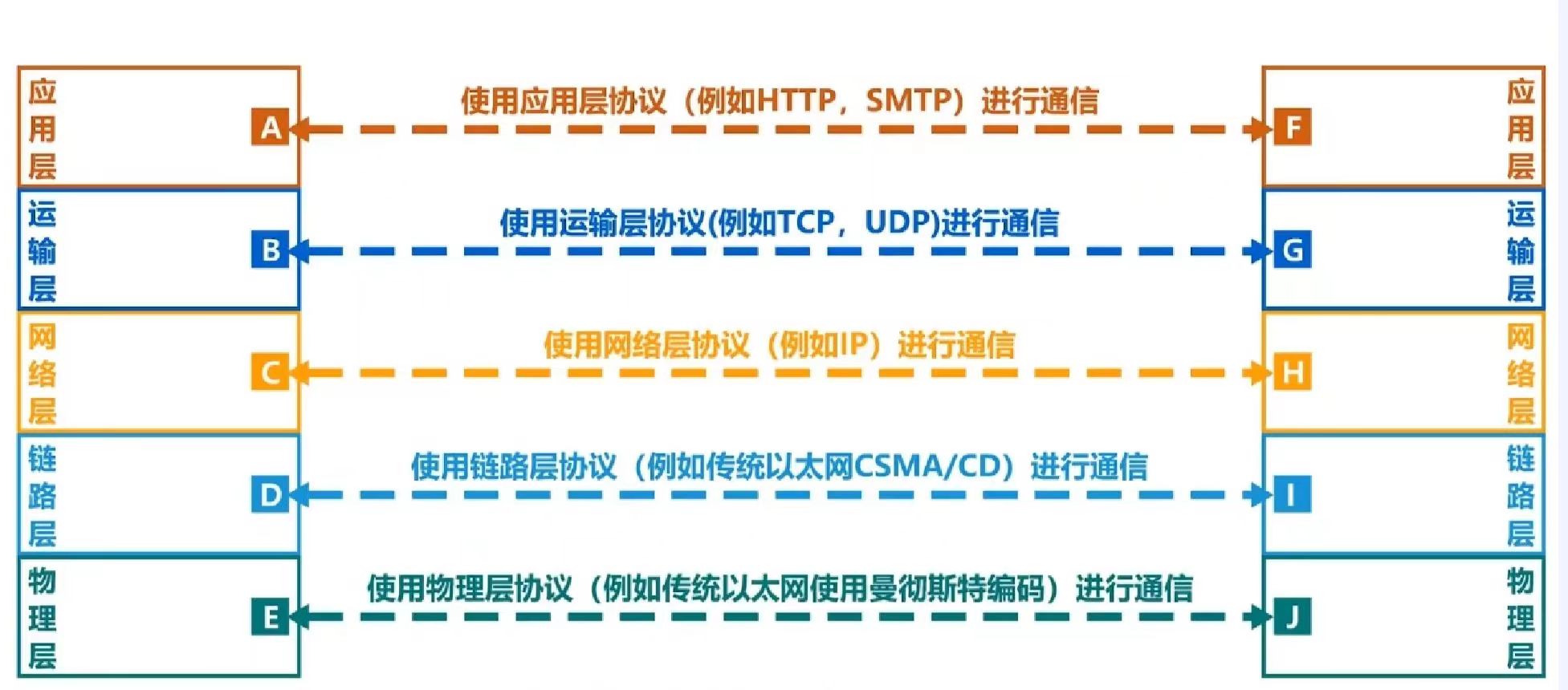
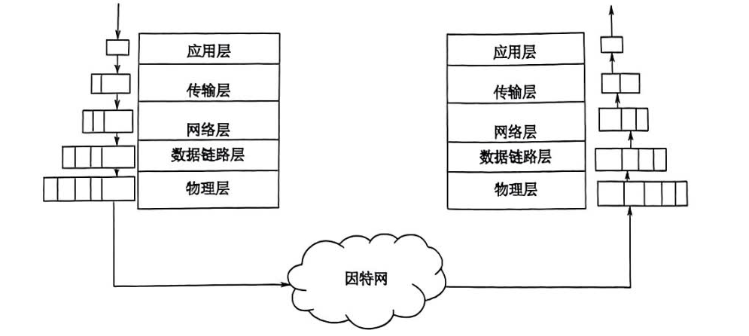
数据从电脑A到服务器B的完整五层传输过程如下:
-
应用层:电脑A上的浏览器生成一个HTTP请求数据,例如"请把主页发给我"。
-
传输层:为HTTP数据添加TCP头部,包含源端口号(如54321)和目标端口号(如80),形成TCP段。
-
网络层:为TCP段添加IP头部,包含源IP地址(如192.168.1.10)和目标IP地址(如93.184.216.34),形成IP包。
-
数据链路层:为IP包添加帧头和帧尾,包含源MAC地址(A的网卡地址)和下一跳MAC地址(如路由器地址),形成数据帧。
-
物理层:将数据帧转换为比特流,再转换成电信号(或光信号、电磁波),通过物理介质发送出去。
-
网络传输:
- 信号经过交换机时,交换机会查看帧头中的MAC地址,将帧转发到对应端口。
- 信号到达路由器时,路由器会:
a) 剥离帧头,查看IP包中的目标IP地址。
b) 根据路由表决定下一跳路径。
c) 为IP包重新封装新的帧头(更新源和目标MAC地址为当前路由器与下一跳设备的地址),然后转发。 - 此过程在多个路由器间重复,直至数据包到达目标网络。
-
物理层:服务器B的网卡接收到物理信号,将其还原为比特流。
-
数据链路层:将比特流组装成帧,检查帧尾确保数据完整,查看帧头中的目标MAC地址,如果匹配自身地址,则剥离帧头和帧尾,取出IP包向上传递给网络层。
-
网络层:接收IP包,检查IP头部的目标IP地址,如果匹配自身地址,则剥离IP头部,取出TCP段向上传递给传输层。
-
传输层:接收TCP段,检查TCP头部的目标端口号(如80),找到对应监听程序,进行数据排序和确认后,剥离TCP头部,取出HTTP数据向上传递给应用层。
-
应用层:Web服务器程序(如Nginx)接收HTTP请求,处理并生成HTTP响应(网页内容),然后这个响应数据开始一个新的、从B到A的封装和传输过程,原路返回给电脑A的浏览器。
总结与核心要点
| 层 | 核心功能 | 地址/标识 | 数据单元 | 关键动作 |
|---|---|---|---|---|
| 应用层 | 产生或处理最终数据 | - | 数据 | 生成HTTP请求/响应 |
| 传输层 | 端到端连接、可靠性 | 端口号 | 段 | 建立连接、流量控制、可靠传输 |
| 网络层 | 逻辑寻址、路由选择 | IP地址 | 包 | 选择最佳路径、跨网络传送 |
| 数据链路层 | 本地节点间传输、差错检测 | MAC地址 | 帧 | 在局域网内"一跳一跳"地传输 |
| 物理层 | 比特流传输 | - | 比特 | 将数据转换为物理信号 |
关系的简述:
上层与下层是服务与被服务的关系。 上层是服务的使用者 ,下层是服务的提供者。例如,传输层(上层)需要依靠网络层(下层)提供的"主机到主机"的寻址和路由服务;应用层(上层)需要依靠传输层(下层)提供的"端到端"的可靠或不可靠传输服务。
下层为上层提供透明的数据传输通道。 下层实现的复杂细节(例如,物理层如何调制信号、数据链路层如何纠错)对上层是完全隐藏的。
对等层之间是虚拟的逻辑通信关系。 虽然物理通信只发生在最底层的物理介质上,但在逻辑上,每一层都认为自己是在与对方的同一层直接对话。例如,电脑A的传输层认为自己发送的TCP段是直接交给电脑B的传输层,实际上这个段是经过了下层逐层封装、传输、再解封装才送达的。这种逻辑通信的规则就是协议。
各层的核心作用:
- 应用层:为应用程序提供网络服务接口,处理用户产生的实际数据(如网页、邮件)。
- 传输层:提供端到端的可靠或不可靠的数据传输,管理数据分段、流量控制和错误恢复。
- 网络层:负责在不同网络之间进行逻辑寻址和路由选择,将数据包从源主机送达目标主机。
- 数据链路层:在直接相连的节点之间,提供可靠的帧传输和差错检测,管理物理寻址(MAC地址)。
- 物理层 :在物理介质上透明地传输原始比特流,定义电气、机械和时序接口标准。
理解:先比特,再在局域网(链路)上传播,再在网络传播,再找端,最后显示
计算机网络的性能
时延
时延 = 数据从网络一端到另一端的总时间,包括:
-
发送时延 (传输时延)
将全部分组数据发出所需时间 = 分组长度 / 发送速率
是主机或路由器把分组"推出去"的时间 -
传播时延
信号在介质中传播的时间 = 信道长度 / 传播速率
是比特在链路上"跑过去"的时间 -
处理时延
路由器检查分组、查路由等处理时间
-
排队时延
分组在路由器中排队等待的时间
总时延 = 发送时延 + 传播时延 + 处理时延 + 排队时延
通常考试中忽略处理和排队时延。
关键区分:发送时延 与链路带宽有关,传播时延与距离有关。
RTT(往返时间)
RTT(往返时间) 在计算机网络中是重要的性能指标,代表双向交互一次所需时间。
示例:
A 向 B 发送 100 MB 数据(发送速率 100 Mbit/s)。
- 发送时间 = 数据长度 / 发送速率 ≈ 8.39 s
- 若 B 收到后立即回复确认(忽略确认发送时间),A 需等待 RTT 时间才能继续发送。
- 若 RTT = 2 s,则:
有效数据率 = 数据长度 /(发送时间 + RTT)≈ 80.7 Mbit/s
可见,由于 RTT 的存在,有效数据率比原始发送速率(100 Mbit/s)降低不少。
计算过程

数据链路和帧(数据链路层)
1)点对点信道
采用一对一的通信方式,PPP协议是目前应用最广泛的点对点协议。
2)广播信道
该信道可连接多个主机,采用一对多的广播通信方式:
- 有线局域网(共享广播信道)普遍使用CSMA/CD协议;
差错检测

CSMA/CD协议(征用流程)(数据链路层)
前情提要
广播信号
一对一通信
碰撞和冲突
CSMA/CD 的特点
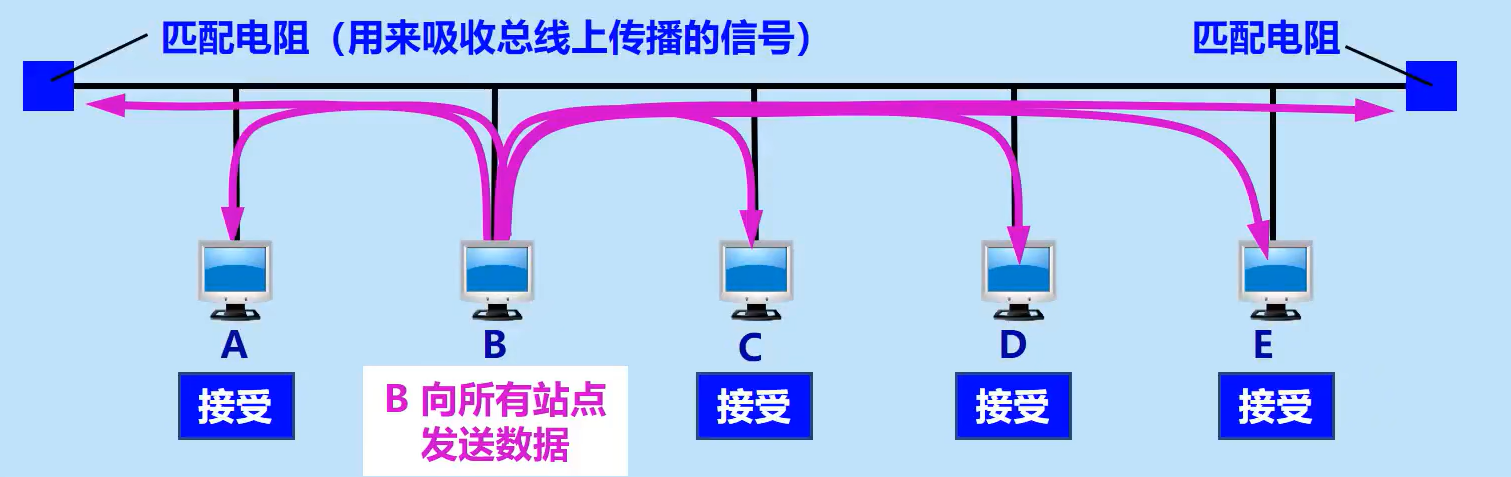
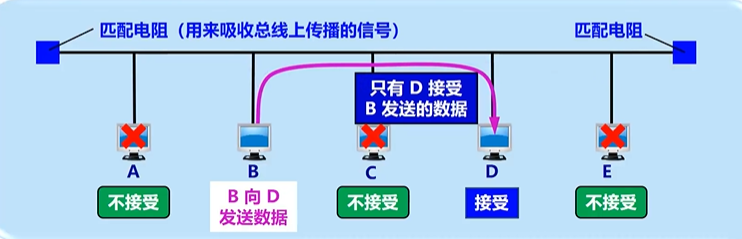
- CSMA/CD (Carrier Sense Multiple Access with Collision Detection):载波监听多点接入 / 碰撞检测。
- 多点接入:说明这是总线型网络。许多计算机以多点接入的方式连接在一根总线上。
- 载波监听:即"边发送边监听"。不管在想要发送数据之前,还是在发送数据之中,每个站都必须不停地检测信道。
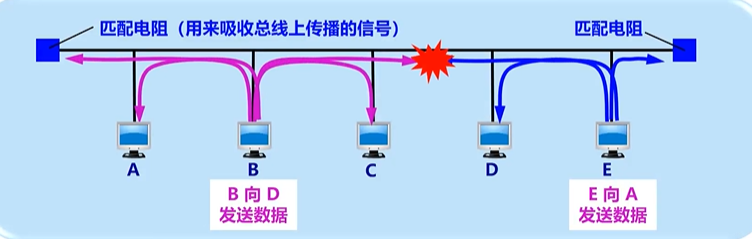
- 碰撞检测:适配器边发送数据,边检测信道上的信号电压的变化情况。电压摆动值超过一定的门限值时,就认为总线上至少有两个站同时在发送数据,表明产生了碰撞(或冲突)。
简短比喻
可以把 CSMA/CD 想象成一间没有主持人的会议室:
- 多点接入:大家都连在同一个会议室(总线)里。
- 载波监听 :想说话前先听听有没有人在说(先听后说)。
- 碰撞检测 :如果说话时听到别人也在说(边说边听,发现碰撞),就立刻停下,等一会儿再尝试。
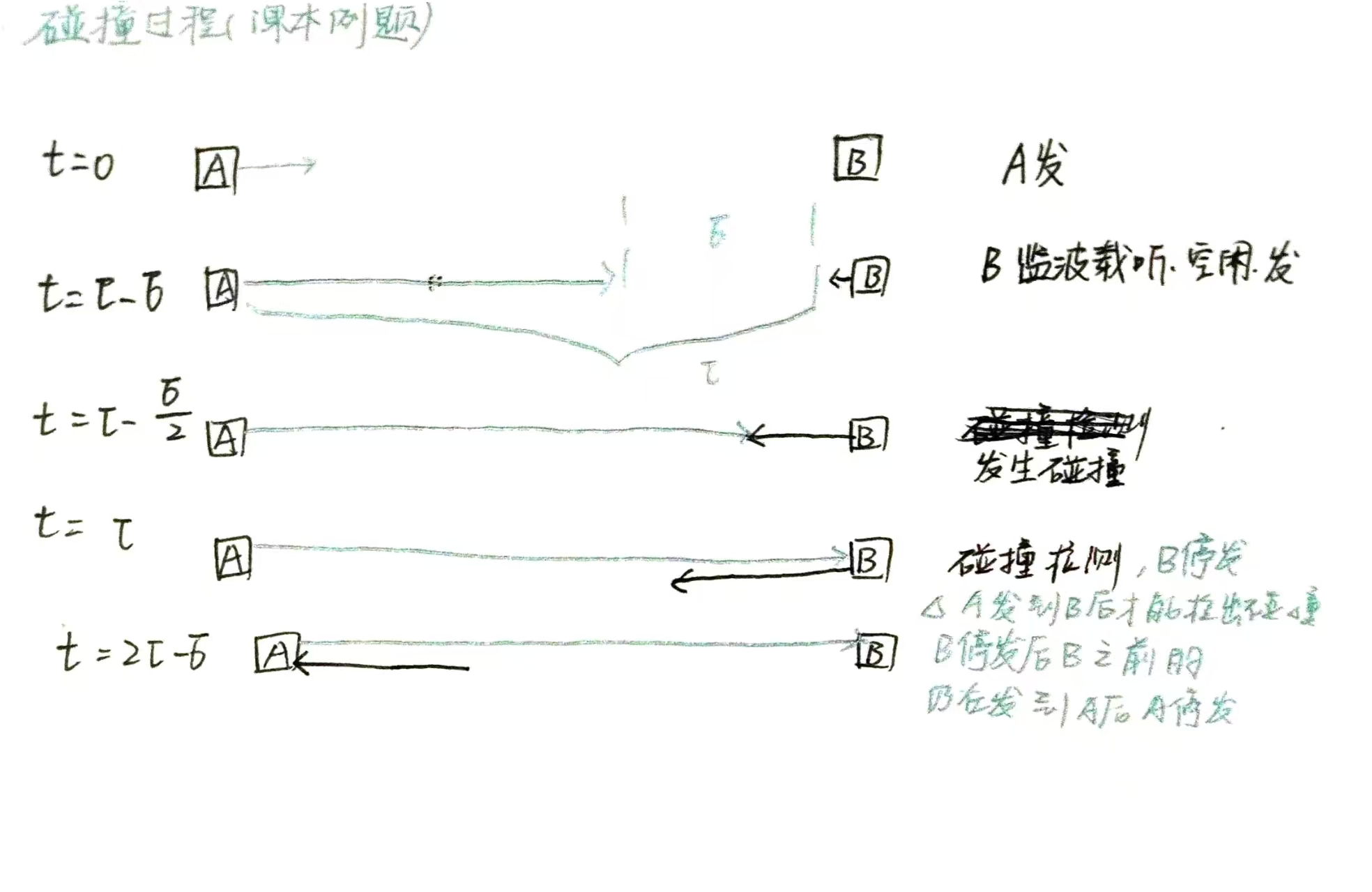
CSMA/CD 中的"争用期"与"最短帧长"
-
争用期(冲突窗口) :在以太网中,从发送开始到最远端的信号返回,需要 端到端往返传播时延的 2 倍时间((2\tau))。在这段时间内,发送站可能检测到冲突。因此,这段时间被称为"争用期"。
-
最短帧长的必要性 :如果帧太短,可能在发送站发完整个帧后,冲突信号才传回来,导致发送站无法检测到冲突,也不会重传,造成数据丢失。为了避免这种情况,以太网规定了 最短帧长。
-
最短帧长计算公式 :

-
举例(10Mb/s 以太网):
-
争用期长度:51.2 μs
-
争用期内可发送的比特数
-
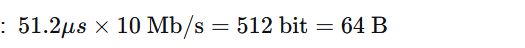
-
因此,最短帧长为 64 字节。如果发送的数据不足 64 字节,需要在 MAC 帧中添加"填充字段"补足。
-
二进制指数退避算法

总结
CSMA/CD算法流程:
- 准备发送:封装分组为帧。
- 检测信道:空闲则发,忙则持续监听。
- 发送与监听 :
- 若争用期内无冲突,发送成功。
- 若检测到冲突,立即停止,执行二进制指数退避,等待随机时间后返回步骤2。
- 若重传16次仍失败,则停止并上报错误。
两种服务(网络层🌠)
了解(助于理解)
1.网络层设计得尽量简单,主要是为了:
1. 保证通用性 :简单才能适配各种底层网络技术(以太网、Wi-Fi等)。
2. 提高效率 :路由器只需快速查表转发,不加复杂判断。
3. 端到端原则 :复杂功能(可靠传输、流量控制)留给终端(TCP)处理。
4. 增强健壮性:核心简单稳定,局部故障不影响全网。
本质是"智能在两端,简单在中间",这样网络才能大规模、高速扩展。好比邮局只负责按地址转发,不保证内容完整(那是写信人和收信人的事)。
数据报服务和虚电路服务(书上标知道)
数据报服务原理
(就是随便发,发到b为止)
- 无需提前联系:主机A直接发送分组,不需要先和主机B建立连接。
- 独立路由:每个分组自带完整目的地址,网络中的路由器(交换结点)根据当前状况为每个分组独立选择最佳路径。
- 存储转发:路由器收到分组后短暂存储,查路由表后立即转发。
- 资源共享:分组只在传输时占用当前链路资源,其他主机可同时通信。
- 简单廉价:网络不保证可靠性、顺序或时延,路由器设计简单,成本低。
工作流程:
- 主机A将分组发给直连的路由器A。
- 路由器A查表后,可能将不同分组转发给路由器C或D(路径可能不同)。
- 沿途路由器重复此过程,直到分组到达主机B。
特点:灵活、抗故障、适合突发数据,但可能乱序、丢失或重复。这是互联网IP协议的基础。
虚电路服务
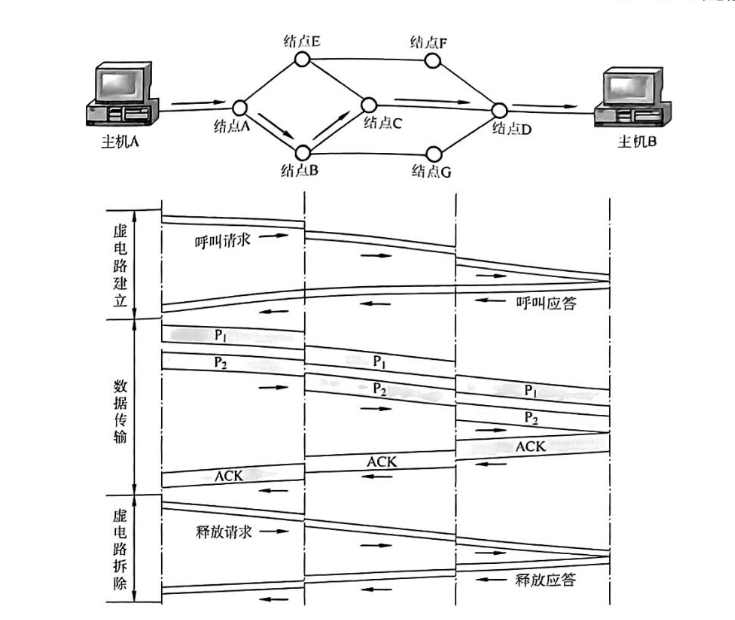
虚电路服务原理
工作流程:
- 建立连接:主机A发送"呼叫请求"分组到主机B,沿途结点记录路径信息,分配虚电路号,形成虚电路表。
- 传输数据:建立后,双方沿虚电路传送分组,分组头只需包含虚电路号。
- 释放连接:通信结束,发送"释放请求"分组拆除虚电路。
特点:需提前建立连接,使用短标识,路径固定,有序可靠,但故障适应性差。用于需要可靠有序传输的场景。
二者处理端到端的差错处理和流量控制
数据报由用户主机负责,虚电路服务可以由网络负责,也可以由用户主机负责(提供可靠服务所以网络可以负责)(ip属于数据报服务)
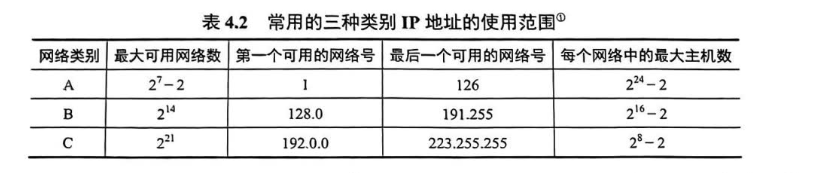
IP地址(网络层🌠)
分类的ip地址
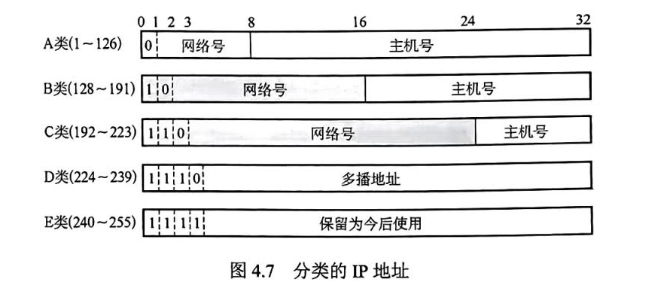
(注:A:8 24 B:16 16 C:24 8 其他和主机号)
注:
特殊用途的IP地址
以下是不可用作普通主机地址的特殊IP地址及其用途:
总结表
| 地址格式 | 示例 | 用途 |
|---|---|---|
| 网络地址(主机号全0) | 192.168.1.0 | 代表整个网络本身 |
| 直接广播地址(主机号全1) | 192.168.1.255 | 向本网络内所有主机广播 |
| 环回地址 | 127.0.0.1 | 本机内部测试与通信 |
| 0.0.0.0 | 0.0.0.0 | 表示本机所有IP地址 |
| 255.255.255.255 | 255.255.255.255 | 向本局域网内所有主机广播 |
注意:这些地址都不能分配给具体主机使用,它们具有特殊的网络功能或测试用途。
(理解:为什么分类)

无分类编址CIDR
和分类的ip地址相比,就是前缀的长可以任取
斜记法



(注意事项:同分类ip地址)
路由聚合
路由聚合(也称构成超网)是指将多个连续的小网络地址块合并成一个更大的地址块,并在路由表中用这一条聚合路由来代表所有被包含的小网络,从而减少路由表条目、降低网络开销并提高路由效率的技术。
效果:像把"1楼到10楼"和"11楼到20楼"合并成"1楼~20楼"。
技术本质:找到这些地址的最长相同前缀,用更短的掩码(如/23代替两个/24)表示一个大地址块。
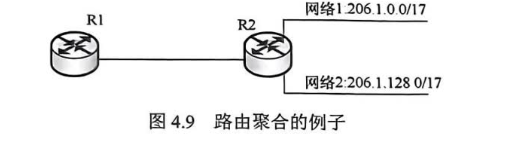
聚合成206.1.0.0/16
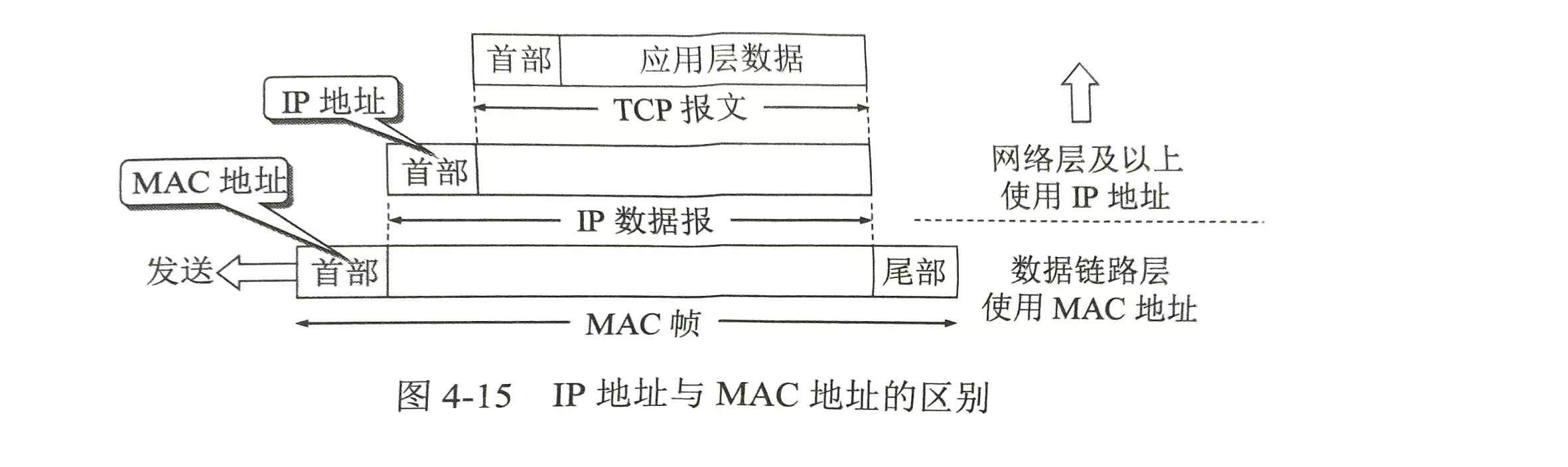
IP地址与MAC地址
IP地址与MAC地址的区别与协作
1. 角色不同
- IP地址:网络层的逻辑地址,用于跨网络寻址。
- MAC地址:数据链路层的物理地址,用于同一局域网内寻址。
2. 协作流程(关键)
- 跨网络时 :路由器只根据目标IP地址 选择下一跳,IP地址不变。
- 到下一跳时 :将IP数据报封装成MAC帧,MAC地址每跳都变(源是发送接口MAC,目标是下一跳接口MAC)。
3. 核心要点
- IP层只能看到IP地址,链路层只能看到MAC地址。
- 路由器隔离广播,MAC地址无法跨网,必须用IP地址跨网络寻址。
- 到达目标网络后,最后一步通过**MAC地址广播(ARP)**找到具体主机。
注:路由器因为连接多个网络,所以它不仅拥有多个IP地址,而且拥有多个硬件地址(MAC地址)。
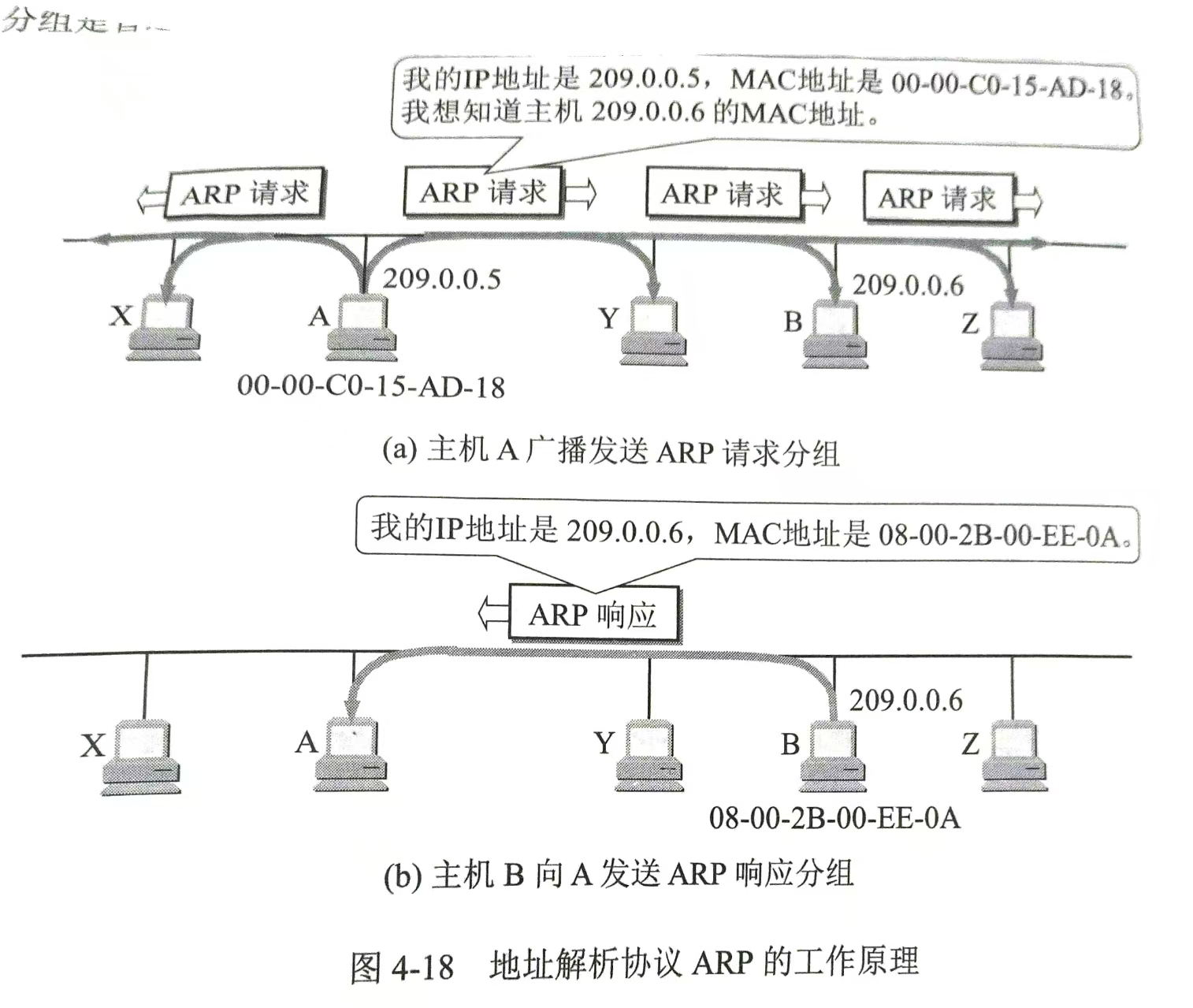
地址解析协议ARP

ARP 完整流程(含缓存查询)
当主机A要给主机B发数据时:
**情况一:缓存中有记录 **
- A直接查看ARP缓存表
- 找到B的IP对应的MAC地址
- 直接封装数据帧发送,无需广播查询
**情况二:缓存中无记录 **
- 广播ARP请求 :目标MAC填
FF-FF-FF-FF-FF-FF,问:"谁是IP_B?" - 主机B单播响应:"我是IP_B,我的MAC是MAC_B"
- A更新ARP缓存 :将
IP_B → MAC_B存入本地缓存表(存几分钟,因为网络会变化) - 发送数据 :用获得的MAC_B封装数据帧发送
ARP 四种情况
-
同网主机发给同网主机
→ 用ARP查对方MAC
-
同网主机发给外网主机
→ 查网关(路由器)MAC,(剩下的路由器来做)
-
路由器发给直连的主机
→ 用ARP查该主机MAC
-
路由器发给不直连的主机
→ 查下一跳路由器MAC
规律:
- ARP只在同局域网内用
- 找的是下一跳的MAC
- 每过一个路由器,MAC地址就换一次
理解:为什么知道了ip还要知道mac
技术原因
-
IP是逻辑的,MAC是物理的
- IP地址是软件分配的,可以变化。
- MAC地址是网卡出厂时烧录的物理标识,一般不变。
-
数据链路层(二层)不识别IP
- 交换机、网卡等硬件设备工作在数据链路层,它们看不懂IP包,只认MAC帧。
- 就像邮局分拣机只认邮政编码,不认收件人姓名。
-
分层解耦
- 网络层(IP)负责跨网络寻址。
- 数据链路层(MAC)负责同一网段内的设备间传递。
- 这样修改上层协议(如IPv4→IPv6)时,下层硬件(如以太网)可以不变。
一句话回答
IP地址用于决定数据包应该送到哪个网络(路由选择),MAC地址用于在到达该网络后,找到具体的物理设备进行最终交付。
IP数据报的格式
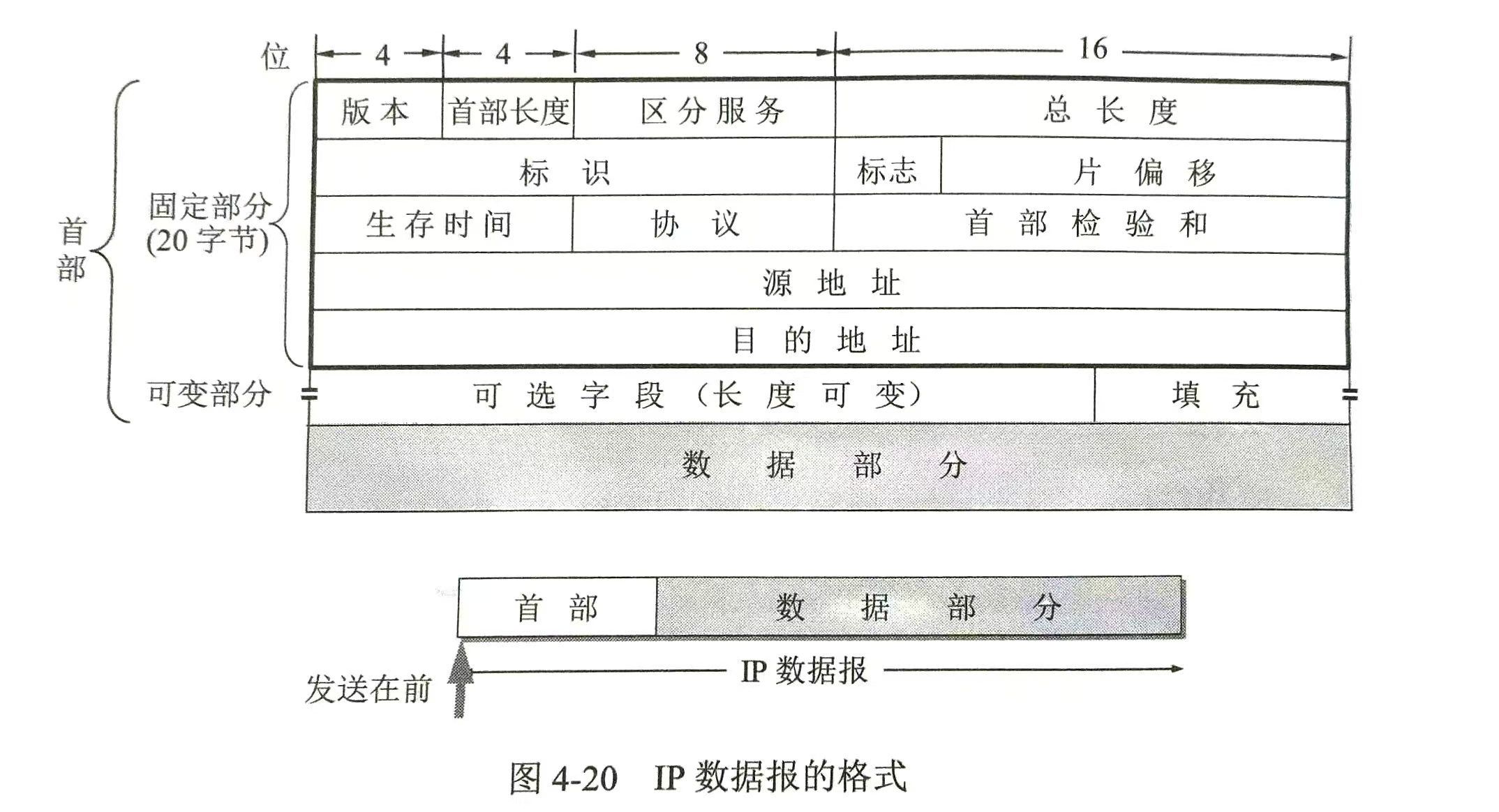
第一行(32位)
- 版本(4位) :IP协议版本,IPv4填
4,IPv6填6。 - 首部长度(4位):IP头部的长度(单位是4字节),最小值为5(即20字节)。
- 区分服务(8位):用于服务质量QoS,标记数据包的优先级或服务类型。(根据服务看哪个优先等)
- 总长度(16位):整个IP数据报的长度(包括头部和数据),单位是字节。
第二行(32位)
- 标识(16位):数据报的唯一标识,用于分片重组。(同一段内容同一个标识)
- 标志(3位):控制分片,比如"是否允许分片"、"是否最后一个分片"。
- 片偏移(13位):表示该分片在原数据报中的位置(单位是8字节)。
第三行(32位)
- 生存时间(8位):TTL,每经过一个路由器减1,减到0就丢弃,防止数据报无限循环。
- 协议(8位):指出数据部分用的协议(如6=TCP,17=UDP,1=ICMP)。
- 首部检验和(16位):只检验IP头部是否出错,不包括数据部分。
第四、五行(各32位)
- 源地址(32位):发送方的IP地址。
- 目的地址(32位):接收方的IP地址。
第六行
- 可选字段(长度可变):很少用,用于特殊控制(如安全选项、时间戳)。
- 填充:将可选字段部分补足到32位的整数倍,确保首部对齐。
最后
- 数据部分:上层传下来的内容(如TCP段、UDP报文等)。
IP分组转发过程(网络层🌠)
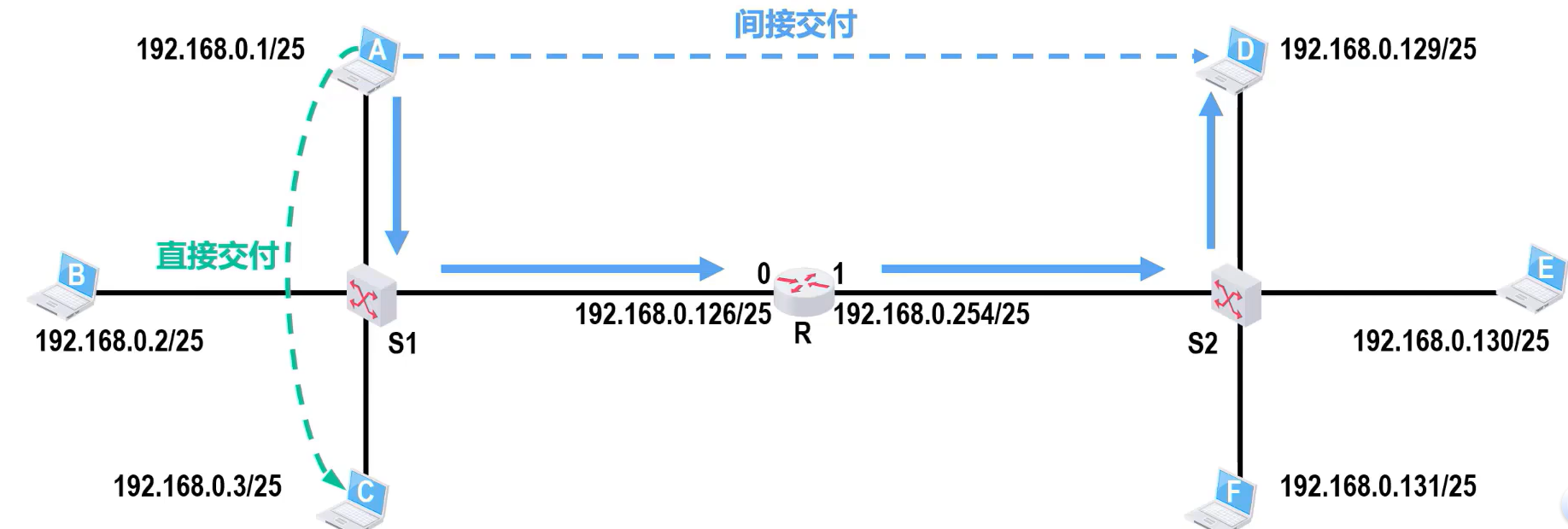
在同一个局域网中直接交付,不同则间接交付
好的,我用技术术语但更简洁直白的方式解释:
子网掩码
本质 :一个32位的二进制数,用于划分IP地址的网络部分和主机部分。
作用:
-
确定网络地址:将IP地址与子网掩码进行按位"与"运算,得到网络地址。
例如: IP: 192.168.5.56 → 二进制:11000000.10101000.00000101.00111000 掩码: 255.255.255.0 → 二进制:11111111.11111111.11111111.00000000 按位与运算结果: → 11000000.10101000.00000101.00000000 网络地址:192.168.5.0 -
判断两个IP是否在同一子网:
- 如果两个IP地址与同一子网掩码进行"与"运算后,得到的网络地址相同,则它们在同一子网内。
- 在同一子网内的设备可以直接通信,不需要路由器。
默认网关
本质 :路由器的IP地址,是本地子网连接到其他网络的出口。
作用:
-
跨子网通信的中转站:
- 当主机要发送数据时,先检查目的IP是否在同一子网。
- 如果在同一子网:直接发送。
- 如果不在同一子网:将数据包发送给默认网关(路由器),由路由器负责转发到其他网络。
-
配置要求:
- 默认网关的IP地址必须与发送主机的IP地址在同一个子网内。
- 例如:主机IP为192.168.5.56/24,默认网关通常为192.168.5.1。
两者关系与工作流程
主机A(IP: 192.168.5.56,掩码: 255.255.255.0,网关: 192.168.5.1)
要发送数据给主机B(IP: 202.120.5.10)
步骤:
1. 主机A用子网掩码计算:
- 自己的网络地址:192.168.5.56 & 255.255.255.0 = 192.168.5.0
- 主机B的网络地址:202.120.5.10 & 255.255.255.0 = 202.120.5.0
2. 比较:192.168.5.0 ≠ 202.120.5.0
3. 结论:主机B不在同一子网
4. 操作:将数据包发送给默认网关192.168.5.1(路由器)
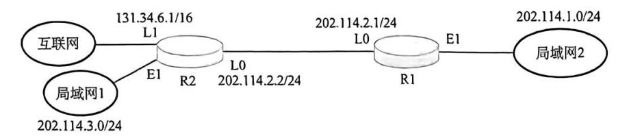
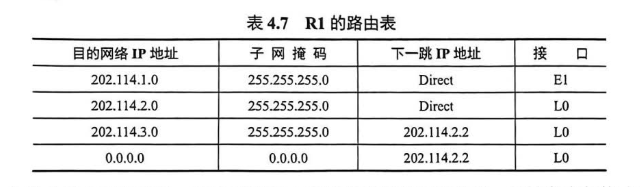
5. 路由器收到后,根据路由表将数据包转发到目标网络理解:路由表
RIP协议(网络层🌠)
RIP(路由信息协议)(可类比狄杰斯特拉)
- 性质 :内部网关协议,基于距离向量算法。
- 度量标准 :用跳数衡量距离,直连网络=1跳,每经过一个路由器+1跳。
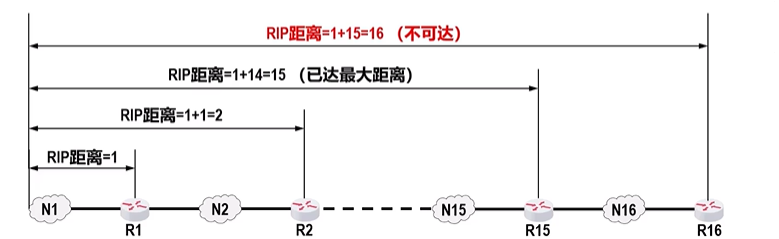
- 跳数限制:最大15跳,16跳视为不可达 → 只适用于小型网络。
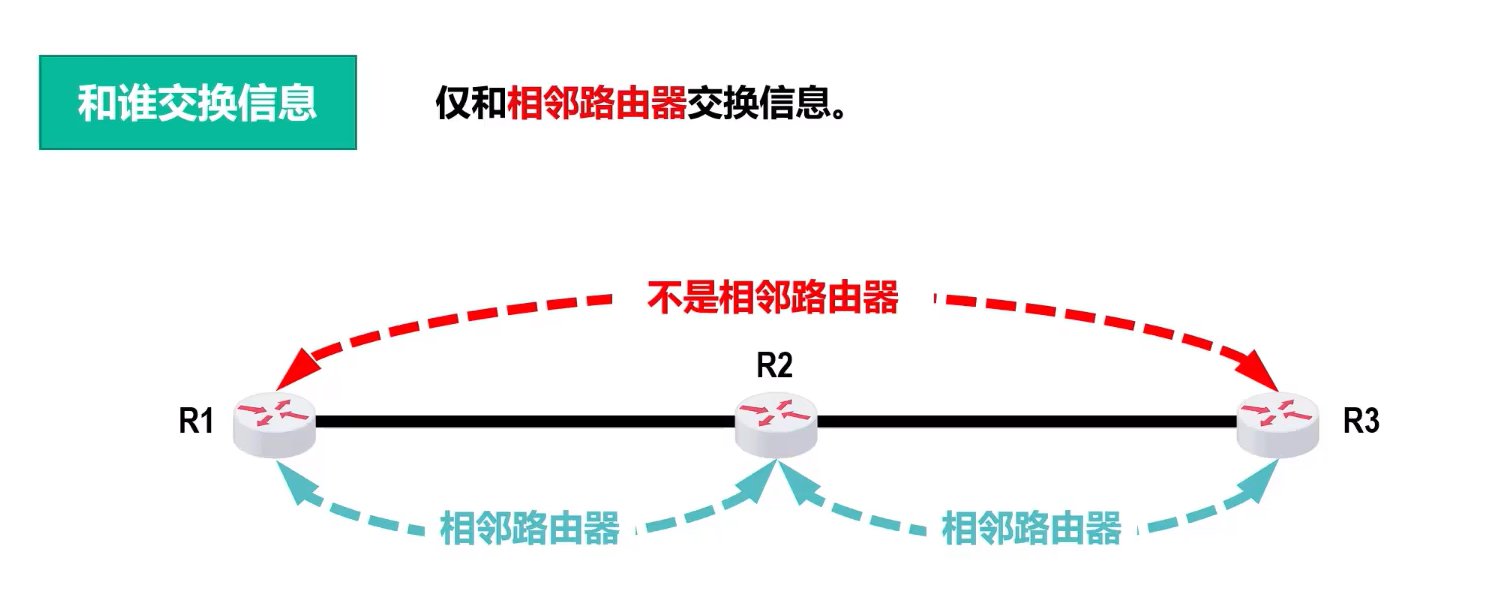
- 工作机制 :每个路由器维护一张距离向量表 ,记录到所有目的网络的跳数,并定期与邻居交换路由信息。
特点


过程:好消息传播得快
RIP更新路由表的过程
假设有3个路由器A、B、C,初始状态如下:
A的路由表:
目标网络 | 下一跳 | 跳数
Net1 | 直连 | 1
Net2 | 直连 | 1
B的路由表:
目标网络 | 下一跳 | 跳数
Net2 | 直连 | 1
Net3 | 直连 | 1
C的路由表:
目标网络 | 下一跳 | 跳数
Net3 | 直连 | 1步骤1:B向A发送RIP更新报文
B告诉A:"我能到达Net2(跳数1)、Net3(跳数1)"
A收到后处理:
-
检查Net2 :A自己已直连Net2(跳数1),比B说的"经B到Net2(1+1=2跳)"更优,不更新。
-
检查Net3 :A路由表中没有Net3,新增一条 :
目标网络 | 下一跳 | 跳数 Net3 | B | 2 (B说的1跳 + 1)
A更新后路由表:
Net1 - 直连 - 1
Net2 - 直连 - 1
Net3 - B - 2步骤2:A向B发送更新
A告诉B:"我能到达Net1(1跳)、Net2(1跳)、Net3(2跳)"
B收到后处理:
- Net1 :B没有,新增
Net1 - A - 2 - Net2:B已直连(1跳),比A说的"经A到Net2(2跳)"更优,不更新。
- Net3:B已直连(1跳),比A说的"经A到Net3(3跳)"更优,不更新。
B更新后路由表:
Net1 - A - 2
Net2 - 直连 - 1
Net3 - 直连 - 1步骤3:C加入,B向C更新
B告诉C:"我能到达Net1(2跳)、Net2(1跳)、Net3(1跳)"
C收到后处理:
- Net1 :C没有,新增
Net1 - B - 3 - Net2 :C没有,新增
Net2 - B - 2 - Net3:C已直连(1跳),不更新
C更新后路由表:
Net1 - B - 3
Net2 - B - 2
Net3 - 直连 - 1完整收敛后三者的路由表:
| 路由器 | 到Net1 | 到Net2 | 到Net3 |
|---|---|---|---|
| A | 直连-1 | 直连-1 | B-2 |
| B | A-2 | 直连-1 | 直连-1 |
| C | B-3 | B-2 | 直连-1 |
更新规则总结
- 新路由:如果目标网络不存在,直接添加(跳数=邻居说的+1)。
- 更优路由:如果存在,但新跳数+1 < 原跳数,则更新。
- 相同下一跳:即使跳数更大也要更新(说明原路径可能变差)。
- 30秒定时更新,180秒未收到更新则标记为不可达(16跳)。
缺点:坏消息传播得慢
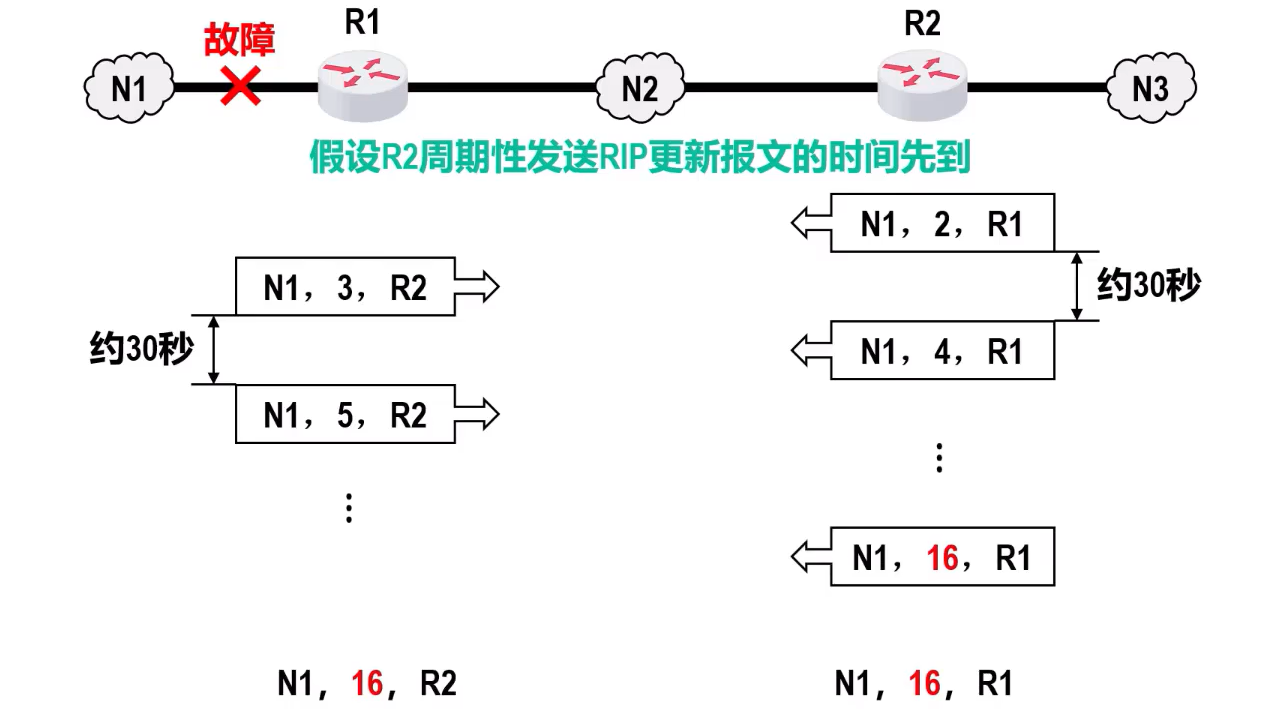
会导致几分钟检测出故障不可达
五、 运输层
1. 网络层和运输层的区别
网络层为主机之间的通信 提供服务 运输层为应用进程之间的通信提供服务
复用:应用层所有应用进程都可以使用通过传输层再传送到IP层(网络层)
分用:运输层从IP层收到发送给各应用进程的数据后,必须分别交付指明的各应用进程
2. 两个主要协议 --- UDP 和 TCP 作用、特点、首部格式等
1. 作用
用户数据报 协议UDP:提供无连接的、不可靠的传输服务。
传输控制 协议TCP:提供面向连接的、可靠的、基于字节流的传输服务。
2.区别:
| 特性 | UDP | TCP |
|---|---|---|
| 连接 | 无连接 | 面向连接 |
| 可靠性 | 不可靠,无重传 | 可靠,保证交付 |
| 传输方式 | 面向报文 | 面向字节流(流是指字节序列) |
| 首部开销 | 8 字节,开销小 | 20 ~ 60 字节 |
| 流量控制 | 无 | 有(滑动窗口) |
| 拥塞控制 | 无 | 有(慢启动、拥塞避免等) |
| 传输速度 | 快 | 慢 |
| 应用场景 | DNS、视频直播、VoIP、实时游戏 | HTTP、FTP、邮件、文件传输 |
| 运输协议数据单元TPDU | UDP 用户数据报 | TCP报文 |
| 支持一对一、一对多、多对一、多对多的交互通信 | 全双工通信:允许双方在任何时候都能发送数据 |
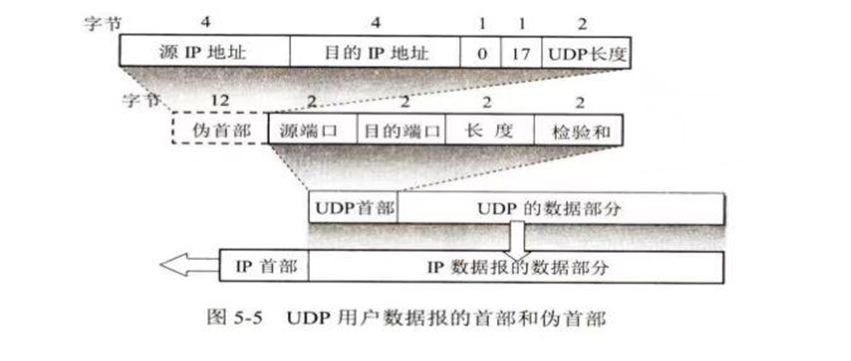
UDP 的首部格式
 ****
****
TCP 的首部格式
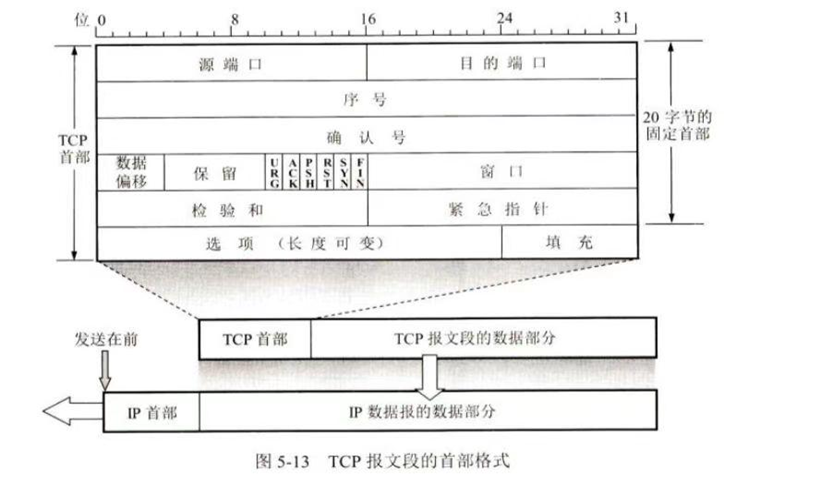
确认号:期望收到对方下一个报文的第一个数据字节的序号
(要会算!总之:若确认号为N 代表到序号N-1为止的所有数据都已正确收到)
ex:B正确收到了A 的报文段,序号字段值为501 ,数据长度 200字节(即序号501 - 700)
则接下来B发送给A的确认号将置为**701 **
2. 常见端口及作用 套接字
- 运输层通过**端口来标识和区分应用层的不同进程**(即复用和分用)。
- 端口是运输层服务访问点 (TSAP)。
- 端口是逻辑概念,不是硬件接口。
端口分类:
服务器端:
- 熟知端口 (0 ~ 1023) :IANA分配给常用服务,如
- FTP(21):文件传输服务,用于客户端与服务器间文件上传、下载。
- TELNET(23):远程终端服务,实现远程登录设备并操作命令行。
- SMTP(25):邮件发送服务,负责将邮件从发件服务器传递到收件服务器。
- DNS(53):域名解析 服务,把域名转换成对应的 IP 地址。
- HTTP(80):超文本传输服务,用于浏览器与 Web 服务器间传输未加密的网页数据。
- HTTPS(443):安全超文本传输服务,加密传输网页数据,保障数据安全。
- 登记端口 (1024 ~ 49151):给没有熟知端口的程序使用。
客户端:
- 短暂端口 (49152 ~ 65535):客户端进程运行时动态选择。
套接字:
- 端口号 + IP地址 = 套接字。
- 套接字唯一标识了网络中的一台主机上的一个进程。
3. TCP可靠传输的工作原理(怎么实现)
1)停止等待协议:
-
原理 :发送方每发送完一个分组,就停止发送,等待对方的确认。收到确认后再发送下一个。
-
三种情况 :(A-发送方 B-接收方)
i. 无差错 :A发送分组(传送的数据单元)M1,B发送ACK1,A收到后接着发送M2,后续同理 。
ii.** 差错出现**:B检测到M1出错,丢弃M1,不发送ACK。A超时重传M1。
iii. 确认丢失 :A发收到(或B发的A,丢失)。A超时后重传M1(B可能会收到重复的M1,然后向A发送确认需要去重)。
-
效率低:每发送一个都要等待,信道利用率低。
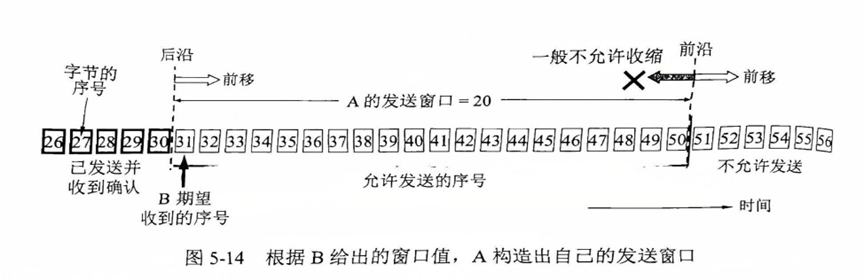
2)连续ARQ协议(滑动窗口协议,重要‼️,依旧A发送方 B接收方):
- 原理 :发送方维持一个发送窗口(滑动窗口以字节 为单位,A的发送窗口不能超过B的接收窗口数值 ),位于窗口内的分组可以连续发送(按照分组序号从小到大),而不需要逐个等待确认。
-
后沿部分是指窗口左边,表示已发送且已收到了确认的字节序号
-
后沿不可能向后移动,前沿一般不允许收缩
-
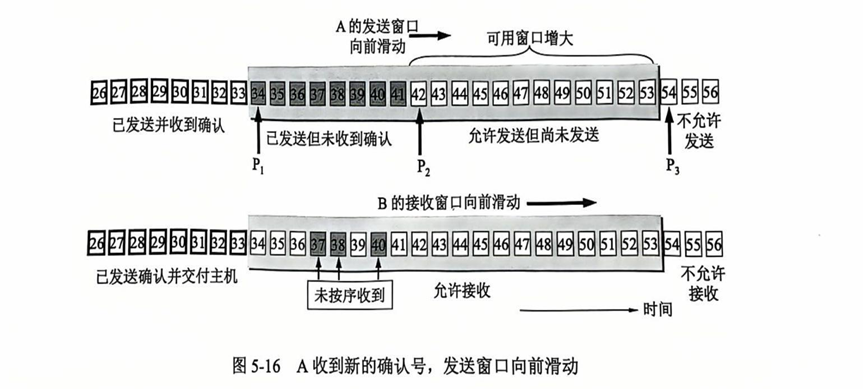
- 积累确认(TCP要求接收方必须有这个功能) :接收方不一定 对收到的每一个分组都发送确认,而是对按序到达 的最后一个 分组发送确认。
-
例如:收到M1, M2, M3,收到M3时发送ACK3,表示M3及M3之前的所有分组都已收到。
-
书p231图5-16 需注意 若B有未按序收到的数据,发送的确认报文段中的确认号将不会改变,会导致A的可用窗口降至0,导致停止发送
-
- 重传机制 :
- Go-back-N (回退N步) :如果发送方收到重复确认(如ACK2)或超时,需要重传从出错分组开始的所有已发送分组。
- 选择重传:只重传出错或丢失的那个特定分组(需更大的缓存和序号范围)。TCP主要使用的是基于选择重传思想的累计确认机制。
4. TCP的流量控制
- 目的:防止发送方发得太快,接收方来不及处理(接收缓冲区溢出)。
- 手段 :滑动窗口。
- 过程 :
- 接收方B每次在TCP报文首部的"窗口"字段中,填入自己接收缓冲区的剩余空间大小 (rwnd - 接收窗口 receiver window,再次强调单位字节,不是报文段)。
- 发送方A根据接收方通告的窗口大小调整自己的发送速率。
- 如果B返回的**接收窗口值为0**,发送方**停止发送**,并启动持续定时器,探询接收方窗口何时恢复(定时发送零窗口探测报文段)。
5. TCP的拥塞控制 原理及四种方法(方法需掌握!)
-
拥塞:是指网络中某一资源的需求超过了该资源所能提供的可用部分
-
目的:防止过多的数据注入到网络中,导致网络路由器或链路过载(全局问题,涉及整个网络环境)。
-
四个 **核心变量**:
cwnd (拥塞窗口) :发送方 根据网络状况自己设定的窗口。
rwnd (接收窗口) :接收方 根据自己的接收能力设定的窗口。
ssthresh (慢开始门限) :用于限制 慢开始cwnd的增长。
发送窗口 = min(cwnd, rwnd)。 -
四种方法 (必须掌握):
- 慢开始(由小到大逐渐增大注入到网络中的数据字节即cwnd数值) :
- 适用场景:连接刚建立或cwnd < ssthresh 时。
- 策略 :cwnd 从 1 开始,每经过一个往返时间 (RTT),cwnd 加倍 (2的指数级增长,因为每收到一个对新报文的确认就加1)。
- 注意:是"慢"开始,但增长速度其实非常快。
- 拥塞避免(也可以说是慢开始的下一个阶段) :
- 适用场景:当 cwnd > ssthresh 时。(注:=时可以用慢开始也可以用拥塞避免)
- 策略 :每经过一个 RTT,cwnd 加1 (线性增长,加法增大)。
- 目的是避免拥塞尽快发生。
- 快重传 :
- 触发条件 :发送方连续收到 3个重复的 ACK (Duplicate ACK)。
- 策略 :立即重传丢失的那个报文段,而不是等待超时定时器到期。
- 快恢复 :
- 配合快重传使用。
- 策略 :
a. 收到3个重复ACK时,将 ssthresh 设置为当前 cwnd 的一半。
b. 将 cwnd 设置为新的 ssthresh 值(即减半)。
c. 直接开始执行拥塞避免算法(线性增长),跳过慢开始过程(网络出现超时 时,不跳过慢开始)。
- 慢开始(由小到大逐渐增大注入到网络中的数据字节即cwnd数值) :
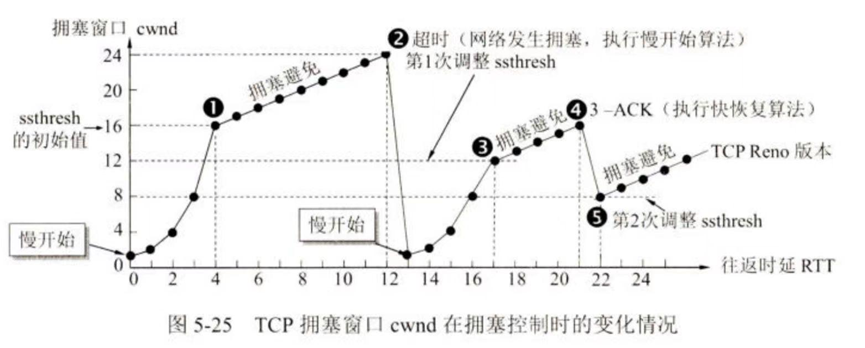
注:圈4的时候出现包丢失
流量控制和拥塞控制类比:流量控制是因为接收设备很小,拥塞控制是因为接收设备太大,导致传输管道内部拥塞了
6. TCP的运输连接管理
三个阶段 连接建立及释放---握手 四次挥手 序列号变化(重点)
(1) 连接建立 (三次握手)
目的:确认双方的接收与发送能力是否正常,协商初始序号。
步骤 (假设A为客户,B为服务器):
i. SYN=1 (报文段不能携带数据,会消耗一个序号), 初始序号seq=x :A发送连接请求报文段,A进入 SYN_SENT 状态。
ii. SYN=1, ACK=1, 也选择一个初始序号seq=y, 确认号ack=x+1 :B收到请求,同意建立连接,发送确认。B进入 SYN_RCVD 状态。
iii. ACK=1, seq=x+1, ack=y+1:A收到B的确认,向B发送确认。A进入 ESTABLISHED 状态。B收到该报文后也进入 ESTABLISHED 状态。
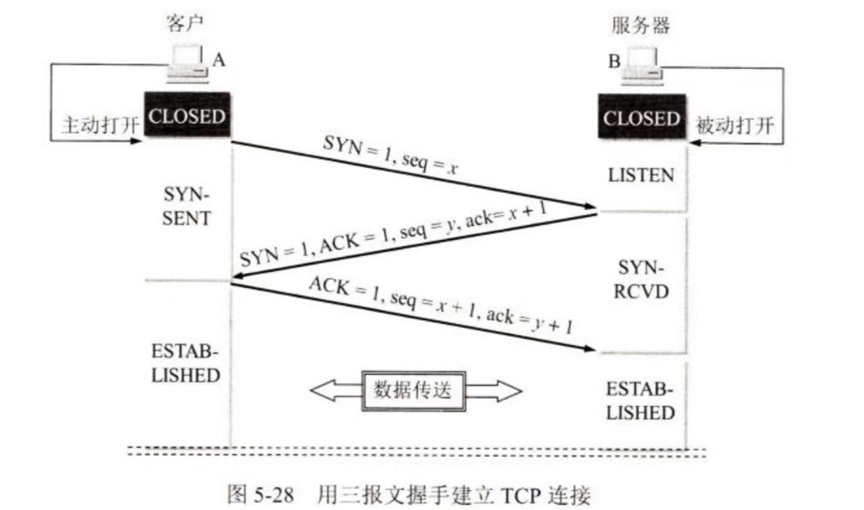
为什么是三次?
(防止失效的连接请求报文段突然又传到了服务器,造成错误)。
(2) 连接释放 (四次挥手 Four-Way Handshake)
步骤 :
i. 终止控制位FIN=1, seq=u(前面已传送过的数据的最后一个字节的序号+1) :A(数据发送完毕)申请断开,进入 FIN_WAIT_1 状态。
ii. ACK=1, seq=v, ack=u+1 :B确认A的断开请求。B进入 CLOSE_WAIT 状态。A收到后进入 FIN_WAIT_2 状态 (此时TCP处于半关闭状态,A->B方向关闭,B->A方向仍可传输)。
iii. FIN=1, ACK=1, seq=w(可能之间还有发送数据,故换一个符号), ack=u+1(重复上次) :B数据发完后,发送断开请求给A。B进入 LAST_ACK 状态。
iv. ACK=1, seq=u+1, ack=w+1 :A确认B的断开请求。A进入 TIME_WAIT 状态。此时TCP连接尚未释放,必须经过时间等待计时器 (2MSL) 后,A才进入 CLOSED 状态。B收到A的确认后立即进入 CLOSED 状态。
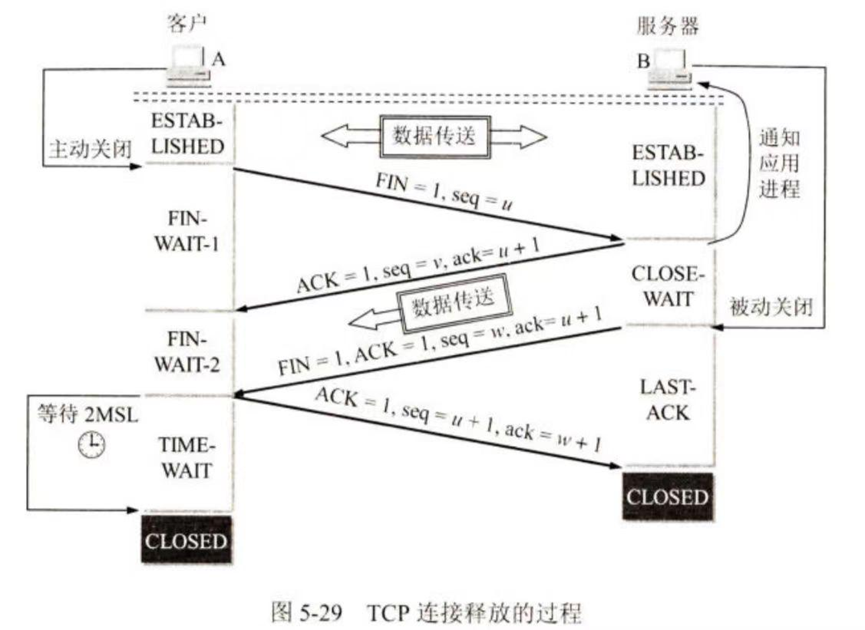
为什么A要等待 2MSL?
i. 保证最后一个ACK能到达B(如果丢了,B会重传FIN)。
ii. 等待网络中所有旧报文段消失,防止新连接中混入旧报文。
(3) 序列号变化总结
- 每次发送数据或握手报文,seq 都会根据数据长度变化(握手通常数据长度为0,但消耗序号)。//虽然 SYN(同步)和 FIN(终止)报文段并没有携带真正的应用层数据(即数据载荷为 0 字节),但是它们在传输过程中,依然会占用一个序列号。
- 确认号 ack 总是等于期望收到的下一个序号,即 上次收到的seq + 数据长度 + 1 (SYN或FIN虽然不携带数据,但也消耗1个序号)。
六、应用层
1. 域名系统 DNS 以及 常见域名
1)作用 :将人类容易记忆的主机域名 (如 www.google.com)IP 地址 (如 142.250.1.1),是一种分布式数据库。
2)域名结构:采用**层次树状结构**。(根无域名 ,第二层为顶级域名 第三层为二级域名...下同理)
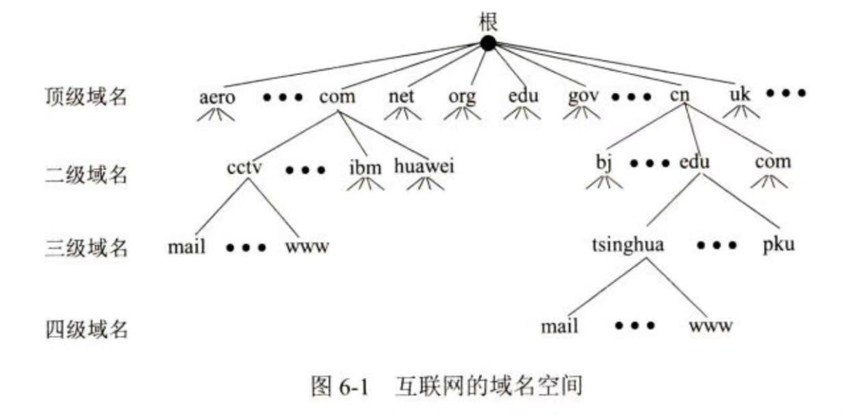
- 语法:标号序列(由点隔开)。例如:三级域名.二级域名.顶级域名。
- 特点:不区分大小写 。
3)常见域名类别 (顶级域名 TLD):
- 国家顶级域名 :如 .cn (中国), .us (美国), .uk (英国), .jp (日本)。
- 通用顶级域名 :
- .com (公司/企业)
- .net (网络服务机构)
- .org (非营利组织)
- .edu (教育机构,常用于美国大学)
- .gov (政府部门,常用于美国政府)
- .mil (军事部门)
- .int (国际组织)
- 基础结构域名:.arpa (用于反向域名解析,即 IP 查域名)。
域名服务器分类:
- 根域名服务器:最高层,知道所有顶级域名服务器的 IP 地址。
- 顶级域名服务器:管理在该顶级域名下的所有二级域名。
- 权限域名服务器:负责一个区的域名解析。
- 本地域名服务器:通常由 ISP 提供,是主机查询 DNS 的入口。
- 域名树的树叶就是单台计算机的名字,不能够再往下划分子域
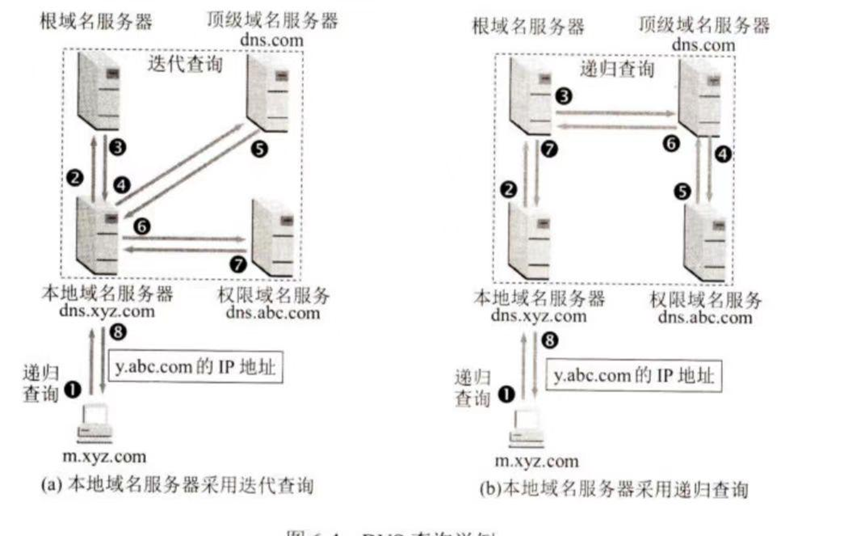
域名解析过程:
- 递归查询:主机问本地 DNS,本地 DNS 如果不知道,就去问别的,直到拿到结果给主机(工作量在服务器端)。
- 迭代查询 :本地 DNS 问根,根说"你去问顶级",本地 DNS 再去问顶级,顶级说"你去问权限"(工作量在本地 DNS 端,通常 DNS 解析采用这种模式)。
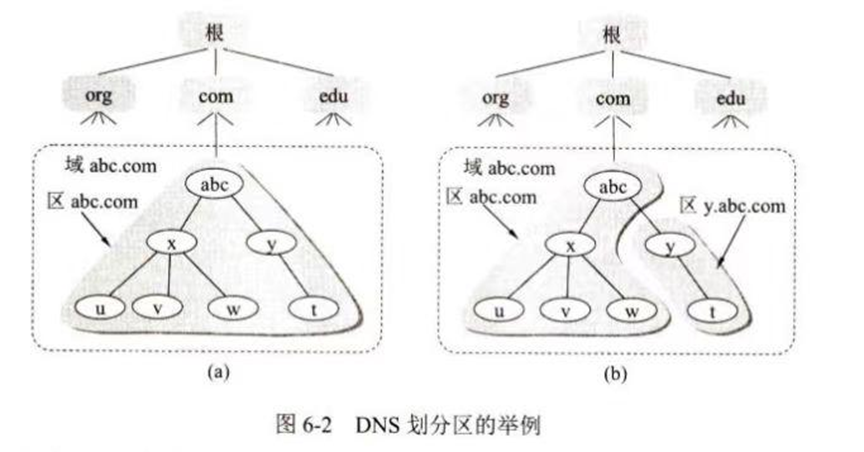
区是域的子集
2. 统一资源定位符 URL
定义 :用来表示互联网上资源的地址和访问方式。
格式 :
<协议>://<主机名>:<端口>/<路径>
- 协议:必须部分。如** http, https, ftp**。
- 主机名:存放资源的主机域名或 IP 地址。
- 端口 :可选。省略时使用协议对应的默认端口(HTTP 默认 80,HTTPS 默认 443)。
- 路径 :资源在主机上的具体路径。
例子 :
http://www.example.com:80/index.html - 协议:http
- 主机名:www.example.com
- 端口:80 (可省略)
- 路径:index.html
3. 超文本传送协议http (重点)
定义:应用层协议,使用 TCP 作为运输层协议,用于在 Web 浏览器和 Web 服务器之间交换数据。
(1) HTTP 的主要特点
- 无状态 :
- 服务器不记得之前访问过它的客户端是谁。
- 优点:简单,服务器不用为每个客户保存连接信息,响应快。
- 缺点:不支持连续事务(如购物车)。
- 解决方案 :使用 Cookie 和 Session。
- 无连接 :(注:HTTP/1.1 之后支持持久连接)
- 早期版本:每个请求/响应都要建立一个新的 TCP 连接,完后断开。
- 请求/响应模式:客户端发起请求,服务器被动响应。
- 灵活:可以传输任意类型的数据(由 Content-Type 标记)。
HTTP 报文格式
A. 请求报文 (客户端 -> 服务器)
<方法> <版本>
<首部字段>
<空行>
<实体主体> (可选)

- 常见方法 :
- GET:请求获取 URL 指定的资源(参数在 URL 中)。
- POST:向服务器提交数据(如表单),数据放在实体主体中(比 GET 安全,长度无限制)。
- HEAD:类似于 GET,但服务器只返回首部,不返回实体主体(用于测试 URL 有效性)。
- PUT:上传文件。
- DELETE:删除文件。
B. 响应报文 (服务器 -> 客户端)
<版本> <状态码> <短语>
<首部字段>
<空行>
<实体主体>

常见状态码:
- 1xx:信息性(如 100 Continue)。
- 2xx :成功。
- 200** OK**:请求成功。
- 3xx :重定向。
- 301 Moved Permanently:永久移位(资源已被分配新 URL)。
- 302 Found:临时移位。
- 4xx :客户端错误。
- 400 Bad Request:请求报文有语法错误。
- 403 Forbidden:服务器拒绝提供服务(无权限)。
- 404** Not Found**:资源不存在。
- 5xx :服务器错误。
- 500 Internal Server Error:服务器内部故障。
- 503 Service Unavailable:服务器目前无法处理请求(过载或维护)。
(3) 持久连接 与 非持久连接
- 非持久连接 (HTTP/1.0 默认):每个资源请求都需要建立一次 TCP 连接(RTT 开销大)。
- 持久连接 (HTTP/1.1 默认) :
- TCP 连接建立后,可以在此连接上传输多个对象(网页、图片等)。
- 分为非流水线 (发完一个收一个)和流水线(连续发送,无需等待前一个响应)。
(4) Cookie 机制 (解决无状态问题)
- 用户第一次访问网站,服务器生成一个唯一 ID,发给浏览器。
- 浏览器将该 ID 以文本文件形式保存在本地(这就是 Cookie)。
- 之后用户再访问该网站,浏览器会自动在请求报文中带上这个 Cookie。
- 服务器读取 Cookie,识别出是"老用户",从而恢复状态(如"你好,张三")。
(5) HTTP 与 HTTPS 的区别
- 协议:HTTP 是明文传输;HTTPS (HTTP Secure) 是 HTTP + SSL/TLS,加密传输。
- 端口:HTTP 默认 80;HTTPS 默认 443。
- 安全性:HTTP 不安全,容易被窃听或篡改;HTTPS 安全,防窃听、防篡改、防冒充。
5. 代理服务器(万维网高速缓存)
把最近的一些请求和响应暂存在本地磁盘中,减少时延