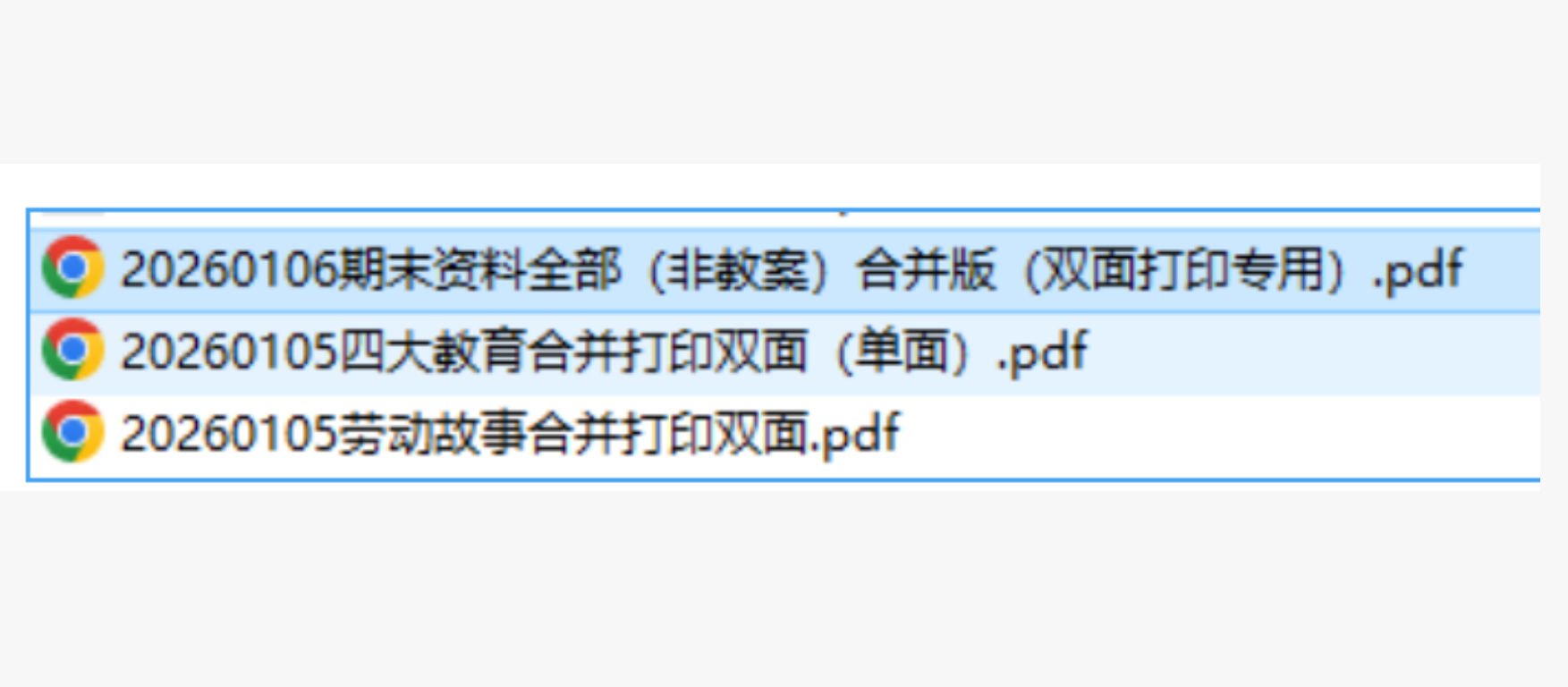
背景需求:
期末了1月12日前打印所有班级资料。
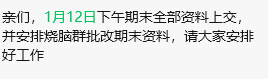
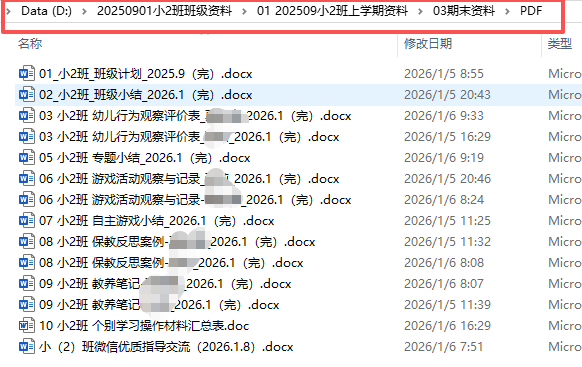
借助前几年的教学资料+Python批量修改基本信息(统一文件名)+AI撰文,快速做好了"档案资料文件"里的WORD

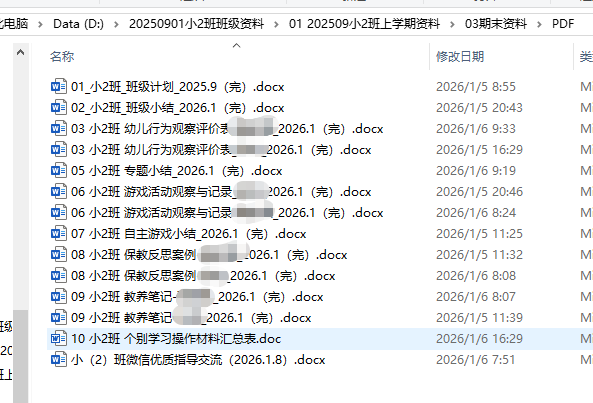
但是有13个文件,打印时要打开13次文件,设置双面打印的参数。而且分园的电脑和打印机需要手动翻页。也要动13次。
我觉得太繁琐了,我想把所有的docx转单个PDF,所有PDF合并成一个PDF。这样只要打开1个文件,设置1次双面打印,翻1次纸张,打印效率直接翻倍。
修改思路
之前在周计划打印里,我做过"周计划教案合并PDF",其中如果一个docx是单数页,就插入一个空白页,补成双数页,这样就能保证所有的周计划横版页面都在单数页上。
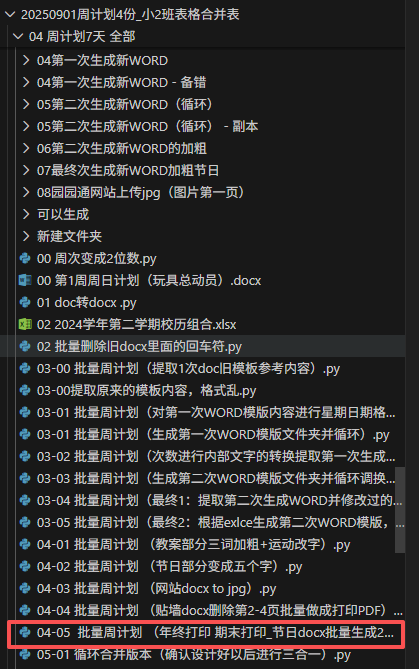
把这个代码复制,替换新的路径
'''
期末资料(非教案资料共13份) 所有页合并打印,docx是单数页,就加一个空白页补成双数页,
修改:只在单数页时添加空白页
Deepseek、豆包、阿夏
20260106
'''
# 19个docx合并成一个PDF,便于打印
import os
from docx2pdf import convert
from PyPDF2 import PdfMerger, PdfReader
from docx import Document
from docx.enum.text import WD_BREAK
from docx.shared import Cm, Pt
from docx.enum.section import WD_SECTION, WD_ORIENT
import time
import shutil
path = r'D:\20250901小2班班级资料\01 202509小2班上学期资料\03期末资料'
old = path + r'\PDF'
new = path
name='20260106期末资料全部(非教案)合并版(双面打印专用)'
# new = path + r'\PDF合并'
os.makedirs(new, exist_ok=True)
new_ls = new + r'\零时文件夹'
if not os.path.exists(new_ls):
# 如果文件夹不存在,则新建文件夹
os.makedirs(new_ls)
# 获取docx文件列表
docx_files = [f for f in os.listdir(old) if f.lower().endswith('.docx') or f.lower().endswith('.doc')]
print(f"在{old}中找到 {len(docx_files)} 个docx文件:")
for i, file_name in enumerate(docx_files, 1):
print(f" {i:2d}. {file_name}")
print('\n' + '='*60)
print('--------1、处理所有docx文件,按需添加空白页---------')
n = 1
processed_files = []
error_files = []
def add_blank_page_to_doc(doc):
"""在文档末尾添加一个空白页"""
try:
# 添加分页符
doc.add_page_break()
# 添加一个几乎不可见的空白段落
blank_para = doc.add_paragraph()
blank_run = blank_para.add_run(" ") # 一个空格
blank_run.font.size = Pt(1) # 极小的字体
blank_para.paragraph_format.space_after = Pt(0)
blank_para.paragraph_format.space_before = Pt(0)
return True
except Exception as e:
print(f" ⚠️ 添加空白页失败: {str(e)}")
return False
def get_pdf_page_count(docx_path, temp_pdf_path):
"""将docx转换为PDF并获取页数"""
try:
# 先转换为PDF
convert(docx_path, temp_pdf_path)
time.sleep(1) # 等待转换完成
# 读取PDF页数
if os.path.exists(temp_pdf_path):
reader = PdfReader(temp_pdf_path)
page_count = len(reader.pages)
return page_count
return None
except Exception as e:
print(f" ⚠️ 获取PDF页数失败: {str(e)}")
return None
finally:
# 清理临时PDF文件
if os.path.exists(temp_pdf_path):
try:
os.remove(temp_pdf_path)
except:
pass
for file_name in docx_files:
print(f"\n{'='*50}")
print(f"正在处理第{n}个文件: {file_name}")
file_path = os.path.join(old, file_name)
temp_pdf_path = os.path.join(new_ls, f"temp_{n}.pdf")
save_path = os.path.join(new_ls, file_name)
try:
# 方法1:直接读取表格判断
doc = Document(file_path)
need_blank_page = False
table_count = len(doc.tables)
if table_count > 0:
try:
# 尝试根据表格列数判断
first_table = doc.tables[0]
first_row = first_table.rows[0]
num_columns = len(first_row.cells)
print(f" 📊 表格信息: {table_count}个表格,第1表格列数: {num_columns}")
if num_columns == 9: # 5天的情况
print(" ✓ 检测到5天周计划,需要2页")
# 这里假设5天需要2页,但实际需要检查页数
elif num_columns == 10: # 6天的情况
print(" ✓ 检测到6天周计划")
elif num_columns == 11: # 7天的情况
print(" ✓ 检测到7天周计划")
else:
print(f" 📝 表格列数{num_columns},采用通用处理")
except Exception as e:
print(f" ⚠️ 无法读取表格信息: {str(e)}")
# 方法2:转换为PDF检查实际页数
print(" 🔍 检查文档实际页数...")
original_page_count = get_pdf_page_count(file_path, temp_pdf_path)
if original_page_count is not None:
print(f" 📄 文档实际页数: {original_page_count}页")
if original_page_count % 2 == 1: # 单数页
print(f" ➕ 文档为单数页({original_page_count}页),需要添加空白页")
need_blank_page = True
else: # 双数页
print(f" ✓ 文档为双数页({original_page_count}页),无需添加空白页")
need_blank_page = False
else:
print(" ⚠️ 无法获取页数,采用备用策略")
# 备用策略:根据内容长度判断
total_paragraphs = len(doc.paragraphs)
print(f" 📝 文档段落数: {total_paragraphs}")
# 简单启发式:如果有很多段落,可能内容较多
if total_paragraphs > 20:
print(" ⚠️ 文档内容较多,可能需要多页,采用保守策略(添加空白页)")
need_blank_page = True
else:
print(" ⚠️ 文档内容较少,采用保守策略(不添加空白页)")
need_blank_page = False
# 如果需要添加空白页
if need_blank_page:
print(" 📝 正在添加空白页...")
success = add_blank_page_to_doc(doc)
if success:
print(" ✓ 空白页添加成功")
else:
print(" ⚠️ 添加空白页失败,但会继续处理")
# 保存处理后的文档
try:
doc.save(save_path)
if os.path.exists(save_path):
file_size = os.path.getsize(save_path) / 1024 # KB
print(f" 💾 已保存到: {save_path} ({file_size:.1f} KB)")
# 验证处理后页数(可选)
if need_blank_page:
print(" 🔍 验证处理后的页数...")
new_page_count = get_pdf_page_count(save_path, temp_pdf_path.replace("temp_", "temp2_"))
if new_page_count:
print(f" 📄 处理后页数: {new_page_count}页")
if new_page_count % 2 == 0:
print(" ✅ 处理后为双数页,适合双面打印")
else:
print(" ⚠️ 处理后仍为单数页,可能需要检查")
processed_files.append(file_name)
else:
print(f" ❌ 保存失败: 文件不存在")
error_files.append(f"{file_name}: 保存后文件不存在")
except Exception as e:
print(f" ❌ 保存文件失败: {str(e)}")
error_files.append(f"{file_name}: 保存失败 - {str(e)}")
n += 1
time.sleep(1) # 给文件系统一点时间
except Exception as e:
print(f" ❌ 处理文件 {file_name} 时出错: {str(e)}")
error_files.append(f"{file_name}: 处理出错 - {str(e)}")
continue
print(f'\n{"="*60}')
print("处理完成统计:")
print(f"总共处理文件数: {len(docx_files)}")
print(f"成功处理文件数: {len(processed_files)}")
print(f"出错文件数: {len(error_files)}")
if processed_files:
print(f"\n✓ 成功处理的文件 ({len(processed_files)}个):")
for i, f in enumerate(processed_files, 1):
print(f" {i:2d}. {f}")
if error_files:
print(f"\n❌ 出错的文件 ({len(error_files)}个):")
for i, f in enumerate(error_files, 1):
print(f" {i:2d}. {f}")
# 将零时文件夹docx文件转换为PDF
print('\n' + '='*60)
print('--------2、开始转换为PDF--------')
pdf_files = []
for ls_name in os.listdir(new_ls):
if ls_name.endswith('.docx') or ls_name.endswith('.doc'):
print(f"\n转换: {ls_name}")
docx_path = os.path.join(new_ls, ls_name)
pdf_file = os.path.splitext(ls_name)[0] + '.pdf'
pdf_path = os.path.join(new_ls, pdf_file)
try:
convert(docx_path, pdf_path)
if os.path.exists(pdf_path):
pdf_files.append(pdf_path)
file_size = os.path.getsize(pdf_path) / 1024 # KB
print(f" ✓ 转换成功: {pdf_file} ({file_size:.1f} KB)")
else:
print(f" ❌ 转换后文件不存在: {pdf_path}")
time.sleep(2)
except Exception as e:
print(f" ❌ 转换失败: {str(e)}")
print(f'\n找到 {len(pdf_files)} 个PDF文件准备合并')
# 合并PDF文件
print('\n' + '='*60)
print('--------3、开始合并PDF--------')
if pdf_files:
merger = PdfMerger()
# 按文件名排序,确保顺序正确
pdf_files.sort()
print(f"将要合并 {len(pdf_files)} 个PDF文件:")
for i, pdf_file in enumerate(pdf_files, 1):
try:
file_size = os.path.getsize(pdf_file) / 1024 # KB
merger.append(pdf_file)
print(f" {i:2d}. 已添加: {os.path.basename(pdf_file)} ({file_size:.1f} KB)")
except Exception as e:
print(f" {i:2d}. ❌ 添加PDF失败: {os.path.basename(pdf_file)} - {str(e)}")
# 保存合并后的PDF文件
output_file = os.path.join(new, f'{name}.pdf')
try:
merger.write(output_file)
merger.close()
if os.path.exists(output_file):
output_size = os.path.getsize(output_file) / 1024 / 1024 # MB
print(f'\n✓ 合并完成!')
print(f' 保存位置: {output_file}')
print(f' 文件大小: {output_size:.2f} MB')
print(f' 包含文件数: {len(pdf_files)} 个')
# 验证合并后的PDF是否为双数页
try:
reader = PdfReader(output_file)
total_pages = len(reader.pages)
print(f' 合并后总页数: {total_pages}页')
if total_pages % 2 == 0:
print(' ✅ 合并后文档为双数页,适合双面打印')
else:
print(' ⚠️ 合并后文档为单数页,最后一页可能需要手动打印')
print(' 建议: 打印时选择"双面打印",打印机通常会处理单数页情况')
except Exception as e:
print(f' ⚠️ 无法验证合并后PDF页数: {str(e)}')
else:
print(f'\n❌ 合并文件未生成: {output_file}')
except Exception as e:
print(f"\n❌ 保存合并文件失败: {str(e)}")
else:
print("❌ 没有找到可转换的PDF文件")
# 删除临时文件夹
print('\n' + '='*60)
print('--------4、清理临时文件--------')
try:
if os.path.exists(new_ls):
# 先查看临时文件夹内容
temp_files = os.listdir(new_ls)
print(f"临时文件夹中包含 {len(temp_files)} 个文件:")
for f in temp_files[:10]: # 只显示前10个
f_path = os.path.join(new_ls, f)
size = os.path.getsize(f_path) / 1024 if os.path.exists(f_path) else 0
print(f" {f} ({size:.1f} KB)")
if len(temp_files) > 10:
print(f" ... 还有 {len(temp_files)-10} 个文件")
shutil.rmtree(new_ls)
print("✓ 临时文件夹已删除")
else:
print("⚠️ 临时文件夹不存在")
except Exception as e:
print(f"❌ 删除临时文件夹失败: {str(e)}")
print('\n' + '='*60)
print('所有处理完成!')
print(f'原始文件夹: {old}')
print(f'输出文件夹: {new}')
print(f'成功处理文件数: {len(processed_files)}/{len(docx_files)}')
# 最后提示
print('\n' + '='*60)
print('📋 打印建议:')
print('1. 打开生成的PDF文件: ' + output_file)
print('2. 在打印设置中选择"双面打印"')
print('3. 如果打印机不支持自动双面,选择"手动双面打印"')
print('4. 纸张方向根据周计划表格选择(通常为横向)')
print('='*60)

共64页(双数)
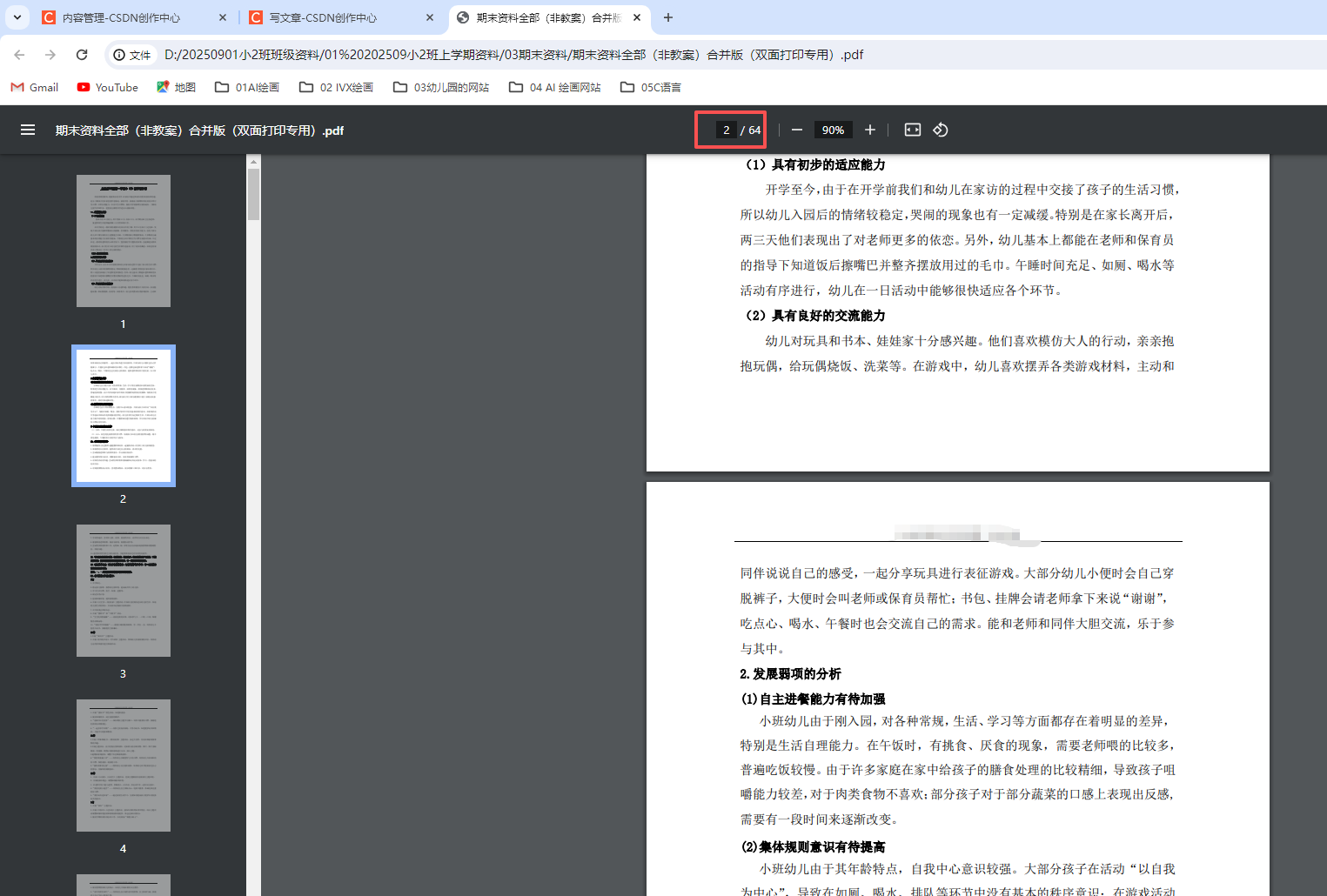
班级计划一共5页,默认补了1页空白,凑足6页,正反打印时,就能正好3张纸一份资料。
不会因为合并PDF,出现下一个内容打印在第6页上,这样就出现无法拆开的情况,也就是所有的标题都要在奇数页上


把PDF打印时,同事正好也在打印。她说"你先打,我等等"
我打开唯一的PDF,设置一次参数。
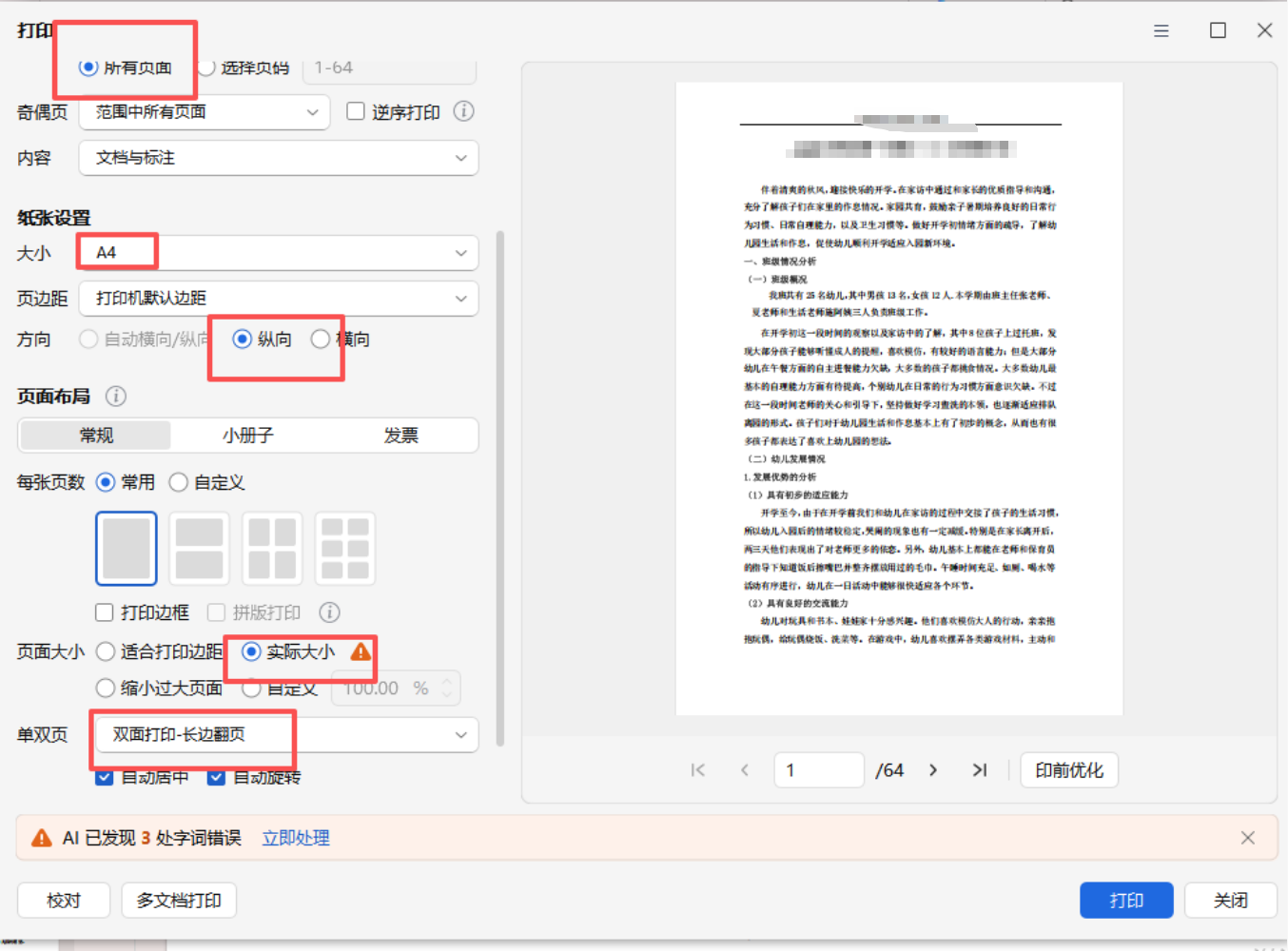
翻页1次
2分钟全部打印好,速度超级快。
同事在旁边发出惊呼:"这么快!"
我回答:"对,我把所有WORD合并在一起了,不过这么做也有风险,如果一页错位了(没有留下双数页空白、表格多余回车出现空白一页等情况),纸就全浪费了"
"是啊,那我还是一份份打印,更保险。"
因为前期我无数次调整了每个docx的内容,去掉回车,换行符等,所以打印出来发现完美,没有错页。
下午一些零散的家教资料也提示上交了

WORD已经准备好,数量多份。我同样方法合并PDF(每份凑成双数页),加快打印速度
一、劳动故事
'''
四份劳动故事 所有页合并打印,docx是单数页,就加一个空白页补成双数页,
修改:只在单数页时添加空白页
Deepseek、豆包、阿夏
20260106
'''
# 19个docx合并成一个PDF,便于打印
import os
from docx2pdf import convert
from PyPDF2 import PdfMerger, PdfReader
from docx import Document
from docx.enum.text import WD_BREAK
from docx.shared import Cm, Pt
from docx.enum.section import WD_SECTION, WD_ORIENT
import time
import shutil
path = r'D:\20250901小2班班级资料\01 202509小2班上学期资料\04家园沟通'
old = os.path.join(path, '20260105小2班劳动故事') # 优化路径拼接方式,避免硬编码反斜杠
name='20260105劳动故事合并打印双面'
# new = path + r'\PDF合并'
new = path
os.makedirs(new, exist_ok=True)
new_ls = os.path.join(new, '零时文件夹') # 优化路径拼接方式
if not os.path.exists(new_ls):
# 如果文件夹不存在,则新建文件夹
os.makedirs(new_ls)
# 获取docx文件列表
docx_files = [f for f in os.listdir(old) if f.lower().endswith('.docx') or f.lower().endswith('.doc')]
print(f"在{old}中找到 {len(docx_files)} 个docx文件:")
for i, file_name in enumerate(docx_files, 1):
print(f" {i:2d}. {file_name}")
print('\n' + '='*60)
print('--------1、处理所有docx文件,按需添加空白页---------')
n = 1
processed_files = []
error_files = []
def add_blank_page_to_doc(doc):
"""在文档末尾添加一个空白页"""
try:
# 添加分页符
doc.add_page_break()
# 添加一个几乎不可见的空白段落
blank_para = doc.add_paragraph()
blank_run = blank_para.add_run(" ") # 一个空格
blank_run.font.size = Pt(1) # 极小的字体
blank_para.paragraph_format.space_after = Pt(0)
blank_para.paragraph_format.space_before = Pt(0)
return True
except Exception as e:
print(f" ⚠️ 添加空白页失败: {str(e)}")
return False
def get_pdf_page_count(docx_path, temp_pdf_path):
"""将docx转换为PDF并获取页数"""
try:
# 先转换为PDF
convert(docx_path, temp_pdf_path)
time.sleep(1) # 等待转换完成
# 读取PDF页数
if os.path.exists(temp_pdf_path):
reader = PdfReader(temp_pdf_path)
page_count = len(reader.pages)
return page_count
return None
except Exception as e:
print(f" ⚠️ 获取PDF页数失败: {str(e)}")
return None
finally:
# 清理临时PDF文件
if os.path.exists(temp_pdf_path):
try:
os.remove(temp_pdf_path)
except:
pass
for file_name in docx_files:
print(f"\n{'='*50}")
print(f"正在处理第{n}个文件: {file_name}")
file_path = os.path.join(old, file_name)
temp_pdf_path = os.path.join(new_ls, f"temp_{n}.pdf")
save_path = os.path.join(new_ls, file_name)
try:
# 方法1:直接读取表格判断
doc = Document(file_path)
need_blank_page = False
table_count = len(doc.tables)
if table_count > 0:
try:
# 尝试根据表格列数判断
first_table = doc.tables[0]
first_row = first_table.rows[0]
num_columns = len(first_row.cells)
print(f" 📊 表格信息: {table_count}个表格,第1表格列数: {num_columns}")
if num_columns == 9: # 5天的情况
print(" ✓ 检测到5天周计划,需要2页")
# 这里假设5天需要2页,但实际需要检查页数
elif num_columns == 10: # 6天的情况
print(" ✓ 检测到6天周计划")
elif num_columns == 11: # 7天的情况
print(" ✓ 检测到7天周计划")
else:
print(f" 📝 表格列数{num_columns},采用通用处理")
except Exception as e:
print(f" ⚠️ 无法读取表格信息: {str(e)}")
# 方法2:转换为PDF检查实际页数
print(" 🔍 检查文档实际页数...")
original_page_count = get_pdf_page_count(file_path, temp_pdf_path)
if original_page_count is not None:
print(f" 📄 文档实际页数: {original_page_count}页")
if original_page_count % 2 == 1: # 单数页
print(f" ➕ 文档为单数页({original_page_count}页),需要添加空白页")
need_blank_page = True
else: # 双数页
print(f" ✓ 文档为双数页({original_page_count}页),无需添加空白页")
need_blank_page = False
else:
print(" ⚠️ 无法获取页数,采用备用策略")
# 备用策略:根据内容长度判断
total_paragraphs = len(doc.paragraphs)
print(f" 📝 文档段落数: {total_paragraphs}")
# 简单启发式:如果有很多段落,可能内容较多
if total_paragraphs > 20:
print(" ⚠️ 文档内容较多,可能需要多页,采用保守策略(添加空白页)")
need_blank_page = True
else:
print(" ⚠️ 文档内容较少,采用保守策略(不添加空白页)")
need_blank_page = False
# 如果需要添加空白页
if need_blank_page:
print(" 📝 正在添加空白页...")
success = add_blank_page_to_doc(doc)
if success:
print(" ✓ 空白页添加成功")
else:
print(" ⚠️ 添加空白页失败,但会继续处理")
# 保存处理后的文档
try:
doc.save(save_path)
if os.path.exists(save_path):
file_size = os.path.getsize(save_path) / 1024 # KB
print(f" 💾 已保存到: {save_path} ({file_size:.1f} KB)")
# 验证处理后页数(可选)
if need_blank_page:
print(" 🔍 验证处理后的页数...")
new_page_count = get_pdf_page_count(save_path, temp_pdf_path.replace("temp_", "temp2_"))
if new_page_count:
print(f" 📄 处理后页数: {new_page_count}页")
if new_page_count % 2 == 0:
print(" ✅ 处理后为双数页,适合双面打印")
else:
print(" ⚠️ 处理后仍为单数页,可能需要检查")
processed_files.append(file_name)
else:
print(f" ❌ 保存失败: 文件不存在")
error_files.append(f"{file_name}: 保存后文件不存在")
except Exception as e:
print(f" ❌ 保存文件失败: {str(e)}")
error_files.append(f"{file_name}: 保存失败 - {str(e)}")
n += 1
time.sleep(1) # 给文件系统一点时间
except Exception as e:
print(f" ❌ 处理文件 {file_name} 时出错: {str(e)}")
error_files.append(f"{file_name}: 处理出错 - {str(e)}")
continue
print(f'\n{"="*60}')
print("处理完成统计:")
print(f"总共处理文件数: {len(docx_files)}")
print(f"成功处理文件数: {len(processed_files)}")
print(f"出错文件数: {len(error_files)}")
if processed_files:
print(f"\n✓ 成功处理的文件 ({len(processed_files)}个):")
for i, f in enumerate(processed_files, 1):
print(f" {i:2d}. {f}")
if error_files:
print(f"\n❌ 出错的文件 ({len(error_files)}个):")
for i, f in enumerate(error_files, 1):
print(f" {i:2d}. {f}")
# 将零时文件夹docx文件转换为PDF
print('\n' + '='*60)
print('--------2、开始转换为PDF--------')
pdf_files = []
for ls_name in os.listdir(new_ls):
if ls_name.endswith('.docx') or ls_name.endswith('.doc'):
print(f"\n转换: {ls_name}")
docx_path = os.path.join(new_ls, ls_name)
pdf_file = os.path.splitext(ls_name)[0] + '.pdf'
pdf_path = os.path.join(new_ls, pdf_file)
try:
convert(docx_path, pdf_path)
if os.path.exists(pdf_path):
pdf_files.append(pdf_path)
file_size = os.path.getsize(pdf_path) / 1024 # KB
print(f" ✓ 转换成功: {pdf_file} ({file_size:.1f} KB)")
else:
print(f" ❌ 转换后文件不存在: {pdf_path}")
time.sleep(2)
except Exception as e:
print(f" ❌ 转换失败: {str(e)}")
print(f'\n找到 {len(pdf_files)} 个PDF文件准备合并')
# 合并PDF文件
print('\n' + '='*60)
print('--------3、开始合并PDF--------')
if pdf_files:
merger = PdfMerger()
# 按文件名排序,确保顺序正确
pdf_files.sort()
print(f"将要合并 {len(pdf_files)} 个PDF文件:")
for i, pdf_file in enumerate(pdf_files, 1):
try:
file_size = os.path.getsize(pdf_file) / 1024 # KB
merger.append(pdf_file)
print(f" {i:2d}. 已添加: {os.path.basename(pdf_file)} ({file_size:.1f} KB)")
except Exception as e:
print(f" {i:2d}. ❌ 添加PDF失败: {os.path.basename(pdf_file)} - {str(e)}")
# 保存合并后的PDF文件
output_file = os.path.join(new, f'{name}.pdf')
try:
merger.write(output_file)
merger.close()
if os.path.exists(output_file):
output_size = os.path.getsize(output_file) / 1024 / 1024 # MB
print(f'\n✓ 合并完成!')
print(f' 保存位置: {output_file}')
print(f' 文件大小: {output_size:.2f} MB')
print(f' 包含文件数: {len(pdf_files)} 个')
# 验证合并后的PDF是否为双数页
try:
reader = PdfReader(output_file)
total_pages = len(reader.pages)
print(f' 合并后总页数: {total_pages}页')
if total_pages % 2 == 0:
print(' ✅ 合并后文档为双数页,适合双面打印')
else:
print(' ⚠️ 合并后文档为单数页,最后一页可能需要手动打印')
print(' 建议: 打印时选择"双面打印",打印机通常会处理单数页情况')
except Exception as e:
print(f' ⚠️ 无法验证合并后PDF页数: {str(e)}')
else:
print(f'\n❌ 合并文件未生成: {output_file}')
except Exception as e:
print(f"\n❌ 保存合并文件失败: {str(e)}")
else:
print("❌ 没有找到可转换的PDF文件")
# 删除临时文件夹
print('\n' + '='*60)
print('--------4、清理临时文件--------')
try:
if os.path.exists(new_ls):
# 先查看临时文件夹内容
temp_files = os.listdir(new_ls)
print(f"临时文件夹中包含 {len(temp_files)} 个文件:")
for f in temp_files[:10]: # 只显示前10个
f_path = os.path.join(new_ls, f)
size = os.path.getsize(f_path) / 1024 if os.path.exists(f_path) else 0
print(f" {f} ({size:.1f} KB)")
if len(temp_files) > 10:
print(f" ... 还有 {len(temp_files)-10} 个文件")
shutil.rmtree(new_ls)
print("✓ 临时文件夹已删除")
else:
print("⚠️ 临时文件夹不存在")
except Exception as e:
print(f"❌ 删除临时文件夹失败: {str(e)}")
print('\n' + '='*60)
print('所有处理完成!')
print(f'原始文件夹: {old}')
print(f'输出文件夹: {new}')
print(f'成功处理文件数: {len(processed_files)}/{len(docx_files)}')
# 最后提示
print('\n' + '='*60)
print('📋 打印建议:')
print('1. 打开生成的PDF文件: ' + output_file)
print('2. 在打印设置中选择"双面打印"')
print('3. 如果打印机不支持自动双面,选择"手动双面打印"')
print('4. 纸张方向根据周计划表格选择(通常为横向)')
print('='*60)


同理做五大教育(小2光盘)有docx和doc
'''
5个月的五大教育(光盘行动) 所有页合并打印,docx是单数页,就加一个空白页补成双数页,
修改:只在单数页时添加空白页
Deepseek、豆包、阿夏
20260106
'''
# 19个docx合并成一个PDF,便于打印
import os
from docx2pdf import convert
from PyPDF2 import PdfMerger, PdfReader
from docx import Document
from docx.enum.text import WD_BREAK
from docx.shared import Cm, Pt
from docx.enum.section import WD_SECTION, WD_ORIENT
import time
import shutil
path = r'D:\20250901小2班班级资料\01 202509小2班上学期资料\04家园沟通'
old = os.path.join(path, '20260106四大教育(小2光盘)') # 源文件目录
new = path
name = '20260105四大教育合并打印双面(单面)'
# new = path + r'\PDF合并'
os.makedirs(new, exist_ok=True)
new_ls = new + r'\零时文件夹'
if not os.path.exists(new_ls):
# 如果文件夹不存在,则新建文件夹
os.makedirs(new_ls)
# 获取docx文件列表
docx_files = [f for f in os.listdir(old) if f.lower().endswith('.docx') or f.lower().endswith('.doc')]
print(f"在{old}中找到 {len(docx_files)} 个docx文件:")
for i, file_name in enumerate(docx_files, 1):
print(f" {i:2d}. {file_name}")
print('\n' + '='*60)
print('--------1、处理所有docx文件,按需添加空白页---------')
n = 1
processed_files = []
error_files = []
def add_blank_page_to_doc(doc):
"""在文档末尾添加一个空白页"""
try:
# 添加分页符
doc.add_page_break()
# 添加一个几乎不可见的空白段落
blank_para = doc.add_paragraph()
blank_run = blank_para.add_run(" ") # 一个空格
blank_run.font.size = Pt(1) # 极小的字体
blank_para.paragraph_format.space_after = Pt(0)
blank_para.paragraph_format.space_before = Pt(0)
return True
except Exception as e:
print(f" ⚠️ 添加空白页失败: {str(e)}")
return False
def get_pdf_page_count(docx_path, temp_pdf_path):
"""将docx转换为PDF并获取页数"""
try:
# 先转换为PDF
convert(docx_path, temp_pdf_path)
time.sleep(1) # 等待转换完成
# 读取PDF页数
if os.path.exists(temp_pdf_path):
reader = PdfReader(temp_pdf_path)
page_count = len(reader.pages)
return page_count
return None
except Exception as e:
print(f" ⚠️ 获取PDF页数失败: {str(e)}")
return None
finally:
# 清理临时PDF文件
if os.path.exists(temp_pdf_path):
try:
os.remove(temp_pdf_path)
except:
pass
for file_name in docx_files:
print(f"\n{'='*50}")
print(f"正在处理第{n}个文件: {file_name}")
file_path = os.path.join(old, file_name)
temp_pdf_path = os.path.join(new_ls, f"temp_{n}.pdf")
save_path = os.path.join(new_ls, file_name)
try:
# 方法1:直接读取表格判断
doc = Document(file_path)
need_blank_page = False
table_count = len(doc.tables)
if table_count > 0:
try:
# 尝试根据表格列数判断
first_table = doc.tables[0]
first_row = first_table.rows[0]
num_columns = len(first_row.cells)
print(f" 📊 表格信息: {table_count}个表格,第1表格列数: {num_columns}")
if num_columns == 9: # 5天的情况
print(" ✓ 检测到5天周计划,需要2页")
# 这里假设5天需要2页,但实际需要检查页数
elif num_columns == 10: # 6天的情况
print(" ✓ 检测到6天周计划")
elif num_columns == 11: # 7天的情况
print(" ✓ 检测到7天周计划")
else:
print(f" 📝 表格列数{num_columns},采用通用处理")
except Exception as e:
print(f" ⚠️ 无法读取表格信息: {str(e)}")
# 方法2:转换为PDF检查实际页数
print(" 🔍 检查文档实际页数...")
original_page_count = get_pdf_page_count(file_path, temp_pdf_path)
if original_page_count is not None:
print(f" 📄 文档实际页数: {original_page_count}页")
if original_page_count % 2 == 1: # 单数页
print(f" ➕ 文档为单数页({original_page_count}页),需要添加空白页")
need_blank_page = True
else: # 双数页
print(f" ✓ 文档为双数页({original_page_count}页),无需添加空白页")
need_blank_page = False
else:
print(" ⚠️ 无法获取页数,采用备用策略")
# 备用策略:根据内容长度判断
total_paragraphs = len(doc.paragraphs)
print(f" 📝 文档段落数: {total_paragraphs}")
# 简单启发式:如果有很多段落,可能内容较多
if total_paragraphs > 20:
print(" ⚠️ 文档内容较多,可能需要多页,采用保守策略(添加空白页)")
need_blank_page = True
else:
print(" ⚠️ 文档内容较少,采用保守策略(不添加空白页)")
need_blank_page = False
# 如果需要添加空白页
if need_blank_page:
print(" 📝 正在添加空白页...")
success = add_blank_page_to_doc(doc)
if success:
print(" ✓ 空白页添加成功")
else:
print(" ⚠️ 添加空白页失败,但会继续处理")
# 保存处理后的文档
try:
doc.save(save_path)
if os.path.exists(save_path):
file_size = os.path.getsize(save_path) / 1024 # KB
print(f" 💾 已保存到: {save_path} ({file_size:.1f} KB)")
# 验证处理后页数(可选)
if need_blank_page:
print(" 🔍 验证处理后的页数...")
new_page_count = get_pdf_page_count(save_path, temp_pdf_path.replace("temp_", "temp2_"))
if new_page_count:
print(f" 📄 处理后页数: {new_page_count}页")
if new_page_count % 2 == 0:
print(" ✅ 处理后为双数页,适合双面打印")
else:
print(" ⚠️ 处理后仍为单数页,可能需要检查")
processed_files.append(file_name)
else:
print(f" ❌ 保存失败: 文件不存在")
error_files.append(f"{file_name}: 保存后文件不存在")
except Exception as e:
print(f" ❌ 保存文件失败: {str(e)}")
error_files.append(f"{file_name}: 保存失败 - {str(e)}")
n += 1
time.sleep(1) # 给文件系统一点时间
except Exception as e:
print(f" ❌ 处理文件 {file_name} 时出错: {str(e)}")
error_files.append(f"{file_name}: 处理出错 - {str(e)}")
continue
print(f'\n{"="*60}')
print("处理完成统计:")
print(f"总共处理文件数: {len(docx_files)}")
print(f"成功处理文件数: {len(processed_files)}")
print(f"出错文件数: {len(error_files)}")
if processed_files:
print(f"\n✓ 成功处理的文件 ({len(processed_files)}个):")
for i, f in enumerate(processed_files, 1):
print(f" {i:2d}. {f}")
if error_files:
print(f"\n❌ 出错的文件 ({len(error_files)}个):")
for i, f in enumerate(error_files, 1):
print(f" {i:2d}. {f}")
# 将零时文件夹docx文件转换为PDF
print('\n' + '='*60)
print('--------2、开始转换为PDF--------')
pdf_files = []
for ls_name in os.listdir(new_ls):
if ls_name.endswith('.docx') or ls_name.endswith('.doc'):
print(f"\n转换: {ls_name}")
docx_path = os.path.join(new_ls, ls_name)
pdf_file = os.path.splitext(ls_name)[0] + '.pdf'
pdf_path = os.path.join(new_ls, pdf_file)
try:
convert(docx_path, pdf_path)
if os.path.exists(pdf_path):
pdf_files.append(pdf_path)
file_size = os.path.getsize(pdf_path) / 1024 # KB
print(f" ✓ 转换成功: {pdf_file} ({file_size:.1f} KB)")
else:
print(f" ❌ 转换后文件不存在: {pdf_path}")
time.sleep(2)
except Exception as e:
print(f" ❌ 转换失败: {str(e)}")
print(f'\n找到 {len(pdf_files)} 个PDF文件准备合并')
# 合并PDF文件
print('\n' + '='*60)
print('--------3、开始合并PDF--------')
if pdf_files:
merger = PdfMerger()
# 按文件名排序,确保顺序正确
pdf_files.sort()
print(f"将要合并 {len(pdf_files)} 个PDF文件:")
for i, pdf_file in enumerate(pdf_files, 1):
try:
file_size = os.path.getsize(pdf_file) / 1024 # KB
merger.append(pdf_file)
print(f" {i:2d}. 已添加: {os.path.basename(pdf_file)} ({file_size:.1f} KB)")
except Exception as e:
print(f" {i:2d}. ❌ 添加PDF失败: {os.path.basename(pdf_file)} - {str(e)}")
# 保存合并后的PDF文件
output_file = os.path.join(new, f'{name}.pdf')
try:
merger.write(output_file)
merger.close()
if os.path.exists(output_file):
output_size = os.path.getsize(output_file) / 1024 / 1024 # MB
print(f'\n✓ 合并完成!')
print(f' 保存位置: {output_file}')
print(f' 文件大小: {output_size:.2f} MB')
print(f' 包含文件数: {len(pdf_files)} 个')
# 验证合并后的PDF是否为双数页
try:
reader = PdfReader(output_file)
total_pages = len(reader.pages)
print(f' 合并后总页数: {total_pages}页')
if total_pages % 2 == 0:
print(' ✅ 合并后文档为双数页,适合双面打印')
else:
print(' ⚠️ 合并后文档为单数页,最后一页可能需要手动打印')
print(' 建议: 打印时选择"双面打印",打印机通常会处理单数页情况')
except Exception as e:
print(f' ⚠️ 无法验证合并后PDF页数: {str(e)}')
else:
print(f'\n❌ 合并文件未生成: {output_file}')
except Exception as e:
print(f"\n❌ 保存合并文件失败: {str(e)}")
else:
print("❌ 没有找到可转换的PDF文件")
# 删除临时文件夹
print('\n' + '='*60)
print('--------4、清理临时文件--------')
try:
if os.path.exists(new_ls):
# 先查看临时文件夹内容
temp_files = os.listdir(new_ls)
print(f"临时文件夹中包含 {len(temp_files)} 个文件:")
for f in temp_files[:10]: # 只显示前10个
f_path = os.path.join(new_ls, f)
size = os.path.getsize(f_path) / 1024 if os.path.exists(f_path) else 0
print(f" {f} ({size:.1f} KB)")
if len(temp_files) > 10:
print(f" ... 还有 {len(temp_files)-10} 个文件")
shutil.rmtree(new_ls)
print("✓ 临时文件夹已删除")
else:
print("⚠️ 临时文件夹不存在")
except Exception as e:
print(f"❌ 删除临时文件夹失败: {str(e)}")
print('\n' + '='*60)
print('所有处理完成!')
print(f'原始文件夹: {old}')
print(f'输出文件夹: {new}')
print(f'成功处理文件数: {len(processed_files)}/{len(docx_files)}')
# 最后提示
print('\n' + '='*60)
print('📋 打印建议:')
print('1. 打开生成的PDF文件: ' + output_file)
print('2. 在打印设置中选择"双面打印"')
print('3. 如果打印机不支持自动双面,选择"手动双面打印"')
print('4. 纸张方向根据周计划表格选择(通常为横向)')
print('='*60)


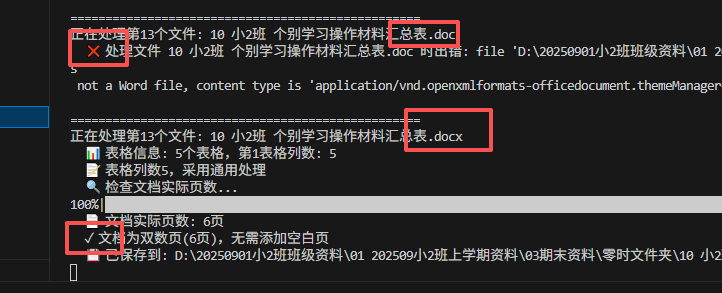
我试了多次,还是不行,测试了doc和docx,发现doc文件必须转成docx才能操作

;'''
doc转docx
豆包,阿夏
20260106
'''
import os
import win32com.client
from pathlib import Path
def batch_doc_to_docx(source_folder, target_folder=None):
"""
批量将doc文件转换为docx文件
:param source_folder: 源文件夹路径(存放doc文件)
:param target_folder: 目标文件夹路径(存放转换后的docx文件),默认在源文件夹下创建docx_output子文件夹
"""
# 处理路径,确保路径格式正确
source_path = Path(source_folder)
if not source_path.exists():
print(f"错误:源文件夹 {source_folder} 不存在!")
return
# 设置目标文件夹,默认在源文件夹下创建docx_output
if target_folder is None:
target_path = source_path / "docx_output"
else:
target_path = Path(target_folder)
# 创建目标文件夹(如果不存在)
target_path.mkdir(exist_ok=True)
# 初始化Word应用程序(后台运行,不显示界面)
word = win32com.client.DispatchEx("Word.Application")
word.Visible = False
word.DisplayAlerts = 0 # 禁用弹出的提示框
# 遍历源文件夹下所有.doc文件(排除.docx)
doc_files = list(source_path.glob("*.doc"))
if not doc_files:
print("未找到任何.doc格式的文件!")
word.Quit()
return
success_count = 0
fail_files = []
for doc_file in doc_files:
# 跳过临时文件(Word自动生成的~$开头的文件)和docx文件
if doc_file.name.startswith("~$") or doc_file.suffix.lower() == ".docx":
continue
# 构造目标docx文件路径
docx_filename = doc_file.stem + ".docx"
docx_file = target_path / docx_filename
try:
# 打开doc文件
doc = word.Documents.Open(str(doc_file))
# 另存为docx格式(16是docx的文件格式代码)
doc.SaveAs(str(docx_file), FileFormat=16)
doc.Close()
success_count += 1
print(f"成功转换:{doc_file.name} -> {docx_filename}")
except Exception as e:
fail_files.append((doc_file.name, str(e)))
print(f"转换失败:{doc_file.name},错误:{e}")
# 关闭Word应用程序,释放资源
word.Quit()
# 输出转换结果
print("\n=== 转换完成 ===")
print(f"成功转换:{success_count} 个文件")
if fail_files:
print(f"转换失败:{len(fail_files)} 个文件")
for filename, error in fail_files:
print(f" - {filename}:{error}")
print(f"转换后的文件已保存到:{target_path.absolute()}")
# 主程序执行
if __name__ == "__main__":
# 源文件夹路径(123文件夹),请根据实际路径修改
# 示例:如果123文件夹在桌面,路径可以是 "C:/Users/你的用户名/Desktop/123"
source_folder = r"D:\20250901小2班班级资料\01 202509小2班上学期资料\04家园沟通\20260106四大教育(小2光盘)" # 相对路径(当前脚本所在目录下的123文件夹)
# 调用转换函数
batch_doc_to_docx(source_folder)
互相剪切黏贴,文件夹里替换成docx文件
继续用刚才的代码合并
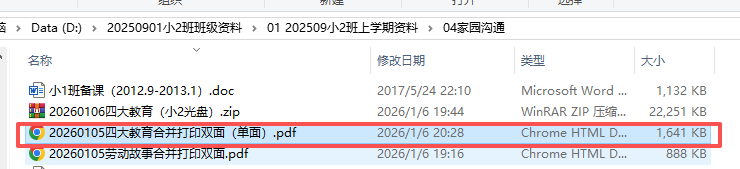
正确,一个月2张纸
