在政务服务数字化转型的浪潮中,政府政务服务中心作为服务群众和企业的前沿阵地,每日需处理海量各类申请表单,涵盖企业开办、社保参保、不动产登记、民生福利申领等多个领域。这些申请表单形式多样,既有标准化的结构化表格,也有因业务特性衍生的半结构化表格,传统人工录入与处理模式面临效率低下、误差率高、信息流转不畅等诸多痛点,成为制约政务服务效能提升的关键瓶颈。一种基于深度学习与计算机视觉技术研发的高精度表格识别技术,精准切入政务服务申请表处理场景,通过自动化提取表格文字与布局信息、实现复杂表格精准解析和版面还原,为政务服务数字化升级注入核心动力。
核心技术解析:深度学习驱动的智能表格识别系统
表格识别技术以自研的多模态深度神经网络架构为基础,融合了目标检测、语义分割、序列建模与图神经网络等前沿AI技术。系统首先通过高鲁棒性的图像预处理模块,对扫描件或手机拍摄的申请表图像进行去噪、纠偏、增强等操作,确保输入质量;随后,利用基于Transformer的文本检测与识别模型,实现对中文、数字、符号等多类型字符的高精度OCR识别,准确率高达99.5%以上。
更重要的是,表格识别技术不仅关注"文字内容",更聚焦于"表格结构"。通过引入布局感知的版面分析算法,系统能够自动识别表格线、单元格、合并区域、标题行、数据区等关键元素,并重建原始表格的逻辑结构与空间关系。即使面对无边框表格、手写混排、跨页表格等复杂场景,也能保持高度的解析稳定性。
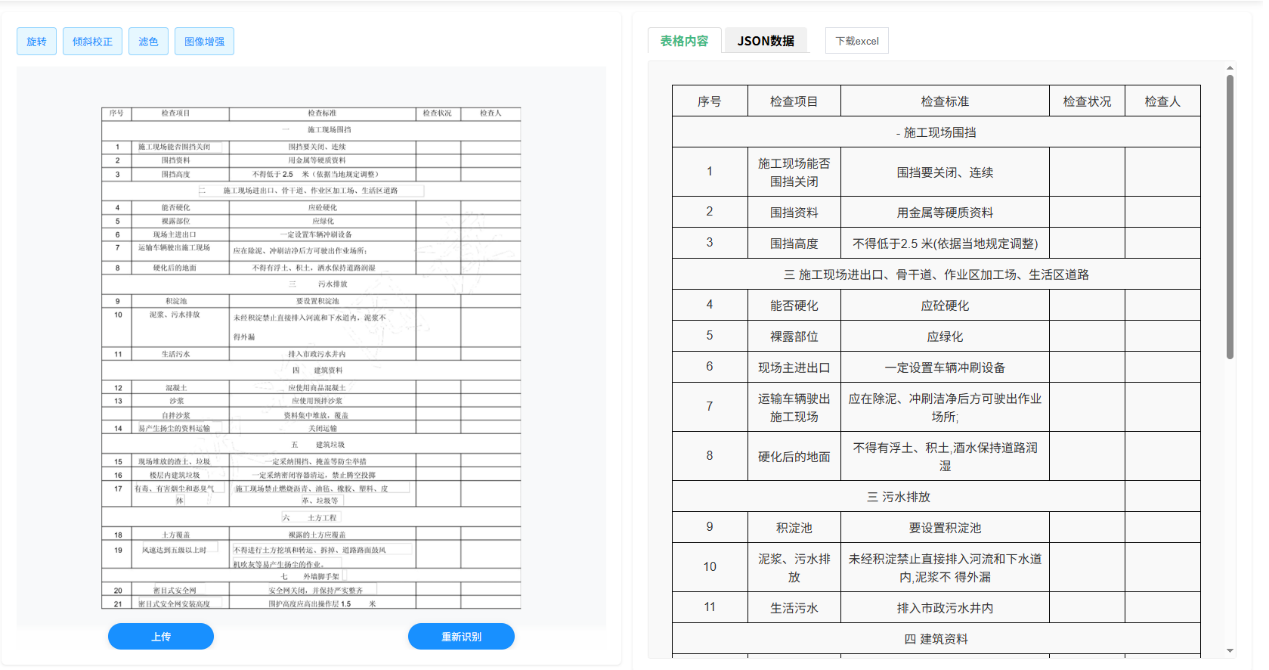
核心功能特点详解
1.全格式自适应解析能力
- 无模板化处理:无需预定义模板即可自动识别多种表格结构,包括复杂合并单元格、斜线表头、嵌套表格等
- 多格式兼容:支持纸质扫描件、手机拍照、PDF/Word电子文档等多种输入源;
- 动态结构识别:准确识别"根据情况勾选"产生的可变长度字段和动态生成栏目。
2.高精度多模态文本识别
- 混合字体识别:印刷体识别率>99.5%,工整手写体>98%,支持楷体、宋体、仿宋等公文常用字体;
- 复杂背景处理:有效分离红色印章、背景水印、表格线与文字内容;
- 多语言支持:同时识别中英文、数字、特殊符号及繁体字,满足跨境业务需求。
3.毫秒级处理与实时校验
- 批量并发处理:单服务器支持每秒处理50+页表格,满足高峰时段需求;
- 置信度反馈:为每个识别结果提供可信度评分,指导人工复核重点。
4.精准版面还原与数字孪生
- 矢量级重构:生成与原始表格布局一致的数字化版本,保留100%版面信息;
- 可编辑化输出:一键导出为可编辑Word、Excel、结构化JSON及标准PDF/A归档格式;
- 元数据嵌入:为每个字段添加语义标签和时间戳,满足电子档案管理要求。
政务场景应用:从信息提取到结构化处理全流程
智能受理与自动化处理
- 一窗受理辅助:窗口人员扫描申请材料后,系统3秒内完成关键信息提取与预填入业务系统;
- 批量年检处理:支持上百份企业年检表的并行处理,自动汇总统计信息;
- 跨表信息关联:自动关联同一申请人的多份表格,构建完整申报画像。
复杂场景专项突破
- 特殊表格处理:精准处理复写纸多联表格、碳素笔迹褪色表格等疑难情况;
- 移动端采集:群众通过政务APP拍照上传,系统实时识别并预审填报内容。
高精度表格识别技术,不仅是一项OCR工具的升级,更是政务服务从"以流程为中心"向"以用户为中心"转型的关键支撑。通过让机器精准"读懂"每一张申请表的结构与内容,政府工作人员得以从重复性劳动中解放,将更多精力投入到政策解读、群众沟通与服务优化中。