现在的AI发展势头,在笔者的思考下,除非AI实现大一统,否则任何AI检测工具都意义不大,很容易被绕过,笔者已成果实践绕过文本类AI检测
要想规躲过AI率识别,首先要清楚AI率是怎么统计的
一、文本AI是怎么检测的?
1、统计特征分析
困惑度 (Perplexity) 计算:衡量文本的不可预测性,AI 文本因模式化强,通常困惑度更低(更 "平滑"),人类写作则因用词多样、表达灵活困惑度更高。
突发性 (Burstiness) 分析:评估词汇使用的不均匀分布,人类写作常有自然的 "词汇爆发"(突然使用罕见词或复杂句式),AI 文本则突发性低、表达更均匀。
熵值与重复率:AI 文本信息熵更低,局部重复现象更明显,高频词占比更高,长尾词使用较少。
句子结构指标:AI 偏好使用固定句式(如 "首先... 其次..."),句子长度变化小,语法完美无瑕疵,缺乏人类写作中的自然错误
2、机器学习判别器
核心:用海量人类文本与 AI 文本训练分类模型(如 BERT、RoBERTa 变体),学习两者在语言模式上的差异
流程:
提取文本特征(词向量、句法结构、语义关系等)
与训练库中的 AI / 人类特征对比匹配
输出 AI 生成概率(AI 率),而非简单二元判断
代表:OpenAI 的 GPT 检测器、GPTZero 等主流工具
3、水印与特征嵌入检测
原理:部分 AI 服务(如 Google SynthID、Microsoft Azure)在生成内容时嵌入不可见数字水印(特定词汇选择偏向、字符分布模式)
优势:检测准确率高,可精准溯源特定 AI 模型生成内容
局限:仅适用于带水印的 AI 内容,无法检测无水印或开源模型生成文本
4、高级零样本检测(如 DetectGPT)
创新:"以 AI 检测 AI",通过文本改写一致性分析判断杭州科技政务网
流程:
对待测文本进行同义改写(用不同 AI 模型)
计算原文本与改写文本的相似度
AI 生成内容因统计惯性,改写后相似度显著高于人类文本
二、怎么简单的办法绕过去呢?
已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除
已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除
已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除
已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除 已删除
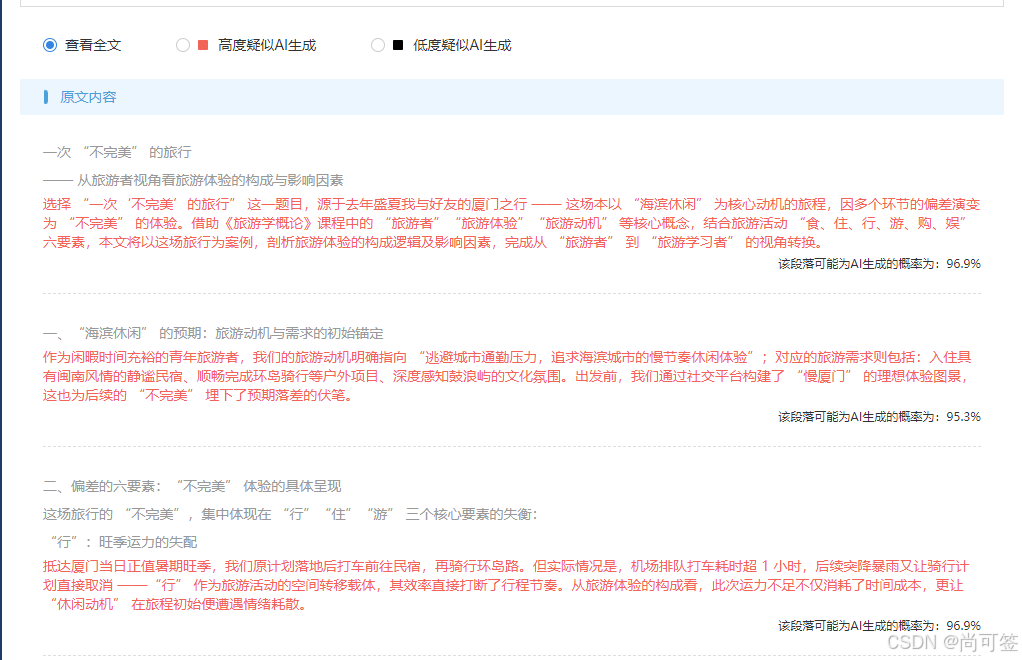
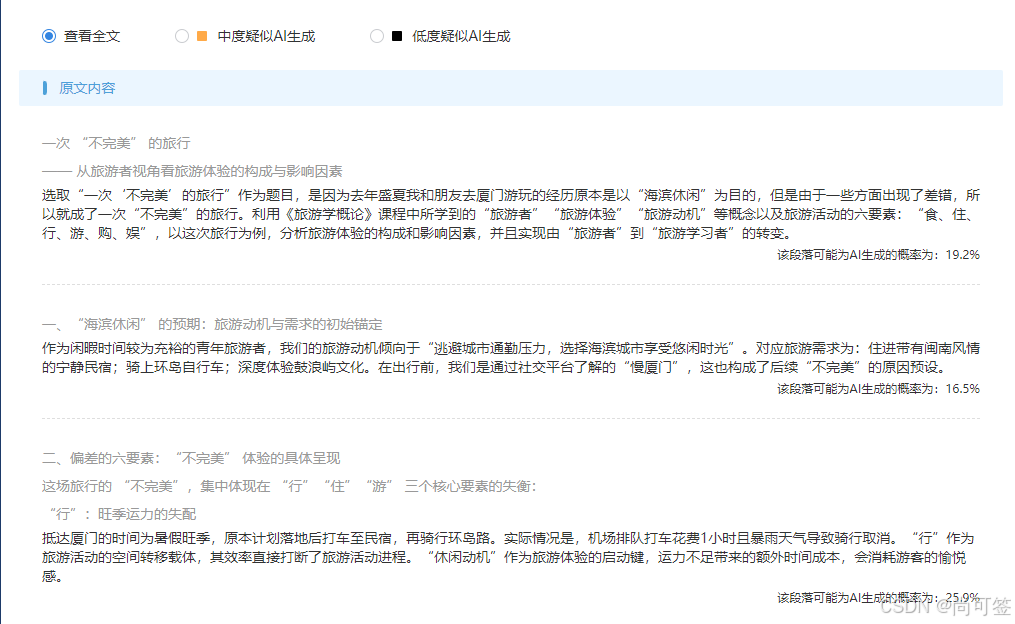
现在AI检测、AI降重盛行,笔者怕牵扯到,目前方法已删除并不打算开源出去了,暂不打算上线工具,阅读到本篇文章的朋友,可以私信笔者交流,正当用途可以免费帮忙降低一次
注:脾气古怪,保持礼貌...