利用扣子开发智能体、工作流程和应用已经成为新的热点。下面说说我的一些尝试。
一、利用现有资源生成工作流
此前已经利用已经上架的插件、大模型,编排了一个数据取数的工作流。
具体如下:
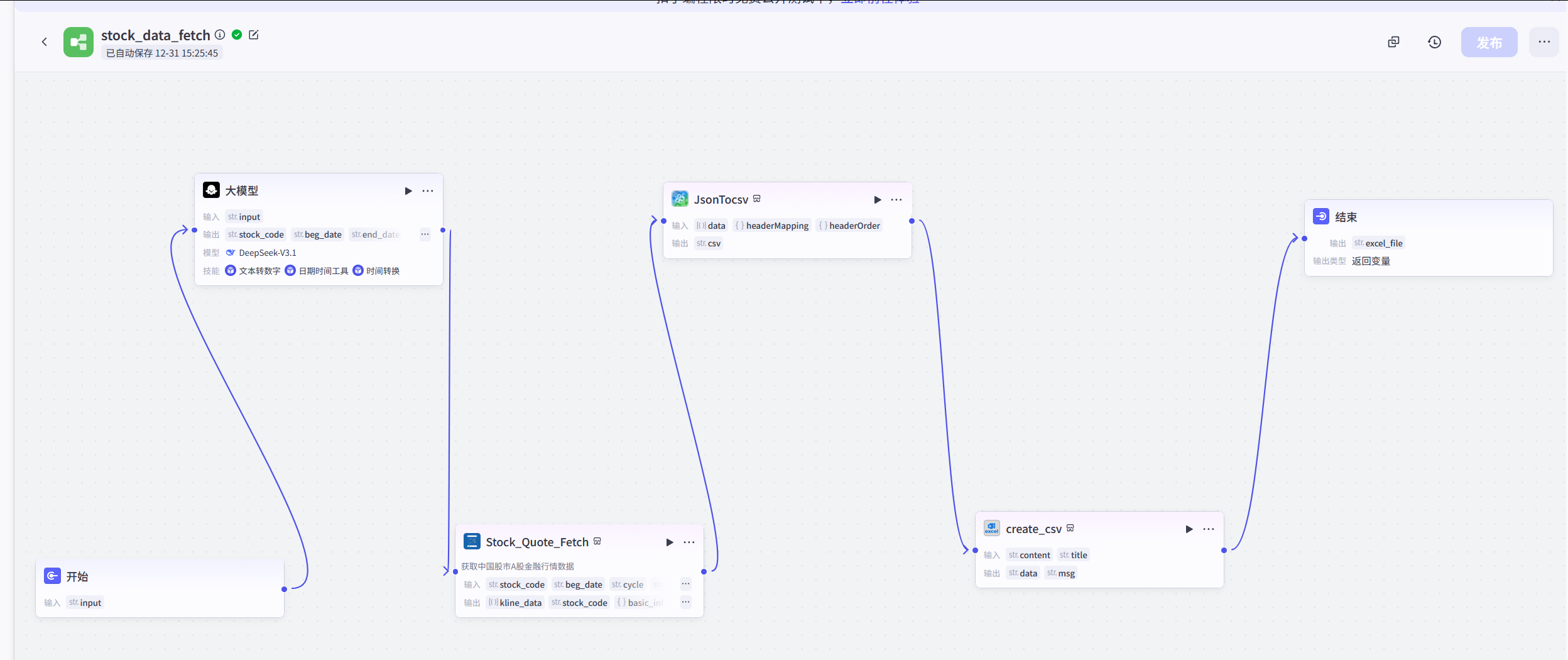
可以实现:
输入文本:
"比如请帮我取一下招商银行(600036)过去8周的日度数据"
输出:
生成csv的文件链接在浏览器上,直接下载即可。
在这个创建的扣子工作流中,利用平台上架的资源,共设置了5个具体的工作流:
工作流1:通过设置相应的大模型,把"取一下招商银行(600036)过去8周的日度数据"转换成相应的json,喂给下一个插件;【文本转json】
工作流2:把工作流1生成的相关输入,输入插件stock_quote_fetch中,并生成新的输出;【输入字段,输出json数据】
工作流3:把工作2的输出,输入到jsontocsv中,把json文件转换到csv数据;【json转csv】
工作流4:把csv数据文件生成相应的文件;【csv数据生成csv文件】
工作流5:生成csv文件链接,供直接下载。【提供csv文件的链接和下载】

上面就是在平台上测试的情况。
总的来讲,利用大模型、现有的插件资源,来提供相应的服务,还是比较有意思的(关键是服务能力将有质的提升)。
二、关于自有插件的创建
上面的扣子工作流,都是利用现成的上架的资源(智能体、大模型、插件)来实现的。
毕竟有一些插件需要自定义,做特定的工作流或智能体呢,那只能进行自开发了。
那么,如何利用自身开的发插件,来实现自己的工作流或智能体?
首先,点击"资源库",并找到"+资源"
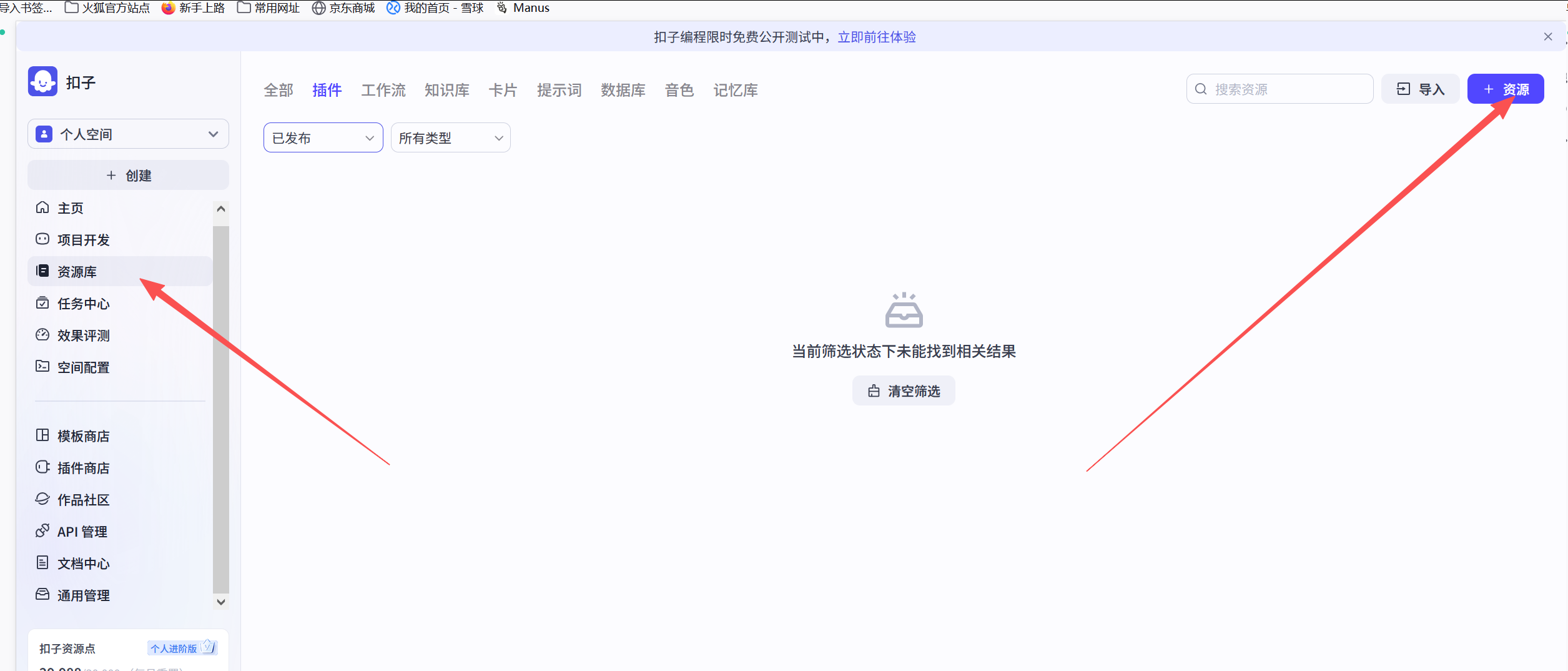 打开后,出现下面输入界面,并填好。
打开后,出现下面输入界面,并填好。
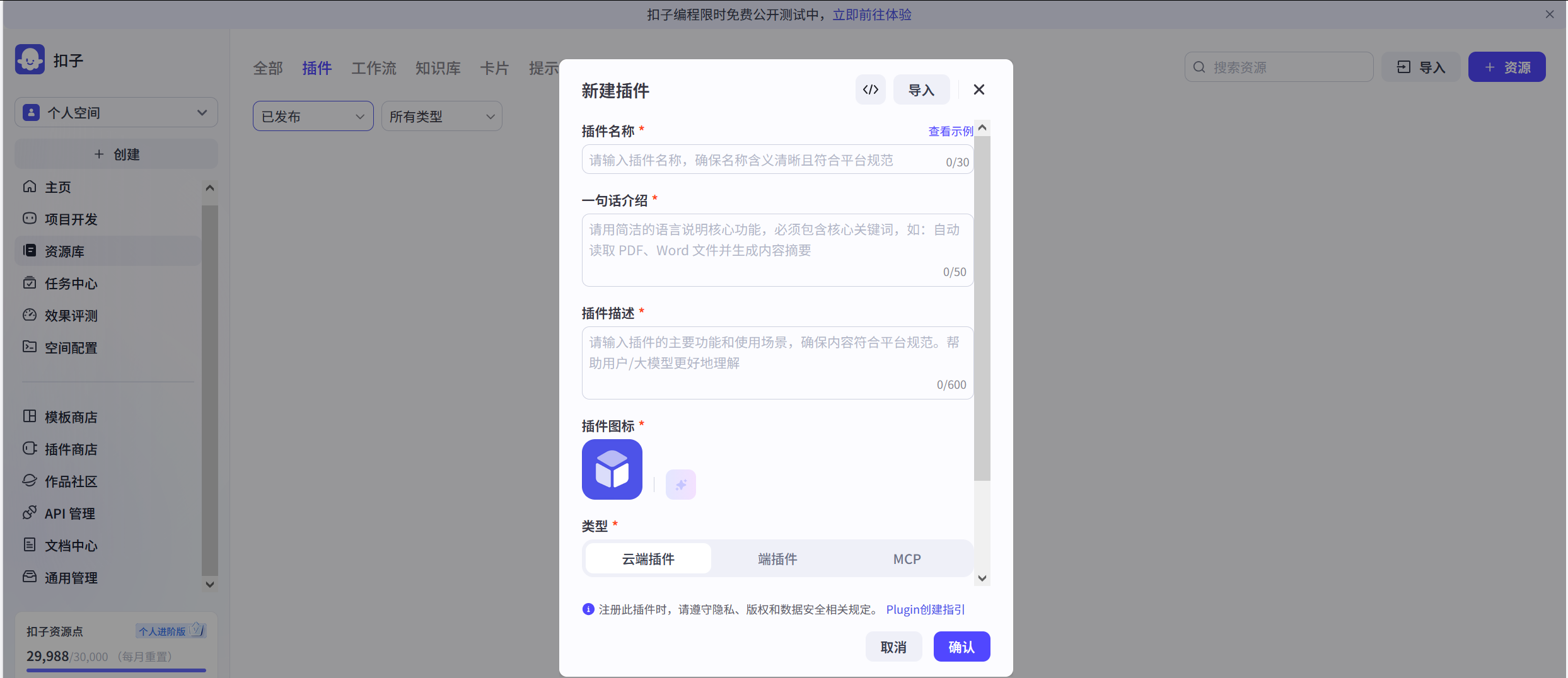 需要说明的是,目前开发语言只有node.js和python两种选项。
需要说明的是,目前开发语言只有node.js和python两种选项。
填后确认后,可以进入编写插件的平台。
并点击生成工具。就会开现相关代码平台。
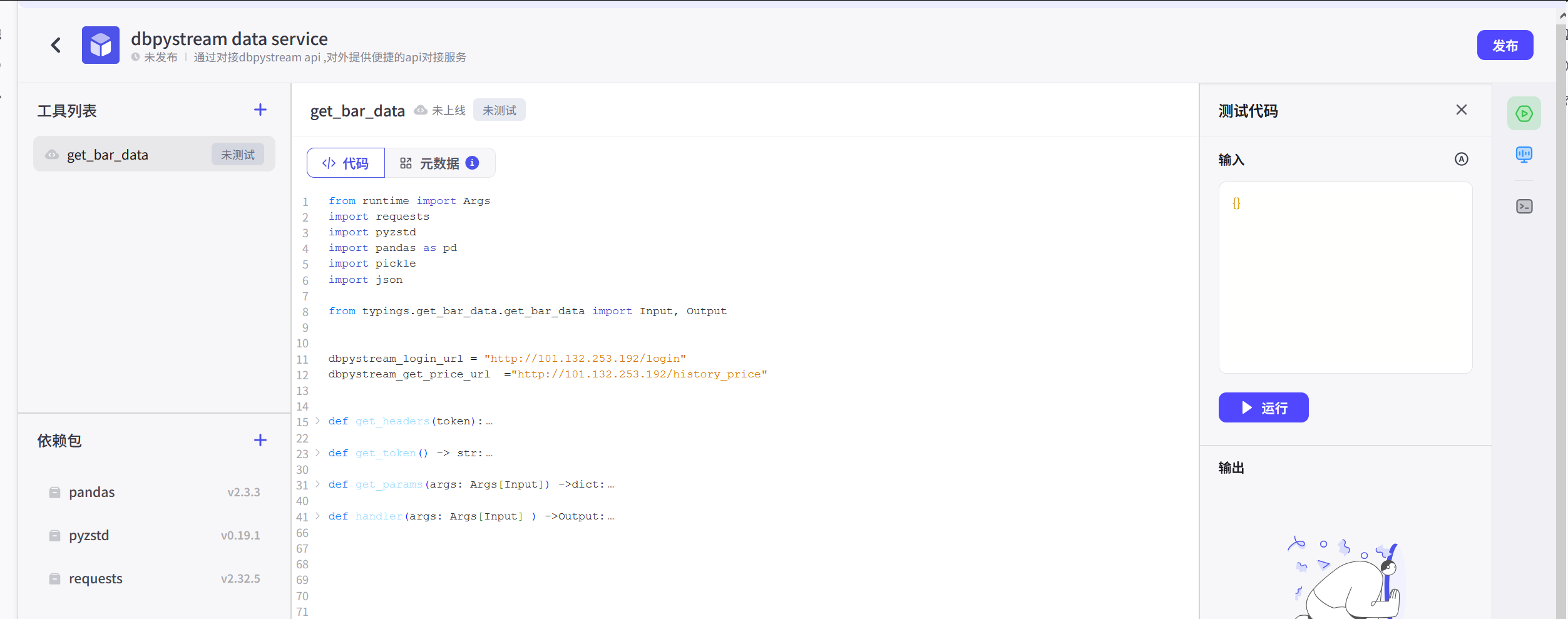
里面有几个重点内容:
1、Input和Output;2、代码和元数据
当然,可以看到里面有一段关于Input和Output的说明,可以了解一下。
下面以dbpystream api为基础,创建自主插件的Input和Output来进行具体说明。
关于Input
css
args: Args[Input]:代表是输入的参数体。具体的参数字段在args.input里面。 在写代码时需要注意。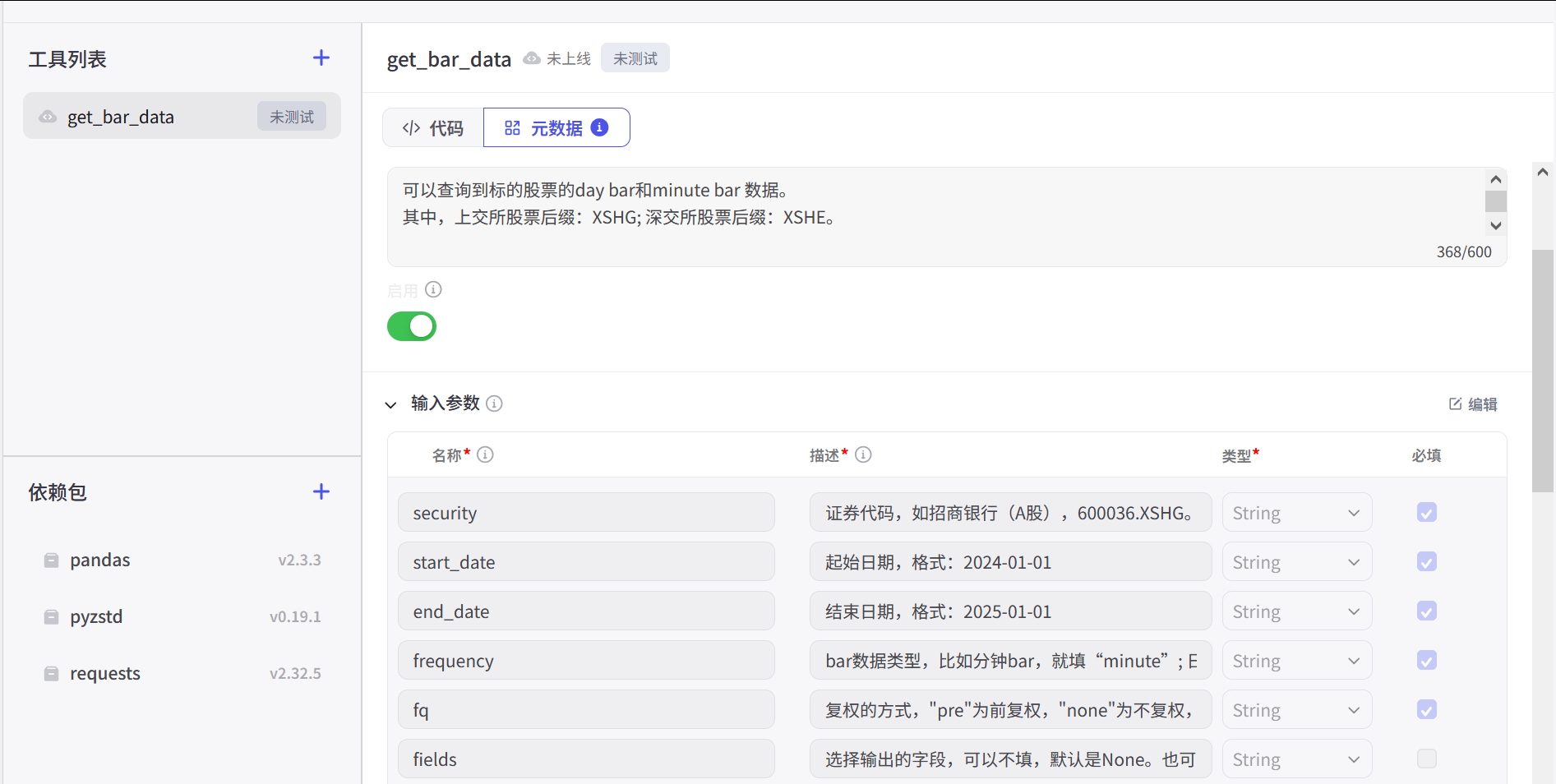
如果你点击一下元数据,security这个字段,可以对应写代码可以:
css
args.input.security其它对应即可。
关于Output
在代码编写时不用管。这里只需要注意,把格式要进行一一对应即可。
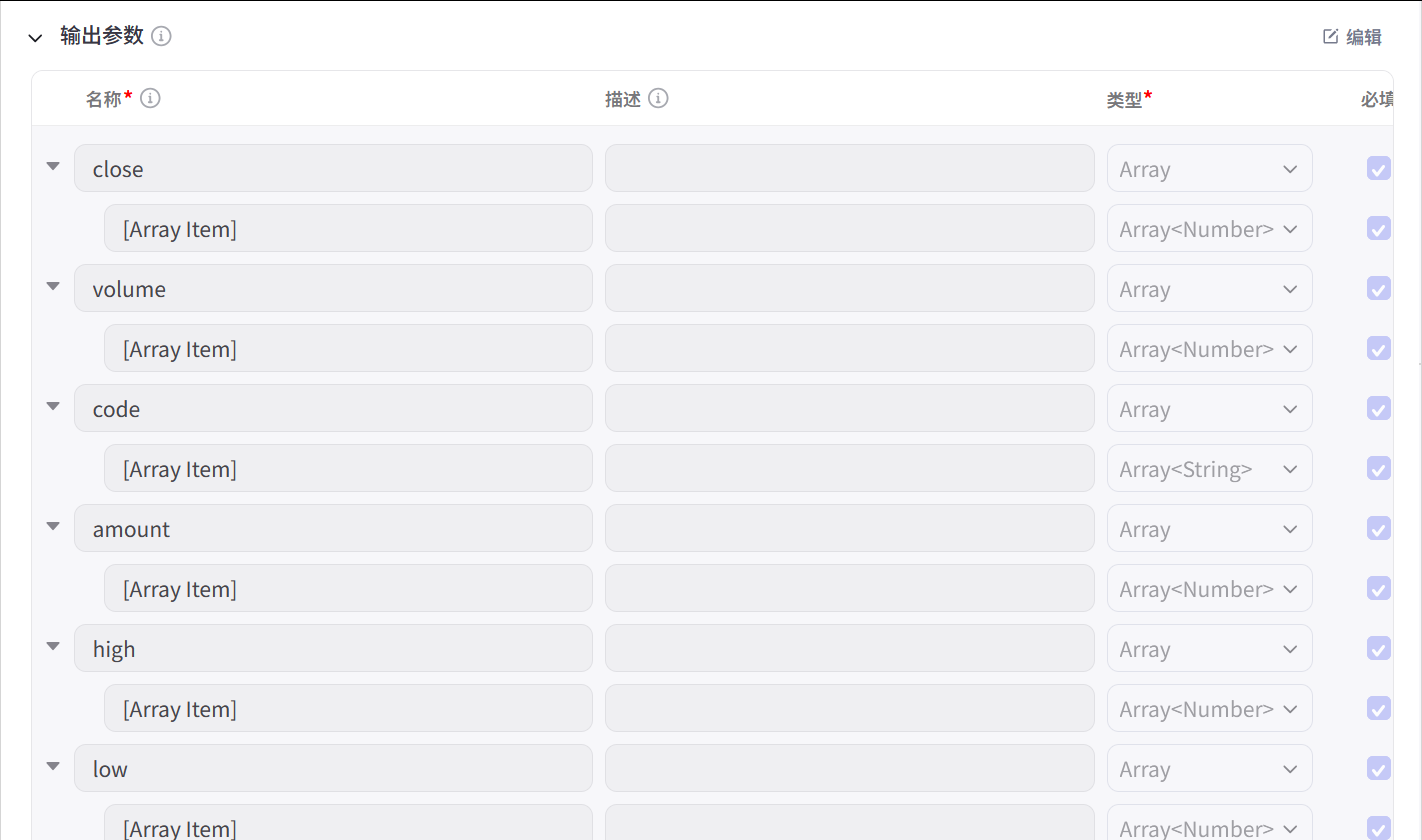
输出参数坑比较多。比如,pandas中有一些数据结构并不支持,需要进行特别处理。
我已经在下面尝试了一些复杂的数据结构。具体可以参考。
三、dbpystream api插件开发的python代码
1、dbpystream api
dbpystream api 项目具体见:
css
https://github.com/songroom2016/dbpystream2、插件代码
把dbpystream api 做成扣子中自主插件,以下是全部的代码:
css
from runtime import Args
import requests
import pyzstd
import pandas as pd
import pickle
import json
from typings.get_bar_data.get_bar_data import Input, Output
dbpystream_login_url = "http://101.132.253.192/login"
dbpystream_get_price_url ="http://101.132.253.192/history_price"
def get_headers(token) ->dict:
headers = {"Content-Type": "application/json",
"Authorization": token,
"lang" :"python",
"compression":"zstd"
}
return headers
def get_token() -> str:
username = "************" # 此处隐去!
password = "*************" # 此处隐去!
payload = {"username":username,"password":password}
response = requests.post(dbpystream_login_url, json=payload)
token = response.text
return token
# 有关input
def get_params(args: Args[Input]) ->dict:
params = {"security" : args.input.security,
"start_date":args.input.start_date,
"end_date":args.input.end_date,
"frequency":args.input.frequency,
"fq":args.input.fq,
"fields":args.input.fields};
return params
def handler(args: Args[Input] ) ->Output:
df = pd.DataFrame()
params = get_params(args)
data = json.dumps(params)
token = get_token()
headers = get_headers(token)
response = requests.post(dbpystream_get_price_url,data = data,headers = headers)
result = response.content #得到服务端传过来的zstd压缩后的字节流文件
_msg = pyzstd.decompress(result) #默认是zstd方式解压
if _msg != b'':
decompress_data = pickle.loads(_msg) # 需要通过pickle来反序列化,得到dict
df = pd.DataFrame(decompress_data) # 生产datafram
# 相关数据处理
dt = list(map(str,list(df.datetime))) #不支持原生的格式,需要进行处理
code =list(df.code)
open = list(df.open)
close = list(df.close)
high = list(df.high)
low = list(df.low)
volume = list(df.volume)
amount = list(df.money)
result = {"close":close,"datetime":dt,"code":code,"high":high,"open":open,"low":low,"volume":volume,"amount":amount}
return result四、测试
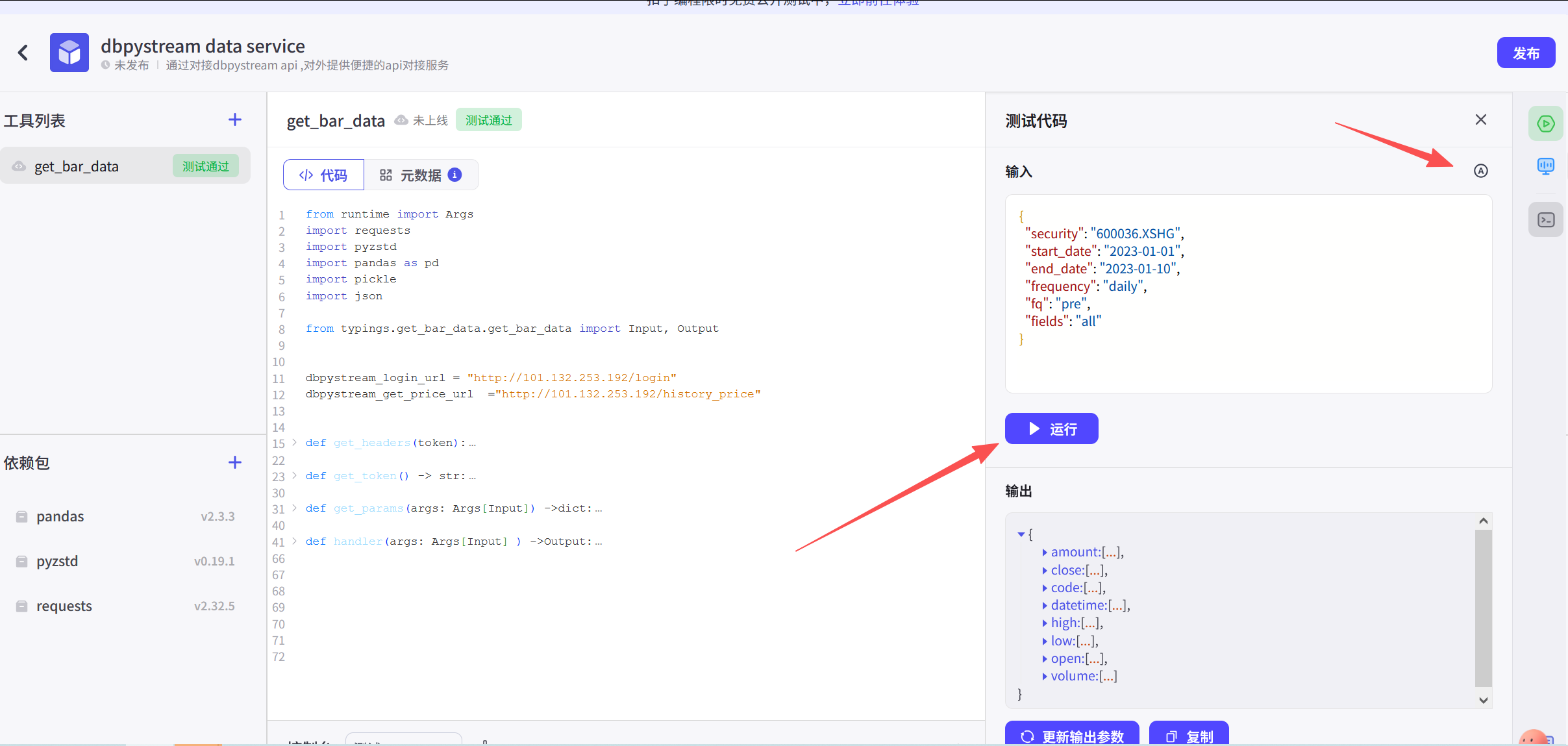
在开发平台上可以进行相关的测试。上面的代码也通过了相应的测试,总体上和写其它的代码差异不大,主要是Output格式上。
五、其它
扣子原生的开发平台目前支持还比较弱,报错信息和输出不太友好。可以先把代码放到原生IDE中进行调试。再搬回这个平台,这样效率高一些。
此外,一些数据支持的格式,需要进行摸索,有点费人。
希望大家一起来开发智能体,提高工作效率。