1. 何为Oracle统计信息
ORACLE数据库里的统计信息是这样的一组数据:它存储在数据字典里,且从多个维度描述了ORACLE数据库里对象的详细信息。
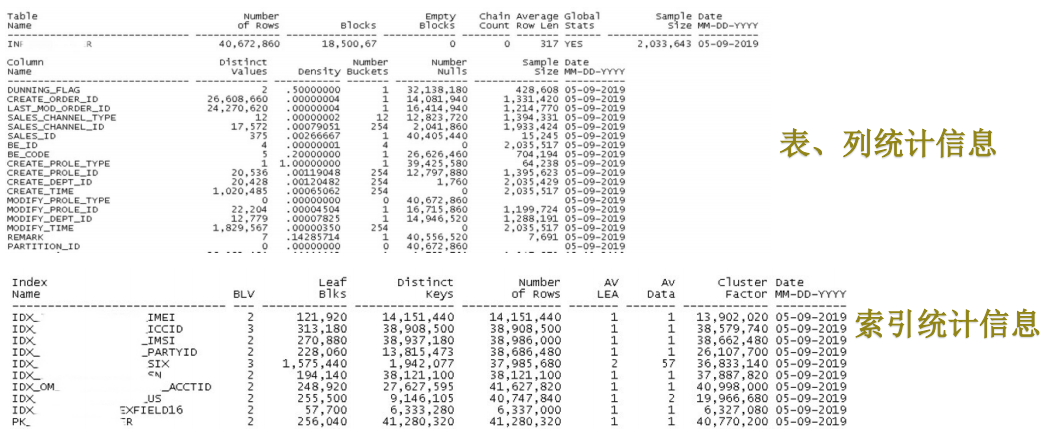
2. 收集统计信息的方法与区别
|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------------------|
| ANALYZE | DBMS_STATS |
| 可用于索引、表、列、数据字典统计信息 | 可用于索引、表、列、数据字典统计信息 |
| 无法收集系统表统计信息,如xbh: SQL\> analyze table xbh compute statistics; analyze table xbh compute statistics \* ERROR at line 1: ORA-02030: can only select from fixed tables/views | 可用于收集**系统表**统计信息: SQL\> exec dbms_stats.gather_table_stats('SYS','XBH'); PL/SQL procedure successfully completed. |
| 不能准确的收集分区表的统计信息:如对于有子分区的分区表,会先收集子分区的统计信息然后再汇总、推导出分区和表级的统计信息,但有的统计信息能从下一级对象推导,如表的行数,而有的不行,如num_distinct、density等 | 可以准确的收集分区表的统计信息 |
| 不能并行收集统计信息 | 可以并行收集统计信息 |
| 可以用来分析和收集如行迁移、行链接的数量,分析索引的结构 | 只能收集与CBO相关的统计信息,而与CBO无关的额外信息则无法收集 |
3. 表统计信息
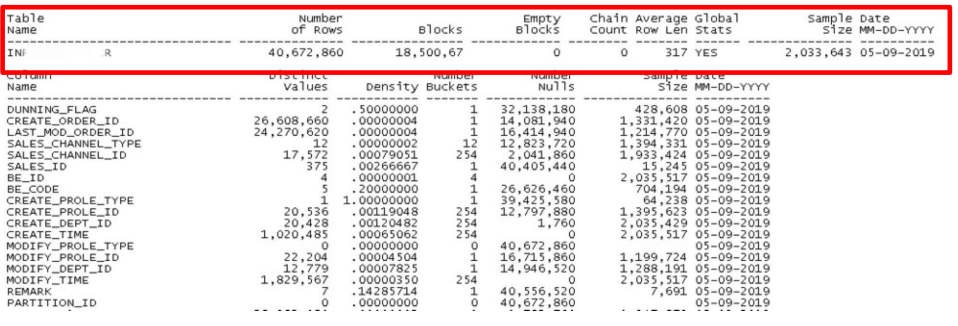
上图的红框用于描述表的详细统计信息,包含了记录数、表块(表里的数据块)的数量、平均行长度等典型
的纬度。这些纬度信息都存储在数据字典基表TAB、TABPART、TABSUBPART$等中,可以通过数据字典
DBA_TABLES、DBA_TAB_PARTITIONS、DBA_TAB_SUBPARTITIONS来分别查看表、分区表的分区和分区表的子分区
的统计信息。
4. 索引统计信息
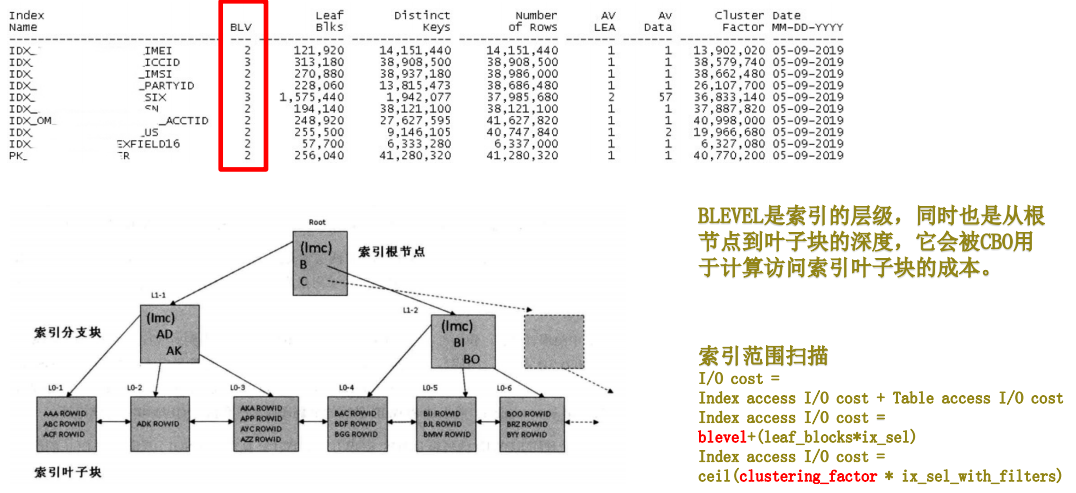
ORACLE数据库中,如果要 降低目标B树索引的层级 ,可以通过 rebuild该索引的 方式来实现。
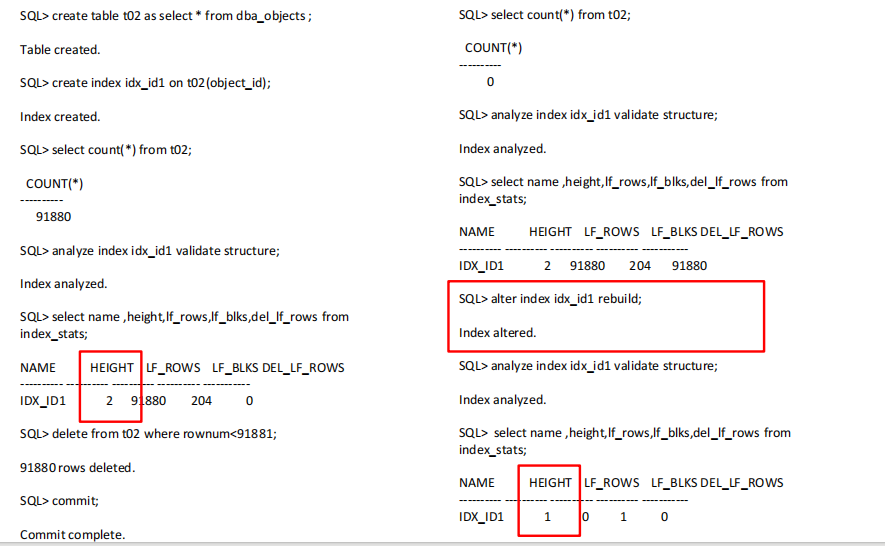
5. 聚簇因子
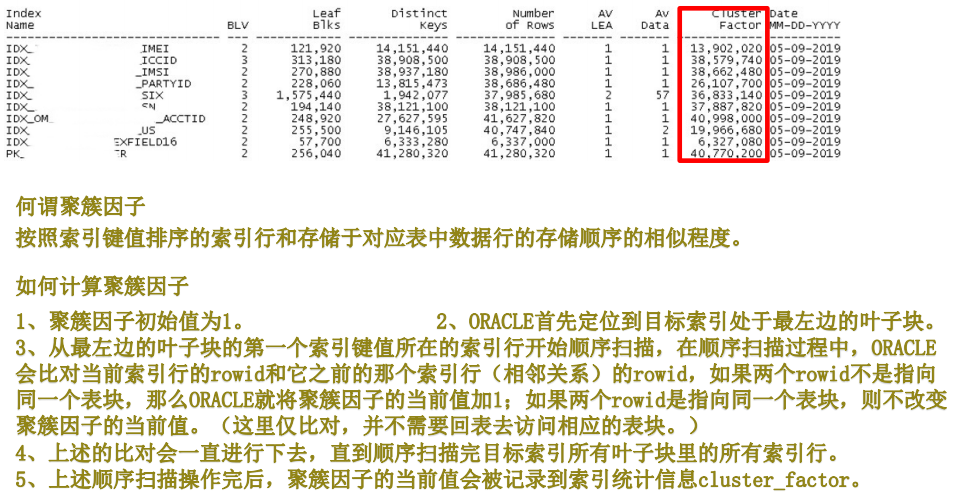
聚簇因子是基于索引的值去比较表中行的顺序,如果聚簇因子的值接近与块的数量(4),说明表的顺序是良好的,这种情况下,一个叶块的索引项通常指向的是同一个数据块中的行。
如果聚簇因子的值接近与行的值(20),说明的表的顺序是不好的,这种情况下,同一个叶块的索引项可能没有指向同一个数据块。
通过order by id 重建的话,使 id (按照索引的键值顺序)按照顺序的插入表中,降低目标聚簇因子的值,
但是会增加这张表上其他索引聚簇因子
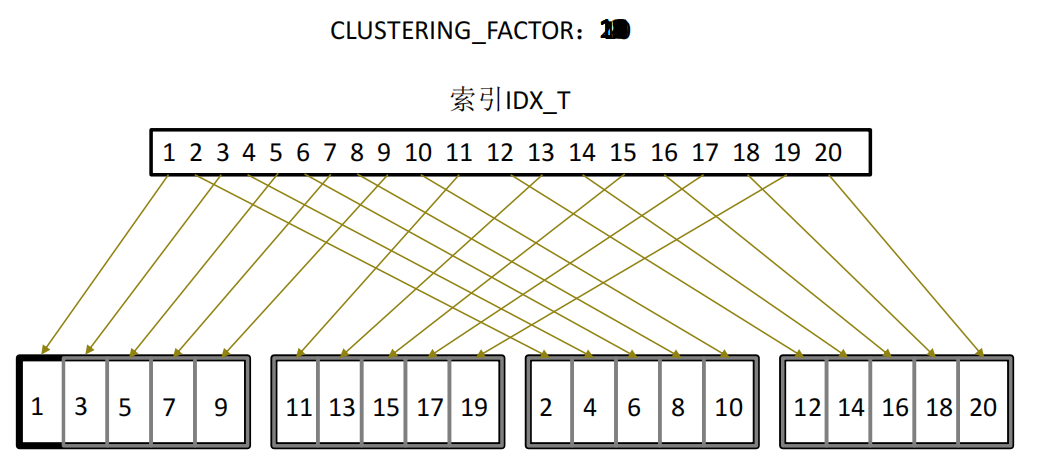
6. 列统计信息


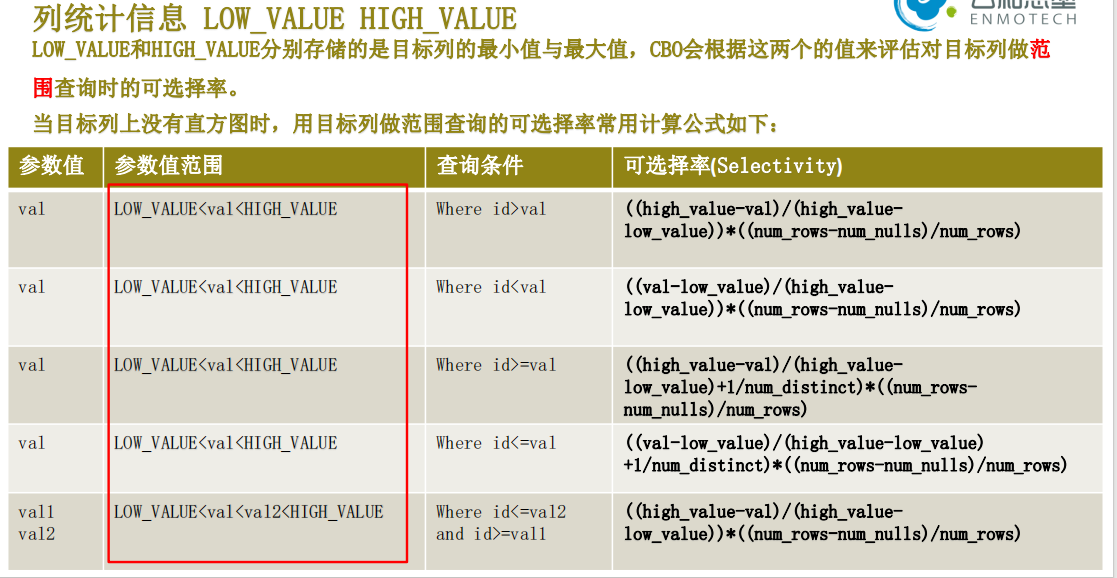
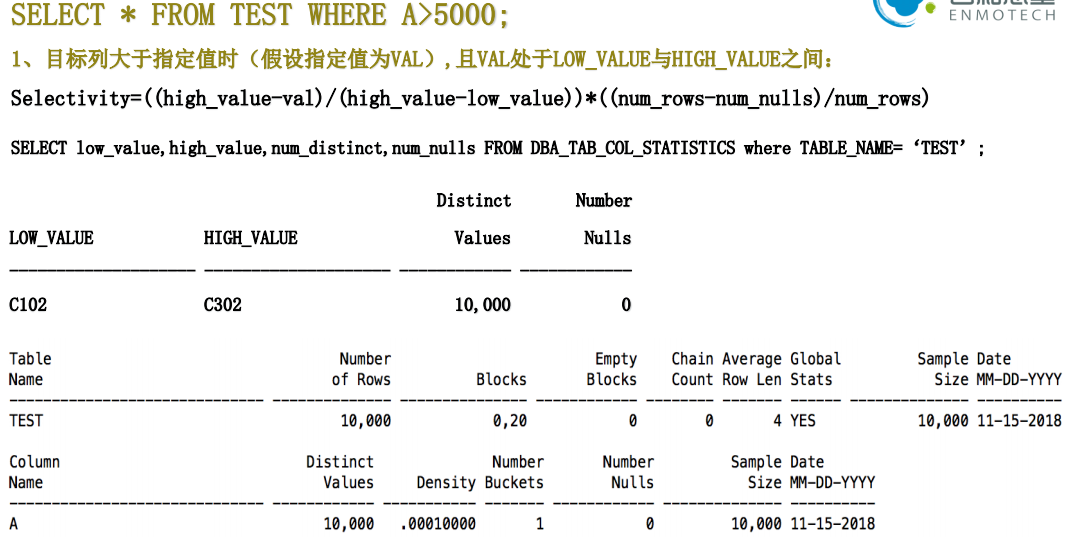
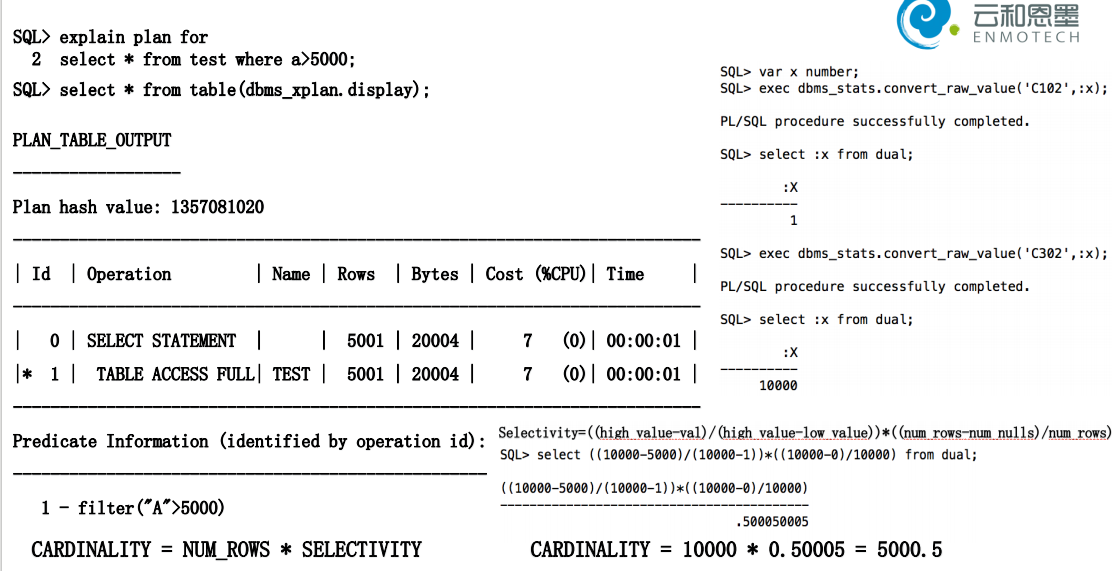
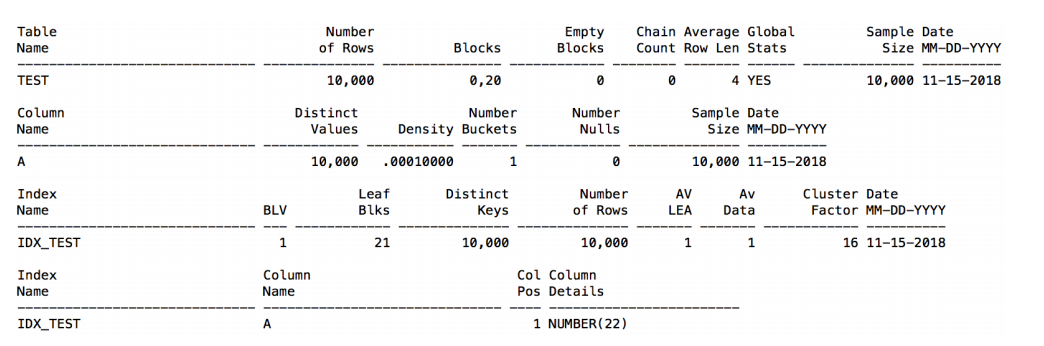
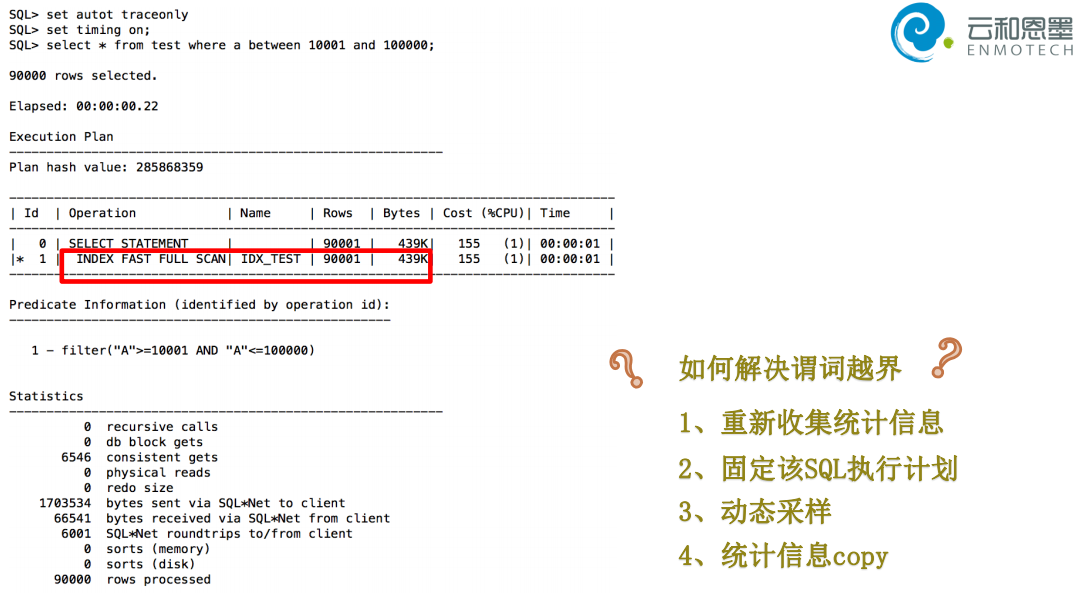
7. 谓词越界
如果对目标列指定的where查询条件不在该列的最大值(high_value)与最小值(low_value)之间,CBO就无法
判断出针对该列的查询条件的可选择率,所以只能用一个估算值来作为针对该目标列的查询条件的可选择率。
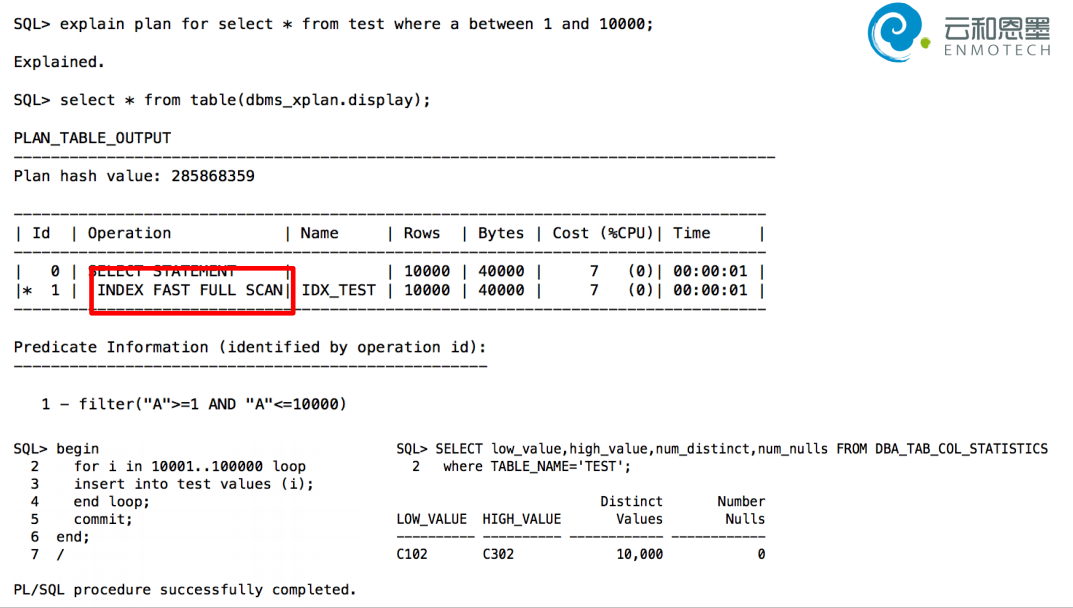
没有使用 index range scan, index range scan是单块读,index fast full scan是多块读(效率更高)
继续插入数据:(不收集它的统计信息)
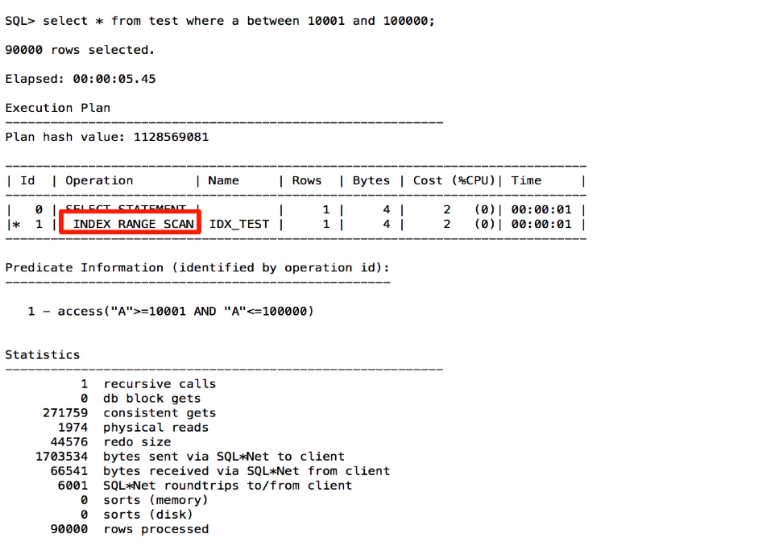
执行计划选择了单块读的index range scan ,并且 Rows和Bytes是1和4 ,对于查询10000条数据,这里的估值存在了很大的偏差

对test表重新收集的统计信息,再次的查看执行计划,执行计划是正确的了。
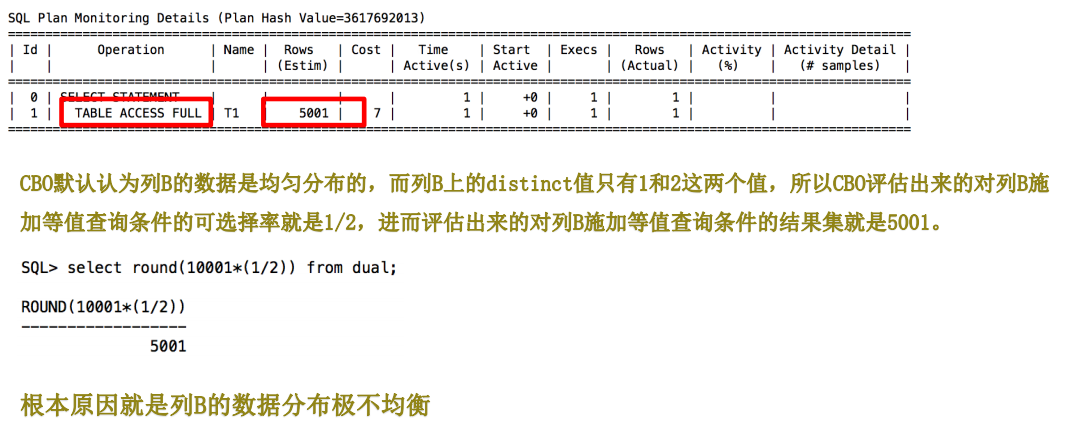
对CBO而言,他会默认的认为目标列的数据在其最小值(low_value)和最大值(high_value)之间是均匀分布的,并且按照均匀分布的原则来计算
对目标列施加查询条件以后的可选择率以及结果集,进而计算成本并选择执行计划,但是目标列数据均匀分部的这个原则,并不是永远正确的,因为在实际中,目标列的数据分布是不均匀的,甚至是极度倾斜,那根据这样的计算的成本和执行计划都可能是不合理的,甚至是错误的,这时候oracle引入了直方图。
8. 直方图
直方图是一种按数据出现的频率来进行分类存储的方法.在oracle中直方图是用来描述表中列数据的分布情况。
数据分布极不均衡而导致CBO选错执行计划的例子:
T1
1有10000条,2有1条,并且创建索引,以不收集直方图的方式(columns size 1),进行索引的统计信息收集

执行了b=2 的语句:
为了解决上面的问题,oracle引入了直方图,详细的描述了列的数据分布情况。
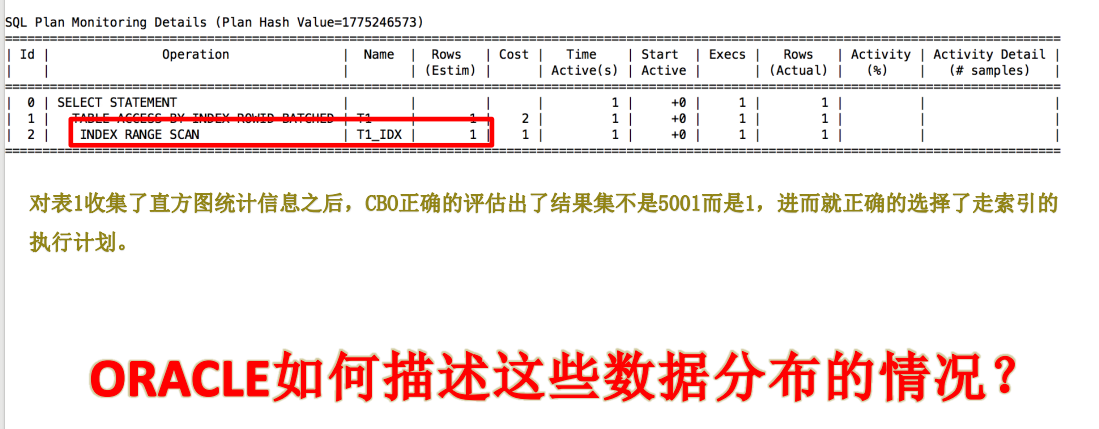


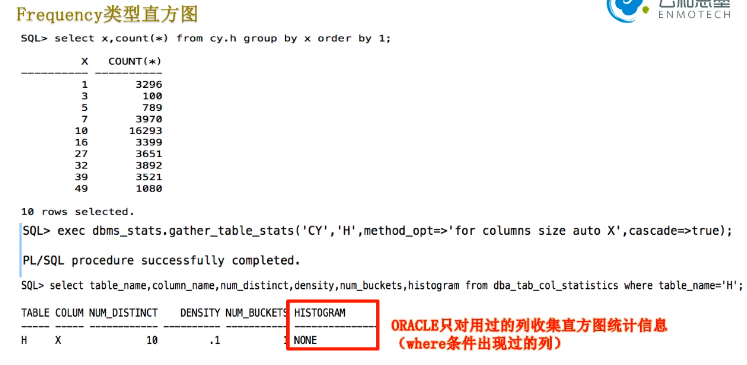
oracle 只对用过的列收集直方图统计信息,(也就是在where条件中出现过的列)
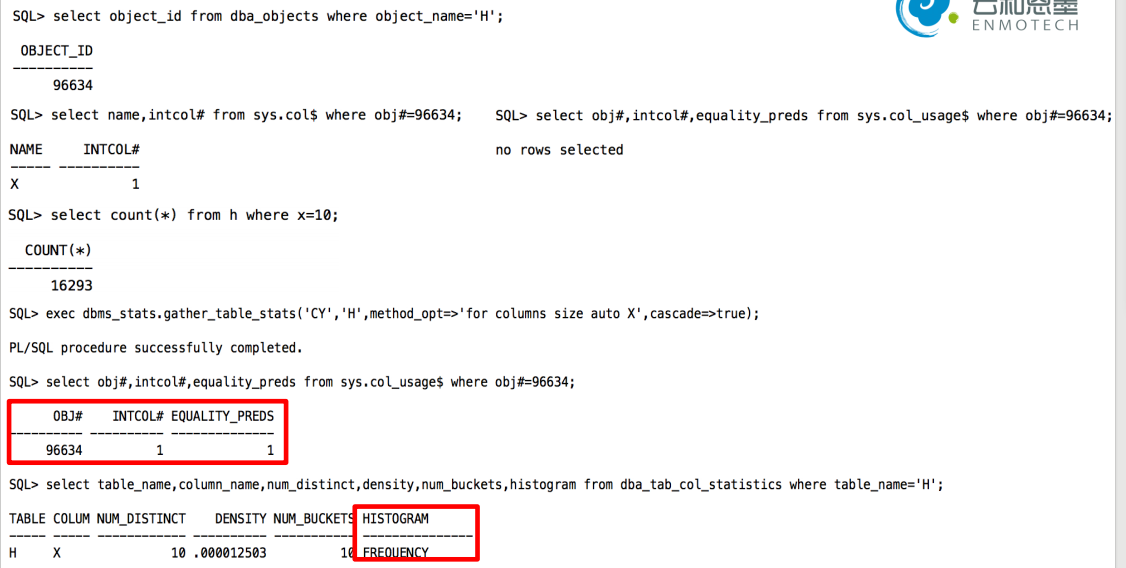


ENDPOINT_NUMBER用来记录Bucket号,从0号开始一直到N。其中0号Bucket里存储的是目标列的最小值;
ENDPOINT_VALUE实际上存放的是到此记录所描述的Buckets为止,之前所有Bucket描述的记录里目标列的最大值。
除了0号Bucket之外,其他所有记录的ENDPOINT_VALUE值都是用如下公式来计算的:
//目标表总记录数为M,需要使用的Bucket 数量为N
//每个Bucket里所存放的记录数为O,O = M/N
select max(目标列) from (select 目标列 from 表 order by 目标列) where rownum <= O; //1号桶
select max(目标列) from (select 目标列 from 表 order by 目标列) where rownum <= O*2; //2号桶
select max(目标列) from (select 目标列 from 表 order by 目标列) where rownum <= O*3; //3号桶
...
select max(目标列) from (select 目标列 from 表 order by 目标列) where rownum <= O*(N-1); //N-1号桶
select max(目标列) from (select 目标列 from 表 order by 目标列) where rownum <= O*N; //N号桶

ENDPOINT_NUMBER中没有2号,是因为数据字典中把ENDPOINT_NUMBER不同而ENDPOINT_VALUE相同的,进行合并。


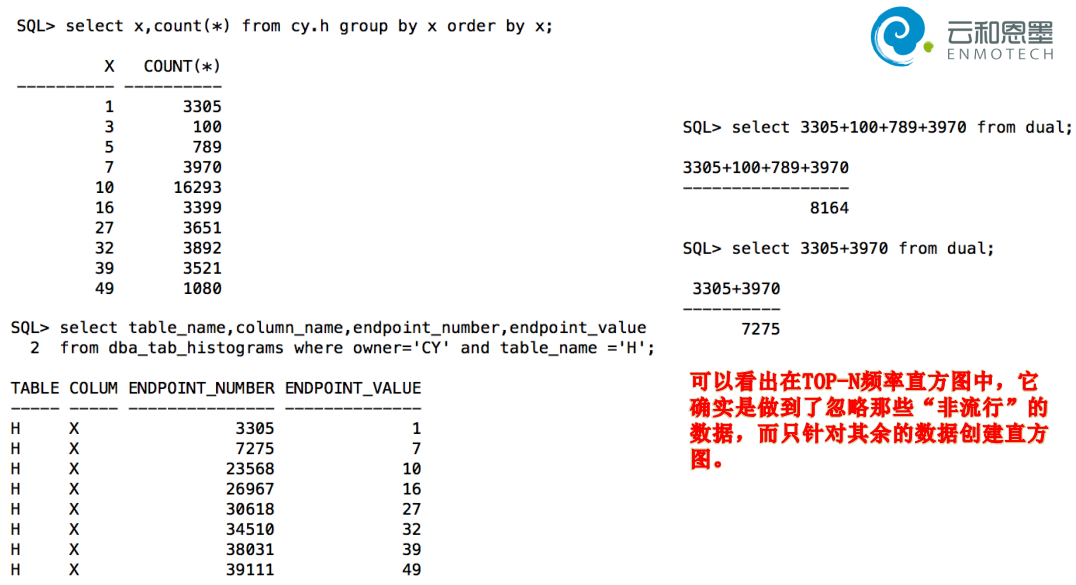
3和5被忽略了

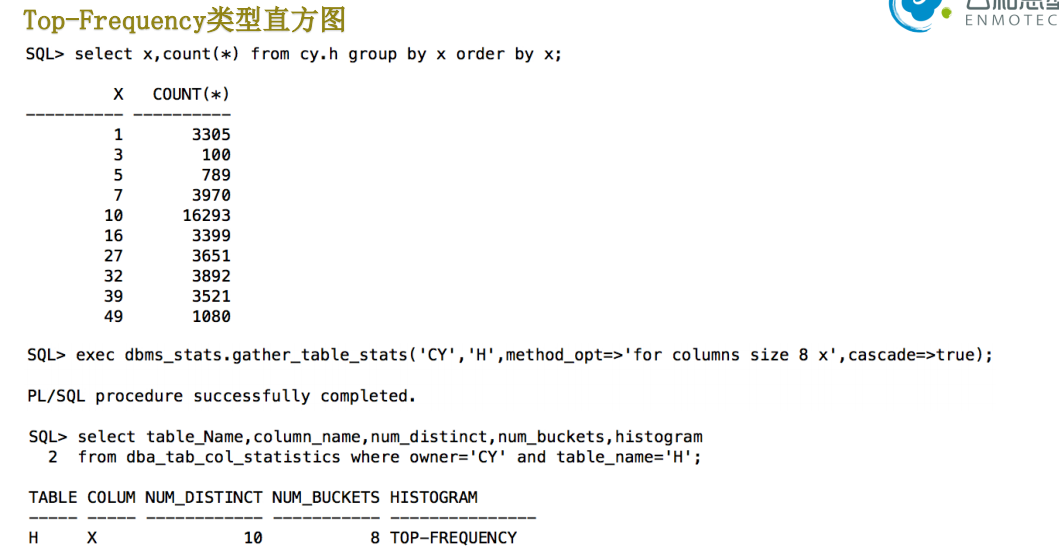
显然Top Frequency直方图他的计算更加精确,
对于distinct 超过254 且倾斜数据占据表中大量行的情况下,显然12c中的Top Frequency直方图估算的row更加准确。
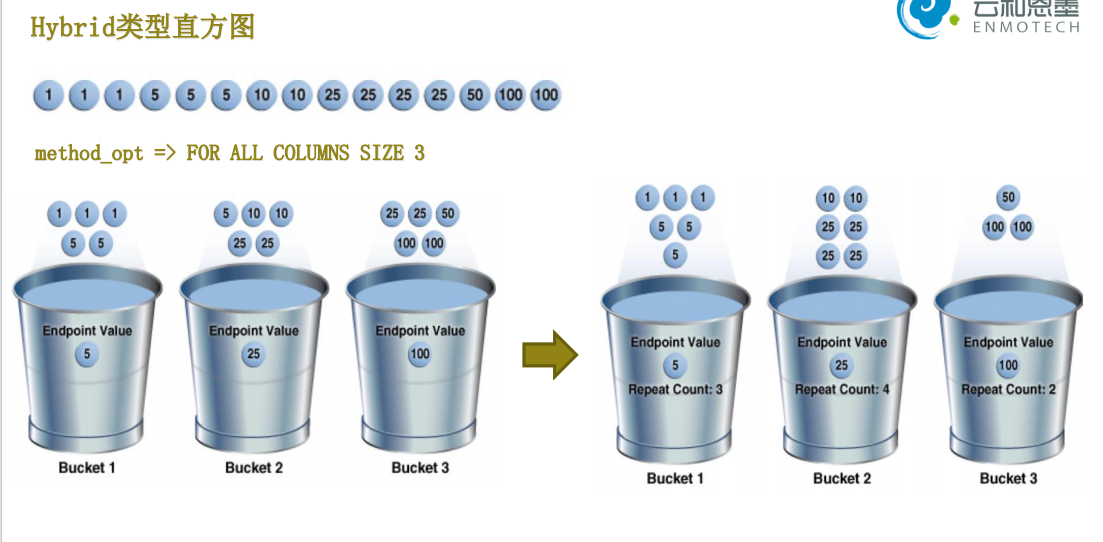
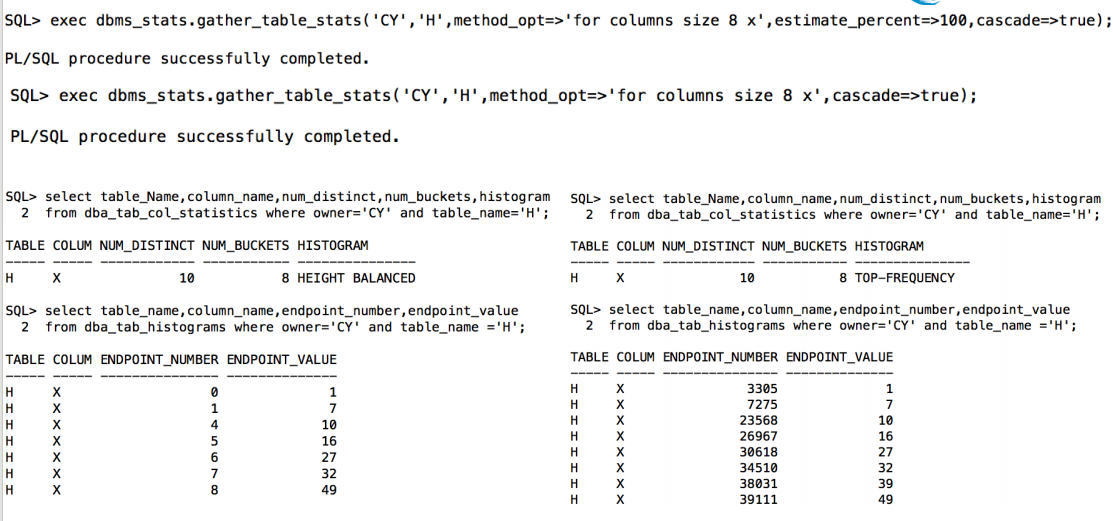
在12c中oracle这样推混合直方图(Hybird Histogram)和Top Frequency直方图,其实都是相应的弥补了高平衡直方图的不足的地方
oracle是怎么产生这四种的直方图的条件:
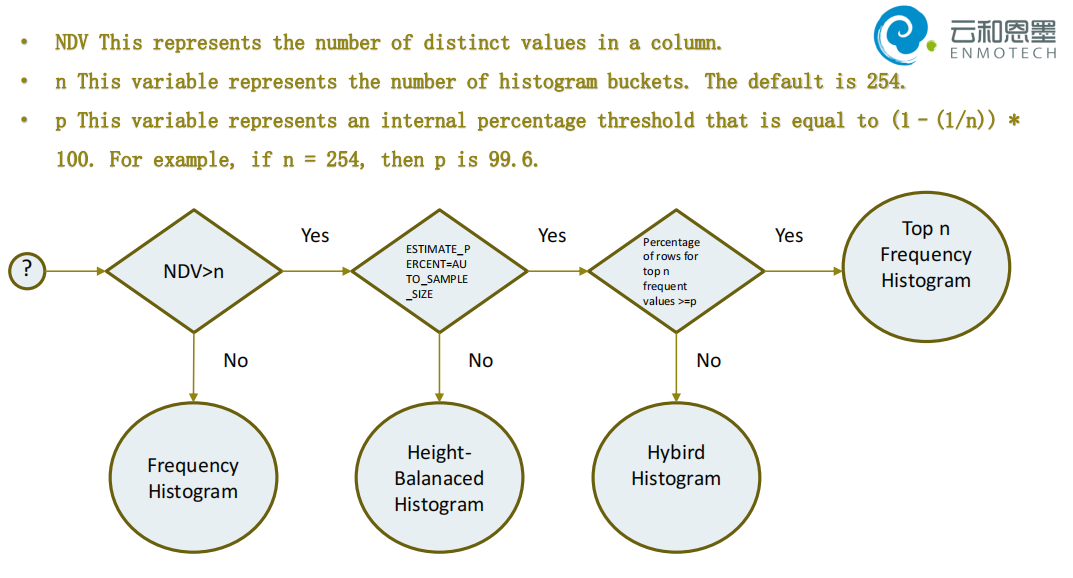
NDV>n distince values大于桶数
Frequency Histogram 频率直方图
Height-Balanaced Histogram 高平衡直方图
Hybird Histogram 混合直方图
Top Frequency 高频率直方图
一文搞懂 Oracle 统计信息
• 直方图类型
• Frequency ---- 列的NDV<=254
• Top-frequency----列的NDV>254 但是高频的254个列值占总行数比例大于100-100/n
• Hybrid Histogram ---列的NDV>254 但是高频的254个列值占总行数比例小于100-100/n
• Height-balanced---如果使用了AUTO_SAMPLE_SIZE将不再创建这个类型的直方图
--转载于恩墨大课堂