springAi特性VS Langchain4j
Spring Al 是一个面向人工智能工程的应用框架。解决了 AI集成的基本挑战:将企业数据和API与AI模型连接起来。
特性:
提示词工厂
可以说是大模型应用中最简单也是最核心的一个技术。他是我们更大模型交互的媒介,提示词给的好大模型才能按你想要的方式响应。
对话拦截advisors
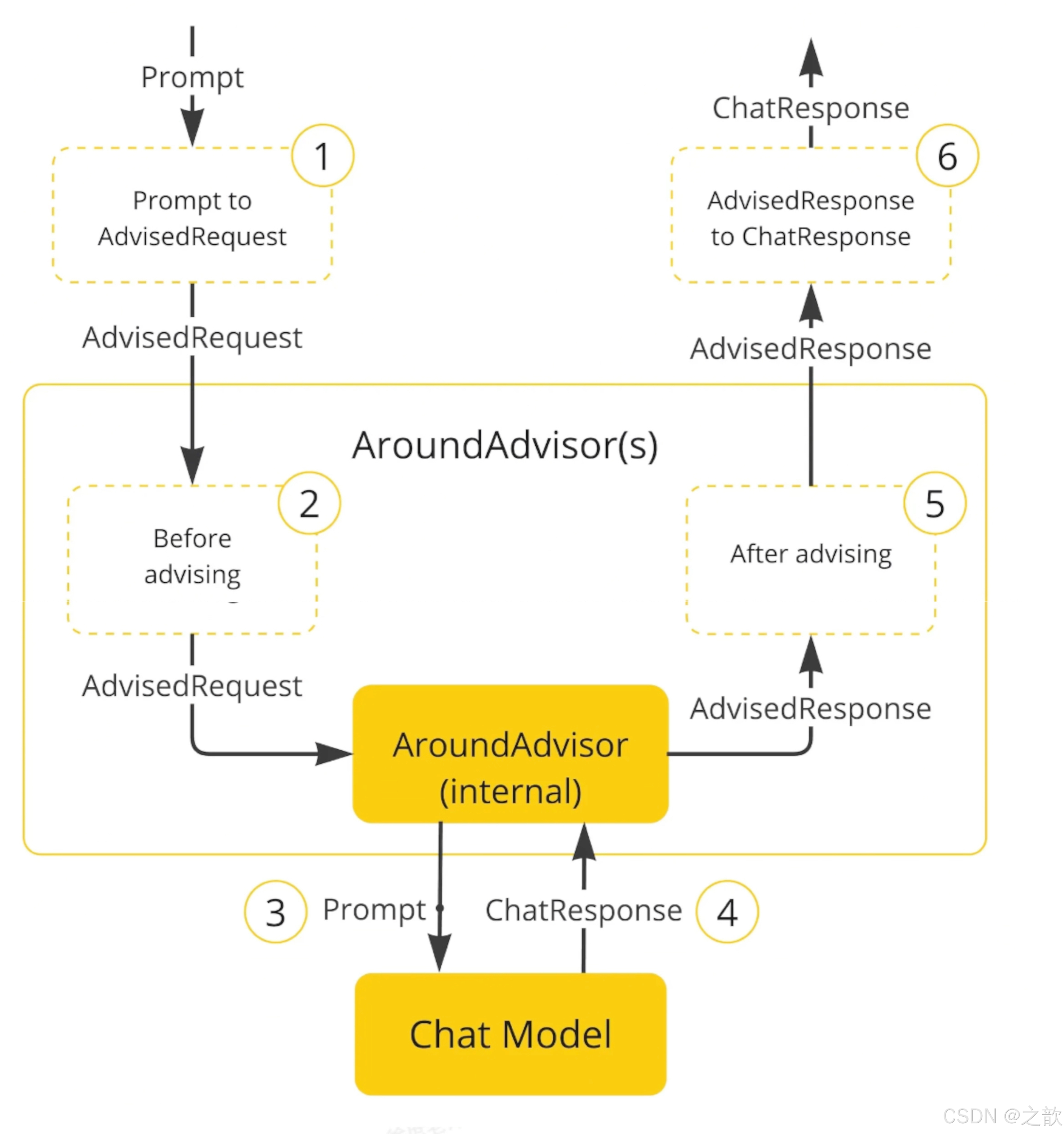
面向切面的思想对对模型对话和响应进行增强。
对话记忆
java
@Autowired
private ChatMemoryRepository chatMemoryRepository;tools
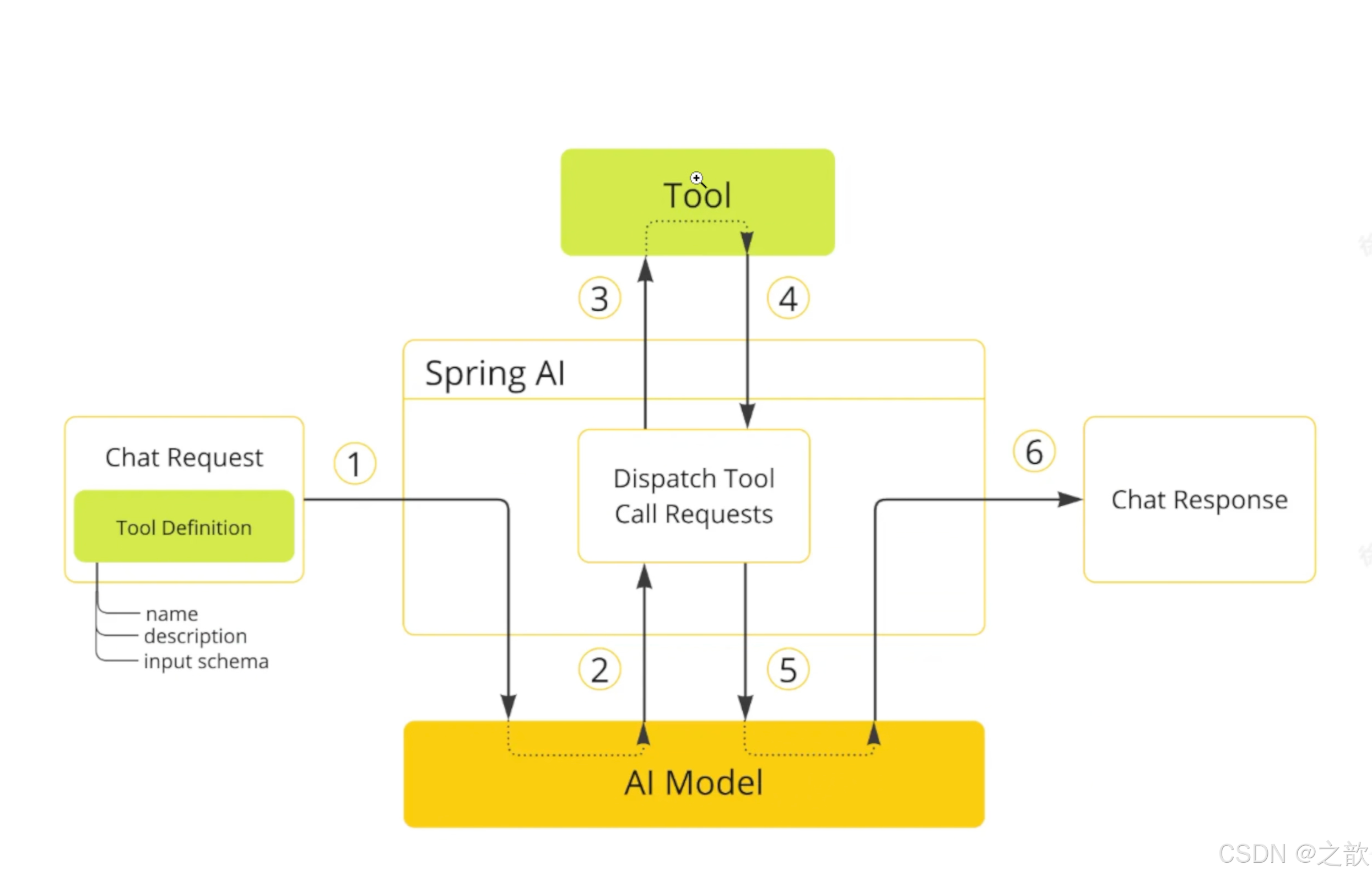
让大模型可以跟企业业务API进行互联,这一块实现起来也是非常的优雅
java
// 获取北京的天气
@Tool(description = "获取指定位置天气,根据位置自动推算经纬度")
public String getAirQuality(@ToolParam(description = "纬度") double latitude,
@ToolParam(description = "经度") double longitude) {
return "天晴";
}RAG技术下的 ETL
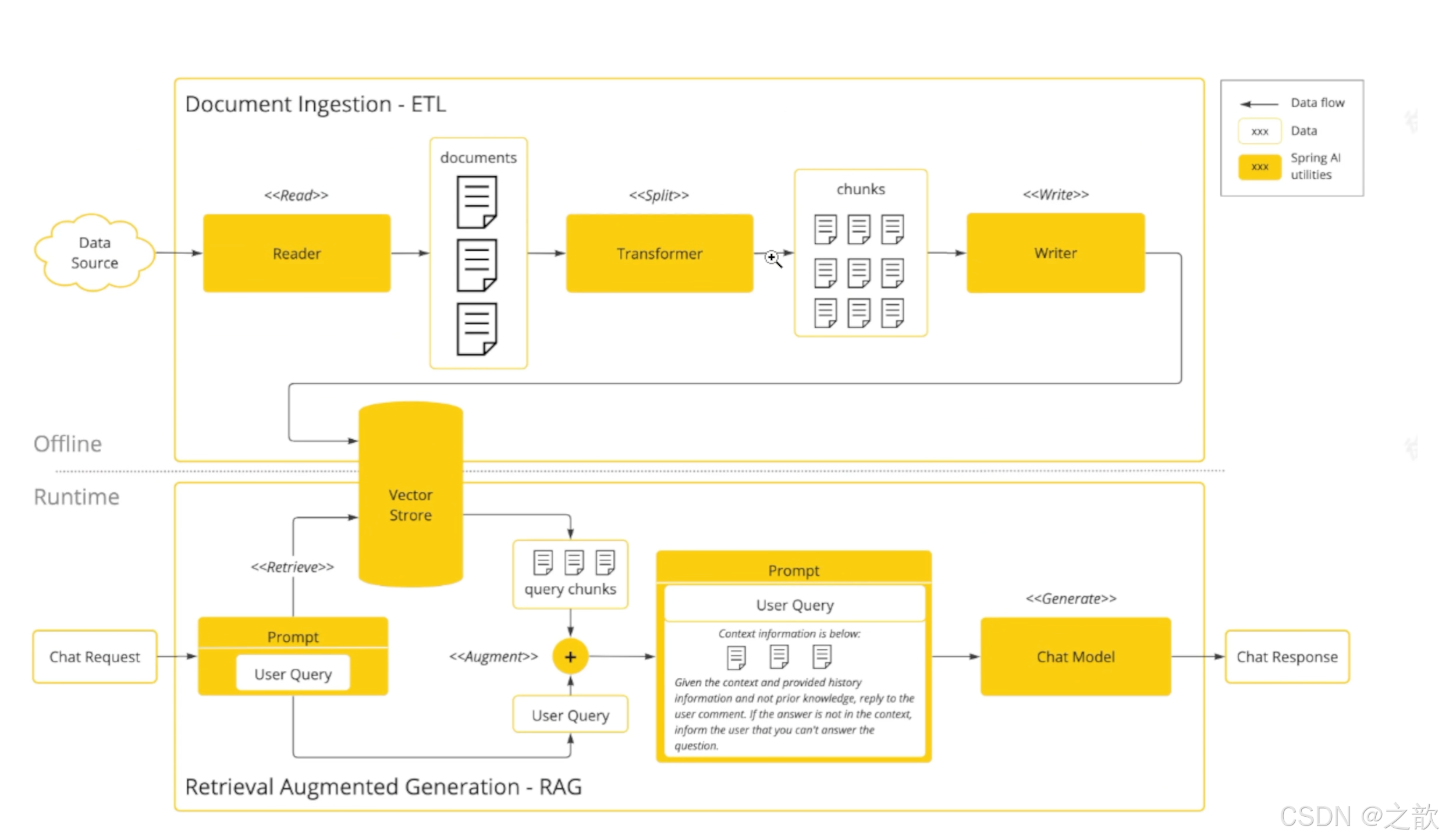
让大模型可以跟企业业务数据进行互联(包括读取文件、分隔文件、向量化)向量数据库支持目前支持 20+种向量数据库的集成这块我到时候也会详细去讲
MCP
让tools外部化,形成公共工具让外部开箱即用。原来MCP协议的JAVA SDK就是spring ai团队提供的提回供了MCP 客户端、服务端、以及MCP认证授权方案,还有目前正在孵化的Spring MCP Agent 开源项目:
-
模型的评估
- 可以测试大模型的幻觉反应(在系列课详细讲解)
-
可观察性
- 它把Al运行时的大量关键指标暴露出来,可以提供Spring Boot actuctor进行观测(在系列课详细讲解)
agent应用
springai 提供了5种agent模式的示例
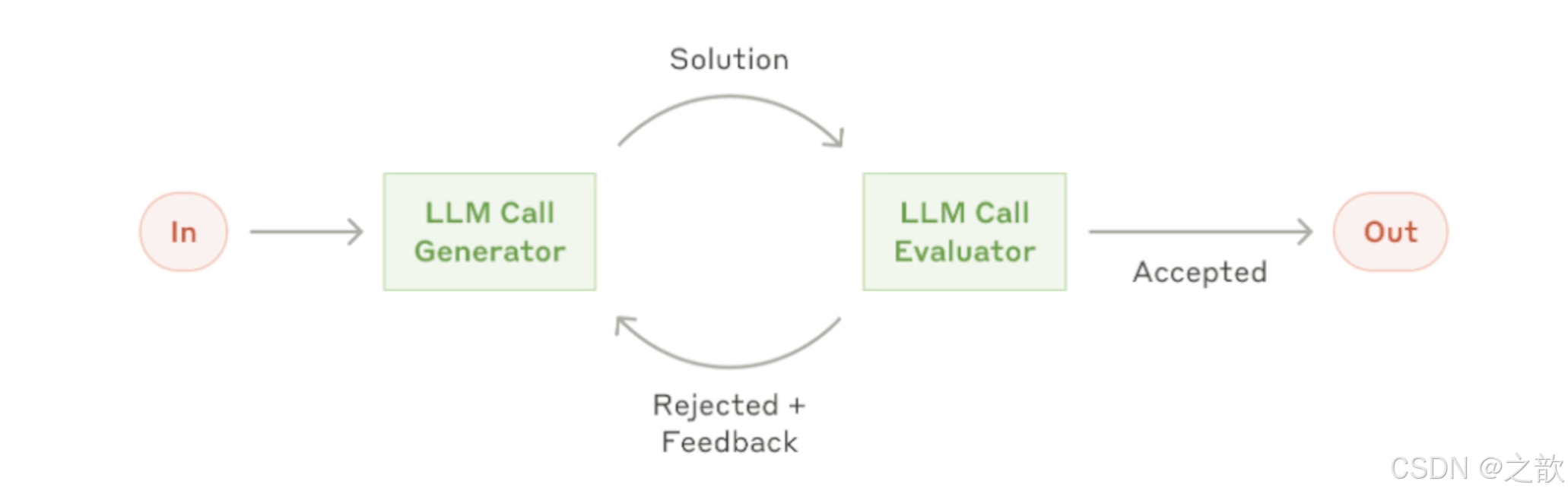
-
Routing - This pattern enables intelligent routing of inputs to specialized handlers based on classification of the user request and context.
-
Orchestrator Workers - This pattern is a flexible approach for handling complex tasks that require dynamic task decomposition and specialized processing
-
Chaining - The pattern decomposes complex tasks into a sequence of steps, where each LLM call processes the output of the previous one.
-
Parallelization - The pattern is useful for scenarios requiring parallel execution of LLM calls with automated output aggregation.
langchain4j vs springAl
| 对比项 | LangChain4j | Spring AI |
|---|---|---|
| 生态 | 不依赖Spring,需要单独集成Spring | Spring官方,和Spring无缝集成 |
| 诞生 | 更早,中国团队,受 LangChain 启发 | 稍晚,但是明显后来居上 |
| jdk | v0.35.0 前的版本支持jdk8,后支持jdk17 | 全版本jdk17 |
| 功能 | 没有mcp server,官方建议使用quarkus-mcp-server | 早期落后langchain4j,现在功能全面,并且生态活跃,开源贡献者众多 |
| 易用性 | 尚可,中文文档 | 易用,api优雅 |
| 最终 | 不需要spring选择! | 无脑选! |
大模型选型
-
自研(算法 c++ python 深度学习机器学习神经网络视觉处理),AI算法岗位
-
云端大模型不占用算力(推荐阿里的千问系列),token 计费, 功能完善成熟 。
-
开源的大模型(本地部署)购买算力
-
选型
-
自己构建选型-->评估流程
- 业务确定:(电商、医疗、教育)
- 样本准备:数据集样本选择题
- 任务定制:问答(利用多个大模型)
- 评估:人工评估
-
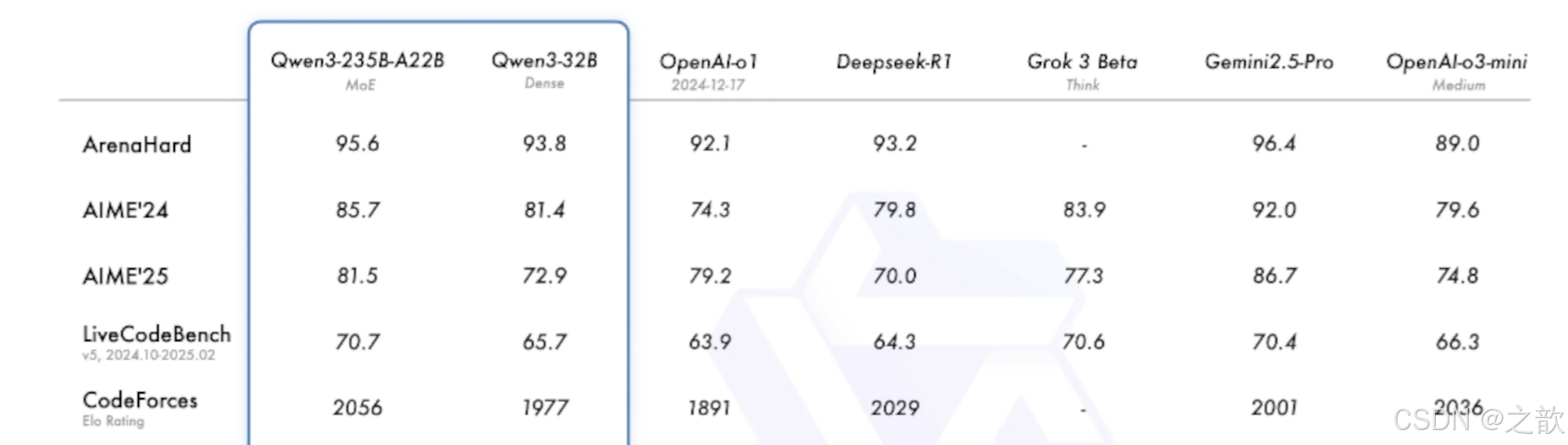
通用能力毕竟好的
- 2月份 deepseek 6710亿 671b =算力显存 H20 96G 140万;比 openai gpt4节省了40/1成本。
- 3月份阿里 qwq-32b(深度思考)32b=320亿媲美deepseek-r1 32G 比deepseek-r1 节省20/1
- 4月份阿里 qwen3(深度思考)2-3倍 itf7(qwen3-30b) 2350亿=235b 赶超了deepseek-r1 比deepseek-r1节省
- 5月 deepseek-r1-0528 6710亿 671b 性能都要要
-
对成本有要求:选择(qwen3-30b)
-
不差钱 deepseek-r1-0528 满血版本
-
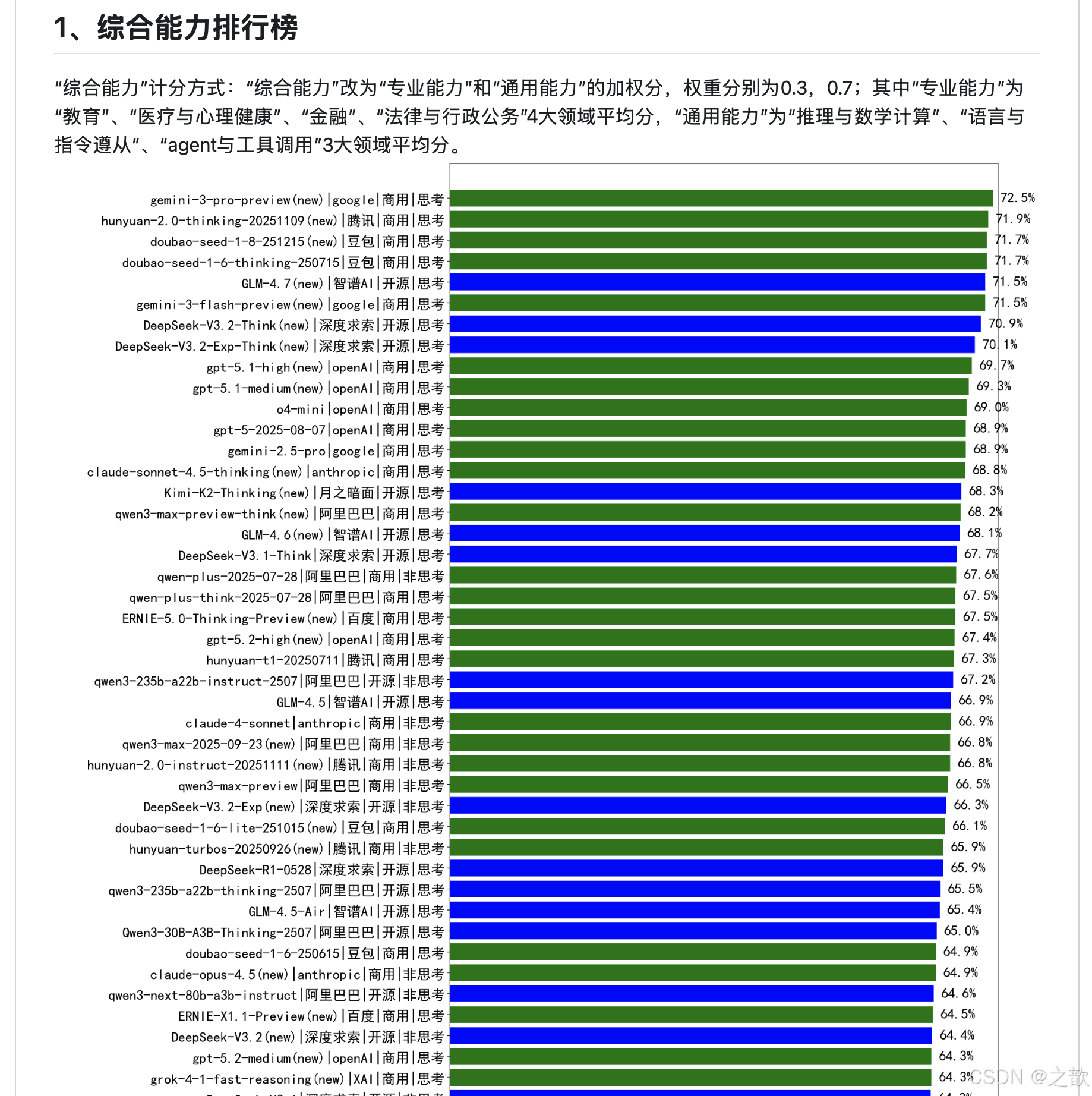
大模型的排行榜单 。
https://github.com/jeinlee1991/chinese-llm-benchmark?tab=readme-ov-file#-#M5t>
接入阿里百炼
阿里自己的团队维护spring - ai 。但是也必须依赖spring-ai 。好处是扩展度更高,坏处是必须是 spring ai先出来, spring-ai-alibaba。延迟几天出来。
如果需要接入阿里的百炼平台,就必须用该组件
使用
1.申请api-key
在调用前,您需要开通模型服务并获取API Key,再配置API Key到环境变量。
2.依赖
java
<dependencies>
<!--deepseek-->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-deepseek</artifactId>
</dependency>
<!--百炼-->
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter-dashscope</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>dashscope-sdk-java</artifactId>
<!-- 请将 'the-latest-version' 替换为最新版本号:https://mvnrepository.com/artifact/com.alibaba/dashscope-sdk-java -->
<version>2.20.6</version>
</dependency>
<!--ollama-->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-ollama</artifactId>
</dependency>
<!--web-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!--单元测试-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>配置阿里,deepseek 配置
java
spring.application.name=quick-start
#deepseek
spring.ai.deepseek.api-key= sk-xxx
spring.ai.deepseek.chat.options.model= deepseek-reasoner
# ali百炼
spring.ai.dashscope.api-key=sk-xxx
#spring.ai.dashscope.chat.options.model=
# ollama
# spring.ai.ollama.base-url=
spring.ai.ollama.chat.model= qwen3:4b
默认模型 qwen-plus
接入deepseek
申请key
https://platform.deepseek.com/api_keys
快速开始
java
package com.xushu.springai.quickstart;
import java.util.Arrays;
import org.junit.jupiter.api.Test;
import org.springframework.ai.chat.model.ChatResponse;
import org.springframework.ai.chat.prompt.Prompt;
import org.springframework.ai.deepseek.DeepSeekAssistantMessage;
import org.springframework.ai.deepseek.DeepSeekChatModel;
import org.springframework.ai.deepseek.DeepSeekChatOptions;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import reactor.core.publisher.Flux;
@SpringBootTest
public class TestDeepseek {
/**
* 测试 DeepSeekChatModel 的基本同步调用方式
*
* 该方法演示了 Spring AI 中 ChatModel 接口的 call(String) 方法的基本用法。
* call 方法接收一个字符串作为用户输入,返回 AI 模型的完整回复文本。
* 这是最简单的调用方式,适用于不需要额外配置的场景。
*
* 底层实现:DeepSeekChatModel 实现了 ChatModel 接口的 call(String) 方法,
* 内部会将字符串转换为 UserMessage,创建 Prompt,调用 call(Prompt) 方法,
* 最终返回 ChatResponse 中的文本内容。
*
* @param deepSeekChatModel 自动注入的 DeepSeekChatModel Bean,由 Spring AI 根据配置自动创建
* 配置来源:application.properties 中的 spring.ai.deepseek.* 配置项
*/
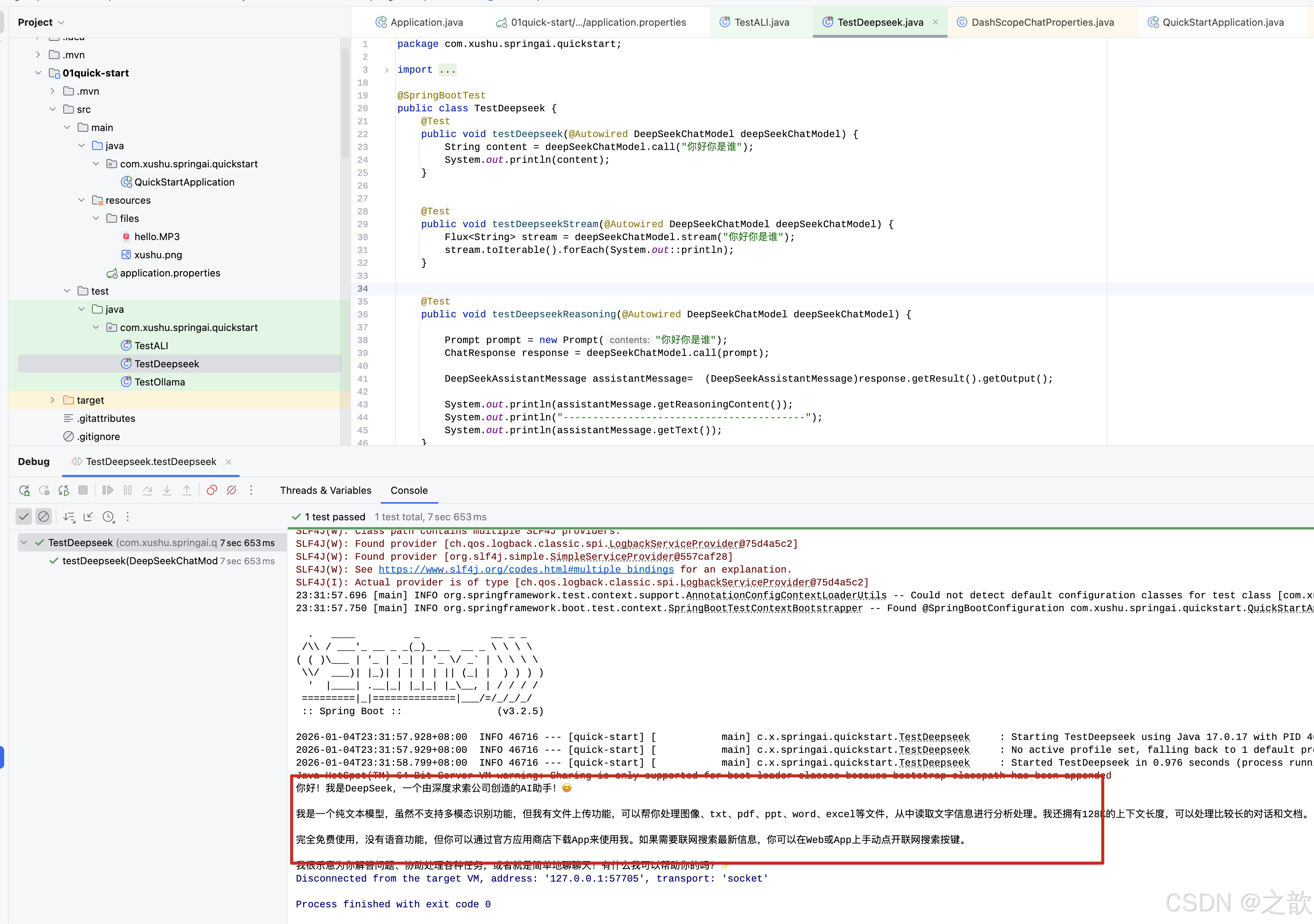
@Test
public void testDeepseek(@Autowired DeepSeekChatModel deepSeekChatModel) {
String content = deepSeekChatModel.call("你好你是谁");
System.out.println(content);
}
}
流式相应
java
package com.xushu.springai.quickstart;
import org.junit.jupiter.api.Test;
import org.springframework.ai.deepseek.DeepSeekChatModel;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import reactor.core.publisher.Flux;
@SpringBootTest
public class TestDeepseek_stream {
/**
* 测试 DeepSeekChatModel 的流式调用方式
*
* 该方法演示了 Spring AI 中 ChatModel 接口的 stream(String) 方法的用法。
* stream 方法返回一个 Flux<String>,这是响应式编程中的流式数据源。
* 与 call 方法不同,stream 方法会实时返回 AI 生成的文本片段,而不是等待完整回复。
*
* 底层实现:DeepSeekChatModel 实现了 ChatModel 接口的 stream(String) 方法,
* 内部会将字符串转换为 UserMessage,创建 Prompt,调用 stream(Prompt) 方法,
* 返回一个 Flux<ChatResponse>,然后提取每个响应中的文本片段。
*
* 使用场景:适用于需要实时显示 AI 回复的场景,如聊天界面、流式输出等。
*
* @param deepSeekChatModel 自动注入的 DeepSeekChatModel Bean
*/
@Test
public void testDeepseekStream(@Autowired DeepSeekChatModel deepSeekChatModel) {
Flux<String> stream = deepSeekChatModel.stream("你好你是谁");
stream.toIterable().forEach(System.out::println);
}
}options配置选项
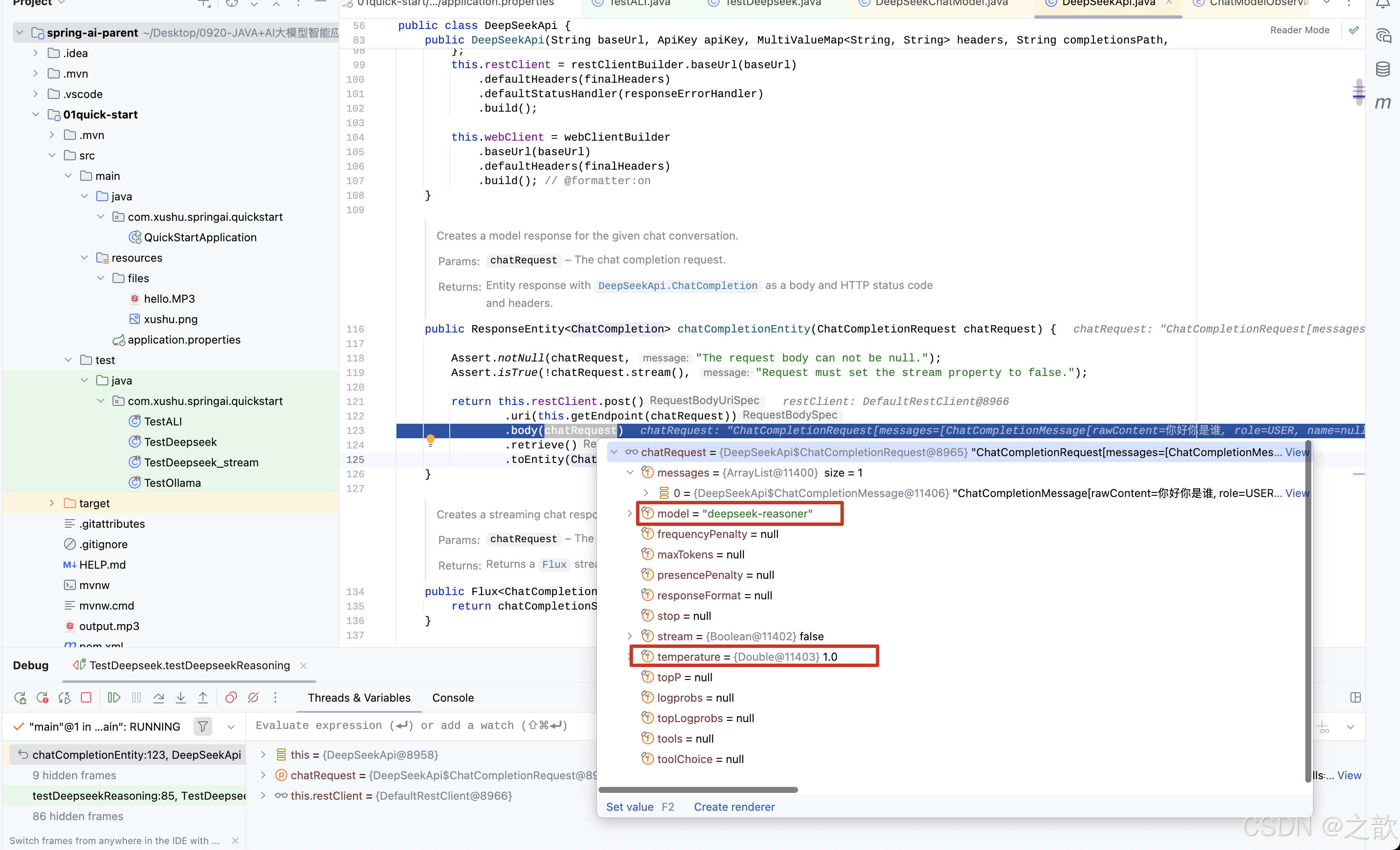
AI 模型 Temperature 参数说明
数值越高更有创造性热情热情
- 数值越低保守
- 0-2 浮点数值
- 也可以通过提示词降低他的主观臆想:
- 只引用可靠来源中的信息,不做任何假设或扩展描述。
- 请只基于已知事实回答,不要主观臆想或添加额外内容。
- 请简明、客观地给出答案,不要进行修饰或补充未经请求的信息。
概述
Temperature 参数控制 AI 模型生成文本的随机性和创造性。不同的 temperature 值适用于不同的业务场景,影响模型的输出风格。
Temperature 参数范围与业务场景对照表
| Temperature 范围 | 建议业务场景 | 输出风格 | 说明/应用举例 |
|---|---|---|---|
| 0.0 ~ 0.2 | 严谨问答、代码补全、数学解题 | 严格、确定性、标准化 | 法律/金融问答、API 响应模板、考试试卷等 |
| 0.3 ~ 0.6 | 聊天机器人、日常摘要、辅助写作 | 略有变化、相对稳定 | 公众号摘要、一般对话、邮件生成等 |
| 0.7 ~ 1.0 | 内容创作、广告文案、标题生成 | 丰富、创造性、灵活 | 诗歌创作、短文案、趣味对话、产品描述等 |
| 1.1 ~ 1.5 | 头脑风暴式、灵感碰撞场景 | 高度想象力、极富变化 | 故事创作、奇思妙想推荐、多样化内容 |
详细说明
1. Temperature: 0.0 ~ 0.2
特点:
- 输出严格、确定性高
- 适合需要准确性和一致性的场景
- 模型倾向于选择概率最高的 token
适用场景:
- ✅ 法律咨询问答
- ✅ 金融数据分析
- ✅ 代码自动补全
- ✅ 数学问题求解
- ✅ API 响应模板生成
- ✅ 考试题目生成
示例:
java
DeepSeekChatOptions options = DeepSeekChatOptions.builder()
.temperature(0.1) // 低温度,确保输出准确
.build();2. Temperature: 0.3 ~ 0.6
特点:
- 输出略有变化,但相对稳定
- 在准确性和创造性之间取得平衡
- 适合日常交互场景
适用场景:
- ✅ 智能客服聊天机器人
- ✅ 文章摘要生成
- ✅ 邮件自动生成
- ✅ 公众号内容摘要
- ✅ 一般性对话交互
示例:
java
DeepSeekChatOptions options = DeepSeekChatOptions.builder()
.temperature(0.5) // 中等温度,平衡准确性和创造性
.build();3. Temperature: 0.7 ~ 1.0
特点:
- 输出丰富、具有创造性
- 灵活多变,适合内容创作
- 在保持合理性的同时增加多样性
适用场景:
- ✅ 诗歌创作
- ✅ 广告文案撰写
- ✅ 文章标题生成
- ✅ 产品描述优化
- ✅ 趣味对话生成
- ✅ 短文案创作
示例:
java
DeepSeekChatOptions options = DeepSeekChatOptions.builder()
.temperature(0.8) // 较高温度,增强创造性
.build();4. Temperature: 1.1 ~ 1.5
特点:
- 高度想象力,极富变化
- 输出可能偏离常规,但极具创意
- 适合需要突破性思维的场景
适用场景:
- ✅ 故事创作
- ✅ 头脑风暴
- ✅ 创意灵感碰撞
- ✅ 奇思妙想推荐
- ✅ 多样化内容生成
注意事项:
⚠️ 过高的 temperature 可能导致输出不够准确或偏离主题,需要根据具体场景谨慎使用。
示例:
java
DeepSeekChatOptions options = DeepSeekChatOptions.builder()
.temperature(1.2) // 高温度,最大化创造性
.build();在 Spring AI 中的使用
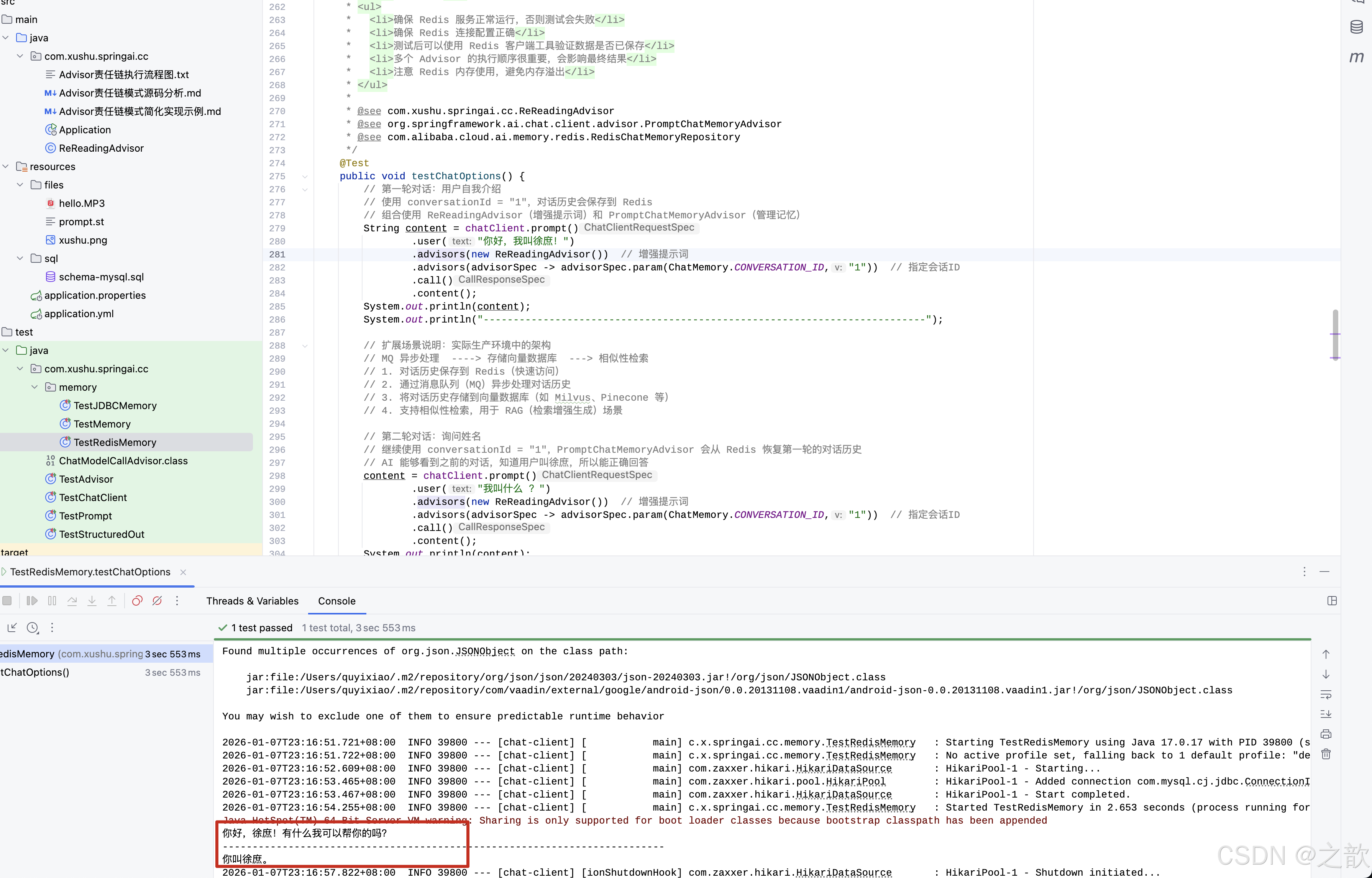
基本用法
java
@Test
public void testChatOptions(@Autowired DeepSeekChatModel chatModel) {
// 创建配置选项
DeepSeekChatOptions options = DeepSeekChatOptions.builder()
.model("deepseek-chat")
.temperature(0.8) // 设置 temperature 参数
.build();
// 创建 Prompt 并传入选项
Prompt prompt = new Prompt("请写一句五言绝句诗描述清晨的景色。", options);
// 调用模型
ChatResponse res = chatModel.call(prompt);
System.out.println(res.getResult().getOutput().getText());
}不同场景的配置建议
java
// 场景1:严谨问答(低温度)
DeepSeekChatOptions strictOptions = DeepSeekChatOptions.builder()
.temperature(0.1)
.build();
// 场景2:日常对话(中温度)
DeepSeekChatOptions chatOptions = DeepSeekChatOptions.builder()
.temperature(0.5)
.build();
// 场景3:内容创作(高温度)
DeepSeekChatOptions creativeOptions = DeepSeekChatOptions.builder()
.temperature(0.9)
.build();
// 场景4:头脑风暴(极高温度)
DeepSeekChatOptions brainstormingOptions = DeepSeekChatOptions.builder()
.temperature(1.3)
.build();选择建议
- 需要准确性 → 选择 0.0 ~ 0.2
- 需要平衡 → 选择 0.3 ~ 0.6
- 需要创造性 → 选择 0.7 ~ 1.0
- 需要突破性思维 → 选择 1.1 ~ 1.5
注意事项
- ⚠️ Temperature 值过高可能导致输出不稳定或偏离主题
- ⚠️ Temperature 值过低可能导致输出过于机械和重复
- 💡 建议根据实际业务需求进行调优,找到最佳平衡点
- 💡 不同模型对 temperature 的敏感度可能不同,需要实际测试
maxTokens
- 默认
- maxTokens:限制AI模型生成的最人token数(近似理解为字数上限)。
- 需要简洁回复、打分、列表、短摘要等,建议小值(如10~50)。
- 防止用户跑长对话导致无关内容或花费过多token费用。
- 如果遇到生成内容经常被截断,可以适当配置更大maxTokens。
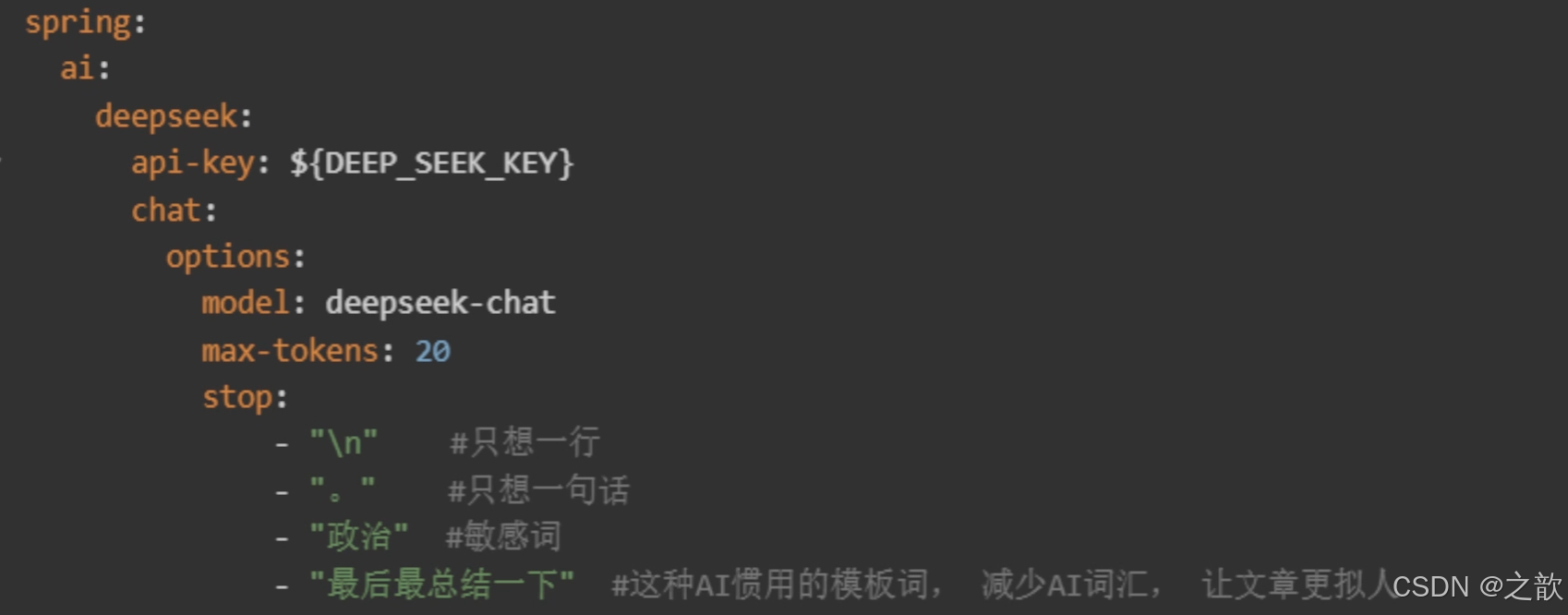
stop
- 停止词列表,当生成的内容包含这些词时,停止生成
- 截断你不想输出的内容比如:
java
/**
* 测试 DeepSeekChatOptions 配置选项的使用
*
* 该方法演示了如何使用 DeepSeekChatOptions 来配置模型的各种参数。
* DeepSeekChatOptions 是 DeepSeek 特有的配置类,继承自 ChatOptions,
* 提供了 DeepSeek API 特有的配置选项。
*
* 配置参数说明:
* - model(String):指定使用的模型名称,如 "deepseek-chat" 或 "deepseek-reasoner"
* - maxTokens(Integer):限制生成的最大 token 数量(注释掉的代码)
* - stop(List<String>):停止词列表,当生成的内容包含这些词时,停止生成
* - temperature(Double):控制生成的随机性,范围通常为 0.0-2.0
* 值越高,输出越随机和创造性;值越低,输出越确定和保守
*
* 底层实现:
* - DeepSeekChatOptions.builder() 使用建造者模式创建配置对象
* - Prompt 构造函数可以接收 ChatOptions 作为第二个参数
* - 这些选项会被传递给 DeepSeek API,影响模型的生成行为
*
* 使用场景:适用于需要精确控制模型生成行为的场景,如内容创作、代码生成等。
*
* @param chatModel 自动注入的 DeepSeekChatModel Bean
*/
@Test
public void testChatOptions(@Autowired
DeepSeekChatModel chatModel) {
DeepSeekChatOptions options = DeepSeekChatOptions.builder()
.model("deepseek-chat")
//.maxTokens(5) // 字数
.stop(Arrays.asList(","))
.temperature(2.0).build();
Prompt prompt = new Prompt("请写一句诗描述清晨。", options);
ChatResponse res = chatModel.call(prompt);
System.out.println(res.getResult().getOutput().getText());
}流式输出
java
/**
* 测试 DeepSeekChatModel 的流式调用方式
*
* 该方法演示了 Spring AI 中 ChatModel 接口的 stream(String) 方法的用法。
* stream 方法返回一个 Flux<String>,这是响应式编程中的流式数据源。
* 与 call 方法不同,stream 方法会实时返回 AI 生成的文本片段,而不是等待完整回复。
*
* 底层实现:DeepSeekChatModel 实现了 ChatModel 接口的 stream(String) 方法,
* 内部会将字符串转换为 UserMessage,创建 Prompt,调用 stream(Prompt) 方法,
* 返回一个 Flux<ChatResponse>,然后提取每个响应中的文本片段。
*
* 使用场景:适用于需要实时显示 AI 回复的场景,如聊天界面、流式输出等。
*
* @param deepSeekChatModel 自动注入的 DeepSeekChatModel Bean
*/
@Test
public void testDeepseekStream(@Autowired DeepSeekChatModel deepSeekChatModel) {
Flux<String> stream = deepSeekChatModel.stream("你好你是谁");
stream.toIterable().forEach(System.out::println);
}获取模型思维链的过程
java
/**
* 测试 DeepSeek 推理模型的推理过程获取
*
* 该方法演示了如何使用 DeepSeek 的推理模型(deepseek-reasoner)获取推理过程。
* DeepSeek 推理模型会提供两个部分的内容:
* 1. reasoningContent:模型的内部推理过程(思考过程)
* 2. text:模型的最终回复文本
*
* 底层实现:
* - 使用 Prompt 对象包装用户输入,可以传入额外的 ChatOptions
* - call(Prompt) 方法返回 ChatResponse,包含完整的响应信息
* - ChatResponse.getResult().getOutput() 返回 AssistantMessage
* - DeepSeekAssistantMessage 是 DeepSeek 特有的消息类型,扩展了标准 AssistantMessage
* - getReasoningContent() 返回推理过程文本(仅推理模型支持)
* - getText() 返回最终回复文本
*
* 注意:只有使用 deepseek-reasoner 模型时,getReasoningContent() 才会有内容。
* 使用 deepseek-chat 模型时,该方法可能返回 null 或空字符串。
*
* @param deepSeekChatModel 自动注入的 DeepSeekChatModel Bean,需配置为 deepseek-reasoner 模型
*/
@Test
public void testDeepseekReasoning(@Autowired DeepSeekChatModel deepSeekChatModel) {
Prompt prompt = new Prompt("你好你是谁");
ChatResponse response = deepSeekChatModel.call(prompt);
DeepSeekAssistantMessage assistantMessage= (DeepSeekAssistantMessage)response.getResult().getOutput();
System.out.println(assistantMessage.getReasoningContent());
System.out.println("-----------------------------------------");
System.out.println(assistantMessage.getText());
}以流式返回
java
/**
* 测试 DeepSeek 推理模型的流式推理过程获取
*
* 该方法演示了如何以流式方式获取 DeepSeek 推理模型的推理过程和最终回复。
* 与 testDeepseekReasoning 不同,该方法使用 stream 方法,可以实时获取推理过程的片段。
*
* 底层实现:
* - stream(Prompt) 方法返回 Flux<ChatResponse>,每个 ChatResponse 代表一个响应片段
* - 每个 ChatResponse 都包含一个 DeepSeekAssistantMessage
* - 在流式输出中,推理内容和最终文本会分阶段返回
* - 第一次遍历获取所有推理过程的片段
* - 第二次遍历获取所有最终回复的片段
*
* 注意:代码中存在一个潜在问题,stream.toIterable() 会消费 Flux,第二次调用时
* Flux 已经被消费完毕,可能无法再次获取数据。正确的做法应该是只遍历一次,
* 在遍历过程中同时处理推理内容和最终文本。
*
* 使用场景:适用于需要实时显示推理过程和最终回复的场景,如调试、教学演示等。
*
* @param deepSeekChatModel 自动注入的 DeepSeekChatModel Bean,需配置为 deepseek-reasoner 模型
*/
@Test
public void testDeepseekStreamReasoning(@Autowired DeepSeekChatModel deepSeekChatModel) {
Flux<ChatResponse> stream = deepSeekChatModel.stream(new Prompt("你好你是谁"));
stream.toIterable().forEach(chatResponse -> {
DeepSeekAssistantMessage assistantMessage= (DeepSeekAssistantMessage)chatResponse.getResult().getOutput();
System.out.println(assistantMessage.getReasoningContent());
});
System.out.println("-----------------------------------------");
stream.toIterable().forEach(chatResponse -> {
DeepSeekAssistantMessage assistantMessage= (DeepSeekAssistantMessage)chatResponse.getResult().getOutput();
System.out.println(assistantMessage.getText());
});
}输出:

deepseek请求原理
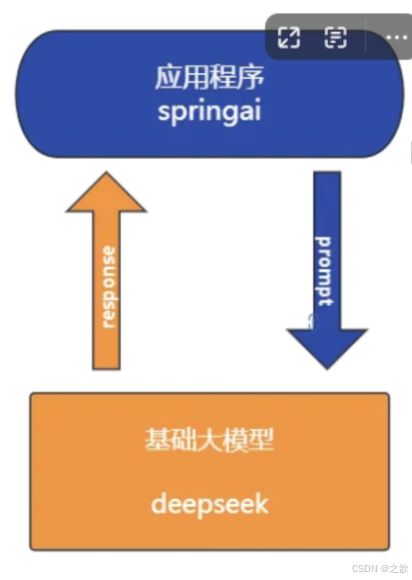
底层还是通过http的方式访问大模型 。
接入AlibabaAi阿里百炼
阿里自己的团队维护spring-ai-alibaba。 但是也必须依赖spring-ai。 好处是扩展度更高,坏处是必须是 springai先出来,spring-ai-alibaba。延迟几天出来。
-
添加pom.xml
java
<!--百炼-->
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter-dashscope</artifactId>
</dependency>- 配置application.properties
java
# ali百炼
spring.ai.dashscope.api-key=sk-xxx # 百炼申请的key
#spring.ai.dashscope.chat.options.model=1. 文本生成图片
java
/**
* 测试文本生成图片(Text-to-Image)功能
*
* 功能说明:
* - 使用阿里云通义万相(Wanx)模型将文本描述转换为图片
* - 支持通过文本提示词生成对应的图片,返回图片的 URL 或 Base64 编码
*
* 实现逻辑:
* 1. 构建 DashScopeImageOptions 配置对象,指定使用的图片生成模型(wanx2.1-t2i-turbo)
* - withN(): 可设置生成图片的数量(注释掉表示使用默认值)
* - withWidth()/withHeight(): 可设置图片的宽度和高度(注释掉表示使用默认值)
* 2. 创建 ImagePrompt 对象,包含文本提示词和配置选项
* 3. 调用 imageModel.call() 方法,将提示词发送到 DashScope API 进行图片生成
* 4. 从响应中获取生成的图片 URL(存储在 OSS 上)
* 5. 也可以通过 getB64Json() 获取 Base64 编码的图片数据(适用于小图片)
*
* 使用场景:
* - 根据文本描述生成图片
* - 图片 URL 可用于直接展示或下载
* - Base64 编码适用于需要内嵌图片的场景
*
* @param imageModel 阿里云 DashScope 图片生成模型,由 Spring 容器自动注入
*/
@Test
public void text2Img(
@Autowired DashScopeImageModel imageModel) {
DashScopeImageOptions imageOptions = DashScopeImageOptions.builder()
//.withN()
//.withWidth()
//.withHeight()
.withModel("wanx2.1-t2i-turbo").build();
ImageResponse imageResponse = imageModel.call(
new ImagePrompt("程序员徐庶", imageOptions));
String imageUrl = imageResponse.getResult().getOutput().getUrl();
// 图片url
System.out.println(imageUrl);
// 图片base64
// imageResponse.getResult().getOutput().getB64Json();
/*
按文件流相应
InputStream in = url.openStream();
response.setHeader("Content-Type", MediaType.IMAGE_PNG_VALUE);
response.getOutputStream().write(in.readAllBytes());
response.getOutputStream().flush();*/
}生成的图

2. 文本转语音
java
/**
* 测试文本转语音(Text-to-Speech, TTS)功能
*
* 功能说明:
* - 使用阿里云 CosyVoice 模型将文本转换为自然流畅的语音
* - 支持多种音色选择,可配置语速、响应格式等参数
* - 生成的音频数据以 ByteBuffer 形式返回,可保存为音频文件
*
* 实现逻辑:
* 1. 构建 DashScopeSpeechSynthesisOptions 配置对象:
* - voice("longyingtian"): 指定音色,longyingtian 是其中一个可选音色
* - speed(): 可设置语速(注释掉表示使用默认语速)
* - model("cosyvoice-v2"): 指定使用的语音合成模型
* - responseFormat(): 可设置响应格式,如 MP3(注释掉表示使用默认格式)
* 2. 创建 SpeechSynthesisPrompt 对象,包含要转换的文本和配置选项
* 3. 调用 speechSynthesisModel.call() 方法,将文本发送到 DashScope API 进行语音合成
* 4. 从响应中获取音频数据(ByteBuffer 格式)
* 5. 将音频数据写入文件系统,保存为 MP3 文件
*
* 使用场景:
* - 语音播报、语音助手
* - 有声读物生成
* - 多语言语音合成
*
* 参考文档:
* https://bailian.console.aliyun.com/?spm=5176.29619931.J__Z58Z6CX7MY__Ll8p1ZOR.1.74cd59fcXOTaDL&tab=doc#/doc/?type=model&url=https%3A%2F%2Fhelp.aliyun.com%2Fdocument_detail%2F2842586.html&renderType=iframe
*
* @param speechSynthesisModel 阿里云 DashScope 语音合成模型,由 Spring 容器自动注入
* @throws IOException 当文件写入失败时抛出
*/
// https://bailian.console.aliyun.com/?spm=5176.29619931.J__Z58Z6CX7MY__Ll8p1ZOR.1.74cd59fcXOTaDL&tab=doc#/doc/?type=model&url=https%3A%2F%2Fhelp.aliyun.com%2Fdocument_detail%2F2842586.html&renderType=iframe
@Test
public void testText2Audio(@Autowired DashScopeSpeechSynthesisModel speechSynthesisModel) throws IOException {
DashScopeSpeechSynthesisOptions options = DashScopeSpeechSynthesisOptions.builder()
.voice("longyingtian") // 人声
//.speed() // 语速
.model("cosyvoice-v2") // 模型
//.responseFormat(DashScopeSpeechSynthesisApi.ResponseFormat.MP3)
.build();
SpeechSynthesisResponse response = speechSynthesisModel.call(
new SpeechSynthesisPrompt("大家好, 我是人帅活好的徐庶。",options)
);
File file = new File( System.getProperty("user.dir") + "/output.mp3");
try (FileOutputStream fos = new FileOutputStream(file)) {
ByteBuffer byteBuffer = response.getResult().getOutput().getAudio();
fos.write(byteBuffer.array());
}
catch (IOException e) {
throw new IOException(e.getMessage());
}
}3. 语音转文本
java
/**
* 测试语音转文本(Speech-to-Text, STT)功能
*
* 功能说明:
* - 使用阿里云 Paraformer 模型将音频文件转换为文本
* - 支持多种音频格式(WAV、MP3、FLAC 等)
* - 可以从 URL 资源或本地文件读取音频进行转写
*
* 实现逻辑:
* 1. 构建 DashScopeAudioTranscriptionOptions 配置对象:
* - withModel(): 可指定使用的语音识别模型(注释掉表示使用默认模型)
* 2. 创建 AudioTranscriptionPrompt 对象:
* - 使用 UrlResource 从 URL 加载音频资源(也可以使用 ClassPathResource 加载本地资源)
* - 传入配置选项
* 3. 调用 transcriptionModel.call() 方法,将音频发送到 DashScope API 进行语音识别
* 4. 从响应中获取识别出的文本内容并输出
*
* 使用场景:
* - 会议录音转文字
* - 语音助手识别用户指令
* - 音频内容索引和搜索
* - 多语言语音识别
*
* @param transcriptionModel 阿里云 DashScope 音频转文本模型,由 Spring 容器自动注入
* @throws MalformedURLException 当音频 URL 格式错误时抛出
*/
@Test
public void testAudio2Text(
@Autowired
DashScopeAudioTranscriptionModel transcriptionModel
) throws MalformedURLException {
DashScopeAudioTranscriptionOptions transcriptionOptions = DashScopeAudioTranscriptionOptions.builder()
//.withModel() 模型
.build();
AudioTranscriptionPrompt prompt = new AudioTranscriptionPrompt(
new UrlResource(AUDIO_RESOURCES_URL),
transcriptionOptions
);
AudioTranscriptionResponse response = transcriptionModel.call(
prompt
);
System.out.println(response.getResult().getOutput());
}4. 图片理解
java
/**
* 测试多模态(图片理解)功能
*
* 功能说明:
* - 使用通义千问视觉模型(Qwen-VL)实现图片理解能力
* - 支持图片识别、图片内容描述、图片问答等场景
* - 模型可以同时理解文本和图片内容,进行多模态交互
*
* 实现逻辑:
* 1. 从类路径加载图片资源(ClassPathResource)
* 2. 创建 Media 对象,指定媒体类型为图片(IMAGE_JPEG)和资源文件
* 3. 构建 DashScopeChatOptions 配置:
* - withMultiModel(true): 启用多模态能力,允许模型处理图片和文本
* - withModel("qwen-vl-max-latest"): 指定使用通义千问视觉模型的最新版本
* 4. 构建 Prompt 对象:
* - 使用 UserMessage.builder() 创建用户消息
* - media(media): 添加图片媒体内容
* - text("识别图片"): 添加文本指令,告诉模型要对图片做什么操作
* 5. 调用 dashScopeChatModel.call() 方法,将图片和文本一起发送到 DashScope API
* 6. 从响应中获取模型对图片的理解结果(文本描述)
*
* 使用场景:
* - 图片内容识别和描述
* - 图片问答(如"图片中有什么?"、"图片中的人在做什么?")
* - OCR 文字识别
* - 图片内容分析
*
* 支持的媒体格式:
* 音频:flac、mp3、mp4、mpeg、mpga、m4a、ogg、wav 或 webm
* 图片:jpg、png、gif 等常见图片格式
*
* @param dashScopeChatModel 阿里云 DashScope 聊天模型,由 Spring 容器自动注入
* @throws MalformedURLException 当资源 URL 格式错误时抛出
*/
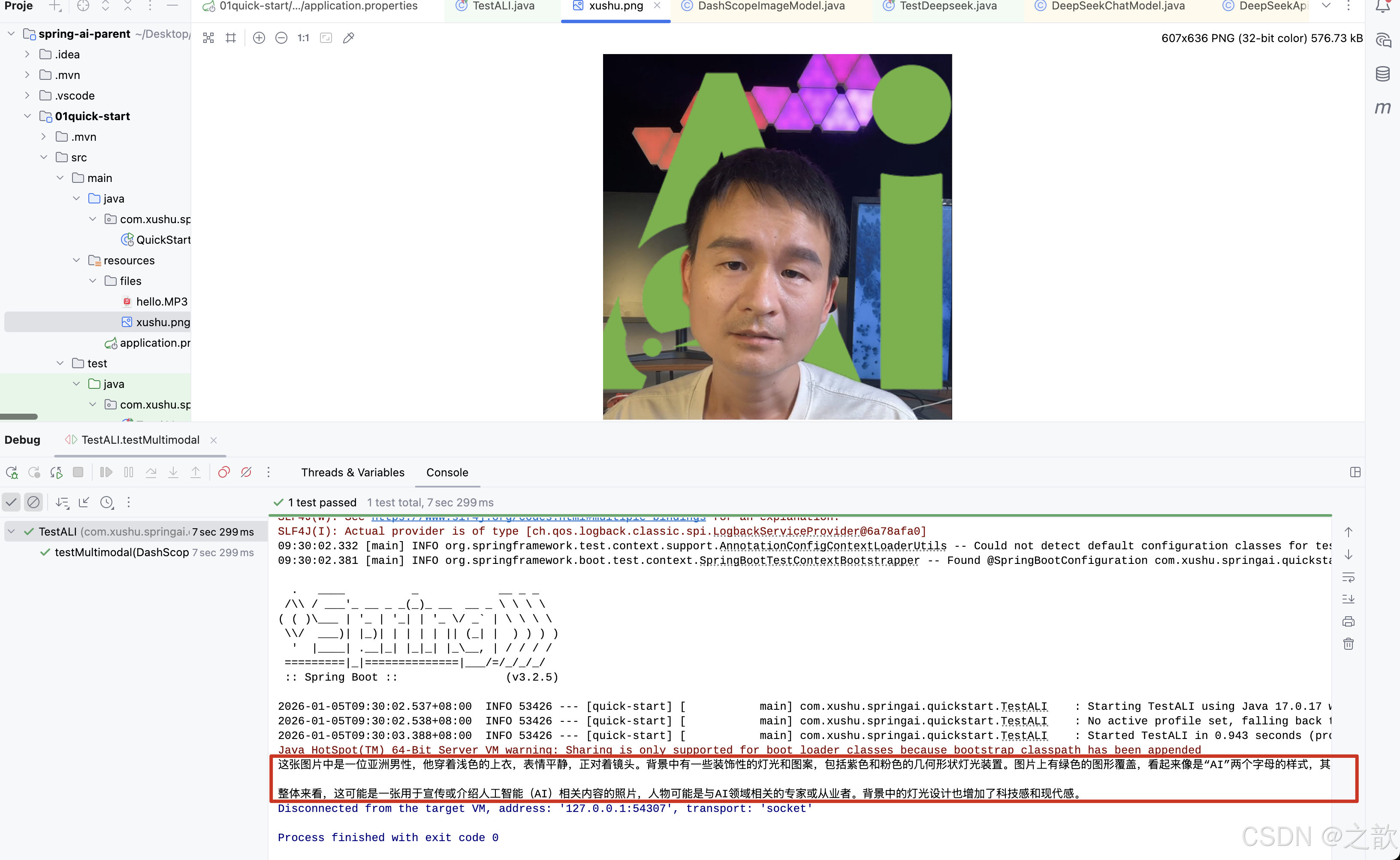
@Test
public void testMultimodal(@Autowired DashScopeChatModel dashScopeChatModel
) throws MalformedURLException {
// flac、mp3、mp4、mpeg、mpga、m4a、ogg、wav 或 webm。
var audioFile = new ClassPathResource("/files/xushu.png");
Media media = new Media(MimeTypeUtils.IMAGE_JPEG, audioFile);
DashScopeChatOptions options = DashScopeChatOptions.builder()
.withMultiModel(true)
.withModel("qwen-vl-max-latest").build();
Prompt prompt= Prompt.builder().chatOptions(options)
.messages(UserMessage.builder().media(media)
.text("识别图片").build())
.build();
ChatResponse response = dashScopeChatModel.call(prompt);
System.out.println(response.getResult().getOutput().getText());
}图片 :

结果输出 :
5. 文本生成视频
java
/**
* 测试文本生成视频(Text-to-Video)功能
*
* 功能说明:
* - 使用阿里云通义万相(Wanx)视频生成模型将文本描述转换为视频
* - 支持根据文本提示词生成对应的视频内容
* - 视频生成是异步过程,需要等待处理完成后获取视频 URL
*
* 实现逻辑:
* 1. 创建 VideoSynthesis 对象,用于调用视频生成 API
* 2. 构建 VideoSynthesisParam 参数对象:
* - model("wanx2.1-t2v-turbo"): 指定使用的视频生成模型(turbo 版本,速度较快)
* - prompt("一只小猫在月光下奔跑"): 文本提示词,描述要生成的视频内容
* - size("1280*720"): 设置视频分辨率(宽*高),支持多种分辨率选项
* - apiKey(): 从环境变量获取 API Key(注意:这里直接使用环境变量,不是通过 Spring 注入)
* 3. 调用 vs.call() 方法,将参数发送到 DashScope API 进行视频生成
* - 视频生成是异步任务,可能需要较长时间
* - 方法会等待生成完成后返回结果
* 4. 从响应中获取生成的视频 URL(存储在 OSS 上)
*
* 注意事项:
* - 视频生成是耗时操作,可能需要等待较长时间
* - API Key 需要从环境变量 ALI_AI_KEY 中获取
* - 生成的视频 URL 有时效性,需要及时下载或使用
*
* 使用场景:
* - 根据文本描述生成短视频
* - 视频内容创作
* - 营销视频自动生成
*
* @throws ApiException 当 API 调用失败时抛出
* @throws NoApiKeyException 当未提供 API Key 时抛出
* @throws InputRequiredException 当必需参数缺失时抛出
*/
@Test
public void text2Video() throws ApiException, NoApiKeyException, InputRequiredException {
VideoSynthesis vs = new VideoSynthesis();
VideoSynthesisParam param =
VideoSynthesisParam.builder()
.model("wanx2.1-t2v-turbo")
.prompt("一只小猫在月光下奔跑")
.size("1280*720")
.apiKey(TestApiKey.ALI_AI_KEY)
.build();
System.out.println("please wait...");
VideoSynthesisResult result = vs.call(param);
System.out.println(result.getOutput().getVideoUrl());
}生成的视频

Ollama接入
购买机器
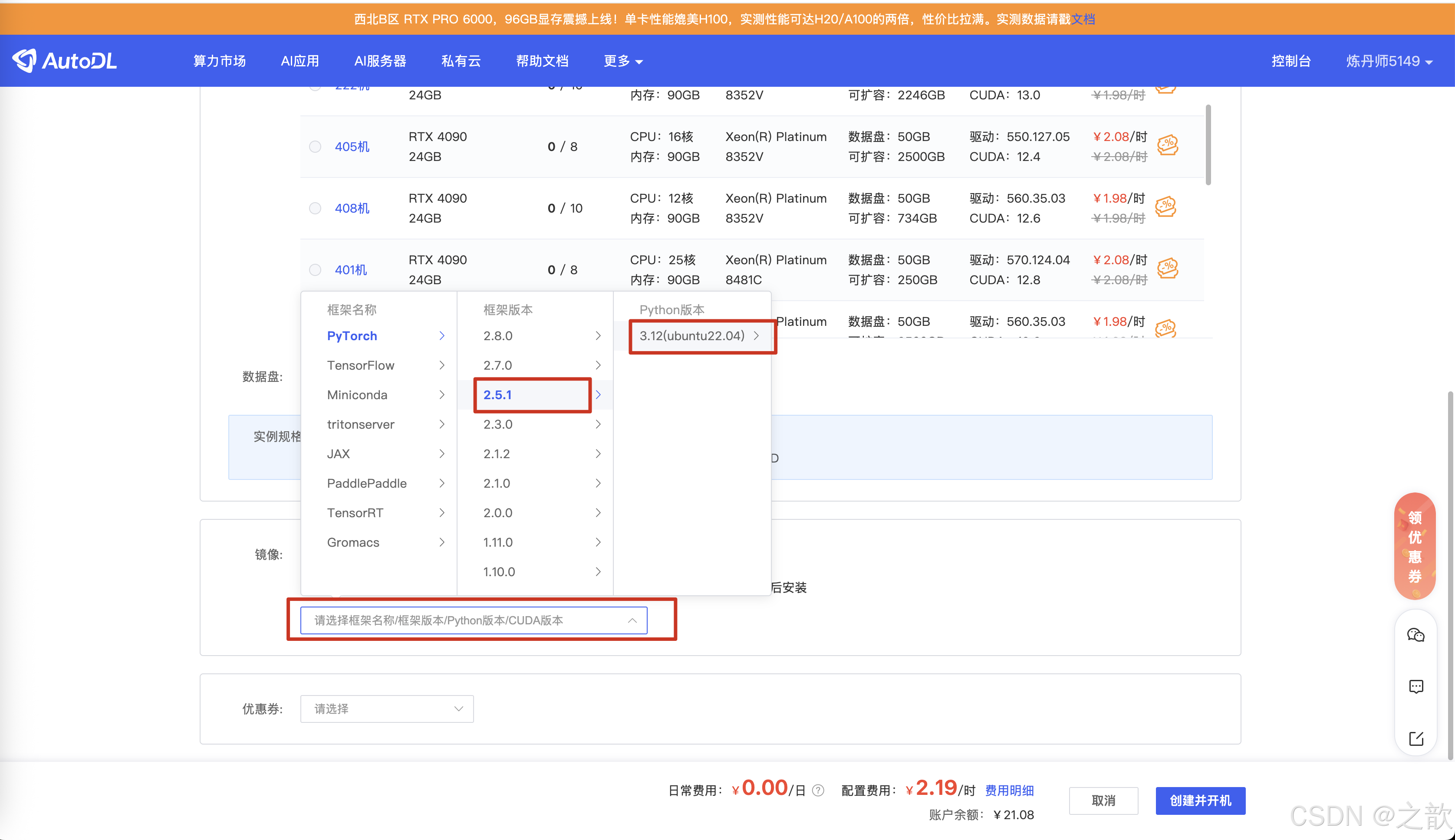
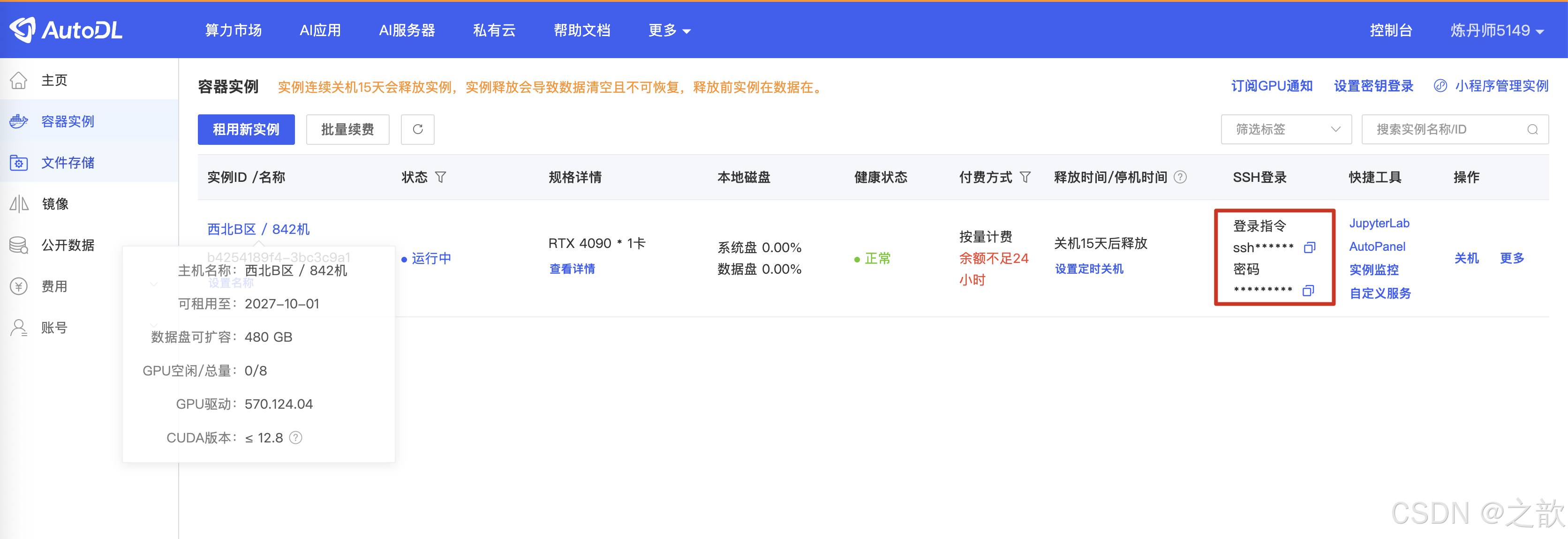
创建并开机
复制登录信息在vscode 中登录
Ollama部署大模型

Ollama 是针对个人的, 比较好用, 企业级一般不使用。
https://ollama.com/download/linux
可以看另外一篇博客 https://blog.csdn.net/quyixiao/article/details/149789888?spm=1011.2415.3001.5331
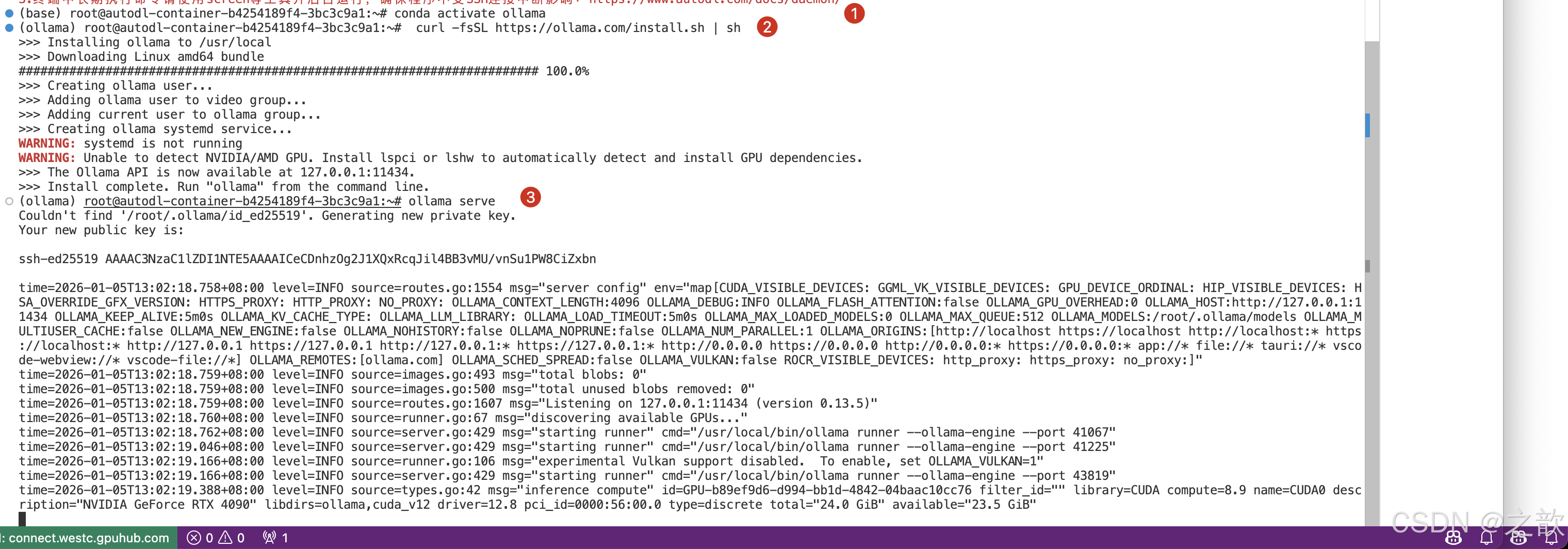
autodl 安装ollama环境
创建一个虚拟环境
conda create -n ollama
激活ollama1环境
conda activate ollama
安装ollama1
curl -fsSL https://ollama.com/install.sh | sh
启动ollama
ollama serve
查找大模型
进入到这个链接
https://ollama.com/library/qwen3:4b
打开另外一个终端窗口
运行# ollama run qwen3:4b

ollama 只能运行gguf的格式的大模型 , 是量化之后的模型,只针对个人用户,简单,快速 。 模型是阉割之后的大模型 。启动之后,就可以进行聊天了。
mac 安装ollama环境
https://ollama.com/download/mac 下载 ollama
下载下来之后直接双击安装
手动下载安装
访问官网:https://ollama.com/download
下载 macOS 版本(.dmg 文件)
双击安装包进行安装

安装后使用
启动 Ollama 服务
启动 Ollama(如果通过 Homebrew 安装,可能需要手动启动)
ollama serve
ollama run qwen3:4b

注意事项
- 系统要求:
- macOS 10.13 或更高版本
- Apple Silicon (M1/M2/M3) 或 Intel 芯片
- 端口:
- 默认端口:11434
- 确保端口未被占用
- 首次运行:
- 首次运行模型时会自动下载,可能需要一些时间
- 内存:
- 模型会占用内存,建议至少 8GB RAM
1. 配置pom
java
<!--ollama-->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-ollama</artifactId>
</dependency>2. 配置application.properties
java
# Ollama 配置
spring.ai.ollama.base-url=http://localhost:11434
spring.ai.ollama.chat.model=qwen3:4b3.1跳过推理过程,直接返回结果
java
/**
* 测试 OllamaChatModel 的基本同步调用方式
*
* 该方法演示了 Spring AI 中 OllamaChatModel 的 call(String) 方法的基本用法。
* call 方法接收一个字符串作为用户输入,返回 AI 模型的完整回复文本。
* 这是最简单的调用方式,适用于不需要额外配置的场景。
*
* 底层实现:OllamaChatModel 实现了 ChatModel 接口的 call(String) 方法,
* 内部会将字符串转换为 UserMessage,创建 Prompt,调用 call(Prompt) 方法,
* 最终返回 ChatResponse 中的文本内容。
*
* 注意:消息中的 "/no_think" 后缀是某些模型(如推理模型)的特殊指令,
* 用于跳过推理过程,直接返回结果。Ollama 会根据模型类型处理该指令。
*
* @param ollamaChatModel 自动注入的 OllamaChatModel Bean,由 Spring AI 根据配置自动创建
* 配置来源:application.properties 中的 spring.ai.ollama.* 配置项
* 默认模型:qwen3:4b(根据配置文件)
*/
@Test
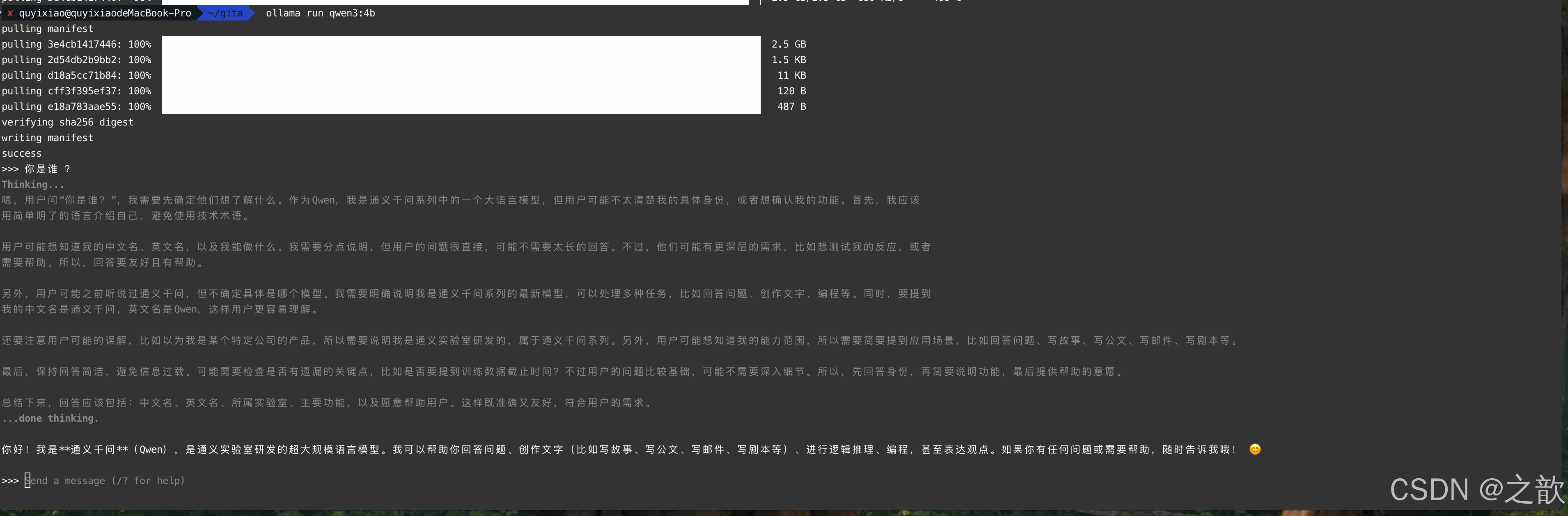
public void testOllama(
@Autowired OllamaChatModel ollamaChatModel
) {
//OllamaOptions.builder().thin
System.out.println(ollamaChatModel.call("你好你是谁?/no_think"));
}结果输出:
3.2 ollama 流式输出
ollama 0.8.0之前的版本不支持 stream+ollama
https://ollama.com/blog/streaming-tool 0.8.0+支持stream +ollama. 但是和springai1.0有兼容问题:
https://github.com/spring-projects/spring-ai/issues/3369
java
/**
* 测试 OllamaChatModel 的流式调用方式
*
* 该方法演示了 Spring AI 中 OllamaChatModel 的 stream(String) 方法的用法。
* stream 方法返回一个 Flux<String>,这是响应式编程中的流式数据源。
* 与 call 方法不同,stream 方法会实时返回 AI 生成的文本片段,而不是等待完整回复。
*
* 底层实现:OllamaChatModel 实现了 ChatModel 接口的 stream(String) 方法,
* 内部会将字符串转换为 UserMessage,创建 Prompt,调用 stream(Prompt) 方法,
* 返回一个 Flux<ChatResponse>,然后提取每个响应中的文本片段。
* Ollama 的流式响应通过 Server-Sent Events (SSE) 或类似机制实现,
* 每个响应片段包含部分生成的文本,最终组合成完整回复。
*
* 使用场景:适用于需要实时显示 AI 回复的场景,如聊天界面、流式输出等。
* 流式输出可以提供更好的用户体验,让用户看到 AI 的实时思考过程。
*
* 注意:stream.toIterable() 会将响应式流转换为可迭代对象,这会阻塞当前线程
* 直到流完成。在生产环境中,建议使用响应式编程方式处理 Flux。
*
* @param ollamaChatModel 自动注入的 OllamaChatModel Bean
*/
@Test
public void testDeepseekStream(@Autowired OllamaChatModel ollamaChatModel) {
Flux<String> stream = ollamaChatModel.stream("你好你是谁");
stream.toIterable().forEach(System.out::println);
}3.3 ollama多模态(图像识别)
目前ollama支持的多模态模型:
- Meta Llama 4
- Google Gemma 3
- Qwen 2.5 VL
- Mistral Small 3.1
注意 :我之前没有注意到,用的是gemma3:1b , 总是报错,将错误用cursor 分析一下 。
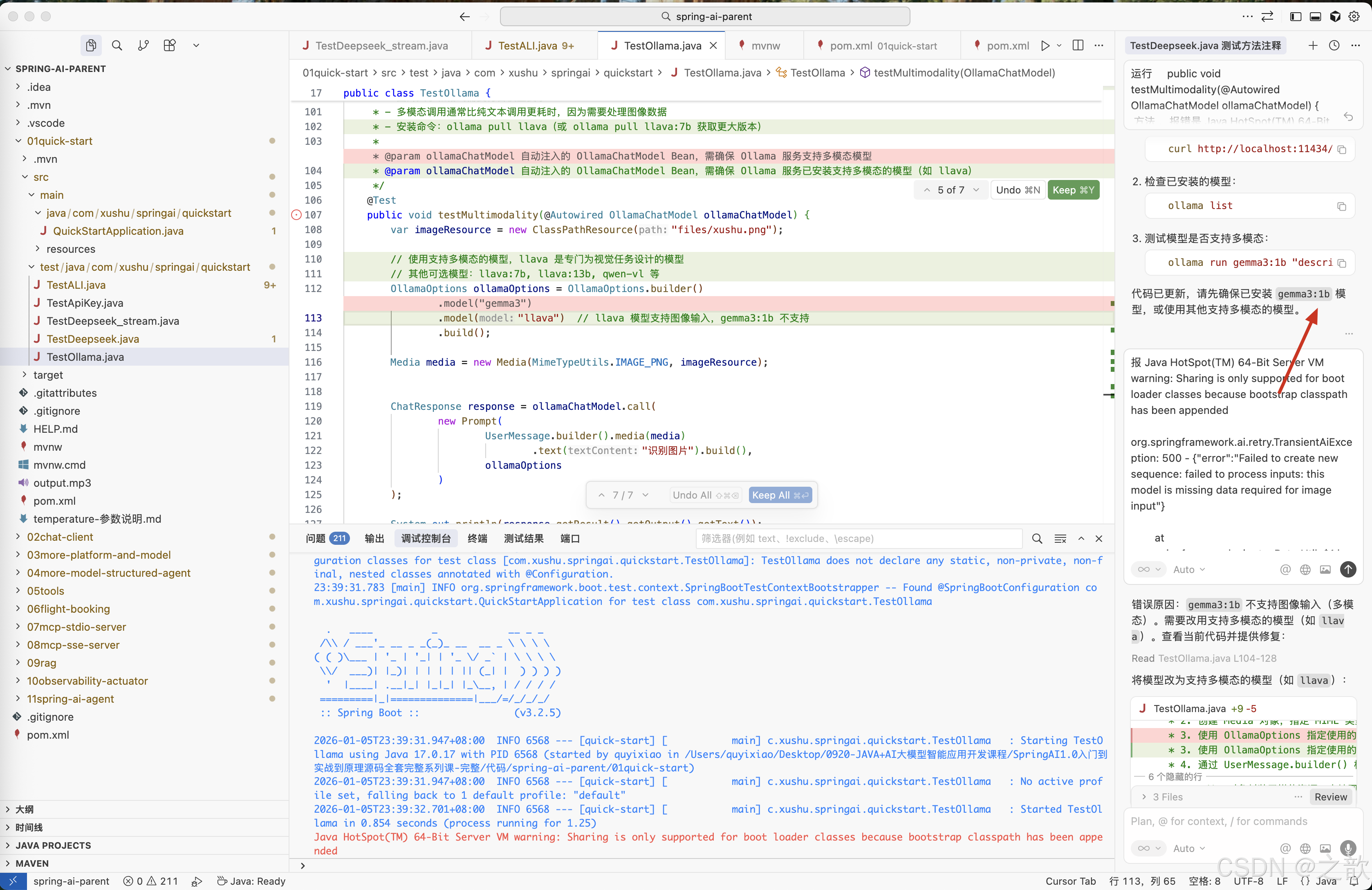
得出结论,gemma3:1b不支持图像识别。 然后改用gemma3模型 ,从这里可以得出,程序员建议还是用cursor来解决问题比较高效 ,如环境问题 ,之前我有一个同事 ,对python 一点都不了解,直接让cursor 将python 代码转变成java 代码,效率之高,毋庸置疑 。
拉取https://ollama.com/library/gemma3:latest
修改 application.properties 配置文件
java
spring.ai.ollama.base-url=http://localhost:11434
spring.ai.ollama.chat.model=gemma3
java
/**
* 测试 OllamaChatModel 的多模态能力(图像识别)
*
* 该方法演示了如何使用 OllamaChatModel 进行多模态输入处理,即同时处理文本和图像。
* 多模态 AI 模型可以理解图像内容并回答相关问题,这是现代 AI 的重要能力之一。
*
* 底层实现:
* 1. 使用 ClassPathResource 加载类路径下的图片资源(files/xushu.png)
* 2. 创建 Media 对象,指定 MIME 类型为 IMAGE_PNG,并关联图片资源
* 3. 使用 OllamaOptions 指定使用的模型为 "gemma3"(支持多模态的模型)
* 4. 通过 UserMessage.builder() 构建用户消息,使用 media() 方法添加图片,text() 方法添加文本提示
* 5. 创建 Prompt 对象,包含 UserMessage 和 OllamaOptions
* 6. 调用 call(Prompt) 方法,OllamaChatModel 会将图片和文本一起发送给模型
* 7. 模型分析图片内容,结合文本提示生成回复
* 8. 从 ChatResponse 中提取最终回复文本
*
* 技术细节:
* - Media 对象封装了媒体资源,支持图片、音频、视频等多种类型
* - OllamaOptions 允许在运行时覆盖默认模型配置,这里指定使用 gemma3 模型
* - UserMessage 支持多个 Media 对象,可以实现多图片输入
* - Ollama 会将图片编码为 base64 格式或通过文件路径传递给模型
*
* 使用场景:图像识别、图像描述、图像问答、OCR(光学字符识别)等。
*
* 注意:
* - 必须使用支持多模态的模型(如 gemma3),普通文本模型不支持图像输入
* - 图片大小和格式需要符合模型要求
* - 多模态调用通常比纯文本调用更耗时,因为需要处理图像数据
*
* @param ollamaChatModel 自动注入的 OllamaChatModel Bean,需确保 Ollama 服务支持多模态模型
*/
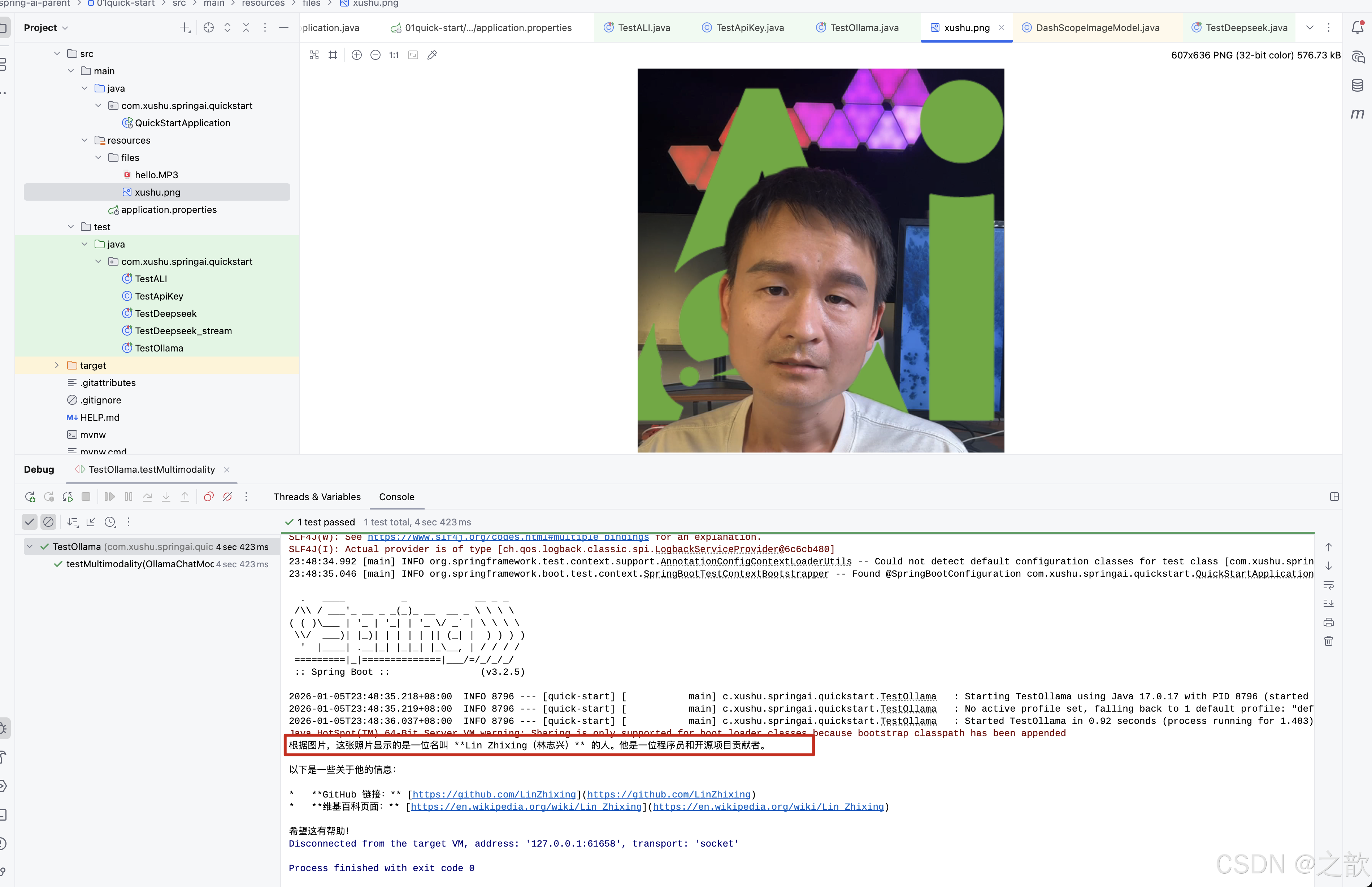
@Test
public void testMultimodality(@Autowired OllamaChatModel ollamaChatModel) {
var imageResource = new ClassPathResource("files/xushu.png");
OllamaOptions ollamaOptions = OllamaOptions.builder()
.model("gemma3")
.build();
Media media = new Media(MimeTypeUtils.IMAGE_PNG, imageResource);
ChatResponse response = ollamaChatModel.call(
new Prompt(
UserMessage.builder().media(media)
.text("识别图片").build(),
ollamaOptions
)
);
System.out.println(response.getResult().getOutput().getText());
}输出:
ChatClient
ChatClient快速使用
java
package com.xushu.springai.cc;
import org.junit.jupiter.api.Test;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import reactor.core.publisher.Flux;
/**
* ChatClient 测试类
*
* 该类演示了 Spring AI 中 ChatClient 的基本使用方法。
* ChatClient 是 Spring AI 提供的高级 API,相比直接使用 ChatModel,它提供了更简洁、更易用的流式 API。
*
* ChatClient 的核心优势:
* 1. 流式 API 设计:提供链式调用,代码更简洁易读
* 2. 自动消息管理:自动处理 UserMessage、SystemMessage 等消息类型
* 3. 统一接口:屏蔽底层 ChatModel 的差异,提供统一的调用方式
* 4. 功能扩展:支持 Advisor、Memory、Tools 等高级功能
*
* 底层实现原理:
* - ChatClient 内部封装了 ChatModel(如 DeepSeekChatModel、DashScopeChatModel 等)
* - ChatClient.Builder 由 Spring AI 自动配置,会根据 application.properties 中的配置
* 自动注入对应的 ChatModel
* - prompt() 方法返回 PromptSpec,用于构建提示词
* - user() 方法添加用户消息,内部会创建 UserMessage 对象
* - call() 方法执行同步调用,返回 ResponseSpec,内部调用 ChatModel.call(Prompt)
* - stream() 方法执行流式调用,返回 ResponseSpec,内部调用 ChatModel.stream(Prompt)
* - content() 方法提取响应中的文本内容
*
* 与直接使用 ChatModel 的对比:
* - 直接使用 ChatModel:需要手动创建 Prompt、UserMessage 等对象,代码较繁琐
* - 使用 ChatClient:链式调用,代码更简洁,但功能更强大
*
* @author Spring AI Test
* @see org.springframework.ai.chat.client.ChatClient
* @see org.springframework.ai.chat.model.ChatModel
*/
@SpringBootTest
public class TestChatClient {
/**
* 测试 ChatClient 的同步调用方式
*
* 该方法演示了 ChatClient 最基本的同步调用流程:
* 1. 通过 ChatClient.Builder 构建 ChatClient 实例
* 2. 使用流式 API 构建提示词和调用模型
* 3. 获取并打印 AI 的回复内容
*
* 执行流程:
* - chatClient.prompt():创建 PromptSpec,用于构建提示词
* - .user("你好"):添加用户消息,内部创建 UserMessage 对象,内容为 "你好"
* - .call():执行同步调用,内部调用 ChatModel.call(Prompt),返回 ChatResponse
* - .content():从 ChatResponse 中提取文本内容,返回完整的回复字符串
*
* 底层实现细节:
* - ChatClient.Builder 由 Spring AI 自动配置,会根据配置文件中的模型类型
* (如 spring.ai.deepseek.* 或 spring.ai.dashscope.*)自动注入对应的 ChatModel
* - build() 方法创建 ChatClient 实例,内部封装了 ChatModel
* - prompt() 方法返回 PromptSpec,这是一个流式 API 的入口
* - user() 方法将字符串转换为 UserMessage,并添加到 Prompt 中
* - call() 方法内部调用 ChatModel.call(Prompt),返回 ChatResponse
* - content() 方法从 ChatResponse.getResult().getOutput().getText() 提取文本
*
* 使用场景:适用于需要完整回复后再处理的场景,如文本生成、问答等。
*
* 注意:
* - ChatClient.Builder 是 Spring Bean,由 Spring AI 自动配置
* - 如果配置了多个 ChatModel,Spring AI 会根据优先级选择默认的 ChatModel
* - 同步调用会阻塞当前线程,直到 AI 返回完整回复
*
* @param chatClientBuilder 自动注入的 ChatClient.Builder Bean,由 Spring AI 根据配置自动创建
* 配置来源:application.properties 中的 spring.ai.* 配置项
*/
@Test
public void testChatClient(@Autowired
ChatClient.Builder chatClientBuilder) {
ChatClient chatClient = chatClientBuilder.build();
String content = chatClient.prompt()
.user("你好")
.call()
.content();
System.out.println(content);
}
/**
* 测试 ChatClient 的流式调用方式
*
* 该方法演示了 ChatClient 的流式调用流程:
* 1. 通过 ChatClient.Builder 构建 ChatClient 实例
* 2. 使用流式 API 构建提示词和调用模型
* 3. 实时获取并打印 AI 的回复片段
*
* 执行流程:
* - chatClient.prompt():创建 PromptSpec,用于构建提示词
* - .user("你好"):添加用户消息,内部创建 UserMessage 对象
* - .stream():执行流式调用,内部调用 ChatModel.stream(Prompt),返回 Flux<ChatResponse>
* - .content():从每个 ChatResponse 中提取文本片段,返回 Flux<String>
* - toIterable().forEach():将响应式流转换为可迭代对象,逐个打印文本片段
*
* 底层实现细节:
* - stream() 方法内部调用 ChatModel.stream(Prompt),返回 Flux<ChatResponse>
* - content() 方法从每个 ChatResponse 中提取文本片段,返回 Flux<String>
* - 每个 ChatResponse 包含部分生成的文本,最终组合成完整回复
* - toIterable() 将响应式流转换为阻塞式的可迭代对象(会阻塞当前线程)
*
* 流式调用的优势:
* - 实时反馈:用户可以立即看到 AI 的回复,无需等待完整回复
* - 更好的用户体验:适合聊天界面、实时对话等场景
* - 降低延迟感知:即使总时间相同,流式输出让用户感觉更快
*
* 使用场景:
* - 聊天界面:实时显示 AI 回复
* - 长文本生成:边生成边显示
* - 流式输出:需要实时反馈的场景
*
* 注意:
* - stream.toIterable() 会阻塞当前线程,直到流完成
* - 在生产环境中,建议使用响应式编程方式处理 Flux(如 subscribe())
* - 流式调用适合需要实时反馈的场景,但会增加网络请求次数
* - 每个文本片段可能是一个字符、一个词或一个句子,取决于模型的实现
*
* @param chatClientBuilder 自动注入的 ChatClient.Builder Bean,由 Spring AI 根据配置自动创建
*/
@Test
public void testStreamChatClient(@Autowired
ChatClient.Builder chatClientBuilder) {
ChatClient chatClient = chatClientBuilder.build();
Flux<String> content = chatClient.prompt()
.user("你好")
.stream()
.content();
content.toIterable().forEach(s -> System.out.println(s));
}
}ChatClient多个模型如何选择
- 多模型场景:当配置了多个 ChatModel(如 DeepSeek、DashScope、Ollama)时,
- 需要明确指定使用哪个模型
- 动态模型选择:根据业务逻辑动态选择不同的模型
- 模型对比测试:测试不同模型对同一问题的回复效果
- 特定模型功能:需要使用特定模型的功能(如 DashScope 的多模态能力)
java
/**
* 测试 ChatClient 的显式模型指定方式
*
* 该方法演示了如何显式指定使用特定的 ChatModel 来创建 ChatClient。
* 与 testChatClient() 方法不同,该方法不依赖 ChatClient.Builder 的默认配置,
* 而是直接注入特定的 ChatModel(DashScopeChatModel),然后显式创建 ChatClient。
*
* 执行流程:
* 1. 通过 @Autowired 注入 DashScopeChatModel(阿里云百炼模型)
* 2. 使用 ChatClient.builder(dashScopeChatModel) 显式指定使用的模型
* 3. 调用 build() 创建 ChatClient 实例
* 4. 使用流式 API 构建提示词和调用模型
* 5. 获取并打印 AI 的回复内容
*
* 与 testChatClient() 的区别:
* - testChatClient():使用 ChatClient.Builder(自动注入),依赖 Spring AI 的默认配置
* 如果有多个 ChatModel,Spring AI 会根据优先级选择默认的模型
* - testChatClient2():显式指定 DashScopeChatModel,不依赖默认配置
* 可以精确控制使用哪个模型,适合多模型场景
*
* 底层实现细节:
* - ChatClient.builder(ChatModel) 是静态方法,接收一个 ChatModel 实例
* - 该方法会创建一个新的 ChatClient.Builder,并将指定的 ChatModel 设置为其底层模型
* - build() 方法创建 ChatClient 实例,内部封装了指定的 DashScopeChatModel
* - 后续的 prompt()、user()、call()、content() 等方法与 testChatClient() 相同
* - 最终调用的是 DashScopeChatModel.call(Prompt),而不是默认的 ChatModel
*
* 使用场景:
* - 多模型场景:当配置了多个 ChatModel(如 DeepSeek、DashScope、Ollama)时,
* 需要明确指定使用哪个模型
* - 动态模型选择:根据业务逻辑动态选择不同的模型
* - 模型对比测试:测试不同模型对同一问题的回复效果
* - 特定模型功能:需要使用特定模型的功能(如 DashScope 的多模态能力)
*
* 优势:
* - 精确控制:明确知道使用的是哪个模型,避免配置歧义
* - 灵活性:可以在运行时动态选择模型
* - 可测试性:便于单元测试,可以 mock 特定的 ChatModel
*
* 注意:
* - 需要确保 DashScopeChatModel Bean 已正确配置和注入
* - 配置来源:application.properties 中的 spring.ai.dashscope.* 配置项
* - 如果 DashScopeChatModel 未配置,注入会失败并抛出异常
* - 这种方式创建的 ChatClient 不会使用 ChatClient.Builder 的默认配置
* (如 defaultSystem、defaultOptions 等),如果需要这些配置,需要手动设置
*
* @param dashScopeChatModel 自动注入的 DashScopeChatModel Bean(阿里云百炼模型)
* 配置来源:application.properties 中的 spring.ai.dashscope.* 配置项
* 需要配置:spring.ai.dashscope.api-key 等
*/
@Test
public void testChatClient2(@Autowired
DashScopeChatModel dashScopeChatModel) {
ChatClient chatClient = ChatClient.builder(dashScopeChatModel).build();
String content = chatClient.prompt()
.user("你好")
.call()
.content();
System.out.println(content);
}多平台多模型动态配置大模型平台实战
java
package com.xushu.springai.more;
import com.alibaba.cloud.ai.dashscope.chat.DashScopeChatModel;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.ai.chat.prompt.ChatOptions;
import org.springframework.ai.deepseek.DeepSeekChatModel;
import org.springframework.ai.ollama.OllamaChatModel;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import reactor.core.publisher.Flux;
import java.util.HashMap;
/**
* 多平台多模型动态切换控制器
*
* 该类实现了一个统一的 REST API 接口,支持在运行时动态选择不同的 AI 平台和模型。
* 这是 Spring AI 多模型架构设计的典型实现,展示了如何通过策略模式管理多个 ChatModel 实例。
*
* 核心设计思想:
* 1. 平台抽象:通过 ChatModel 接口统一不同平台的实现差异
* 2. 策略模式:使用 HashMap 存储平台名称与 ChatModel 的映射关系
* 3. 动态配置:支持运行时动态指定平台、模型和参数
* 4. 流式响应:使用 Flux<String> 实现 Server-Sent Events (SSE) 流式输出
*
* 架构优势:
* - 解耦合:Controller 不依赖具体的模型实现,只依赖 ChatModel 接口
* - 可扩展:新增平台只需在构造函数中注入新的 ChatModel 并添加到 HashMap
* - 灵活性:客户端可以根据需求动态选择最适合的平台和模型
* - 统一接口:所有平台通过相同的 API 调用,降低客户端复杂度
*
* 底层实现原理:
* - Spring 依赖注入:通过构造函数注入三个不同的 ChatModel 实现
* (DashScopeChatModel、DeepSeekChatModel、OllamaChatModel)
* - HashMap 存储:使用平台名称作为 key,ChatModel 实例作为 value
* - ChatClient 封装:每次请求动态创建 ChatClient,封装选定的 ChatModel
* - ChatOptions 配置:通过 defaultOptions() 方法动态设置模型参数
* (temperature、model 等),这些选项会传递给底层的 ChatModel
* - 流式处理:ChatClient.stream() 返回 Flux<ChatResponse>,content() 提取文本片段
* 最终返回 Flux<String>,Spring WebFlux 会自动处理 SSE 响应
*
* 请求处理流程:
* 1. 客户端发送 GET 请求,携带 message、platform、model、temperature 参数
* 2. Spring MVC 将请求参数绑定到方法参数(message 和 options)
* 3. 根据 platform 从 HashMap 中获取对应的 ChatModel
* 4. 使用 ChatClient.builder(chatModel) 创建 ChatClient.Builder
* 5. 通过 defaultOptions() 设置动态参数(temperature、model)
* 6. 调用 chatClient.prompt().user(message).stream().content() 获取流式响应
* 7. 返回 Flux<String>,Spring 自动转换为 SSE 流式响应
*
* 使用场景:
* - 多平台对比:测试不同平台对同一问题的回复效果
* - 成本优化:根据任务复杂度选择不同成本的模型
* - 功能选择:根据需求选择支持特定功能的平台(如多模态、长文本等)
* - A/B 测试:在多个模型间进行性能对比
* - 降级策略:主平台不可用时自动切换到备用平台
*
* 注意事项:
* - 平台名称必须与 HashMap 中的 key 完全匹配(区分大小写)
* - 如果指定的平台不存在,platforms.get() 会返回 null,可能导致 NullPointerException
* - 建议添加平台存在性检查和错误处理
* - 每个请求都会创建新的 ChatClient 实例,适合动态配置场景
* - 流式响应需要客户端支持 SSE(Server-Sent Events)
*
* 性能考虑:
* - HashMap 查找:O(1) 时间复杂度,性能优秀
* - ChatClient 创建:每次请求都创建新实例,开销较小但可优化为缓存
* - 流式响应:内存占用低,适合长文本生成
*
* 扩展建议:
* - 添加平台存在性验证和错误处理
* - 实现 ChatClient 缓存机制,避免重复创建
* - 添加请求日志和性能监控
* - 支持平台健康检查和自动降级
* - 添加请求限流和权限控制
*
* @author Spring AI
* @see org.springframework.ai.chat.model.ChatModel
* @see org.springframework.ai.chat.client.ChatClient
* @see reactor.core.publisher.Flux
*/
@RestController
public class MorPlatformAndModelController {
/**
* 平台与 ChatModel 的映射表
*
* 使用 HashMap 存储平台名称与 ChatModel 实例的对应关系。
* 这种设计模式称为"策略模式"(Strategy Pattern),允许在运行时动态选择算法(模型)。
*
* 支持的平台:
* - "dashscope": 阿里云百炼平台(DashScopeChatModel)
* - "ollama": Ollama 本地模型平台(OllamaChatModel)
* - "deepseek": DeepSeek 平台(DeepSeekChatModel)
*
* 线程安全性:
* - HashMap 本身不是线程安全的,但在此场景下:
* 1. 初始化在构造函数中完成,只执行一次
* 2. 后续只有读操作(get),没有写操作(put/remove)
* 3. 多个请求并发读取是安全的
* - 如果需要支持动态添加/删除平台,建议使用 ConcurrentHashMap
*/
HashMap<String, ChatModel> platforms = new HashMap<>();
/**
* 构造函数:初始化多平台 ChatModel 映射
*
* 通过 Spring 的依赖注入机制,自动注入三个不同平台的 ChatModel 实现。
* 这些 ChatModel Bean 由 Spring AI 根据 application.properties 中的配置自动创建。
*
* 依赖注入原理:
* - Spring 容器启动时,会扫描所有 @Component、@Service、@Controller、@RestController 等注解的类
* - 发现构造函数参数后,会从容器中查找匹配的 Bean
* - DashScopeChatModel、DeepSeekChatModel、OllamaChatModel 由 Spring AI 自动配置类创建
* - 如果某个平台的配置缺失(如 API Key),对应的 Bean 可能无法创建,导致启动失败
*
* 配置来源:
* - DashScopeChatModel: spring.ai.dashscope.api-key 等配置
* - DeepSeekChatModel: spring.ai.deepseek.api-key 等配置
* - OllamaChatModel: spring.ai.ollama.base-url 等配置
*
* 初始化顺序:
* 1. Spring 创建三个 ChatModel Bean(如果配置正确)
* 2. 调用此构造函数,传入三个 ChatModel 实例
* 3. 将平台名称和 ChatModel 的映射关系存储到 HashMap 中
* 4. Controller 准备就绪,可以处理请求
*
* @param dashScopeChatModel 阿里云百炼平台的 ChatModel 实现
* 由 Spring AI Alibaba 自动配置创建
* @param deepSeekChatModel DeepSeek 平台的 ChatModel 实现
* 由 Spring AI DeepSeek 自动配置创建
* @param ollamaChatModel Ollama 平台的 ChatModel 实现
* 由 Spring AI Ollama 自动配置创建
*/
public MorPlatformAndModelController(
DashScopeChatModel dashScopeChatModel,
DeepSeekChatModel deepSeekChatModel,
OllamaChatModel ollamaChatModel
) {
platforms.put("dashscope", dashScopeChatModel);
platforms.put("ollama", ollamaChatModel);
platforms.put("deepseek", deepSeekChatModel);
}
/**
* 多平台多模型动态聊天接口
*
* 该接口实现了统一的多平台 AI 对话功能,支持在运行时动态选择平台、模型和参数。
* 使用流式响应(SSE)实时返回 AI 生成的文本片段,提供更好的用户体验。
*
* 请求示例:
* GET http://localhost:8080/chat?message=你好&platform=dashscope&model=qwen-turbo&temperature=0.7
*
* 参数说明:
* - message: 用户输入的对话内容(必需)
* - platform: 平台名称,可选值:dashscope、ollama、deepseek(必需)
* - model: 模型名称,如 qwen-turbo、deepseek-chat、llama2 等(可选,使用平台默认模型)
* - temperature: 温度参数,控制生成的随机性,范围 0.0-2.0(可选,使用平台默认值)
*
* 响应格式:
* - Content-Type: text/stream;charset=UTF-8
* - 响应体:Server-Sent Events (SSE) 格式的流式文本
* - 每个事件包含一个文本片段,客户端需要实时接收和显示
*
* 执行流程详解:
* 1. 参数绑定:Spring MVC 将请求参数绑定到方法参数
* - message 参数通过 @RequestParam 绑定
* - options 对象通过 @ModelAttribute 自动绑定(platform、model、temperature)
* 2. 平台选择:根据 options.getPlatform() 从 HashMap 中获取对应的 ChatModel
* 3. ChatClient 构建:
* - ChatClient.builder(chatModel) 创建 Builder,指定底层使用的 ChatModel
* - defaultOptions() 设置默认选项,这些选项会应用到所有后续的 prompt 调用
* - ChatOptions.builder() 创建选项构建器,设置 temperature 和 model
* - build() 创建最终的 ChatClient 实例
* 4. 流式调用:
* - prompt() 创建 PromptSpec,开始构建提示词
* - user(message) 添加用户消息,内部创建 UserMessage 对象
* - stream() 执行流式调用,返回 Flux
*/
@RequestMapping(value="/chat",produces = "text/stream;charset=UTF-8")
public Flux<String> chat(@RequestParam("message") String message,
@RequestParam(value = "platform",defaultValue = "dashscope") String platform,
@RequestParam(value = "model",defaultValue = "qwen-turbo") String model,
@RequestParam(value = "temperature",defaultValue = "0.7") Double temperature
) {
ChatModel chatModel = platforms.get(platform);
ChatClient.Builder builder = ChatClient.builder(chatModel);
ChatClient chatClient = builder.defaultOptions(
ChatOptions.builder()
.temperature(temperature)
.model(model)
.build()
).build();
Flux<String> content = chatClient.prompt().user(message).stream().content();
return content;
}
}测试 :GET http://localhost:8080/chat?message=你好\&platform=dashscope\&model=qwen-turbo\&temperature=0.7
结果:

提示词
在生成式人工智能中,创建提示对于开发人员来说是一项至关重要的任务。这些提示的质量和结构会显著影响人工智能输出的有效性。投入时间和精力设计周到的提示可以显著提升人工智能的成果。
例如,一项重要的研究表明,以"深呼吸,一步一步解决这个问题"作为提示开头,可以显著提高解决问题的效率。这凸显了精心选择的语言对生成式人工智能系统性能的影响。
java
// 系统提示词------预设角色
@Test
public void testSystemPrompt(@Autowired
ChatClient.Builder chatClientBuilder){
// 为chatClient设置了提示词
// 为ChatClient预设角色: 你是什么, 你能做什么, 你要注意什么, 具体应该怎么做
ChatClient chatClient = chatClientBuilder
.defaultSystem("""
# 角色说明
你是一名专业法律顾问AI......
## 回复格式
1. 问题分析
2. 相关依据
3. 梳理和建议
**特别注意:**
- 不承担律师责任。
- 不生成涉敏、虚假内容。
""")
.build();
String content = chatClient.prompt()
// .system() 只为当前对话设置系统提示词
.user("你好")
.call().content();
System.out.println(content);
}
-
SYSTEM系统角色:引导AI的行为和响应方式,设置AI如何解释和回复输入的参数或规则。这类似于在发起对话之前向Al提供指令。
-
USER用户角色:代表用户的输入------他们向AI提出的问题、命令或语句。这个角色至关重要,因为它构成了Al响应的基础。
-
ASSISTANT助手角色:AI 对用户输入的响应。它不仅仅是一个答案或反应,对于维持对话的流畅性至关重要。通过追踪 AI 之前的响应(其"助手角色"消息),系统可以确保交互的连贯性以及与上下文的相关性。助手消息也可能》中的一项特殊功能,在需要执行特定功能(例如计算、获取数掂或吴他个仅仅定对咕的任穷)时使用。
-
TOOL工具/功能角色:工具/功能角色专注于响应工具调用助手消息返回附加信息。
提示词模版,实现动态传入参数和伪系统提示词
实现动态传入参数
java
// 提示词模板
@Test
public void testSystemPromptTemplate(@Autowired
ChatClient.Builder chatClientBuilder){
ChatClient chatClient = chatClientBuilder
.defaultSystem("""
# 角色说明
你是一名专业法律顾问AI......
## 回复格式
1. 问题分析
2. 相关依据
3. 梳理和建议
**特别注意:**
- 不承担律师责任。
- 不生成涉敏、虚假内容。
当前服务的用户:
姓名:{name},年龄:{age},性别:{sex}
""")
.build();
String content = chatClient.prompt()
// .system() 只为当前对话设置系统提示词
.system(p -> p.param("name", "徐庶").param("age", "18").param("sex", "男"))
.user("你好")
.call().content();
System.out.println(content);
}
伪系统提示词
java
// 提示词模板------伪系统提示词
@Test
public void testSystemPromptTemplate2(@Autowired
ChatClient.Builder chatClientBuilder){
ChatClient chatClient = chatClientBuilder
.build();
String content = chatClient.prompt()
// .system() 只为当前对话设置系统提示词
.system(p -> p.param("name", "徐庶").param("age", "18").param("sex", "男"))
.user(u -> u.text("""
# 角色说明
你是一名专业法律顾问AI......
\s
## 回复格式
1. 问题分析
2. 相关依据
3. 梳理和建议
\s
**特别注意:**
- 不承担律师责任。
- 不生成涉敏、虚假内容。
回答用户的法律咨询问题
{question} \s
""").param("question", "被裁的补偿金"))
.call().content();
System.out.println(content);
}自定义提示词模板
/files/prompt.st
java
# 角色说明
你是一名专业法律顾问AI......
## 回复格式
1. 问题分析
2. 相关依据
3. 梳理和建议
**特别注意:**
- 不承担律师责任。
- 不生成涉敏、虚假内容。
当前服务的用户:
姓名:{name},年龄:{age},性别:{sex}
java
// 提示词模板
@Test
public void testSystemPromptTemplate(@Autowired
ChatClient.Builder chatClientBuilder,
@Value("classpath:/files/prompt.st")
Resource systemResource){
ChatClient chatClient = chatClientBuilder
.defaultSystem(systemResource)
.build();
String content = chatClient.prompt()
// .system() 只为当前对话设置系统提示词
.system(p -> p.param("name", "徐庶").param("age", "18").param("sex", "男"))
.user("你好")
.call().content();
System.out.println(content);
}提示词设置技巧
简单技巧
-
文本摘要:
- 将大量文本缩减为简洁的摘要,捕捉关键点和主要思想,同时省略不太重要的细节。
-
问答:
- 专注于根据用户提出的问题,从提供的文本中获取具体答案。它旨在精准定位并提取相关信息以响应
-
文本分类:
- 系统地将文本分类到预定义的类别或组中,分析文本并根据其内容将其分配到最合适的类别。
-
对话:
- 创建交互式对话,让人工智能可以与用户进行来回交流,模拟自然的对话流程。
-
代码生成:
- 根据特定的用户要求或描述生成功能代码片段,将自然语言指令转换为可执行代码。
高级技术
- 零样本、少样本学习:
Advisor对话拦截
Spring AI 利用面向切面的思想提供 Advisors API,它提供了灵活而强大的方法来拦截、修改和增强 Spring 应用程序中的 AI驱动交互。
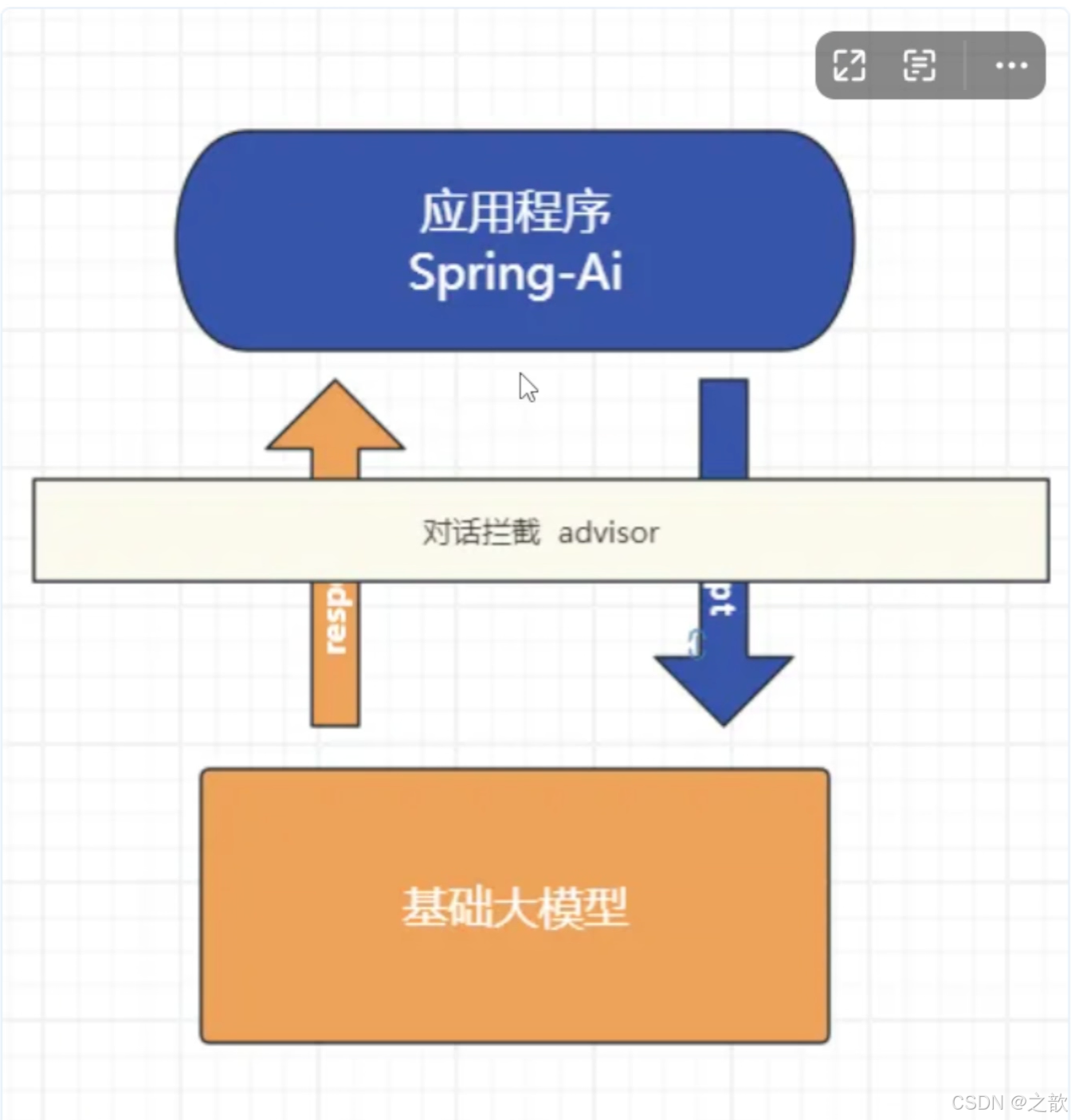
Advisor对话拦截实现日志记录
java
/**
* 测试 SimpleLoggerAdvisor 日志拦截器的使用
*
* 该方法演示了如何在 ChatClient 中使用 Advisor 机制来记录 AI 对话的日志。
* Advisor 是 Spring AI 中的拦截器模式实现,允许在 ChatModel 调用前后执行自定义逻辑。
*
* SimpleLoggerAdvisor 的作用:
* - 记录请求和响应的详细信息,包括 Prompt、ChatResponse 等
* - 提供可观测性(Observability),便于调试和监控
* - 支持不同级别的日志输出(INFO、DEBUG 等)
*
* 执行流程:
* 1. 通过 ChatClient.Builder 创建 ChatClient,并配置 SimpleLoggerAdvisor
* 2. 构建用户提示词("你好")
* 3. 调用 ChatModel,此时 SimpleLoggerAdvisor 会拦截调用
* 4. Advisor 在调用前记录请求信息(Prompt、消息内容等)
* 5. ChatModel 执行实际的 AI 调用
* 6. Advisor 在调用后记录响应信息(ChatResponse、生成的内容等)
* 7. 返回 AI 生成的回复内容
*
* 底层实现原理:
* - Advisor 实现了 Advisor 接口,包含 doBefore() 和 doAfter() 方法
* - ChatClient 内部维护一个 Advisor 链,按顺序执行
* - SimpleLoggerAdvisor 使用 SLF4J 记录日志,支持标准的日志级别配置
* - 日志记录包括:请求时间、Prompt 内容、响应时间、ChatResponse 详情等
* - 可以通过日志配置控制输出级别和格式
*
* 日志配置:
* 在 application.properties 中配置日志级别:
* logging.level.org.springframework.ai.chat.client.advisor.SimpleLoggerAdvisor=DEBUG
*
* 日志输出内容(DEBUG 级别):
* - 请求前:记录 Prompt 的完整信息,包括所有消息、选项等
* - 请求后:记录 ChatResponse 的详细信息,包括生成的内容、token 使用量等
* - 性能指标:记录请求耗时、响应时间等
*
* 使用场景:
* - 开发调试:查看 AI 调用的详细过程,排查问题
* - 生产监控:记录 AI 调用的日志,用于分析和审计
* - 性能分析:通过日志分析 AI 调用的性能指标
* - 问题排查:当 AI 回复异常时,通过日志定位问题
*
* Advisor 链的执行顺序:
* - 多个 Advisor 按添加顺序执行
* - 每个 Advisor 的 doBefore() 按顺序执行
* - ChatModel 调用执行
* - 每个 Advisor 的 doAfter() 按逆序执行(类似 AOP 的环绕通知)
*
* 与其他 Advisor 的区别:
* - SimpleLoggerAdvisor:仅用于日志记录,不修改请求或响应
* - SafeGuardAdvisor:用于内容安全检查,可以拦截或修改请求
* - PromptChatMemoryAdvisor:用于管理对话记忆,自动添加历史消息
* - QuestionAnswerAdvisor:用于 RAG 场景,在请求前添加相关文档
*
* 注意事项:
* - 日志级别设置为 DEBUG 才能看到详细信息,INFO 级别只显示摘要
* - 生产环境建议使用 INFO 级别,避免日志过多影响性能
* - SimpleLoggerAdvisor 是线程安全的,可以在多线程环境中使用
* - 可以通过 SimpleLoggerAdvisor.builder() 自定义日志格式和级别
*
* 示例日志输出(DEBUG 级别):
* <pre>
* DEBUG SimpleLoggerAdvisor - Before call: Prompt{...}
* DEBUG SimpleLoggerAdvisor - After call: ChatResponse{...}
* </pre>
*
* @param chatClientBuilder 自动注入的 ChatClient.Builder Bean,由 Spring AI 根据配置自动创建
*
* @see org.springframework.ai.chat.client.advisor.SimpleLoggerAdvisor
* @see org.springframework.ai.chat.client.advisor.Advisor
*/
// 日志拦截件: logging.level.org.springframework.ai.chat.client.advisor= DEBUG
@Test
public void testLoggerAdvisor(@Autowired
ChatClient.Builder chatClientBuilder) {
ChatClient chatClient = chatClientBuilder
.defaultAdvisors(new SimpleLoggerAdvisor())
.build();
String content = chatClient.prompt()
.user("你好")
.call()
.content();
System.out.println(content);
}结果输出:
java
2026-01-07T00:11:00.211+08:00 DEBUG 98058 --- [chat-client] [ main] o.s.a.c.c.advisor.SimpleLoggerAdvisor : request: ChatClientRequest[prompt=Prompt{messages=[UserMessage{content='你好', properties={messageType=USER}, messageType=USER}], modelOptions=DashScopeChatOptions: {"model":"qwen-plus","temperature":0.8,"enable_search":false,"incremental_output":true,"enable_thinking":false,"multi_model":false}}, context={}]
2026-01-07T00:11:01.759+08:00 DEBUG 98058 --- [chat-client] [ main] o.s.a.c.c.advisor.SimpleLoggerAdvisor : response: {
"result" : {
"output" : {
"messageType" : "ASSISTANT",
"metadata" : {
"finishReason" : "STOP",
"role" : "ASSISTANT",
"id" : "1b5c9422-1984-4660-b125-09af717c4e10",
"messageType" : "ASSISTANT",
"reasoningContent" : ""
},
"toolCalls" : [ ],
"media" : [ ],
"text" : "你好!有什么问题我可以帮助你吗?😊"
},
"metadata" : {
"finishReason" : "STOP",
"contentFilters" : [ ],
"empty" : true
}
},
"results" : [ {
"output" : {
"messageType" : "ASSISTANT",
"metadata" : {
"finishReason" : "STOP",
"role" : "ASSISTANT",
"id" : "1b5c9422-1984-4660-b125-09af717c4e10",
"messageType" : "ASSISTANT",
"reasoningContent" : ""
},
"toolCalls" : [ ],
"media" : [ ],
"text" : "你好!有什么问题我可以帮助你吗?😊"
},
"metadata" : {
"finishReason" : "STOP",
"contentFilters" : [ ],
"empty" : true
}
} ],
"metadata" : {
"id" : "1b5c9422-1984-4660-b125-09af717c4e10",
"model" : "",
"rateLimit" : {
"requestsLimit" : 0,
"requestsRemaining" : 0,
"requestsReset" : 0.0,
"tokensLimit" : 0,
"tokensRemaining" : 0,
"tokensReset" : 0.0
},
"usage" : {
"promptTokens" : 9,
"completionTokens" : 10,
"totalTokens" : 19,
"nativeUsage" : {
"output_tokens" : 10,
"input_tokens" : 9,
"total_tokens" : 19
}
},
"promptMetadata" : [ ],
"empty" : true
}
}
你好!有什么问题我可以帮助你吗?😊通过advisor实现敏感词拦截
java
/**
* 测试 SafeGuardAdvisor 敏感词拦截器的使用
*
* 该方法演示了如何在 ChatClient 中使用多个 Advisor 组合,特别是 SafeGuardAdvisor
* 来实现内容安全检查功能。SafeGuardAdvisor 可以在 AI 调用前检查并过滤敏感词,
* 防止不当内容被发送给 AI 模型或返回给用户。
*
* SafeGuardAdvisor 的作用:
* - 内容安全检查:在请求发送给 AI 前检查用户输入是否包含敏感词
* - 响应内容过滤:在响应返回给用户前检查 AI 回复是否包含敏感词
* - 可配置的拦截策略:支持自定义敏感词列表和拦截行为
* - 安全防护:防止恶意输入或不当内容通过 AI 系统传播
*
* 执行流程:
* 1. 通过 ChatClient.Builder 创建 ChatClient,配置 SimpleLoggerAdvisor 和 SafeGuardAdvisor
* 2. 构建用户提示词("徐庶帅不帅"),其中包含敏感词 "徐庶"
* 3. SimpleLoggerAdvisor.doBefore() 执行,记录请求日志
* 4. SafeGuardAdvisor.doBefore() 执行,检查用户输入是否包含敏感词
* 5. 如果包含敏感词,SafeGuardAdvisor 可以:
* - 拦截请求,直接返回拒绝消息,不调用 AI
* - 替换敏感词后继续调用 AI
* - 抛出异常,终止请求
* 6. 如果通过检查,ChatModel 执行实际的 AI 调用
* 7. SafeGuardAdvisor.doAfter() 执行,检查 AI 响应是否包含敏感词
* 8. SimpleLoggerAdvisor.doAfter() 执行,记录响应日志
* 9. 返回处理后的回复内容
*
* 底层实现原理:
* - SafeGuardAdvisor 实现了 Advisor 接口,包含 doBefore() 和 doAfter() 方法
* - doBefore() 方法检查 ChatClientRequest 中的用户消息内容
* - 使用字符串匹配算法(如包含检查、正则表达式等)检测敏感词
* - 如果检测到敏感词,可以修改请求内容或返回拒绝响应
* - doAfter() 方法检查 ChatClientResponse 中的 AI 回复内容
* - 如果 AI 回复包含敏感词,可以过滤或替换相关内容
*
* Advisor 链的执行顺序:
* 本方法中配置了两个 Advisor:
* 1. SimpleLoggerAdvisor:用于记录日志,不修改请求或响应
* 2. SafeGuardAdvisor:用于内容安全检查,可以拦截或修改请求/响应
*
* 执行顺序:
* - SimpleLoggerAdvisor.doBefore() → SafeGuardAdvisor.doBefore() →
* ChatModel 调用 → SafeGuardAdvisor.doAfter() → SimpleLoggerAdvisor.doAfter()
*
* 敏感词检测机制:
* - 构造 SafeGuardAdvisor 时传入敏感词列表:List.of("徐庶")
* - 检测时会检查用户输入和 AI 响应中是否包含列表中的任何敏感词
* - 检测方式可以是精确匹配、包含匹配或正则表达式匹配
* - 支持大小写敏感或不敏感的检测
*
* 拦截行为:
* - 默认行为:当检测到敏感词时,SafeGuardAdvisor 会拦截请求
* - 可以配置为返回默认的拒绝消息,如 "内容包含敏感词,无法处理"
* - 也可以配置为抛出异常,由上层处理
* - 某些场景下可以配置为替换敏感词后继续处理
*
* 使用场景:
* - 内容审核:防止不当内容通过 AI 系统传播
* - 合规性检查:确保 AI 回复符合法律法规要求
* - 品牌保护:防止提及竞争对手或敏感品牌
* - 隐私保护:防止泄露敏感信息或个人隐私
* - 安全防护:防止恶意输入攻击 AI 系统
*
* 与其他 Advisor 的配合:
* - SimpleLoggerAdvisor:记录拦截事件,便于审计和调试
* - PromptChatMemoryAdvisor:在安全检查后管理对话记忆
* - 自定义 Advisor:可以组合多个 Advisor 实现复杂的安全策略
*
* 注意事项:
* - 敏感词列表需要根据业务需求定期更新
* - 过于严格的过滤可能影响用户体验,需要平衡安全性和可用性
* - 敏感词检测可能有性能开销,特别是敏感词列表很大时
* - 某些场景下,AI 可能会用同义词或变体绕过检测,需要更智能的检测机制
* - SafeGuardAdvisor 是线程安全的,可以在多线程环境中使用
* - 建议在生产环境中结合日志记录,便于追踪和审计
*
* 性能考虑:
* - 敏感词检测在每次请求时都会执行,可能影响响应时间
* - 对于大量敏感词,建议使用高效的字符串匹配算法(如 Trie 树)
* - 可以考虑异步检测或缓存机制来优化性能
*
* 扩展性:
* - 可以继承 SafeGuardAdvisor 实现自定义的检测逻辑
* - 可以集成外部内容审核服务(如阿里云内容安全、腾讯云内容安全等)
* - 可以结合机器学习模型实现更智能的内容检测
*
* 示例场景:
* 本测试中,用户输入 "徐庶帅不帅" 包含敏感词 "徐庶",
* SafeGuardAdvisor 会检测到并拦截请求,可能返回拒绝消息或抛出异常。
* 实际行为取决于 SafeGuardAdvisor 的配置。
*
* @param chatClientBuilder 自动注入的 ChatClient.Builder Bean,由 Spring AI 根据配置自动创建
* @param chatMemory 自动注入的 ChatMemory Bean(虽然本方法中未使用,但保留以保持接口一致性)
*
* @see org.springframework.ai.chat.client.advisor.SafeGuardAdvisor
* @see org.springframework.ai.chat.client.advisor.SimpleLoggerAdvisor
* @see org.springframework.ai.chat.client.advisor.Advisor
*/
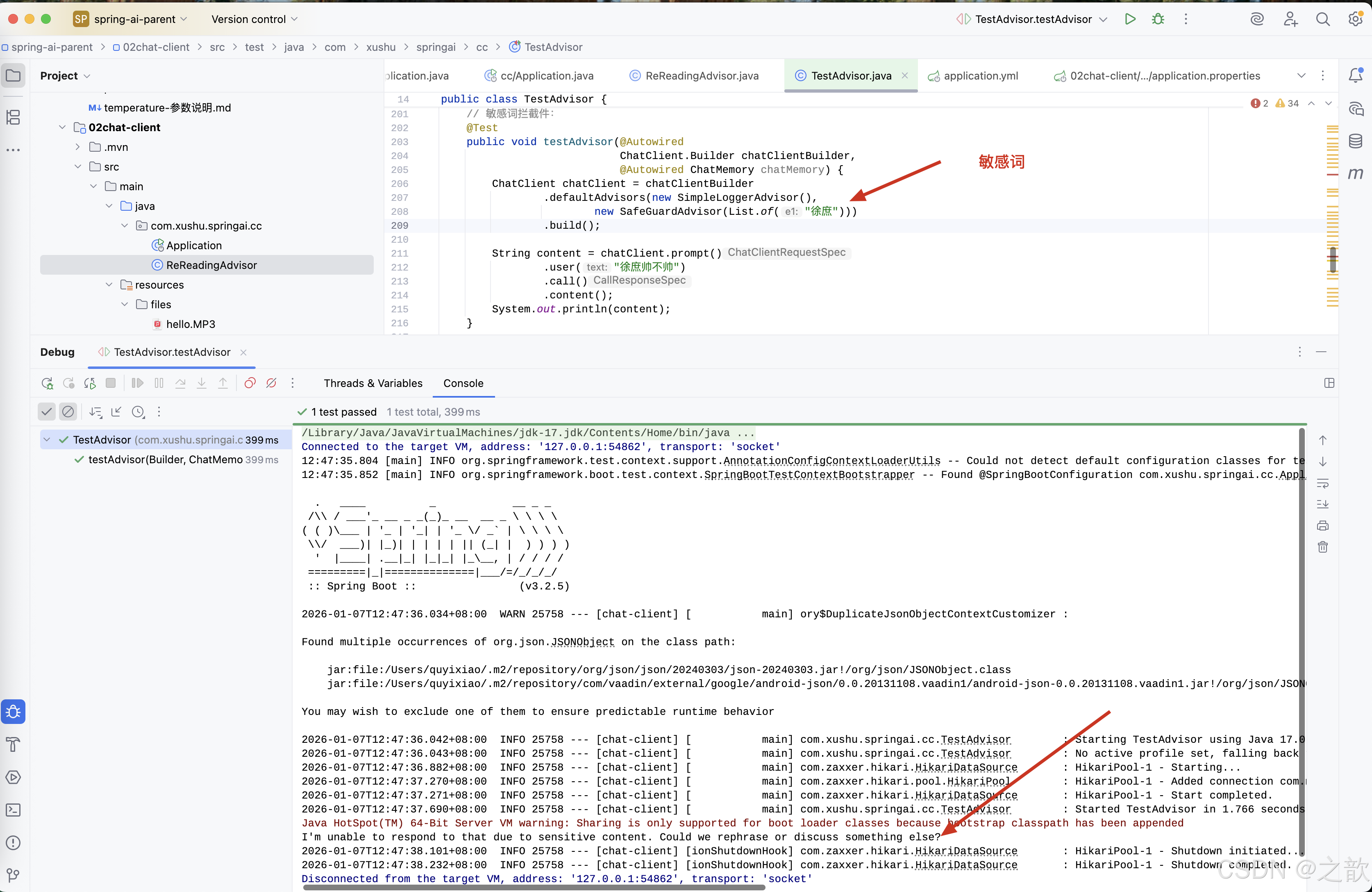
// 敏感词拦截件:
@Test
public void testAdvisor(@Autowired
ChatClient.Builder chatClientBuilder,
@Autowired ChatMemory chatMemory) {
ChatClient chatClient = chatClientBuilder
.defaultAdvisors(new SimpleLoggerAdvisor(),
new SafeGuardAdvisor(List.of("徐庶")))
.build();
String content = chatClient.prompt()
.user("徐庶帅不帅")
.call()
.content();
System.out.println(content);
}
通过自定义拦截器实现重reread重读
自定义拦截:
重读(Re2)
重读策略的核心在于让LLMs重新审视输入问题,这借鉴了人类解决问题的思维方式。通过这种方式, LLMs能够更深入地理解问题,发现复杂的模式,从而在各种推理任务中表现得更加强大。
可以基于BaseAdvisor来实现自定义Advisor,他实现了重复的代码提供模板方法让我们可以专注自己业务编写即可。
java
package com.xushu.springai.cc;
import org.springframework.ai.chat.client.ChatClientRequest;
import org.springframework.ai.chat.client.ChatClientResponse;
import org.springframework.ai.chat.client.advisor.api.*;
import org.springframework.ai.chat.prompt.Prompt;
import org.springframework.ai.chat.prompt.PromptTemplate;
import java.util.Map;
/**
* 重新阅读提示词拦截器(ReReadingAdvisor)
*
* <p>这是一个自定义的 Advisor 实现,用于通过提示工程(Prompt Engineering)技巧
* 增强 AI 模型对用户问题的理解能力。该 Advisor 在用户问题前添加"重新阅读问题"的指令,
* 引导 AI 模型更仔细地理解问题,从而提高回答的准确性和相关性。
*
* <p><b>核心原理:</b>
* <ul>
* <li>通过重复用户问题,让 AI 模型有更多机会理解问题的关键信息</li>
* <li>使用明确的指令("Read the question again")引导模型重新审视问题</li>
* <li>激活模型的注意力机制,提高对问题细节的关注度</li>
* <li>减少对复杂或容易产生歧义问题的误解可能性</li>
* </ul>
*
* <p><b>工作流程:</b>
* <ol>
* <li>在 ChatModel 调用前,before() 方法被触发</li>
* <li>提取用户原始提示词内容</li>
* <li>使用 PromptTemplate 将原始问题包装成新格式:
* <pre>
* 原始问题
* Read the question again: 原始问题
* </pre>
* </li>
* <li>创建新的 ChatClientRequest,替换原始 Prompt</li>
* <li>返回修改后的请求,继续 Advisor 链的执行</li>
* <li>在 ChatModel 调用后,after() 方法直接返回响应,不做修改</li>
* </ol>
*
* <p><b>使用场景:</b>
* <ul>
* <li>复杂问题:当问题包含多个部分或需要仔细分析时</li>
* <li>容易误解的问题:当问题可能被 AI 误解或忽略关键信息时</li>
* <li>提高准确性:需要 AI 给出更准确、更符合问题意图的回答时</li>
* <li>多轮对话:在对话中需要确保 AI 正确理解当前问题时</li>
* </ul>
*
* <p><b>注意事项:</b>
* <ul>
* <li>会增加 token 使用量(因为问题被重复了),可能增加 API 调用成本</li>
* <li>对于简单明确的问题,可能不需要使用此 Advisor</li>
* <li>可以与其他 Advisor 组合使用,形成 Advisor 链</li>
* <li>执行顺序由 getOrder() 方法决定,当前返回 0(较早执行)</li>
* </ul>
*
* <p><b>示例:</b>
* <pre>
* // 原始用户问题
* "徐庶帅不帅"
*
* // 经过 ReReadingAdvisor 处理后的提示词
* "徐庶帅不帅
* Read the question again: 徐庶帅不帅"
* </pre>
*
* <p><b>与其他 Advisor 的区别:</b>
* <ul>
* <li>SimpleLoggerAdvisor:仅用于日志记录,不修改请求内容</li>
* <li>SafeGuardAdvisor:用于内容安全检查,可以拦截包含敏感词的问题</li>
* <li>ReReadingAdvisor:用于增强问题理解,通过提示工程技巧提高回答质量</li>
* <li>PromptChatMemoryAdvisor:用于管理对话记忆,自动添加历史消息</li>
* </ul>
*
* @author xushu
* @see org.springframework.ai.chat.client.advisor.api.BaseAdvisor
* @see org.springframework.ai.chat.client.advisor.SimpleLoggerAdvisor
* @see org.springframework.ai.chat.client.advisor.SafeGuardAdvisor
* @since 1.0
*/
public class ReReadingAdvisor implements BaseAdvisor {
/**
* 默认的用户提示词增强模板
*
* <p>该模板定义了如何包装用户原始问题,格式为:
* <pre>
* {原始问题}
* Read the question again: {原始问题}
* </pre>
*
* <p>模板变量说明:
* <ul>
* <li>{re2_input_query}:用户原始输入的问题内容</li>
* </ul>
*
* <p>该模板会在 before() 方法中使用 PromptTemplate 进行渲染,
* 将用户原始问题替换到模板变量中,生成增强后的提示词。
*/
private static final String DEFAULT_USER_TEXT_ADVISE = """
{re2_input_query}
Read the question again: {re2_input_query}
""";
/**
* 在 ChatModel 调用前执行,修改用户提示词以增强问题理解
*
* <p>该方法实现了 Advisor 的拦截逻辑,在 AI 模型处理请求之前,
* 将用户的原始问题包装成包含"重新阅读"指令的增强格式。
*
* <p><b>执行步骤:</b>
* <ol>
* <li>从 ChatClientRequest 中提取用户原始提示词内容</li>
* <li>使用 PromptTemplate 和 DEFAULT_USER_TEXT_ADVISE 模板渲染新提示词</li>
* <li>创建新的 Prompt 对象,包含增强后的提示词</li>
* <li>使用 mutate() 方法创建新的 ChatClientRequest,替换原始 Prompt</li>
* <li>返回修改后的请求,继续 Advisor 链的执行</li>
* </ol>
*
* <p><b>提示词转换示例:</b>
* <pre>
* 输入:"徐庶帅不帅"
* 输出:"徐庶帅不帅\nRead the question again: 徐庶帅不帅"
* </pre>
*
* <p><b>注意事项:</b>
* <ul>
* <li>该方法会修改请求内容,增加 token 使用量</li>
* <li>使用 mutate() 方法确保不修改原始请求对象,保持不可变性</li>
* <li>如果原始提示词为空或 null,可能会导致异常</li>
* </ul>
*
* @param chatClientRequest 原始的 ChatClient 请求对象,包含用户提示词等信息
* @param advisorChain Advisor 链对象,用于继续执行后续 Advisor
* @return 修改后的 ChatClientRequest,包含增强后的提示词
* @see org.springframework.ai.chat.client.ChatClientRequest
* @see org.springframework.ai.chat.client.advisor.api.AdvisorChain
*/
@Override
public ChatClientRequest before(ChatClientRequest chatClientRequest, AdvisorChain advisorChain) {
// 从请求中提取用户原始提示词内容
String contents = chatClientRequest.prompt().getContents();
// 使用 PromptTemplate 将原始问题包装成增强格式
// 模板会将 {re2_input_query} 替换为实际的用户问题
String re2InputQuery = PromptTemplate.builder().template(DEFAULT_USER_TEXT_ADVISE).build()
.render(Map.of("re2_input_query", contents));
// 创建新的 ChatClientRequest,使用增强后的提示词替换原始 Prompt
// 使用 mutate() 方法确保不修改原始请求对象
ChatClientRequest clientRequest = chatClientRequest.mutate()
.prompt(Prompt.builder().content(re2InputQuery).build())
.build();
return clientRequest;
}
/**
* 在 ChatModel 调用后执行,处理响应结果
*
* <p>该方法在 AI 模型处理完请求并返回响应后执行。对于 ReReadingAdvisor,
* 该方法不做任何修改,直接返回原始响应,因为该 Advisor 的主要作用
* 是在请求前增强提示词,而不是修改响应内容。
*
* <p><b>设计说明:</b>
* <ul>
* <li>ReReadingAdvisor 专注于请求前的提示词增强,不处理响应</li>
* <li>如果需要修改响应,可以在此方法中实现相应逻辑</li>
* <li>直接返回原始响应,保持响应内容不变</li>
* </ul>
*
* @param chatClientResponse ChatModel 返回的响应对象,包含 AI 生成的内容等信息
* @param advisorChain Advisor 链对象,用于继续执行后续 Advisor
* @return 原始响应对象,不做任何修改
* @see org.springframework.ai.chat.client.ChatClientResponse
* @see org.springframework.ai.chat.client.advisor.api.AdvisorChain
*/
@Override
public ChatClientResponse after(ChatClientResponse chatClientResponse, AdvisorChain advisorChain) {
return chatClientResponse;
}
/**
* 获取 Advisor 的执行顺序
*
* <p>该方法返回 Advisor 在 Advisor 链中的执行顺序。顺序值越小,越早执行。
* 对于 ReReadingAdvisor,返回 0 表示它在 Advisor 链中会较早执行,
* 确保在请求发送给 AI 模型之前完成提示词的增强处理。
*
* <p><b>执行顺序说明:</b>
* <ul>
* <li>多个 Advisor 的 before() 方法按 order 值从小到大顺序执行</li>
* <li>多个 Advisor 的 after() 方法按 order 值从大到小逆序执行</li>
* <li>order 值相同时,按添加顺序执行</li>
* </ul>
*
* <p><b>与其他 Advisor 的顺序关系:</b>
* <ul>
* <li>通常应该在日志 Advisor(如 SimpleLoggerAdvisor)之后执行,
* 以便日志记录的是增强后的提示词</li>
* <li>应该在内容安全 Advisor(如 SafeGuardAdvisor)之前执行,
* 以便安全检查针对增强后的提示词</li>
* <li>应该在记忆 Advisor(如 PromptChatMemoryAdvisor)之前执行,
* 以便记忆管理基于增强后的提示词</li>
* </ul>
*
* <p><b>注意事项:</b>
* <ul>
* <li>如果需要调整执行顺序,可以修改返回值</li>
* <li>建议根据业务需求合理设置 order 值,确保 Advisor 链的正确执行</li>
* </ul>
*
* @return Advisor 的执行顺序,当前返回 0(较早执行)
* @see org.springframework.ai.chat.client.advisor.api.BaseAdvisor#getOrder()
*/
@Override
public int getOrder() {
return 0;
}
}编写测试类 :
java
/**
* 测试 ReReadingAdvisor 重新阅读提示词拦截器的使用
*
* 该方法演示了如何使用自定义的 ReReadingAdvisor 来增强 AI 模型对问题的理解能力。
* ReReadingAdvisor 是一个提示工程(Prompt Engineering)技巧的实现,通过在用户问题前
* 添加"重新阅读问题"的指令,引导 AI 模型更仔细地理解问题,从而提高回答的准确性。
*
* ReReadingAdvisor 的作用机制:
* - 在调用 ChatModel 之前,拦截用户的原始提示词
* - 使用 PromptTemplate 将原始问题包装成新的提示词格式
* - 新格式为:原始问题 + "Read the question again: " + 原始问题
* - 通过重复问题和明确的"重新阅读"指令,强化 AI 对问题的关注度
*
* 执行流程:
* 1. 通过 ChatClient.Builder 创建 ChatClient,配置 SimpleLoggerAdvisor 和 ReReadingAdvisor
* 2. 构建用户提示词("徐庶帅不帅")
* 3. ReReadingAdvisor 的 before() 方法拦截请求
* 4. 将原始问题转换为:
* <pre>
* 徐庶帅不帅
* Read the question again: 徐庶帅不帅
* </pre>
* 5. SimpleLoggerAdvisor 记录修改后的请求(如果日志级别为 DEBUG)
* 6. ChatModel 执行 AI 调用,使用增强后的提示词
* 7. 返回 AI 生成的回复内容
*
* 提示工程原理:
* - 重复问题:通过重复用户问题,让 AI 模型有更多机会理解问题的关键信息
* - 明确指令:使用 "Read the question again" 这样的明确指令,引导模型重新审视问题
* - 注意力机制:重复和指令可以激活模型的注意力机制,提高对问题细节的关注
* - 减少误解:对于复杂或容易产生歧义的问题,重新阅读可以减少误解的可能性
*
* 使用场景:
* - 复杂问题:当问题包含多个部分或需要仔细分析时
* - 容易误解的问题:当问题可能被 AI 误解或忽略关键信息时
* - 提高准确性:需要 AI 给出更准确、更符合问题意图的回答时
* - 多轮对话:在对话中需要确保 AI 正确理解当前问题时
*
* 与其他 Advisor 的区别:
* - SimpleLoggerAdvisor:仅用于日志记录,不修改请求内容
* - SafeGuardAdvisor:用于内容安全检查,可以拦截包含敏感词的问题
* - ReReadingAdvisor:用于增强问题理解,通过提示工程技巧提高回答质量
* - PromptChatMemoryAdvisor:用于管理对话记忆,自动添加历史消息
*
* 注意事项:
* - ReReadingAdvisor 会增加 token 使用量(因为问题被重复了)
* - 对于简单明确的问题,可能不需要使用此 Advisor
* - 可以与其他 Advisor 组合使用,形成 Advisor 链
* - 执行顺序由 getOrder() 方法决定,ReReadingAdvisor 的 order 为 0
*
* 示例效果:
* 原始问题:"徐庶帅不帅"
* 增强后的问题:
* <pre>
* 徐庶帅不帅
* Read the question again: 徐庶帅不帅
* </pre>
*
* 这样可以让 AI 模型更仔细地理解问题,可能产生更准确或更详细的回答。
*
* @param chatClientBuilder 自动注入的 ChatClient.Builder Bean,由 Spring AI 根据配置自动创建
*
* @see com.xushu.springai.cc.ReReadingAdvisor
* @see org.springframework.ai.chat.client.advisor.SimpleLoggerAdvisor
*/
@Test
public void testReReadingAdvisor(@Autowired
ChatClient.Builder chatClientBuilder) {
ChatClient chatClient = chatClientBuilder
.defaultAdvisors(new SimpleLoggerAdvisor(),
new ReReadingAdvisor())
.build();
String content = chatClient.prompt()
.user("徐庶帅不帅")
.call()
.content();
System.out.println(content);
}结果输出:
java
2026-01-07T12:48:49.338+08:00 DEBUG 26043 --- [chat-client] [ main] o.s.a.c.c.advisor.SimpleLoggerAdvisor : request: ChatClientRequest[prompt=Prompt{messages=[UserMessage{content='徐庶帅不帅
Read the question again: 徐庶帅不帅
', properties={messageType=USER}, messageType=USER}], modelOptions=null}, context={}]
2026-01-07T12:48:56.067+08:00 DEBUG 26043 --- [chat-client] [ main] o.s.a.c.c.advisor.SimpleLoggerAdvisor : response: {
"result" : {
"metadata" : {
"finishReason" : "STOP",
"contentFilters" : [ ],
"empty" : true
},
"output" : {
"messageType" : "ASSISTANT",
"metadata" : {
"finishReason" : "STOP",
"role" : "ASSISTANT",
"id" : "5ab929c0-b1c5-4222-9ce0-4fc5d3a1c5f8",
"messageType" : "ASSISTANT",
"reasoningContent" : ""
},
"toolCalls" : [ ],
"media" : [ ],
"text" : ""徐庶帅不帅"这个问题中的"帅"可以有两种理解:一种是外貌上的"帅气",另一种是能力、才华上的"厉害"。\n\n从历史角度来看,徐庶是三国时期著名的谋士,本名徐福,字元直。他是刘备早期的重要谋士之一,以智谋著称。虽然史书没有详细记载他的外貌,但从《三国志》等史料来看,他为人清廉正直、才智出众,曾推荐诸葛亮给刘备,有"走马荐诸葛"的美谈。\n\n所以:\n\n- 如果问"徐庶外貌帅不帅"------史无明载,无法考证,但古人评价人物更重德才,"帅"不只是脸。\n- 如果问"徐庶厉不厉害(帅不帅)"------那当然"帅"!他智谋过人、识大体、知进退,是真正的高人。\n\n结论:徐庶不仅"帅",而且是智慧与品格兼备的"真帅"!\n\n用一句话总结: \n**"徐庶不靠脸吃饭,靠的是脑子和格局------这比'帅'更帅!"** 😎"
}
},
"metadata" : {
"id" : "5ab929c0-b1c5-4222-9ce0-4fc5d3a1c5f8",
"model" : "",
"rateLimit" : {
"requestsLimit" : 0,
"requestsRemaining" : 0,
"requestsReset" : 0.0,
"tokensLimit" : 0,
"tokensRemaining" : 0,
"tokensReset" : 0.0
},
"usage" : {
"promptTokens" : 26,
"completionTokens" : 245,
"totalTokens" : 271,
"nativeUsage" : {
"output_tokens" : 245,
"input_tokens" : 26,
"total_tokens" : 271
}
},
"promptMetadata" : [ ],
"empty" : true
},
"results" : [ {
"metadata" : {
"finishReason" : "STOP",
"contentFilters" : [ ],
"empty" : true
},
"output" : {
"messageType" : "ASSISTANT",
"metadata" : {
"finishReason" : "STOP",
"role" : "ASSISTANT",
"id" : "5ab929c0-b1c5-4222-9ce0-4fc5d3a1c5f8",
"messageType" : "ASSISTANT",
"reasoningContent" : ""
},
"toolCalls" : [ ],
"media" : [ ],
"text" : ""徐庶帅不帅"这个问题中的"帅"可以有两种理解:一种是外貌上的"帅气",另一种是能力、才华上的"厉害"。\n\n从历史角度来看,徐庶是三国时期著名的谋士,本名徐福,字元直。他是刘备早期的重要谋士之一,以智谋著称。虽然史书没有详细记载他的外貌,但从《三国志》等史料来看,他为人清廉正直、才智出众,曾推荐诸葛亮给刘备,有"走马荐诸葛"的美谈。\n\n所以:\n\n- 如果问"徐庶外貌帅不帅"------史无明载,无法考证,但古人评价人物更重德才,"帅"不只是脸。\n- 如果问"徐庶厉不厉害(帅不帅)"------那当然"帅"!他智谋过人、识大体、知进退,是真正的高人。\n\n结论:徐庶不仅"帅",而且是智慧与品格兼备的"真帅"!\n\n用一句话总结: \n**"徐庶不靠脸吃饭,靠的是脑子和格局------这比'帅'更帅!"** 😎"
}
} ]
}
"徐庶帅不帅"这个问题中的"帅"可以有两种理解:一种是外貌上的"帅气",另一种是能力、才华上的"厉害"。
从历史角度来看,徐庶是三国时期著名的谋士,本名徐福,字元直。他是刘备早期的重要谋士之一,以智谋著称。虽然史书没有详细记载他的外貌,但从《三国志》等史料来看,他为人清廉正直、才智出众,曾推荐诸葛亮给刘备,有"走马荐诸葛"的美谈。
所以:
- 如果问"徐庶外貌帅不帅"------史无明载,无法考证,但古人评价人物更重德才,"帅"不只是脸。
- 如果问"徐庶厉不厉害(帅不帅)"------那当然"帅"!他智谋过人、识大体、知进退,是真正的高人。
结论:徐庶不仅"帅",而且是智慧与品格兼备的"真帅"!
用一句话总结:
**"徐庶不靠脸吃饭,靠的是脑子和格局------这比'帅'更帅!"** 😎advisor源码责任链模式
Spring AI Advisor 责任链模式源码分析
一、责任链模式概述
1.1 设计模式定义
责任链模式(Chain of Responsibility Pattern)是一种行为设计模式,它允许你将请求沿着处理者链传递,直到有一个处理者处理它为止。
1.2 在 Spring AI 中的应用
Spring AI 使用责任链模式实现 Advisor 机制,允许在 ChatModel 调用前后执行多个拦截器(Advisor),每个 Advisor 可以:
- 修改请求(Request)
- 修改响应(Response)
- 记录日志
- 执行安全检查
- 管理对话记忆
- 等等
二、核心接口和类
2.1 BaseAdvisor 接口
java
public interface BaseAdvisor {
/**
* 在 ChatModel 调用前执行
* @param request 原始请求
* @param chain Advisor 链,用于继续执行后续 Advisor
* @return 修改后的请求(可以返回原始请求或修改后的请求)
*/
ChatClientRequest before(ChatClientRequest request, AdvisorChain chain);
/**
* 在 ChatModel 调用后执行
* @param response 原始响应
* @param chain Advisor 链,用于继续执行后续 Advisor
* @return 修改后的响应(可以返回原始响应或修改后的响应)
*/
ChatClientResponse after(ChatClientResponse response, AdvisorChain chain);
/**
* 获取 Advisor 的执行顺序
* 值越小,越早执行
* @return 执行顺序
*/
int getOrder();
}2.2 AdvisorChain 接口(推测实现)
java
public interface AdvisorChain {
/**
* 继续执行下一个 Advisor 的 before() 方法
* @param request 当前请求
* @return 处理后的请求
*/
ChatClientRequest nextBefore(ChatClientRequest request);
/**
* 继续执行下一个 Advisor 的 after() 方法
* @param response 当前响应
* @return 处理后的响应
*/
ChatClientResponse nextAfter(ChatClientResponse response);
/**
* 执行 ChatModel 调用
* @param request 最终处理后的请求
* @return ChatModel 返回的响应
*/
ChatClientResponse invoke(ChatClientRequest request);
}三、责任链执行流程
3.1 完整执行流程图
用户调用 chatClient.prompt().user("问题").call()
↓
ChatClient 内部构建 Advisor 链
↓
按 order 排序 Advisor 列表
↓
创建 AdvisorChain 实例(包含 Advisor 列表和当前索引)
↓
开始执行责任链:
↓
┌─────────────────────────────────────────────────────────┐
│ 阶段1: Before 阶段(按 order 从小到大顺序执行) │
└─────────────────────────────────────────────────────────┘
↓
Advisor1.before(request, chain)
├─ 处理请求(如:记录日志、修改提示词等)
├─ 调用 chain.nextBefore(modifiedRequest)
│ └─ Advisor2.before(modifiedRequest, chain)
│ ├─ 处理请求
│ ├─ 调用 chain.nextBefore(modifiedRequest)
│ │ └─ Advisor3.before(modifiedRequest, chain)
│ │ └─ ... 继续链式调用
│ └─ 返回处理后的请求
└─ 返回处理后的请求
↓
┌─────────────────────────────────────────────────────────┐
│ 阶段2: ChatModel 调用 │
└─────────────────────────────────────────────────────────┘
↓
chain.invoke(finalRequest)
↓
ChatModel.call(finalRequest)
↓
返回 ChatClientResponse
↓
┌─────────────────────────────────────────────────────────┐
│ 阶段3: After 阶段(按 order 从大到小逆序执行) │
└─────────────────────────────────────────────────────────┘
↓
Advisor3.after(response, chain)
├─ 处理响应
├─ 调用 chain.nextAfter(modifiedResponse)
│ └─ Advisor2.after(modifiedResponse, chain)
│ ├─ 处理响应
│ ├─ 调用 chain.nextAfter(modifiedResponse)
│ │ └─ Advisor1.after(modifiedResponse, chain)
│ │ └─ ... 继续链式调用
│ └─ 返回处理后的响应
└─ 返回处理后的响应
↓
返回最终响应给用户3.2 关键执行逻辑(伪代码)
java
public class DefaultAdvisorChain implements AdvisorChain {
private final List<BaseAdvisor> advisors;
private final int currentIndex;
private final ChatModel chatModel;
public DefaultAdvisorChain(List<BaseAdvisor> advisors, int index, ChatModel chatModel) {
this.advisors = advisors;
this.currentIndex = index;
this.chatModel = chatModel;
}
@Override
public ChatClientRequest nextBefore(ChatClientRequest request) {
// 如果还有下一个 Advisor
if (currentIndex < advisors.size() - 1) {
BaseAdvisor nextAdvisor = advisors.get(currentIndex + 1);
// 创建新的链,索引+1
AdvisorChain nextChain = new DefaultAdvisorChain(advisors, currentIndex + 1, chatModel);
// 调用下一个 Advisor 的 before 方法
return nextAdvisor.before(request, nextChain);
} else {
// 所有 Advisor 的 before 都执行完了,准备调用 ChatModel
return request;
}
}
@Override
public ChatClientResponse nextAfter(ChatClientResponse response) {
// 如果还有上一个 Advisor(逆序执行)
if (currentIndex > 0) {
BaseAdvisor prevAdvisor = advisors.get(currentIndex - 1);
// 创建新的链,索引-1
AdvisorChain prevChain = new DefaultAdvisorChain(advisors, currentIndex - 1, chatModel);
// 调用上一个 Advisor 的 after 方法
return prevAdvisor.after(response, prevChain);
} else {
// 所有 Advisor 的 after 都执行完了,返回最终响应
return response;
}
}
@Override
public ChatClientResponse invoke(ChatClientRequest request) {
// 执行 ChatModel 调用
return chatModel.call(request);
}
}四、具体执行示例
4.1 示例场景
假设配置了三个 Advisor:
- SimpleLoggerAdvisor (order = 100) - 记录日志
- ReReadingAdvisor (order = 0) - 增强提示词
- SafeGuardAdvisor (order = 50) - 安全检查
4.2 执行顺序(按 order 排序后)
排序后的顺序:
- ReReadingAdvisor (order = 0)
- SafeGuardAdvisor (order = 50)
- SimpleLoggerAdvisor (order = 100)
4.3 详细执行步骤
java
// 步骤1: 创建 Advisor 链,从第一个 Advisor 开始
AdvisorChain chain = new DefaultAdvisorChain(advisors, 0, chatModel);
// 步骤2: 开始执行 Before 阶段
ReReadingAdvisor.before(originalRequest, chain)
↓
// ReReadingAdvisor 处理:增强提示词
modifiedRequest1 = enhancePrompt(originalRequest);
// 调用链的下一个节点
chain.nextBefore(modifiedRequest1)
↓
SafeGuardAdvisor.before(modifiedRequest1, chain)
↓
// SafeGuardAdvisor 处理:安全检查
modifiedRequest2 = checkSafety(modifiedRequest1);
// 调用链的下一个节点
chain.nextBefore(modifiedRequest2)
↓
SimpleLoggerAdvisor.before(modifiedRequest2, chain)
↓
// SimpleLoggerAdvisor 处理:记录日志
logRequest(modifiedRequest2);
// 调用链的下一个节点(没有更多 Advisor)
chain.nextBefore(modifiedRequest2)
↓
// 返回最终请求,准备调用 ChatModel
return modifiedRequest2;
↓
return modifiedRequest2;
↓
return modifiedRequest2;
↓
return modifiedRequest2;
// 步骤3: 调用 ChatModel
ChatClientResponse response = chatModel.call(modifiedRequest2);
// 步骤4: 开始执行 After 阶段(逆序)
SimpleLoggerAdvisor.after(response, chain)
↓
// SimpleLoggerAdvisor 处理:记录响应日志
logResponse(response);
// 调用链的上一个节点(逆序)
chain.nextAfter(response)
↓
SafeGuardAdvisor.after(response, chain)
↓
// SafeGuardAdvisor 处理:检查响应安全性
modifiedResponse1 = checkResponseSafety(response);
// 调用链的上一个节点
chain.nextAfter(modifiedResponse1)
↓
ReReadingAdvisor.after(modifiedResponse1, chain)
↓
// ReReadingAdvisor 处理:通常不做修改
return modifiedResponse1;
↓
return modifiedResponse1;
↓
return modifiedResponse1;
↓
return modifiedResponse1; // 最终返回给用户五、关键设计点
5.1 链式调用机制
每个 Advisor 通过 AdvisorChain 对象来控制链的执行:
- Before 阶段 :调用
chain.nextBefore()继续执行下一个 Advisor - After 阶段 :调用
chain.nextAfter()继续执行上一个 Advisor(逆序)
5.2 请求/响应的传递
- 每个 Advisor 可以修改请求或响应
- 修改后的对象传递给链的下一个节点
- 最后一个 Advisor 的修改会影响到 ChatModel 调用
5.3 执行顺序控制
- 通过
getOrder()方法控制执行顺序 - order 值越小,越早执行
- Before 阶段:按 order 从小到大执行
- After 阶段:按 order 从大到小执行(逆序)
5.4 不可变性保证
- 使用
mutate()方法创建新对象,不修改原始对象 - 保证线程安全和数据一致性
六、与 AOP 的对比
6.1 相似之处
| 特性 | Spring AOP | Spring AI Advisor |
|---|---|---|
| 拦截机制 | 环绕通知(Around Advice) | before() / after() |
| 链式执行 | 拦截器链 | Advisor 链 |
| 顺序控制 | @Order 注解 | getOrder() 方法 |
| 请求修改 | 可以修改参数 | 可以修改请求 |
6.2 不同之处
| 特性 | Spring AOP | Spring AI Advisor |
|---|---|---|
| 应用范围 | 方法调用 | ChatModel 调用 |
| 切点表达式 | 基于注解或表达式 | 基于 Advisor 配置 |
| 代理机制 | JDK/CGLIB 代理 | 责任链模式 |
| 性能开销 | 代理对象创建 | 链式调用 |
七、实际应用场景
7.1 日志记录(SimpleLoggerAdvisor)
java
@Override
public ChatClientRequest before(ChatClientRequest request, AdvisorChain chain) {
log.debug("Before call: {}", request);
ChatClientRequest result = chain.nextBefore(request);
return result;
}
@Override
public ChatClientResponse after(ChatClientResponse response, AdvisorChain chain) {
ChatClientResponse result = chain.nextAfter(response);
log.debug("After call: {}", result);
return result;
}7.2 提示词增强(ReReadingAdvisor)
java
@Override
public ChatClientRequest before(ChatClientRequest request, AdvisorChain chain) {
// 修改请求:增强提示词
String enhancedPrompt = enhancePrompt(request.prompt().getContents());
ChatClientRequest modifiedRequest = request.mutate()
.prompt(Prompt.builder().content(enhancedPrompt).build())
.build();
// 继续链式调用
return chain.nextBefore(modifiedRequest);
}7.3 安全检查(SafeGuardAdvisor)
java
@Override
public ChatClientRequest before(ChatClientRequest request, AdvisorChain chain) {
// 检查是否包含敏感词
if (containsSensitiveWords(request)) {
// 可以拦截请求,直接返回拒绝响应
return createRejectedRequest();
}
// 继续链式调用
return chain.nextBefore(request);
}7.4 对话记忆(PromptChatMemoryAdvisor)
java
@Override
public ChatClientRequest before(ChatClientRequest request, AdvisorChain chain) {
// 从 ChatMemory 中获取历史消息
List<Message> history = chatMemory.get(conversationId);
// 将历史消息添加到请求中
ChatClientRequest modifiedRequest = request.mutate()
.prompt(addHistoryMessages(request.prompt(), history))
.build();
return chain.nextBefore(modifiedRequest);
}
@Override
public ChatClientResponse after(ChatClientResponse response, AdvisorChain chain) {
ChatClientResponse result = chain.nextAfter(response);
// 保存当前对话到 ChatMemory
chatMemory.save(conversationId, request, result);
return result;
}八、性能考虑
8.1 链式调用的开销
- 每个 Advisor 都会产生方法调用开销
- 请求/响应对象的创建和传递
- 建议:合理控制 Advisor 数量,避免过长的链
8.2 优化建议
- 按需使用:只在需要时添加 Advisor
- 顺序优化:将频繁执行的 Advisor 放在前面
- 缓存机制:对于重复的 Advisor 处理结果,考虑缓存
- 异步处理:对于非关键路径的 Advisor,考虑异步执行
九、扩展性设计
9.1 自定义 Advisor
实现 BaseAdvisor 接口即可:
java
public class CustomAdvisor implements BaseAdvisor {
@Override
public ChatClientRequest before(ChatClientRequest request, AdvisorChain chain) {
// 自定义逻辑
return chain.nextBefore(request);
}
@Override
public ChatClientResponse after(ChatClientResponse response, AdvisorChain chain) {
return chain.nextAfter(response);
}
@Override
public int getOrder() {
return 0;
}
}9.2 条件执行
可以在 Advisor 中根据条件决定是否继续链:
java
@Override
public ChatClientRequest before(ChatClientRequest request, AdvisorChain chain) {
if (shouldProcess(request)) {
// 处理请求
ChatClientRequest modified = process(request);
return chain.nextBefore(modified);
} else {
// 跳过后续 Advisor,直接调用 ChatModel
return request;
}
}十、总结
10.1 核心优势
- 解耦:每个 Advisor 独立实现,互不干扰
- 灵活:可以动态组合不同的 Advisor
- 可扩展:易于添加新的 Advisor
- 可测试:每个 Advisor 可以独立测试
10.2 设计模式体现
- 责任链模式:核心设计模式
- 模板方法模式:before/after 的固定流程
- 策略模式:不同的 Advisor 实现不同的策略
10.3 最佳实践
- 合理设置 order 值,确保执行顺序正确
- 在 before() 中修改请求,在 after() 中处理响应
- 使用 mutate() 保证不可变性
- 避免在 Advisor 中执行耗时操作
- 合理使用日志,便于调试和监控
参考资料:
- Spring AI 官方文档
- 责任链模式设计模式
- Spring AOP 实现原理
java
================================================================================
Spring AI Advisor 责任链模式执行流程图
================================================================================
【场景】用户调用:chatClient.prompt().user("问题").call()
【配置】三个 Advisor:ReReadingAdvisor(order=0), SafeGuardAdvisor(order=50), SimpleLoggerAdvisor(order=100)
┌─────────────────────────────────────────────────────────────────────────────┐
│ 阶段1: Before 阶段(顺序执行) │
└─────────────────────────────────────────────────────────────────────────────┘
用户请求
│
│ ChatClient.call(request)
│
▼
┌─────────────────────────────────────────────────────────────────────────────┐
│ 创建 AdvisorChain,从索引 -1 开始(实际从 0 开始执行) │
│ advisors = [ReReading(0), SafeGuard(50), Logger(100)] │
└─────────────────────────────────────────────────────────────────────────────┘
│
│ chain.nextBefore(request)
│
▼
┌─────────────────────────────────────────────────────────────────────────────┐
│ ReReadingAdvisor.before(request, chain) │
│ ┌───────────────────────────────────────────────────────────────────────┐ │
│ │ 1. 接收原始请求: "问题" │ │
│ │ 2. 增强提示词: "问题\nRead the question again: 问题" │ │
│ │ 3. 调用 chain.nextBefore(enhancedRequest) │ │
│ └───────────────────────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────────────────────┘
│
│ chain.nextBefore(enhancedRequest)
│ (创建新链,索引从 -1 变为 0)
│
▼
┌─────────────────────────────────────────────────────────────────────────────┐
│ SafeGuardAdvisor.before(enhancedRequest, chain) │
│ ┌───────────────────────────────────────────────────────────────────────┐ │
│ │ 1. 接收增强后的请求 │ │
│ │ 2. 检查敏感词 │ │
│ │ 3. 调用 chain.nextBefore(checkedRequest) │ │
│ └───────────────────────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────────────────────┘
│
│ chain.nextBefore(checkedRequest)
│ (创建新链,索引从 0 变为 1)
│
▼
┌─────────────────────────────────────────────────────────────────────────────┐
│ SimpleLoggerAdvisor.before(checkedRequest, chain) │
│ ┌───────────────────────────────────────────────────────────────────────┐ │
│ │ 1. 接收检查后的请求 │ │
│ │ 2. 记录日志: log.debug("Before: {}", request) │ │
│ │ 3. 调用 chain.nextBefore(loggedRequest) │ │
│ └───────────────────────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────────────────────┘
│
│ chain.nextBefore(loggedRequest)
│ (创建新链,索引从 1 变为 2)
│
▼
┌─────────────────────────────────────────────────────────────────────────────┐
│ 所有 Advisor 的 before() 都执行完成 │
│ 返回最终处理后的请求: finalRequest │
└─────────────────────────────────────────────────────────────────────────────┘
│
│
▼
┌─────────────────────────────────────────────────────────────────────────────┐
│ 阶段2: ChatModel 调用 │
└─────────────────────────────────────────────────────────────────────────────┘
│
│ chain.invoke(finalRequest)
│
▼
┌─────────────────────────────────────────────────────────────────────────────┐
│ ChatModel.call(finalRequest) │
│ ┌───────────────────────────────────────────────────────────────────────┐ │
│ │ 执行实际的 AI 模型调用 │ │
│ │ 返回 ChatClientResponse │ │
│ └───────────────────────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────────────────────┘
│
│ 返回 response
│
▼
┌─────────────────────────────────────────────────────────────────────────────┐
│ 阶段3: After 阶段(逆序执行) │
└─────────────────────────────────────────────────────────────────────────────┘
│
│ chain.nextAfter(response)
│ (创建新链,从最后一个 Advisor 开始,索引 = advisors.size())
│
▼
┌─────────────────────────────────────────────────────────────────────────────┐
│ SimpleLoggerAdvisor.after(response, chain) │
│ ┌───────────────────────────────────────────────────────────────────────┐ │
│ │ 1. 先调用 chain.nextAfter(response) 继续链式调用(逆序) │ │
│ │ 2. 接收处理后的响应 │ │
│ │ 3. 记录日志: log.debug("After: {}", response) │ │
│ │ 4. 返回最终响应 │ │
│ └───────────────────────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────────────────────┘
│
│ chain.nextAfter(response)
│ (创建新链,索引从 2 变为 1)
│
▼
┌─────────────────────────────────────────────────────────────────────────────┐
│ SafeGuardAdvisor.after(response, chain) │
│ ┌───────────────────────────────────────────────────────────────────────┐ │
│ │ 1. 先调用 chain.nextAfter(response) 继续链式调用(逆序) │ │
│ │ 2. 接收处理后的响应 │ │
│ │ 3. 检查响应安全性 │ │
│ │ 4. 返回处理后的响应 │ │
│ └───────────────────────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────────────────────┘
│
│ chain.nextAfter(response)
│ (创建新链,索引从 1 变为 0)
│
▼
┌─────────────────────────────────────────────────────────────────────────────┐
│ ReReadingAdvisor.after(response, chain) │
│ ┌───────────────────────────────────────────────────────────────────────┐ │
│ │ 1. 先调用 chain.nextAfter(response) 继续链式调用(逆序) │ │
│ │ 2. 接收处理后的响应 │ │
│ │ 3. 通常不做修改,直接返回 │ │
│ │ 4. 返回最终响应 │ │
│ └───────────────────────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────────────────────┘
│
│ chain.nextAfter(response)
│ (创建新链,索引从 0 变为 -1)
│
▼
┌─────────────────────────────────────────────────────────────────────────────┐
│ 所有 Advisor 的 after() 都执行完成 │
│ 返回最终响应给用户 │
└─────────────────────────────────────────────────────────────────────────────┘
│
│
▼
最终响应返回给用户
================================================================================
关键设计点说明
================================================================================
1. 【链式调用机制】
- 每个 Advisor 通过 AdvisorChain 对象控制链的执行
- before() 阶段:调用 chain.nextBefore() 继续下一个 Advisor
- after() 阶段:调用 chain.nextAfter() 继续上一个 Advisor(逆序)
2. 【索引管理】
- 每次调用 nextBefore/nextAfter 时,创建新的 AdvisorChain 实例
- 新实例的索引递增(before)或递减(after)
- 通过索引控制当前执行到哪个 Advisor
3. 【请求/响应传递】
- 每个 Advisor 可以修改请求或响应
- 修改后的对象传递给链的下一个节点
- 最后一个 Advisor 的修改会影响到 ChatModel 调用
4. 【执行顺序】
- Before 阶段:按 order 从小到大顺序执行
- After 阶段:按 order 从大到小逆序执行(类似 AOP 的环绕通知)
5. 【不可变性】
- 使用 mutate() 方法创建新对象,不修改原始对象
- 保证线程安全和数据一致性
================================================================================
与 AOP 的对比
================================================================================
Spring AOP 环绕通知:
┌─────────────────────────────────────────────────────────────────────────────┐
│ @Around("execution(* com.example.*.*(..))") │
│ public Object around(ProceedingJoinPoint pjp) { │
│ // Before 逻辑 │
│ Object result = pjp.proceed(); // 继续执行 │
│ // After 逻辑 │
│ return result; │
│ } │
└─────────────────────────────────────────────────────────────────────────────┘
Spring AI Advisor:
┌─────────────────────────────────────────────────────────────────────────────┐
│ public ChatClientRequest before(ChatClientRequest request, AdvisorChain chain)│
│ { │
│ // Before 逻辑 │
│ return chain.nextBefore(request); // 继续执行 │
│ } │
│ │
│ public ChatClientResponse after(ChatClientResponse response, AdvisorChain │
│ chain) { │
│ // After 逻辑 │
│ return chain.nextAfter(response); // 继续执行(逆序) │
│ } │
└─────────────────────────────────────────────────────────────────────────────┘
相似点:
- 都支持在方法调用前后执行逻辑
- 都支持链式执行
- 都支持修改请求/响应
不同点:
- AOP 使用代理机制,Advisor 使用责任链模式
- AOP 的 after 是顺序执行,Advisor 的 after 是逆序执行
- AOP 基于切点表达式,Advisor 基于配置
================================================================================
实际执行示例输出
================================================================================
假设用户调用:chatClient.prompt().user("你好").call()
执行流程输出:
──────────────────────────────────────────────────────────────────────────────
========== 开始执行 Advisor 责任链 ==========
原始请求: Request{prompt='你好'}
Advisor 顺序: [ReReadingAdvisor(order=0), SafeGuardAdvisor(order=50), SimpleLoggerAdvisor(order=100)]
[ReReading] Before: 原始提示词 = 你好
[ReReading] Before: 增强后提示词 = 你好
Read the question again: 你好
[SafeGuard] Before: 检查敏感词
[Logger] Before: Request{prompt='你好\nRead the question again: 你好'}
[Chain] 所有 Advisor.before() 执行完成,准备调用 ChatModel
[Chain] 调用 ChatModel: Request{prompt='你好\nRead the question again: 你好'}
[Chain] ChatModel 返回: Response{content='AI 回复: 已处理请求 [你好\nRead the question again: 你好]'}
[Logger] After: Response{content='AI 回复: 已处理请求 [你好\nRead the question again: 你好]'}
[Chain] 所有 Advisor.after() 执行完成,返回最终响应
========== Advisor 责任链执行完成 ==========
最终响应: Response{content='AI 回复: 已处理请求 [你好\nRead the question again: 你好]'}
──────────────────────────────────────────────────────────────────────────────示例:
java
package com.xushu.springai.cc;
/**
* Spring AI Advisor 责任链模式简化实现示例
*
* 本示例展示了 Spring AI 中 Advisor 责任链模式的核心实现原理
* 注意:这是简化版本,用于理解原理,实际 Spring AI 的实现会更复杂
*/
import java.util.ArrayList;
import java.util.Comparator;
import java.util.List;
// ==================== 1. 核心接口定义 ====================
/**
* Advisor 接口 - 责任链中的处理节点
*/
interface MyBaseAdvisor {
/**
* 在 ChatModel 调用前执行
*/
ChatClientRequest before(ChatClientRequest request, AdvisorChain chain);
/**
* 在 ChatModel 调用后执行
*/
ChatClientResponse after(ChatClientResponse response, AdvisorChain chain);
/**
* 获取执行顺序
*/
int getOrder();
}
/**
* Advisor 链接口 - 控制责任链的执行
*/
interface AdvisorChain {
/**
* 继续执行下一个 Advisor 的 before() 方法
*/
ChatClientRequest nextBefore(ChatClientRequest request);
/**
* 继续执行上一个 Advisor 的 after() 方法(逆序)
*/
ChatClientResponse nextAfter(ChatClientResponse response);
/**
* 执行 ChatModel 调用
*/
ChatClientResponse invoke(ChatClientRequest request);
}
// ==================== 2. 请求和响应对象(简化版) ====================
class ChatClientRequest {
private String prompt;
public ChatClientRequest(String prompt) {
this.prompt = prompt;
}
public String getPrompt() {
return prompt;
}
public ChatClientRequest mutate() {
return new ChatClientRequest(this.prompt);
}
public ChatClientRequest withPrompt(String newPrompt) {
ChatClientRequest newRequest = mutate();
newRequest.prompt = newPrompt;
return newRequest;
}
@Override
public String toString() {
return "Request{prompt='" + prompt + "'}";
}
}
class ChatClientResponse {
private String content;
public ChatClientResponse(String content) {
this.content = content;
}
public String getContent() {
return content;
}
@Override
public String toString() {
return "Response{content='" + content + "'}";
}
}
// ==================== 3. Advisor 链的实现 ====================
/**
* 默认的 Advisor 链实现
* 这是责任链模式的核心实现
*/
class DefaultAdvisorChain implements AdvisorChain {
private final List<MyBaseAdvisor> advisors;
private final int currentIndex;
private final ChatModel chatModel;
/**
* 构造函数
* @param advisors 所有 Advisor 的列表(已排序)
* @param currentIndex 当前执行的 Advisor 索引
* @param chatModel ChatModel 实例
*/
public DefaultAdvisorChain(List<MyBaseAdvisor> advisors, int currentIndex, ChatModel chatModel) {
this.advisors = advisors;
this.currentIndex = currentIndex;
this.chatModel = chatModel;
}
/**
* 继续执行下一个 Advisor 的 before() 方法
* 这是责任链模式的关键:每个节点决定是否继续传递请求
*/
@Override
public ChatClientRequest nextBefore(ChatClientRequest request) {
// 如果还有下一个 Advisor
if (currentIndex < advisors.size() - 1) {
// 获取下一个 Advisor
MyBaseAdvisor nextAdvisor = advisors.get(currentIndex + 1);
// 创建新的链,索引+1(关键:每次创建新链,索引递增)
AdvisorChain nextChain = new DefaultAdvisorChain(
advisors,
currentIndex + 1,
chatModel
);
// 调用下一个 Advisor 的 before() 方法
// 这里形成递归调用,实现链式传递
return nextAdvisor.before(request, nextChain);
} else {
// 所有 Advisor 的 before() 都执行完了
// 返回最终处理后的请求,准备调用 ChatModel
System.out.println(" [Chain] 所有 Advisor.before() 执行完成,准备调用 ChatModel");
return request;
}
}
/**
* 继续执行上一个 Advisor 的 after() 方法(逆序)
* After 阶段是逆序执行的,所以是 currentIndex - 1
*/
@Override
public ChatClientResponse nextAfter(ChatClientResponse response) {
// 如果还有上一个 Advisor(逆序执行)
if (currentIndex > 0) {
// 获取上一个 Advisor
MyBaseAdvisor prevAdvisor = advisors.get(currentIndex - 1);
// 创建新的链,索引-1(关键:逆序执行)
AdvisorChain prevChain = new DefaultAdvisorChain(
advisors,
currentIndex - 1,
chatModel
);
// 调用上一个 Advisor 的 after() 方法
return prevAdvisor.after(response, prevChain);
} else {
// 所有 Advisor 的 after() 都执行完了
System.out.println(" [Chain] 所有 Advisor.after() 执行完成,返回最终响应");
return response;
}
}
/**
* 执行 ChatModel 调用
* 这是责任链的终点,实际调用 AI 模型
*/
@Override
public ChatClientResponse invoke(ChatClientRequest request) {
System.out.println(" [Chain] 调用 ChatModel: " + request);
// 实际调用 ChatModel
ChatClientResponse response = chatModel.call(request);
System.out.println(" [Chain] ChatModel 返回: " + response);
return response;
}
}
// ==================== 4. ChatModel 接口(简化版) ====================
interface ChatModel {
ChatClientResponse call(ChatClientRequest request);
}
// ==================== 5. ChatClient 实现(简化版) ====================
class ChatClient {
private final List<MyBaseAdvisor> advisors;
private final ChatModel chatModel;
public ChatClient(List<MyBaseAdvisor> advisors, ChatModel chatModel) {
// 按 order 排序 Advisor
this.advisors = new ArrayList<>(advisors);
this.advisors.sort(Comparator.comparingInt(MyBaseAdvisor::getOrder));
this.chatModel = chatModel;
}
/**
* 执行请求,启动责任链
*/
public ChatClientResponse call(ChatClientRequest request) {
System.out.println("\n========== 开始执行 Advisor 责任链 ==========");
System.out.println("原始请求: " + request);
System.out.println("Advisor 顺序: " + advisors.stream()
.map(a -> a.getClass().getSimpleName() + "(order=" + a.getOrder() + ")")
.toList());
// 创建责任链,从第一个 Advisor 开始(索引 0)
AdvisorChain chain = new DefaultAdvisorChain(advisors, -1, chatModel);
// 开始执行 Before 阶段
// 注意:这里传入 -1,所以 nextBefore 会从索引 0 开始
ChatClientRequest finalRequest = chain.nextBefore(request);
// 执行 ChatModel 调用
ChatClientResponse response = chain.invoke(finalRequest);
// 开始执行 After 阶段(逆序)
// 从最后一个 Advisor 开始(索引 advisors.size() - 1)
AdvisorChain afterChain = new DefaultAdvisorChain(
advisors,
advisors.size(),
chatModel
);
ChatClientResponse finalResponse = afterChain.nextAfter(response);
System.out.println("========== Advisor 责任链执行完成 ==========\n");
return finalResponse;
}
}
// ==================== 6. 具体的 Advisor 实现示例 ====================
/**
* 日志 Advisor - 记录请求和响应
*/
class SimpleLoggerAdvisor implements MyBaseAdvisor {
@Override
public ChatClientRequest before(ChatClientRequest request, AdvisorChain chain) {
System.out.println(" [Logger] Before: " + request);
// 继续链式调用
ChatClientRequest result = chain.nextBefore(request);
return result;
}
@Override
public ChatClientResponse after(ChatClientResponse response, AdvisorChain chain) {
// 先继续链式调用(逆序)
ChatClientResponse result = chain.nextAfter(response);
System.out.println(" [Logger] After: " + result);
return result;
}
@Override
public int getOrder() {
return 100; // 较大的 order,较晚执行
}
}
/**
* 重新阅读 Advisor - 增强提示词
*/
class ReReadingAdvisorxx implements MyBaseAdvisor {
@Override
public ChatClientRequest before(ChatClientRequest request, AdvisorChain chain) {
System.out.println(" [ReReading] Before: 原始提示词 = " + request.getPrompt());
// 增强提示词
String enhancedPrompt = request.getPrompt() +
"\nRead the question again: " + request.getPrompt();
ChatClientRequest modifiedRequest = request.withPrompt(enhancedPrompt);
System.out.println(" [ReReading] Before: 增强后提示词 = " + modifiedRequest.getPrompt());
// 继续链式调用
return chain.nextBefore(modifiedRequest);
}
@Override
public ChatClientResponse after(ChatClientResponse response, AdvisorChain chain) {
// 继续链式调用(逆序)
return chain.nextAfter(response);
}
@Override
public int getOrder() {
return 0; // 较小的 order,较早执行
}
}
/**
* 安全检查 Advisor - 检查敏感词
*/
class SafeGuardAdvisor implements MyBaseAdvisor {
private final List<String> sensitiveWords;
public SafeGuardAdvisor(List<String> sensitiveWords) {
this.sensitiveWords = sensitiveWords;
}
@Override
public ChatClientRequest before(ChatClientRequest request, AdvisorChain chain) {
System.out.println(" [SafeGuard] Before: 检查敏感词");
String prompt = request.getPrompt();
for (String word : sensitiveWords) {
if (prompt.contains(word)) {
System.out.println(" [SafeGuard] 检测到敏感词: " + word);
// 可以在这里拦截请求,直接返回拒绝响应
// 为了演示,这里只是打印日志,继续执行
}
}
// 继续链式调用
return chain.nextBefore(request);
}
@Override
public ChatClientResponse after(ChatClientResponse response, AdvisorChain chain) {
// 继续链式调用(逆序)
return chain.nextAfter(response);
}
@Override
public int getOrder() {
return 50; // 中等 order
}
}
// ==================== 7. ChatModel 实现(模拟) ====================
class MockChatModel implements ChatModel {
@Override
public ChatClientResponse call(ChatClientRequest request) {
// 模拟 AI 模型调用
String responseContent = "AI 回复: 已处理请求 [" + request.getPrompt() + "]";
return new ChatClientResponse(responseContent);
}
}
// ==================== 8. 测试示例 ====================
public class Advisor责任链模式简化实现示例 {
public static void main(String[] args) {
// 创建 ChatModel
ChatModel chatModel = new MockChatModel();
// 创建 Advisor 列表
List<MyBaseAdvisor> advisors = List.of(
new SimpleLoggerAdvisor(), // order = 100
new ReReadingAdvisor(), // order = 0
new SafeGuardAdvisor(List.of("敏感词")) // order = 50
);
// 创建 ChatClient
ChatClient chatClient = new ChatClient(advisors, chatModel);
// 执行请求
ChatClientRequest request = new ChatClientRequest("用户问题:你好");
ChatClientResponse response = chatClient.call(request);
System.out.println("最终响应: " + response);
/*
* 预期输出:
*
* ========== 开始执行 Advisor 责任链 ==========
* 原始请求: Request{prompt='用户问题:你好'}
* Advisor 顺序: [ReReadingAdvisor(order=0), SafeGuardAdvisor(order=50), SimpleLoggerAdvisor(order=100)]
* [ReReading] Before: 原始提示词 = 用户问题:你好
* [ReReading] Before: 增强后提示词 = 用户问题:你好
* Read the question again: 用户问题:你好
* [SafeGuard] Before: 检查敏感词
* [Logger] Before: Request{prompt='用户问题:你好\nRead the question again: 用户问题:你好'}
* [Chain] 所有 Advisor.before() 执行完成,准备调用 ChatModel
* [Chain] 调用 ChatModel: Request{prompt='用户问题:你好\nRead the question again: 用户问题:你好'}
* [Chain] ChatModel 返回: Response{content='AI 回复: 已处理请求 [用户问题:你好\nRead the question again: 用户问题:你好]'}
* [Logger] After: Response{content='AI 回复: 已处理请求 [用户问题:你好\nRead the question again: 用户问题:你好]'}
* [Chain] 所有 Advisor.after() 执行完成,返回最终响应
* ========== Advisor 责任链执行完成 ==========
*
* 最终响应: Response{content='AI 回复: 已处理请求 [用户问题:你好\nRead the question again: 用户问题:你好]'}
*/
}
}多轮对话实现大模型的"记忆"
那我们平常跟一些大模型聊天是怎么记住我们对话的呢?实际上,每次对话都需要将之前的对话消息内置发送给大模型,这种方式称为多轮对话。
java
/**
* 测试手动管理对话记忆的方式
*
* <p>该方法演示了如何在不使用 ChatMemory 和 PromptChatMemoryAdvisor 的情况下,
* 通过手动拼接对话历史来实现多轮对话功能。这是一种简单但不够优雅的方式,
* 主要用于理解对话记忆的基本概念和对比自动管理记忆的优势。
*
* <p><b>实现方式:</b>
* <ul>
* <li>第一轮对话:直接发送用户消息,获取 AI 回复</li>
* <li>第二轮对话:将第一轮的用户消息、AI 回复和新的用户消息拼接在一起,
* 作为新的提示词发送给 AI</li>
* <li>通过字符串拼接的方式,让 AI 能够"看到"之前的对话历史</li>
* </ul>
*
* <p><b>执行流程:</b>
* <ol>
* <li>创建 ChatClient,不配置任何 Advisor(包括 PromptChatMemoryAdvisor)</li>
* <li>第一轮对话:
* <ul>
* <li>用户输入:"我叫徐庶"</li>
* <li>AI 回复:可能是 "你好,徐庶!很高兴认识你。"</li>
* <li>将用户输入和 AI 回复保存到 chatHis 变量中</li>
* </ul>
* </li>
* <li>第二轮对话:
* <ul>
* <li>将第一轮的完整对话历史和新问题拼接:chatHis + "我叫什么 ?"</li>
* <li>发送给 AI 的完整提示词可能是:
* <pre>
* 我叫徐庶
* AI回复内容
* 我叫什么 ?
* </pre>
* </li>
* <li>AI 基于对话历史,能够回答:"你叫徐庶"</li>
* </ul>
* </li>
* </ol>
*
* <p><b>优点:</b>
* <ul>
* <li>实现简单,不需要额外的配置和依赖</li>
* <li>可以完全控制对话历史的格式和内容</li>
* <li>适合简单的对话场景和快速原型开发</li>
* </ul>
*
* <p><b>缺点:</b>
* <ul>
* <li>需要手动管理对话历史,代码繁琐且容易出错</li>
* <li>随着对话轮次增加,提示词会越来越长,消耗更多 token</li>
* <li>无法自动管理对话窗口,可能导致超出模型的最大 token 限制</li>
* <li>无法持久化对话历史,每次都是新的对话</li>
* <li>无法支持多会话管理(不同用户或不同对话线程)</li>
* <li>字符串拼接方式不够优雅,容易出错</li>
* </ul>
*
* <p><b>与自动管理记忆的对比:</b>
* <table border="1">
* <tr>
* <th>特性</th>
* <th>手动管理(本方法)</th>
* <th>自动管理(testMemoryAdvisor)</th>
* </tr>
* <tr>
* <td>实现复杂度</td>
* <td>简单但繁琐</td>
* <td>配置简单,使用方便</td>
* </tr>
* <tr>
* <td>对话窗口管理</td>
* <td>手动控制,容易出错</td>
* <td>自动管理,可配置窗口大小</td>
* </tr>
* <tr>
* <td>持久化</td>
* <td>不支持</td>
* <td>支持(通过 ChatMemoryRepository)</td>
* </tr>
* <tr>
* <td>多会话支持</td>
* <td>需要手动实现</td>
* <td>通过 conversationId 自动支持</td>
* </tr>
* <tr>
* <td>Token 管理</td>
* <td>无法自动优化</td>
* <td>可以自动截断,保留最近的对话</td>
* </tr>
* </table>
*
* <p><b>使用场景:</b>
* <ul>
* <li>学习和理解对话记忆的基本概念</li>
* <li>快速原型开发,不需要复杂的记忆管理</li>
* <li>单次对话,不需要保存历史</li>
* <li>对话历史很短,不会超出 token 限制的场景</li>
* </ul>
*
* <p><b>注意事项:</b>
* <ul>
* <li>本方法仅用于演示,生产环境建议使用 ChatMemory 和 PromptChatMemoryAdvisor</li>
* <li>字符串拼接时要注意格式,确保 AI 能正确理解对话结构</li>
* <li>随着对话轮次增加,要注意 token 使用量,避免超出模型限制</li>
* <li>如果对话历史很长,建议使用 MessageWindowChatMemory 自动管理</li>
* </ul>
*
* <p><b>示例输出:</b>
* <pre>
* 第一轮回复:你好,徐庶!很高兴认识你。
* --------------------------------------------------------------------------
* 第二轮回复:你叫徐庶。
* </pre>
*
* <p><b>改进建议:</b>
* <ul>
* <li>使用 ChatMemory 和 PromptChatMemoryAdvisor 自动管理对话记忆</li>
* <li>参考 testMemory2() 方法,使用 ChatMemory 手动管理但更规范</li>
* <li>参考 testMemoryAdvisor() 方法,使用 PromptChatMemoryAdvisor 自动管理</li>
* </ul>
*
* @param chatModel 自动注入的 DashScopeChatModel Bean,用于执行 AI 对话
*
* @see #testMemory2(DashScopeChatModel) 使用 ChatMemory 手动管理对话记忆
* @see #testMemoryAdvisor(ChatMemory) 使用 PromptChatMemoryAdvisor 自动管理对话记忆
* @see org.springframework.ai.chat.memory.ChatMemory
* @see org.springframework.ai.chat.client.advisor.PromptChatMemoryAdvisor
*/
@Test
public void testMemory(@Autowired DashScopeChatModel chatModel) {
// 创建 ChatClient,不配置任何 Advisor(包括 PromptChatMemoryAdvisor)
// 这意味着不会自动管理对话记忆,需要手动处理
ChatClient chatClient = ChatClient
.builder(chatModel)
.build();
// 第一轮对话:用户自我介绍
String chatHis="我叫徐庶";
String content = chatClient.prompt()
.user(chatHis)
.call()
.content();
System.out.println(content);
System.out.println("--------------------------------------------------------------------------");
// 手动拼接对话历史:将第一轮的用户消息和 AI 回复拼接
// 然后添加第二轮的用户问题
chatHis+=content;
chatHis+="我叫什么 ?";
// 第二轮对话:基于完整的对话历史提问
// AI 能够看到之前的对话,知道用户叫徐庶,所以能正确回答
content = chatClient.prompt()
.user(chatHis)
.call()
.content();
System.out.println(content);
}ChatMemory 手动管理对话记忆的方式
java
/**
* 测试使用 ChatMemory 手动管理对话记忆的方式
*
* <p>该方法演示了如何使用 Spring AI 的 ChatMemory 接口来管理对话历史,
* 相比 testMemory() 方法中的字符串拼接方式,这种方式更加规范和优雅。
* 它使用 MessageWindowChatMemory 来存储和管理对话消息,支持多轮对话和对话历史管理。
*
* <p><b>实现方式:</b>
* <ul>
* <li>创建 MessageWindowChatMemory 实例来管理对话记忆</li>
* <li>使用 conversationId 来区分不同的对话会话</li>
* <li>手动将用户消息和 AI 回复添加到 ChatMemory 中</li>
* <li>每次调用 ChatModel 时,从 ChatMemory 获取完整的对话历史</li>
* <li>ChatMemory 会自动管理对话窗口,控制历史消息的数量</li>
* </ul>
*
* <p><b>执行流程:</b>
* <ol>
* <li>创建 MessageWindowChatMemory 实例
* <ul>
* <li>使用 builder 模式创建,可以配置 maxMessages 等参数</li>
* <li>如果不配置,使用默认的窗口大小</li>
* </ul>
* </li>
* <li>第一轮对话:
* <ul>
* <li>创建 UserMessage("我叫徐庶")</li>
* <li>调用 chatMemory.add(conversationId, userMessage1) 添加到记忆</li>
* <li>调用 chatMemory.get(conversationId) 获取当前对话历史(包含用户消息)</li>
* <li>使用 ChatModel.call() 执行 AI 调用,传入包含历史消息的 Prompt</li>
* <li>将 AI 回复添加到记忆:chatMemory.add(conversationId, response1.getResult().getOutput())</li>
* </ul>
* </li>
* <li>第二轮对话:
* <ul>
* <li>创建 UserMessage("我叫什么?")</li>
* <li>添加到记忆:chatMemory.add(conversationId, userMessage2)</li>
* <li>获取对话历史:chatMemory.get(conversationId) 现在包含:
* <pre>
* 1. UserMessage("我叫徐庶")
* 2. AssistantMessage(AI 第一轮回复)
* 3. UserMessage("我叫什么?")
* </pre>
* </li>
* <li>调用 ChatModel,AI 基于完整历史能够回答:"你叫徐庶"</li>
* <li>将 AI 回复添加到记忆</li>
* </ul>
* </li>
* </ol>
*
* <p><b>核心组件说明:</b>
* <ul>
* <li><b>MessageWindowChatMemory</b>:
* <ul>
* <li>实现了 ChatMemory 接口</li>
* <li>使用滑动窗口机制管理对话历史</li>
* <li>可以配置 maxMessages 限制窗口大小,自动保留最近的 N 条消息</li>
* <li>支持持久化(通过 ChatMemoryRepository)</li>
* </ul>
* </li>
* <li><b>conversationId</b>:
* <ul>
* <li>对话会话的唯一标识符</li>
* <li>不同的 conversationId 对应不同的对话会话</li>
* <li>支持多用户、多会话的场景</li>
* </ul>
* </li>
* <li><b>chatMemory.add()</b>:
* <ul>
* <li>将消息添加到指定会话的记忆中</li>
* <li>支持 UserMessage、AssistantMessage 等不同类型的消息</li>
* <li>自动维护消息的顺序</li>
* </ul>
* </li>
* <li><b>chatMemory.get()</b>:
* <ul>
* <li>获取指定会话的完整对话历史</li>
* <li>返回 List<Message>,包含所有历史消息</li>
* <li>消息按时间顺序排列</li>
* </ul>
* </li>
* </ul>
*
* <p><b>与 testMemory() 方法的对比:</b>
* <table border="1">
* <tr>
* <th>特性</th>
* <th>testMemory()(字符串拼接)</th>
* <th>testMemory2()(ChatMemory)</th>
* </tr>
* <tr>
* <td>实现方式</td>
* <td>手动字符串拼接</td>
* <td>使用 ChatMemory API</td>
* </tr>
* <tr>
* <td>消息管理</td>
* <td>简单的字符串拼接</td>
* <td>结构化的 Message 对象</td>
* </tr>
* <tr>
* <td>对话窗口</td>
* <td>无法自动管理</td>
* <td>自动管理,可配置窗口大小</td>
* </tr>
* <tr>
* <td>多会话支持</td>
* <td>需要手动实现</td>
* <td>通过 conversationId 自动支持</td>
* </tr>
* <tr>
* <td>持久化</td>
* <td>不支持</td>
* <td>支持(通过 ChatMemoryRepository)</td>
* </tr>
* <tr>
* <td>代码可读性</td>
* <td>较差</td>
* <td>较好</td>
* </tr>
* <tr>
* <td>类型安全</td>
* <td>无类型检查</td>
* <td>强类型,编译时检查</td>
* </tr>
* </table>
*
* <p><b>优点:</b>
* <ul>
* <li>使用标准的 Spring AI API,代码更加规范</li>
* <li>支持对话窗口管理,可以自动截断旧消息</li>
* <li>支持多会话管理,通过 conversationId 区分不同对话</li>
* <li>支持持久化,可以将对话历史保存到数据库</li>
* <li>类型安全,使用 Message 对象而不是字符串</li>
* <li>可以配置窗口大小,控制 token 使用量</li>
* </ul>
*
* <p><b>缺点:</b>
* <ul>
* <li>需要手动管理消息的添加和获取</li>
* <li>每次调用都需要手动从 ChatMemory 获取历史并构建 Prompt</li>
* <li>代码相对繁琐,需要多行代码完成一次对话</li>
* <li>没有使用 PromptChatMemoryAdvisor,无法自动管理</li>
* </ul>
*
* <p><b>与 testMemoryAdvisor() 方法的对比:</b>
* <ul>
* <li><b>testMemory2()</b>:手动管理,需要显式调用 chatMemory.add() 和 chatMemory.get()</li>
* <li><b>testMemoryAdvisor()</b>:自动管理,PromptChatMemoryAdvisor 自动处理所有记忆操作</li>
* <li>testMemoryAdvisor() 更加简洁,推荐在生产环境使用</li>
* </ul>
*
* <p><b>使用场景:</b>
* <ul>
* <li>需要精确控制对话历史管理的场景</li>
* <li>需要自定义消息处理逻辑的场景</li>
* <li>学习和理解 ChatMemory 的工作原理</li>
* <li>不适合使用 Advisor 的特殊场景</li>
* </ul>
*
* <p><b>配置选项:</b>
* <ul>
* <li><b>maxMessages</b>:设置对话窗口的最大消息数量
* <pre>
* MessageWindowChatMemory.builder()
* .maxMessages(10) // 只保留最近 10 条消息
* .build();
* </pre>
* </li>
* <li><b>chatMemoryRepository</b>:配置持久化存储
* <pre>
* MessageWindowChatMemory.builder()
* .chatMemoryRepository(chatMemoryRepository)
* .build();
* </pre>
* </li>
* </ul>
*
* <p><b>注意事项:</b>
* <ul>
* <li>每次调用 ChatModel 前,需要先添加用户消息到 ChatMemory</li>
* <li>每次获取 AI 回复后,需要将回复添加到 ChatMemory</li>
* <li>使用 chatMemory.get(conversationId) 获取历史时,会返回包含当前用户消息的完整历史</li>
* <li>conversationId 应该唯一,用于区分不同的对话会话</li>
* <li>如果配置了 maxMessages,超出窗口的消息会被自动移除</li>
* <li>建议在生产环境使用 PromptChatMemoryAdvisor 自动管理,代码更简洁</li>
* </ul>
*
* <p><b>示例输出:</b>
* <pre>
* 第二轮回复:你叫徐庶。
* </pre>
*
* <p><b>改进建议:</b>
* <ul>
* <li>使用 PromptChatMemoryAdvisor 自动管理对话记忆(参考 testMemoryAdvisor())</li>
* <li>配置 ChatMemoryRepository 实现持久化存储</li>
* <li>根据业务需求合理设置 maxMessages,平衡上下文长度和 token 使用量</li>
* </ul>
*
* @param chatModel 自动注入的 DashScopeChatModel Bean,用于执行 AI 对话
*
* @see #testMemory(DashScopeChatModel) 使用字符串拼接手动管理对话记忆
* @see #testMemoryAdvisor(ChatMemory) 使用 PromptChatMemoryAdvisor 自动管理对话记忆
* @see org.springframework.ai.chat.memory.ChatMemory
* @see org.springframework.ai.chat.memory.MessageWindowChatMemory
* @see org.springframework.ai.chat.client.advisor.PromptChatMemoryAdvisor
*/
@Test
public void testMemory2(@Autowired
DashScopeChatModel chatModel) {
// 创建 MessageWindowChatMemory 实例
// MessageWindowChatMemory 使用滑动窗口机制管理对话历史
// 可以配置 maxMessages 来限制窗口大小,自动保留最近的 N 条消息
ChatMemory chatMemory = MessageWindowChatMemory.builder().build();
// 对话会话的唯一标识符
// 不同的 conversationId 对应不同的对话会话,支持多用户、多会话场景
String conversationId = "xs001";
// 第一轮对话:用户自我介绍
// 1. 创建用户消息对象
UserMessage userMessage1 = new UserMessage("我叫徐庶");
// 2. 将用户消息添加到对话记忆中
chatMemory.add(conversationId, userMessage1);
// 3. 从 ChatMemory 获取当前对话历史(包含刚添加的用户消息)
// 4. 使用 ChatModel 调用 AI,传入包含历史消息的 Prompt
ChatResponse response1 = chatModel.call(new Prompt(chatMemory.get(conversationId)));
// 5. 将 AI 回复添加到对话记忆中,以便下一轮对话使用
chatMemory.add(conversationId, response1.getResult().getOutput());
// 第二轮对话:询问姓名
// 1. 创建新的用户消息
UserMessage userMessage2 = new UserMessage("我叫什么?");
// 2. 添加到记忆(现在记忆包含:第一轮用户消息、第一轮 AI 回复、第二轮用户消息)
chatMemory.add(conversationId, userMessage2);
// 3. 获取完整对话历史并调用 AI
// AI 能够看到之前的对话,知道用户叫徐庶,所以能正确回答
ChatResponse response2 = chatModel.call(new Prompt(chatMemory.get(conversationId)));
// 4. 将 AI 回复添加到记忆
chatMemory.add(conversationId, response2.getResult().getOutput());
// 输出第二轮 AI 回复的内容
System.out.println(response2.getResult().getOutput().getText());
}输出:
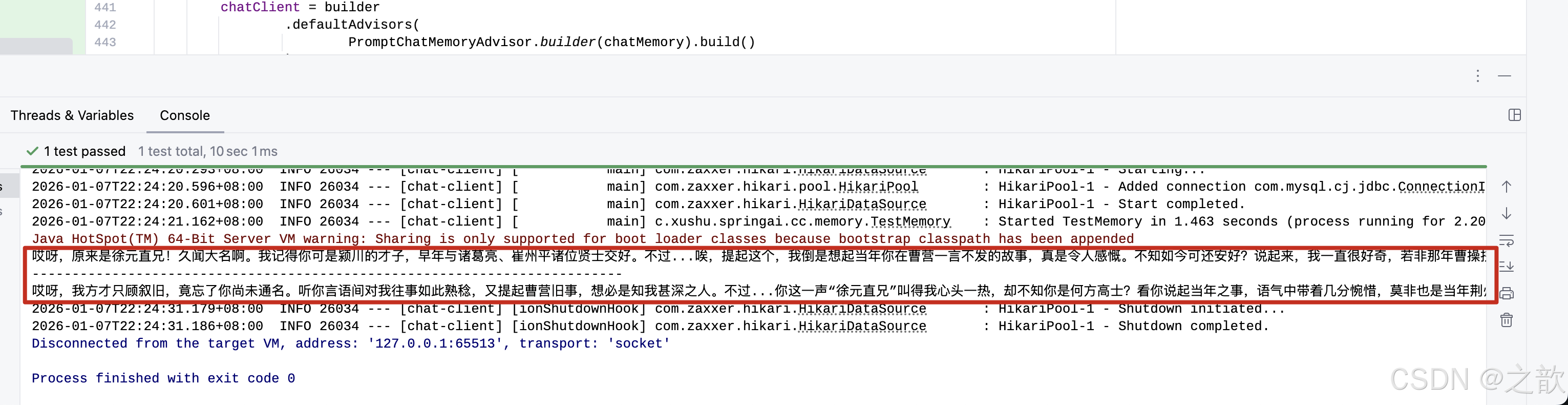
多轮对话实现大模型的"记忆"
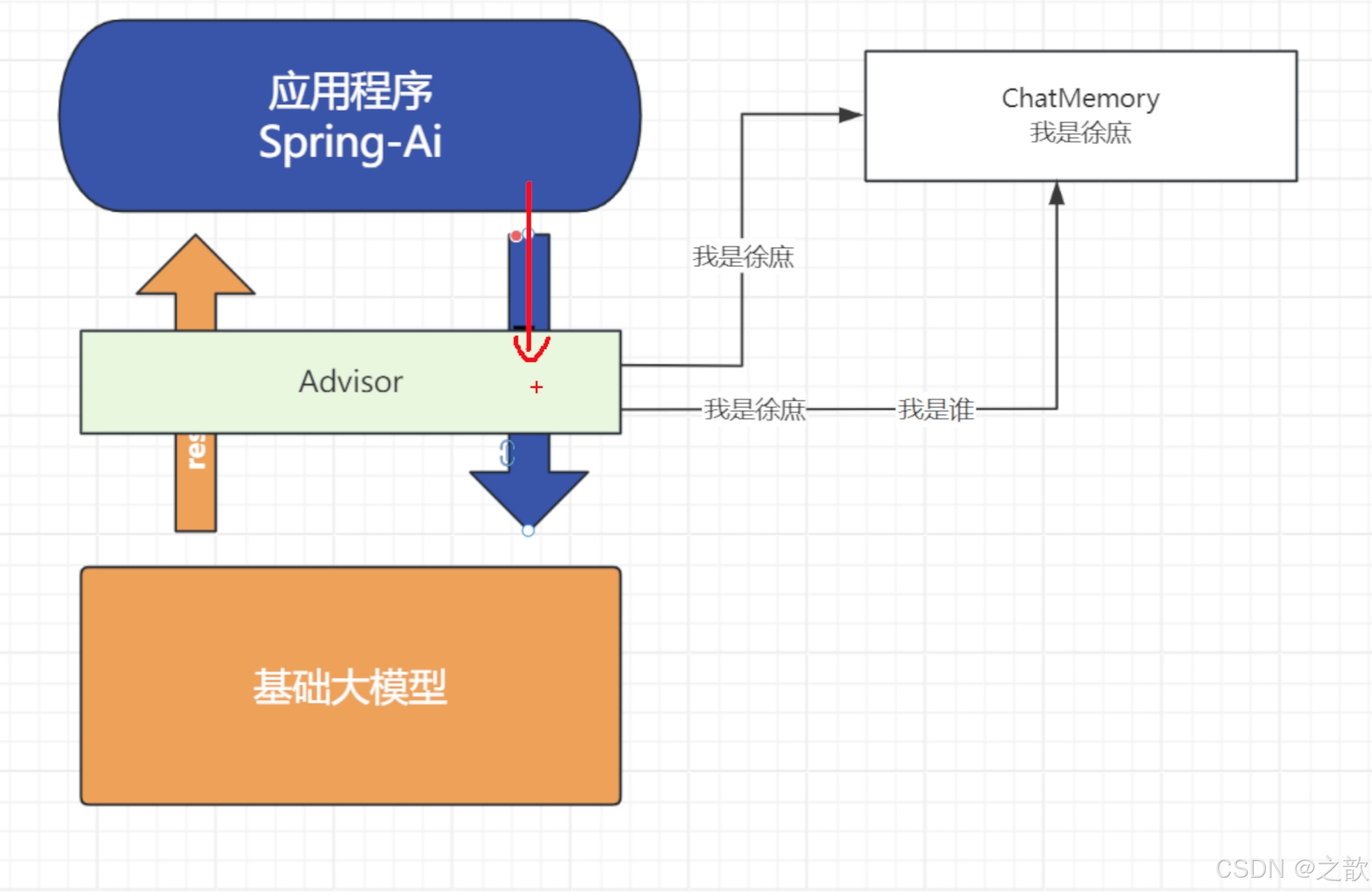
java
ChatClient chatClient;
@BeforeEach
public void init(@Autowired ChatClient.Builder builder,
@Autowired ChatMemory chatMemory) {
chatClient = builder
.defaultAdvisors(
PromptChatMemoryAdvisor.builder(chatMemory).build()
)
.build();
}
/**
* 测试使用 PromptChatMemoryAdvisor 自动管理对话记忆的方式
*
* <p>该方法演示了如何使用 PromptChatMemoryAdvisor 来自动管理对话记忆,
* 这是 Spring AI 中推荐的生产环境使用方式。相比 testMemory() 和 testMemory2() 方法,
* 这种方式完全自动化,代码最简洁,无需手动管理对话历史的添加和获取。
*
* <p><b>核心优势:</b>
* <ul>
* <li><b>完全自动化</b>:PromptChatMemoryAdvisor 自动处理所有记忆操作</li>
* <li><b>代码简洁</b>:只需调用 chatClient.prompt().user().call(),无需手动管理</li>
* <li><b>透明化</b>:对话记忆的管理对业务代码完全透明</li>
* <li><b>统一管理</b>:通过 Advisor 机制统一管理,易于维护和扩展</li>
* </ul>
*
* <p><b>实现原理:</b>
* <ul>
* <li>在 @BeforeEach 方法中,ChatClient 已配置了 PromptChatMemoryAdvisor</li>
* <li>PromptChatMemoryAdvisor 实现了 Advisor 接口,在责任链中执行</li>
* <li>在 before() 阶段:自动从 ChatMemory 获取历史消息并添加到当前请求</li>
* <li>在 after() 阶段:自动将用户消息和 AI 回复保存到 ChatMemory</li>
* <li>整个过程对业务代码完全透明,无需关心记忆管理的细节</li>
* </ul>
*
* <p><b>执行流程:</b>
* <ol>
* <li><b>初始化阶段</b>(@BeforeEach):
* <ul>
* <li>创建 ChatClient,配置 PromptChatMemoryAdvisor</li>
* <li>PromptChatMemoryAdvisor 绑定到 ChatMemory 实例</li>
* <li>ChatMemory 由 Config 类配置,使用 MessageWindowChatMemory</li>
* </ul>
* </li>
* <li><b>第一轮对话</b>:
* <ul>
* <li>调用 chatClient.prompt().user("我叫徐庶").call()</li>
* <li>PromptChatMemoryAdvisor.before() 执行:
* <ul>
* <li>从 ChatMemory 获取当前会话的历史消息(首次为空)</li>
* <li>将历史消息添加到当前请求的 Prompt 中</li>
* </ul>
* </li>
* <li>ChatModel 执行 AI 调用,返回回复</li>
* <li>PromptChatMemoryAdvisor.after() 执行:
* <ul>
* <li>将用户消息 "我叫徐庶" 保存到 ChatMemory</li>
* <li>将 AI 回复保存到 ChatMemory</li>
* </ul>
* </li>
* <li>返回 AI 回复内容</li>
* </ul>
* </li>
* <li><b>第二轮对话</b>:
* <ul>
* <li>调用 chatClient.prompt().user("我叫什么 ?").call()</li>
* <li>PromptChatMemoryAdvisor.before() 执行:
* <ul>
* <li>从 ChatMemory 获取历史消息(包含第一轮的完整对话)</li>
* <li>将历史消息添加到当前请求的 Prompt 中</li>
* <li>现在 Prompt 包含:
* <pre>
* 1. UserMessage("我叫徐庶")
* 2. AssistantMessage(AI 第一轮回复)
* 3. UserMessage("我叫什么 ?") // 当前消息
* </pre>
* </li>
* </ul>
* </li>
* <li>ChatModel 执行 AI 调用,基于完整历史能够回答:"你叫徐庶"</li>
* <li>PromptChatMemoryAdvisor.after() 执行:
* <ul>
* <li>将用户消息 "我叫什么 ?" 保存到 ChatMemory</li>
* <li>将 AI 回复保存到 ChatMemory</li>
* </ul>
* </li>
* <li>返回 AI 回复内容</li>
* </ul>
* </li>
* </ol>
*
* <p><b>PromptChatMemoryAdvisor 工作原理:</b>
* <ul>
* <li><b>before() 方法</b>:
* <ul>
* <li>从请求参数中获取 conversationId(如果未指定,使用默认值)</li>
* <li>调用 chatMemory.get(conversationId) 获取历史消息</li>
* <li>将历史消息添加到当前请求的 Prompt 中</li>
* <li>返回修改后的请求,继续 Advisor 链的执行</li>
* </ul>
* </li>
* <li><b>after() 方法</b>:
* <ul>
* <li>从请求中提取用户消息</li>
* <li>从响应中提取 AI 回复</li>
* <li>调用 chatMemory.add(conversationId, userMessage) 保存用户消息</li>
* <li>调用 chatMemory.add(conversationId, assistantMessage) 保存 AI 回复</li>
* <li>返回响应,继续 Advisor 链的执行</li>
* </ul>
* </li>
* </ul>
*
* <p><b>与 testMemory() 和 testMemory2() 的对比:</b>
* <table border="1">
* <tr>
* <th>特性</th>
* <th>testMemory()</th>
* <th>testMemory2()</th>
* <th>testMemoryAdvisor()</th>
* </tr>
* <tr>
* <td>实现方式</td>
* <td>字符串拼接</td>
* <td>手动调用 ChatMemory API</td>
* <td>自动管理(Advisor)</td>
* </tr>
* <tr>
* <td>代码复杂度</td>
* <td>简单但繁琐</td>
* <td>中等</td>
* <td>最简单</td>
* </tr>
* <tr>
* <td>记忆管理</td>
* <td>手动拼接</td>
* <td>手动 add/get</td>
* <td>完全自动</td>
* </tr>
* <tr>
* <td>代码行数</td>
* <td>较多</td>
* <td>较多</td>
* <td>最少</td>
* </tr>
* <tr>
* <td>维护成本</td>
* <td>高</td>
* <td>中</td>
* <td>低</td>
* </tr>
* <tr>
* <td>生产环境适用性</td>
* <td>不推荐</td>
* <td>可用但不推荐</td>
* <td>强烈推荐</td>
* </tr>
* </table>
*
* <p><b>配置说明:</b>
* <ul>
* <li><b>ChatMemory 配置</b>(在 Config 类中):
* <pre>
* MessageWindowChatMemory.builder()
* .maxMessages(1) // 只保留最近 1 条消息(示例配置,实际可根据需求调整)
* .chatMemoryRepository(chatMemoryRepository) // 持久化存储
* .build();
* </pre>
* </li>
* <li><b>PromptChatMemoryAdvisor 配置</b>(在 @BeforeEach 中):
* <pre>
* PromptChatMemoryAdvisor.builder(chatMemory).build()
* </pre>
* </li>
* </ul>
*
* <p><b>conversationId 管理:</b>
* <ul>
* <li>本方法未显式指定 conversationId,使用默认值</li>
* <li>如果需要支持多会话,可以在调用时指定:
* <pre>
* chatClient.prompt()
* .user("消息")
* .advisors(advisorSpec -> advisorSpec.param(ChatMemory.CONVERSATION_ID, "session1"))
* .call()
* </pre>
* </li>
* <li>参考 testChatOptions() 方法了解如何指定 conversationId</li>
* </ul>
*
* <p><b>优点:</b>
* <ul>
* <li>代码最简洁,业务逻辑清晰</li>
* <li>完全自动化,无需关心记忆管理细节</li>
* <li>统一管理,易于维护和扩展</li>
* <li>支持持久化,对话历史可以保存到数据库</li>
* <li>支持多会话,通过 conversationId 区分不同对话</li>
* <li>支持对话窗口管理,自动控制 token 使用量</li>
* <li>符合 Spring AI 的最佳实践</li>
* </ul>
*
* <p><b>使用场景:</b>
* <ul>
* <li>生产环境的多轮对话场景(强烈推荐)</li>
* <li>需要持久化对话历史的场景</li>
* <li>需要支持多用户、多会话的场景</li>
* <li>需要统一管理对话记忆的场景</li>
* <li>希望代码简洁、易于维护的场景</li>
* </ul>
*
* <p><b>注意事项:</b>
* <ul>
* <li>必须在 ChatClient 构建时配置 PromptChatMemoryAdvisor</li>
* <li>需要注入 ChatMemory Bean(由 Config 类提供)</li>
* <li>如果未指定 conversationId,所有对话会共享同一个会话</li>
* <li>建议根据业务需求合理设置 maxMessages,平衡上下文和 token 使用</li>
* <li>如果配置了 ChatMemoryRepository,对话历史会自动持久化</li>
* <li>PromptChatMemoryAdvisor 在 Advisor 链中的执行顺序很重要</li>
* </ul>
*
* <p><b>示例输出:</b>
* <pre>
* 第一轮回复:你好,徐庶!很高兴认识你。
* --------------------------------------------------------------------------
* 第二轮回复:你叫徐庶。
* </pre>
*
* <p><b>扩展使用:</b>
* <ul>
* <li>指定 conversationId 支持多会话(参考 testChatOptions())</li>
* <li>配置不同的 ChatMemory 实现(如 VectorStoreChatMemory)</li>
* <li>结合其他 Advisor 使用(如 SimpleLoggerAdvisor、SafeGuardAdvisor)</li>
* <li>自定义 ChatMemoryRepository 实现自定义存储逻辑</li>
* </ul>
*
* @param chatMemory 自动注入的 ChatMemory Bean,由 Config 类配置提供
* 注意:虽然参数中有 chatMemory,但实际使用的是 @BeforeEach 中
* 配置的 ChatClient,该 ChatClient 已经绑定了 ChatMemory
*
* @see #testMemory(DashScopeChatModel) 使用字符串拼接手动管理对话记忆
* @see #testMemory2(DashScopeChatModel) 使用 ChatMemory 手动管理对话记忆
* @see #testChatOptions() 使用 conversationId 支持多会话
* @see org.springframework.ai.chat.client.advisor.PromptChatMemoryAdvisor
* @see org.springframework.ai.chat.memory.ChatMemory
* @see org.springframework.ai.chat.memory.MessageWindowChatMemory
*/
@Test
public void testMemoryAdvisor(
@Autowired ChatMemory chatMemory) {
// 第一轮对话:用户自我介绍
// PromptChatMemoryAdvisor 会自动:
// 1. 在调用前:从 ChatMemory 获取历史消息(首次为空)并添加到请求
// 2. 在调用后:将用户消息和 AI 回复保存到 ChatMemory
// 整个过程对业务代码完全透明,无需手动管理
String content = chatClient.prompt()
.user("我叫徐庶" )
.call()
.content();
System.out.println(content);
System.out.println("--------------------------------------------------------------------------");
// 第二轮对话:询问姓名
// PromptChatMemoryAdvisor 会自动:
// 1. 在调用前:从 ChatMemory 获取历史消息(包含第一轮的完整对话)并添加到请求
// 2. AI 能够看到之前的对话,知道用户叫徐庶,所以能正确回答
// 3. 在调用后:将用户消息和 AI 回复保存到 ChatMemory
content = chatClient.prompt()
.user("我叫什么 ?")
.call()
.content();
System.out.println(content);
}管理多个独立对话会话,多用户记忆隔离
- 配置多用户隔离记忆
如果有多个用户在进行对话,肯定不能将对话记录混在一起,不同的用户的对话记忆需要隔离
java
/**
* 测试使用 conversationId 管理多个独立对话会话
*
* <p>该方法演示了如何通过指定 conversationId 来管理多个独立的对话会话。
* 这是多用户、多会话场景的核心功能,不同的 conversationId 对应不同的对话历史,
* 彼此之间完全隔离,互不影响。
*
* <p><b>核心概念:</b>
* <ul>
* <li><b>conversationId</b>:对话会话的唯一标识符</li>
* <li>相同的 conversationId 共享同一份对话历史</li>
* <li>不同的 conversationId 拥有独立的对话历史</li>
* <li>通过 conversationId 可以实现多用户、多会话的隔离</li>
* </ul>
*
* <p><b>执行流程:</b>
* <ol>
* <li><b>第一轮对话(会话1)</b>:
* <ul>
* <li>指定 conversationId = "1"</li>
* <li>用户输入:"我叫徐庶 ?"</li>
* <li>PromptChatMemoryAdvisor 从会话1的记忆中获取历史(首次为空)</li>
* <li>AI 回复后,对话历史保存到会话1的记忆中</li>
* </ul>
* </li>
* <li><b>第二轮对话(会话1,继续)</b>:
* <ul>
* <li>继续使用 conversationId = "1"</li>
* <li>用户输入:"我叫什么 ?"</li>
* <li>PromptChatMemoryAdvisor 从会话1的记忆中获取历史(包含第一轮对话)</li>
* <li>AI 基于会话1的完整历史,能够回答:"你叫徐庶"</li>
* <li>对话历史继续保存到会话1的记忆中</li>
* </ul>
* </li>
* <li><b>第三轮对话(会话2,新会话)</b>:
* <ul>
* <li>使用新的 conversationId = "2"</li>
* <li>用户输入:"我叫什么 ?"</li>
* <li>PromptChatMemoryAdvisor 从会话2的记忆中获取历史(首次为空,新会话)</li>
* <li>AI 无法回答,因为会话2没有之前的对话历史</li>
* <li>这证明了不同 conversationId 的会话是完全隔离的</li>
* </ul>
* </li>
* </ol>
*
* <p><b>conversationId 的指定方式:</b>
* <pre>
* chatClient.prompt()
* .user("消息内容")
* .advisors(advisorSpec -> advisorSpec.param(ChatMemory.CONVERSATION_ID, "会话ID"))
* .call()
* </pre>
*
* <p><b>会话隔离机制:</b>
* <ul>
* <li>每个 conversationId 对应一个独立的 ChatMemory 存储空间</li>
* <li>ChatMemory.get(conversationId) 只返回该会话的历史消息</li>
* <li>ChatMemory.add(conversationId, message) 只保存到该会话的记忆中</li>
* <li>不同会话之间的对话历史完全隔离,互不影响</li>
* </ul>
*
* <p><b>使用场景:</b>
* <ul>
* <li><b>多用户场景</b>:每个用户使用不同的 conversationId</li>
* <li><b>多会话场景</b>:同一用户的不同对话线程使用不同的 conversationId</li>
* <li><b>上下文隔离</b>:需要完全隔离的对话场景</li>
* <li><b>会话管理</b>:需要管理多个独立对话的场景</li>
* </ul>
*
* <p><b>conversationId 的生成策略:</b>
* <ul>
* <li><b>用户ID</b>:使用用户唯一标识作为 conversationId
* <pre>
* String conversationId = userId; // 每个用户一个会话
* </pre>
* </li>
* <li><b>会话ID</b>:为每个对话线程生成唯一ID
* <pre>
* String conversationId = UUID.randomUUID().toString(); // 每个对话一个会话
* </pre>
* </li>
* <li><b>组合ID</b>:用户ID + 会话类型
* <pre>
* String conversationId = userId + "_" + sessionType; // 用户的不同会话类型
* </pre>
* </li>
* <li><b>时间戳ID</b>:基于时间生成
* <pre>
* String conversationId = "session_" + System.currentTimeMillis();
* </pre>
* </li>
* </ul>
*
* <p><b>与 testMemoryAdvisor() 的对比:</b>
* <table border="1">
* <tr>
* <th>特性</th>
* <th>testMemoryAdvisor()</th>
* <th>testChatOptions()</th>
* </tr>
* <tr>
* <td>conversationId</td>
* <td>使用默认值(所有对话共享)</td>
* <td>显式指定(支持多会话)</td>
* </tr>
* <tr>
* <td>会话隔离</td>
* <td>无隔离,所有对话共享历史</td>
* <td>完全隔离,不同ID独立历史</td>
* </tr>
* <tr>
* <td>适用场景</td>
* <td>单会话场景</td>
* <td>多会话场景</td>
* </tr>
* <tr>
* <td>代码复杂度</td>
* <td>更简单</td>
* <td>稍复杂(需要指定ID)</td>
* </tr>
* </table>
*
* <p><b>注意事项:</b>
* <ul>
* <li>conversationId 必须是字符串类型</li>
* <li>conversationId 应该唯一,避免会话冲突</li>
* <li>如果未指定 conversationId,所有对话会共享默认会话</li>
* <li>conversationId 区分大小写,"1" 和 "1 " 是不同的会话</li>
* <li>建议使用有意义的 conversationId,便于管理和调试</li>
* <li>如果配置了 ChatMemoryRepository,不同会话的历史会持久化到数据库</li>
* </ul>
*
* <p><b>实际应用示例:</b>
* <ul>
* <li><b>客服系统</b>:每个客户使用唯一的 conversationId
* <pre>
* String conversationId = "customer_" + customerId;
* </pre>
* </li>
* <li><b>多轮对话应用</b>:每个对话线程使用独立的 conversationId
* <pre>
* String conversationId = sessionId; // 从请求中获取会话ID
* </pre>
* </li>
* <li><b>用户个性化</b>:每个用户的不同话题使用不同的 conversationId
* <pre>
* String conversationId = userId + "_" + topicId;
* </pre>
* </li>
* </ul>
*
* <p><b>示例输出:</b>
* <pre>
* 第一轮回复(会话1):你好,徐庶!很高兴认识你。
* --------------------------------------------------------------------------
* 第二轮回复(会话1):你叫徐庶。
* --------------------------------------------------------------------------
* 第三轮回复(会话2):抱歉,我不知道你的名字。 // 新会话,没有历史
* </pre>
*
* <p><b>最佳实践:</b>
* <ul>
* <li>在生产环境中,conversationId 应该从请求上下文中获取(如用户ID、会话ID)</li>
* <li>建议使用有意义的命名规则,便于日志追踪和问题排查</li>
* <li>对于长期会话,考虑设置合理的 maxMessages,避免历史过长</li>
* <li>定期清理不再使用的会话历史,释放存储空间</li>
* <li>在分布式环境中,确保 conversationId 的生成策略是唯一的</li>
* </ul>
*
* @see #testMemoryAdvisor(ChatMemory) 使用默认 conversationId 的单会话场景
* @see org.springframework.ai.chat.memory.ChatMemory#CONVERSATION_ID
* @see org.springframework.ai.chat.client.advisor.PromptChatMemoryAdvisor
*/
@Test
public void testChatOptions() {
// 第一轮对话:会话1
// 指定 conversationId = "1",这是第一个独立的对话会话
// PromptChatMemoryAdvisor 会使用这个 ID 来管理该会话的记忆
String content = chatClient.prompt()
.user("我叫徐庶 ?")
.advisors(advisorSpec -> advisorSpec.param(ChatMemory.CONVERSATION_ID,"1"))
.call()
.content();
System.out.println(content);
System.out.println("--------------------------------------------------------------------------");
// 第二轮对话:继续会话1
// 继续使用 conversationId = "1",与第一轮对话属于同一个会话
// PromptChatMemoryAdvisor 会从会话1的记忆中获取历史消息(包含第一轮对话)
// AI 能够看到之前的对话,知道用户叫徐庶,所以能正确回答
content = chatClient.prompt()
.user("我叫什么 ?")
.advisors(advisorSpec -> advisorSpec.param(ChatMemory.CONVERSATION_ID,"1"))
.call()
.content();
System.out.println(content);
System.out.println("--------------------------------------------------------------------------");
// 第三轮对话:新会话2
// 使用新的 conversationId = "2",这是一个全新的独立会话
// PromptChatMemoryAdvisor 会从会话2的记忆中获取历史消息(首次为空,新会话)
// AI 无法看到会话1的历史,所以无法回答用户的名字
// 这证明了不同 conversationId 的会话是完全隔离的
content = chatClient.prompt()
.user("我叫什么 ?")
.advisors(advisorSpec -> advisorSpec.param(ChatMemory.CONVERSATION_ID,"2"))
.call()
.content();
System.out.println(content);
}输出:
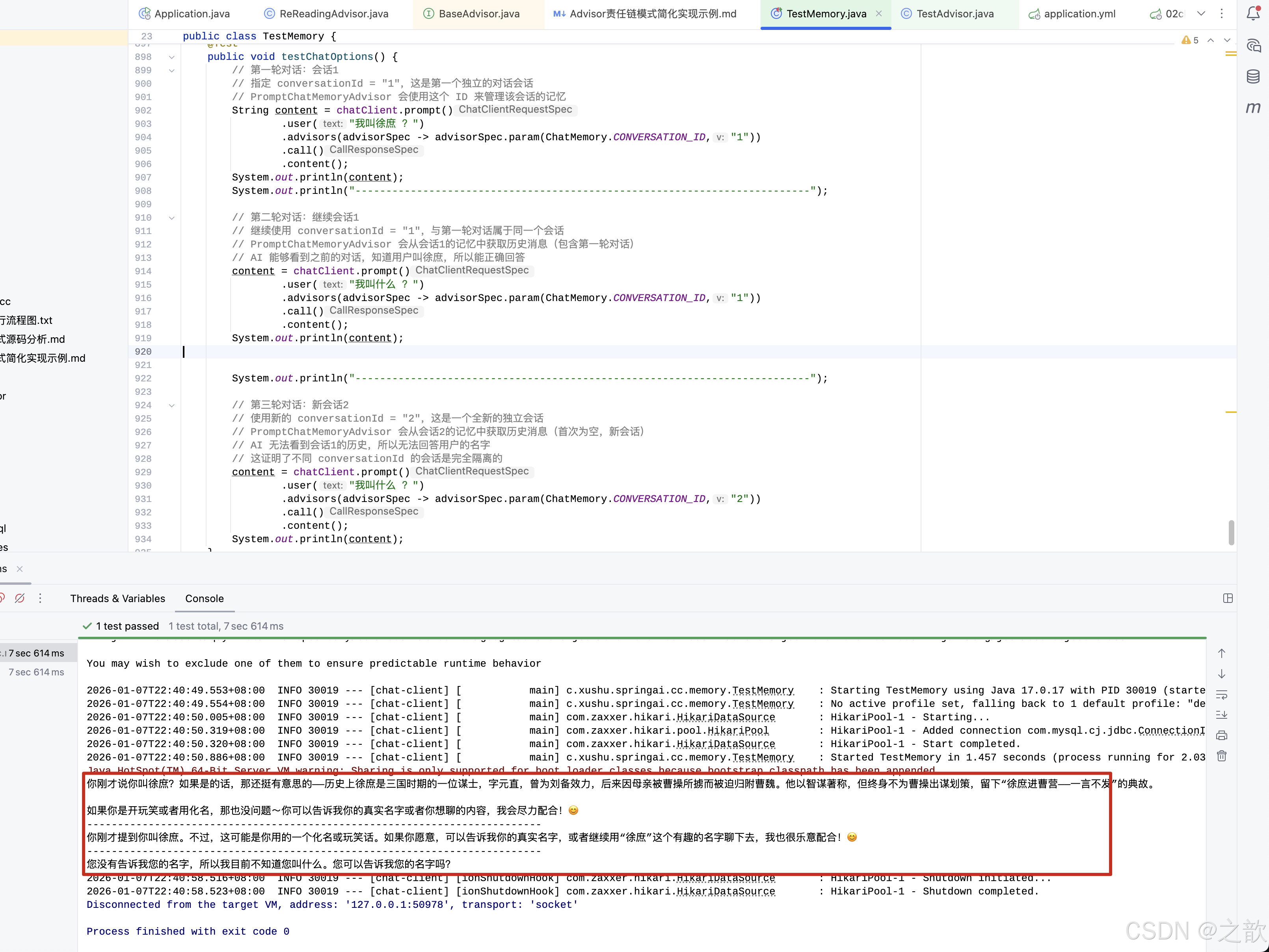
配置聊天记录最大存储数量
你要知道,我们把聊天记录发给大模型,都是算token计数的。
:大模型的token是有上限了,如果你发送过多聊天记录,可能就会导致token过长。
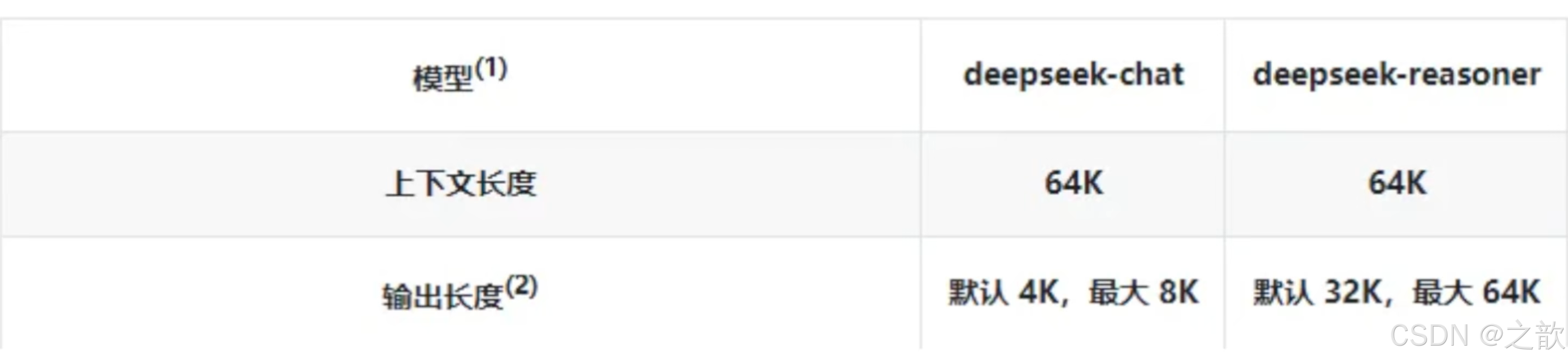
并且更多的token也意味更多的费用,更久的解析时间,所以不建议太长(DEFAULT_MAX_MESSAGES默认20即10次对话)
一旦超出DEFAULT_MAX_MESSAGES只会存最后面N条(可以理解为先进先出),参考 Message
java
/**
* 测试配置类
*
* <p>该类使用 @TestConfiguration 注解,用于在测试环境中配置 Spring Bean。
* 它提供了 ChatMemory Bean 的配置,供测试方法使用。
*
* <p><b>作用:</b>
* <ul>
* <li>配置测试环境所需的 ChatMemory Bean</li>
* <li>使用 MessageWindowChatMemory 实现对话记忆管理</li>
* <li>配置对话窗口大小和持久化存储</li>
* <li>为测试方法提供统一的 ChatMemory 实例</li>
* </ul>
*
* <p><b>@TestConfiguration 注解说明:</b>
* <ul>
* <li>@TestConfiguration 是 Spring Boot Test 提供的注解</li>
* <li>用于在测试类中定义测试专用的配置</li>
* <li>与 @Configuration 类似,但只在测试环境中生效</li>
* <li>不会影响主应用的配置</li>
* <li>可以通过 @Import 导入到其他测试类中</li>
* </ul>
*
* <p><b>ChatMemory Bean 配置说明:</b>
* <ul>
* <li><b>实现类</b>:MessageWindowChatMemory
* <ul>
* <li>使用滑动窗口机制管理对话历史</li>
* <li>自动保留最近的 N 条消息</li>
* <li>超出窗口的消息会被自动移除</li>
* </ul>
* </li>
* <li><b>maxMessages</b>:设置为 1
* <ul>
* <li>只保留最近 1 条消息(示例配置)</li>
* <li>实际生产环境应根据需求调整</li>
* <li>较小的值可以节省 token,但可能丢失重要上下文</li>
* <li>较大的值可以保留更多上下文,但会增加 token 使用量</li>
* </ul>
* </li>
* <li><b>chatMemoryRepository</b>:持久化存储
* <ul>
* <li>通过依赖注入获取 ChatMemoryRepository</li>
* <li>用于将对话历史持久化到数据库或其他存储</li>
* <li>支持对话历史的持久化和恢复</li>
* <li>如果不配置,对话历史只存在于内存中</li>
* </ul>
* </li>
* </ul>
*
* <p><b>配置参数说明:</b>
* <table border="1">
* <tr>
* <th>参数</th>
* <th>当前值</th>
* <th>说明</th>
* <th>建议值</th>
* </tr>
* <tr>
* <td>maxMessages</td>
* <td>1</td>
* <td>对话窗口的最大消息数量</td>
* <td>根据业务需求,通常 10-50</td>
* </tr>
* <tr>
* <td>chatMemoryRepository</td>
* <td>注入的实例</td>
* <td>持久化存储实现</td>
* <td>根据存储需求选择(JDBC、Redis等)</td>
* </tr>
* </table>
*
* <p><b>使用场景:</b>
* <ul>
* <li>测试环境中的 ChatMemory 配置</li>
* <li>需要自定义 ChatMemory 行为的测试</li>
* <li>需要模拟不同配置场景的测试</li>
* <li>隔离测试配置和主应用配置</li>
* </ul>
*
* <p><b>与其他测试方法的关系:</b>
* <ul>
* <li>testMemoryAdvisor() 方法使用此配置的 ChatMemory</li>
* <li>testChatOptions() 方法使用此配置的 ChatMemory</li>
* <li>所有使用 @Autowired ChatMemory 的测试方法都会使用此配置</li>
* </ul>
*
* <p><b>配置建议:</b>
* <ul>
* <li><b>测试环境</b>:
* <ul>
* <li>可以使用较小的 maxMessages,加快测试速度</li>
* <li>可以使用内存存储,不需要持久化</li>
* </ul>
* </li>
* <li><b>生产环境</b>:
* <ul>
* <li>根据业务需求设置合理的 maxMessages</li>
* <li>配置 ChatMemoryRepository 实现持久化</li>
* <li>考虑使用 Redis 或数据库存储</li>
* </ul>
* </li>
* </ul>
*
* <p><b>扩展配置示例:</b>
* <pre>
* // 配置更大的对话窗口
* MessageWindowChatMemory.builder()
* .maxMessages(20) // 保留最近 20 条消息
* .chatMemoryRepository(chatMemoryRepository)
* .build();
*
* // 不配置持久化(仅内存)
* MessageWindowChatMemory.builder()
* .maxMessages(10)
* .build();
*
* // 使用不同的 ChatMemory 实现
* VectorStoreChatMemory.builder()
* .vectorStore(vectorStore)
* .build();
* </pre>
*
* <p><b>注意事项:</b>
* <ul>
* <li>maxMessages=1 是示例配置,实际测试中可能需要更大的值</li>
* <li>如果 maxMessages 太小,可能导致上下文丢失</li>
* <li>chatMemoryRepository 参数会自动注入,无需手动创建</li>
* <li>此配置只影响测试环境,不影响主应用</li>
* <li>如果需要不同的配置,可以创建多个 @TestConfiguration 类</li>
* </ul>
*
* @see org.springframework.boot.test.context.TestConfiguration
* @see org.springframework.ai.chat.memory.ChatMemory
* @see org.springframework.ai.chat.memory.MessageWindowChatMemory
* @see org.springframework.ai.chat.memory.ChatMemoryRepository
*/
@TestConfiguration
static class Config {
/**
* 配置 ChatMemory Bean
*
* <p>该方法创建并配置 MessageWindowChatMemory 实例,用于管理对话记忆。
* 配置包括对话窗口大小和持久化存储。
*
* <p><b>配置详情:</b>
* <ul>
* <li>使用 MessageWindowChatMemory 实现</li>
* <li>设置 maxMessages = 1(示例配置,实际可根据需求调整)</li>
* <li>配置 chatMemoryRepository 实现持久化存储</li>
* </ul>
*
* <p><b>依赖注入:</b>
* <ul>
* <li>chatMemoryRepository 参数会自动注入</li>
* <li>Spring 会查找 ChatMemoryRepository 类型的 Bean</li>
* <li>如果找不到,会抛出异常</li>
* </ul>
*
* @param chatMemoryRepository 自动注入的 ChatMemoryRepository Bean,
* 用于持久化对话历史
* @return 配置好的 ChatMemory 实例
*
* @see org.springframework.ai.chat.memory.MessageWindowChatMemory
* @see org.springframework.ai.chat.memory.ChatMemoryRepository
*/
@Bean
ChatMemory chatMemory(ChatMemoryRepository chatMemoryRepository) {
return MessageWindowChatMemory
.builder()
.maxMessages(1) // 只保留最近 1 条消息(示例配置)
.chatMemoryRepository(chatMemoryRepository) // 持久化存储
.build();
}
}数据库存储记忆
添加数据库表
java
CREATE TABLE IF NOT EXISTS SPRING_AI_CHAT_MEMORY (
`conversation_id` VARCHAR(36) NOT NULL,
`content` TEXT NOT NULL,
`type` VARCHAR(10) NOT NULL,
`timestamp` TIMESTAMP NOT NULL,
INDEX `SPRING_AI_CHAT_MEMORY_CONVERSATION_ID_TIMESTAMP_IDX` (`conversation_id`, `timestamp`)
);配置 application.yml
java
spring:
datasource:
url: jdbc:mysql://localhost:3306/heyu_admin?useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=true&serverTimezone=GMT%2B8
username: root
password: root
driver-class-name: com.mysql.cj.jdbc.Driver测试类
java
package com.xushu.springai.cc.memory;
import com.alibaba.cloud.ai.dashscope.chat.DashScopeChatModel;
import com.xushu.springai.cc.ReReadingAdvisor;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.client.advisor.PromptChatMemoryAdvisor;
import org.springframework.ai.chat.memory.ChatMemory;
import org.springframework.ai.chat.memory.MessageWindowChatMemory;
import org.springframework.ai.chat.memory.repository.jdbc.JdbcChatMemoryRepository;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.boot.test.context.TestConfiguration;
import org.springframework.context.annotation.Bean;
/**
* 测试使用 JDBC 持久化存储的对话记忆
*
* <p>该类演示了如何使用 JdbcChatMemoryRepository 将对话历史持久化到关系型数据库中。
* 这是生产环境中常用的持久化方案,支持对话历史的长期保存和跨会话恢复。
*
* <p><b>核心特性:</b>
* <ul>
* <li><b>JDBC 持久化</b>:使用 JdbcChatMemoryRepository 将对话历史保存到数据库</li>
* <li><b>跨会话恢复</b>:对话历史持久化后,可以在不同会话中恢复</li>
* <li><b>数据持久性</b>:应用重启后,对话历史不会丢失</li>
* <li><b>多会话管理</b>:通过 conversationId 管理多个独立的对话会话</li>
* <li><b>Advisor 组合</b>:演示如何组合使用多个 Advisor(PromptChatMemoryAdvisor 和 ReReadingAdvisor)</li>
* </ul>
*
* <p><b>与 TestMemory 类的区别:</b>
* <table border="1">
* <tr>
* <th>特性</th>
* <th>TestMemory</th>
* <th>TestJDBCMemory</th>
* </tr>
* <tr>
* <td>持久化存储</td>
* <td>可能使用内存或默认存储</td>
* <td>明确使用 JDBC 数据库存储</td>
* </tr>
* <tr>
* <td>数据持久性</td>
* <td>可能丢失(取决于配置)</td>
* <td>持久化到数据库,不会丢失</td>
* </tr>
* <tr>
* <td>适用场景</td>
* <td>测试、开发环境</td>
* <td>生产环境</td>
* </tr>
* <tr>
* <td>Advisor 组合</td>
* <td>仅使用 PromptChatMemoryAdvisor</td>
* <td>组合使用 PromptChatMemoryAdvisor 和 ReReadingAdvisor</td>
* </tr>
* </table>
*
* <p><b>JdbcChatMemoryRepository 说明:</b>
* <ul>
* <li><b>数据存储</b>:将对话消息存储到关系型数据库表中</li>
* <li><b>表结构</b>:通常包含 conversation_id、message_id、content、role、timestamp 等字段</li>
* <li><b>自动创建</b>:Spring AI 可以自动创建表结构(如果配置了 schema)</li>
* <li><b>查询优化</b>:支持按 conversationId 快速查询对话历史</li>
* <li><b>事务支持</b>:支持数据库事务,保证数据一致性</li>
* </ul>
*
* <p><b>数据库配置要求:</b>
* <ul>
* <li>需要在 application.properties 或 application.yml 中配置数据源</li>
* <li>需要创建相应的数据库表(可以通过 schema.sql 自动创建)</li>
* <li>确保 JdbcChatMemoryRepository Bean 已正确配置</li>
* </ul>
*
* <p><b>使用场景:</b>
* <ul>
* <li>生产环境中的对话记忆持久化</li>
* <li>需要长期保存对话历史的场景</li>
* <li>需要跨会话恢复对话历史的场景</li>
* <li>需要审计和分析对话历史的场景</li>
* <li>多服务器部署,需要共享对话历史的场景</li>
* </ul>
*
* <p><b>注意事项:</b>
* <ul>
* <li>确保数据库连接配置正确</li>
* <li>确保数据库表结构已创建</li>
* <li>注意数据库性能,大量对话历史可能影响查询速度</li>
* <li>考虑定期清理旧的对话历史,避免数据库过大</li>
* <li>在生产环境中,建议配置数据库连接池</li>
* </ul>
*
* @see com.xushu.springai.cc.memory.TestMemory 使用默认存储的对话记忆测试
* @see org.springframework.ai.chat.memory.repository.jdbc.JdbcChatMemoryRepository
* @see org.springframework.ai.chat.memory.MessageWindowChatMemory
* @see org.springframework.ai.chat.client.advisor.PromptChatMemoryAdvisor
*/
@SpringBootTest
public class TestJDBCMemory {
/**
* ChatClient 实例
* 在 @BeforeEach 方法中初始化,配置了 PromptChatMemoryAdvisor
*/
ChatClient chatClient;
/**
* 初始化 ChatClient
*
* <p>该方法在每个测试方法执行前运行,用于初始化 ChatClient 实例。
* ChatClient 配置了 PromptChatMemoryAdvisor,用于自动管理对话记忆。
*
* <p><b>配置说明:</b>
* <ul>
* <li>使用 DashScopeChatModel 作为 AI 模型</li>
* <li>配置 PromptChatMemoryAdvisor 自动管理对话记忆</li>
* <li>ChatMemory 由 Config 类配置,使用 JDBC 持久化存储</li>
* </ul>
*
* @param chatModel 自动注入的 DashScopeChatModel Bean
* @param chatMemory 自动注入的 ChatMemory Bean,由 Config 类配置,使用 JDBC 存储
*/
@BeforeEach
public void init(@Autowired DashScopeChatModel chatModel,
@Autowired ChatMemory chatMemory) {
chatClient = ChatClient
.builder(chatModel)
.defaultAdvisors(
PromptChatMemoryAdvisor.builder(chatMemory).build()
)
.build();
}
/**
* 测试使用 JDBC 持久化的对话记忆,并组合使用多个 Advisor
*
* <p>该方法演示了如何在使用 JDBC 持久化存储的同时,组合使用多个 Advisor。
* 包括 PromptChatMemoryAdvisor(自动管理对话记忆)和 ReReadingAdvisor(增强提示词)。
*
* <p><b>测试场景:</b>
* <ul>
* <li>第一轮对话:用户自我介绍,对话历史保存到数据库</li>
* <li>第二轮对话:询问姓名,从数据库恢复对话历史,AI 能够正确回答</li>
* <li>验证对话历史的持久化和恢复功能</li>
* <li>验证多个 Advisor 的组合使用</li>
* </ul>
*
* <p><b>Advisor 组合说明:</b>
* <ul>
* <li><b>PromptChatMemoryAdvisor</b>(defaultAdvisors):
* <ul>
* <li>自动从数据库获取对话历史</li>
* <li>自动将对话保存到数据库</li>
* <li>在责任链中较早执行</li>
* </ul>
* </li>
* <li><b>ReReadingAdvisor</b>(advisors):
* <ul>
* <li>增强用户提示词,添加"重新阅读"指令</li>
* <li>在 PromptChatMemoryAdvisor 之后执行</li>
* <li>对已包含历史消息的 Prompt 进行增强</li>
* </ul>
* </li>
* </ul>
*
* <p><b>执行流程:</b>
* <ol>
* <li><b>第一轮对话</b>:
* <ul>
* <li>用户输入:"你好,我叫徐庶!"</li>
* <li>PromptChatMemoryAdvisor.before():从数据库获取历史(首次为空)</li>
* <li>ReReadingAdvisor.before():增强提示词</li>
* <li>ChatModel 执行 AI 调用</li>
* <li>ReReadingAdvisor.after():不做修改</li>
* <li>PromptChatMemoryAdvisor.after():将对话保存到数据库</li>
* </ul>
* </li>
* <li><b>第二轮对话</b>:
* <ul>
* <li>用户输入:"我叫什么 ?"</li>
* <li>PromptChatMemoryAdvisor.before():从数据库恢复第一轮对话历史</li>
* <li>ReReadingAdvisor.before():增强包含历史消息的提示词</li>
* <li>ChatModel 执行 AI 调用,基于完整历史能够回答</li>
* <li>PromptChatMemoryAdvisor.after():将第二轮对话保存到数据库</li>
* </ul>
* </li>
* </ol>
*
* <p><b>数据库操作:</b>
* <ul>
* <li><b>保存操作</b>:每次对话后,JdbcChatMemoryRepository 会将消息保存到数据库</li>
* <li><b>查询操作</b>:每次对话前,从数据库查询指定 conversationId 的历史消息</li>
* <li><b>事务管理</b>:数据库操作在事务中执行,保证数据一致性</li>
* </ul>
*
* <p><b>conversationId 使用:</b>
* <ul>
* <li>使用 conversationId = "1" 标识当前对话会话</li>
* <li>所有对话历史都保存到 conversationId = "1" 的会话中</li>
* <li>数据库查询时,使用 conversationId 作为查询条件</li>
* </ul>
*
* <p><b>与 TestMemory.testChatOptions() 的对比:</b>
* <ul>
* <li>都使用 conversationId 管理会话</li>
* <li>都组合使用多个 Advisor</li>
* <li>TestJDBCMemory 使用 JDBC 持久化,TestMemory 可能使用内存存储</li>
* <li>TestJDBCMemory 的对话历史会持久化到数据库</li>
* </ul>
*
* <p><b>验证要点:</b>
* <ul>
* <li>验证对话历史能够正确保存到数据库</li>
* <li>验证对话历史能够从数据库正确恢复</li>
* <li>验证多个 Advisor 能够正确组合使用</li>
* <li>验证 AI 能够基于持久化的历史正确回答</li>
* </ul>
*
* <p><b>示例输出:</b>
* <pre>
* 第一轮回复:你好,徐庶!很高兴认识你。
* --------------------------------------------------------------------------
* 第二轮回复:你叫徐庶。
* </pre>
*
* <p><b>注意事项:</b>
* <ul>
* <li>确保数据库连接正常,否则测试会失败</li>
* <li>确保数据库表结构已创建</li>
* <li>测试后可以检查数据库,验证对话历史是否已保存</li>
* <li>多个 Advisor 的执行顺序很重要,会影响最终结果</li>
* </ul>
*
* @see com.xushu.springai.cc.ReReadingAdvisor
* @see org.springframework.ai.chat.client.advisor.PromptChatMemoryAdvisor
* @see org.springframework.ai.chat.memory.repository.jdbc.JdbcChatMemoryRepository
*/
@Test
public void testChatOptions() {
// 第一轮对话:用户自我介绍
// 使用 conversationId = "1",对话历史会保存到数据库
// 组合使用 ReReadingAdvisor(增强提示词)和 PromptChatMemoryAdvisor(管理记忆)
String content = chatClient.prompt()
.user("你好,我叫徐庶!")
.advisors(new ReReadingAdvisor()) // 增强提示词
.advisors(advisorSpec -> advisorSpec.param(ChatMemory.CONVERSATION_ID,"1")) // 指定会话ID
.call()
.content();
System.out.println(content);
System.out.println("--------------------------------------------------------------------------");
// 第二轮对话:询问姓名
// 继续使用 conversationId = "1",PromptChatMemoryAdvisor 会从数据库恢复第一轮的对话历史
// AI 能够看到之前的对话,知道用户叫徐庶,所以能正确回答
content = chatClient.prompt()
.user("我叫什么 ?")
.advisors(new ReReadingAdvisor()) // 增强提示词
.advisors(advisorSpec -> advisorSpec.param(ChatMemory.CONVERSATION_ID,"1")) // 指定会话ID
.call()
.content();
System.out.println(content);
}
/**
* 测试配置类
*
* <p>该类配置使用 JDBC 持久化存储的 ChatMemory Bean。
* 与 TestMemory.Config 的区别在于,这里明确使用 JdbcChatMemoryRepository 作为持久化存储。
*
* <p><b>配置说明:</b>
* <ul>
* <li>使用 MessageWindowChatMemory 实现对话记忆管理</li>
* <li>配置 maxMessages = 1(示例配置,实际可根据需求调整)</li>
* <li>使用 JdbcChatMemoryRepository 实现数据库持久化</li>
* </ul>
*
* <p><b>JdbcChatMemoryRepository 说明:</b>
* <ul>
* <li>Spring AI 提供的 JDBC 实现</li>
* <li>自动注入,由 Spring Boot 自动配置</li>
* <li>需要配置数据源和数据库表结构</li>
* <li>支持标准的 SQL 数据库(MySQL、PostgreSQL、H2 等)</li>
* </ul>
*
* @see org.springframework.ai.chat.memory.repository.jdbc.JdbcChatMemoryRepository
* @see com.xushu.springai.cc.memory.TestMemory.Config
*/
@TestConfiguration
static class Config {
/**
* 配置使用 JDBC 持久化存储的 ChatMemory Bean
*
* <p>该方法创建并配置 MessageWindowChatMemory 实例,使用 JdbcChatMemoryRepository
* 作为持久化存储,将对话历史保存到关系型数据库中。
*
* <p><b>配置详情:</b>
* <ul>
* <li>使用 MessageWindowChatMemory 实现</li>
* <li>设置 maxMessages = 1(示例配置)</li>
* <li>使用 JdbcChatMemoryRepository 实现数据库持久化</li>
* </ul>
*
* <p><b>数据库要求:</b>
* <ul>
* <li>需要配置数据源(DataSource)</li>
* <li>需要创建相应的数据库表</li>
* <li>JdbcChatMemoryRepository 会自动注入,无需手动创建</li>
* </ul>
*
* @param chatMemoryRepository 自动注入的 JdbcChatMemoryRepository Bean,
* 用于将对话历史持久化到数据库
* @return 配置好的 ChatMemory 实例,使用 JDBC 持久化存储
*
* @see org.springframework.ai.chat.memory.MessageWindowChatMemory
* @see org.springframework.ai.chat.memory.repository.jdbc.JdbcChatMemoryRepository
*/
@Bean
ChatMemory chatMemory(JdbcChatMemoryRepository chatMemoryRepository) {
return MessageWindowChatMemory
.builder()
.maxMessages(1) // 只保留最近 1 条消息(示例配置)
.chatMemoryRepository(chatMemoryRepository) // JDBC 数据库持久化
.build();
}
}
}开始测试
数据库中的值

redis存储对话记忆
多层次记忆架构痛点
记忆多=聪明,记忆多会触发token上限
要知道,无论你用什么存储对话以及,也只能保证服务端的存储性能。
但是一旦聊天记录多了依然会超过token上限,但是有时候我们依然希望存储更多的聊天记录,这样才能保证整个对话更像"人"。
多层次记忆架构(模仿人类)
-
近期记忆:保留在上下文窗口中的最近几轮对话,每轮对话完成后立即存储(可通过 ChatMemory) ;
-
中期记忆:通过RAG检索的相关历史对话(每轮对话完成后,异步将对话内容转换为向量并存入向量数据库)
-
长期记忆:关键信息的固化总结
- 方式一:定时批处理
- 通过定时任务(如每天或每周)对积累的对话进行总结和提炼
- 提取关键信息、用户偏好、重要事实等
- 批处理方式降低计算成本,适合大规模处理
- 方式二:关键点实时处理
- 在对话中识别出关键信息点时立即提取并存储
- 例如,当用户明确表达偏好、提供个人信息或设置持久性指令时
- 采用"写入触发器"机制,在特定条件下自动更新长期记忆
- 方式一:定时批处理
配置application.yml
java
spring:
ai:
memory:
redis:
host: localhost
port: 6379
timeout: 5000
password: root
java
package com.xushu.springai.cc.memory;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.client.advisor.PromptChatMemoryAdvisor;
import org.springframework.ai.chat.memory.ChatMemory;
import org.springframework.ai.chat.memory.MessageWindowChatMemory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.boot.test.context.TestConfiguration;
import org.springframework.context.annotation.Bean;
import com.alibaba.cloud.ai.dashscope.chat.DashScopeChatModel;
import com.alibaba.cloud.ai.memory.redis.RedisChatMemoryRepository;
import com.xushu.springai.cc.ReReadingAdvisor;
/**
* 测试使用 Redis 持久化存储的对话记忆
*
* <p>该类演示了如何使用 RedisChatMemoryRepository 将对话历史持久化到 Redis 中。
* Redis 作为高性能的内存数据库,特别适合高并发场景下的对话记忆存储。
*
* <p><b>核心特性:</b>
* <ul>
* <li><b>Redis 持久化</b>:使用 RedisChatMemoryRepository 将对话历史保存到 Redis</li>
* <li><b>高性能</b>:Redis 基于内存存储,读写速度极快</li>
* <li><b>高并发支持</b>:Redis 支持高并发访问,适合多用户场景</li>
* <li><b>数据持久性</b>:支持 RDB 和 AOF 持久化,数据不会丢失</li>
* <li><b>分布式支持</b>:Redis 支持集群模式,适合分布式部署</li>
* <li><b>多会话管理</b>:通过 conversationId 管理多个独立的对话会话</li>
* <li><b>Advisor 组合</b>:演示如何组合使用多个 Advisor(PromptChatMemoryAdvisor 和 ReReadingAdvisor)</li>
* </ul>
*
* <p><b>与 TestJDBCMemory 的对比:</b>
* <table border="1">
* <tr>
* <th>特性</th>
* <th>TestJDBCMemory(JDBC)</th>
* <th>TestRedisMemory(Redis)</th>
* </tr>
* <tr>
* <td>存储类型</td>
* <td>关系型数据库(磁盘)</td>
* <td>内存数据库(内存)</td>
* </tr>
* <tr>
* <td>读写性能</td>
* <td>较慢(磁盘 I/O)</td>
* <td>极快(内存访问)</td>
* </tr>
* <tr>
* <td>并发能力</td>
* <td>中等</td>
* <td>极高</td>
* </tr>
* <tr>
* <td>数据容量</td>
* <td>大(受磁盘限制)</td>
* <td>中等(受内存限制)</td>
* </tr>
* <tr>
* <td>适用场景</td>
* <td>长期存储、数据分析</td>
* <td>高并发、实时访问</td>
* </tr>
* <tr>
* <td>成本</td>
* <td>较低(磁盘存储)</td>
* <td>较高(内存存储)</td>
* </tr>
* </table>
*
* <p><b>RedisChatMemoryRepository 说明:</b>
* <ul>
* <li><b>数据存储</b>:将对话消息存储到 Redis 中,使用 Hash 或 String 数据结构</li>
* <li><b>Key 设计</b>:通常使用 conversationId 作为 key 的一部分</li>
* <li><b>过期策略</b>:可以配置 TTL(Time To Live),自动清理过期数据</li>
* <li><b>序列化</b>:消息对象需要序列化后存储(JSON、Protobuf 等)</li>
* <li><b>原子操作</b>:Redis 支持原子操作,保证数据一致性</li>
* </ul>
*
* <p><b>Redis 配置要求:</b>
* <ul>
* <li>需要在 application.properties 或 application.yml 中配置 Redis 连接信息</li>
* <li>配置项包括:host、port、password(可选)、timeout</li>
* <li>确保 Redis 服务已启动并可访问</li>
* <li>建议配置 Redis 持久化(RDB 或 AOF)</li>
* </ul>
*
* <p><b>使用场景:</b>
* <ul>
* <li>高并发场景下的对话记忆存储</li>
* <li>需要快速读写对话历史的场景</li>
* <li>分布式部署,需要共享对话历史的场景</li>
* <li>实时聊天应用</li>
* <li>需要临时存储对话历史的场景(可配置 TTL)</li>
* </ul>
*
* <p><b>注意事项:</b>
* <ul>
* <li>确保 Redis 服务正常运行</li>
* <li>确保 Redis 连接配置正确</li>
* <li>注意 Redis 内存使用,避免内存溢出</li>
* <li>考虑配置 Redis 持久化,避免数据丢失</li>
* <li>对于大量对话历史,考虑使用 Redis 集群</li>
* <li>建议配置 Redis 连接池,提高性能</li>
* </ul>
*
* @see com.xushu.springai.cc.memory.TestJDBCMemory 使用 JDBC 持久化的对话记忆测试
* @see com.xushu.springai.cc.memory.TestMemory 使用默认存储的对话记忆测试
* @see com.alibaba.cloud.ai.memory.redis.RedisChatMemoryRepository
* @see org.springframework.ai.chat.memory.MessageWindowChatMemory
* @see org.springframework.ai.chat.client.advisor.PromptChatMemoryAdvisor
*/
@SpringBootTest
public class TestRedisMemory {
/**
* ChatClient 实例
* 在 @BeforeEach 方法中初始化,配置了 PromptChatMemoryAdvisor
*/
ChatClient chatClient;
/**
* 初始化 ChatClient
*
* <p>该方法在每个测试方法执行前运行,用于初始化 ChatClient 实例。
* ChatClient 配置了 PromptChatMemoryAdvisor,用于自动管理对话记忆。
*
* <p><b>配置说明:</b>
* <ul>
* <li>使用 DashScopeChatModel 作为 AI 模型</li>
* <li>配置 PromptChatMemoryAdvisor 自动管理对话记忆</li>
* <li>ChatMemory 由 Config 类配置,使用 Redis 持久化存储</li>
* </ul>
*
* @param chatModel 自动注入的 DashScopeChatModel Bean
* @param chatMemory 自动注入的 ChatMemory Bean,由 Config 类配置,使用 Redis 存储
*/
@BeforeEach
public void init(@Autowired DashScopeChatModel chatModel,
@Autowired ChatMemory chatMemory) {
chatClient = ChatClient
.builder(chatModel)
.defaultAdvisors(
PromptChatMemoryAdvisor.builder(chatMemory).build()
)
.build();
}
/**
* 测试使用 Redis 持久化的对话记忆,并组合使用多个 Advisor
*
* <p>该方法演示了如何在使用 Redis 持久化存储的同时,组合使用多个 Advisor。
* 包括 PromptChatMemoryAdvisor(自动管理对话记忆)和 ReReadingAdvisor(增强提示词)。
*
* <p><b>测试场景:</b>
* <ul>
* <li>第一轮对话:用户自我介绍,对话历史保存到 Redis</li>
* <li>第二轮对话:询问姓名,从 Redis 恢复对话历史,AI 能够正确回答</li>
* <li>验证对话历史的持久化和恢复功能</li>
* <li>验证多个 Advisor 的组合使用</li>
* </ul>
*
* <p><b>Advisor 组合说明:</b>
* <ul>
* <li><b>PromptChatMemoryAdvisor</b>(defaultAdvisors):
* <ul>
* <li>自动从 Redis 获取对话历史</li>
* <li>自动将对话保存到 Redis</li>
* <li>在责任链中较早执行</li>
* </ul>
* </li>
* <li><b>ReReadingAdvisor</b>(advisors):
* <ul>
* <li>增强用户提示词,添加"重新阅读"指令</li>
* <li>在 PromptChatMemoryAdvisor 之后执行</li>
* <li>对已包含历史消息的 Prompt 进行增强</li>
* </ul>
* </li>
* </ul>
*
* <p><b>执行流程:</b>
* <ol>
* <li><b>第一轮对话</b>:
* <ul>
* <li>用户输入:"你好,我叫徐庶!"</li>
* <li>PromptChatMemoryAdvisor.before():从 Redis 获取历史(首次为空)</li>
* <li>ReReadingAdvisor.before():增强提示词</li>
* <li>ChatModel 执行 AI 调用</li>
* <li>ReReadingAdvisor.after():不做修改</li>
* <li>PromptChatMemoryAdvisor.after():将对话保存到 Redis</li>
* </ul>
* </li>
* <li><b>第二轮对话</b>:
* <ul>
* <li>用户输入:"我叫什么 ?"</li>
* <li>PromptChatMemoryAdvisor.before():从 Redis 恢复第一轮对话历史</li>
* <li>ReReadingAdvisor.before():增强包含历史消息的提示词</li>
* <li>ChatModel 执行 AI 调用,基于完整历史能够回答</li>
* <li>PromptChatMemoryAdvisor.after():将第二轮对话保存到 Redis</li>
* </ul>
* </li>
* </ol>
*
* <p><b>Redis 操作:</b>
* <ul>
* <li><b>保存操作</b>:每次对话后,RedisChatMemoryRepository 会将消息保存到 Redis</li>
* <li><b>查询操作</b>:每次对话前,从 Redis 查询指定 conversationId 的历史消息</li>
* <li><b>数据结构</b>:使用 Redis Hash 或 String 存储对话消息</li>
* <li><b>性能优势</b>:Redis 基于内存,读写速度极快</li>
* </ul>
*
* <p><b>conversationId 使用:</b>
* <ul>
* <li>使用 conversationId = "1" 标识当前对话会话</li>
* <li>所有对话历史都保存到 conversationId = "1" 的会话中</li>
* <li>Redis 查询时,使用 conversationId 作为 key 的一部分</li>
* </ul>
*
* <p><b>扩展场景说明:</b>
* <ul>
* <li>代码中的注释提到了 MQ 异步处理和向量数据库存储</li>
* <li>这是实际生产环境中的常见架构:
* <ul>
* <li>对话历史保存到 Redis(快速访问)</li>
* <li>通过消息队列(MQ)异步处理</li>
* <li>存储到向量数据库(用于相似性检索)</li>
* <li>支持 RAG(检索增强生成)场景</li>
* </ul>
* </li>
* </ul>
*
* <p><b>与 TestJDBCMemory.testChatOptions() 的对比:</b>
* <ul>
* <li>都使用 conversationId 管理会话</li>
* <li>都组合使用多个 Advisor</li>
* <li>TestRedisMemory 使用 Redis 持久化,性能更高</li>
* <li>TestRedisMemory 适合高并发场景</li>
* <li>TestJDBCMemory 适合长期存储和数据分析</li>
* </ul>
*
* <p><b>验证要点:</b>
* <ul>
* <li>验证对话历史能够正确保存到 Redis</li>
* <li>验证对话历史能够从 Redis 正确恢复</li>
* <li>验证多个 Advisor 能够正确组合使用</li>
* <li>验证 AI 能够基于持久化的历史正确回答</li>
* <li>验证 Redis 读写性能</li>
* </ul>
*
* <p><b>示例输出:</b>
* <pre>
* 第一轮回复:你好,徐庶!很高兴认识你。
* --------------------------------------------------------------------------
* 第二轮回复:你叫徐庶。
* </pre>
*
* <p><b>注意事项:</b>
* <ul>
* <li>确保 Redis 服务正常运行,否则测试会失败</li>
* <li>确保 Redis 连接配置正确</li>
* <li>测试后可以使用 Redis 客户端工具验证数据是否已保存</li>
* <li>多个 Advisor 的执行顺序很重要,会影响最终结果</li>
* <li>注意 Redis 内存使用,避免内存溢出</li>
* </ul>
*
* @see com.xushu.springai.cc.ReReadingAdvisor
* @see org.springframework.ai.chat.client.advisor.PromptChatMemoryAdvisor
* @see com.alibaba.cloud.ai.memory.redis.RedisChatMemoryRepository
*/
@Test
public void testChatOptions() {
// 第一轮对话:用户自我介绍
// 使用 conversationId = "1",对话历史会保存到 Redis
// 组合使用 ReReadingAdvisor(增强提示词)和 PromptChatMemoryAdvisor(管理记忆)
String content = chatClient.prompt()
.user("你好,我叫徐庶!")
.advisors(new ReReadingAdvisor()) // 增强提示词
.advisors(advisorSpec -> advisorSpec.param(ChatMemory.CONVERSATION_ID,"1")) // 指定会话ID
.call()
.content();
System.out.println(content);
System.out.println("--------------------------------------------------------------------------");
// 扩展场景说明:实际生产环境中的架构
// MQ 异步处理 ----> 存储向量数据库 ---> 相似性检索
// 1. 对话历史保存到 Redis(快速访问)
// 2. 通过消息队列(MQ)异步处理对话历史
// 3. 将对话历史存储到向量数据库(如 Milvus、Pinecone 等)
// 4. 支持相似性检索,用于 RAG(检索增强生成)场景
// 第二轮对话:询问姓名
// 继续使用 conversationId = "1",PromptChatMemoryAdvisor 会从 Redis 恢复第一轮的对话历史
// AI 能够看到之前的对话,知道用户叫徐庶,所以能正确回答
content = chatClient.prompt()
.user("我叫什么 ?")
.advisors(new ReReadingAdvisor()) // 增强提示词
.advisors(advisorSpec -> advisorSpec.param(ChatMemory.CONVERSATION_ID,"1")) // 指定会话ID
.call()
.content();
System.out.println(content);
}
/**
* 测试配置类
*
* <p>该类配置使用 Redis 持久化存储的 ChatMemory Bean。
* 与 TestJDBCMemory.Config 的区别在于,这里使用 RedisChatMemoryRepository 作为持久化存储。
*
* <p><b>配置说明:</b>
* <ul>
* <li>使用 MessageWindowChatMemory 实现对话记忆管理</li>
* <li>配置 maxMessages = 10(保留最近 10 条消息)</li>
* <li>使用 RedisChatMemoryRepository 实现 Redis 持久化</li>
* <li>从配置文件读取 Redis 连接信息</li>
* </ul>
*
* <p><b>Redis 配置参数:</b>
* <ul>
* <li><b>host</b>:Redis 服务器地址</li>
* <li><b>port</b>:Redis 服务器端口(默认 6379)</li>
* <li><b>password</b>:Redis 密码(可选,如果未设置密码则注释该项)</li>
* <li><b>timeout</b>:连接超时时间(毫秒)</li>
* </ul>
*
* <p><b>配置文件示例(application.properties):</b>
* <pre>
* spring.ai.memory.redis.host=localhost
* spring.ai.memory.redis.port=6379
* spring.ai.memory.redis.password=your_password
* spring.ai.memory.redis.timeout=2000
* </pre>
*
* @see com.alibaba.cloud.ai.memory.redis.RedisChatMemoryRepository
* @see com.xushu.springai.cc.memory.TestJDBCMemory.Config
*/
@TestConfiguration
static class Config {
/**
* Redis 服务器地址
* 从配置文件 spring.ai.memory.redis.host 读取
*/
@Value("${spring.ai.memory.redis.host}")
private String redisHost;
/**
* Redis 服务器端口
* 从配置文件 spring.ai.memory.redis.port 读取
*/
@Value("${spring.ai.memory.redis.port}")
private int redisPort;
/**
* Redis 密码
* 从配置文件 spring.ai.memory.redis.password 读取
* 如果 Redis 未设置密码,则注释该项
*/
@Value("${spring.ai.memory.redis.password}")
private String redisPassword;
/**
* Redis 连接超时时间(毫秒)
* 从配置文件 spring.ai.memory.redis.timeout 读取
*/
@Value("${spring.ai.memory.redis.timeout}")
private int redisTimeout;
/**
* 配置 RedisChatMemoryRepository Bean
*
* <p>该方法创建并配置 RedisChatMemoryRepository 实例,用于将对话历史
* 持久化到 Redis 中。
*
* <p><b>配置详情:</b>
* <ul>
* <li>使用 builder 模式创建 RedisChatMemoryRepository</li>
* <li>配置 Redis 连接信息(host、port、password、timeout)</li>
* <li>如果 Redis 未设置密码,需要注释 .password() 配置</li>
* </ul>
*
* <p><b>注意事项:</b>
* <ul>
* <li>确保 Redis 服务已启动并可访问</li>
* <li>如果 Redis 设置了密码,必须配置 password</li>
* <li>如果 Redis 未设置密码,必须注释 .password() 配置,否则会连接失败</li>
* <li>timeout 应该根据网络情况合理设置</li>
* </ul>
*
* @return 配置好的 RedisChatMemoryRepository 实例
*
* @see com.alibaba.cloud.ai.memory.redis.RedisChatMemoryRepository
*/
@Bean
public RedisChatMemoryRepository redisChatMemoryRepository() {
return RedisChatMemoryRepository.builder()
.host(redisHost) // Redis 服务器地址
.port(redisPort) // Redis 服务器端口
// 若没有设置密码则注释该项
.password(redisPassword) // Redis 密码(如果设置了密码,取消注释;如果未设置密码,注释此行)
.timeout(redisTimeout) // 连接超时时间
.build();
}
/**
* 配置使用 Redis 持久化存储的 ChatMemory Bean
*
* <p>该方法创建并配置 MessageWindowChatMemory 实例,使用 RedisChatMemoryRepository
* 作为持久化存储,将对话历史保存到 Redis 中。
*
* <p><b>配置详情:</b>
* <ul>
* <li>使用 MessageWindowChatMemory 实现</li>
* <li>设置 maxMessages = 10(保留最近 10 条消息)</li>
* <li>使用 RedisChatMemoryRepository 实现 Redis 持久化</li>
* </ul>
*
* <p><b>maxMessages 说明:</b>
* <ul>
* <li>设置为 10,表示只保留最近 10 条消息</li>
* <li>超出窗口的消息会被自动移除</li>
* <li>可以根据业务需求调整,平衡上下文长度和内存使用</li>
* <li>Redis 基于内存,建议合理设置,避免占用过多内存</li>
* </ul>
*
* <p><b>Redis 要求:</b>
* <ul>
* <li>RedisChatMemoryRepository 需要先配置(通过 redisChatMemoryRepository() 方法)</li>
* <li>确保 Redis 服务正常运行</li>
* <li>确保 Redis 连接配置正确</li>
* </ul>
*
* @param chatMemoryRepository 自动注入的 RedisChatMemoryRepository Bean,
* 用于将对话历史持久化到 Redis
* @return 配置好的 ChatMemory 实例,使用 Redis 持久化存储
*
* @see org.springframework.ai.chat.memory.MessageWindowChatMemory
* @see com.alibaba.cloud.ai.memory.redis.RedisChatMemoryRepository
*/
@Bean
ChatMemory chatMemory(RedisChatMemoryRepository chatMemoryRepository) {
return MessageWindowChatMemory
.builder()
.maxMessages(10) // 保留最近 10 条消息
.chatMemoryRepository(chatMemoryRepository) // Redis 持久化存储
.build();
}
}
}测试 :