达梦数据库适配方案总结
前言
在近几年的国内开发领域,不少同学或多或少都曾听闻甚至使用过一些国产数据库。其中,达梦数据库的应用尤为广泛,众多企业都存在将原有数据库迁移到达梦数据库的需求。达梦数据库在安装时自带了迁移工具,这使得数据迁移过程并不复杂。然而,业务代码中的 SQL 语句往往存在诸多不适配的情况,需要同步进行修改调整。
下面,我想分享一下自己是如何提前规避未来数据库迁移可能带来的问题的。自国产数据库迁移趋势初现端倪,我在后端开发过程中,便开始大量运用持久层框架,像 MyBatis、MyBatis plus 等,以此避免直接编写 JDBC 代码。秉持着"能不写 SQL 就尽量不写"的原则,因为较高版本的 MyBatis plus(例如 3.0 以上版本)对达梦数据库有着良好的支持。如此一来,即便后续从 MySQL 迁移到达梦数据库,业务代码也无需进行大规模的改动,大大降低了迁移成本与风险。
此时,或许有人会提及优化方面的问题。倘若你并非架构师,大可放心使用这些框架;若你身为架构师,也无需为此类问题纠结,毕竟有众多专业大佬在维护这些框架,在优化层面,它们未必逊色于你。在我工作中,遇到过不少人热衷于自己"造轮子",试图以此彰显自身技术的高超。实际上,这大可不必。未来负责维护代码的人看到那些复杂冗余的代码,大概率只会心生抱怨。当然,如果你的工作性质特殊,确实需要针对某些细微之处进行优化,那自然另当别论。
如果是老项目,已经编写了大量SQL代码,那就需要对其进行专门的适配,接下来以MySQL迁移到达梦为例,给大家展示整个流程。
达梦数据库
简介
达梦数据库是武汉达梦数据库股份有限公司自主研发的数据库管理系统,具有自主知识产权,其版本包括DM8。该系统采用多级存储架构与内存计算技术,支持大规模数据处理,兼容OLTP和OLAP请求,提供存储加密功能及高可用解决方案,并通过了公安部安全四级评测和EAL4级认证 。该系统基于对等无共享MPP架构,支持SQL并行处理与自动化分区,并采用Raft共识算法实现多副本事务一致性。
安装
根据官方文档所示流程进行安装:点击跳转官方文档
正常安装完成后将新增以下工具:

配置实例
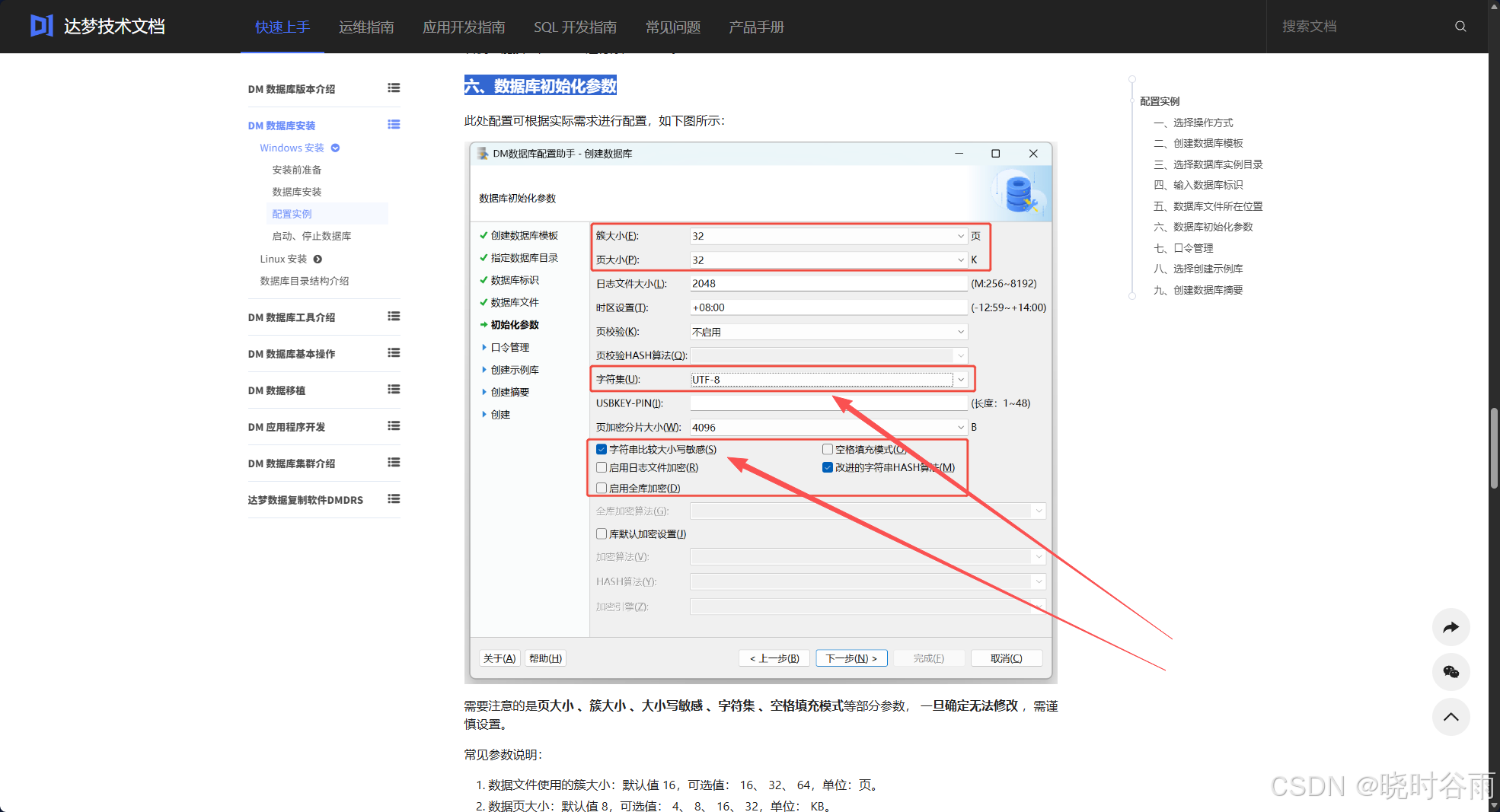
根据官方文档所示流程进行配置:点击跳转官方文档
需要注意文档中的第六步,箭头所指的字符集和大小写敏感,请务必取消勾选大小写敏感,否则将大大增加适配难度,且一旦配置完成后将无法再修改大小写敏感!
数据迁移
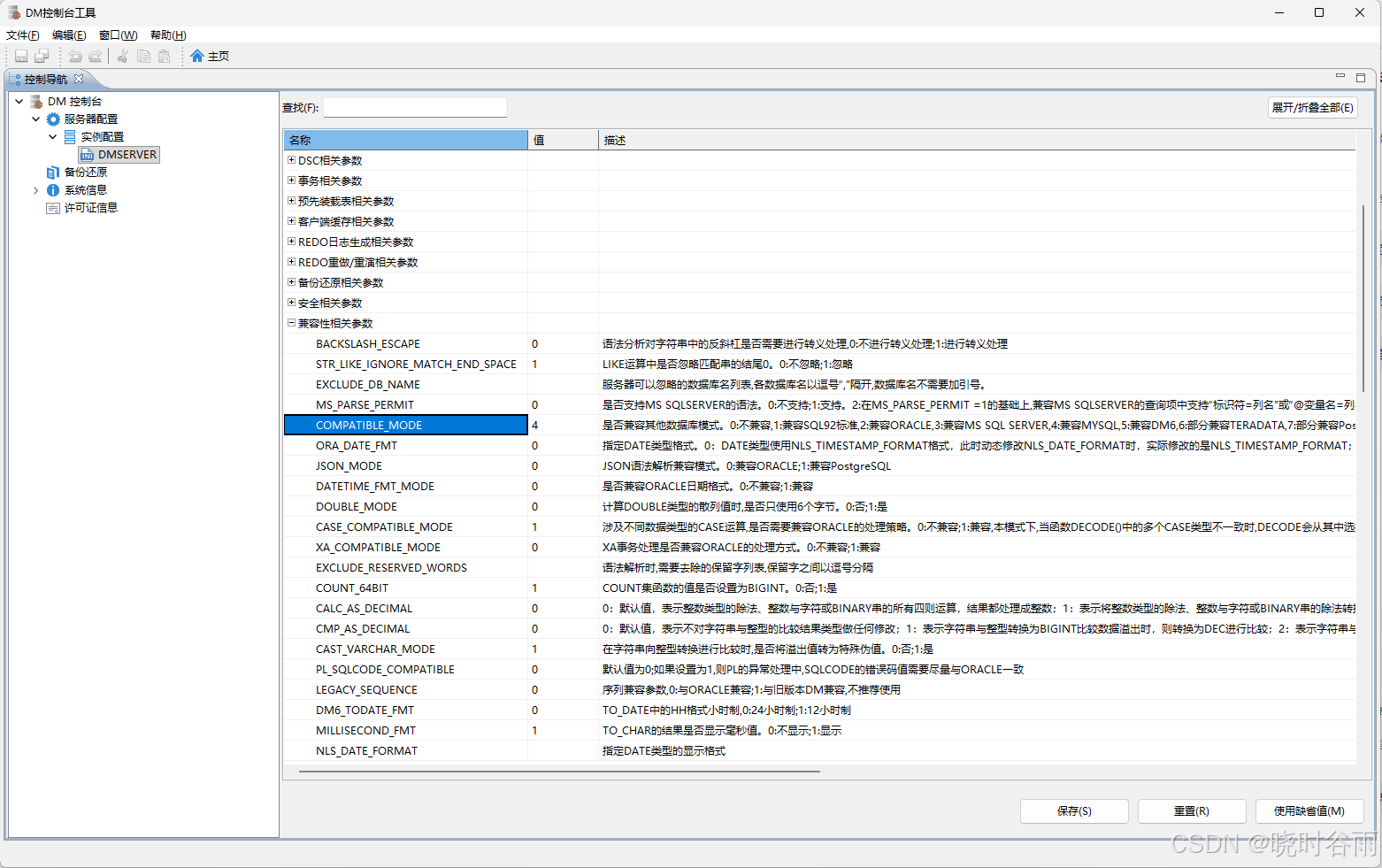
迁移前建议先仔细阅读官方迁移文档:点击跳转官方文档,其中比较重要的兼容性设置需要在控制台工具中进行修改。

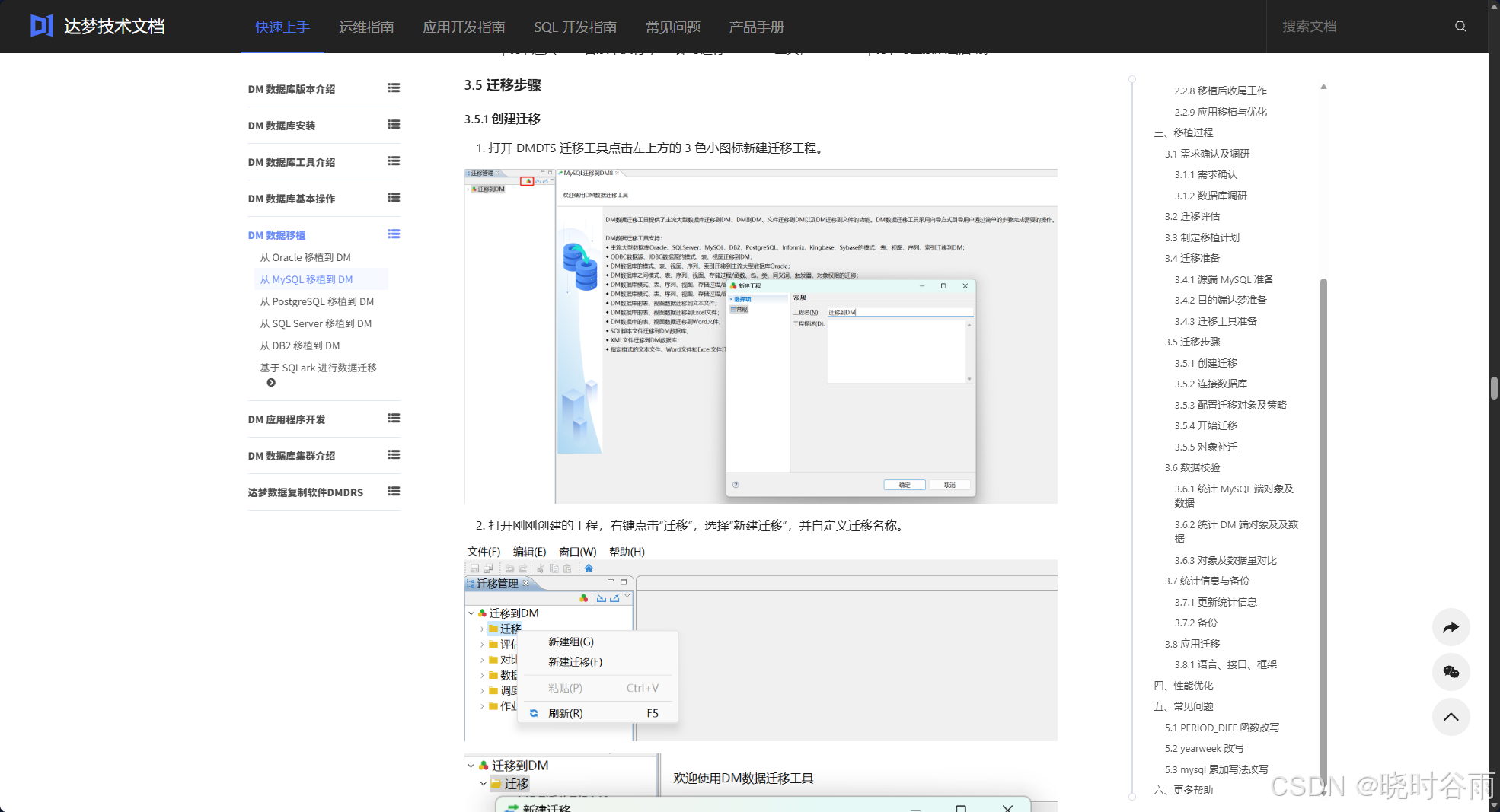
配置完成后,即可从文档的3.5开始迁移步骤。
后端配置
后端架构支持的话,最好做多环境配置和切换,以常用的springboot框架为例:
application.yml
application
# active 用于指定当前激活的配置文件,从而加载对应的环境配置。
spring:
profiles:
active: 这里的参数根据环境变化 mysql/mdapplication-dm.yml
application
# dm环境数据库连接配置
spring:
datasource:
type: com.alibaba.druid.pool.DruidDataSource
druid:
driver-class-name: dm.jdbc.driver.DmDriver
url: jdbc:dm://127.0.0.1:5236/TEST?useUnicode=true&characterEncoding=UTF8&serverTimezone=Asia/Shanghai&useSSL=true
username: SYSDBA
password: ******
# 其作用是在每次获取数据库连接时自动执行指定的SQL语句,该配置是MySQL迁移到达梦时的重要平滑手段,通过自动切换模式,让业务代码无需大量修改表名前缀
connection-init-sqls: [ "SET SCHEMA TEST" ]
在mapper文件夹下创建mysql、md两个文件夹,配置文件中指定加载mapper.xml文件路径,读取对应环境语法的SQL文件
application-dm.yml
application
mybatis:
mapper-locations: classpath:mapper/dm/**/*.xmlapplication-mysql.yml
application
mybatis:
mapper-locations: classpath:mapper/mysql/**/*.xml函数适配
达梦数据库与其他数据库在语法上必然存在部分差异,这就要求我们开展适配工作。而且,大家所使用的达梦数据库版本参差不齐,有新有旧。据了解,新版本已经自行适配了许多以往无法使用的函数和方法。不过,鉴于不同版本之间存在差异,我无法确切地指出哪些函数必须进行适配,哪些函数无法适配。因此,我在这里仅列举几个示例,旨在为大家在遇到问题时提供解决思路。至于具体问题的解决方案,大家可以依据自身使用的版本去查阅相关资料。
- 达梦没有该函数且没有相似功能的函数 ,这就要我们创建自定义函数,以MySQL中的
FIND_IN_SET函数为例(据说新版本达梦已经适配了该函数,比自定义函数效率高):
sql
CREATE OR REPLACE FUNCTION FIND_IN_SET
(
piv_str1 varchar2,
piv_str2 varchar2,
p_sep varchar2 := ',')
RETURN NUMBER
IS
l_idx number:=0; -- 用于计算piv_str2中分隔符的位置
str varchar2(500); -- 根据分隔符截取的子字符串
piv_str varchar2(500) := piv_str2; -- 将piv_str2赋值给piv_str
res number :=0; -- 返回结果
loopIndex number :=0;
BEGIN
-- 如果piv_str中没有分割符,直接判断piv_str1和piv_str是否相等,相等 res=1
IF instr(piv_str, p_sep, 1) = 0 THEN
IF piv_str = piv_str1 THEN
res := 1;
END IF;
ELSE
-- 循环按分隔符截取piv_str
LOOP
l_idx := instr(piv_str, p_sep);
loopIndex:=loopIndex+1;
-- 当piv_str中还有分隔符时
IF l_idx > 0 THEN
-- 截取第一个分隔符前的字段str
str:= substr(piv_str, 1, l_idx-1);
-- 判断 str 和piv_str1 是否相等,相等 res=1 并结束循环判断
IF str = piv_str1 THEN
res:= loopIndex;
EXIT;
END IF;
piv_str := substr(piv_str, l_idx+length(p_sep));
ELSE
-- 当截取后的piv_str 中不存在分割符时,判断piv_str和piv_str1是否相等,相等 res=1
IF piv_str = piv_str1 THEN
res:= loopIndex;
END IF;
-- 无论最后是否相等,都跳出循环
EXIT;
END IF;
END LOOP;
-- 结束循环
END IF;
-- 返回res
RETURN res;
END FIND_IN_SET;
create table TABLE_T(id int,ids varchar(10));
insert into TABLE_T values(1,'2,33');
insert into TABLE_T values(1,'20');
insert into TABLE_T values(1,'6,88');
insert into TABLE_T values(1,'8');
insert into TABLE_T values(1,'6,12');
insert into TABLE_T values(1,'10,15');
commit;
select t.* from TABLE_T t where find_in_set('6', t.ids) > 0- 达梦没有该函数但有相似功能的函数 ,这就要我们自行创建函数,以MySQL中的
GROUP_CONCAT函数为例(达梦的wm_concat函数与之功能相似):
sql
# 在达梦数据库中创建一个名为group_concat的公共同义词,指向达梦内置的wm_concat函数,使得原本使用MySQL GROUP_CONCAT函数的SQL语句无需修改即可在达梦中执行。
CREATE OR REPLACE PUBLIC SYNONYM group_concat FOR wm_concat;语法适配
语法上的差异较多,我下面列出一些常见的差异如何修改,其他的可以参考官方文档:点击跳转官方文档
- 更新语句执行后需要再执行
commit;才能生效
错误:
sql
UPDATE test SET a=1 WHERE b=1;正确:
sql
UPDATE test SET a=1 WHERE b=1;
commit;- 反引号 ` 报错,sql语句、实体类中的反引号都需要删掉:
错误:
sql
SELECT * FROM `TEST` WHERE `A` = 1 AND `B` = 1
java
@Table("test")
public class Test {
@Column(name = "`a`")
private String a;
@Column(name = "`b`")
private String b;
}正确:
sql
SELECT * FROM TEST WHERE A = 1 AND B = 1
java
@Table("test")
public class Test {
@Column(name = "a")
private String a;
@Column(name = "b")
private String b;
}GROUP BY后面不能使用别名:
错误:
sql
SELECT a, b as b1
FROM test
GROUP BY a, b1正确:
sql
SELECT a, b as b1
FROM test
GROUP BY a, bORDER BY与GROUP BY一起使用时,ORDER BY后面的字段必须包含在GROUP BY里面
错误:
sql
SELECT a, b
FROM test
GROUP BY a, b
ORDER BY a正确:
sql
SELECT a, b
FROM test
GROUP BY a, b
ORDER BY a, b结束语
综上所述,国产数据库迁移已成为当下开发领域不可忽视的趋势,达梦数据库作为其中的佼佼者,其迁移工作既蕴含机遇也充满挑战。通过提前运用持久层框架,我们能够有效降低迁移成本与风险;而对于老项目,专门的适配流程则是确保迁移顺利推进的关键。希望本次分享的内容能为大家在国产数据库迁移的实践中提供有益的参考,助力大家在数据库迁移的道路上少走弯、平稳地完成迁移任务,推动业务系统的持续稳定发展。
距离上次迁移达梦过去挺久的了,可能有些方案已经过时,如有不对的地方或有更好的方案,欢迎大家在评论区讨论和分享。