网站地址:爬虫练习网站
找加密参数及位置
找到接口:
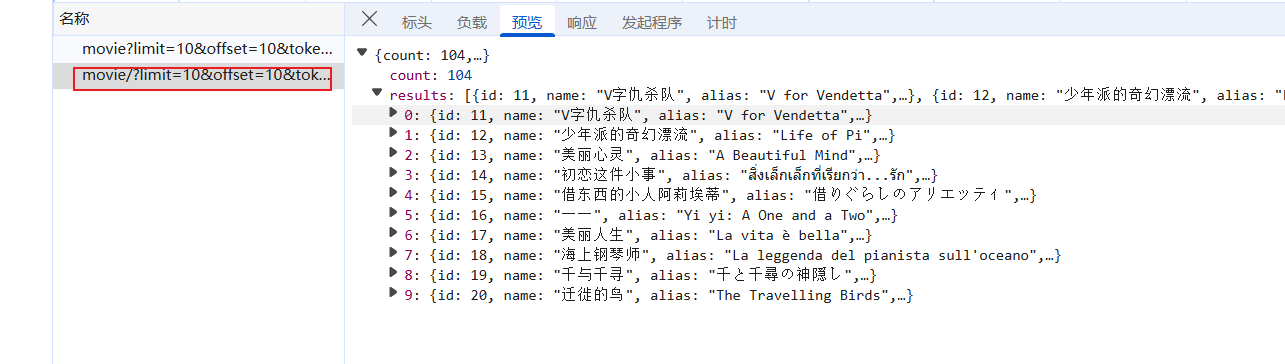
加密参数:

直接搜索关键字:
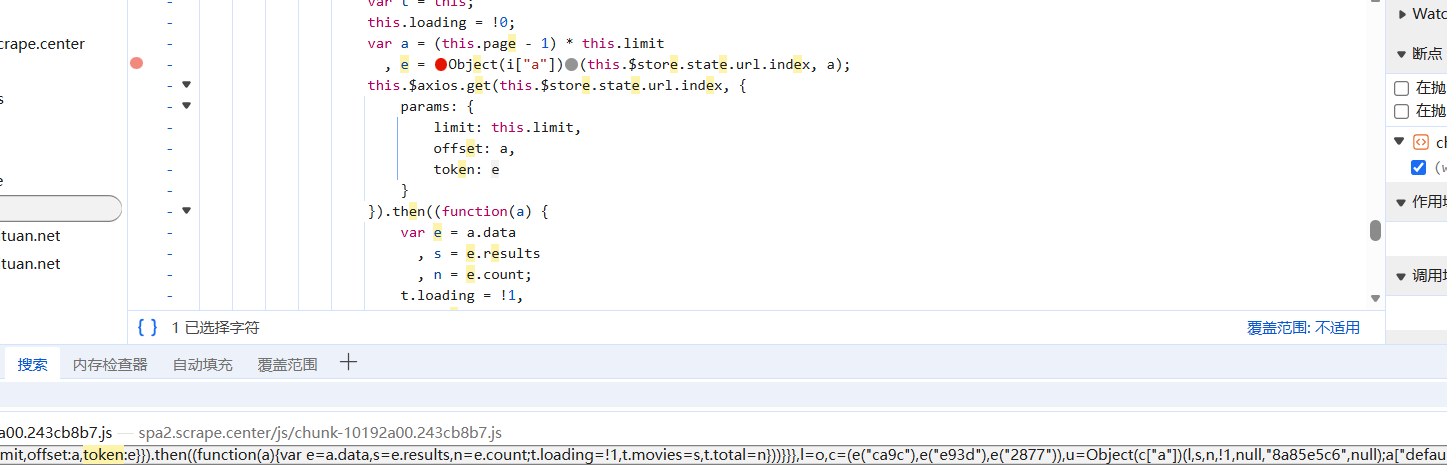
打上断点,其他都不像,然后翻页触发断点:

进函数内部看看:

这里有一个sha1加密和base64编码,我们看看sha1是否是标准加密:
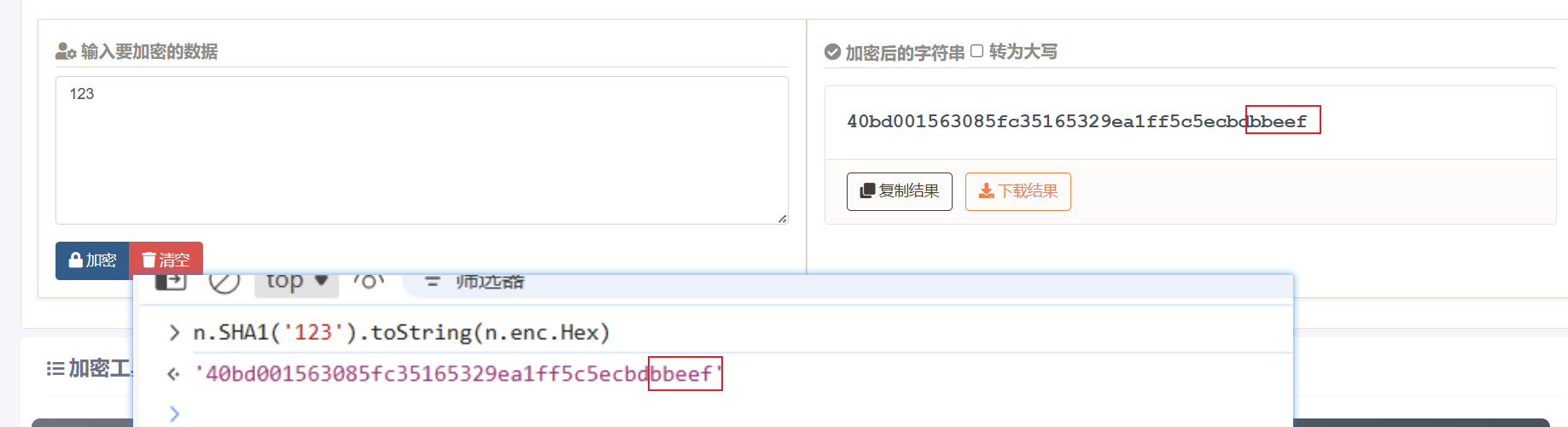
sha1是加密的,然后base64也看看:
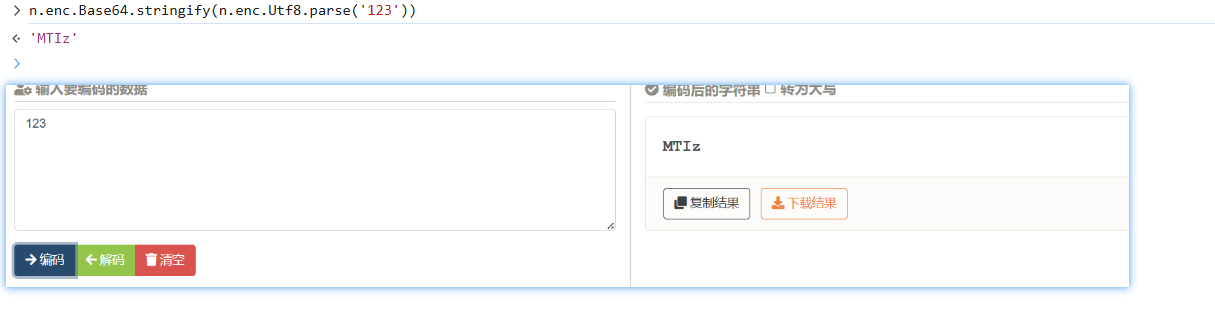
都是标准的,看一下参数即可:
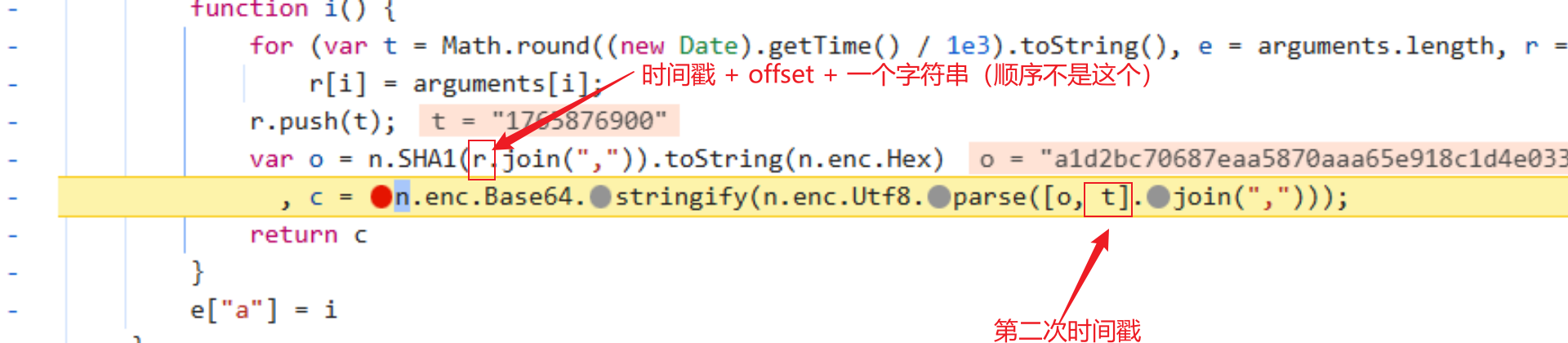
外面参数是offset:

下面开始扣代码
扣代码复现逻辑
先扣i函数:

将n全部改为第三方库:
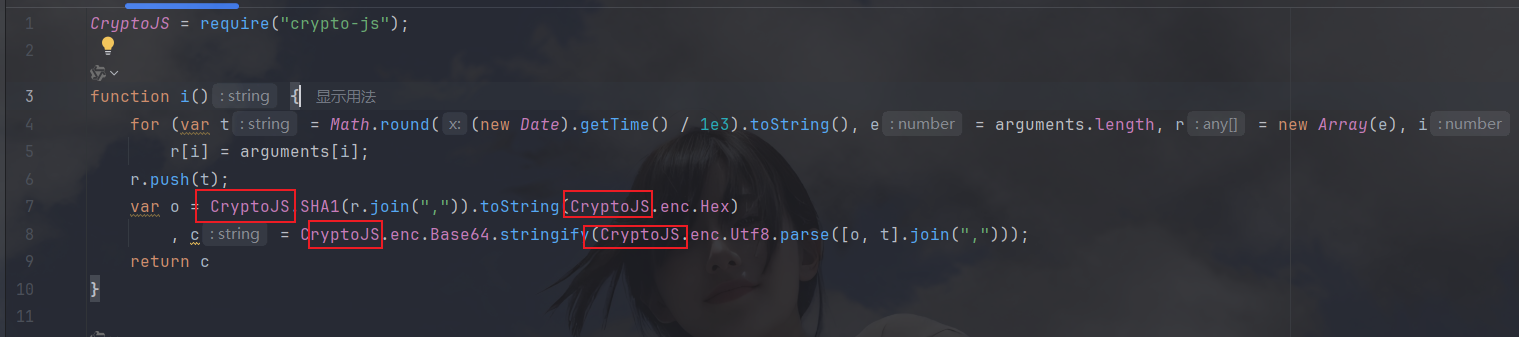
然后将外部调用的代码扣下来:

封装成函数:
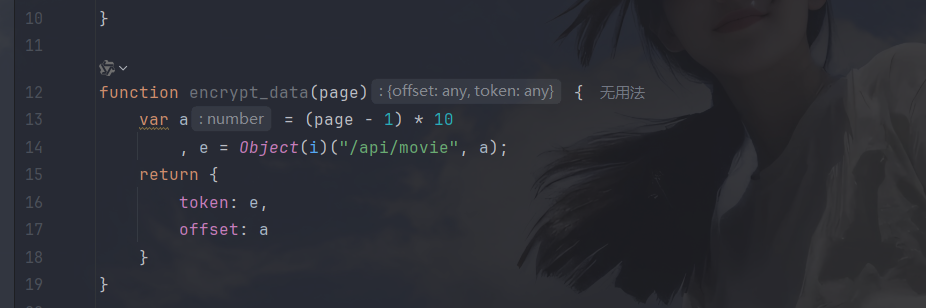
整体代码如下:
python
CryptoJS = require("crypto-js");
function i() {
for (var t = Math.round((new Date).getTime() / 1e3).toString(), e = arguments.length, r = new Array(e), i = 0; i < e; i++)
r[i] = arguments[i];
r.push(t);
var o = CryptoJS.SHA1(r.join(",")).toString(CryptoJS.enc.Hex)
, c = CryptoJS.enc.Base64.stringify(CryptoJS.enc.Utf8.parse([o, t].join(",")));
return c
}
function encrypt_data(page) {
var a = (page - 1) * 10
, e = Object(i)("/api/movie", a);
return {
token: e,
offset: a
}
}
// console.log(encrypt_data(19));返回a是因为后端会根据offset校验token
py调用
plain
import execjs
import os
import requests
class JSExecutor:
def __init__(self, file_path):
if not os.path.exists(file_path):
print('NotFoundFile')
with open(file_path, 'r', encoding='utf-8') as f:
self.js_code = f.read()
self.js_code = execjs.compile(self.js_code)
def run(self, func_name, *args):
return self.js_code.call(func_name, *args)
def get_data(token, offset):
headers = {
'Accept': 'application/json, text/plain, */*',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
'Pragma': 'no-cache',
'Referer': 'https://spa2.scrape.center/page/2',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Safari/537.36 Edg/143.0.0.0',
'sec-ch-ua': '"Microsoft Edge";v="143", "Chromium";v="143", "Not A(Brand";v="24"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
}
params = {
'limit': '10',
'offset': str(offset),
'token': token,
}
return requests.get('https://spa2.scrape.center/api/movie/', params=params, headers=headers).json()
if __name__ == '__main__':
js_executor = JSExecutor('10.js')
for page in range(1, 11):
params_js = js_executor.run('encrypt_data', page)
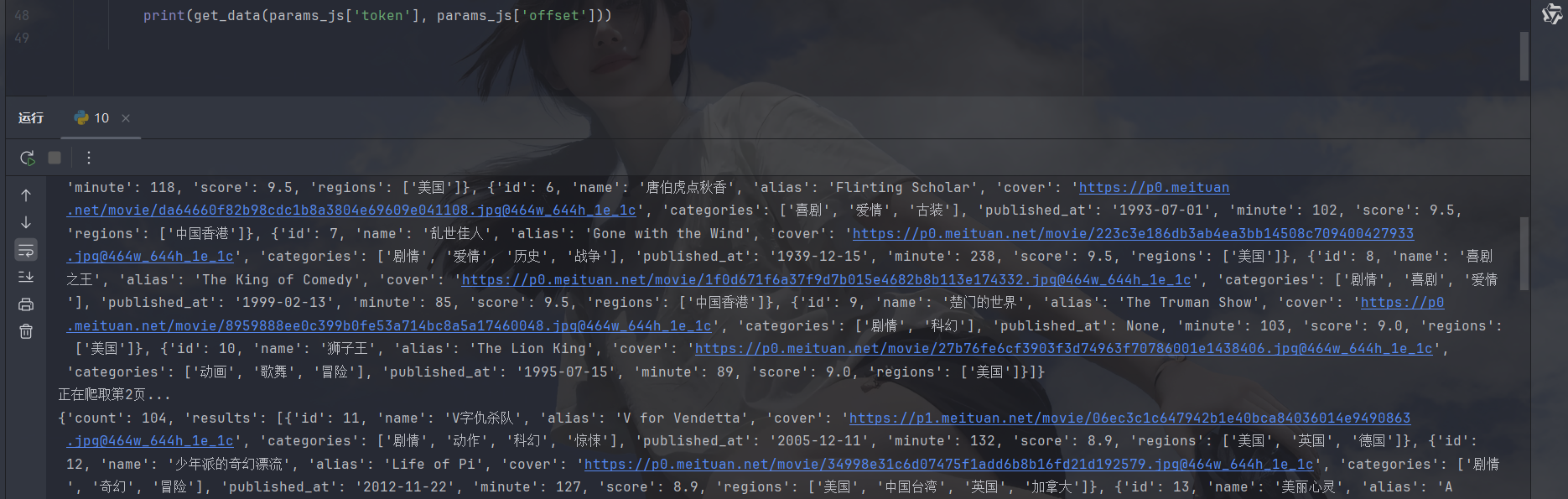
print(f'正在爬取第{page}页...')
print(get_data(params_js['token'], params_js['offset']))result:
小结
文章内容简单,小白可以试试手,如有问题及时提出,加油加油