简单先过一下概念
JWT(JSON Web Token)一般用来身份校验和授权。由三部分组成:Header.Payload.Signature,其中Header是加密算法和令牌类型;Payload是核心负载,包括了用户身份和权限信息,Signature则是校验。
JWT必须和HTTPS配合使用才能保证安全,否则容易被中间人攻击。
整体使用流程如下:
- 用户登录 → 服务器验证凭证
- 服务器生成JWT → 返回给客户端
- 客户端存储JWT → 通常在localStorage或cookie中
- 客户端发送请求 → 在Authorization头中包含JWT
- 服务器验证JWT → 返回请求的数据
为啥我要搞JWT?
一方面是历史的原因。以前做了很多后端服务,主要是内部在使用,图省事也没有搞。后来发现,用的人多了以后多少是有点失控的。不清楚谁在用,用了多少。
然后我的微服务越来越多,而且也开始做前端。如果说后端很多服务还是比较个性化的,如果参数不对甚至调不通,那么到了前端就不同了:很多应用一目了然。所以就要开始做授权和鉴权。当然这里仍然可以偷点懒,比如服务起在本地,或者IP白名单什么的。
最近,我觉得智能网关是非常重要的一环。网关需要处理每一个请求,把请求体解开通常是不行的,网关的开销过大,很多应用就没有意义了。所以网关能利用的请求信息最好是放在请求头,而既然要放请求头,而且要通用,那么JWT就是一个很好的选择。
- 1 JWT 是一个通行的规范
- 2 JWT 里带了鉴权、也可以设置权限范围
- 3 JWT 里可以自定义一些其他内容,正好用于区分不同的路由
所以现在必须要把JWT工程化了。
JWT payload设计
尽量使用通用的字段,然后稍微对其中一些字段重定义
| 字段 | 中文 | 作用 |
|---|---|---|
iss |
签发者 | 识别 token 来源,安全边界 |
aud |
受众 | 识别 token 面向哪个系统 |
sub |
主体 | 用户或客户端标识,业务身份 |
jti |
token 唯一 ID | 日志追溯、重放防护、撤销控制 |
scope |
权限范围 | 接口权限控制 |
iat |
签发时间 | token 生命周期参考 |
exp |
过期时间 | token 生命周期控制 |
- iss和aud会被重定义为该jwt可用的微服务,逻辑上对应 tier1和tier2,这种两级命名足够覆盖我的微服务体系
- sub: 则作为用户的身份标志,比如user_id
- jti: 用于日志分析和特定控制(可以用布隆过滤器来实现黑名单控制)
- scope: 用户在某个子系统(微服务)下允许的权限
- iat和exp: 基本的声明周期控制
这样一套JWT可实现每次处理时,系统知道用户是谁,现在计划访问什么系统,可以具有怎样的权限
未来,For 智能网关:
智能网关收到一个请求,通过解析header中的jwt,就可以:
- 1 知道用户sub向 iss.aud.url 发起请求
- 2 网关可以获取 iss.aud.url的权限要求(redis kv), 和scope比较(is in),这样就可以决定是否要转发
智能网关的智能性主要体现在路由的策略上:
- 记忆性:每个请求存在记忆性,当某个pid(时空唯一)被反复请求时,智能网关会根据被转发的服务来决定如何应答。
- 策略性:一个请求到了以后,有若干下游服务可以提供同质(同版本的扩展)和异质(不同版本),智能网关会进行全量或者部分的多发,来评估性能或者分摊压力。
用户注册表
需要使用一个数据库来产生初始的jwt颁发。
基于mysql数据建表
表名:jwt_users
- id - 自增主键
- pid - 主键
- username - 不可改,不可重的字段,不超过100字符
- email - 不可空
- phone - 可空,非缺失时按大陆手机号格式
- password - 加密存储 bcrypt
- is_enable - 是否启用
- create_time - 创建时间
- update_time - 修改时间
生成字段:
password 由 username + 创建时间生成
pid是依据用户名+创建时间的md5值
用户权限表
存储用户可使用的权限
表名: jwt_auth
- jwt_user_pid : jwt_users 的pid,索引
- tier1: 微服务一级名称,不超过200字符,索引
- tier2: 微服务二级名称, 不超过200字符,索引
- scope: 权限内容,TEXT格式; * 开头代表完全许可; ~代表禁止功能列表;否则代表许可功能列表;每个功能许可将以api.read这样的格式声明
- is_enable - 是否启用
- create_time - 创建时间
- update_time - 修改时间
JWT相关设置及函数
各个服务器上采用相同的JWT_KEY和JWT_ALGO才能复现signature,从而确保不被伪造
JWT_KEY和JWT_ALGO直接写入env文件中。
- create_jwt_token: 用户输入iss,aud(对应着微服务的一级和二级),和对应的scope(默认为 * ,后续可以进一步细化)
- verify_jwt_token: 验证jwt,成功时返回payload,失败时则为False
创建jwt模块,并实现以上两个函数,
创建数据模型(内存) -- node
jwt_user
- username
- password
- phone 可选
参考 data.JwtUsers 创建
jwt_auth
- tier1
- tier2
- scope
参考 data.JwtAuth创建
jwt_payload
- iss 对应 tier1
- aud 对应 tier2
- sub 主体,对应用户的 pid
- scope 默认 *
- duration 默认 60(分钟)
参考 data.JwtAuth 和 jwt_token.create_jwt_token
创建连接 -- link
- 1 从内存节点到硬盘节点
jwt_user_to_jwt_users - 2 从内存节点到硬盘节点
jwt_user_auth_to_jwt_auth
创建子图 -- subgraph
- 1 用户创建引导:创建一个交互式命令行,引导用户完成;基于
link.jwt_user_to_jwt_users - 2 权限创建引导:创建一个交互式命令行,引导用户完成,基于
link.jwt_user_auth_to_jwt_auth - 3 token创建:创建一个交互式命令行,引导用户完成。首先提示进行用户名和密码的认证,然后引导用户输入node.memory_node.jwt_payload对应的字段,校验对应字段在data.JwtAuth中被允许,最后通过jwt_token.create_jwt_token返回一个jwt。为这个子图(CreateTokenGraph)创建多一个示例,在生成了jwt之后验证jwt(使用jwt_token.verify_jwt_token).
实现
用opencode + minimax2.1 构造
先创建项目,然后创建分支 v0.1
- 1 基于st-0008 创建项目文件结构(st系列我在之前文章提过,是总结下来的固定做法)
- 2 基于st-0003 创建jwt_users 的ORM。
- 3 生成一个username: test, email: test@test.com, password:test的用户
- 4 为test创建test_ms.test_api.* 权限
- 5 基于st-0007 创建 JWT相关函数
- 6 基于st-0001 参考data.JwtUsers,创建 jwt user 相关模型
- 7 基于st-0002 建一个link函数,from node.memory_node.jwtUser to data.JwtUsers
- 8 基于st-0009,完成用户创建引导:创建一个交互式命令行,引导用户完成;基于
link.jwt_user_to_jwt_users,但是要先判断用户是否可以创建(比如已存在或者其他限制) - 9 基于st-0001 参考data.JwtAuth,创建 jwt auth 相关模型
- 10 基于st-0002 建一个link函数, from node.memory_node.jwtUserAuth to data.JwtAuth
- 11 基于st-0009,创建一个交互式命令行,完成用户创建引导,基于
link.jwt_user_auth_to_jwt_auth,同样需要判断是否已经存在,采用 create or update 的方式完成权限设置。 - 12 基于st-0001,参考
data.JwtAuth和jwt_token.create_jwt_token创建jwt_payload原型 - 13 创建fronend 文件夹,在其下使用gradio创建前端,将三个子图流程使用前端实现。
使用
使用三个子图进行用户创建、用户权限创建、token生成, 所以我在其他服务中,只要有了.env中的环境变量和 verify_jwt_token 这个函数就可以验证token了
有一个前端是比较重要的,使用gradio可以比较简单的进行操作和检查
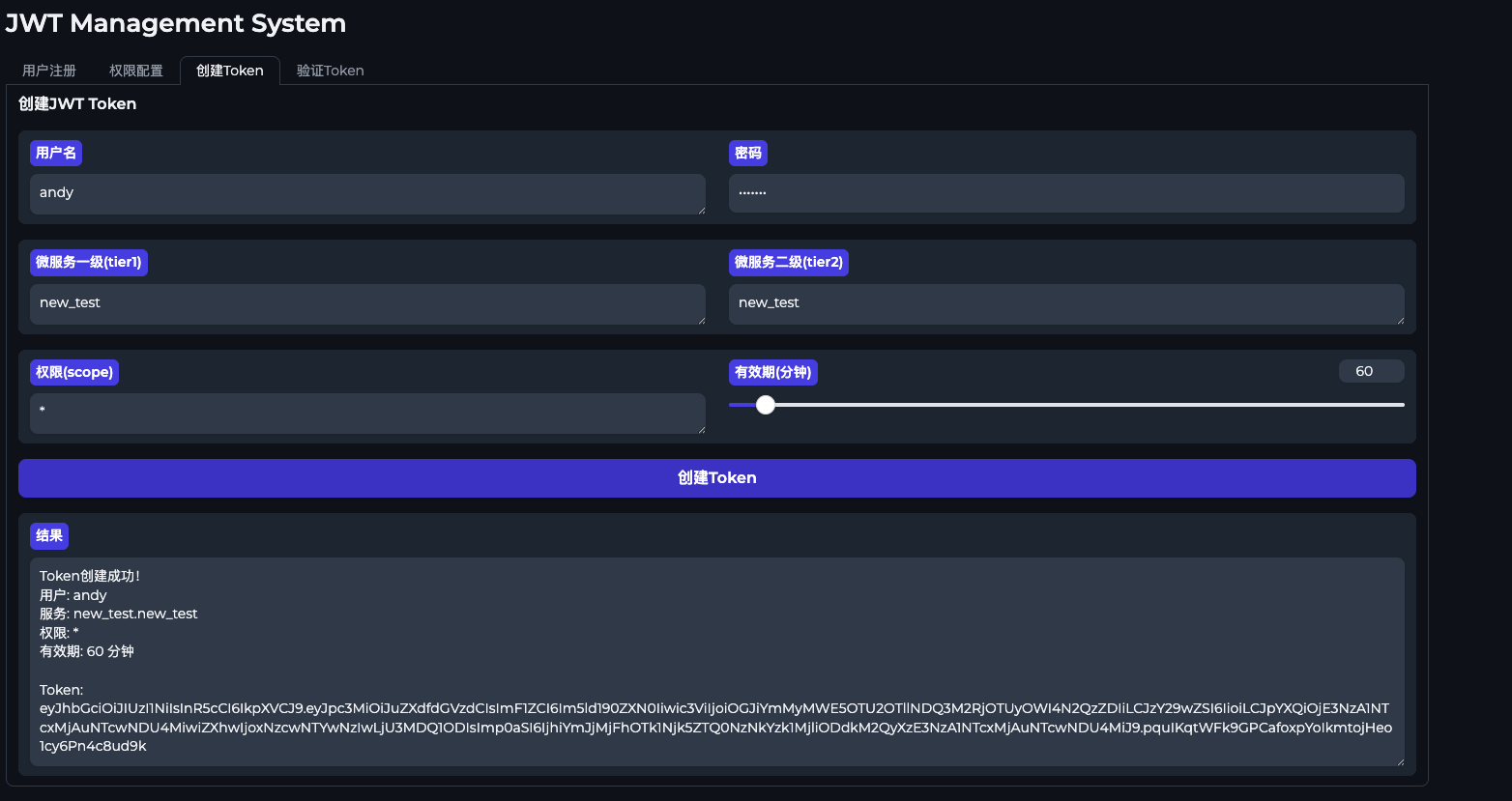
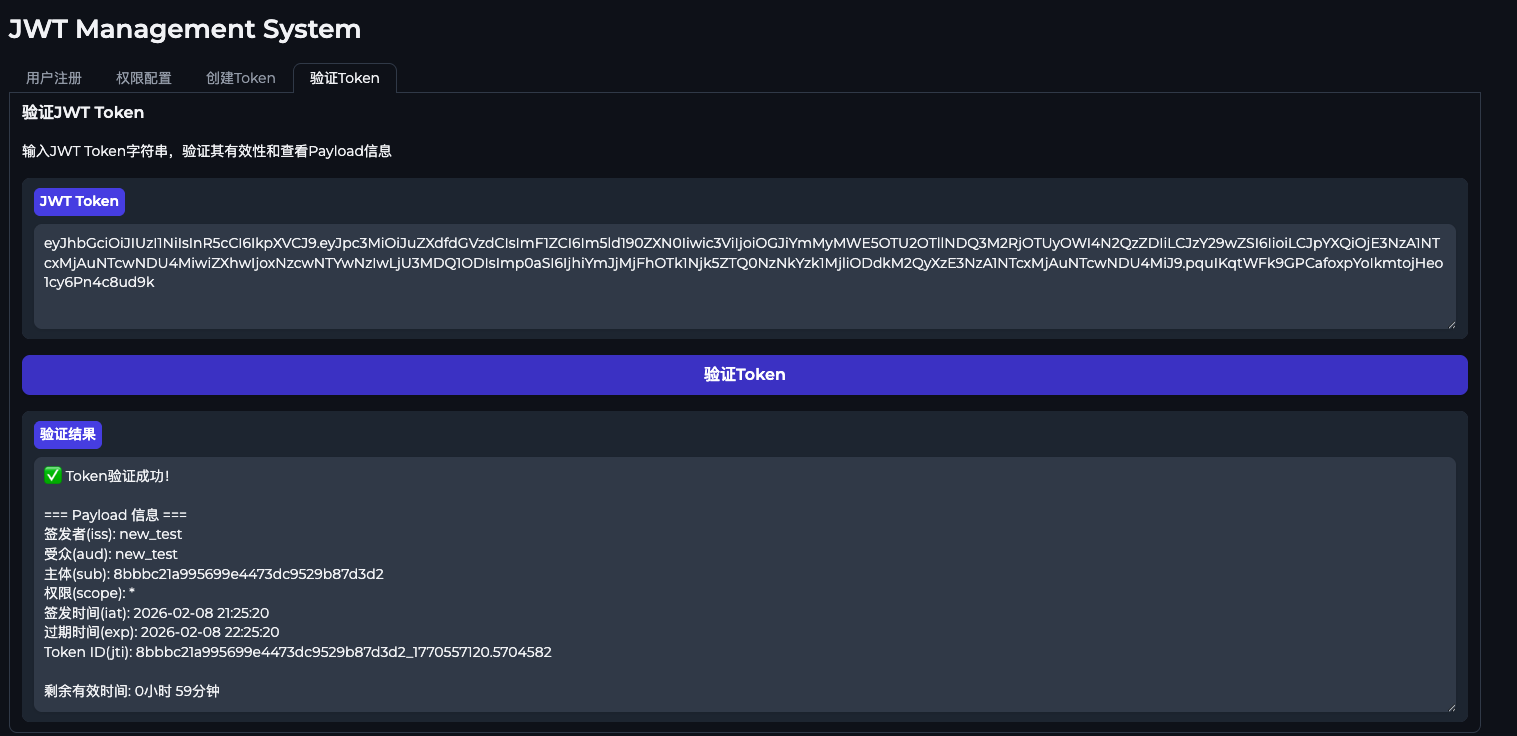
验证
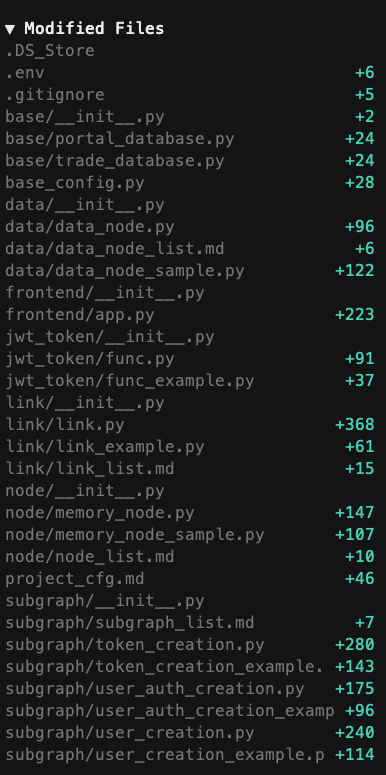
最终开发形成的文件如下:
回顾
我要的具体功能实现了。整个过程耗时一天,具体我参与的时间只有4-5个小时,严格来说我改的代码只有3行(在最后搭建前端服务的时候没有给规范,大模型在载入env文件上竟然有个很傻的错误:没有载入env却先获取环境变量了,关键是不构成启动报错,但是--> 大模型的逻辑还是有点弱)。
其中我花的时间80%在思考、修改规范和等待。因为部分设计细节我之前是没想清楚的,以及我的规范之前写的还不够完善,所以是边交互、边开发、边完善的过程。这样的结果就是进一步强化抽象经验,使得整个过程足够规范(类似以前的写文档),这些规范最终也会被贯彻执行(因为大模型非常适合这么调教,而人往往不是这样的)。
这意味什么?
逻辑密度会进一步提升。比如我之前有设想给做好的后端服务带上一个前端,但是在一次开发(可以认为类似session)以前没有精力实现,现在就可以了。
另外,由于结构上高度清晰,未来要debug或者进一步加功能是非常简单的。逻辑越清晰,本身也会更加稳定。
时间可控性变强。 由于开发者需要的是把东西"想明白,说清楚",不在低层面的代码细节上浪费时间,或者至少说,对于确定性的数据处理逻辑(如ETL类)是完全可以交给大模型实现的。
我觉得大模型时代 ,变化将会更有趣。更抽象的思考,更结构化的表达!