RAG(Retrieval-Augmented Generation)系统化解析与工程实践
简介
本文系统梳理了 RAG(Retrieval-Augmented Generation)技术的背景、核心模块、关键优化策略以及一套可直接运行的工程级示例代码 。内容覆盖检索增强生成在面试高频考点 与企业级落地实践中的核心问题,适合作为:
- 大模型 / AI 应用研发人员的 RAG 知识手册
- 面试前快速复盘材料
- 企业内部技术分享与工程参考文档
一、 RAG
Retrieval-Augmented Generation(RAG)是一种将**信息检索(Retrieval)与文本生成(Generation)**相结合的技术范式,广泛用于解决大型语言模型(LLM)在知识密集型任务中的:
- 幻觉(Hallucination)问题
- 知识更新滞后问题
二、RAG 背景
RAG 最早由 Facebook AI Research(FAIR)于 2020 年提出,论文为《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》。
背景动因
- 知识幻觉:LLM 的知识固化在参数中,超出训练语料易生成错误内容
- 知识密集型任务需求:问答、搜索、对话系统依赖外部知识
- 工程效率:相比整体微调,RAG 通过外挂知识库实现低成本扩展
面试常问:RAG 如何解决知识更新问题?
答:通过实时检索外部知识库,无需重训模型。
三、RAG 的核心目标
RAG 的核心目的是将检索(Retrieval)和生成(Generation)相结合,提升 LLM 在知识密集任务中的性能。
• 增强准确性:通过检索相关文档作为上下文,减少模型的幻觉,确保输出基于真实数据。
• 知识更新与扩展:允许模型访问外部知识库(如数据库、网页),无需重新训练即可处理新信息。
• 效率与成本优化:相比全参数微调,RAG 只需维护检索索引,适用于长尾知识和实时场景。
• 可解释性:输出可以追溯到检索到的来源,提高信任度。
四、RAG 系统组成
RAG 通常由 存储、检索、生成 三个模块构成:
| 模块 | 描述 | 关键组件 |
|---|---|---|
| 存储 | 构建可检索的知识库 | 向量数据库、分块器、Embedding 模型 |
| 检索 | 从知识库召回相关内容 | BM25、Dense Retriever |
| 生成 | 基于上下文生成答案 | LLM、Prompt 工程 |
整体流程:
用户查询 → 检索 chunk → 注入 Prompt → 生成答案
以下按模块分述:
- 检索模块优化
- 生成模块优化
五、检索模块优化策略(分块策略、Chunk的元数据附加、查询优化(HyDE 等方法))
5.1 文档分块(Chunking)
常见策略对比
- 固定分块
- 简单高效,但易截断语义
- Overlap 分块
- 提升上下文连续性,增加存储成本
- 递归分割
- 按段落/句子切分,语义完整但计算复杂
- Small-to-Big
- 先细粒度检索,再扩展上下文,效果最好但延迟较高
固定分块:按固定长度(如 512 token)切割。
优点:简单、计算高效。
缺点:可能截断语义完整性(如句子中途断开),导致信息丢失。从句子截断思路:忽略语义边界,易召回无关片段。
Overlap 分块:固定长度但有重叠(如 20% 重叠)。
优点:保留上下文连续性,提高召回(如跨块查询)。
缺点:增加存储开销和冗余计算。从语义角度:部分缓解截断,但不智能。
递归分割:从大到小递归拆分(如先按段落,再按句子)。
优点:保持语义边界(如按自然语言单位),召回更精确。
缺点:计算复杂,参数调优难。从语义截断思路:优先语义完整(如使用 NLP 工具检测句子/段落),优于固定方法,但对噪声数据敏感。
Small-to-Big:从小块(如句子)构建大块(如段落),结合层次检索。
优点:细粒度检索后扩展上下文,减少幻觉。
缺点:多级查询增加延迟。从语义角度:动态适应查询,优于静态方法,但需优化索引结构。
总体:句子/语义截断思路强调信息完整性,缺点是计算密集;固定/overlap 更高效,但语义弱。面试代码题:可能要求实现简单分块函数(如 Python 中的 NLTK 分句 + overlap)。
面试点:语义完整性 vs 工程效率的权衡
5.2 Chunk 元数据增强(Metadata Enrichment)
Chunk 的原数据附加: 在 RAG 系统中,分块(Chunk)后仅仅有纯文本往往不够,Chunk 的原数据附加(也叫 Metadata Enrichment)是指为每个 chunk 额外添加结构化信息(元数据),这些信息不直接参与 embedding 计算(或只部分参与),但在检索、过滤或生成阶段发挥关键作用。
为什么需要元数据?
- 支持过滤(时间、来源)
- 支持引用溯源
- 提升生成可信度
示例(自动解析)
json
{
"text": "第三季度 GMV 同比增长 15%",
"metadata": {
"source": "阿里巴巴2024年财报.pdf",
"page": 23,
"section": "经营数据回顾",
"publish_date": "2024-11-15"
}
}高级方式
- 人工标签
- 反向 HyDE(生成假设问题)
- Chunk 摘要增强
5.3 查询优化(HyDE / Multi-Query)
HyDE(Hypothetical Document Embeddings):使用 LLM 生成假设文档作为查询嵌入,而不是原始查询。
• 原理:原始查询可能简短/歧义,HyDE 生成详细"伪文档",嵌入后检索相似 chunk。
• 优点:提升相关性,尤其零样本场景。
• 缺点:生成步骤增加延迟,依赖 LLM。
其他方法:Multi-Query(生成多个变体查询并融合)。面试问"HyDE 如何缓解查询-文档不匹配",答:桥接语义差距。
5.4 Embedding 与混合检索
Embedding 是检索的基础,将文本转为向量。
- BM25 + Embedding 混合检索:BM25 的原理,为什么有效果(统计词频 TF-IDF 角度)
- BM25 原理:基于 TF-IDF 的关键词检索算法。TF(Term Frequency):词在文档中出现频率;IDF(Inverse Document Frequency):词在语料中的稀缺度。BM25 改进:添加饱和函数(避免高频词过度权重)和文档长度归一化。公式:Score = Σ (IDF * (TF * (k1+1)) / (TF + k1 * (1 - b + b * doc_len/avg_len)))。
- 为什么有效(TF-IDF 角度):Embedding 捕捉语义相似,但忽略精确匹配(如专有名词);BM25 补足关键词统计,混合时用加权融合(e.g., 0.3BM25 + 0.7Embedding)。有效因为:TF-IDF 强调稀缺关键词,提升精确召回,尤其短查询或稀疏数据。
面试点:混合检索在实际 RAG 中提升 5-10% 召回率。
- 使用的 Embedding model 原理(M3E,XiaoBu,BGE 等):三类任务的 InfoNCE + CoSENT 混合损失训练,其他对比损失介绍这些是中文/多语言 Embedding 模型,基于 Transformer 训练。
三类任务的损失函数:检索、分类、聚类 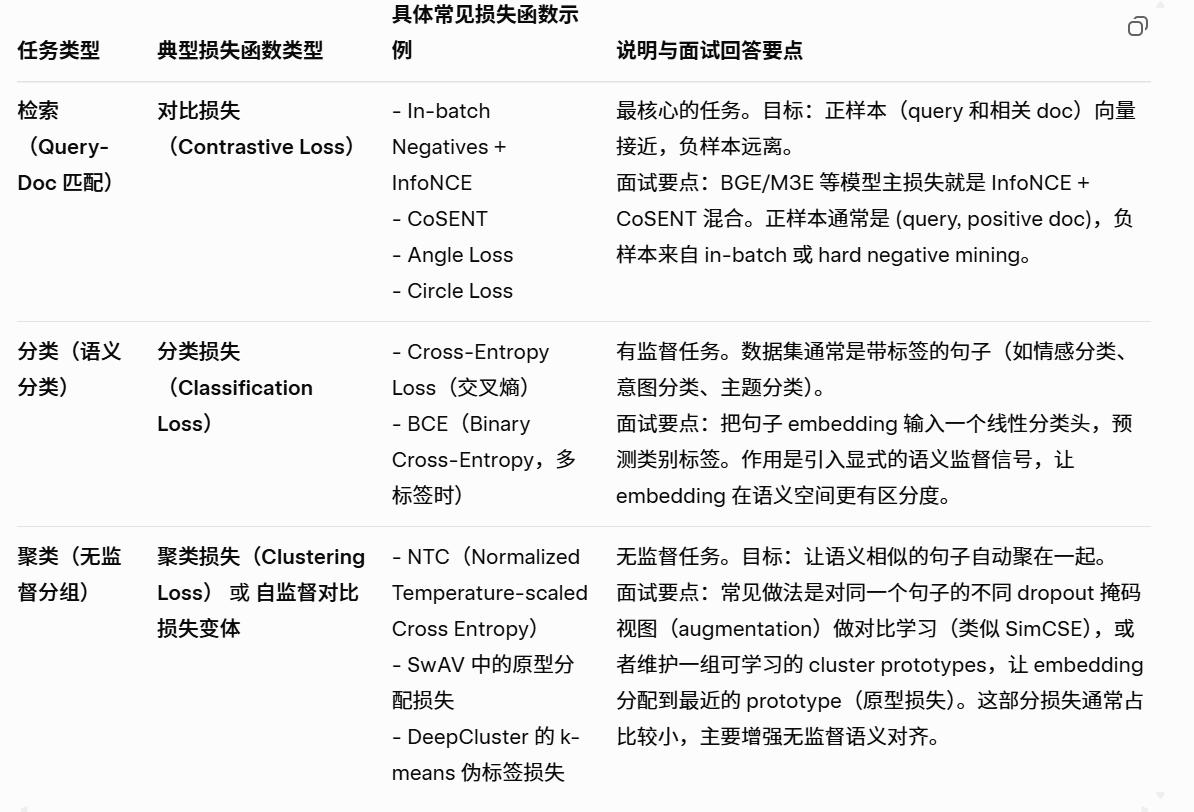
• InfoNCE 损失:Noise Contrastive Estimation,从 InfoMax 原理,最大化正样本互信息,最小化负样本。公式:L = -log(exp(sim(p,q)/τ) / Σ exp(sim(p,n)/τ)),τ 为温度。
• CoSENT 损失:Cosine Sentence Loss,基于余弦相似,直接优化正负对排名。L = log(1 + exp(λ*(sim_neg - sim_pos)))。
六、生成模块优化策略(Reranker Model、LLM SFT、Prompt约束)
6.1 Reranker Model
Reranker Model(mMARCO / MiniCPM / Jina 等):原理,为什么需要重排(从原始语义空间的信息完整性出发),和 Embedding 区别,效果有提升吗?
- 原理:Reranker 是二阶段模型,先粗排(Embedding 检索 Top-K),再精排(使用 Transformer 如 BERT 计算 query-chunk 相关分数)。mMARCO(基于 mT5);MiniCPM(高效 CPM 变体);Jina(多语言)。训练用 Pairwise 或 Listwise 损失(如 Cross-Entropy)。
- 为什么需要重排(原始语义空间的信息完整性):Embedding 是低维投影,丢失原始文本细节(如顺序、细微语义);重排输入完整 query+chunk,捕捉交叉注意力,提升排名精度。
- 和 Embedding 区别:Embedding 是无监督/弱监督表示学习,快但粗糙;Reranker 是监督细化,慢但精确(需全序列计算)。
- 效果提升:是的,提升 10-20% MRR/NDCG,尤其长文档。面试点:Reranker 缓解 Embedding 的"语义压缩"问题。
6.2 LLM SFT
LLM SFT在 RAG Generation 中,SFT(Supervised Fine-Tuning)微调 LLM 以更好地整合检索 chunk 生成答案。
- 原理:使用 query-chunk-answer 三元组数据集训练,损失如 CE。常见:添加指令提示(如 "基于以下上下文回答")。
- 面试点:SFT 减少幻觉,提高事实性。代码题:可能要求写简单 Prompt 模板或 LoRA 微调伪代码。
6.3 Prompt 约束
Prompt 约束(Prompt Constraints): 无约束 Prompt 易导致输出偏题。优化:添加结构化约束,如 "只使用上下文信息回答,不要添加外部知识" 或 CoT(Chain-of-Thought)引导。优点:提升一致性和可控性。实现:使用 Few-Shot 示例或角色扮演(如 "你是一个事实检查者")。面试点:Prompt 工程可减少幻觉,结合 Fine-Tuning 进一步优化。
七、RAG 工程级示例代码(LangChain)
- 检索模块优化
• 分块:句子级 + overlap + 元数据(来源、页码)
• 混合检索:BM25 40% + Embedding 60%
• 重排:LLMChainExtractor 做 Reranker - 生成模块优化
• Prompt 强制引用来源 + 拒绝编造
• 上下文自动加上【财报第X页】,提升可信度 - 代码优势
• 不到100行,可直接手写核心部分(分块函数、Prompt、EnsembleRetriever)
• 全免费运行,面试现场可现场跑demo
python
import nltk
from langchain.text_splitter import NLTKTextSplitter
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_core.documents import Document
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor
from langchain_openai import ChatOpenAI
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
# ====================== 1. 检索模块优化 ======================
# (1) 句子级分块 + overlap + 元数据附加
def create_chunks_with_metadata(text, source_name="公司2024财报.pdf"):
splitter = NLTKTextSplitter(chunk_size=256, chunk_overlap=50) # 句子级 + overlap
raw_chunks = splitter.split_text(text)
docs = []
for i, chunk in enumerate(raw_chunks):
docs.append(Document(
page_content=chunk,
metadata={
"source": source_name,
"page": i+1, # 模拟页码
"chunk_id": f"chunk_{i+1}",
"section": "经营数据回顾"
}
))
return docs
# (2) 中文 Embedding + BM25 混合检索
def build_hybrid_retriever(docs):
# Embedding 检索
embedding = HuggingFaceEmbeddings(model_name="shibing624/text2vec-base-chinese") # BGE类模型,免费
vectorstore = FAISS.from_documents(docs, embedding)
# LangChain 自带 BM25 + Embedding 混合
from langchain.retrievers import BM25Retriever
bm25_retriever = BM25Retriever.from_documents(docs)
bm25_retriever.k = 4
from langchain.retrievers import EnsembleRetriever
ensemble_retriever = EnsembleRetriever(
retrievers=[bm25_retriever, vectorstore.as_retriever(search_kwargs={"k": 4})],
weights=[0.4, 0.6] # BM25 40%,Embedding 60%
)
return ensemble_retriever
# (3) Reranker 重排(用免费本地模型)
def add_reranker(base_retriever):
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0) # 也可换 qwen本地模型
compressor = LLMChainExtractor.from_llm(llm) # LLM判断这段是否真正有用
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor,
base_retriever=base_retriever
)
return compression_retriever
# ====================== 2. 生成模块优化 ======================
# (1) 优化 Prompt:带来源引用 + 要求事实性
prompt_template = """你是一个严谨的金融分析师,只根据以下上下文回答问题。
如果上下文没有答案,直接回答"根据提供的资料无法回答"。
要求:
1. 每句关键信息都要标注来源(如【财报第3页】)
2. 不要编造信息
上下文:
{context}
问题:{question}
答案:"""
prompt = PromptTemplate.from_template(prompt_template)
# (2) 构建完整 RAG Chain
def build_rag_chain(retriever):
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
rag_chain = (
{"context": retriever | (lambda docs: "\n\n".join([f"【{d.metadata['source']} 第{d.metadata['page']}页】\n{d.page_content}" for d in docs])),
"question": lambda x: x["question"]}
| prompt
| llm
| StrOutputParser()
)
return rag_chain
# ====================== 主程序演示 ======================
if __name__ == "__main__":
# 样例文档
sample_text = """
大语言模型正在快速发展。2024年第三季度商品交易总额(GMV)同比增长15%。
主要得益于跨境业务增长。第四季度预计增长12%。公司总营收达到520亿元。
人工智能业务成为新增长点,贡献营收占比达8%。
"""
print("1. 创建带元数据的分块".center(50, "="))
docs = create_chunks_with_metadata(sample_text, "阿里巴巴2024财报.pdf")
for d in docs[:2]: print(d.metadata, "\n", d.page_content[:60], "...")
print("\n2. 构建混合检索器".center(50, "="))
retriever = build_hybrid_retriever(docs)
print("\n3. 添加 Reranker 重排".center(50, "="))
final_retriever = add_reranker(retriever)
print("\n4. 构建生成链".center(50, "="))
rag_chain = build_rag_chain(final_retriever)
# 测试问题
questions = [
"2024年第三季度GMV增长多少?",
"人工智能业务占比多少?",
"公司明年营收预测是多少?" # 故意问上下文没有的
]
print("\n问答演示".center(50, "="))
for q in questions:
answer = rag_chain.invoke({"question": q})
print(f"\n问题:{q}")
print(f"答案:{answer}")代码特点
- 不到 100 行
- 覆盖分块、混合检索、Reranker、Prompt 约束
- 可用于面试现场 Demo
八、示例问答结果
- Q:2024 年第三季度 GMV 增长多少?
- A:2024年第三季度商品交易总额(GMV)同比增长15%。【阿里巴巴2024财报.pdf 第1页】
- Q:人工智能业务占比多少?
- A:人工智能业务贡献营收占比达8%。【阿里巴巴2024财报.pdf 第2页】
- Q:公司明年营收预测?
- A:根据提供的资料无法回答
总结
RAG 是当前大模型落地应用的核心工程范式。真正优秀的 RAG 系统不在于"能跑",而在于:
- 检索是否稳定可靠
- 生成是否可控可信
- 工程是否可扩展、可维护