import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
# 设置中文字体
import matplotlib
matplotlib.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei', 'DejaVu Sans'] # 设置中文字体
matplotlib.rcParams['axes.unicode_minus'] = False # 正常显示负号
import matplotlib.pyplot as plt
# 从本地文件加载数据
file_path = r"E:\PyStudy\heart.csv"
df = pd.read_csv(file_path)
print("数据集信息:")
print(f"总样本数: {len(df)}")
print(f"类别分布:\n{df['target'].value_counts()}")
print(f"少数类比例: {df['target'].value_counts(normalize=True)[0]:.2%}")
# 划分特征和标签
X = df.drop('target', axis=1)
y = df['target']
# 数据标准化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 基础模型评估函数
from sklearn.model_selection import StratifiedKFold, cross_val_predict
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import f1_score, classification_report
def evaluate_model(X_data, y_data, model=None):
if model is None:
model = RandomForestClassifier(n_estimators=100, random_state=42, class_weight='balanced')
skf = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
y_pred = cross_val_predict(model, X_data, y_data, cv=skf, method='predict')
f1 = f1_score(y_data, y_pred, average='weighted')
# 计算各个类别的F1
f1_class_0 = f1_score(y_data, y_pred, average=None)[0]
f1_class_1 = f1_score(y_data, y_pred, average=None)[1]
return f1, f1_class_0, f1_class_1, y_pred
print("\n" + "="*50)
print("1. 原始数据评估")
original_f1, original_f1_0, original_f1_1, _ = evaluate_model(X_scaled, y)
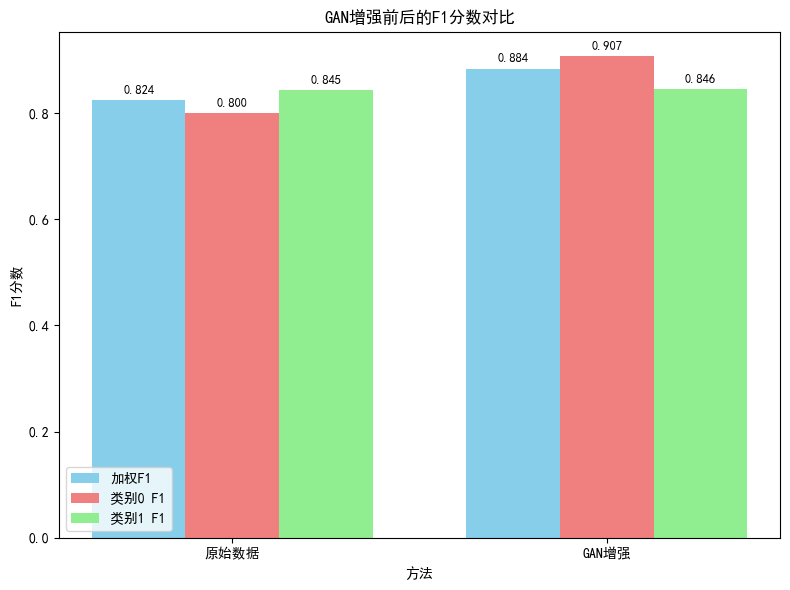
print(f"加权F1分数: {original_f1:.4f}")
print(f"类别0(无心脏病)F1: {original_f1_0:.4f}")
print(f"类别1(有心脏病)F1: {original_f1_1:.4f}")
# 使用GAN生成少数类样本
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
# 检查是否有GPU
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"\n使用设备: {device}")
# 准备少数类数据(target=0)
minority_class = df[df['target'] == 0]
X_minority = minority_class.drop('target', axis=1).values
X_minority_scaled = scaler.transform(X_minority)
# 转换为PyTorch张量
minority_tensor = torch.FloatTensor(X_minority_scaled).to(device)
# 定义GAN模型
class Generator(nn.Module):
def __init__(self, latent_dim, output_dim):
super(Generator, self).__init__()
self.model = nn.Sequential(
nn.Linear(latent_dim, 128),
nn.LeakyReLU(0.2),
nn.BatchNorm1d(128),
nn.Linear(128, 256),
nn.LeakyReLU(0.2),
nn.BatchNorm1d(256),
nn.Linear(256, 512),
nn.LeakyReLU(0.2),
nn.BatchNorm1d(512),
nn.Linear(512, output_dim),
nn.Tanh()
)
def forward(self, z):
return self.model(z)
class Discriminator(nn.Module):
def __init__(self, input_dim):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(input_dim, 512),
nn.LeakyReLU(0.2),
nn.Dropout(0.3),
nn.Linear(512, 256),
nn.LeakyReLU(0.2),
nn.Dropout(0.3),
nn.Linear(256, 128),
nn.LeakyReLU(0.2),
nn.Dropout(0.3),
nn.Linear(128, 1),
nn.Sigmoid()
)
def forward(self, x):
return self.model(x)
# 训练GAN
def train_gan(X_minority, n_epochs=2000, batch_size=32, latent_dim=100, n_samples=None):
if n_samples is None:
n_samples = len(X_minority) # 生成与少数类相同数量的样本
input_dim = X_minority.shape[1]
# 初始化模型
generator = Generator(latent_dim, input_dim).to(device)
discriminator = Discriminator(input_dim).to(device)
# 优化器
g_optimizer = optim.Adam(generator.parameters(), lr=0.0002, betas=(0.5, 0.999))
d_optimizer = optim.Adam(discriminator.parameters(), lr=0.0002, betas=(0.5, 0.999))
# 损失函数
criterion = nn.BCELoss()
# 创建数据加载器
dataset = TensorDataset(torch.FloatTensor(X_minority).to(device))
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
# 训练循环
for epoch in range(n_epochs):
for batch_idx, (real_data,) in enumerate(dataloader):
batch_size_real = real_data.size(0)
# 真实标签和假标签
real_labels = torch.ones(batch_size_real, 1).to(device)
fake_labels = torch.zeros(batch_size_real, 1).to(device)
# 训练判别器
d_optimizer.zero_grad()
# 真实数据
real_output = discriminator(real_data)
d_real_loss = criterion(real_output, real_labels)
# 生成假数据
z = torch.randn(batch_size_real, latent_dim).to(device)
fake_data = generator(z)
fake_output = discriminator(fake_data.detach())
d_fake_loss = criterion(fake_output, fake_labels)
d_loss = d_real_loss + d_fake_loss
d_loss.backward()
d_optimizer.step()
# 训练生成器
g_optimizer.zero_grad()
z = torch.randn(batch_size_real, latent_dim).to(device)
fake_data = generator(z)
fake_output = discriminator(fake_data)
g_loss = criterion(fake_output, real_labels) # 骗过判别器
g_loss.backward()
g_optimizer.step()
if (epoch + 1) % 500 == 0:
print(f'Epoch [{epoch+1}/{n_epochs}], d_loss: {d_loss.item():.4f}, g_loss: {g_loss.item():.4f}')
# 生成样本
generator.eval()
with torch.no_grad():
z = torch.randn(n_samples, latent_dim).to(device)
generated_data = generator(z).cpu().numpy()
return generated_data, generator, discriminator
print("\n" + "="*50)
print("2. 训练GAN生成少数类样本")
generated_data, generator, discriminator = train_gan(
X_minority_scaled,
n_epochs=2000,
batch_size=32,
n_samples=len(X_minority) # 生成与少数类相同数量的样本
)
# 反标准化生成的数据
generated_original = scaler.inverse_transform(generated_data)
# 创建增强后的数据集
# 为生成的样本添加标签(0表示无心脏病)
generated_df = pd.DataFrame(generated_original, columns=X.columns)
generated_df['target'] = 0
# 合并原始数据和生成的数据
augmented_df = pd.concat([df, generated_df], ignore_index=True)
print(f"增强后数据集大小: {len(augmented_df)}")
print(f"增强后类别分布:\n{augmented_df['target'].value_counts()}")
# 准备增强后的数据
X_aug = augmented_df.drop('target', axis=1)
y_aug = augmented_df['target']
X_aug_scaled = scaler.fit_transform(X_aug)
print("\n" + "="*50)
print("3. GAN增强数据评估")
augmented_f1, augmented_f1_0, augmented_f1_1, _ = evaluate_model(X_aug_scaled, y_aug)
print(f"加权F1分数: {augmented_f1:.4f}")
print(f"类别0(无心脏病)F1: {augmented_f1_0:.4f}")
print(f"类别1(有心脏病)F1: {augmented_f1_1:.4f}")
# 可视化对比结果
import matplotlib.pyplot as plt
# F1分数对比
methods = ['原始数据', 'GAN增强']
weighted_f1_scores = [original_f1, augmented_f1]
f1_class_0_scores = [original_f1_0, augmented_f1_0]
f1_class_1_scores = [original_f1_1, augmented_f1_1]
x = np.arange(len(methods))
width = 0.25
fig, ax = plt.subplots(figsize=(8, 6))
rects1 = ax.bar(x - width, weighted_f1_scores, width, label='加权F1', color='skyblue')
rects2 = ax.bar(x, f1_class_0_scores, width, label='类别0 F1', color='lightcoral')
rects3 = ax.bar(x + width, f1_class_1_scores, width, label='类别1 F1', color='lightgreen')
ax.set_xlabel('方法')
ax.set_ylabel('F1分数')
ax.set_title('GAN增强前后的F1分数对比')
ax.set_xticks(x)
ax.set_xticklabels(methods)
ax.legend()
# 在柱状图上添加数值
def autolabel(rects):
for rect in rects:
height = rect.get_height()
ax.annotate(f'{height:.3f}',
xy=(rect.get_x() + rect.get_width() / 2, height),
xytext=(0, 3),
textcoords="offset points",
ha='center', va='bottom', fontsize=9)
autolabel(rects1)
autolabel(rects2)
autolabel(rects3)
plt.tight_layout()
plt.show()
# 生成可视化对比报告
print("\n" + "="*50)
print("4. F1分数对比总结")
print("="*50)
print(f"{'方法':<15} {'加权F1':<10} {'类别0 F1':<10} {'类别1 F1':<10} {'F1提升':<10}")
print("-"*50)
print(f"{'原始数据':<15} {original_f1:.4f} {original_f1_0:.4f} {original_f1_1:.4f} {'基准':<10}")
print(f"{'GAN增强':<15} {augmented_f1:.4f} {augmented_f1_0:.4f} {augmented_f1_1:.4f} {augmented_f1 - original_f1:+.4f}")
# 分析提升情况
print("\n" + "="*50)
print("5. 分析结论")
if augmented_f1 > original_f1:
print(f"✓ GAN增强使整体F1分数提升了 {100*(augmented_f1-original_f1)/original_f1:.2f}%")
if augmented_f1_0 > original_f1_0:
print(f"✓ 类别0(无心脏病)的F1分数提升了 {100*(augmented_f1_0-original_f1_0)/original_f1_0:.2f}%")
else:
print(f"✗ 类别0(无心脏病)的F1分数下降了 {100*(original_f1_0-augmented_f1_0)/original_f1_0:.2f}%")
if augmented_f1_1 > original_f1_1:
print(f"✓ 类别1(有心脏病)的F1分数提升了 {100*(augmented_f1_1-original_f1_1)/original_f1_1:.2f}%")
else:
print(f"✗ 类别1(有心脏病)的F1分数下降了 {100*(original_f1_1-augmented_f1_1)/original_f1_1:.2f}%")
else:
print("✗ GAN增强没有提升整体F1分数")
# 可视化生成样本的特征分布(PCA降维)
from sklearn.decomposition import PCA
print("\n" + "="*50)
print("6. 特征空间可视化")
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)
generated_pca = pca.transform(generated_data)
plt.figure(figsize=(12, 5))
# 原始数据分布
plt.subplot(1, 2, 1)
plt.scatter(X_pca[y==0, 0], X_pca[y==0, 1], alpha=0.5, label='无心脏病 (原始)', c='red')
plt.scatter(X_pca[y==1, 0], X_pca[y==1, 1], alpha=0.5, label='有心脏病 (原始)', c='blue')
plt.xlabel('PCA Component 1')
plt.ylabel('PCA Component 2')
plt.title('原始数据特征空间分布')
plt.legend()
plt.grid(True, alpha=0.3)
# 原始数据+生成数据分布
plt.subplot(1, 2, 2)
plt.scatter(X_pca[y==0, 0], X_pca[y==0, 1], alpha=0.3, label='无心脏病 (原始)', c='red')
plt.scatter(generated_pca[:, 0], generated_pca[:, 1], alpha=0.5, label='无心脏病 (GAN生成)',
c='orange', marker='x')
plt.scatter(X_pca[y==1, 0], X_pca[y==1, 1], alpha=0.3, label='有心脏病 (原始)', c='blue')
plt.xlabel('PCA Component 1')
plt.ylabel('PCA Component 2')
plt.title('GAN增强后特征空间分布')
plt.legend()
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
# 特征重要性分析
print("\n" + "="*50)
print("7. 特征重要性分析(原始数据 vs GAN增强数据)")
# 在原始数据上训练随机森林
rf_original = RandomForestClassifier(n_estimators=100, random_state=42, class_weight='balanced')
rf_original.fit(X_scaled, y)
importances_original = rf_original.feature_importances_
# 在增强数据上训练随机森林
rf_augmented = RandomForestClassifier(n_estimators=100, random_state=42, class_weight='balanced')
rf_augmented.fit(X_aug_scaled, y_aug)
importances_augmented = rf_augmented.feature_importances_
# 创建特征重要性DataFrame
importance_df = pd.DataFrame({
'特征': X.columns,
'原始数据重要性': importances_original,
'GAN增强重要性': importances_augmented
}).sort_values('原始数据重要性', ascending=False)
print("\nTop 10重要特征对比:")
print(importance_df.head(10).to_string(index=False))
# 可视化特征重要性变化
top_n = 10
top_features = importance_df.head(top_n)['特征'].values
fig, axes = plt.subplots(1, 2, figsize=(14, 6))
# 原始数据特征重要性
axes[0].barh(range(top_n), importance_df.head(top_n)['原始数据重要性'][::-1])
axes[0].set_yticks(range(top_n))
axes[0].set_yticklabels(importance_df.head(top_n)['特征'][::-1])
axes[0].set_xlabel('重要性')
axes[0].set_title('原始数据 - Top 10特征重要性')
# GAN增强数据特征重要性
axes[1].barh(range(top_n), importance_df.head(top_n)['GAN增强重要性'][::-1])
axes[1].set_yticks(range(top_n))
axes[1].set_yticklabels(importance_df.head(top_n)['特征'][::-1])
axes[1].set_xlabel('重要性')
axes[1].set_title('GAN增强数据 - Top 10特征重要性')
plt.tight_layout()
plt.show()
# 保存生成的数据(可选)
print("\n" + "="*50)
print("8. 数据保存")
print(f"原始数据已保存到: {file_path}")
print("如需保存增强后的数据,可以取消注释以下代码:")
print("# augmented_df.to_csv('E:\\PyStudy\\heart_augmented.csv', index=False)")
print("# print('增强数据已保存到: E:\\PyStudy\\heart_augmented.csv')")