1. Kafka概述
1.1 Kafka定义
Apache Kafka 是一款开源的消息系统。可以在系统中起到"肖峰填谷"的作用,也可以用于异构、分布式系统中海量数据的异步化处理。
1.2 Kafka使用场景
- 消息中间件: 作为消息中间件进行消息传递,作为TCP HTTP或者RPC的替代方案,可以实现异步、解耦、削峰(RabbitMQ和RocketMQ能做的事情,它也能做)。因为kafka的吞吐量更高,在大规模消息系统中更有优势。
- 大数据领域: 例如日志归集、行为跟踪、应用监控。
- 数据集成+流计算: 对流式数据进行继承和实时计算。
2、Kafka服务端基本认识
目前比较流行的服务端管理界面主要是 kafka-manager 和 kafka-eagle (国产)。
2.1 Kafka与ZK的关系
总结起来:利用ZK的有序节点、临时节点和监听机制,ZK帮kafka做了这些事情:配置中心(管理Broker、Topic、Partition、Consumer的信息,包括元数据的变动)、负载均衡、命名服务、分布式通知、集群管理和选举、分布式锁。
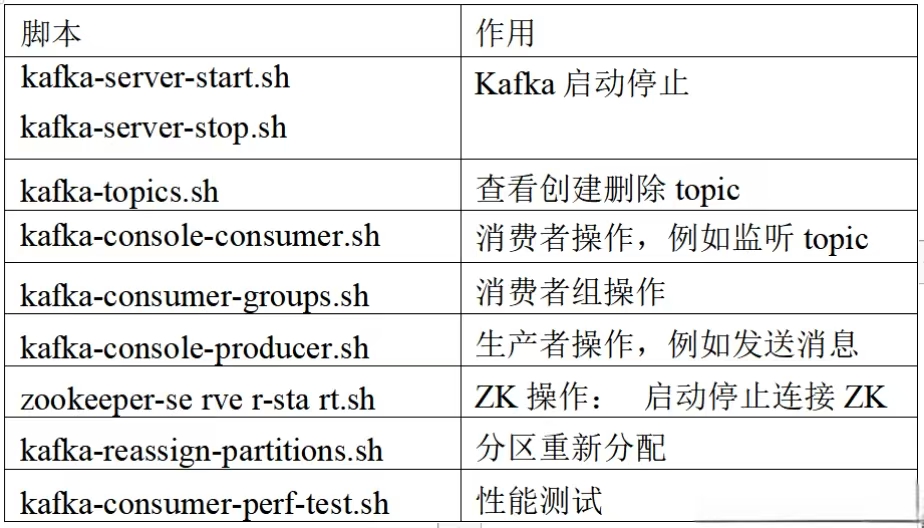
2.2 Kafka脚本介绍
3、Kafka架构分析
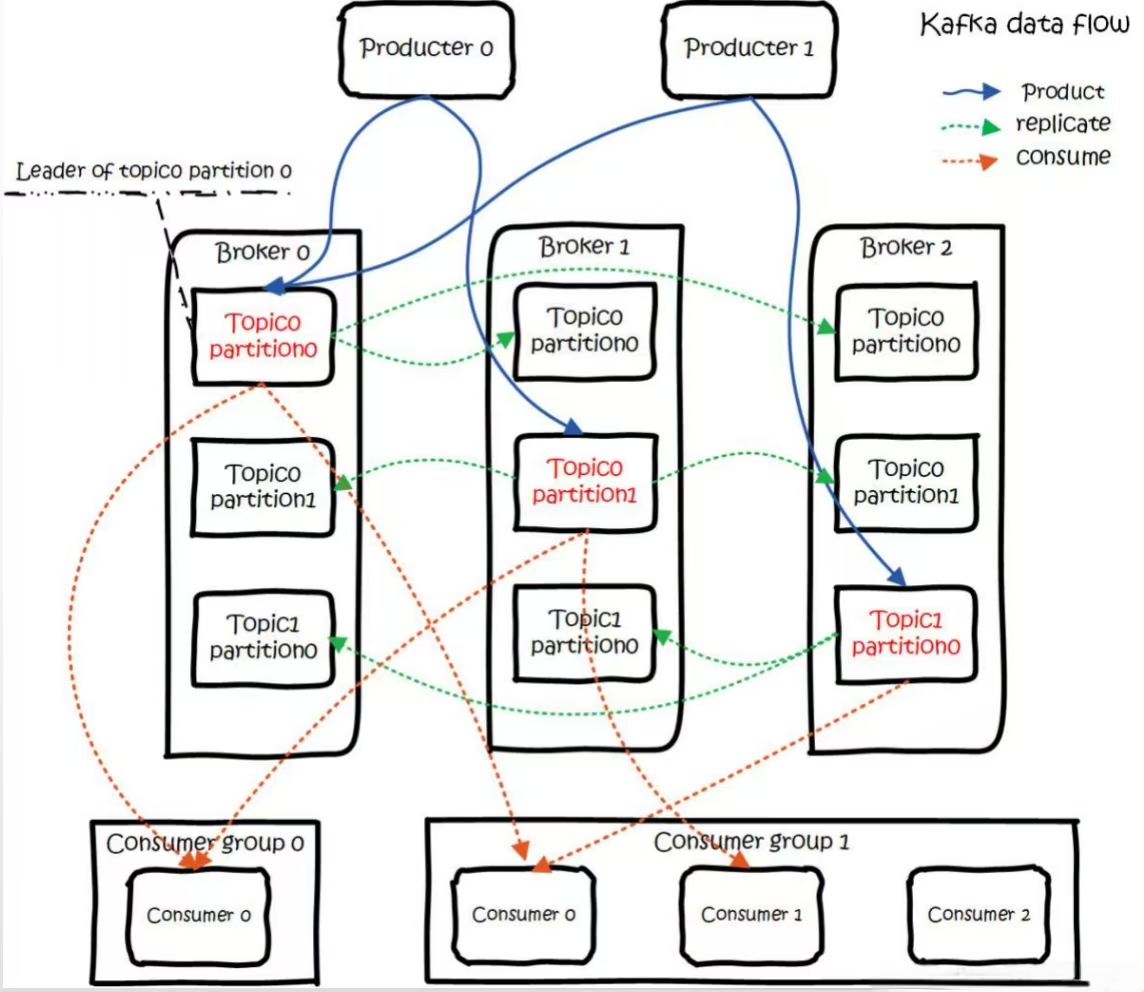
3.1 Broker
Kafka作为一个中间件,是帮我们存储和转发消息的,它做的事情有点像中介,所以我们把kafka的服务叫做Broker,默认是9092的端口。生产者和消费者都需要跟这个Broker建立一个连接,才可以实现消息的收发。
3.2 消息
客户端之间传输的数据叫做消息,或者叫做记录(Record)。在客户端的代码中,Record可以是一个KV键值对,生产者的封装类是ProducerRecord,消费者的封装类是ConsumerRecord。
消息在传输过程中需要序列化,所以在代码中要指定序列化工具。
3.3 生产者
发送消息的一方叫做生产者。为了提升发送效率,生产者不是逐条发送消息给Broker,而是批量发送的 ,发送的数据大小 和时间间隔由以下参数决定:
java
batch.size=16384
linger.ms=03.4 消费者
接收消息的一方叫做消费者。
---般来说消费者获取消息有两种模式,一种是pull模式,一种是push模式。Pull模式就是消费放在Broker,消费者自己决定什么时候去获取。Push模式是消息放在Consumer,只要有消息到达Broker,都直接推给消费者。
Kafka只支持pull模式 ,在push模式下,如果消息产生速度远远大于消费者消费消息的速率,那消费者就会不堪重负(你已经吃不下了,但是还要不断地往你嘴里塞),直到挂掉。而且在pull模式下消费者一次pull获取多少条消息由以下参数决定:
java
max.poll.records=5003.5 Topic
生产者跟消费者是怎么关联起来的呢?或者说,生产者发送的消息,怎么才能到达某个特定的消费者?他们要通过队列关联起来,也就是说,生产者发送消息,要指定发给哪个队列。消费者接收消息,要指定从哪个队列接收。在Kafka里面,这个队列叫做Topic。它是一个逻辑的概念,可以理解为一组消息的集合(用以区分不同业务用途的消息)。
注意,生产者发送消息时,如果Topic不存在,会自动创建。由以下参数决定:
java
auto.create.topics.enable=true3.6 Partition
如果说一个Topic中的消息太多,会带来两个问题:
第一个是不方便横向扩展,比如我想要在集群中把数据分布在不同的机器上实现扩展,而不是通过升级硬件做到,如果一个Topic的消息无法在物理上拆分到多台机器的时候,这个是做不到的。第二个是并发或者负载的问题,所有的客户端操作的都是同一个Topic,在高并发的场景下性能会大大下降。
怎么解决这个问题呢?我们想到的就是把一个Topic进行拆分。 Kafka引入了一个分区(Partition)的概念。一个Topic可以划分成多个分区。 分区在创建topic的时候指定,每个topic至少有一个分区。
在创建topic时需要指定分区数由以下参数决定:
java
num.partitions=1Partition思想上有点类似于分库分表,实现的也是横向扩展和负载的目的。举个例子,Topic有3个分区,生产者依次发送9条消息,对消息进行编号。 第一个分区存1 4 7,第二个分区存2 5 8,第三个分区存3 6 9,这个就实现了负载。
3.7 Replica
如果partition的数据只存储一份,在发生网络或者硬件故障的时候,该分区的数据就无法访问或者无法恢复了。
Kafka在0.8的版本之后增加了副本机制。每个partition可以有若干个副本(Replica),副本必须在不同的Broker 上面。---般我们说的副本包括其中的主节点。由 replication-factor指定一个Topic 的副本数。默认副本数由以下参数决定
java
offsets.topic.replication.factor=1举例:部署了 3个Broker,该topic有3个分区,每个分区一共3个副本。
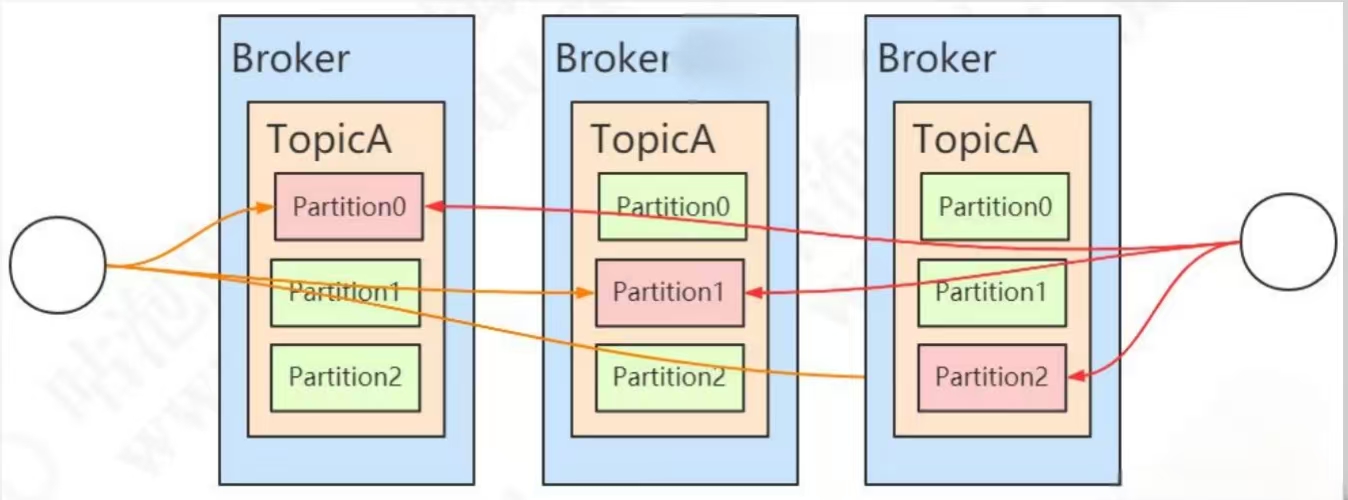
注意:这些存放相同数据的partition副本有leader(图中红色)和follower(图中绿色)的概念。leader在哪台机器是不一定的,选举岀来的。
3.8 Segment
Kafka的数据是放在后缀.log的文件里面的 。如果一个partition只有一个log文件,消息不断地追加,这个log文件也会变得越来越大,这个时候要检索数据效率就很低了。所以干脆把partition再做一个切分,切分岀来的单位就叫做段(segment)。实际上kafka的存储文件是划分成段来存储的。默认存储路径:/tmp/kafka-logs/。每个segment都有至少有1个数据文件和2个索引文件(xxx.log、xxx.index、xxx.timeindex),这3个文件是成套出现的。
3.9 Consumer Group
我们知道消息中间件一般会支持发布/订阅模式和广播模式,那么在Kafka中是如何实现的呢?或者换一种问法,当多个消费者订阅了同一个topic的时候,该如何区分这条消息是要单发还是群发呢?
Kafka引入了消费者组Consumer Group的概念,通过group.id来配置,group.id相同的消费者属于同一个消费者组,Kafka对不同消费者组进行广播,而同一个消费者组中的消费者只消费一次消息。
具体点说,同一个消费者组的消费者不能订阅相同的分区。当消费者数量小于分区数时,一个消费者消费多个分区,当消费者数量大于分区数时,多余的消费者将不进行工作。
3.10 Consumer Offset
我们已经知道Kafka消息是写在日志文件中,并且不会在消费过后就被删除。那么当一个消费者组在消费一半时重启了,该如何继续上一次的位置读取消息呢?为此,Kafka引入Consumer Offset的概念。
Consumer Offset是标记一个消费者组在一个partition即将消费的下一条记录 ,这个信息直接保存在Kafka本身一个特殊的topic中,叫__consumer_offsets,默认创建50个分区。