大数据挖掘建模平台主要由8个模块组成:模型库、数据连接、我的数据、我的工程、系统算法、个人算法、模型管理、计划任务、接口拓展、用户管理系统。

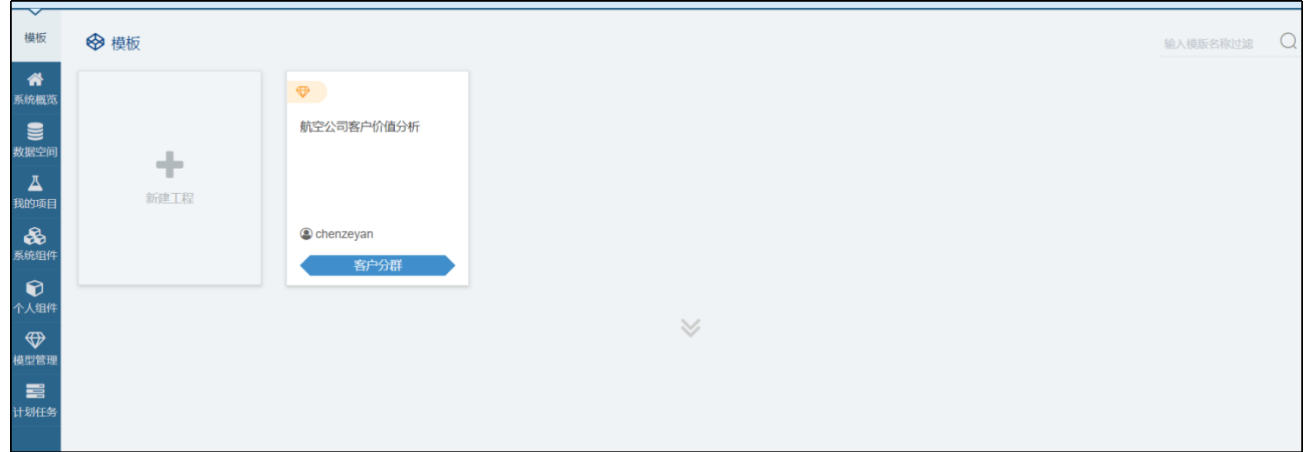
1、模型库
成功登录平台后,进入的第一个页面就是模型库,首页用于展示模型。模型主要用于标准大数据分析案例的快速创建和展示。通过模型,能够建立一个个无需导入数据,设置参数就能够快速运行的工程。同时,每一个模板的创建者都具有模型的所有权,能够对模型进行管理。\
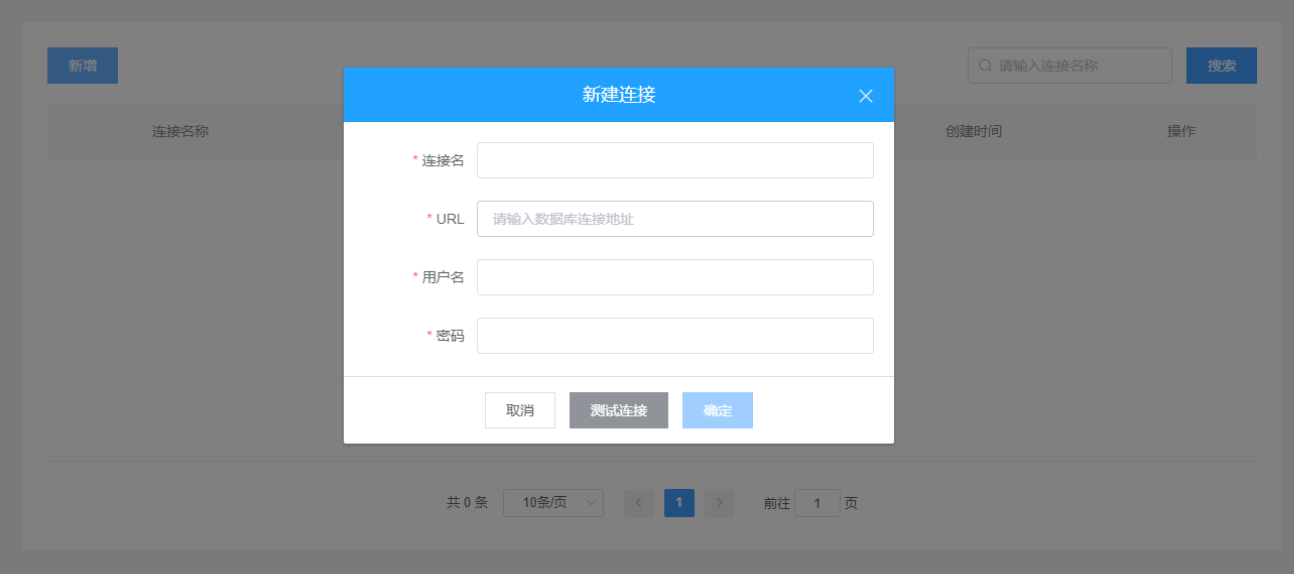
2、数据连接
数据连接是维护各个原始数据库的JDBC连接属性,只要支持JDBC连接的都需要在此进行维护,支持的数据库包含DB2、SQL Server、MySQL、Oracle、PostgreSQL、Kingbase、达梦等有关系型数据库,同时还支持clickhouse、hive等分布式数据库。
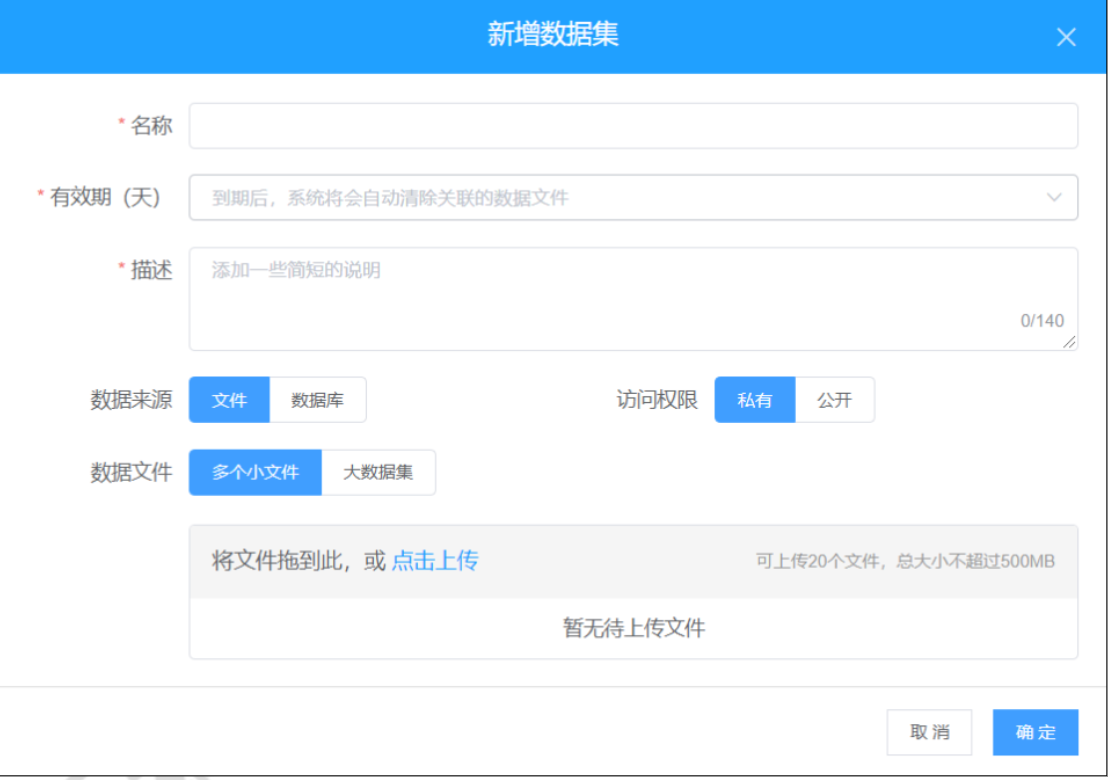
3、我的数据
我的数据是"数据管理员"用于维护系统分析所用的数据源、构建数据模型、创建视图,并进行数据共享分配与管理的模块。数据源管理支持多种类型数据源添加;数据源模块主要用于数据集的导入与管理,用户可根据数据大小选择来源于文件或者来源于数据库。来源于文件支持从本地导入任意类型的数据;来源于数据库支持从DB2、SQL Server、MySQL、Oracle、PostgreSQL等常用关系型数据库导入数据,同时也支持Hive、HBase、HDFS、ES、kafka等。与此同时,每一份导入的数据都能够进行数据预览,数据删除等操作。我的数据同同时支持数据共享操作,共享后该数据即可被其他人查看和使用。
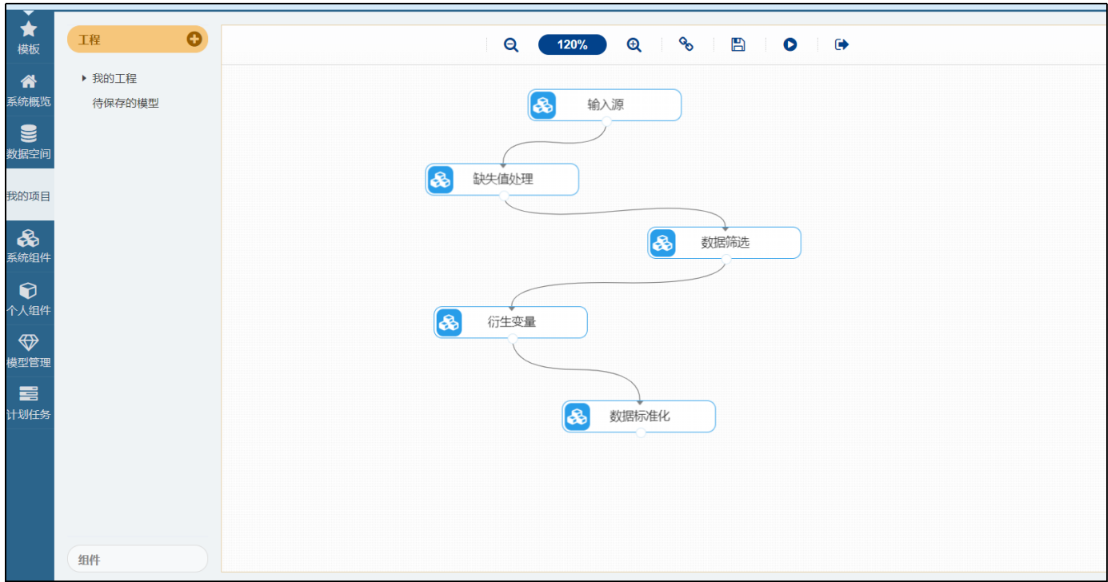
4、我的工程
我的工程模块主要用于机器学习、AI建模流程化案例的创建与管理。通过工程模块,能够创建空白工程,进行AI项目流程的配置,建模结果可通过可视化报告进行查看。对于完成度优秀的工程,可以将其保存到模型库,让其他使用者学习和借鉴。
整个分析流程设计基于拖拽式节点操作、连线式流程串接、参数配置,用户可以通过简单拖拽、配置的方式快速完成挖掘分析流程构建。大数据挖掘建模平台内置数据处理、数据融合、特征工程、扩展编程等功能,让用户能够灵活的运用多种处理手段对数据进行预处理,同时丰富的算法库为用户建模提供了更多的选择,自动学习功能自动推荐最优的算法和参数配置,帮助用户高效建模,快速挖掘数据隐藏价值。
平台分布式算法主要基于业界主流的Spark分布式内存计算框架开发,并采用Spark语言和Python语言中的Pyspark函数进行算法实现,能够支持海量数据的高效挖掘分析。
5.1 系统组件
系统集成了大量的机器学习、人工智能算法,平台内置11大类共164种算法,其中数据清洗47种、文本分析18种、统计分析10种、分类算法20种、聚类算法15种、回归算法20种、时间序列算法10种、关联规则5种、归一化4种、深度学习5种、迁移学习5种、画图5种,满足绝大多数的业务分析场景;支持分布式算法,可对海量数据进行快速挖掘分析;支持深度学习算法、Tensorflow框架、飞桨框架,为用户分析高维海量数据提供更加强大的算法引擎;支持多种集成学习算法,帮助用户提升算法模型的准确度和泛化能力。
5.2 数据管理
平台提供数据管理功能包括数据输入、数据输出,支持关系数据库输入、HIVE、HDFS、HBASE、文件等多种输入节点,作为挖掘分析的数据源。支持关系数据库输出、HIVE 、Hbase、文件输出等多种数据输出,可将结果数据输出到指定位置。
5.3 数据清洗
支持多种数据清洗方法,包括数据标准化(Python算法)、数据离散化(R语言算法)、缺失值处理(Python算法)、异常值处理(R语言算法)等等
5.4 文本分析
为了满足用户对于中文文本数据的分析需求,大数据挖掘建模平台集成了分词器、停词器、词汇分隔、词频统计、文本分词、jieba分词(Pyspark算法)、去停用词(Pyspark算法)、文本过滤等
5.5 统计分析
大数据挖掘建模平台支持全表统计(Python算法)、行列统计(Spark算法)、正态性检验(Python算法)、相关性分析(Python算法)、卡方检验(Python算法)、主成分分析(Python算法)、纯随机性检验(Python算法)、平稳性检验(Python算法)、累计计算(Pyspark算法)、主成分分析(Pyspark算法)等多种统计分析方法,对数据进行初步的统计分析发现数据特征及数据规律,为挖掘分析打好基础。
6、自定义组件
大数据挖掘建模平台内置的自定义算法功能,允许用户通过R\Python\Scala\PySpark基于平台规范封装自主算法并发布形成平台节点,方便用户灵活扩展平台算法节点功能,增强平台的业务适应能力,充分满足企业级用户的个性化需求。
7、模型管理
模型管理模块主要针对分类算法,对训练集使用某分类算法得出的模型,里面将包括模型的输入、输出、算法参数的信息,还可以查询模型快照。可将该模型部署到一批新的数据上用于验证或者预测。