一、前言
在日常使用 Tomcat 时,我们往往只关注它如何"跑起来",却很少真正去理解 Tomcat 是如何一步一步完成启动的。 本文从 Bootstrap 入口开始,到 Server、Service、Connector、Engine、Host、Context 的层层初始化,再到端口监听、请求接管,Tomcat 在启动过程中隐藏了大量精巧的设计与工程实践。
本文将以 Tomcat 9 源码为基础,从 init() 和 start() 两个生命周期方法入手,结合调试过程,系统性地梳理 Tomcat 的启动流程,重点回答以下几个问题:
-
Tomcat 的启动入口在哪里?
-
init 和 start 在语义和职责上有什么本质区别?
-
Connector、Endpoint、Acceptor、Poller 分别在什么时候创建并启动?
-
Web 应用的 Context 是在启动阶段还是请求阶段初始化的?
-
为什么 Tomcat 要频繁切换线程上下文类加载器(TCCL)?
二、Tomcat的Bootstrap init源码分析
Tomcat的启动类入口是位于org.apache.catalina.startup.Bootstrap包下的类,会调用其main方法,该方法的源码如下:
public static void main(String[] args) {
synchronized (daemonLock) {
if (daemon == null) {
Bootstrap bootstrap = new Bootstrap();
try {
bootstrap.init();
} catch (Throwable t) {
handleThrowable(t);
log.error("Init exception", t);
return;
}
daemon = bootstrap;
} else {
Thread.currentThread().setContextClassLoader(daemon.catalinaLoader);
}
}
try {
String command = "start";
if (args.length > 0) {
command = args[args.length - 1];
}
switch (command) {
case "startd":
args[args.length - 1] = "start";
daemon.load(args);
daemon.start();
break;
case "stopd":
args[args.length - 1] = "stop";
daemon.stop();
break;
case "start":
daemon.setAwait(true);
daemon.load(args);
daemon.start();
if (null == daemon.getServer()) {
System.exit(1);
}
break;
case "stop":
daemon.stopServer(args);
break;
case "configtest":
daemon.load(args);
if (null == daemon.getServer()) {
System.exit(1);
}
System.exit(0);
break;
default:
break;
}
} catch (Throwable t) {
Throwable throwable = t;
if (throwable instanceof InvocationTargetException && throwable.getCause() != null) {
throwable = throwable.getCause();
}
handleThrowable(throwable);
System.exit(1);
}
}我们看到主要创建了Bootstrap类,调用其init方法,该方法的源码如下:
public void init() throws Exception {
initClassLoaders();
Thread.currentThread().setContextClassLoader(catalinaLoader);
SecurityClassLoad.securityClassLoad(catalinaLoader);
if (log.isTraceEnabled()) {
log.trace("Loading startup class");
}
Class<?> startupClass = catalinaLoader.loadClass("org.apache.catalina.startup.Catalina");
Object startupInstance = startupClass.getConstructor().newInstance();
// Set the shared extensions class loader
if (log.isTraceEnabled()) {
log.trace("Setting startup class properties");
}
String methodName = "setParentClassLoader";
Class<?>[] paramTypes = new Class[1];
paramTypes[0] = Class.forName("java.lang.ClassLoader");
Object[] paramValues = new Object[1];
paramValues[0] = sharedLoader;
Method method = startupInstance.getClass().getMethod(methodName, paramTypes);
method.invoke(startupInstance, paramValues);
catalinaDaemon = startupInstance;
}我们可以看到又调用了initClassLoaders方法,那么我们就先分析它的这个执行路径Bootstrap.main->Bootstrap.init()->Bootstrap.initClassLoaders(),initClassLoaders方法的源码如下:
private void initClassLoaders() {
try {
commonLoader = createClassLoader("common", null);
if (commonLoader == null) {
commonLoader = this.getClass().getClassLoader();
}
catalinaLoader = createClassLoader("server", commonLoader);
sharedLoader = createClassLoader("shared", commonLoader);
} catch (Throwable t) {
handleThrowable(t);
log.error("Class loader creation threw exception", t);
System.exit(1);
}
}可以明显看出这个方法创建了三个类加载器,分别是CommonLoader、CatalinaLoader、SharedLoader,其中CatalinaLoader、SharedLoader的父类加载器是CommonLoader这正是我上篇文章说的那样的类加载器关系,那现在重点来看createClassLoader方法,它的源码如下:
private ClassLoader createClassLoader(String name, ClassLoader parent) throws Exception {
String value = CatalinaProperties.getProperty(name + ".loader");
if ((value == null) || (value.isEmpty())) {
return parent;
}
value = replace(value);
List<Repository> repositories = new ArrayList<>();
String[] repositoryPaths = getPaths(value);
for (String repository : repositoryPaths) {
try {
URI uri = new URI(repository);
@SuppressWarnings("unused")
URL url = uri.toURL();
repositories.add(new Repository(repository, RepositoryType.URL));
continue;
} catch (IllegalArgumentException | MalformedURLException | URISyntaxException e) {
}
if (repository.endsWith("*.jar")) {
repository = repository.substring(0, repository.length() - "*.jar".length());
repositories.add(new Repository(repository, RepositoryType.GLOB));
} else if (repository.endsWith(".jar")) {
repositories.add(new Repository(repository, RepositoryType.JAR));
} else {
repositories.add(new Repository(repository, RepositoryType.DIR));
}
}
return ClassLoaderFactory.createClassLoader(repositories, parent);
}读取catalina.properties配置文件中的common.loader="${catalina.base}/lib","${catalina.base}/lib/*.jar","${catalina.home}/lib","${catalina.home}/lib/*.jar"
解析出对应的项目目录封装为repositoryPaths字符串数组,遍历该数组封装为List<Repository> repositories,最后调用ClassLoaderFactory.createClassLoader(repositories, parent)方法创建一个URLClassLoader类加载器,加载路径就是从这些路径上的jar包下加载类,同理server、shared都是类似加载规则,但是默认情况下catalina.properties都没配置这两个路径,由源码可知如果没有配置默认返回父类加载器,所以
catalinaLoader=sharedLoader=commonLoader。
好,我们继续回到Bootstrap的init方法,执行这段代码Thread.currentThread().setContextClassLoader(catalinaLoader);设置当前线程类加载器是CatalinaLoader,反射调用创建org.apache.catalina.startup.Catalina对象并设置Catalina的成员属性的ClassLoader为SharedLoader,最后把BootStrap对象的成员属性catalinaDaemon设置为反射创建的org.apache.catalina.startup.Catalina对象。
执行到这里返回到Bootstrap的load方法,该方法里面又反射调用Catalina的load方法,该方法的源码如下:
public void load() {
if (loaded) {
return;
}
// Parse main server.xml
parseServerXml(true);
Server s = getServer();
if (s == null) {
return;
}
getServer().setCatalina(this);
getServer().setCatalinaHome(Bootstrap.getCatalinaHomeFile());
getServer().setCatalinaBase(Bootstrap.getCatalinaBaseFile());
// Stream redirection
initStreams();
// Start the new server
try {
getServer().init();
} catch (LifecycleException e) {
if (Boolean.getBoolean("org.apache.catalina.startup.EXIT_ON_INIT_FAILURE")) {
throw new Error(e);
} else {
log.error(sm.getString("catalina.initError"), e);
}
}
if (log.isInfoEnabled()) {
log.info(sm.getString("catalina.init",
Long.toString(TimeUnit.NANOSECONDS.toMillis(System.nanoTime() - t1))));
}
}先调用parseServerXml方法解析conf/server.xml配置文件,把它封装为Server对象,Server对象里面又有多个Service对象,该对象结构就像server.xml那样嵌套的结构一样。
在解析配置文件并把它们封装为各个对象时候会调用它们的构造方法,值得说明一点的是在实例化StandardHost对象时候,构造方法创建一个是这样的:
public StandardHost() {
super();
pipeline.setBasic(new StandardHostValve());
}其中pipeline的类型是StandardPipeline,它实现了Pipeline接口,用于管理执行Valves添加和执行,这里手动实例化了StandardHostValve,后面请求的时候会调用这个类的invoke方法。
同样实例化StandardContext时候,它的构造方法也是创建一个Pipeline接口,代码如下:
public StandardContext() {
super();
pipeline.setBasic(new StandardContextValve());
}这里也手动实例化了一个StandardContextValve对象,后面请求的时候也会调用这个类的invoke方法。
实例化StandardWrapper对象时候同样创建一个StandardWrapperValve对象,后面请求时候会调用这个类的invoke方法,代码如下:
public StandardWrapper() {
super();
swValve = new StandardWrapperValve();
pipeline.setBasic(swValve);
broadcaster = new NotificationBroadcasterSupport();
}设置Server对象的Catalina、catalinaHome、catalinaBase属性分为Catalina对象、catalinaHome文件路径、catalinaBase文件路径,调用Server类的init方法,Server的实现类是StandardServer, 它的类继承结构是这样的:
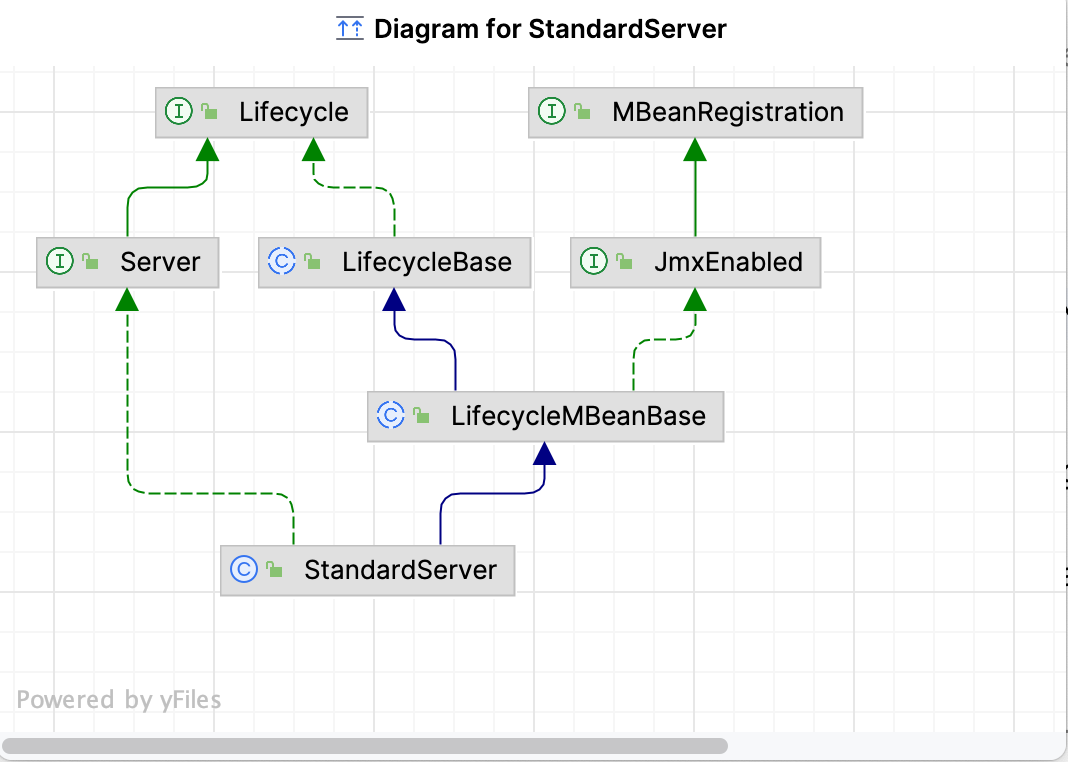
从图中可以看出它继承了LifecycleMBeanBase,LifecycleMBeanBase是一个抽象类,继承了LifecycleBase抽象类实现Lifecycle接口,LifecycleBase抽象类实现了接口Lifecycle的init、start、destroy等方法、init、start方法里面分别又调用了initInternal、startInternal方法,把这些实现都留给了子类去实现,这是典型的模板方法设计模式。
好,那我们现在来看看StandardServer的init方法源码,实际上是调用它的父类LifecycleBase的init方法,源码如下:
public final synchronized void init() throws LifecycleException {
if (!state.equals(LifecycleState.NEW)) {
invalidTransition(BEFORE_INIT_EVENT);
}
try {
setStateInternal(LifecycleState.INITIALIZING, null, false);
initInternal();
setStateInternal(LifecycleState.INITIALIZED, null, false);
} catch (Throwable t) {
handleSubClassException(t, "lifecycleBase.initFail", toString());
}
}又调用了setStateInternal方法,该方法源码如下:
private synchronized void setStateInternal(LifecycleState state, Object data, boolean check)
throws LifecycleException {
this.state = state;
String lifecycleEvent = state.getLifecycleEvent();
if (lifecycleEvent != null) {
fireLifecycleEvent(lifecycleEvent, data);
}
}主要做的事情主要有:
-
修改内部状态为INITIALIZING
-
触发
BEFORE_INIT_EVENT -
通知所有
LifecycleListener
子类真正实现init逻辑主要是调用initInternal方法,它的实现类是StandardServer,该方法源码如下:
protected void initInternal() throws LifecycleException {
for (Service service : findServices()) {
service.init();
}
}它这里又调用了Service类的init方法,它的实现类是StandardService,它同样是继承了LifecycleMBeanBase实现Lifecycle接口,只需要看它的initInternal方法,该方法源码如下:
protected void initInternal() throws LifecycleException {
if (engine != null) {
engine.init();
}
for (Executor executor : findExecutors()) {
if (executor instanceof JmxEnabled) {
((JmxEnabled) executor).setDomain(getDomain());
}
executor.init();
}
// Initialize mapper listener
mapperListener.init();
// Initialize our defined Connectors
for (Connector connector : findConnectors()) {
connector.init();
}
}这里我们重点分析一下connector.init()的逻辑,主要是初始化 Tomcat 的所有网络监听端口和底层通信组件,但并不开始接收请求,Connector是Tomcat的网络入口,它的作用如下:
| 职责 | 举例 |
|---|---|
| 监听端口 | 8080 / 8443 |
| 协议解析 | HTTP / HTTPS |
| 线程模型 | NIO / APR |
| 把请求交给容器 | Engine |
Connector的initInternal源码如下:
protected void initInternal() throws LifecycleException {
super.initInternal();
if (protocolHandler == null) {
throw new LifecycleException(sm.getString("coyoteConnector.protocolHandlerInstantiationFailed"));
}
adapter = new CoyoteAdapter(this);
protocolHandler.setAdapter(adapter);
try {
protocolHandler.init();
} catch (Exception e) {
throw new LifecycleException(sm.getString("coyoteConnector.protocolHandlerInitializationFailed"), e);
}
}首先判断protocolHandler是否等于null,如果是null抛出异常,一般情况下它不会是null,它是在解析Server.xml时候赋值的,默认是Http11NioProtocol,它主要解析Http协议的类,接着创建一个CoyoteAdapter对象,它主要 负责把解析后的请求,交给 Tomcat 容器(Engine / Host / Context / Servlet)。接着调用Http11NioProtocol的init方法,该方法里面实例化一个HttpParser对象,它负责解析http协议,这里面它又调用了父类AbstractProtocol的init方法,这里主要调用了NioEndpoint的init方法,NioEndpoint主要负责网络监听的类,作用主要包括bind 端口、启动启动 Acceptor 线程等。
各个组件的init执行完成后都会执行其setStateInternal方法,该方法主要是
1.修改内部状态为INITIALIZED
2.触发 AFTER_INIT_EVENT
3.通知所有 LifecycleListener
至此Server的init方法执行完成了,Server.init() 的作用:初始化整个 Tomcat 实例的"运行骨架",创建并初始化所有 Service(包括 Engine 和 Connector),但此时还不对外提供服务。
三、Tomcat的Bootstrap start源码分析
此时继续执行会调用到Catalina.start方法,该方法源码如下:
public void start() {
if (getServer() == null) {
load();
}
if (getServer() == null) {
log.fatal(sm.getString("catalina.noServer"));
return;
}
long t1 = System.nanoTime();
try {
getServer().start();
} catch (LifecycleException e) {
log.fatal(sm.getString("catalina.serverStartFail"), e);
try {
getServer().destroy();
} catch (LifecycleException e1) {
log.debug(sm.getString("catalina.destroyFail"), e1);
}
return;
}
if (log.isInfoEnabled()) {
log.info(sm.getString("catalina.startup",
Long.toString(TimeUnit.NANOSECONDS.toMillis(System.nanoTime() - t1))));
}
if (generateCode) {
generateLoader();
}
if (useShutdownHook) {
if (shutdownHook == null) {
shutdownHook = new CatalinaShutdownHook();
}
Runtime.getRuntime().addShutdownHook(shutdownHook);
LogManager logManager = LogManager.getLogManager();
if (logManager instanceof ClassLoaderLogManager) {
((ClassLoaderLogManager) logManager).setUseShutdownHook(false);
}
}
if (await) {
await();
stop();
}
}首先调用的是Server的start方法,继而调用所有子节点的start方法,跟执行init流程是一致的,我们来看一下Engine的start方法,因为Server的start方法没什么逻辑,首先需要说明一下Engine不是像Server和Service直接继承Lifecycle,而是直接继承的Container接口, 那么Container是什么那?为啥有的实现了 Container,有的实现了 Lifecycle,Container解决的是请求如何被路由和处理的问题,Lifecycle 解决的是「组件如何被启动、停止和管理」的问题。只有Engine、Host、 Context、Wrapper直接继承了该接口,因为它们都涉及到请求的处理,明白了这一点我们来看看StandardEngine的startInternal方法是如何实现的。 它调用了父类ContainerBase的startInternal方法,该方法源码如下:
protected void startInternal() throws LifecycleException {
reconfigureStartStopExecutor(getStartStopThreads());
Container[] children = findChildren();
List<Future<Void>> results = new ArrayList<>(children.length);
for (Container child : children) {
results.add(startStopExecutor.submit(new StartChild(child)));
}
MultiThrowable multiThrowable = null;
for (Future<Void> result : results) {
try {
result.get();
} catch (Throwable t) {
log.error(sm.getString("containerBase.threadedStartFailed"), t);
if (multiThrowable == null) {
multiThrowable = new MultiThrowable();
}
multiThrowable.add(t);
}
}
if (multiThrowable != null) {
throw new LifecycleException(sm.getString("containerBase.threadedStartFailed"),
multiThrowable.getThrowable());
}
if (pipeline instanceof Lifecycle) {
((Lifecycle) pipeline).start();
}
setState(LifecycleState.STARTING);
if (backgroundProcessorDelay > 0) {
monitorFuture = Container.getService(ContainerBase.this).getServer().getUtilityExecutor()
.scheduleWithFixedDelay(new ContainerBackgroundProcessorMonitor(), 0, 60, TimeUnit.SECONDS);
}
}先是调用了reconfigureStartStopExecutor方法实例化一个startStopExecutor变量是InlineExecutorService,它实现了ExecutorService线程池对象,获取子Container对象数组,即是StandardHost,在异步线程池中提交调用StandardHost的start方法并调用result.get()方法阻塞获取结果,那这里就先需要看一下StandardHost的startInternal方法执行逻辑,该方法源码如下:
protected void startInternal() throws LifecycleException {
String errorValve = getErrorReportValveClass();
if ((errorValve != null) && (!errorValve.isEmpty())) {
try {
boolean found = false;
Valve[] valves = getPipeline().getValves();
for (Valve valve : valves) {
if (errorValve.equals(valve.getClass().getName())) {
found = true;
break;
}
}
if (!found) {
Valve valve = ErrorReportValve.class.getName().equals(errorValve) ? new ErrorReportValve() :
(Valve) Class.forName(errorValve).getConstructor().newInstance();
getPipeline().addValve(valve);
}
} catch (Throwable t) {
ExceptionUtils.handleThrowable(t);
log.error(sm.getString("standardHost.invalidErrorReportValveClass", errorValve), t);
}
}
super.startInternal();
}获取Valve集合,上篇文章说过,配置Valve是在所有执行Context之前执行用于做一些事情,比如Server.xml中的这段配置:
<Valve className="org.apache.catalina.valves.AccessLogValve" directory="logs"
prefix="localhost_access_log" suffix=".txt"
pattern="%h %l %u %t "%r" %s %b" />用户记录日志操作,这里又在Pipeline中添加一个ErrorReportValve一个个执行。
接着调用父类的startInternal方法,此时去获取StandardHost的子Container集合,此处获取的是空的,但是它发布了一个STARTING事件,HostConfig监听了
STARTING事件,它处理逻辑主要是添加Context(Web应用),即webapps下面的所有配置,它的deployApps方法如下:
protected void deployApps() {
File appBase = host.getAppBaseFile();
File configBase = host.getConfigBaseFile();
String[] filteredAppPaths = filterAppPaths(appBase.list());
// Deploy XML descriptors from configBase
deployDescriptors(configBase, configBase.list());
deployWARs(appBase, filteredAppPaths);
deployDirectories(appBase, filteredAppPaths);
}首先调用解析deployDescriptors方法解析conf\Catalina\localhost下的配置文件,主要调用的是HostConfig的deployDescriptor方法,调用digester.parse方法生成一个StandardContext对象,在生成StandardContext对象过程中实例化它的成员属性ApplicationContext context,它代表的是一个Web上下文对象,它是一个重要对象以后的Servlet都封装为Wrapper对象添加到ApplicationContext上。 反射创建一个ContextConfig对象并把它设置为StandardContext的监听对象,当调用StandardContext的start方法时候会调用ContextConfig的webConfig解析web.xml,然后调用host.addChild(context)把Context加入到Host对象中,下面重点看一下StandardContext的startInternal方法,该方法源码简化如下:
protected void startInternal() throws LifecycleException {
setResources(new StandardRoot(this));
resourcesStart();
if (getLoader() == null) {
WebappLoader webappLoader = new WebappLoader();
webappLoader.setDelegate(getDelegate());
setLoader(webappLoader);
}
ClassLoader oldCCL = bindThread();
Loader loader = getLoader();
if (loader instanceof Lifecycle) {
((Lifecycle) loader).start();
}
}先说明一下StandardRoot,它是 Tomcat 中 Web 应用的"资源视图层",负责统一访问 Web 应用的所有资源包括:
- WEB-INF/web.xml
- WEB-INF/classes
- WEB-INF/lib/*.jar
- 静态资源(html / js / css / 图片)
- 外部挂载目录(docBase 之外的资源)
首先创建一个StandardRoot对象,它内部维护多个 WebResourceSet,每个代表一类资源,用一个表格说明里面的多个WebResourceSet都代表什么:
| ResourceSet | 来源 |
|---|---|
| Main | webapp 根目录 |
| Class | WEB-INF/classes |
| Jar | WEB-INF/lib/*.jar |
| Pre / Post | 外部挂载资源 |
然后调用该对象的start方法,该方法源码如下:
protected void startInternal() throws LifecycleException {
mainResources.clear();
main = createMainResourceSet();
mainResources.add(main);
for (List<WebResourceSet> list : allResources) {
if (list != classResources) {
for (WebResourceSet webResourceSet : list) {
webResourceSet.start();
}
}
}
processWebInfLib();
for (WebResourceSet classResource : classResources) {
classResource.start();
}
cache.enforceObjectMaxSizeLimit();
setState(LifecycleState.STARTING);
}调用createMainResourceSet方法创建一个代表conf\Catalina\localhost配置文件下的docBase指定的文件夹对象,实现类是DirResourceSet,这块暂时没看明白先空下。
接着继续执行StandardContext的startInternal方法,创建一个WebappLoader,它是为 Web 应用准备"自己的类加载器(WebappClassLoader),它主要是扫描WEB-INF/classes 、WEB-INF/lib/*.jar 、Servlet / Filter / Listener等。
接着调用bindThread方法绑定当前线程的ClassLoader为WebappClassLoader,第一次oldCCL是null,调用Loader的startInternal方法进行绑定,我们重点来看一下它的方法源码是如何实现的:
protected void startInternal() throws LifecycleException {
try {
classLoader = createClassLoader();
classLoader.setResources(context.getResources());
classLoader.setDelegate(this.delegate);
setClassPath();
} catch (Throwable t) {
Throwable throwable = ExceptionUtils.unwrapInvocationTargetException(t);
ExceptionUtils.handleThrowable(throwable);
throw new LifecycleException(sm.getString("webappLoader.startError"), throwable);
}
setState(LifecycleState.STARTING);
}调动createClassLoader方法创建一个ParallelWebappClassLoader对象并设置它的父的Classloader是URLClassLoader,从这以后就用这个ClassLoader去加载每个应用WEB-INF、WEB-CLASSES下面的Listener、Filter、Servlet ,知道这一点很重要,接着设置WebResourceRoot路径,设置delegate属性默认是false,代表是子优先加载(即是Web应用),如果是true表示让父去加载(比如JDK/Tomcat容器),一般情况我们都设置为false,表示要让ParallelWebappClassLoader去加载,调用setClassPath方法把自己的路径和父Classloader能加载的路径赋值到成员属性classpath上,最终复制到ServletContext的key是org.apache.catalina.jsp_classpath,value值是classpath。
此时又返回到StandardContext的startInternal方法接着执行bindThread方法把创建出来的ParallelWebappClassLoader绑定到当前线程。
接着调用fireLifecycleEvent(CONFIGURE_START_EVENT, null)发布Context已经启动的监听事件,此时会调用到ContextConfig的configureStart方法,又调用webConfig,这个方法就比较重要了,它是解析web.xml主要方法,Listener、Filter、Servlet等解析都在这里。这里我调一些主要的分析。
首先是调用processServletContainerInitializers方法,该方法源码如下:
protected void processServletContainerInitializers() {
List<ServletContainerInitializer> detectedScis;
try {
WebappServiceLoader<ServletContainerInitializer> loader = new WebappServiceLoader<>(context);
detectedScis = loader.load(ServletContainerInitializer.class);
} catch (IOException ioe) {
log.error(sm.getString("contextConfig.servletContainerInitializerFail", context.getName()), ioe);
ok = false;
return;
}
for (ServletContainerInitializer sci : detectedScis) {
initializerClassMap.put(sci, new HashSet<>());
HandlesTypes ht;
try {
ht = sci.getClass().getAnnotation(HandlesTypes.class);
} catch (Exception e) {
if (log.isDebugEnabled()) {
log.debug(sm.getString("contextConfig.sci.debug", sci.getClass().getName()), e);
} else {
log.info(sm.getString("contextConfig.sci.info", sci.getClass().getName()));
}
continue;
}
if (ht == null) {
continue;
}
Class<?>[] types = ht.value();
if (types == null) {
continue;
}
for (Class<?> type : types) {
if (type.isAnnotation()) {
handlesTypesAnnotations = true;
} else {
handlesTypesNonAnnotations = true;
}
typeInitializerMap.computeIfAbsent(type, k -> new HashSet<>()).add(sci);
}
}
}可以看到这块有个主要类**ServletContainerInitializer** ,它是Servlet3.0 引入的"容器启动扩展点",让框架可以在 Web 应用启动时,由容器主动回调,而不是靠 web.xml,主要通过SPI机制去应用的META-INF/services/javax.servlet.ServletContainerInitializer文件去找实现ServletContainerInitializer接口实现类,然后可以自定义添加自定义的Servlet,先看WebappServiceLoader的load方法,该方法源码如下:
public List<T> load(Class<T> serviceType) throws IOException {
String configFile = SERVICES + serviceType.getName();
ClassLoader loader = context.getParentClassLoader();
Enumeration<URL> containerResources;
if (loader == null) {
containerResources = ClassLoader.getSystemResources(configFile);
} else {
containerResources = loader.getResources(configFile);
}
LinkedHashSet<String> containerServiceClassNames = new LinkedHashSet<>();
Set<URL> containerServiceConfigFiles = new HashSet<>();
while (containerResources.hasMoreElements()) {
URL containerServiceConfigFile = containerResources.nextElement();
containerServiceConfigFiles.add(containerServiceConfigFile);
parseConfigFile(containerServiceClassNames, containerServiceConfigFile);
}
if (containerSciFilterPattern != null) {
containerServiceClassNames.removeIf(s -> containerSciFilterPattern.matcher(s).find());
}
LinkedHashSet<String> applicationServiceClassNames = new LinkedHashSet<>();
List<String> orderedLibs = (List<String>) servletContext.getAttribute(ServletContext.ORDERED_LIBS);
if (orderedLibs == null) {
Enumeration<URL> allResources = servletContext.getClassLoader().getResources(configFile);
while (allResources.hasMoreElements()) {
URL serviceConfigFile = allResources.nextElement();
if (!containerServiceConfigFiles.contains(serviceConfigFile)) {
parseConfigFile(applicationServiceClassNames, serviceConfigFile);
}
}
} else {
URL unpacked = servletContext.getResource(CLASSES + configFile);
if (unpacked != null) {
parseConfigFile(applicationServiceClassNames, unpacked);
}
for (String lib : orderedLibs) {
URL jarUrl = servletContext.getResource(LIB + lib);
if (jarUrl == null) {
continue;
}
String base = jarUrl.toExternalForm();
URL url;
if (base.endsWith("/")) {
URI uri;
try {
uri = new URI(base + configFile);
} catch (URISyntaxException e) {
throw new IOException(e);
}
url = uri.toURL();
} else {
url = JarFactory.getJarEntryURL(jarUrl, configFile);
}
try {
parseConfigFile(applicationServiceClassNames, url);
} catch (FileNotFoundException e) {
}
}
}
containerServiceClassNames.addAll(applicationServiceClassNames);
if (containerServiceClassNames.isEmpty()) {
return Collections.emptyList();
}
return loadServices(serviceType, containerServiceClassNames);
}先获取应用的父加载器的ClassLoader去$CATALINA_HOME/lib寻找META-INF/services/javax.servlet.ServletContainerInitializer,如果有加入到有顺序的LinkedHashSet中这样可以保证父ClassLoader加载的在前面,接着在执行自己的ClassLoader去寻找同样加入到LinkedHashSet中,然后调用loadServices方法反射创建META-INF/services/javax.servlet.ServletContainerInitializer指定的类并把它实例化为对象。
接着执行返回到processServletContainerInitializers方法得到一个List<ServletContainerInitializer> detectedScis集合,遍历该集合把它放入到Map<ServletContainerInitializer,Set<Class<?>>>数据结构中,其中key是得到的ServletContainerInitializer对象,value是一个Set集合,接着判断ServletContainerInitializer上是否有HandlesTypes注解类,@HandlesTypes 是 Servlet 3.0+ 中 ServletContainerInitializer的一个关键注解 ,它的作用主要是 告诉容器在启动阶段哪些类对这个 SCI 可能感兴趣 ,方便容器提前扫描和传递给 onStartup 方法。 它的主要查找逻辑是找到所有HandlesTypes注解修饰的类所有实现类最终加入到initializerClassMap的Value中。 接着会执行ContextConfig的processClass方法,该方法主要是查找是否有@WebServlet、WebFilter、WebListener注解把它们扫描到对应的定义类中去,我们来看看这个方法源码:
protected void processClass(WebXml fragment, JavaClass clazz) {
AnnotationEntry[] annotationsEntries = clazz.getAnnotationEntries();
if (annotationsEntries != null) {
String className = clazz.getClassName();
for (AnnotationEntry ae : annotationsEntries) {
String type = ae.getAnnotationType();
if ("Ljavax/servlet/annotation/WebServlet;".equals(type)) {
processAnnotationWebServlet(className, ae, fragment);
} else if ("Ljavax/servlet/annotation/WebFilter;".equals(type)) {
processAnnotationWebFilter(className, ae, fragment);
} else if ("Ljavax/servlet/annotation/WebListener;".equals(type)) {
fragment.addListener(className);
} else {
// Unknown annotation - ignore
}
}
}
}首先获取类名称,然后获取它的类上的注解,如果注解是WebServlet,调用processAnnotationWebServlet方法,该方法源码如下:
protected void processAnnotationWebServlet(String className, AnnotationEntry ae, WebXml fragment) {
String servletName = null;
List<ElementValuePair> evps = ae.getElementValuePairs();
for (ElementValuePair evp : evps) {
String name = evp.getNameString();
if ("name".equals(name)) {
servletName = evp.getValue().stringifyValue();
break;
}
else if ("initParams".equals(name)) {
Map<String,String> initParams = processAnnotationWebInitParams(evp.getValue());
for (Map.Entry<String,String> entry : initParams.entrySet()) {
servletDef.addInitParameter(entry.getKey(), entry.getValue());
}
}
}
else if ("loadOnStartup".equals(name)) {
if (servletDef.getLoadOnStartup() == null) {
servletDef.setLoadOnStartup(evp.getValue().stringifyValue());
}
}
}
ServletDef servletDef = new ServletDef();
servletDef.setServletName(servletName);
servletDef.setServletClass(className);
if ( urlPatterns != null) {
fragment.addServlet(servletDef);
}
if (urlPatterns != null) {
if (!fragment.getServletMappings().containsValue(servletName)) {
for (String urlPattern : urlPatterns) {
fragment.addServletMapping(urlPattern, servletName);
}
}
}
}先获取WebFilter注解的name名称然后赋值给变量servletName,变量evps判断是否有urlPatterns属性,代表的是Servlet的请求路径,如果有解析出来赋值给变量urlPatterns,它是一个String数组,判断注解是否有loadOnStartup属性如果有设置到ServletDef上,判断是否有initParams属性,如果有添加到ServletDef对象成员属性Map<String,String> paramete上。
最后判断如果urlPatterns不为空,调用fragment.addServlet(servletDef)方法把servletDef添加到对象WebXml的成员属性Map<String,ServletDef> servlet上,如果urlPatterns不为空,调用fragment.addServletMapping(urlPattern, servletName)方法把key=urlPattern,value=servletName放到WebXml的成员属性Map<String,String> servletMappings上。
此时回到processClass方法判断如果有WebFilter注解调用processAnnotationWebFilter方法进线处理,该方法源码如下:
protected void processAnnotationWebFilter(String className, AnnotationEntry ae, WebXml fragment) {
String filterName = null;
List<ElementValuePair> evps = ae.getElementValuePairs();
for (ElementValuePair evp : evps) {
String name = evp.getNameString();
if ("filterName".equals(name)) {
filterName = evp.getValue().stringifyValue();
break;
}
}
if (filterName == null) {
filterName = className;
}
FilterDef filterDef = fragment.getFilters().get(filterName);
FilterMap filterMap = new FilterMap();
if (filterDef == null) {
filterDef = new FilterDef();
filterDef.setFilterName(filterName);
filterDef.setFilterClass(className);
}
boolean urlPatternsSet = false;
boolean servletNamesSet = false;
boolean dispatchTypesSet = false;
String[] urlPatterns;
for (ElementValuePair evp : evps) {
String name = evp.getNameString();
if ("value".equals(name) || "urlPatterns".equals(name)) {
if (urlPatternsSet) {
throw new IllegalArgumentException(
sm.getString("contextConfig.urlPatternValue", "WebFilter", className));
}
urlPatterns = processAnnotationsStringArray(evp.getValue());
urlPatternsSet = urlPatterns.length > 0;
for (String urlPattern : urlPatterns) {
filterMap.addURLPattern(urlPattern);
}
} else if ("servletNames".equals(name)) {
String[] servletNames = processAnnotationsStringArray(evp.getValue());
servletNamesSet = servletNames.length > 0;
for (String servletName : servletNames) {
filterMap.addServletName(servletName);
}
} else if ("initParams".equals(name)) {
Map<String,String> initParams = processAnnotationWebInitParams(evp.getValue());
if (isWebXMLfilterDef) {
Map<String,String> webXMLInitParams = filterDef.getParameterMap();
for (Map.Entry<String,String> entry : initParams.entrySet()) {
if (webXMLInitParams.get(entry.getKey()) == null) {
filterDef.addInitParameter(entry.getKey(), entry.getValue());
}
}
} else {
for (Map.Entry<String,String> entry : initParams.entrySet()) {
filterDef.addInitParameter(entry.getKey(), entry.getValue());
}
}
}
}
fragment.addFilter(filterDef);
if (urlPatternsSet || servletNamesSet) {
filterMap.setFilterName(filterName);
fragment.addFilterMapping(filterMap);
}
}先获取WebFilter注解的filterName名称然后赋值给变量filterName,创建FilterDef对象设置FilterName属性为filterName的值,设置FilterClass属性为className。
判断是否有urlPatterns,如果有解析出来它的路径,调用FilterMap对象的addURLPattern方法,把它方法在该对象成员属性urlPatterns上,它是一个String数组结构。
判断是否有servletNames属性,它代表匹配的Servelt名字,只有匹配的名字才会进行拦截,如果指定有为*代表匹配所有Servelt,设置FilterMap对象matchAllServletNames成员属性为true,解析出来放在FilterMap对象的成员属性servletNames上,它同样是一个String数组结构。
判断是否有initParams属性,如果有添加到FilterDef对象成员属性Map<String,String> parameter上,调用fragment.addFilter(filterDef)方法把FilterDef添加到对象WebXml的成员属性Map<String,FilterDef> filters上,设置FilterMap成员属性filterName值为注解修饰的filterName值,调用fragment.addFilterMapping(filterMap)方法放到成员属性Set filterMaps 上。
此时回到processClass方法判断如果有WebListener注解调用fragment.addListener(className);把名称添加到Set listeners成员属性上,这个比较简单。
执行完ContextConfig解析方法会把Servlet、Filter、Listener存放在StandardContext中,此时返回到这段代码继续执行:
for (Map.Entry<ServletContainerInitializer,Set<Class<?>>> entry : initializers.entrySet()) {
try {
entry.getKey().onStartup(entry.getValue(), getServletContext());
} catch (ServletException e) {
log.error(sm.getString("standardContext.sciFail"), e);
ok = false;
break;
}
}此时开始真正执行业务自定义的ServletContainerInitializer的实现类的onStartup方法,该方法第一个参数是Set<Class<?>> c代表HandlesTypes修饰的类,第二个参数是ServletContext,该方法的用途主要是可以往ServletContext添加自定义Servelt,例如我下面这个例子:
@HandlesTypes(A.class)
public class MyServletContainerInitializer implements ServletContainerInitializer {
@Override
public void onStartup(Set<Class<?>> c, ServletContext ctx) throws ServletException {
System.out.println("SCI called");
// 动态注册一个 Servlet
ctx.addServlet("helloServlet", new HelloServlet())
.addMapping("/hello");
}
}这个方法执行完成以后开始调用StandardContext的listenerStart方法,该方法作用主要是实例化自定义ServletContextListener对象并调用其contextInitialized方法,源码如下:
public boolean listenerStart() {
String[] listeners = findApplicationListeners();
Object[] results = new Object[listeners.length];
boolean ok = true;
for (int i = 0; i < results.length; i++) {
try {
String listener = listeners[i];
results[i] = getInstanceManager().newInstance(listener);
} catch (Throwable t) {
Throwable throwable = ExceptionUtils.unwrapInvocationTargetException(t);
ExceptionUtils.handleThrowable(throwable);
getLogger().error(sm.getString("standardContext.applicationListener", listeners[i]), throwable);
ok = false;
}
}
List<Object> lifecycleListeners = new ArrayList<>();
for (Object result : results) {
if ((result instanceof ServletContextAttributeListener) ||
(result instanceof ServletRequestAttributeListener) || (result instanceof ServletRequestListener) ||
(result instanceof HttpSessionIdListener) || (result instanceof HttpSessionAttributeListener)) {
eventListeners.add(result);
}
if ((result instanceof ServletContextListener) || (result instanceof HttpSessionListener)) {
lifecycleListeners.add(result);
}
}
ServletContextEvent event = new ServletContextEvent(getServletContext());
for (Object instance : instances) {
if (!(instance instanceof ServletContextListener)) {
continue;
}
ServletContextListener listener = (ServletContextListener) instance;
try {
listener.contextInitialized(event);
} catch (Throwable t) {
ExceptionUtils.handleThrowable(t);
fireContainerEvent("afterContextInitialized", listener);
getLogger().error(sm.getString("standardContext.listenerStart", instance.getClass().getName()), t);
ok = false;
}
}接着调用filterStart方法,实例化Filter对象,调用其init方法等操作,该方法源码如下:
public boolean filterStart() {
if (getLogger().isTraceEnabled()) {
getLogger().trace("Starting filters");
}
// Instantiate and record a FilterConfig for each defined filter
boolean ok = true;
synchronized (filterDefs) {
filterConfigs.clear();
for (Entry<String,FilterDef> entry : filterDefs.entrySet()) {
String name = entry.getKey();
if (getLogger().isTraceEnabled()) {
getLogger().trace(" Starting filter '" + name + "'");
}
try {
ApplicationFilterConfig filterConfig = new ApplicationFilterConfig(this, entry.getValue());
filterConfigs.put(name, filterConfig);
} catch (Throwable t) {
Throwable throwable = ExceptionUtils.unwrapInvocationTargetException(t);
ExceptionUtils.handleThrowable(throwable);
getLogger().error(sm.getString("standardContext.filterStart", name), throwable);
ok = false;
}
}
}
return ok;
}首先遍历filterDefs的Filter定义类,然后创建一个ApplicationFilterConfig对象,它实现了FilterConfig接口,里面只有Filter对象,它的构造方法如下:
ApplicationFilterConfig(Context context, FilterDef filterDef)
throws ClassCastException, ReflectiveOperationException, ServletException, NamingException,
IllegalArgumentException, SecurityException {
super();
this.context = context;
this.filterDef = filterDef;
if (filterDef.getFilter() == null) {
getFilter();
} else {
this.filter = filterDef.getFilter();
context.getInstanceManager().newInstance(filter);
initFilter();
}
}设置成员属性Context为StandardContext对象,然后反射实例化Filter对象并调用其init方法,最后把key=Filter的name,value是ApplicationFilterConfig对象放入到StandardContext成员属性的Map<String,ApplicationFilterConfig> filterConfigs中。
接着调用loadOnStartup方法,该方法主要是查找loadOnStartup大于0的Servlet(被封装为Wrapper),调用Wrapper的load方法实例化Servlet对象并调用其init方法,这里的源码跟Filter差不多我就不贴源码了。
到此处StandardContext的startInternal方法就执行完成了,最后还有一个重要步骤是在finally里面unbindThread(oldCCL);目的是切换当前线程的ClassLoader为Tomcat的ClassLoader方便进行后续操作。
这些组件都执行完成以后还有一个组件是Connector的startInternal也比较重要,它是开启Tomcat线程的主要实现,源码如下:
protected void startInternal() throws LifecycleException {
// Validate settings before starting
String id = (protocolHandler != null) ? protocolHandler.getId() : null;
if (id == null && getPortWithOffset() < 0) {
throw new LifecycleException(
sm.getString("coyoteConnector.invalidPort", Integer.valueOf(getPortWithOffset())));
}
setState(LifecycleState.STARTING);
if (protocolHandler != null && service != null) {
protocolHandler.setUtilityExecutor(service.getServer().getUtilityExecutor());
}
try {
protocolHandler.start();
} catch (Exception e) {
throw new LifecycleException(sm.getString("coyoteConnector.protocolHandlerStartFailed"), e);
}
}调用了ProtocolHandler的start方法,它的实现类是Http11NioProtocol,它实现了抽象类AbstractProtocol,调用的是AbstractProtocol的start方法,然后这里是调用NioEndpoint的startInternal方法,该方法源码如下:
public void startInternal() throws Exception {
if (!running) {
running = true;
paused = false;
if (getExecutor() == null) {
createExecutor();
}
// Start poller thread
poller = new Poller();
Thread pollerThread = new Thread(poller, getName() + "-Poller");
pollerThread.setPriority(threadPriority);
pollerThread.setDaemon(true);
pollerThread.start();
startAcceptorThread();
}
}首先调用createExecutor方法创建Tomcat的工作线程,即tomcat执行请求时候所需要的线程,源码如下:
public void createExecutor() {
TaskQueue taskqueue = new TaskQueue(maxQueueSize);
TaskThreadFactory tf = new TaskThreadFactory(getName() + "-exec-", daemon, getThreadPriority());
executor = new ThreadPoolExecutor(getMinSpareThreads(), getMaxThreads(), getThreadsMaxIdleTime(),
TimeUnit.MILLISECONDS, taskqueue, tf);
taskqueue.setParent((ThreadPoolExecutor) executor);
}自定义一个线程工厂TaskThreadFactory,线程名称是以http-nio-8080-exec-开头,getMinSpareThreads方法获取核心线程数默认是10,getMaxThreads方法获取最大线程数默认是200,最后把线程池对象赋值给成员属性Executor。
接着创建一个Poller线程,线程名称是http-nio-8080-Poller,调用startAcceptorThread方法开启一个Acceptor线程,线程名称是http-nio-8080-Acceptor。
这里创建了两个线程,分别是Poller线程、Acceptor线程,Acceptor线程主要作用是负责接收请求,然后Poller线程负责处理请求中的事件,比如读写事件,这样做可以提高并发能力而不是把接收请求和处理 请求都放在一个线程中。
四、总结
本文通过将启动流程拆分为 init 与 start 两个阶段,Tomcat 明确区分了"结构准备"与"运行激活"的边界,并以父容器驱动子容器的方式,逐级完成 Server、Service、Engine、Host 以及 Context 的启动,形成一条自顶向下、层次清晰的生命周期调用链。
在此过程中,WebAppClassLoader 作为 Web 应用级别的类加载器,为每一个 Context 提供独立的类加载空间,通过调整传统双亲委派的加载顺序,实现了应用之间的类隔离与版本隔离,保证了多 Web 应用在同一 JVM 中的稳定共存。
在 Web 3.0 规范引入的无 web.xml 配置模型下,Tomcat 通过 ServletContainerInitializer 这一容器级扩展点,在 Context 启动阶段对应用类进行统一扫描,并借助 @HandlesTypes 收集符合条件的类信息,将框架级初始化逻辑以回调的方式交由第三方框架或应用本身完成。该机制使得容器能够在不感知具体业务语义的前提下,支持复杂框架的自动装配。
与之相比,@WebFilter、@WebServlet、@WebListener 等注解则属于应用级组件定义,它们在启动阶段被容器识别并完成注册,但真正的作用时机发生在运行阶段,请求到来时才参与过滤链或调用链的执行。二者职责清晰分离:前者负责"如何初始化",后者负责"如何处理请求"。