本文入选顶会ACM Multimedia
布局生成在电商图片的设计中起到至关重要的作用。当前的布局生成方法在能力上具有任务特定性,并且评估标准与人类感知不一致,导致其应用范围有限且评估效果不佳。为了解决这些问题,Uni-Layout实现了统一生成、模拟人类的评估以及二者之间的对齐。针对通用生成,该框架将各种布局任务整合到一个统一的分类系统中,并开发了一个统一的生成器,通过自然语言提示处理背景或元素内容受限的任务。为了引入人类反馈以有效评估布局,我们构建了Layout-HF100k,这是首个包含10万个人工标注布局的大规模人类反馈数据集。基于Layout-HF100k,我们引入了一种模拟人类的评估器,该评估器结合视觉和几何信息,采用思维链机制进行定性评估,并通过信心估计模块提供定量测量。为了更好地对齐生成器和评估器,我们采用动态边距偏好优化(DMPO)技术,将二者整合为一个协调系统,以更好地符合人类判断。
一、背景与现状
布局生成旨在为给定的元素设计吸引人的视觉排版,涵盖从海报和文档设计到用户界面布局和杂志排版等广泛任务。虽然生成模型取得了显著进展,但现有方法通常专注于狭义任务,导致解决方案缺乏灵活性和普适性。此外,尽管现有的评估指标基于布局设计原则精心设计,但它们常常与人类的感知不一致。如图1所示,高评分的布局可能在视觉质量上较差,这揭示了现有指标与真实人类感知之间的差距。为了解决这些挑战,我们提出了Uni-Layout,一个通过统一生成器、模拟人类的评估器和动态边距对齐机制来整合布局生成、评估和对齐的整体框架。为了详细阐述Uni-Layout,本文围绕三个核心研究问题展开。

图1:布局生成任务的分类体系与动机阐述
二、如何实现跨任务的统一布局生成
为了系统地统一当前分散的布局生成任务领域,我们提出了一个基于两个维度的精心组织的分类法:背景和元素内容是自由的还是受限的。如图1所示,我们将现有的布局任务分为四种代表性类型:BFEF、BCEF、BFEC和BCEC。当前的任务特定方法在统一布局生成方面存在困难,但多模态大型语言模型(MLLMs)由于其通用的视觉-语言理解能力,提供了有前景的解决方案。利用MLLMs,我们提出了一个统一的布局生成器,其工作方式类似于一名熟练的设计师。该生成器结合视觉约束和文本指令来生成连贯的布局,能够处理背景和元素内容既可以受限也可以自由的多种场景。通过在各种布局任务上的联合训练,它为布局生成提供了一个灵活且统一的解决方案。
为了统一多种布局任务,一个通用的布局任务指令可写作:
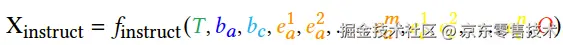
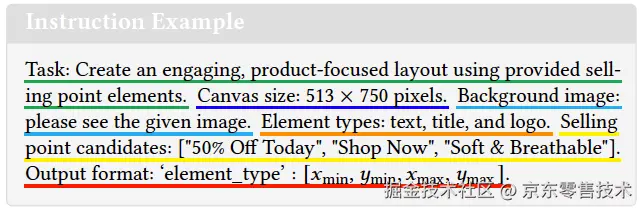
其中T为任务描述,b表示背景的内容和属性,e表示元素的内容和属性,O是指定的输出格式。注意背景和元素的属性是必须的,但其内容可为空。为了清楚起见,我们针对BCEC任务提供了一个说明示例,其中下划线部分对应上式中的对应项。
三、如何模拟人类来评估布局
尽管人类感知在布局设计中非常重要,但现有数据集中缺乏对布局质量的人类反馈。为弥补这一缺口,我们汇总了统一生成器的输出,并编制了Layout-HF100k,这是首个专为布局生成策划的全面人类反馈数据集,包含10万个精心标注的高质量示例,涵盖代表性布局任务。该数据集的示例如图2所示。

图2:Layout-HF100k示例。第一/二行分别为合格/不合格布局。
基于这一全新的数据集,我们开发了一种评估器,结构如图3(b)和(c)所示。其通过视觉和几何信息两个分支处理布局,以有效模拟人类判断模式。此外,该评估器结合了一个输出定量置信度估计的分类头,以及定性"思维链"(CoT)推理,使其能够捕捉微妙的审美偏好,并提供与人类感知模式紧密对齐的可解释评估。通过结合多模态分析和CoT推理,我们的评估器不仅能够做出准确判断,还能阐明其决策背后的理由,类似于人类专家如何评估布局。
具体来说,CoT包含以下四个步骤:
(1) 布局概览:对布局可视化结果快速而全面的扫描,通过简洁的文本描述捕捉布局的第一印象,概述整体构图和上下文元素。
(2) 空间解构:系统地分解布局的基本组成部分,分析几何属性和空间关系。它检查对齐模式、识别潜在重叠,并评估间距一致性,以揭示潜在的结构框架。
(3) 美学评估:对布局的视觉质量进行详细评估,重点关注艺术价值和设计原则。这包括对比例平衡、空间和谐和视觉节奏的评估,同时考虑这些元素如何对整体美学效果产生影响。
(4) 全面评估:最后阶段综合所有先前分析的见解,以提供对布局有效性的全面评估,最后给出"合格"或"不合格"的明确判断。
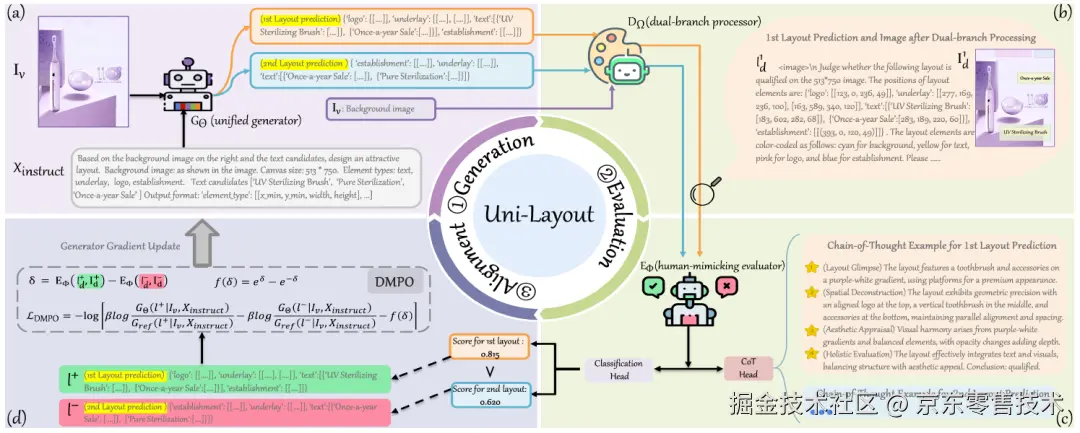
图3:Uni-Layout框架概览
四、如何有效对齐人类反馈和布局生成
现有的对齐方法要么直接最大化人类偏好的输出可能性,要么在其偏好学习目标中使用固定边距。这些传统方法未能反映人类偏好的不同程度,因为它们对强偏好和弱偏好一视同仁。为了解决这一限制,我们提出了一种新的对齐方法,称为动态边距偏好优化(DMPO)。具体而言,当评估者在成对样本之间表现出更强烈的偏好时,DMPO会自动增加边距,以在胜出和失败的响应之间强制产生更大的分数差异,而对于不太明显的偏好则应用较小的边距。这种信心引导的自适应边距策略更好地捕捉了人类判断的范围,从而实现与布局生成和人类偏好的更精确对齐。
如图3(d)所示,给定任务指令和可选的背景或元素内容,生成器产生两个候选布局l1和l2。之后通过双分支处理器将布局结果转化为视觉和几何信息,并通过布局评估器产出候选布局的得分。我们将两种布局的分数差距定义如下:
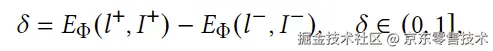
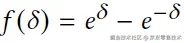
其中I+和l+分别表示高分布局的视觉和几何信息。为了进一步增强对边距的感知,我们应用了非线性变换f()来处理分数差距。最终,DMPO的损失形式可写作:
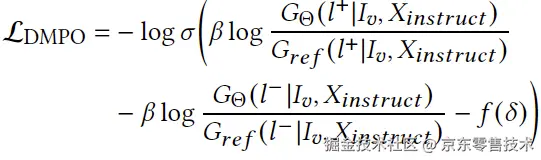
通过将生成和评估整合到反馈循环中,DMPO弥合了布局生成和人类审美偏好之间的差距,产生了更具视觉吸引力的布局。
五、实验结果
1、布局评估模型性能
为了验证我们的评估器,我们将其与一些领先的闭源(M)LLM模型进行比较,包括GPT-4o、Claude3.5 Sonnet(Claude3.5)、GLM-4v和DeepSeek-R1。这些模型遵循"LLM-as-Judge"范式。所有模型接收相同的指令和视觉输入,除了DeepSeek-R1,它只处理文本。如表1所示,我们的模型表现出色,达到85.5%的准确率,比现有的MLLMs高出25-35%。一些MLLMs的表现接近随机(约50%),突显了它们在布局评估中的局限性。
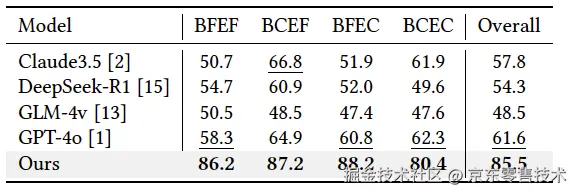
表1 :布局评估模型对比
2、布局生成模型性能
在本小节中,我们与三类基线方法进行了比较:(1) 针对单个布局任务设计的任务特定SOTA模型(例如,LayoutDM);(2) 闭源模型,包括GPT-4o、Claude3.5和DeepSeek-R1;(3) 开源的多模态大语言模型(MLLMs),如联合训练四个任务的LLaVA。
在表2展示的任务特定评估中,我们的方法在多个指标上表现出色。值得注意的是,在BFEF任务中,我们实现了最低的Ove(0.001)和Ali(0.00004),与专用模型如LayoutDM和LayoutFlow持平或超越。在BFEC任务中,我们的方法以最小的Ove(0.00045)和最高的Max.(0.439)创下新纪录。在BCEF任务中,我们在𝑅𝑐𝑜𝑚(31.848)和𝑅𝑠𝑢𝑏(0.774)方面取得了最佳结果。同样,在BCEC任务中,我们的方法以最低的𝑅𝑐𝑜𝑚(8.536)显著优于现有方法,同时在其他指标上保持竞争力。
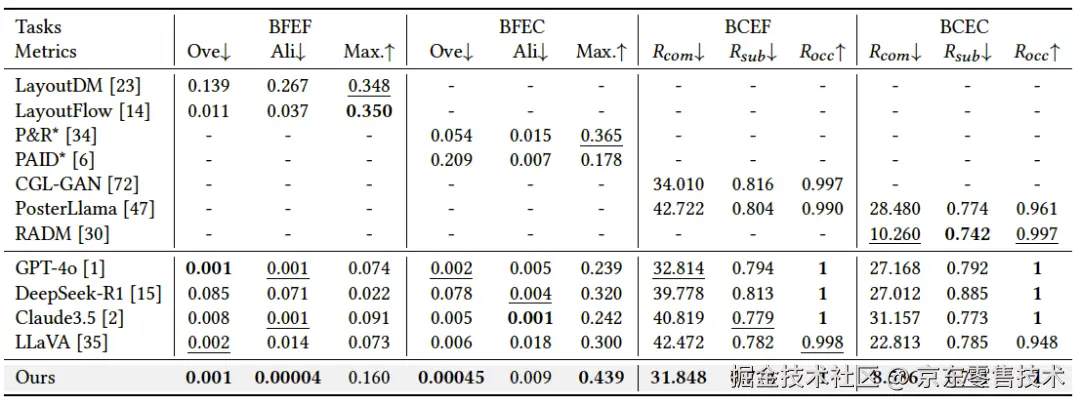
表2:任务特定评估指标结果
针对所有任务的人类模拟评估,我们引入了评估模型的LR分数来评估性能。如图4所示,我们的方法实现了最高的LR分数0.702,在不同布局场景中表现出持续的优越性。与其他模型相比,我们显著超越了GPT-4o(0.584)、Claude3.5(0.575)和DeepSeek-R1(0.401),差距明显。与开源基线LLaVA(0.422)相比,性能差距更加显著,提升了近30%。与LayoutFlow(BFEF的SOTA)、P&R(BFEC的SOTA)和Poster-Llama(BCEF和BCEC的SOTA)取得的平均LR分数0.658相比,我们的方法取得了更优的结果,从而验证了Uni-Layout的有效性。
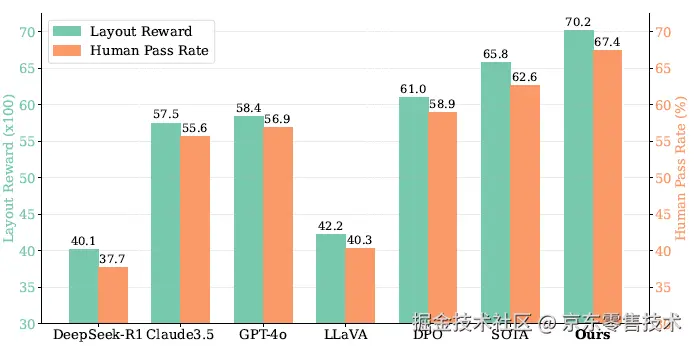
图4: 人类模拟评估指标结果