一、JVM整体架构概览
1.1 Java跨平台的秘密
Java的"一次编写,到处运行"依赖于JVM在软件层面屏蔽了操作系统差异:
HelloWorld.java → javac编译 → HelloWorld.class → JVM执行 ↓ 不同操作系统 ↓ 统一字节码执行环境
1.2 JVM运行时数据区(内存模型)
┌─────────────────────────────────────────────────────────┐
│ JVM运行时数据区 │
├─────────────┬─────────────────┬─────────────────────────┤
│ 线程私有区 │ 共享区 │ 其他区域 │
├─────────────┼─────────────────┼─────────────────────────┤
│ • 程序计数器 │ • 堆(Heap) │ • 直接内存 │
│ • 虚拟机栈 │ - 新生代 │ • 代码缓存(CodeCache) │
│ • 本地方法栈 │ - 老年代 │ │
│ │ • 方法区 │ │
│ │ - JDK8+:元空间 │ │
└─────────────┴─────────────────┴─────────────────────────┘1.3 核心内存区域详解
堆(Heap)- 对象的主战场
-
新生代:Eden + Survivor0 + Survivor1(默认8:1:1)
-
老年代:长期存活对象的归宿
-
参数控制 :
-Xms(初始堆大小)、-Xmx(最大堆大小)、-Xmn(新生代大小)
方法区(Method Area)- 类的仓库
-
JDK7及之前:永久代(PermGen)
-
JDK8+:元空间(Metaspace),使用本地内存
-
参数控制 :
-XX:MetaspaceSize、-XX:MaxMetaspaceSize
虚拟机栈(VM Stack)- 线程的私有空间
-
每个方法对应一个栈帧
-
栈帧包含:局部变量表、操作数栈、动态链接、方法返回地址
-
参数控制 :
-Xss(栈大小)
二、类加载机制:从Class文件到内存对象
2.1 类加载三原则
-
类缓存:每个类加载器对加载过的类都有缓存
-
双亲委派:向上委托查找,向下委托加载
-
沙箱保护 :禁止加载
java.*开头的核心类
2.2 JDK8类加载器体系
启动类加载器(Bootstrap) ↑ 扩展类加载器(Extension) ↑ 应用类加载器(AppClassLoader) ↑ 自定义类加载器
代码示例:
public class LoaderDemo {
public static void main(String[] args) {
// 查看类加载器层次
ClassLoader loader = LoaderDemo.class.getClassLoader();
System.out.println("当前类加载器: " + loader); // sun.misc.Launcher$AppClassLoader
System.out.println("父加载器: " + loader.getParent()); // sun.misc.Launcher$ExtClassLoader
System.out.println("祖父加载器: " + loader.getParent().getParent()); // null
}
}2.3 打破双亲委派的实战场景
场景:Tomcat的多应用隔离
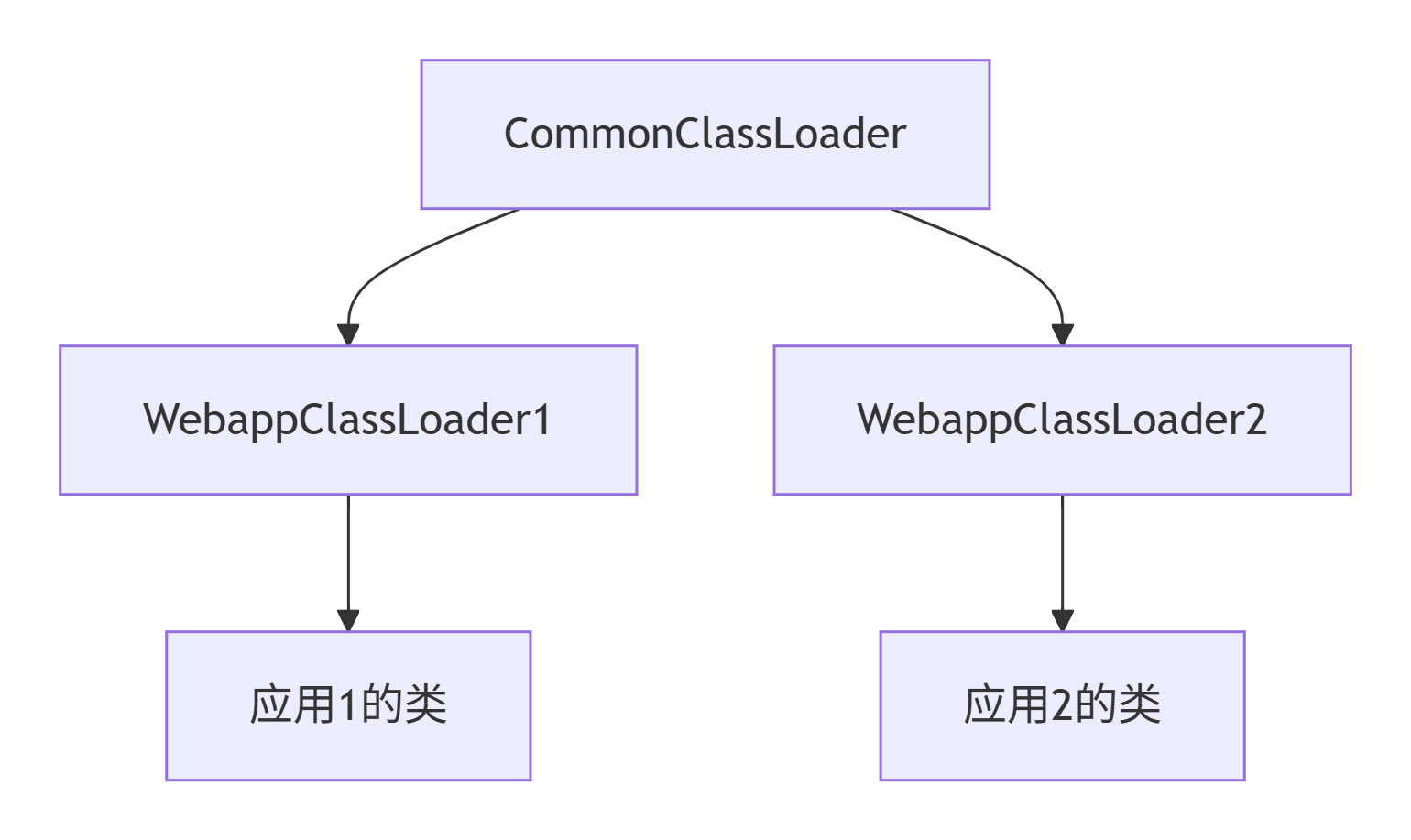
Tomcat为何打破双亲委派?
-
不同Web应用需要加载不同版本的相同类(如Spring)
-
JSP页面需要热更新
-
共享库与私有库分离
场景:自定义热加载实现
public class HotSwapClassLoader extends ClassLoader {
@Override
protected Class<?> loadClass(String name, boolean resolve) {
// 1. 先自己尝试加载(打破双亲委派)
Class<?> c = findClass(name);
if (c == null) {
// 2. 自己加载失败,再交给父类
c = super.loadClass(name, resolve);
}
return c;
}
}2.4 类加载的实战应用
1. 外部JAR包动态加载
URL jarUrl = new URL("file:/path/to/external.jar");
URLClassLoader loader = new URLClassLoader(new URL[]{jarUrl});
Class<?> clazz = loader.loadClass("com.example.ExternalClass");2. Class文件加密与解密
public class SecureClassLoader extends ClassLoader {
@Override
protected Class<?> findClass(String name) {
// 1. 读取加密的.class文件
byte[] encryptedData = loadClassData(name + ".encrypted");
// 2. 解密字节码
byte[] decryptedData = decrypt(encryptedData);
// 3. 定义类
return defineClass(name, decryptedData, 0, decryptedData.length);
}
}3. SPI机制优雅扩展
// 使用ServiceLoader加载所有实现
ServiceLoader<SalaryCalculator> calculators =
ServiceLoader.load(SalaryCalculator.class);
for (SalaryCalculator calc : calculators) {
double salary = calc.calculate(baseSalary);
}三、对象创建与内存分配全流程
3.1 对象创建五部曲
1. 类加载检查 → 2. 分配内存 → 3. 初始化零值 → 4. 设置对象头 → 5. 执行<init>3.2 内存分配策略
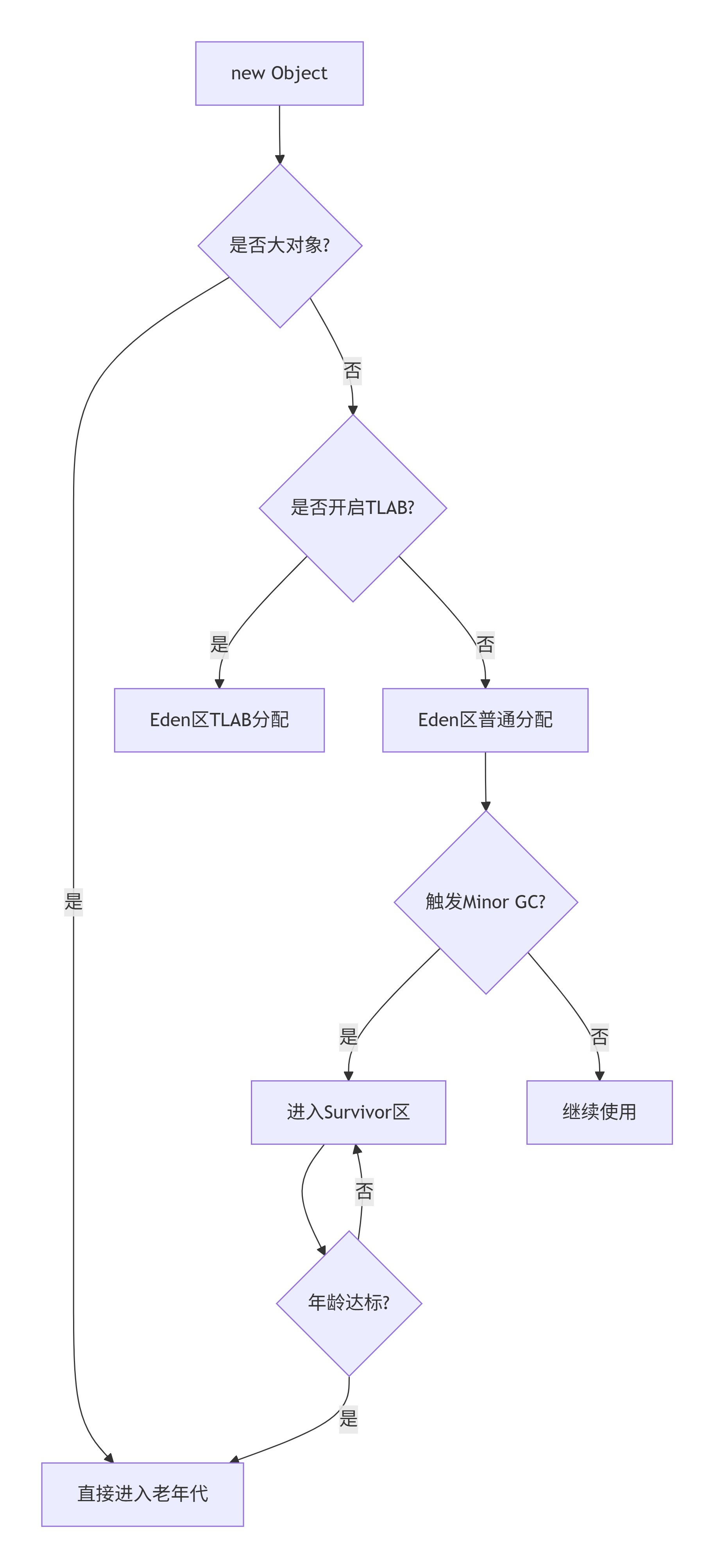
3.3 逃逸分析与栈上分配
逃逸分析三种情况:
// 1. 无逃逸(可栈上分配)
public void noEscape() {
Object obj = new Object(); // 对象不离开方法
}
// 2. 方法逃逸(作为参数传递)
public void methodEscape() {
Object obj = new Object();
externalMethod(obj); // 传递给其他方法
}
// 3. 线程逃逸(被其他线程访问)
public void threadEscape() {
Object obj = new Object();
new Thread(() -> use(obj)).start(); // 跨线程使用
}栈上分配性能对比:
public class StackAllocationDemo {
public static void main(String[] args) {
long start = System.currentTimeMillis();
for (int i = 0; i < 10_000_000; i++) {
allocate(); // 1000万次对象创建
}
System.out.println("耗时: " + (System.currentTimeMillis() - start) + "ms");
}
static void allocate() {
User user = new User(); // 不逃逸对象
user.setId(1);
user.setName("test");
}
}
// 测试结果:
// -XX:+DoEscapeAnalysis -XX:+EliminateAllocations: 约5ms(栈上分配)
// -XX:-DoEscapeAnalysis -XX:-EliminateAllocations: 约2000ms(堆上分配)3.4 对象内存布局解析
使用JOL(Java Object Layout)工具分析:
<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-core</artifactId>
<version>0.16</version>
</dependency>// 分析对象内存布局
System.out.println(ClassLayout.parseInstance(new Object()).toPrintable());64位系统对象头结构(开启指针压缩):
|-------------------------------------------------| | Mark Word (8字节) - 哈希码/锁状态/GC年龄 | |-------------------------------------------------| | Klass Pointer (4字节) - 指向类元数据 | |-------------------------------------------------| | 实例数据 (根据字段类型) | |-------------------------------------------------| | 对齐填充 (保证8字节对齐) | |-------------------------------------------------|
四、JVM执行引擎:从字节码到机器码
4.1 解释执行 vs 编译执行
解释执行(Interpreter)
-
工作方式:逐条翻译字节码
-
优点:启动快,内存占用小
-
缺点:执行效率低
-
适用场景:客户端应用、嵌入式系统
JIT编译执行(Just-In-Time)
-
工作方式:热点代码提前编译缓存
-
优点:执行效率高
-
缺点:预热慢,占用更多内存
-
核心组件:CodeCache
4.2 分层编译:C1与C2的完美配合
HotSpot采用5层分层编译:
| 层级 | 编译器 | 优化级别 | 监控信息 |
|---|---|---|---|
| 0 | 解释器 | 无优化 | 无监控 |
| 1 | C1 | 简单优化 | 无监控 |
| 2 | C1 | 有限优化 | 方法/回边计数 |
| 3 | C1 | 完全优化 | 完整监控 |
| 4 | C2 | 激进优化 | 基于监控优化 |
C1与C2对比:
-
C1(客户端编译器):编译快,优化保守,适合桌面应用
-
C2(服务端编译器):编译慢,优化激进,适合服务器应用
4.3 热点代码识别机制
1. 方法调用计数器
-
统计方法调用次数
-
默认阈值:10000次(
-XX:CompileThreshold)
2. 回边计数器
-
统计循环执行次数
-
默认阈值:10700次(服务端模式)
-
触发OSR(栈上替换)编译
4.4 后端编译优化技术
1. 方法内联(Method Inlining)
// 优化前
public int calculate(int a, int b) {
return add(a, b);
}
private int add(int x, int y) {
return x + y; // 方法调用开销
}
// 内联优化后(逻辑等效)
public int calculate(int a, int b) {
return a + b; // 直接计算,无调用开销
}内联优化参数:
bash
-XX:+Inline # 启用内联(默认开启)
-XX:MaxInlineSize=35 # 内联方法最大字节数
-XX:FreqInlineSize=325 # 热点方法内联阈值
-XX:+PrintInlining # 打印内联决策2. 锁消除(Lock Elision)
public String concat(String s1, String s2) {
StringBuffer sb = new StringBuffer(); // StringBuffer有synchronized锁
sb.append(s1);
sb.append(s2);
return sb.toString();
}
// 单线程环境下,JIT会消除StringBuffer的锁
// 性能接近StringBuilder3. 标量替换(Scalar Replacement)
// 原始对象
class Point {
int x;
int y;
}
// 使用后标量替换
public void method() {
Point p = new Point();
p.x = 10;
p.y = 20;
System.out.println(p.x + p.y);
// 标量替换后(逻辑等效)
int x = 10;
int y = 20;
System.out.println(x + y); // 无需创建Point对象
}五、垃圾收集器深度解析
5.1 垃圾收集算法三大流派
1. 标记-清除(Mark-Sweep)
-
过程:标记存活对象 → 清除未标记对象
-
优点:实现简单
-
缺点:内存碎片,效率问题
2. 标记-整理(Mark-Compact)
-
过程:标记存活对象 → 向一端移动 → 清理边界外
-
优点:无内存碎片
-
缺点:移动对象开销大
3. 复制算法(Copying)
-
过程:内存分两块 → 存活对象复制到另一块 → 清空原块
-
优点:无碎片,高效
-
缺点:内存利用率低(只能使用一半)
-
应用:新生代(Eden:Survivor = 8:1:1)
5.2 经典垃圾收集器详解
Serial收集器(-XX:+UseSerialGC)
-
特点:单线程,STW(Stop-The-World)
-
算法:新生代复制,老年代标记-整理
-
适用场景:客户端应用,小内存
Parallel Scavenge收集器(-XX:+UseParallelGC)
-
特点:多线程,吞吐量优先
-
算法:新生代复制,老年代标记-整理
-
适用场景:后台计算,批量处理
-
JDK8默认收集器
ParNew收集器(-XX:+UseParNewGC)
-
特点:Parallel的多线程版本,可与CMS配合
-
算法:新生代复制
-
适用场景:与CMS搭配使用
CMS收集器(-XX:+UseConcMarkSweepGC)
-
特点:并发收集,低停顿
-
算法:标记-清除
-
四阶段工作流程:

CMS核心参数:
bash
-XX:+UseConcMarkSweepGC # 启用CMS
-XX:CMSInitiatingOccupancyFraction=92 # 老年代92%触发GC
-XX:+UseCMSCompactAtFullCollection # FullGC后压缩
-XX:CMSFullGCsBeforeCompaction=3 # 3次FullGC后压缩一次
-XX:+CMSScavengeBeforeRemark # 重新标记前Minor GC5.3 三色标记算法与读写屏障
三色标记定义
-
白色:未被访问的对象(待回收)
-
灰色:已被访问,但引用未扫描完
-
黑色:已被访问,且所有引用已扫描
并发标记的漏标问题
// 并发标记期间,引用关系可能变化导致漏标
A.b.d = null; // 断开引用
A.d = d; // 建立新引用
// 如果没有处理,对象d可能被误回收解决方案:读写屏障
写屏障实现(以CMS的增量更新为例):
void oop_field_store(oop* field, oop new_value) {
// 写前屏障:记录旧引用(SATB)
pre_write_barrier(field);
// 赋值操作
*field = new_value;
// 写后屏障:记录新引用(增量更新)
post_write_barrier(field, new_value);
}不同收集器的屏障策略:
-
CMS:写屏障 + 增量更新
-
G1/Shenandoah:写屏障 + SATB(原始快照)
-
ZGC:读屏障
5.4 记忆集与卡表
解决跨代引用问题
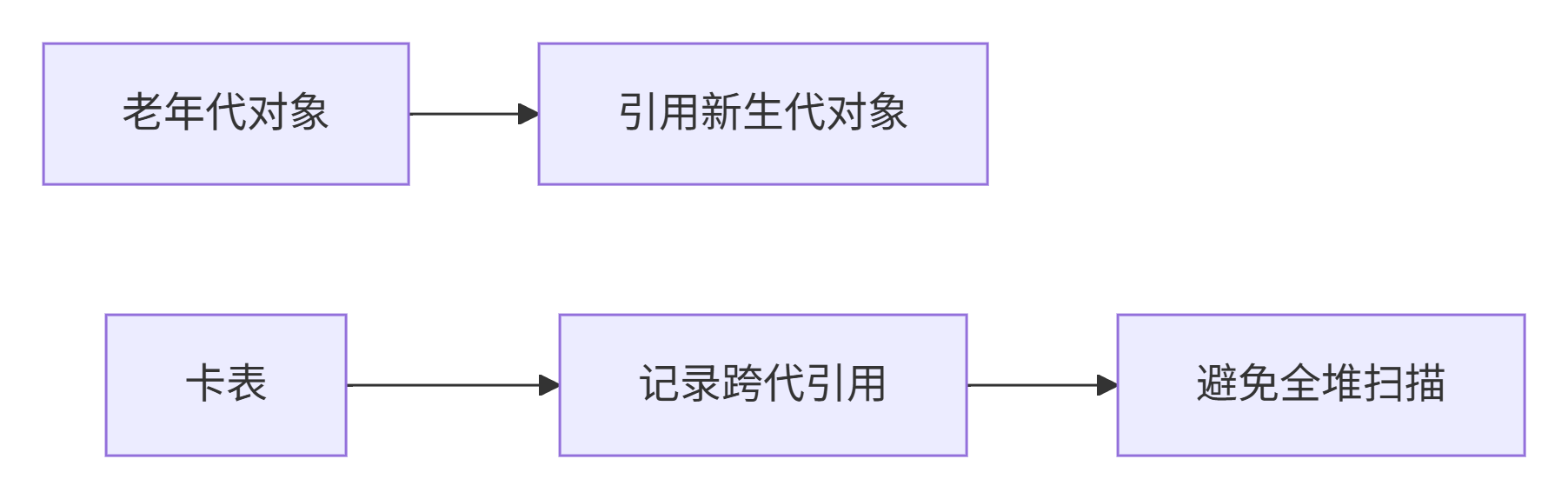
卡表工作原理:
-
将堆内存划分为512字节的卡页
-
每个卡页对应卡表中的一个字节
-
跨代引用时,对应卡表项标记为"脏"
-
GC时只扫描脏卡页,大幅减少扫描范围
六、亿级电商系统JVM调优实战
6.1 系统背景分析
亿级流量电商平台 ├── 日活用户:500万 ├── 付费转化率:10% ├── 日均订单:50万单 ├── 大促峰值:1000+单/秒 └── 日常流量:几十单/秒
6.2 内存需求计算
// 每秒内存消耗估算
订单对象:300单/秒 × 1KB = 300KB/秒
关联对象:300KB × 20倍 = 6MB/秒 // 库存、优惠等
其他操作:6MB × 10倍 = 60MB/秒 // 查询等
结论:系统峰值期每秒产生约60MB对象6.3 JVM参数优化配置
基础配置(8G内存服务器)
bash
# 堆内存配置
-Xms3072M -Xmx3072M # 堆大小3G,避免动态扩容
-Xmn2048M # 新生代2G,给足空间
-Xss1M # 线程栈1M
# 元空间配置
-XX:MetaspaceSize=256M -XX:MaxMetaspaceSize=256M
# 新生代比例
-XX:SurvivorRatio=8 # Eden:S0:S1 = 8:1:1垃圾收集器选择
bash
# ParNew + CMS组合(低停顿)
-XX:+UseParNewGC # 新生代ParNew
-XX:+UseConcMarkSweepGC # 老年代CMS
# CMS优化参数
-XX:CMSInitiatingOccupancyFraction=92 # 92%触发GC
-XX:+UseCMSCompactAtFullCollection # FullGC后压缩
-XX:CMSFullGCsBeforeCompaction=3 # 3次压缩一次
-XX:+CMSScavengeBeforeRemark # 重新标记前Minor GC对象晋升策略优化
bash
# 对象年龄阈值(默认15改小)
-XX:MaxTenuringThreshold=5 # 5次Minor GC后进老年代
# 大对象直接进老年代
-XX:PretenureSizeThreshold=1M # 1MB以上对象直接进老年代6.4 Full GC优化策略
避免频繁Full GC的关键
-
增大新生代:让对象尽可能在新生代回收
-
调整年龄阈值:避免短期对象过早进入老年代
-
合理设置CMS触发阈值:避免老年代过早填满
-
监控对象动态年龄:避免Survivor区过快填满
监控与诊断
bash
# GC日志输出
-XX:+PrintGCDetails # 打印GC详细信息
-XX:+PrintGCDateStamps # 打印GC时间戳
-Xloggc:/path/to/gc.log # GC日志文件
# 使用工具分析
# 1. jstat实时监控
jstat -gcutil <pid> 1000 10
# 2. jmap堆转储分析
jmap -dump:format=b,file=heap.bin <pid>
# 3. 在线分析工具
# https://gceasy.io/ # 上传GC日志自动分析七、JVM学习路径与最佳实践
7.1 系统性学习路径
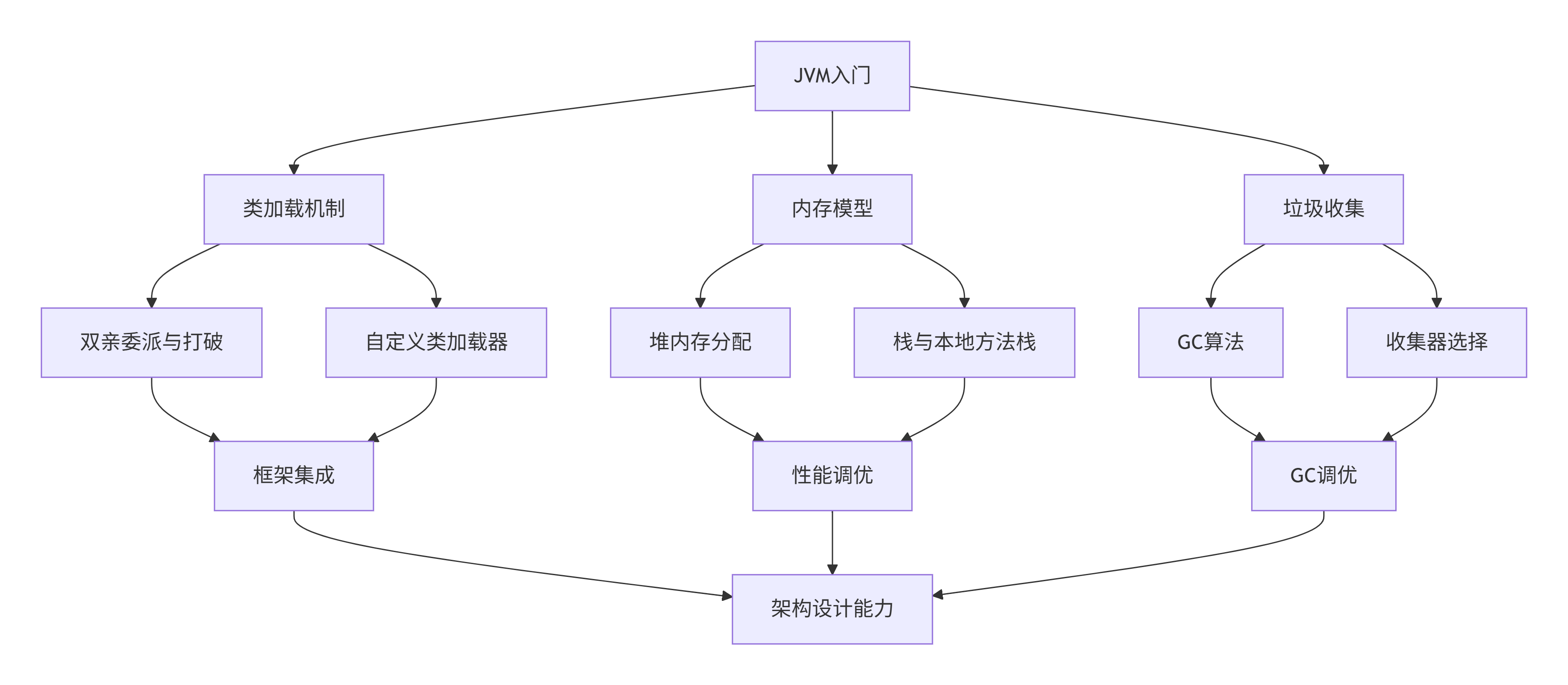
7.2 编码最佳实践
1. 内存使用优化
// 避免:大对象频繁创建
List<String> hugeList = new ArrayList<>(1000000); // 一次性分配
// 推荐:对象复用
private static final ThreadLocal<SimpleDateFormat> formatter =
ThreadLocal.withInitial(() -> new SimpleDateFormat("yyyy-MM-dd"));2. 减少GC压力
// 避免:不必要的对象创建
for (int i = 0; i < list.size(); i++) {
String key = "prefix_" + i; // 每次循环创建新String
map.put(key, value);
}
// 推荐:重用对象或使用StringBuilder
StringBuilder sb = new StringBuilder();
for (int i = 0; i < list.size(); i++) {
sb.setLength(0);
sb.append("prefix_").append(i);
map.put(sb.toString(), value);
}3. 合理使用并发
// 使用线程局部变量避免竞争
private static final ThreadLocal<Random> random =
ThreadLocal.withInitial(Random::new);
public int getRandom() {
return random.get().nextInt(); // 无竞争,高性能
}7.3 监控与调优工具箱
| 工具 | 用途 | 使用场景 |
|---|---|---|
| jps | 查看Java进程 | 快速定位目标进程 |
| jstat | 实时监控GC | 性能分析,问题诊断 |
| jmap | 堆转储分析 | 内存泄漏分析 |
| jstack | 线程转储 | 死锁、CPU高问题 |
| jinfo | 查看JVM参数 | 参数验证 |
| VisualVM | 图形化监控 | 综合性分析 |
| Arthas | 在线诊断 | 生产环境问题排查 |
| MAT | 堆转储分析 | 内存泄漏深度分析 |
7.4 生产环境JVM参数模板
bash
# 通用服务器配置(8-16G内存)
-Xms4g -Xmx4g # 堆大小,生产环境设置相同值
-Xmn2g # 新生代大小,占总堆1/2到2/3
-Xss512k # 线程栈大小,根据并发数调整
# 元空间配置
-XX:MetaspaceSize=256m -XX:MaxMetaspaceSize=256m
# GC配置(根据业务选择)
## 吞吐量优先(后台计算)
-XX:+UseParallelGC -XX:+UseParallelOldGC
-XX:ParallelGCThreads=4
## 低延迟优先(Web服务)
-XX:+UseParNewGC -XX:+UseConcMarkSweepGC
-XX:CMSInitiatingOccupancyFraction=75
-XX:+UseCMSInitiatingOccupancyOnly
-XX:+CMSScavengeBeforeRemark
# 日志与监控
-XX:+PrintGCDetails -XX:+PrintGCDateStamps
-XX:+PrintTenuringDistribution
-Xloggc:/logs/gc-%t.log
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/logs/heapdump.hprof
# 其他优化
-XX:+UseCompressedOops # 指针压缩(默认开启)
-XX:+UseCompressedClassPointers # 类指针压缩
-XX:+AlwaysPreTouch # 启动时预分配内存八、总结:从程序员到架构师的JVM之旅
通过本文的系统性梳理,我们完成了从JVM基础概念到高级调优的完整旅程:
8.1 核心收获
-
理解Java跨平台本质:JVM是Java生态的基石
-
掌握类加载机制:从双亲委派到热加载实战
-
深入内存管理:对象创建、分配、回收全流程
-
优化执行性能:JIT编译、分层优化、热点代码
-
精通垃圾收集:算法、收集器、调优实战
-
构建调优能力:从参数配置到生产问题排查