摘要
本文将详细介绍一个基于LangChain和Qwen模型的智能体项目,该项目能够自动化操作以RuoYi为实例。通过Playwright浏览器自动化技术,结合自定义工具,实现用户管理、表格导出、页面导航等功能的智能化操作。
项目结构
本项目主要包含以下几个核心文件:
agent.py- 智能体核心逻辑tools.py- 自定义工具集browser.py- 浏览器管理模块run.py- 主运行脚本
效果如下
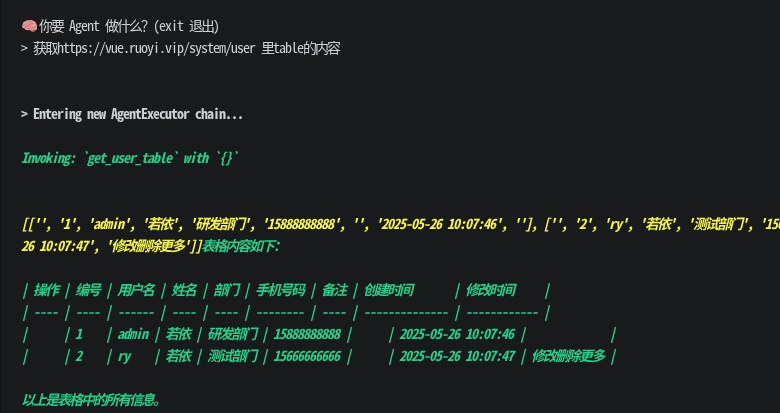
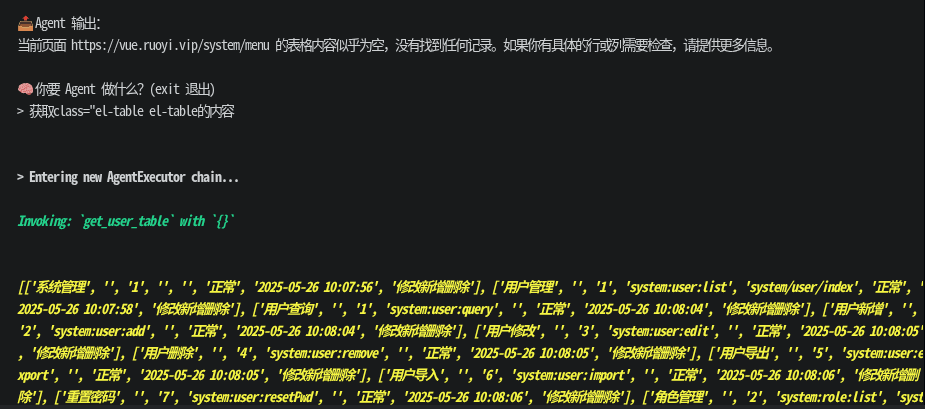
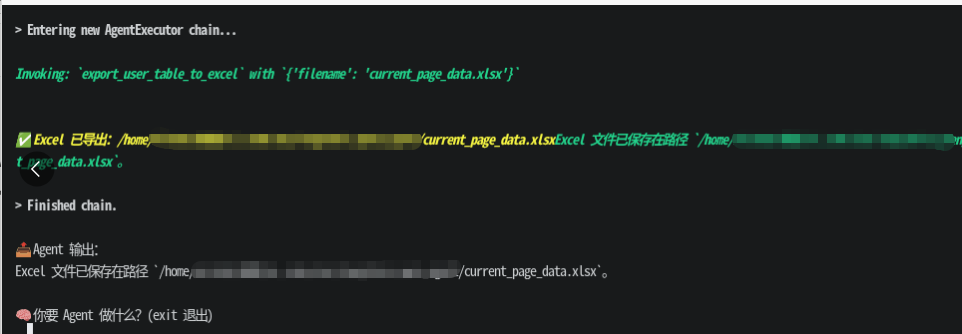
1. 浏览器管理模块 (browser.py)
python
# browser.py
from playwright.sync_api import sync_playwright
_playwright = None
_browser = None
_context = None
_page = None
def get_page():
global _playwright, _browser, _context, _page
if _page is None:
_playwright = sync_playwright().start()
_browser = _playwright.chromium.launch(
headless=False,
slow_mo=200
)
_context = _browser.new_context()
_page = _context.new_page()
return _page功能说明
- 使用Playwright库管理浏览器实例
- 采用单例模式,确保整个程序运行期间只有一个浏览器实例
slow_mo=200参数让操作更慢,便于观察
2. 自定义工具集 (tools.py)
2.1 页面跳转工具
python
@tool
def goto(url: str) -> str:
"""
跳转到指定 URL(保持当前登录态)
"""
page = get_page()
page.goto(url)
return f"已打开页面:{url}"2.2 等待工具
python
@tool
def wait(seconds: int) -> str:
"""等待指定秒数(用于人工输入验证码)"""
time.sleep(seconds)
return f"已等待 {seconds} 秒"2.3 文本获取工具
python
@tool
def get_text(selector: str) -> str:
"""获取页面中某个 selector 的文本内容"""
page = get_page()
el = page.query_selector(selector)
if not el:
return "未找到该元素"
return el.inner_text().strip()2.4 文本查找工具
python
@tool
def find_text(keyword: str) -> str:
"""查找页面中包含指定文字的内容"""
page = get_page()
return page.evaluate("""
(keyword) => {
const walker = document.createTreeWalker(
document.body,
NodeFilter.SHOW_ELEMENT
);
let node;
while (node = walker.nextNode()) {
if (node.innerText && node.innerText.includes(keyword)) {
return node.innerText.trim();
}
}
return null;
}
""", keyword) or "未找到"2.5 表格数据获取工具
python
@tool
def get_user_table() -> list:
"""获取 RuoYi 用户管理页面 el-table 数据"""
page = get_page()
return page.evaluate("""
() => {
const table = document.querySelector(
'.el-table__body-wrapper table.el-table__body'
);
if (!table) return [];
return Array.from(table.querySelectorAll('tbody tr')).map(row =>
Array.from(row.querySelectorAll('td')).map(td =>
td.innerText.trim()
)
);
}
""")2.6 表格表头获取工具
python
@tool
def get_table_headers() -> list:
"""
自动获取 Element-UI 表格表头(el-table)
"""
page = get_page()
headers = page.evaluate("""
() => {
const headerTable = document.querySelector(
'.el-table__header-wrapper table.el-table__header'
);
if (!headerTable) return [];
const ths = headerTable.querySelectorAll('thead th');
return Array.from(ths).map(th => {
const cell = th.querySelector('.cell');
return cell ? cell.innerText.trim() : th.innerText.trim();
});
}
""")
return headers2.7 Excel导出工具
python
@tool
def export_user_table_to_excel(filename: str = "") -> str:
"""
自动解析 el-table 表头 + 数据,并导出为 Excel
"""
page = get_page()
result = page.evaluate("""
() => {
const headerTable = document.querySelector(
'.el-table__header-wrapper table.el-table__header'
);
const bodyTable = document.querySelector(
'.el-table__body-wrapper table.el-table__body'
);
if (!headerTable || !bodyTable) {
return { headers: [], rows: [] };
}
const headers = Array.from(
headerTable.querySelectorAll('thead th')
).map(th => {
const cell = th.querySelector('.cell');
return cell ? cell.innerText.trim() : th.innerText.trim();
});
const rows = Array.from(
bodyTable.querySelectorAll('tbody tr')
).map(row =>
Array.from(row.querySelectorAll('td')).map(td =>
td.innerText.trim()
)
);
return { headers, rows };
}
""")
headers = result["headers"]
rows = result["rows"]
if not rows:
return "❌ 未获取到表格数据,导出失败"
if not filename:
filename = f"ruoyi_users_{datetime.now().strftime('%Y%m%d_%H%M%S')}.xlsx"
wb = Workbook()
ws = wb.active
ws.title = "用户管理"
# ✅ 自动 headers
if headers:
ws.append(headers)
for row in rows:
ws.append(row)
wb.save(filename)
return f"✅ Excel 已导出:{os.path.abspath(filename)}"2.8 点击工具
python
@tool
def click_text(text: str) -> str:
"""
点击页面中【可见】的指定文字(通用点击)
示例:点击"导出"、点击"用户管理"、点击"修改"
"""
page = get_page()
try:
locator = page.get_by_text(text, exact=False).first
locator.wait_for(timeout=5000)
locator.click()
return f"✅ 已点击文字:{text}"
except TimeoutError:
return f"❌ 页面中未找到可点击文字:{text}"
except Exception as e:
return f"❌ 点击失败:{str(e)}"2.9 分页工具
python
@tool
def jump_to_page(page_no: int) -> str:
"""
跳转到 Element-UI 分页组件中的指定页码。
通过"前往页"输入框输入页码并回车。
"""
page = get_page()
print("🔥 jump_to_page 被执行了")
editor = page.locator(".el-pagination__editor input")
editor.wait_for(timeout=5000)
editor.fill(str(page_no))
editor.press("Enter")
return f"✅ 已跳转到第 {page_no} 页"2.10 分页大小设置工具
python
@tool
def set_page_size(size: int) -> str:
"""
设置 Element-UI 分页组件的每页显示条数(如 10 / 20 / 50)
"""
page = get_page()
print(f"🔥 设置每页 {size} 条")
# 1️⃣ 点击 el-select(条数选择框)
select = page.locator(".el-pagination__sizes .el-select")
select.wait_for(timeout=5000)
select.click()
# 2️⃣ 等下拉框出现
dropdown_item = page.locator(
f".el-select-dropdown__item span:text('{size}条/页')"
)
dropdown_item.wait_for(timeout=5000)
# 3️⃣ 点击对应条数
dropdown_item.click()
# 4️⃣ 等表格刷新(非常重要)
page.wait_for_timeout(1500)
return f"✅ 已设置为 {size} 条/页"完整代码
# tools.py
from langchain_core.tools import tool
from browser import get_page
import os
from openpyxl import Workbook
from datetime import datetime
import time
"""
RuoYi Vue 用户管理表格抓取(终极稳定版)
特点:
- 人工登录
- 进入 /system/user
- 在浏览器上下文直接解析 el-table
- 规避 Vue 重绘 / locator 失效问题
- 浏览器不关闭
"""
@tool
def goto(url: str) -> str:
"""
跳转到指定 URL(保持当前登录态)
"""
page = get_page()
page.goto(url)
return f"已打开页面:{url}"
@tool
def wait(seconds: int) -> str:
"""等待指定秒数(用于人工输入验证码)"""
time.sleep(seconds)
return f"已等待 {seconds} 秒"
@tool
def get_text(selector: str) -> str:
"""获取页面中某个 selector 的文本内容"""
page = get_page()
el = page.query_selector(selector)
if not el:
return "未找到该元素"
return el.inner_text().strip()
@tool
def find_text(keyword: str) -> str:
"""查找页面中包含指定文字的内容"""
page = get_page()
return page.evaluate("""
(keyword) => {
const walker = document.createTreeWalker(
document.body,
NodeFilter.SHOW_ELEMENT
);
let node;
while (node = walker.nextNode()) {
if (node.innerText && node.innerText.includes(keyword)) {
return node.innerText.trim();
}
}
return null;
}
""", keyword) or "未找到"
@tool
def get_user_table() -> list:
"""获取 RuoYi 用户管理页面 el-table 数据"""
page = get_page()
return page.evaluate("""
() => {
const table = document.querySelector(
'.el-table__body-wrapper table.el-table__body'
);
if (!table) return [];
return Array.from(table.querySelectorAll('tbody tr')).map(row =>
Array.from(row.querySelectorAll('td')).map(td =>
td.innerText.trim()
)
);
}
""")
@tool
def get_table_headers() -> list:
"""
自动获取 Element-UI 表格表头(el-table)
"""
page = get_page()
headers = page.evaluate("""
() => {
const headerTable = document.querySelector(
'.el-table__header-wrapper table.el-table__header'
);
if (!headerTable) return [];
const ths = headerTable.querySelectorAll('thead th');
return Array.from(ths).map(th => {
const cell = th.querySelector('.cell');
return cell ? cell.innerText.trim() : th.innerText.trim();
});
}
""")
return headers
@tool
def export_user_table_to_excel(filename: str = "") -> str:
"""
自动解析 el-table 表头 + 数据,并导出为 Excel
"""
page = get_page()
result = page.evaluate("""
() => {
const headerTable = document.querySelector(
'.el-table__header-wrapper table.el-table__header'
);
const bodyTable = document.querySelector(
'.el-table__body-wrapper table.el-table__body'
);
if (!headerTable || !bodyTable) {
return { headers: [], rows: [] };
}
const headers = Array.from(
headerTable.querySelectorAll('thead th')
).map(th => {
const cell = th.querySelector('.cell');
return cell ? cell.innerText.trim() : th.innerText.trim();
});
const rows = Array.from(
bodyTable.querySelectorAll('tbody tr')
).map(row =>
Array.from(row.querySelectorAll('td')).map(td =>
td.innerText.trim()
)
);
return { headers, rows };
}
""")
headers = result["headers"]
rows = result["rows"]
if not rows:
return "❌ 未获取到表格数据,导出失败"
if not filename:
filename = f"ruoyi_users_{datetime.now().strftime('%Y%m%d_%H%M%S')}.xlsx"
wb = Workbook()
ws = wb.active
ws.title = "用户管理"
# ✅ 自动 headers
if headers:
ws.append(headers)
for row in rows:
ws.append(row)
wb.save(filename)
return f"✅ Excel 已导出:{os.path.abspath(filename)}"
@tool
def click_text(text: str) -> str:
"""
点击页面中【可见】的指定文字(通用点击)
示例:点击"导出"、点击"用户管理"、点击"修改"
"""
page = get_page()
try:
locator = page.get_by_text(text, exact=False).first
locator.wait_for(timeout=5000)
locator.click()
return f"✅ 已点击文字:{text}"
except TimeoutError:
return f"❌ 页面中未找到可点击文字:{text}"
except Exception as e:
return f"❌ 点击失败:{str(e)}"
@tool
def jump_to_page(page_no: int) -> str:
"""
跳转到 Element-UI 分页组件中的指定页码。
通过"前往页"输入框输入页码并回车。
"""
page = get_page()
print("🔥 jump_to_page 被执行了")
editor = page.locator(".el-pagination__editor input")
editor.wait_for(timeout=5000)
editor.fill(str(page_no))
editor.press("Enter")
return f"✅ 已跳转到第 {page_no} 页"
@tool
def set_page_size(size: int) -> str:
"""
设置 Element-UI 分页组件的每页显示条数(如 10 / 20 / 50)
"""
page = get_page()
print(f"🔥 设置每页 {size} 条")
# 1️⃣ 点击 el-select(条数选择框)
select = page.locator(".el-pagination__sizes .el-select")
select.wait_for(timeout=5000)
select.click()
# 2️⃣ 等下拉框出现
dropdown_item = page.locator(
f".el-select-dropdown__item span:text('{size}条/页')"
)
dropdown_item.wait_for(timeout=5000)
# 3️⃣ 点击对应条数
dropdown_item.click()
# 4️⃣ 等表格刷新(非常重要)
page.wait_for_timeout(1500)
return f"✅ 已设置为 {size} 条/页" 3. 智能体核心 (agent.py)
python
# agent.py
from langchain_ollama import ChatOllama
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_classic.agents import create_tool_calling_agent, AgentExecutor
from tools import (
goto,
wait,
get_text,
find_text,
get_user_table,
jump_to_page,
click_text,
export_user_table_to_excel,
set_page_size
)
tools = [goto, wait, get_text, find_text, get_user_table, jump_to_page, click_text, export_user_table_to_excel, set_page_size]
def create_qwen_agent():
llm = ChatOllama(
model="qwen2.5:7b",
base_url="http://localhost:11434",
temperature=0.7,
)
prompt = ChatPromptTemplate.from_messages([
("system", """
你是一个【浏览器自动化 RPA Agent】,不是聊天助手。
【全局规则(必须遵守)】
1. 浏览器已经处于【登录成功状态】,禁止任何登录行为
2. 不要填写账号、密码、验证码、短信、扫码
3. 不要刷新登录页或返回登录页
4. 所有操作都基于当前已登录的页面
5. 所有浏览器操作【只能】通过工具完成
6. 严禁描述 UI 行为或假装点击,必须真实执行
7. 用户的动作指令必须真实执行工具。
【点击规则】
- 普通点击(菜单 / 按钮 / 文本):
👉 优先使用 click_text
- 禁止自行推断 DOM 结构
- 禁止使用 find_text 来判断功能是否存在
【分页规则(非常重要)】
- "第N页 / 跳转到第N页 / 点击第N页" 属于【分页意图】
- 分页意图【禁止】使用 find_text 或 click_text
- 分页操作【只能】使用:
1️⃣ jump_to_page(page_no)
2️⃣ click_page_number(page_no)(仅当页码可见)
- 禁止通过 nth / index / class=number 点击分页
【表格 / 导出规则】
- "导出 / 表格 / Excel / 数据":
👉 不要点击页面上的"导出"按钮
👉 只能通过 export_user_table_to_excel 工具完成
- 表头必须从页面 DOM 自动解析,不允许硬编码
【分页大小规则】
- "10条/页 / 20条/页 / 50条/页" 属于【分页大小设置】
- 禁止 click_text
- 禁止 find_text
- 必须使用 set_page_size(size)
【行为约束】
- 不要解释页面结构
- 不要分析 UI 合理性
- 不要输出与执行无关的说明
- 用户指令 = 行为意图 → 选择正确工具 → 执行
你的目标是:
【稳定、可复现、可自动化】,而不是"像人一样解释页面"。
"""),
("placeholder", "{chat_history}"),
("human", "{input}"),
MessagesPlaceholder("agent_scratchpad"),
])
agent = create_tool_calling_agent(llm=llm, tools=tools, prompt=prompt)
return AgentExecutor(
agent=agent,
tools=tools,
verbose=True,
max_iterations=15,
)4. 主运行脚本 (run.py)
python
# run.py
from browser import get_page
from agent import create_qwen_agent
def main():
print("\n🌐 通用 RPA 启动器")
login_url = input("🔑 请输入登录页面 URL:\n> ").strip()
page = get_page()
page.goto(login_url)
print("\n👉 请在浏览器中【手动完成登录】")
print("👉 包括:账号 / 密码 / 验证码 / 短信 / 扫码等")
print("👉 登录成功后,在终端按 Enter\n")
input("⏎ 确认登录完成...")
print("✅ 已进入 Agent 接管模式\n")
agent = create_qwen_agent()
while True:
user_input = input("\n🧠 你要 Agent 做什么?(exit 退出)\n> ")
if user_input.lower() in ("exit", "quit"):
break
result = agent.invoke({"input": user_input})
print("\n📤 Agent 输出:")
print(result["output"])
if __name__ == "__main__":
main()6. 项目特点与优势
6.1 智能化操作
- 使用Qwen大模型理解用户意图
- 自动选择合适的工具执行操作
- 支持自然语言交互
6.2 稳定性保证
- 人工登录,规避验证码问题
- 工具化操作,避免DOM变化影响
- 专门的分页和表格处理逻辑
6.3 灵活性
- 支持多种页面操作
- 可扩展的工具系统
- 适用于多种后台管理系统
7. 使用方法
- 安装依赖:
pip install langchain-ollama playwright openpyxl - 启动Ollama服务:
ollama serve - 运行主程序:
python run.py - 手动完成登录后,即可使用自然语言控制浏览器
8. 总结
本项目展示了如何结合LangChain、Qwen模型和Playwright构建一个智能化的浏览器自动化系统。通过自定义工具集,实现了对RuoYi后台管理系统的高效操作,为自动化测试和数据提取提供了新的解决方案。
项目的核心优势在于将大模型的意图理解能力与精确的浏览器操作相结合,实现了真正的智能化RPA系统。