jmete变量提取常用方式
- 一、为什么需要变量提取?
- [二、JMeter 常用变量提取方式(按场景优先级排序)](#二、JMeter 常用变量提取方式(按场景优先级排序))
-
-
- [1. 正则表达式提取器(万能通用)](#1. 正则表达式提取器(万能通用))
- [2. JSON 提取器(JSON 格式专用,推荐)](#2. JSON 提取器(JSON 格式专用,推荐))
- [3. XPath 提取器(XML/HTML 专用)](#3. XPath 提取器(XML/HTML 专用))
- [4. 边界提取器(简单场景快速用)](#4. 边界提取器(简单场景快速用))
-
- 三、变量提取后的使用场景
-
-
- [1. 作为请求参数](#1. 作为请求参数)
- [2. 作为断言依据](#2. 作为断言依据)
- [3. 调试查看变量](#3. 调试查看变量)
-
- 四、扩展
一、为什么需要变量提取?
在接口自动化测试中,很多场景需要复用前置接口的返回数据:
-
登录接口返回的
token,需作为后续所有接口的请求头参数; -
列表接口返回的
商品ID,需传入详情接口查询具体信息; -
依赖接口的返回结果(如订单号),需作为断言依据或后续流程入参。
JMeter 提供了多种变量提取组件,可高效解决这类依赖问题。
二、JMeter 常用变量提取方式(按场景优先级排序)
1. 正则表达式提取器(万能通用)
适用于 所有返回格式 (HTML/JSON/XML/ 纯文本),最常用且灵活。
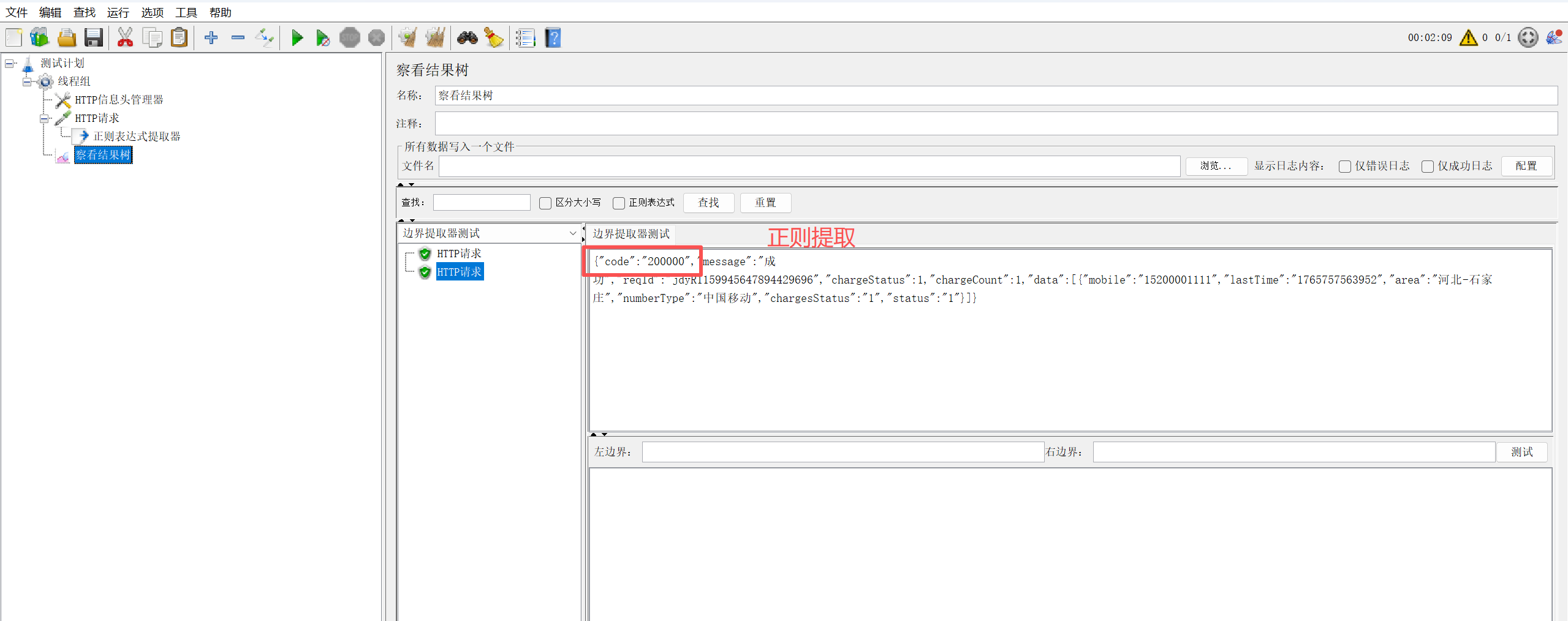
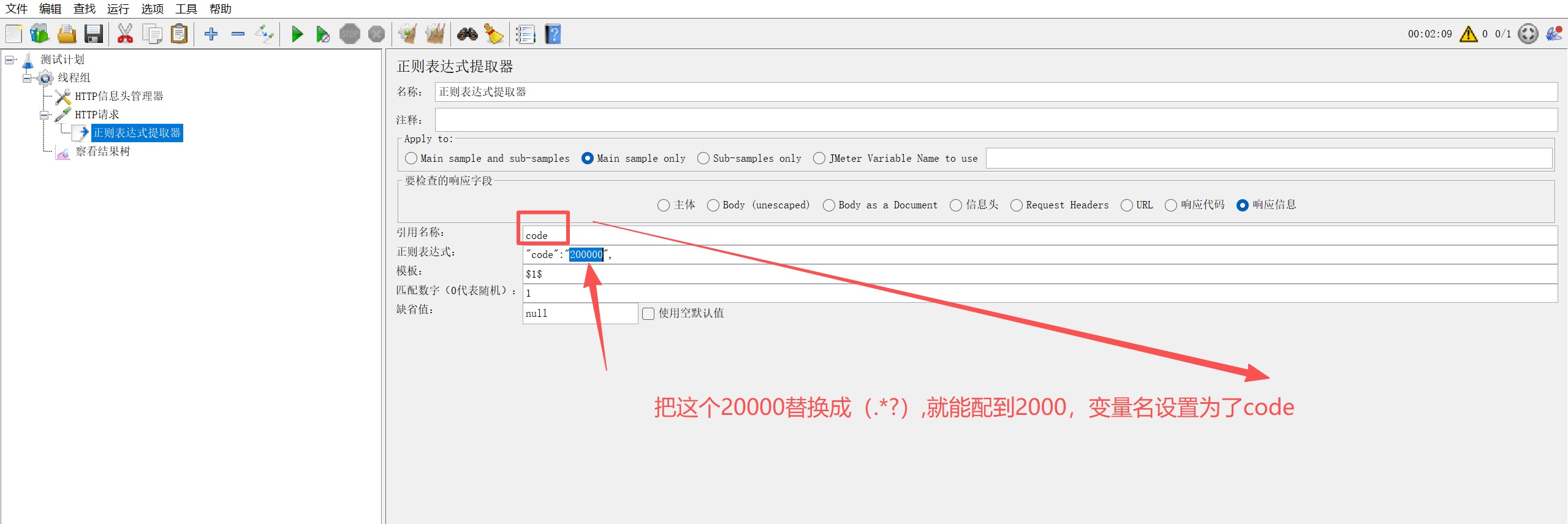
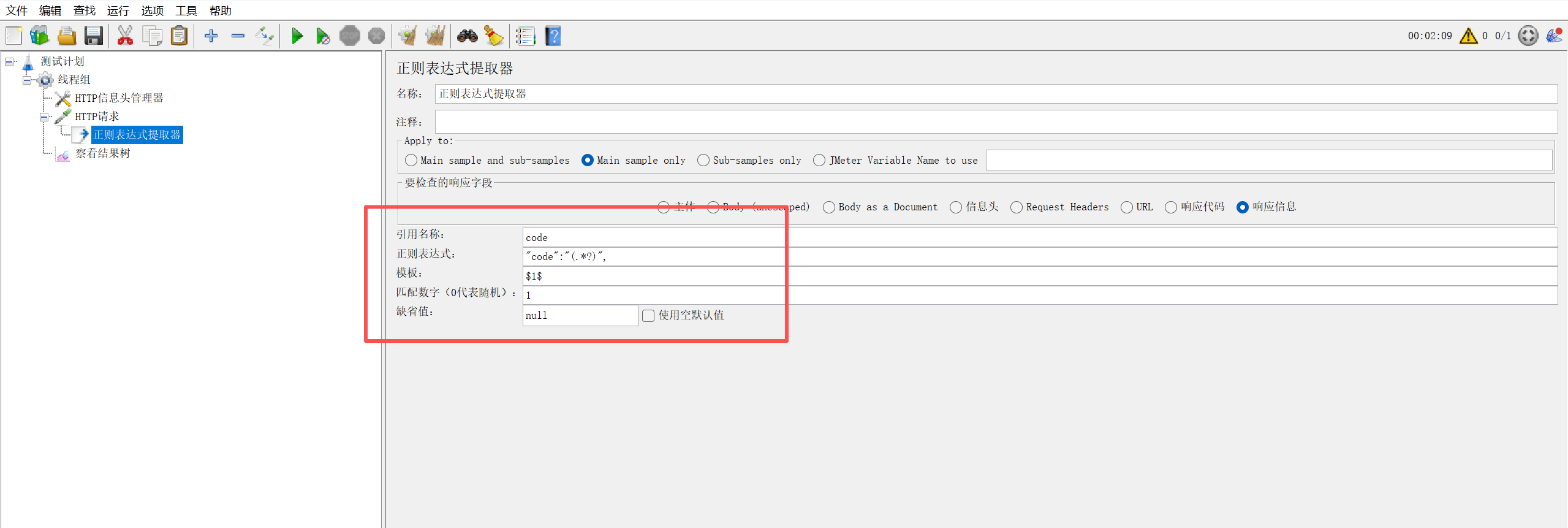
1.1 核心配置(添加路径:取样器 → 后置处理器 → 正则表达式提取器)
| 配置项 | 说明 |
|---|---|
| 引用名称 | 提取后变量的名称(如 code,后续用 ${code} 调用) |
| 正则表达式 | 匹配目标数据的表达式(关键!),格式:左边界(匹配内容)右边界 |
| 模板 | 取匹配结果的第 N 组,$1$ 取第一组,$2$ 取第二组(括号分组) |
| 匹配数字 | 0 = 随机取 1 个,1 = 取第一个,-1 = 取所有匹配结果(存为数组) |
| 缺省值 | 提取失败时的默认值(如 null,便于排查问题) |
1.2 实操案例(提取 JSON 中的 token)
-
接口返回示例:
{"code":200,"msg":"success","data":{"token":"eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9"}} -
正则表达式 :
"token":"(.*?)"左边界 :
"token":"匹配内容:
.*?(非贪婪匹配)右边界:
"():括起来的部分就是要提取的。
. :点匹配任何字符串。
*:代表匹配0个到多个字符
?:不要太贪婪,在找到第一个匹配项后停止。
-
模板:
$1$ -
调用方式:
${token}(如在请求头中添加Authorization: Bearer ${token})
1.3 正则表达式技巧
-
非贪婪匹配(优先用):
.*?(匹配到第一个右边界即停止,避免多匹配) -
固定长度匹配:
(.{32})(匹配 32 位字符,适用于 UUID/MD5 等固定长度字段) -
排除特殊字符:匹配数字 / 字母
([a-zA-Z0-9]+),匹配中文([\u4e00-\u9fa5]+)
1.4 关注点:正则表达式贪婪匹配导致多取数据
错误:"token":"(.*)"(匹配到最后一个 ",可能包含多余字符)
正确:"token":"(.*?)"(非贪婪匹配,优先取最近的边界)
1.5 特殊字符转义(如引号、括号)
- 正则中需转义特殊字符:
左边界\(匹配内容\)右边界(如匹配(token:abc),表达式为\(token:(.*?)\))
2. JSON 提取器(JSON 格式专用,推荐)
如果接口返回是 标准 JSON ,优先用 JSON 提取器(比正则更简洁、不易出错)
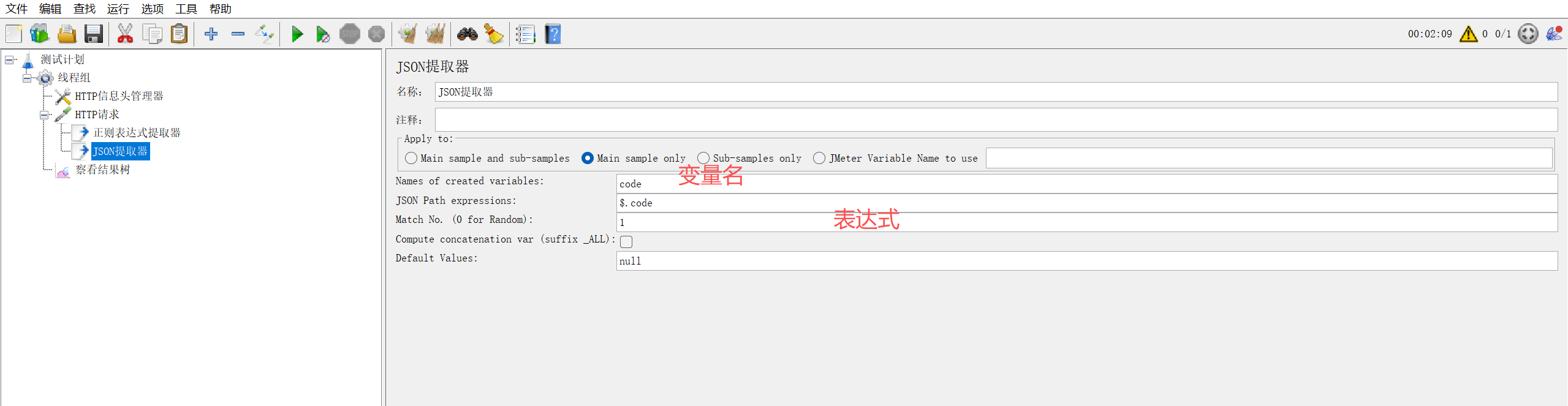
2.1 核心配置(添加路径:取样器 → 后置处理器 → JSON 提取器)
| 配置项 | 说明 |
|---|---|
| Names | 变量名(多个用分号分隔,如 token;userId) |
| JSON Path Expressions | JSON 路径表达式(多个用分号分隔,对应变量名) |
| Match Numbers | 0 = 随机,1 = 第一个,-1 = 所有(数组),与正则一致 |
| Default Values | 缺省值(多个用分号分隔,如 null;0) |
2.2 实操案例(提取 JSON 多字段)
-
返回示例同上(token + userId):
{"data":{"token":"xxx","userId":12345}} -
Names:
token;userId -
JSON Path Expressions:
$.data.token;$.data.userId($表示根节点,.层级访问) -
调用方式:
${token}、${userId}
2.3 JSON Path 常用语法
| 语法 | 说明 | 示例 |
|---|---|---|
$.key |
取根节点下的 key | $.code → 200 |
$.data[0] |
取数组第 1 个元素 | $.list[0].id → 第一个列表 ID |
$..key |
递归取所有层级的 key | $..token → 所有 token 值 |
2.4 关注点:JSON 提取器路径错误(层级漏写)
错误:$.token(实际 token 在 data 节点下)
正确:$.data.token(严格按 JSON 层级编写)
3. XPath 提取器(XML/HTML 专用)
适用于返回格式为 XML 或 HTML 的接口(如 SOAP 接口、网页接口)
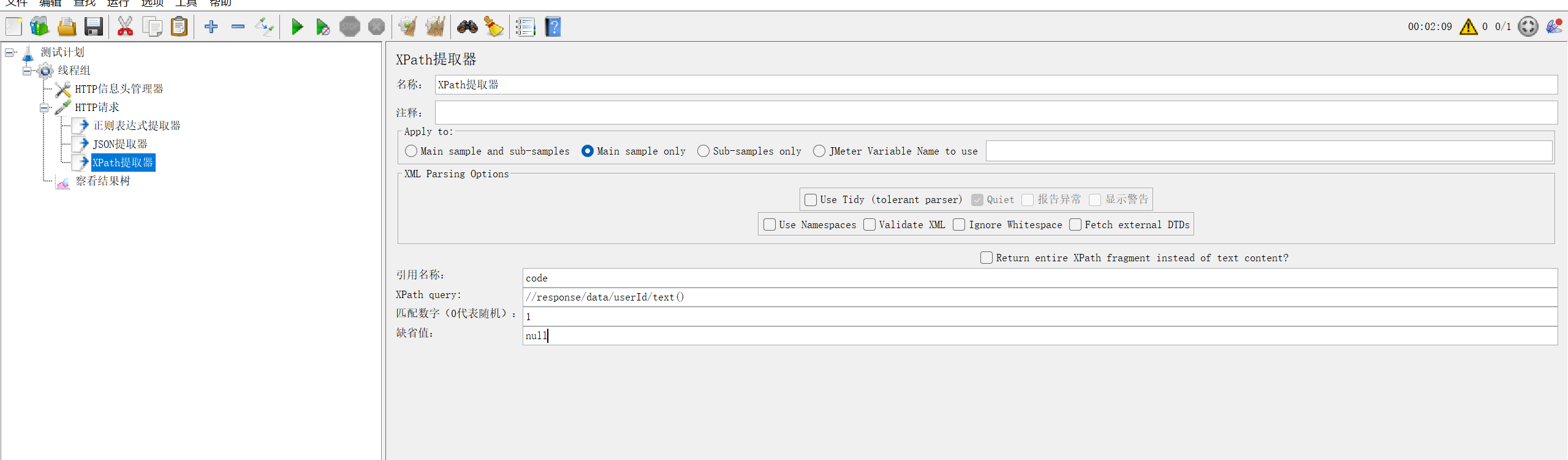
3.1 核心配置(添加路径:取样器 → 后置处理器 → XPath 提取器)
-
引用名称:变量名(如
userId) -
XPath 查询字符串:匹配 XML 节点的 XPath 表达式
-
匹配数字 / 缺省值:同正则提取器
3.2 实操案例(提取 XML 中的用户 ID)
-
接口返回示例:
</code>
<data>
>67890</userId>
</data>
-
XPath 表达式:
//response/data/userId/text()(//递归查找,text()取节点文本值) -
调用方式:
${userId}
4. 边界提取器(简单场景快速用)
适用于返回数据左右边界固定的简单场景(无需写正则,新手友好)。
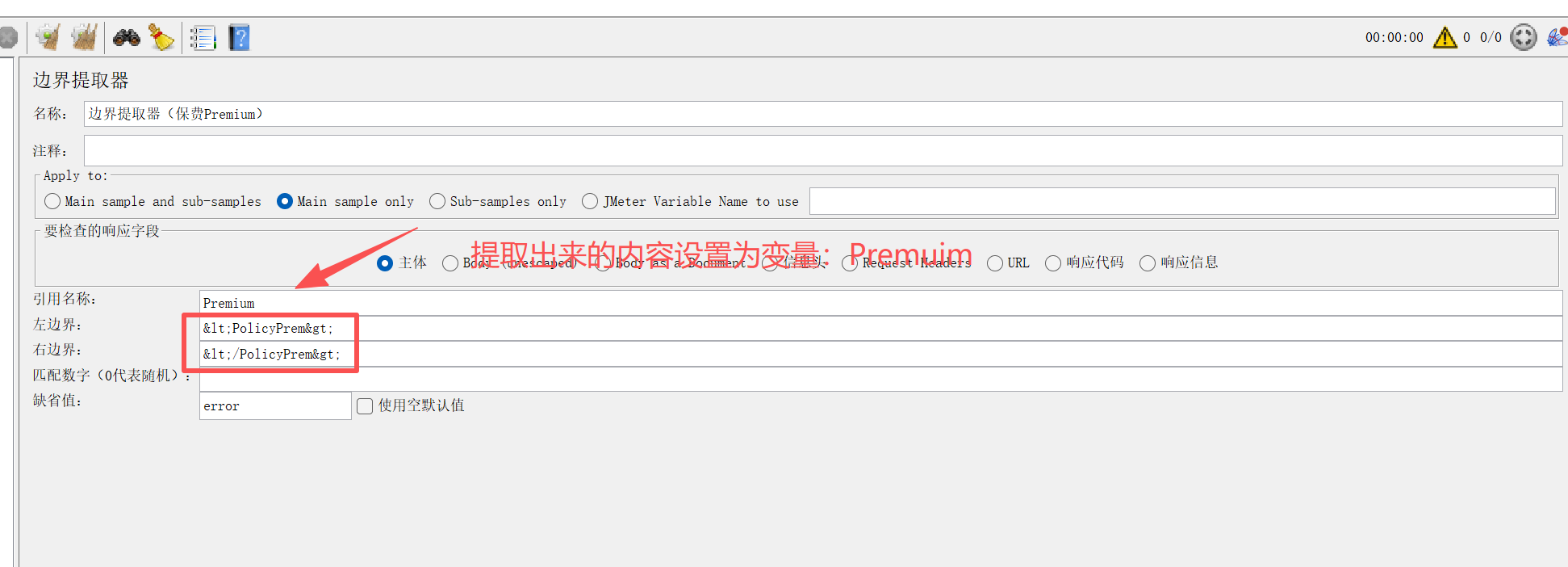
-
核心配置:只需填写「左边界」「右边界」,其他同正则提取器;
-
示例:提取
token=abc123;expire=3600中的 token,左边界token=,右边界;,直接提取abc123。
三、变量提取后的使用场景
1. 作为请求参数
-
路径参数:
/api/user/${userId}(详情接口用前置接口的 userId) -
请求头:
Authorization: ${token}(鉴权 token) -
请求体(JSON):
{"orderId":"${orderNo}"}(用前置接口返回的订单号)
2. 作为断言依据
-
添加「响应断言」,断言内容填写
${token}(验证 token 成功返回); -
断言表达式:
contains(响应数据, ${变量名})。
3. 调试查看变量
如果不确定变量是否提取成功,用以下两种方式验证:
-
添加「调试取样器」+「查看结果树」:调试取样器会显示所有提取的变量;
-
在「用户定义的变量」中引用,或通过「BeanShell 取样器」打印:
log.info("提取的 token:" + vars.get("token"));(日志在 JMeter 控制台查看)。
四、扩展
- 变量未提取成功却直接使用
-
原因:前置接口失败、提取表达式错误、匹配数字设置错误;
-
解决:设置合理的缺省值(如
extract_fail),通过调试取样器排查。
- 提取多个值时数组调用方式
-
当「匹配数字」设为 -1 时,变量会存为数组:
${token_1}(第一个值)、${token_2}(第二个值); -
数组长度:
${token_matchNr}(可用于循环遍历)。