2025年10月
BitNet 蒸馏(BitDistill)
Xun Wu、Shaohan Huang、Wenhui Wang、Ting Song、Li Dong、Yan Xia、Furu Wei†微软研究院https://aka.ms/GeneralAI
摘要
本文提出了 BitNet 蒸馏(BitDistill),这是一种轻量级流水线,可将现成的全精度大型语言模型(LLM,例如 Qwen)微调到 1.58 位精度(即三元权重 {-1, 0, 1}),以适配特定下游任务,在最小化计算成本的同时实现优异的任务特定性能。具体而言,BitDistill 整合了三项关键技术:BitNet 中提出的 SubLN 模块WMD+23;基于 MiniLMWBH+20的多头注意力蒸馏;以及持续预训练 ------ 该步骤作为关键预热环节,可缓解全精度微调模型与 1.58 位 LLM 在特定任务上的性能差距扩展性问题。实验结果表明,BitDistill 在不同模型规模下均能实现与全精度对应模型相当的性能,同时支持高达 10 倍的内存节省和 2.65 倍的 CPU 推理加速。代码已开源于github.com/microsoft/BitNet。
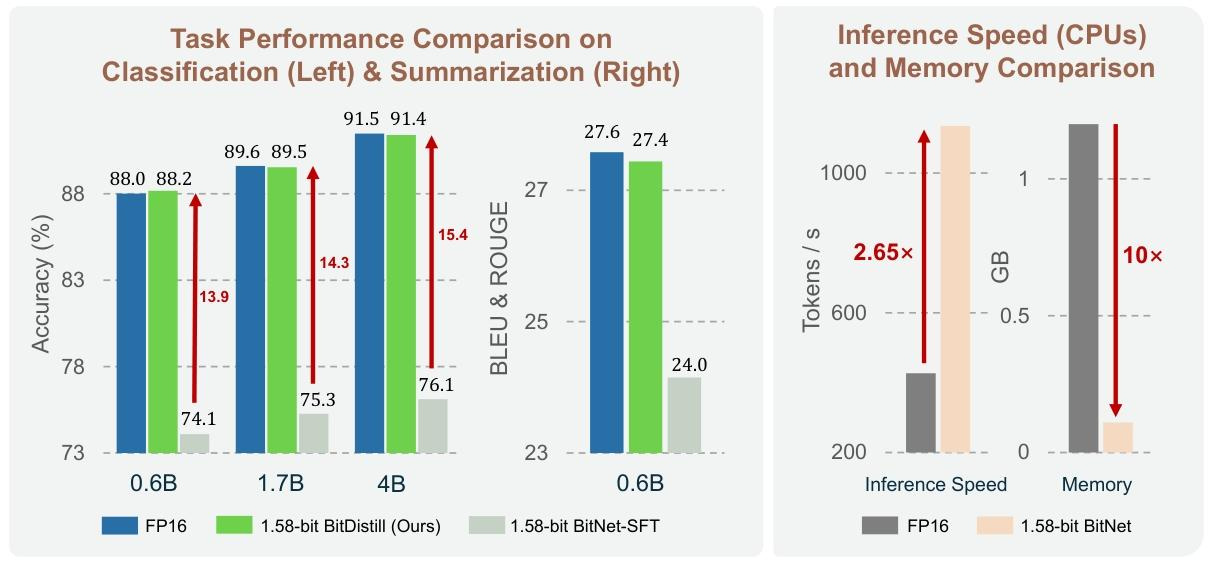
图 1:不同模型规模下下游任务性能,及推理速度和内存效率对比。我们观察到,将全精度 LLM 直接微调到 1.58 位 LLM(记为 1.58 位 BitNet-SFT)与 FP16 基线相比存在显著性能差距,且随着模型规模增大,该差距保持不变甚至扩大。相比之下,BitDistill 保持了良好的扩展性,在所有模型规模下都能实现与全精度模型相当的性能,同时减少 10 倍内存使用量,CPU 推理速度提升 2.65 倍。
†通讯作者。
1 引言
大型语言模型(LLM)AAA+23,GYZ+25不仅在推动通用自然语言处理发展方面变得不可或缺YLY+25,更重要的是,它为各类下游应用提供了强大支持,例如推荐系统WZQ+24,HZL+24,RWX+24、文本分类KDSP25,SLL+23和信息检索ZSB+24,BMH+22。尽管 LLM 应用广泛,但在下游应用中部署 LLM 仍面临巨大挑战。模型规模的快速增长进一步加剧了这些挑战,尤其是在资源受限设备(如智能手机)上,其内存消耗和计算开销均难以承受。
为应对这些挑战,近期针对极低位 LLM 的研究(例如 1.58 位(即三元值 {-1, 0, 1})的 BitNetMWM+24,MWH+25,WMD+23)旨在大幅减少内存占用并加速推理,为下游应用的高效部署提供了可行途径。然而,1.58 位 BitNet 要在下游应用中实现具有竞争力的精度,通常需要先在大规模语料库上从头预训练TXL+25,MWH+25,这会产生巨大的计算和能源开销。此外,如图 1 所示,将量化感知训练(QAT)DZC+24,CSX+24直接应用于现有全精度 LLM 以适配 1.58 位特定下游任务时,往往存在训练不稳定、无法完全保留全精度模型性能的问题,且扩展性较差:当模型规模从 0.6B 扩大到 4B 时,与全精度基线的性能差距从 13.9 扩大到 15.3。这凸显了亟需专门为 1.58 位 BitNet 设计更有效的 QAT 方法。
本研究聚焦于将现有 LLM 微调到 1.58 位以适配特定下游任务,同时实现与全精度模型相当的性能。为此,我们提出了 BitNet 蒸馏(BitDistill)------ 一种易于扩展的 QAT 框架,旨在弥合极低位 1.58 位量化与实际部署之间的差距。BitDistill 包含三个阶段:(i)利用 SubLN 模块WMD+23进行模型优化,以实现稳定训练;(ii)持续预训练,缓解与规模相关的性能差距;(iii)基于 MiniLMWWD+20,WBH+20的多头注意力蒸馏,恢复全精度模型的精度。
通过在四个基准数据集和不同模型规模上的广泛评估,我们证明 BitDistill 具有良好的扩展性,下游任务性能与全精度基线相当。同时,如图 1 所示,该方法实现了 10 倍内存节省和 2.65 倍 CPU 推理加速,在延迟、吞吐量、内存效率和能耗方面均有显著提升,特别适合部署在资源受限的硬件上。
2 预备知识
1.58 位量化
遵循MWM+24,我们采用基于绝对均值(absmean)函数的逐张量量化,将现有 LLM 的权重映射到三元值,即 {-1, 0, 1}:Qw(W)=ΔRoundClip(Δ+ϵWFP16,−1,1),(1)
符号表示最近邻舍入操作。对于 LLM 输入,我们采用 8 位激活量化。具体而言,使用逐 token 的绝对最大值(absmax)和绝对均值(absmean)函数对激活值进行量化,公式如下:QINTS(X)=127γRoundClip(γ+ϵ127XFP16,−128,127),γ=max(∣XFP16∣)
梯度近似
由于公式(2)和(3)中存在不可微操作(例如 RoundClip),反向传播过程中梯度无法在整个模型中传播。遵循MWM+24,MWH+25,WMD+23,我们采用直通估计器(STE)BLC13 为 1.58 位量化 LLM 近似梯度。
3 BitDistill:将 LLM 微调到 1.58 位 BitNet 以适配下游任务
本研究旨在解决资源受限设备上特定下游任务的 LLM 部署挑战。我们聚焦于以最小的性能损失和训练成本,将现有预训练 LLM 高效压缩为 1.58 位 BitNet。所提出的 BitNet 蒸馏(BitDistill)包含三个关键阶段:(1)利用 SubLNWMD+23进行模型优化,实现稳定训练(详见 3.1 节);(2)持续预训练,作为关键预热步骤,缓解全精度微调模型与 1.58 位 BitNet 之间性能扩展性不佳的问题(见 3.2 节);(3)蒸馏式微调,结合日志蒸馏和多头注意力蒸馏,恢复全精度模型性能(见 3.3 节)。
3.1 阶段 1:模型优化
与全精度模型不同,全精度模型在标准初始化方案下,隐藏态方差通常保持在稳定范围内,而 1.58 位 LLM 等低位量化模型往往存在激活方差过大的问题,导致训练不稳定和收敛效果不佳MWM+24,WMD+23。
为缓解这一问题,遵循先前 1.58 位 BitNetMWM+24,MWH+25的设计原则,我们在每个 Transformer 块内的关键位置引入名为 SubLN 的额外归一化层。具体而言,除了在块输入处应用预归一化外,我们还在多头自注意力(MHSA)模块的输出投影前以及前馈网络(FFN)的输出投影前插入 SubLN。以 Qwen3YLY+25为参考架构,第 l 层 Transformer 的计算修改如下:Yl=Xl+SubLN(Concat(heads))WoutMHSA,(4)Xl+1=Yl+SubLN((YlWupHN)⊙σ(YlWgateHN))WdownHN,其中heads={Softmax(dQiKi⊤)Vi∣Qi=XWQ,iMHSA,Ki=XWK,iMHSA,Vi=XWV,iMHSA},(6)
每个公式中的外层 SubLN 对应于在相应输出投影前新插入的归一化层。该设计确保进入量化投影层的隐藏表示方差稳定,避免激活规模爆炸,从而同时提升训练稳定性和任务性能。
3.2 阶段 2:持续预训练
如图 1 所示,将基于现有全精度 LLM 修改得到的 1.58 位 BitNet 直接在下游任务上微调,可能会得到次优结果 ------ 因为有限的训练 token 通常不足以将全精度权重有效适配到受限的 1.58 位表示中,导致扩展性不佳:随着模型规模增大,与全精度基线的性能差距会扩大。
为此,我们提出一种两阶段训练流水线:首先是持续训练阶段,仅利用少量预训练语料实现所需适配,随后在下游任务上进行微调。具体而言,给定小型语料库C=c1,⋯,cN,我们对 3.1 节得到的模型优化后的预训练 LLM 进行微调,损失函数如下:LCT=−N1∑i=1N∑t=1TilogPθ(ci,t∣ci,<<t).(7)
其中Pθ表示由模型参数化的概率分布。关于持续训练效果的详细分析,以及对其潜在机制和支持假设的研究,可参见 4.4 节。
3.3 阶段 3:蒸馏式微调
为更好地缓解精度降低带来的性能损失,我们在下游任务微调阶段融入两种知识蒸馏技术:以全精度微调 LLM 作为教师模型,其 1.58 位量化版本作为学生模型。
日志蒸馏(Logits Distillation)
日志蒸馏近年来已广泛应用于量化模型的 QAT 阶段,并展现出良好效果DZC+24,LSK+25,KKCY24。给定从下游数据集采样的数据对(xi,yi)i=1N,日志蒸馏的目标定义为:LLD=N1∑i=1NDKL(PθFP16(yi∣xi)∥Pθ1.58−bit(yi∣xi)),Pθ(⋅)(y∣x)=∑y′exp(zy′(x;θ)/τ)exp(zy(x;θ)/τ)
其中zy(x;θ)表示模型在输入 x 下为类别 y 生成的未归一化日志概率。引入温度参数τ以控制 FP16 模型和 1.58 位模型输出分布的平滑程度。DKL(⋅∥⋅)表示 KL 散度。
多头注意力蒸馏(Multi-Head Attention Distillation)
由于注意力机制在 LLM 中起着关键作用,且在很大程度上决定了模型的整体性能,我们进一步研究注意力层的蒸馏,以促使 1.58 位学生模型捕捉 FP16 教师模型注意力模式中蕴含的细粒度结构依赖关系。
遵循 MiniLM 系列 WBH+20, WWD+20,给定从下游数据集抽取的训练样本 x,我们定义注意力关系蒸馏损失LAD如下:A(⋅)∼Φ,Φ={Q,K,V},(10)LAD=∣Υ∣1∑i=1∣Υ∣∑j=1∣Φ∣αiAr∣x∣1∑a=1Ar∑t=1∣x∣DKL(Ri,j,a,tFP16∥Ri,j,a,t1.58−bit).
其中Φ对应多头注意力块中的查询(Q)、键(K)和值(V)投影,Υ表示选定用于蒸馏的层集合。αi是控制不同关系项相对权重的系数。|x | 表示序列长度,Ar是注意力头数量。关系分布Ri,j,a,t(⋅)通过缩放点积注意力和隐藏维度为dr的 Softmax 得到,而Ri,j,a,t1.58−bit则通过量化学生模型以类似方式获得,隐藏维度为dr′,即:Ri,j,a,tFP16=Softmax(drAi,j,a,tFP16Ai,j,a,tFP16⊤),Ri,j,a,t1.58−bit=Softmax(dr′Ai,j,a,t1.58−bitAi,j,a,t1.58−bit⊤).(12)
LAD的详细实现见算法 1。遵循 MiniLM WWD+20, WBH\^{+} 20,我们建议仅在单个层(即∣Υ∣=1)而非所有层上进行注意力蒸馏 ------ 这能为 1.58 位学生 BitNet 提供更大的训练灵活性,通常能获得更优的下游性能。
算法 1:LAD的 PyTorch 风格伪代码实现
python
运行
def compute_attention_distillation_loss(student_states, teacher_states, distill_layer, split_heads):
# student_states [3, B, num_heads, seq_len, head_dim]: 1.58位模型的Q、K、V状态
# teacher_states [3, B, num_heads, seq_len, head_dim]: FP16模型的Q、K、V状态
# distill_layer [1]: 用于蒸馏的层索引
# split_heads [1]: 计算注意力关系矩阵时的头数
D = heads * d // split_heads
# 遍历Q、K、V计算蒸馏损失
_, B, heads, L, d = student_states.shape
distill_loss = 0.0
for i in range(3):
s_values, t_values = student_states[i], teacher_states[i]
# 归一化并调整维度
s_values = F.normalize(s_values.transpose(1, 2).reshape(B, L, split_heads, D).transpose(1, 2), dim=-1)
t_values = F.normalize(t_values.transpose(1, 2).reshape(B, L, split_heads, D).transpose(1, 2), dim=-1)
# 计算关系矩阵
s_relation = torch.matmul(s_values, s_values.transpose(-2, -1))
t_relation = torch.matmul(t_values, t_values.transpose(-2, -1))
# 维度重塑:[B, split_heads, L, L] -> [B*split_heads*L, L]
s_relation = (s_relation / temperature).reshape(-1, L)
t_relation = (t_relation / temperature).reshape(-1, L)
# 计算softmax概率
s_prob = F.softmax(s_relation, dim=-1).clamp(min=1e-8)
t_prob = F.softmax(t_relation, dim=-1).clamp(min=1e-8)
# 累加KL散度损失
distill_loss += F.kl_div(torch.log(s_prob), t_prob, reduction="batchmean", log_target=False)
return distill_loss蒸馏式微调阶段的总损失包含三项,旨在最小化学生模型与教师模型之间的差异并提升下游任务性能,通过两个蒸馏系数λ和γ进行缩放,即:L=LCE+λLLD+γLAD,(13)whereLCE=−N1∑i=1N∑t=1∣yi∣logPθ(yit∣xi).(14)
其中LCE表示下游数据集上的交叉熵损失。λ和γ控制蒸馏与模型拟合之间的权衡。
4 实验
4.1 实验设置
数据集
我们在两类代表性任务上评估所提方法 BitDistill 的效果:文本分类和文本摘要。对于分类任务,采用通用语言理解评估(GLUE)基准WSM+19∗中的三个广泛使用的数据集:多类型自然语言推理语料库(MNLI)WNB18、问答自然语言推理数据集(QNLI)RZLL16 和斯坦福情感树库(SST-2)SPW+13。这些数据集同时用于训练和评估,以全面评估我们方法的有效性。对于摘要任务,使用 CNN/DailyMail 数据集(CNNDM)HKG+15†作为训练和评估语料库。
*https://gluebenchmark.com/†https://huggingface.co/datasets/abisee/cnndailymail
对比基线
由于我们的目标是将预训练全精度 LLM 微调到 1.58 位 BitNet 模型以适配特定下游任务,我们将 1.58 位模型(记为 BitDistill)的性能与直接在相应下游任务上微调的 FP16 模型(记为 FP16-SFT)进行对比。此外,我们还报告了将全精度 LLM 直接转换为 1.58 位 BitNet 模型并在下游任务上微调的结果(记为 BitNet-SFT)。
训练设置
我们以 Qwen3 系列YLY+25作为基模型,涵盖 0.6B、1.7B 和 4B 参数规模。此外,通过使用 GemmaTKF+25和 Qwen2.5QY+25等替代骨干网络进行实验,研究不同基模型类型的影响。对于所有基线方法和我们的方法,采用贪心搜索策略选择最优学习率和训练轮数。该过程可缓解过拟合问题,同时确保良好的下游性能和方法间的公平对比。我们将最大训练序列长度固定为 512 个 token,批次大小固定为 32。所有模型均在配备 8×AMD Mi300X GPU 的服务器上训练。
具体而言,日志蒸馏(公式 9)的温度参数设置为 5.0。对于分类任务,公式(14)中λ=10且γ=1e5;对于摘要任务,λ=1且γ=1e3。所有实验中αi=1.0。在 3.2 节描述的持续预训练阶段,我们仅使用从 FALCON 语料库PMH+23采样的 10B 个 token 进一步训练模型。与从头训练 1.58 位 BitNet 的成本(约 4T 个 token)MWH+25相比,这一额外成本几乎可以忽略不计。
评估设置
对于分类和摘要任务,我们将采样参数 p 固定为 1.0,温度固定为 0。分类性能采用准确率评估。对于摘要任务,最大生成长度设置为 4096 个 token。摘要质量采用 BLEU PRWZ02 和 ROUGE-1、ROUGE-2、ROUGE-L、ROUGE-SUM Lin04 进行评估。对于模型运行效率,我们报告 16 线程 CPU 上的 token 吞吐量(tokens per second)。
4.2 主要结果
整体性能
基准数据集上的整体评估结果如表 1 和表 2 所示。在不同模型规模和任务中,通过我们的蒸馏框架(BitDistill)训练的 1.58 位 BitNet 模型,其准确率在大多数情况下与全精度对应模型基本相当,仅存在微小差异。同时,1.58 位模型在系统效率方面取得了显著提升,包括 CPU 推理速度提升高达 2 倍,内存占用减少近一个数量级。这些改进凸显了我们方法在计算资源受限场景下的实际应用价值,同时表明通过精心设计的蒸馏策略,激进量化是可行的。
表 1:文本分类任务结果。所有模型均基于 Qwen3 系列初始化。每个指标和数据集的最高分以粗体突出显示。1.58 位 BitDistill 模型在所有数据集上都实现了与 FP16 基线相当的性能,同时推理速度提升 2 倍,内存减少 10 倍。∗表示 BitDistill 中使用的 FP16 教师模型。
表 2:文本摘要任务结果(CNNDM 数据集)。所有模型均基于 Qwen3 系列初始化。每个指标和数据集的最高分以粗体突出显示。1.58 位 BitDistill 模型在所有数据集上都实现了与 FP16 基线相当的性能,同时推理速度提升 2 倍,内存减少 10 倍。∗表示 BitDistill 中使用的 FP16 教师模型。
不同预训练模型的鲁棒性
为进一步验证框架的通用性,我们将基模型从 Qwen3 系列替换为 Qwen2.5QY+25‡和 GemmaTKF+25§等替代模型进行扩展评估。表 3 中的结果表明,BitDistill 在所有测试架构上均能持续实现与全精度微调接近的下游性能。尽管不同基模型之间存在微小的性能波动,但整体趋势稳定,这表明我们的方法并非针对特定预训练模型家族设计,而是具有更广泛的适用性。这种鲁棒性提升了我们方法在不同部署环境中的潜在应用价值 ------ 在这些环境中,预训练骨干网络的选择可能因可用性和任务需求而异。
‡https://huggingface.co/Qwen/Qwen2.5-0.5B§https://huggingface.co/google/gemma-3-1b-pt
表 3:不同基模型初始化下文本分类任务(MNLI 数据集)的结果。∗表示 BitDistill 中使用的 FP16 教师模型。
4.3 消融实验
BitDistill 各阶段的作用
如 3 节所述,BitDistill 框架包含三个阶段。为明确每个组件的贡献,我们通过逐一移除一个阶段并重新训练模型进行消融实验。表 5 中的结果表明,移除任何一个阶段都会导致下游性能出现显著下降。这表明每个阶段都发挥着互补作用,完整的流水线是实现效率与精度最佳权衡的必要条件。
表 4:不同量化技术下文本分类任务的结果。B、G、A 分别表示 Block Quant、GPTQ 和 AWQ。
3.3 节阶段 3 中不同蒸馏技术的作用
在框架的最后阶段,我们引入两种互补的蒸馏技术,以更好地优化 1.58 位 BitNet 模型适配下游任务。为区分它们各自的作用,我们比较了单独使用每种技术与联合使用两种技术的效果。如表 6 所示,尽管单独使用每种技术都能带来部分改进,但联合使用两种技术能在所有基准数据集上获得最稳定的性能。这一观察结果表明,两种技术针对优化挑战的不同方面,在极端量化场景下,它们的协同作用尤为有益。
与不同量化技术的兼容性
我们进一步验证了 BitDistill 与现有训练后量化和权重量化方法的兼容性。具体而言,我们考虑了 Block-Quant DLSZ21、GPTQ FAHA22、AWQLTT+24以及公式(2)中的简单最小 - 最大量化方案。为此,我们将 BitDistill 与每种量化方法集成,并评估得到的 1.58 位模型。表 4 中的结果得出两个主要结论:(1)无论采用何种底层量化方法,模型都能从所提框架中持续获益,且性能基本与全精度基线相当;(2)更复杂的量化策略(例如 GPTQ、AWQ)在我们的蒸馏流水线基础上能带来额外增益。这些发现表明,BitDistill 与不同量化算法具有互补性,提供了一种统一流程,可在多种量化设置下稳定提升低位模型性能。
表 5:BitDistill 不同阶段的作用。此处以 Qwen3-0.6B 作为基模型。M.D.、C.T. 和 D.F. 分别表示 3.1 节的模型优化、3.2 节的持续预训练和 3.3 节的蒸馏式微调。
表 6:蒸馏技术的作用。此处 LD 表示公式 9 中的日志蒸馏,AD 表示公式 12 中的多头注意力蒸馏。
4.4 分析
3.1 节阶段 1 中 SubLN 的作用
为验证 SubLN 的效果,我们将现有 LLM 量化为 1.58 位 BitNet,并在 FALCON 语料库上微调,对比插入 SubLN(记为 BitNet-SFT w/ SubLN)和不插入 SubLN(记为 BitNet-SFT w/o SubLN)的性能。具体而言,如图 3(a)的训练损失曲线所示,3.1 节详细描述的模型优化(通过在特定位置插入 SubLN 层修改 LLM 架构)有效稳定了 1.58 位 BitNet 的训练,并带来了性能提升。
持续训练缓解扩展性问题的原因
如 1 节所述,1.58 位 BitNet 应用于下游任务的一个关键挑战是扩展性差 ------ 即随着模型规模增大,1.58 位 BitNet 与 FP16 对应模型之间的性能差距越来越显著。我们的实验表明,少量持续训练能有效缓解这一问题,以下将探究其潜在原因。
图 2:模型权重可视化。前两行显示从头训练的 BitNet 的量化权重及其对应的 FP16 分布。后两行显示加载 LLM 权重并进行持续训练(3.2 节阶段 2)后 BitNet 的量化权重及其对应的 FP16 分布。
在图 2 中,我们可视化了持续训练前后 1.58 位 BitNet 的模型权重,并与从头训练的 BitNet 进行对比。我们发现,持续训练后,原本近似高斯分布的权重分布变得与从头训练的 BitNet 分布更相似。这一观察结果支持了 3.2 节中的假设:持续训练使 BitNet 模型能够快速适配更适合 1.58 位优化的特征空间,从而避免收敛到次优局部最小值,最终提升下游性能。
图 3:SubLN、公式 12 的层选择以及训练过程中教师模型选择的分析。(a)插入 SubLN 将现有 LLM 微调到 1.58 位 BitNet,能获得更优性能和更快收敛速度。(b)Qwen3-0.6B 在不同层上进行蒸馏得到的 MNLI 准确率对比。(c)使用不同规模 FP16 教师模型蒸馏 Qwen3-0.6B 得到的 MNLI 准确率对比。
此外,我们还探究了图 2 中观察到的类 BitNet 权重分布为何能提升下游任务性能。具体而言,这种独特分布将更多权重集中在 0 与 - 1 以及 0 与 1 之间的过渡边界附近。这种分布使得量化值能够通过微小的梯度步长更频繁地切换,从而增强 1.58 位 BitNet 拟合下游数据的能力,降低陷入次优局部最小值的风险。
3.3 节阶段 3 中的蒸馏层选择策略
如 3.3 节所述,我们假设在单个层上进行注意力关系蒸馏,相比在所有层上蒸馏,能为 1.58 位 BitNet 提供更大的训练灵活性,从而获得更优性能。为验证这一点,我们探究了蒸馏层的选择策略。图 3(b)可视化了 Qwen3-0.6B 在不同层上进行蒸馏(无持续预训练)时的 MNLI 分类结果。我们的发现总结如下:(1)单个层蒸馏的性能优于所有层蒸馏,支持我们的假设;(2)选择不同的单个层会导致结果存在显著差异,表明合适的层选择策略至关重要;(3)模型后期的层通常能带来更优的蒸馏性能。
更优教师模型带来更优结果
我们探究了所提 BitDistill 是否能利用更高质量的 FP16 教师模型,为 1.58 位 BitNet 带来更大的下游任务增益。为此,我们使用 Qwen3-1.7B 和 Qwen3-4B FP16 模型作为教师模型,对 Qwen3-0.6B 1.58 位 BitNet 进行蒸馏。结果如图 3(c)所示。我们发现,我们的算法能有效从更高质量的教师模型中提取更大增益,甚至能超越同规模的 FP16 模型。这为部署针对特定任务的 BitNet 模型提供了性能保障。
5 相关工作
LLM 量化
量化TXL+25,DZC+24,MWM+24已成为提升 LLM 效率和扩展性的广泛采用的技术。训练后量化(PTQ)XLS+23,DLBZ22(如 GPTQ FAHA22 和 AWQLTT+24)已被广泛研究用于 LLM 的仅权重量化。PTQ 使用少量校准数据对全精度模型进行低位量化,无需访问端到端训练损失。然而,PTQ 通常存在显著的性能损失,尤其是当量化位数低于 4 位时 DLBZ22。为解决这一限制,量化感知训练(QAT)TXL+25,LOZ+23,CSX+24被提出 ------ 通过充分优化继续训练量化后的 LLM,从而提高量化模型的性能上限。
LLM 知识蒸馏
知识蒸馏 KKCY24, HVD15, WWD\^{+} 20, TXL \^{+} 25 已被证明是一种有效的 LLM 压缩技术,通过将知识从高容量教师模型迁移到更紧凑的学生模型,在保持精度的同时实现模型压缩。近年来,研究表明知识蒸馏也可有效用于将知识从全精度模型迁移到量化 LLM。例如,TSLDKLL+23采用层到层蒸馏增强三元量化的量化感知训练(QAT),而 BitDistillerDZC+24利用自蒸馏提升超低位(如 2 位或 3 位)LLM 的性能。尽管取得了这些进展,但大多数现有方法主要针对通用语言建模能力,在下游应用中与全精度对应模型相比仍存在明显的性能差距。
6 结论
本研究针对在严格的内存和延迟约束下,将预训练 LLM 适配到仅 1.58 位权重的超低位精度这一问题展开探究,其动机源于边缘设备上大规模模型部署的实际需求。为此,我们提出了 BitNet 蒸馏(BitDistill)------ 一种三阶段框架:首先通过 SubLN 进行模型优化,然后通过持续预训练恢复关键表示能力,最后通过隐藏态和注意力关系层面的知识蒸馏,缩小低位学生模型与高位教师模型之间的精度差距。在多个下游任务上的广泛实验表明,我们的方法 BitDistill 能实现与 FP16 模型相当的性能,同时显著降低计算和内存占用。除了提升效率外,我们的方法还为低位量化与预训练、蒸馏动态之间的相互作用提供了新的见解,为资源受限部署的可扩展策略提供了参考。