1)是什么
BERT = Bidirectional Encoder Representations from Transformers
中文翻译:双向编码器表示,来自Transformer 。
它是一个由 Google 在 2018 年提出的预训练语言模型,是 NLP 领域的"里程碑"式作品。你可以把它想象成一个"语言通才"------它先在海量文本上自学了语言规律,然后可以被"调教"去干各种任务,比如问答、情感分析、命名实体识别等等。
🎯 核心特点:
- 双向理解:它能同时看一个词左边和右边的上下文。
- 基于 Transformer 架构(尤其是编码器部分)。
- 使用 掩码语言建模(MLM) 和 下一句预测(NSP) 两种预训练任务。
👉 比喻一下:
BERT 就像一个刚进学校的孩子,老师没教具体知识,但让他反复玩两个游戏:
1."你看到一句话,其中某些字被遮住了,猜一猜是什么?"(MLM)
2."这两句话是不是连续的?"(NSP)
通过这两个游戏,孩子学会了语言的"语感"。之后,只要告诉他"现在你要做阅读理解",他就能立刻上手。
2)为什么
在 BERT 出现之前,主流方法是 RNN / LSTM 或 Word2Vec 等,它们有两大硬伤:
- ❌ 单向性:只能从左到右或从右到左读句子,无法同时利用两边信息。
- ❌ 无法捕捉长距离依赖:就像听一段话时,前面说了啥后面忘了。
而 BERT 的突破在于:
✅ 双向上下文理解 :比如"苹果"这个词,在"我吃了苹果"中是水果,在"苹果公司发布了新手机"中是公司。BERT 能根据前后文判断出正确含义。
✅ 预训练 + 微调:先在大量无标注文本上学习通用语言知识,再在特定任务上微调,大大降低了对标注数据的依赖。
📌 举个例子:
以前模型看到"银行"只知道它是"金融机构",但如果上下文是"我在河边钓鱼",BERT 能意识到这里的"银行"可能是"河岸"。
这就是"上下文感知"的力量!
3)什么时候用
BERT 是"瑞士军刀"级别的工具,适合以下情况:
🔹 需要深度语义理解的任务:
- 文本分类(如情感分析)
- 命名实体识别(NER)
- 问答系统(如 SQuAD 数据集)
- 机器翻译(作为编码器)
- 文本相似度计算(比如推荐系统)
🔹 标注数据少,但有大量无标注文本:
- 可以先用 BERT 预训练,再微调,效果远超传统模型。
🔹 追求高精度的 NLP 项目:
- 比如客服机器人、智能搜索、法律文书分析等。
💡 小贴士:
如果你要做一个"理解人类说话意图"的系统,BERT 是非常好的起点。
4)什么时候不用
虽然强大,但 BERT 并不是万能药。这些时候你应该考虑其他方案:
🚫 资源有限时:
- BERT 模型大(Base 版就有 1.1 亿参数),推理慢,显存占用高。
- 如果你在手机端或嵌入式设备部署,可能要用更轻量的模型,比如 DistilBERT、ALBERT 或 TinyBERT。
🚫 实时性要求极高:
- BERT 推理速度慢,不适合毫秒级响应的场景(比如实时语音助手)。
🚫 任务简单,不需要复杂语义理解:
- 比如简单的关键词匹配、规则引擎,用 BERT 大材小用,还浪费算力。
🚫 多语言支持不足(早期版本):
- 原始 BERT 主要是英文,虽然有 mBERT(多语言 BERT),但在低资源语言上表现仍不如专门优化的模型(如 XLM-RoBERTa)。
⚠️ 总结:
BERT 是"大力出奇迹"的代表,但不是所有问题都需要"核弹级"解决方案。
5)总结
1.BERT 是一个双向、基于 Transformer 的预训练语言模型,能深刻理解上下文。
2.它通过"掩码预测"和"下一句判断"学会语言,再微调完成具体任务,实现"一次学习,处处可用"。
3.它强大但不万能,适合高精度语义任务,但需权衡计算成本和实际需求。
🎯 评价:
"别迷信 BERT,但别忽视它。它不是终点,而是通往更好模型的跳板。"
概念
Bert和GPT的一个简单对比
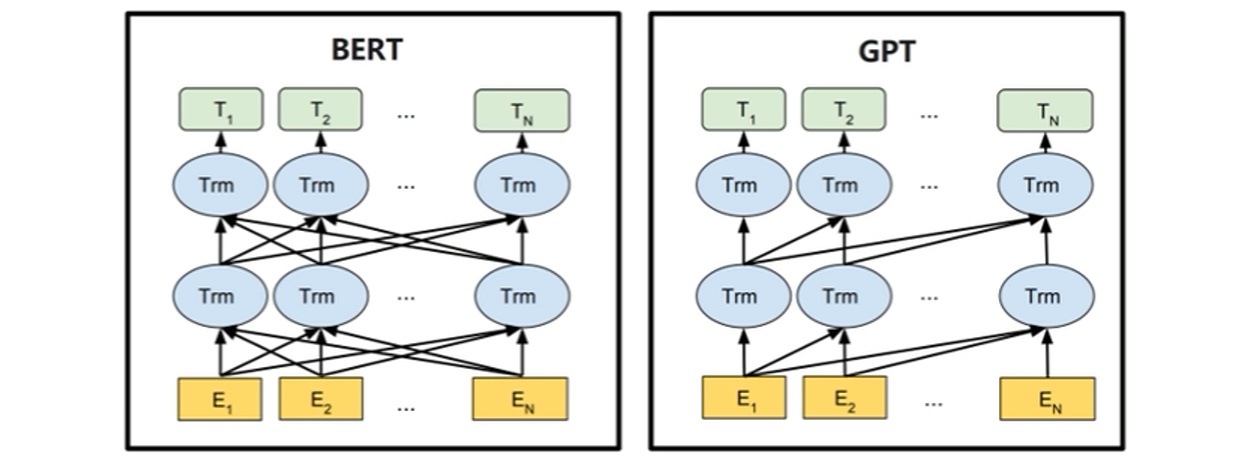
图中表示的是Bert相比于GPT,它是一个双向的RNN结构。Bert通过双向自注意力机制,在建模每个 token 表示时同时整合左右两个方向的上下文信息,从而获得更准确、更丰富的语义表示。
1. 概述
Bert是典型的基于标准的编码器构建的预训练模型。它提供了两种模型规模,分别是BERT-base和BERT-large。
BERT 的设计更侧重于自然语言理解类任务,广泛应用于文本分类、序列标注、句子匹配等场景。模型发布后,在多个语言理解基准测试中取得了前所未有的领先成绩,推动 NLP 研究全面转向"预训练 + 微调"的通用建模范式。
| 模型版本 | 参数量 | 推理速度(CPU) | 显存占用(FP16) | 适用场景 |
|---|---|---|---|---|
| BERT-base | 1.1亿 | ~50 ms/句 | ~400 MB | 中小项目、API服务、移动端蒸馏目标 |
| BERT-large | 3.4亿 | ~120 ms/句 | ~1.2 GB | 高精度任务(如法律文书分析、医学问答) |
💡 案例:
- 阿里客服机器人初期用 BERT-base,响应快;
- 法院智能判案系统用 BERT-large,因为"一字之差可能影响判决"。
⚠️ 注意:BERT-large 并非总是更好!在小数据集上容易过拟合。
2. 结构
2.1 输入层
BERT 的每个输入 token 表示由三部分嵌入相加组成:
- Token Embedding:词本身的语义表示;
- Position Embedding:表示 token 在序列中的位置,为可学习向量;
- Segment Embedding :用于区分句子对任务中的两个句子,分别用一个可学习的向量表示。
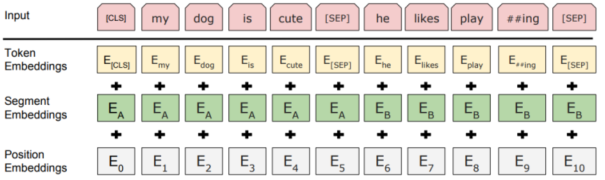
特殊token - CLS:句首标志,其输出向量常用于下游的文本分类任务
- SEP:句间分隔符,出现在每个句子末尾
实战建议
| Token | 用途 | 注意事项 |
|---|---|---|
| CLS | 序列级任务的"代表" | - 微调时接一个全连接层做分类 - 不要用于生成任务(BERT 不是生成模型!) |
| SEP | 分隔句子 | - 单句任务也需加 SEP 在末尾(符合预训练格式) - 多句任务可多个 SEP(但原始 BERT 只支持两段) |
🔍 案例:句子对任务(如问答匹配)
输入:CLS 谁是美国总统? SEP 奥巴马曾担任美国总统。 SEP
- Token Embedding:
→ "美国" 和 "总统" 各自有语义向量(来自 WordPiece 词表) - Position Embedding:
→ 即使"总统"出现在两个位置(问句 vs 答句),模型知道它们是不同的"角色" - Segment Embedding:
→ 所有问句 token 标为 A,答句 token 标为 B,让模型区分"谁问谁答"
🎯 为什么重要?
如果没有 Segment Embedding,模型会把 CLS A SEP B SEP 当成一个长句子,无法理解"这是两个独立句子"。
💡 生动比喻:
就像开会时,主持人(CLS)、发言人1(A段)、发言人2(B段)------即使说同样的话,身份不同,意义不同!
2.2 编码器层
编码器层基本与同原始的Transfomer相同,之前的架构图如下:
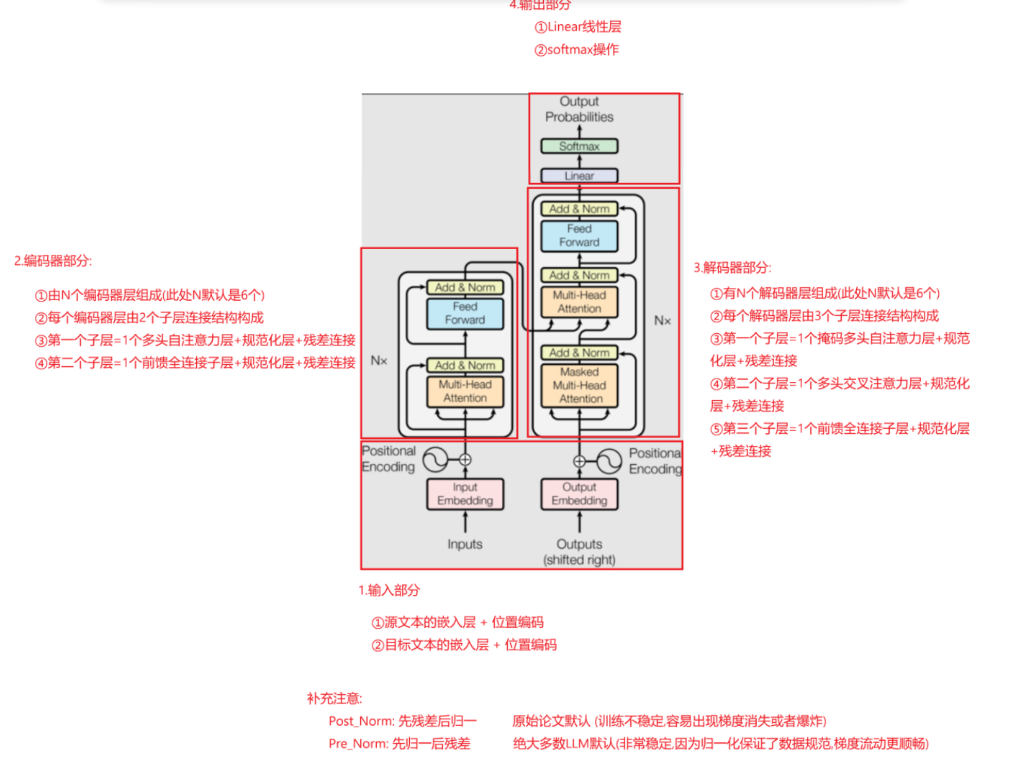
💡 但关键差异如下:
| 特性 | BERT | 原始 Transformer(Encoder) |
|---|---|---|
| 注意力方向 | 双向(Bi-directional) | 双向(编码器本来就是双向) |
| 训练目标 | MLM + NSP | 无(原始用于机器翻译) |
| 位置编码 | 可学习(Learned) | 正弦/余弦(Sinusoidal) |
💡 为什么用可学习的位置编码?
Google 发现:让模型自己学"位置怎么表示"比硬编码公式更灵活,尤其对中文等语言效果更好。
2.3 输出层
根据下游任务的类型,BERT 可以接入不同的任务输出头:
- Token-Level 任务(如命名实体识别):使用每个位置的输出表示;
- Sequence-Level 任务(如文本分类、句子对分类):使用特殊 token CLS 的输出表示,输入时被加在序列开头,专门用于汇总整个序列的语义信息。
BERT 是"主干网络",不同任务接不同"头部":
| 任务类型 | 输出头结构 | 案例 |
|---|---|---|
| 文本分类 | Linear(768 → num_classes) | 情感分析、新闻分类 |
| 句子对匹配 | Linear(768 → 2) | 判断两句话是否矛盾(NLI) |
| 命名实体识别(NER) | Linear(768 → num_tags) | 识别"张三"是人名,"北京"是地名 |
| 问答(SQuAD) | 两个 Linear 层:start_logits & end_logits | 找出答案在原文中的起止位置 |
🧩 SQuAD 问答案例:
text
Question: "谁发明了电话?"
Context: "亚历山大·贝尔发明了电话。"
→ 模型输出 start=0, end=1 → "亚历山大·贝尔"🎯 BERT 不生成新词,而是从原文中抽取片段------这就是为什么它适合"理解",不适合"创作"。
3. 预训练
Bert的预训练阶段包含了两个核心的任务:掩码语言模型(MLM) 和 下一句预测(NSP),前者用于学习词语级语义,后者用于学习句子间逻辑关系
3.1 掩码语言模型
Masked Language Model, MLM
📌 定义:
随机遮蔽输入中的一些 token,让模型根据上下文预测被遮蔽的词。
✅ 目标:学习词级语义和上下文依赖关系
💡 案例:中文 MLM
假设原始句子是:
text
"我喜欢吃苹果。"BERT 会随机遮蔽一个词,比如把"苹果"换成 MASK:
text
"我喜欢吃[MASK]。"然后模型要预测这个位置应该填什么词。
🎯 正确答案:苹果
🎯 可能干扰项:香蕉、西瓜、蛋糕
🎯 模型怎么学?
- 看左边:"我 喜欢 吃" → 表示食物;
- 看右边:"。" → 句子结束;
- 综合判断:最可能是水果类名词。
🧠 为什么用 MLM 而不是传统语言模型?
| 方法 | 方向性 | 缺点 |
|---|---|---|
| 传统 LM(如 LSTM) | 单向(左→右) | 无法利用后文信息 |
| BERT 的 MLM | 双向(前后都看) | 能同时利用上下文 |
✅ 关键突破:
BERT 是第一个真正实现 双向上下文建模 的预训练模型!
🔍 比喻一下:
就像考试时,老师给你一段话,但中间几个字被涂黑了,你要根据前后的意思猜出来。这比只看前面猜(单向)更准确!
⚠️ 注意事项
1.不是所有词都遮蔽
- BERT 默认只遮蔽 15% 的 token;
- 其中:
- 80% 用 MASK 替换;
- 10% 用随机词替换;
- 10% 保持不变;
🎯 目的:防止模型"作弊"(比如总是记住了"MASK"就是原词),增强鲁棒性。
2.遮蔽的是 token,不是字符
- 中文通常是按字(character)遮蔽;
- 英文可能是 subword(如 play → pl, ay);
示例:
"I love playing football" → MASK love pl ay ing football
3.不能直接用于生成任务
- 因为它不支持自回归生成(没法一步步生成新词);
- 所以 GPT 才用因果语言模型(Causal LM);
3.2 下一句预测
📌 定义:
给定两个句子 A 和 B,判断 B 是否是 A 的下一句。
✅ 目标:学习句子间的逻辑关系(是否连贯)
💡 案例:NSP 正例 vs 反例
✅ 正例(IsNext=True)
text
A: "昨天下雨了。"
B: "地面变得湿滑。"
→ 关系:因果 → 应该预测为 True❌ 反例(IsNext=False)
text
A: "昨天下雨了。"
B: "苹果公司发布了新手机。"
→ 关系:无关 → 应该预测为 False🎯 模型怎么学?
- 学习句子之间的主题一致性、逻辑连贯性;
- 例如:如果 A 是关于天气,B 是关于科技,就不太可能是连续句。
🧠 为什么需要 NSP?
在 BERT 出现之前,大多数模型只能理解单个句子内部的关系,比如:
- "银行"是"金融机构"还是"河岸"?
- "苹果"是水果还是公司?
但很多任务需要跨句理解,比如:
- 问答系统:问题在第一句,答案在第二句;
- 自然语言推理:前提和假设是否一致;
- 文档摘要:哪些句子是核心内容?
所以 BERT 加入 NSP,就是为了教会模型:
"这两个句子是不是'一家人'?"
⚠️ 注意事项
1.NSP 任务效果有限
- 后续研究发现:NSP 主要是让模型学会"判断两个句子是否来自同一文档",而不是真正的"逻辑关系";
- 例如:两个句子都在讲"体育",即使不连贯,也可能被判为"是下一句";
2.RoBERTa 去掉了 NSP
- 实验表明:去掉 NSP,只用 MLM,性能反而更好;
- 因为 MLM 已经足够强大,NSP 可能引入噪声;
3.NSP 不适合多段文本
- 原始 BERT 只支持两句话(A+B);
- 如果你想处理长文档,需要用其他方法(如 Longformer、Document-BERT);
3.3 两种预训练小结
| 任务 | 输入格式 | 输出目标 | 学习内容 | 代表模型 |
|---|---|---|---|---|
| MLM | CLS 我 喜欢 吃 MASK 。 SEP | 预测被遮蔽词 | 词级语义、上下文依赖 | BERT, RoBERTa |
| NSP | CLS A SEP B SEP | 判断 B 是否是 A 的下一句 | 句子间逻辑关系 | BERT(早期) |
4. 微调
Bert主要的微调任务分为以下4种:
4.1 句子对分类任务
输入格式:CLS 句子1 SEP 句子2 SEP
📌 定义:
- 判断两个句子之间的关系,如是否矛盾、蕴含、相似等。
🧩 典型场景:
- 自然语言推理(NLI):判断前提与假设的关系
- 语义相似度:判断两句话是不是在说同一件事
- 问答匹配:问题和答案是否相关
💡 案例:中文 NLI(自然语言推理)
text
前提:今天下雨了。
假设:地面湿了。
→ 关系:蕴含(entailment)✅ 输入格式:
text
[CLS] 今天下雨了。 [SEP] 地面湿了。 [SEP]🎯 为什么用 SEP 分隔?
- 让模型知道这是两个独立句子;
- Segment Embedding 能区分 A 和 B 段;
- 预训练时 NSP 任务就是这么做的 → 保持一致性。
⚠️ 注意事项:
- 不要直接拼接成"今天下雨了,地面湿了" → 会丢失"句子对"的结构信息;
- 若使用 Hugging Face 的 AutoModelForSequenceClassification,它自动提取 CLS 输出做分类。
4.2 单句分类任务
输入格式:CLS 句子 SEP
📌 定义:
对单个句子进行分类,如情感分析、主题分类等。
💡 案例:电商评论情感分析
text
输入:"这款手机续航真差!"
输出:负面情绪(negative)✅ 输入格式:
text
[CLS] 这款手机续航真差! [SEP]🎯 为什么加 SEP?
- 虽然只有一个句子,但 BERT 预训练时所有输入都以 SEP 结尾;
- 保证编码器输入结构统一,避免位置编码混乱。
⚠️ 注意事项:
- 如果你不加 SEP,可能会导致 tokenization 错误或 embedding 失准;
- 使用 AutoModelForSequenceClassification,它会自动处理 CLS 的输出。
4.3 问答任务
输入格式:CLS 问题 SEP 段落 SEP
📌 定义:
根据问题和上下文段落,找出答案在段落中的起止位置。
💡 案例:SQuAD 风格问答
text
问题:谁发明了电话?
段落:亚历山大·贝尔于1876年发明了电话。
→ 答案:"亚历山大·贝尔"✅ 输入格式:
text
[CLS] 谁发明了电话? [SEP] 亚历山大·贝尔于1876年发明了电话。 [SEP]🎯 为什么这样设计?
- 问题和段落分开,让模型理解"问什么"、"在哪找";
- BERT 在预训练阶段就学过"掩码语言建模"(MLM),擅长定位词;
- 输出是两个向量:start_logits 和 end_logits,分别预测答案的开始和结束位置。
⚠️ 注意事项:
- 不能只给问题或只给段落;
- 答案必须是原文连续片段(BERT 是抽取式问答,不是生成式);
- 建议使用 AutoModelForQuestionAnswering,它自带 start/end head。
4.4 序列标注任务
输入格式:CLS 句子 SEP
📌 定义:
为每个 token 分配一个标签,如命名实体识别(NER)、分词、词性标注等。
💡 案例:中文命名实体识别(NER)
text
输入:"张三在北京工作。"
标签:[B-PER, I-PER, B-LOC, I-LOC, O]✅ 输入格式:
text
[CLS] 张 三 在 北 京 工 作 。 [SEP]🎯 为什么用这个格式?
- 每个字对应一个隐藏状态(hidden state);
- 模型输出每个 token 的分类结果;
- 不依赖 CLS,而是用整个序列的输出。
⚠️ 注意事项:
- 必须使用 AutoModelForTokenClassification;
- 标签体系需提前定义(如 BIO 格式);
- 中文通常按字级标注,英文可按词级(word-level)。
4.5 四种任务小结
| 任务 | 输入格式 | 输出目标 | 典型数据集 | 推荐模型类 |
|---|---|---|---|---|
| 句子对分类 | CLS A SEP B SEP | 类别(如 entailment) | MNLI, LCQMC | AutoModelForSequenceClassification |
| 单句分类 | CLS 文本 SEP | 类别(如 positive) | IMDB, THUCNews | AutoModelForSequenceClassification |
| 问答 | CLS Q SEP C SEP | 起始/结束位置 | SQuAD, CMRC2018 | AutoModelForQuestionAnswering |
| 序列标注 | CLS 文本 SEP | 每个 token 的标签 | CoNLL-2003, MSRA-NER | AutoModelForTokenClassification |
Bert的局限性
| 问题 | 说明 | 改进方案 |
|---|---|---|
| 不是生成模型 | 无法像 GPT 那样写文章 | 用 BART、T5 等 encoder-decoder 架构 |
| NSP 任务效果存疑 | RoBERTa 证明去掉 NSP 反而更好 | 用 RoBERTa 或 ALBERT |
| 静态分词 | WordPiece 对 OOV 词处理弱 | 用 SentencePiece(如 XLNet)或字符级模型 |
🚀 BERT 下游任务速查
| 任务 | 输入格式 | 用哪个输出? | 典型数据集 |
|---|---|---|---|
| 文本分类 | CLS text SEP | CLS 向量 | IMDb, THUCNews |
| 句子对分类 | CLS A SEP B SEP | CLS 向量 | MNLI, LCQMC(中文) |
| NER | CLS w1 w2 ... wn SEP | 每个 wi 的 hidden state | CoNLL-2003, MSRA-NER |
| 问答 | CLS Q SEP C SEP | 每个 token 的 start/end score | SQuAD, CMRC2018(中文) |