1. 先把概念捋直:Table API 与 DataStream API 怎么选
Table API 适合什么
- 你在做 ETL、数仓建模、聚合统计、Join、窗口分析
- 你希望用 SQL/关系模型 统一表达批/流(同语义)
- 你需要 Catalog、DDL、Connector(Kafka/Filesystem/Print/Blackhole...) 生态
一句话:能用 SQL/表的方式表达,就优先 Table API / SQL,尤其数据管道场景。
DataStream API 适合什么
- 你需要更底层的流处理能力:ProcessFunction、状态/定时器、细粒度控制
- 你更在意每一个算子怎么写、怎么并行、怎么 keyBy、怎么 state
- 你想做事件驱动系统或复杂实时业务逻辑
一句话:需要"流处理编程模型"与更强控制力,就 DataStream API。
两者可以混用吗
可以,而且很常见:
- 用 Table/SQL 接 Kafka、做清洗、Join、窗口
- 再把结果转 DataStream 做复杂业务逻辑
- 或反过来:DataStream 做特殊处理后转 Table 用 SQL 写聚合/落库
2. Table API:纯 Python WordCount(可本地跑)
2.1 环境与依赖
- Java 11
- Python 3.9/3.10/3.11/3.12
- 安装 PyFlink
bash
python -m pip install apache-flink2.2 最小可跑版(从 CSV 读,写到 print 或文件)
下面是"官方示例思路"整理后的版本,重点是 3 步:
- 创建
TableEnvironment - 注册 source/sink(TableDescriptor 或 DDL)
- 计算后
execute_insert().wait()
python
import argparse
import logging
import sys
from pyflink.common import Row
from pyflink.table import (
EnvironmentSettings, TableEnvironment,
TableDescriptor, Schema, DataTypes, FormatDescriptor
)
from pyflink.table.expressions import lit, col
from pyflink.table.udf import udtf
word_count_data = [
"To be, or not to be,--that is the question:--",
"Whether 'tis nobler in the mind to suffer",
"The slings and arrows of outrageous fortune",
]
def word_count(input_path: str | None, output_path: str | None):
t_env = TableEnvironment.create(EnvironmentSettings.in_streaming_mode())
t_env.get_config().set("parallelism.default", "1")
# source
if input_path:
t_env.create_temporary_table(
'source',
TableDescriptor.for_connector('filesystem')
.schema(Schema.new_builder().column('line', DataTypes.STRING()).build())
.option('path', input_path)
.format('csv')
.build()
)
tab = t_env.from_path('source')
else:
tab = t_env.from_elements(
[(s,) for s in word_count_data],
DataTypes.ROW([DataTypes.FIELD('line', DataTypes.STRING())])
)
# sink
if output_path:
t_env.create_temporary_table(
'sink',
TableDescriptor.for_connector('filesystem')
.schema(Schema.new_builder()
.column('word', DataTypes.STRING())
.column('cnt', DataTypes.BIGINT())
.build())
.option('path', output_path)
.format(FormatDescriptor.for_format('canal-json').build())
.build()
)
else:
t_env.create_temporary_table(
'sink',
TableDescriptor.for_connector('print')
.schema(Schema.new_builder()
.column('word', DataTypes.STRING())
.column('cnt', DataTypes.BIGINT())
.build())
.build()
)
@udtf(result_types=[DataTypes.STRING()])
def split(row: Row):
for w in row[0].split():
yield Row(w)
tab.flat_map(split).alias('word') \
.group_by(col('word')) \
.select(col('word'), lit(1).count.alias('cnt')) \
.execute_insert('sink') \
.wait()
if __name__ == '__main__':
logging.basicConfig(stream=sys.stdout, level=logging.INFO, format="%(message)s")
parser = argparse.ArgumentParser()
parser.add_argument('--input', required=False)
parser.add_argument('--output', required=False)
args = parser.parse_args()
word_count(args.input, args.output)运行:
bash
python word_count_table.py2.3 为什么 Table 的输出会出现 +I / -U / +U
你贴的例子里 print sink 输出类似:
2> +I(4,11)
6> -U(2,8)
6> +U(2,15)这不是"打印重复",而是 Table 生态的 ChangeLog(变更日志)。
+I:Insert(新增一行)-U:Update-Before(更新前旧值,需要撤回)+U:Update-After(更新后新值,需要写入/覆盖)
典型原因:你做了聚合(GROUP BY / SUM),某个 key 的聚合结果会不断变化,所以会产生撤回与更新。
如果你的下游 sink 不支持 retract/upsert,就会接不住这种结果。解决思路通常是:
- 使用支持 upsert 的 sink(比如 Upsert-Kafka、支持主键的 JDBC/OLAP 等)
- 在 Table 设计中明确主键/语义(Flink SQL 支持主键声明 NOT ENFORCED)
- 或把结果转换为 append-only(某些窗口场景可以做到)
3. DataStream API:同样 WordCount(FileSource → 聚合 → FileSink/print)
DataStream 的核心是:
env -> source -> transform(map/flat_map/key_by/reduce) -> sink -> env.execute()
python
import argparse
import logging
import sys
from pyflink.common import WatermarkStrategy, Encoder, Types
from pyflink.datastream import StreamExecutionEnvironment, RuntimeExecutionMode
from pyflink.datastream.connectors.file_system import (
FileSource, StreamFormat, FileSink, OutputFileConfig, RollingPolicy
)
word_count_data = [
"To be, or not to be,--that is the question:--",
"Whether 'tis nobler in the mind to suffer",
"The slings and arrows of outrageous fortune",
]
def word_count(input_path: str | None, output_path: str | None):
env = StreamExecutionEnvironment.get_execution_environment()
env.set_runtime_mode(RuntimeExecutionMode.BATCH)
env.set_parallelism(1)
if input_path:
ds = env.from_source(
source=FileSource.for_record_stream_format(StreamFormat.text_line_format(), input_path)
.process_static_file_set().build(),
watermark_strategy=WatermarkStrategy.for_monotonous_timestamps(),
source_name="file_source"
)
else:
ds = env.from_collection(word_count_data)
def split(line: str):
yield from line.split()
ds = ds.flat_map(split) \
.map(lambda w: (w, 1), output_type=Types.TUPLE([Types.STRING(), Types.INT()])) \
.key_by(lambda x: x[0]) \
.reduce(lambda a, b: (a[0], a[1] + b[1]))
if output_path:
ds.sink_to(
FileSink.for_row_format(output_path, Encoder.simple_string_encoder())
.with_output_file_config(OutputFileConfig.builder()
.with_part_prefix("prefix")
.with_part_suffix(".ext")
.build())
.with_rolling_policy(RollingPolicy.default_rolling_policy())
.build()
)
else:
ds.print()
env.execute("word_count_datastream")
if __name__ == '__main__':
logging.basicConfig(stream=sys.stdout, level=logging.INFO, format="%(message)s")
parser = argparse.ArgumentParser()
parser.add_argument('--input', required=False)
parser.add_argument('--output', required=False)
args = parser.parse_args()
word_count(args.input, args.output)DataStream 的一个关键点:output_type
你贴的 Data Types 文档强调了:
- 不声明类型时默认
Types.PICKLED_BYTE_ARRAY(),会用 pickle 序列化 - 要和 Java 算子/Java sink 交互(比如 FileSink)时,必须给 output_type
- 给了 type info,序列化会更快、更稳定
4. TableEnvironment 常用 API:你需要记住的"主干接口"
建议记住这 6 个
TableEnvironment.create(settings):入口execute_sql(ddl/dml/dql):DDL/DML/SHOW/DESCRIBE/EXPLAIN 一把梭sql_query(sql):把 SQL 查询变成 Tablefrom_path(name):拿注册过的表create_temporary_view(name, table):Table ↔ SQL 互通的桥create_statement_set():一个 Job 写多个 sink(多 insert 一次提交)
execute_sql 的 wait() 用法
- 本地 mini cluster/IDE 里:通常需要
.wait(),否则脚本可能直接退出 - 提交到远程集群(detach 模式):一般不 wait(让集群跑,客户端退出)
5. Table API 与 SQL 混用:最实用的两种姿势
5.1 Table → SQL(把 Table 注册成 view)
python
table = table_env.from_elements([(1, 'Hi'), (2, 'Hello')], ['id', 'data'])
table_env.create_temporary_view('table_api_table', table)
table_env.execute_sql("INSERT INTO table_sink SELECT * FROM table_api_table").wait()5.2 SQL → Table(from_path 或 sql_query)
python
table_env.execute_sql("""
CREATE TABLE sql_source (
id BIGINT,
data TINYINT
) WITH (
'connector' = 'datagen',
'fields.id.kind'='sequence',
'fields.id.start'='1',
'fields.id.end'='4',
'fields.data.kind'='sequence',
'fields.data.start'='4',
'fields.data.end'='7'
)
""")
t = table_env.from_path("sql_source")
t.execute().print()6. Emit Results:print / collect / to_pandas / 多 sink 一次提交
6.1 TableResult.print 与 collect
print():适合预览,小心内存(会物化)collect():返回可迭代对象,适合你自己处理输出,同样注意 limit
python
table_result = table_env.execute_sql("SELECT ...")
table_result.print()
with table_result.collect() as it:
for row in it:
print(row)6.2 Table ↔ Pandas(Arrow)
from_pandas():把 DataFrame 作为 Arrow Sourceto_pandas():把 Table 收集回客户端(一定要 limit,确保能放进内存)
python
pdf = table.limit(100).to_pandas()6.3 一次 Job 写多个 sink:StatementSet
python
statement_set = table_env.create_statement_set()
statement_set.add_insert("first_sink", table1)
statement_set.add_insert_sql("INSERT INTO second_sink SELECT ...")
statement_set.execute().wait()7. UDF 体系:UDF / UDTF / UDAF + 向量化(Pandas)怎么选
7.1 普通 UDF(逐行)适合什么
- 逻辑复杂但每行处理不重
- 你需要更好的隔离与兼容性
- 你要用 open() 预加载资源(模型、字典)
python
from pyflink.table.udf import ScalarFunction, udf
from pyflink.table import DataTypes
class HashCode(ScalarFunction):
def open(self, ctx):
self.factor = int(ctx.get_job_parameter("hashcode_factor", "12"))
def eval(self, s: str):
return hash(s) * self.factor
hash_code = udf(HashCode(), result_type=DataTypes.INT())
t_env.get_config().set('pipeline.global-job-parameters', 'hashcode_factor:31')
t_env.create_temporary_system_function("hashCode", hash_code)7.2 UDTF(flat_map)适合什么
- 一行拆多行(split、explode、解析数组/JSON 等)
7.3 UDAF(聚合)适合什么
- 你要自定义 accumulate/retract/merge 的精细行为(流聚合常用)
7.4 向量化 Pandas UDF:性能更高但有限制
原理:JVM ↔ Python 之间用 Arrow 列式批量传输,减少序列化与调用开销。
典型配置项:python.fn-execution.arrow.batch.size
注意点(很关键):
- Pandas UDAF 不支持部分聚合,group/window 的数据可能一次性进内存
- 返回类型限制(你贴的文档提到暂不支持 RowType/MapType 等场景)
- 如果 group/window 很大,可能 OOM
8. Connector 与依赖管理:PyFlink 上线最容易踩坑的地方
8.1 Connector/Format 是 Java Jar,不是 pip
用 Table/SQL connectors 时,需要把 jar 加入 pipeline 依赖:
python
t_env.get_config().set(
"pipeline.jars",
"file:///my/jar/path/flink-sql-connector-kafka.jar;file:///my/jar/path/flink-json.jar"
)DataStream 里常用:
python
env.add_jars("file:///path/to/flink-sql-connector-kafka.jar")8.2 Python 依赖三件套:python.files / requirements / archives
add_python_file:把你的 py 文件/包打给 workerset_python_requirements:requirements.txt 让集群安装依赖add_python_archive:虚拟环境/模型文件/数据包(zip/tar)一起带上
典型线上姿势(远程集群最稳):
- 代码本体:
python.files(或add_python_file) - 三方依赖:requirements + cache(离线安装)
- 大资源:archives(模型/字典/venv)
8.3 常见报错:ModuleNotFoundError
几乎都是因为:UDF 在 worker 端找不到你的自定义模块。
解决:把 UDF 文件用 python-files(或 add_python_file)带过去。
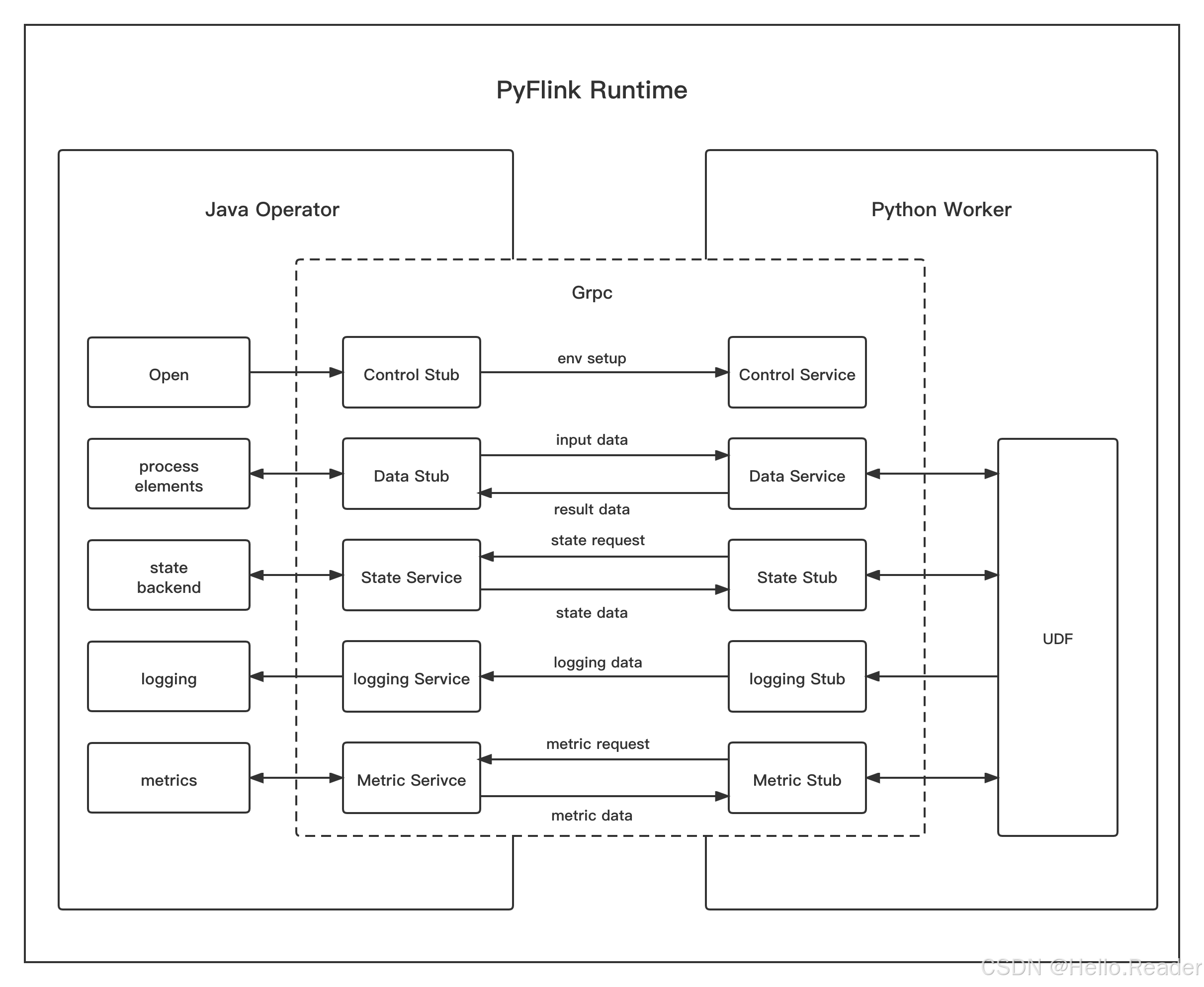
9. PyFlink Runtime:PROCESS vs THREAD(结合你贴的两张图)
你给的两张图表达的是同一件事:Python 代码怎么在 Flink 里跑。
9.1 PROCESS 模式(默认)
- Java Operator 与 Python Worker 是 两个进程
- 通过 gRPC 通信
- Open/数据传输/状态访问/日志/指标都走对应的 Service/Stub
优点: - 隔离最好(Python 崩了不一定拖垮 JVM)
- 兼容性好(Pandas UDF/UDAF 这些全支持)
缺点: - 进程间通信 + 序列化/反序列化有成本
9.2 THREAD 模式(1.15 引入)
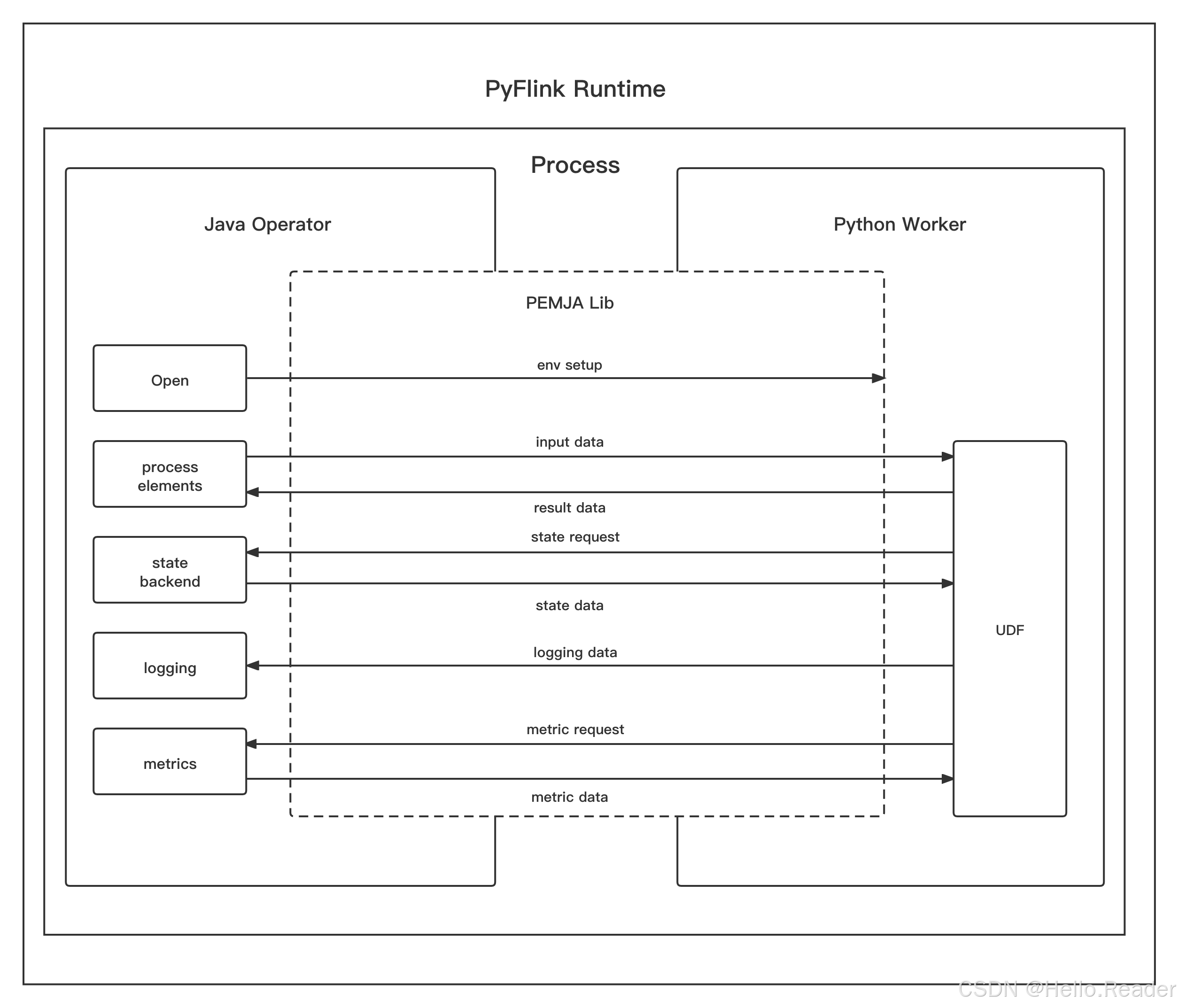
-
Python UDF 不再在独立进程
-
而是通过 PEMJA 把 Python 嵌进 JVM 进程内执行
优点:
-
少了进程间通信与很多序列化开销,通常会更快
缺点:
-
仍受 GIL 影响:多个 Python UDF 在同 JVM 并行度受限
-
支持范围更窄:你贴的表里写得很清楚
- Table API:Python UDAF、Pandas UDF/UDAF 等不支持 THREAD
- DataStream:某些高级算子(interval join/async io 等)不支持
配置方式:
python
# Table API
table_env.get_config().set("python.execution-mode", "process") # or "thread"
# DataStream API(用 Configuration 创建 env)
from pyflink.common import Configuration
from pyflink.datastream import StreamExecutionEnvironment
config = Configuration()
config.set_string("python.execution-mode", "thread")
env = StreamExecutionEnvironment.get_execution_environment(config)9.3 会"回退到 PROCESS"的真实原因
你配置了 THREAD,但实际跑着跑着发现还是 PROCESS,通常是:
- 你用了 THREAD 不支持的 UDF 类型(尤其 Pandas UDF/UDAF、Python UDAF)
- 或用了不支持的算子/场景
Flink 会为了正确性和兼容性直接回退。
10. 一个落地建议:写 PyFlink 项目时的"工程化模板"
10.1 本地开发阶段
- print sink 输出
- 小数据 to_pandas/collect 预览
parallelism.default=1,方便调试与对齐输出
10.2 准备上线阶段
- 统一管理依赖:requirements + cache + archives
- 统一管理 jar:pipeline.jars / env.add_jars
- 规划 ChangeLog sink:是否需要 upsert/retract 支持
- 明确执行模式:性能敏感先评估 THREAD,否则 PROCESS 更稳
10.3 性能抓手(先记住这几个就够用)
- 向量化:Pandas UDF(能用就用,但注意内存与限制)
- Arrow batch:
python.fn-execution.arrow.batch.size - 类型声明:DataStream 明确
output_type,减少 pickle - 合理算子链:必要时禁用 chaining,避免某个爆炸 flat_map 拖死链路