前言
昨天,给小伙伴们普及了一下大模型的定义和分类等知识点,今天给大家说一下我们在哪里可以获取大模型的API接口,进行大模型的调用。以供我们后续学习的时候使用,当然大家在平时也可以研究一下这些大模型的应用。
废话不多说,直接开启旅程!
一、开源与闭源
你是不是也纠结过:想调用大模型做开发,该选开源还是闭源?其实这俩概念一点不复杂,就像我们每天接触的科技产品------开源像安卓手机能自由折腾,闭源像iOS系统省心稳定,看完这三段你就懂怎么选!
开源大模型 ------"把厨房公开,人人能掌勺" 开源大模型本质是"技术不藏私" :核心的模型权重、基础代码会完全公开,任何人都能下载部署、修改优化,还能根据MIT、Apache 2.0等开源协议二次开发。就像一个共享厨房,不仅给你做好的饭菜,还附上完整菜谱和食材清单,你想换调料、改做法都随心所欲。
它的核心亮点 超实用:数据能本地处理 ,敏感信息不用外发,特别适合金融、医疗等对隐私要求高的场景;还能针对垂直领域深度微调,比如医疗模型植入专业知识库后,诊断准确率能提升18%。
闭源大模型 ------"点份外卖,不用管后厨" 闭源大模型走的是"省心路线" :核心技术像黑箱子一样保密,你看不到底层代码和模型权重,只能通过官方API接口调用使用。这就像点外卖,不用自己买菜做饭、洗碗收拾,点开就能用,味道还稳定,出问题直接找官方售后就行。
它的优势精准戳中"怕麻烦"需求:开箱即用不用折腾部署,注册账号拿API密钥就能快速上线应用;厂商持续优化性能,比如GPT-5.2在编程测试中通过率超55%,Gemini 3 Pro支持百万级上下文窗口,处理长文档速度飞快;还能享受企业级SLA保障,像电商618大促这样的高并发场景也能零故障运行。
核心区别: 其实是"控制权"和"省心度"的权衡,控制权 :开源把主动权交给你,能本地部署、深度定制;闭源由厂商掌控,你只需要用好功能就行 。 成本结构:开源前期部署费点劲,但长期免费无token成本;闭源按调用量付费,短期省钱但量大后成本会上升。
二、有哪些开源模型
目前主流的开源模型主要有哪些,我们来瞧一瞧。
2.1 国内主流开源大模型
1. 通义千问Qwen3(阿里巴巴)
核心定位:全球最活跃开源模型家族,覆盖从1.8B到235B全参数规模,支持多模态(文本、图像、语音)
核心优势:数学与编程能力顶尖,中文理解与生成效果出色,Apache 2.0协议商用友好,衍生模型超10万个
关键特性:支持128K-200K超长上下文窗口,推理速度快,适配从手机到服务器全硬件环境。
2. DeepSeek-R1/V3.2(深度求索)
核心定位:开源推理性能天花板,训练成本极低却对标GPT-5的"性价比之王"
核心优势:MIT协议完全开源,魔改自由度高,编程与复杂推理能力接近闭源顶尖水平,在相关评测中表现突出
关键特性:采用创新混合专家(MoE)架构,参数效率高,支持快速微调与部署
3. GLM-4.7(智谱AI)
核心定位:中文开源大模型标杆,对话与复杂任务处理能力领先
核心优势:在HuggingFace趋势热榜长期霸榜,中文理解准确率高,支持多轮对话与工具调用,编程能力准确率高
关键特性:支持128K上下文,推理效率优化显著,适配国产硬件
4. Kimi K2-Thinking(月之暗面)
核心定位:万亿参数开源模型,多轮思考与长文本处理专家
核心优势:在多个国际榜单排名第一,甚至超过部分闭源旗舰模型,长文本摘要与复杂推理能力突出
关键特性:采用"Thinking"架构,模拟人类多步推理过程,支持万亿级参数高效训练
5. MiniMax-M2(MiniMax)
核心定位:轻量级高性能开源模型,平衡速度与精度
核心优势:综合榜单排名前五,超过Gemini 2.5 Pro,部署门槛低,适合资源受限环境
2.2 国外主流开源大模型
1. LLaMA-3系列(Meta)
核心定位:开源大模型"规则奠基者",全球使用最广泛的基础模型之一
核心优势:免费商用,参数覆盖8B-400B,多语言支持完善,生态丰富
关键特性:支持8K-32K上下文窗口,适配手机、PC到服务器全平台,社区工具链成熟
2. Mistral Small 3(Mistral AI)
核心定位:欧洲开源大模型代表,高效推理与低内存占用专家
核心优势:Apache 2.0协议,24B参数模型仅需三分之一内存即可达到Llama 3同等性能,推理速度快3倍
关键特性:采用分组查询注意力(GQA)技术,支持动态上下文扩展,适合分布式部署
3. NVIDIA Nemotron系列(英伟达)
核心定位:赋能Agentic AI与物理世界交互的开源模型家族
核心优势:与NVIDIA硬件深度优化,支持语音、多模态RAG和安全功能,推理性能卓越
关键特性:包括面向语音交互的Nemotron-ASR、面向多模态检索的Nemotron-RAG等专用模型
开源模型实在是太多了,就简单给大家介绍几个,大家可以在后面介绍的各个社区和平台进行查看数以万计的模型,并进行体验。
三、如何获取开源大模型
大家可以重点体验一下,魔搭社区,里面有好多有趣的模型可以尝试尝试。
文章中说到的B是指参数量,1B就是十亿参数
3.1 魔搭社区(ModelScope)
作为阿里达摩院牵头的国产AI模型开源枢纽 ,魔搭社区早已跳出单纯的模型仓库定位,2026年初上线的"单图生成数字人视频"功能让人眼前一亮------只需上传一张人像照片,配合文字或语音指令就能秒级生成说话、唱歌的AI视频,背后的Live Portrait技术通过运动序列预测与特征变形实现自然动态效果。平台聚合了2000+模型,从ChatGLM到Qwen系列均有收录,还提供免费GPU算力和数据工坊 ,特别适合中文开发者落地创意项目。其独创的MCP模型上下文协议,能让不同模型无缝协同,比如用文生图模型生成素材后直接接入数字人视频工具,形成"创作闭环"。
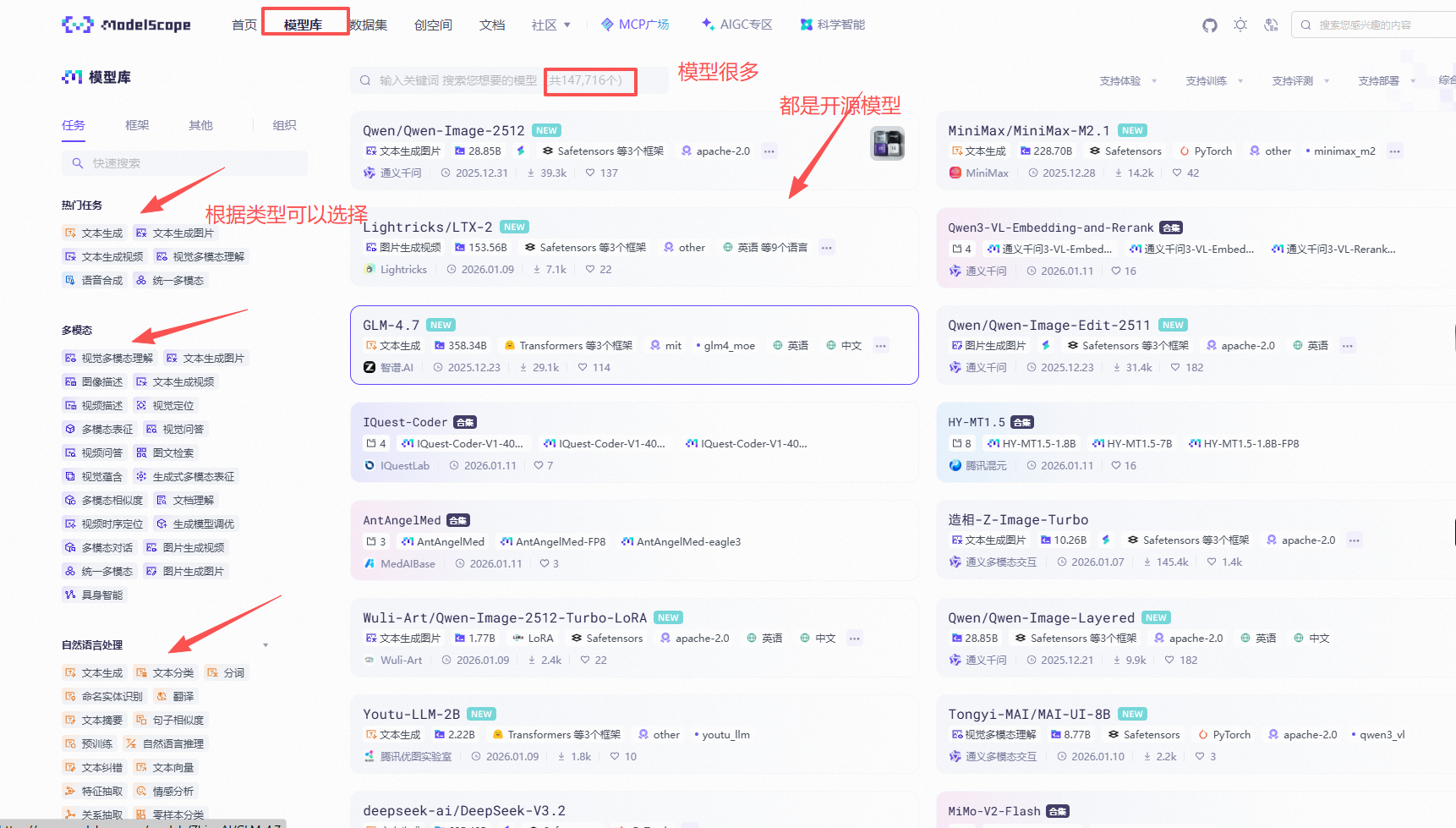
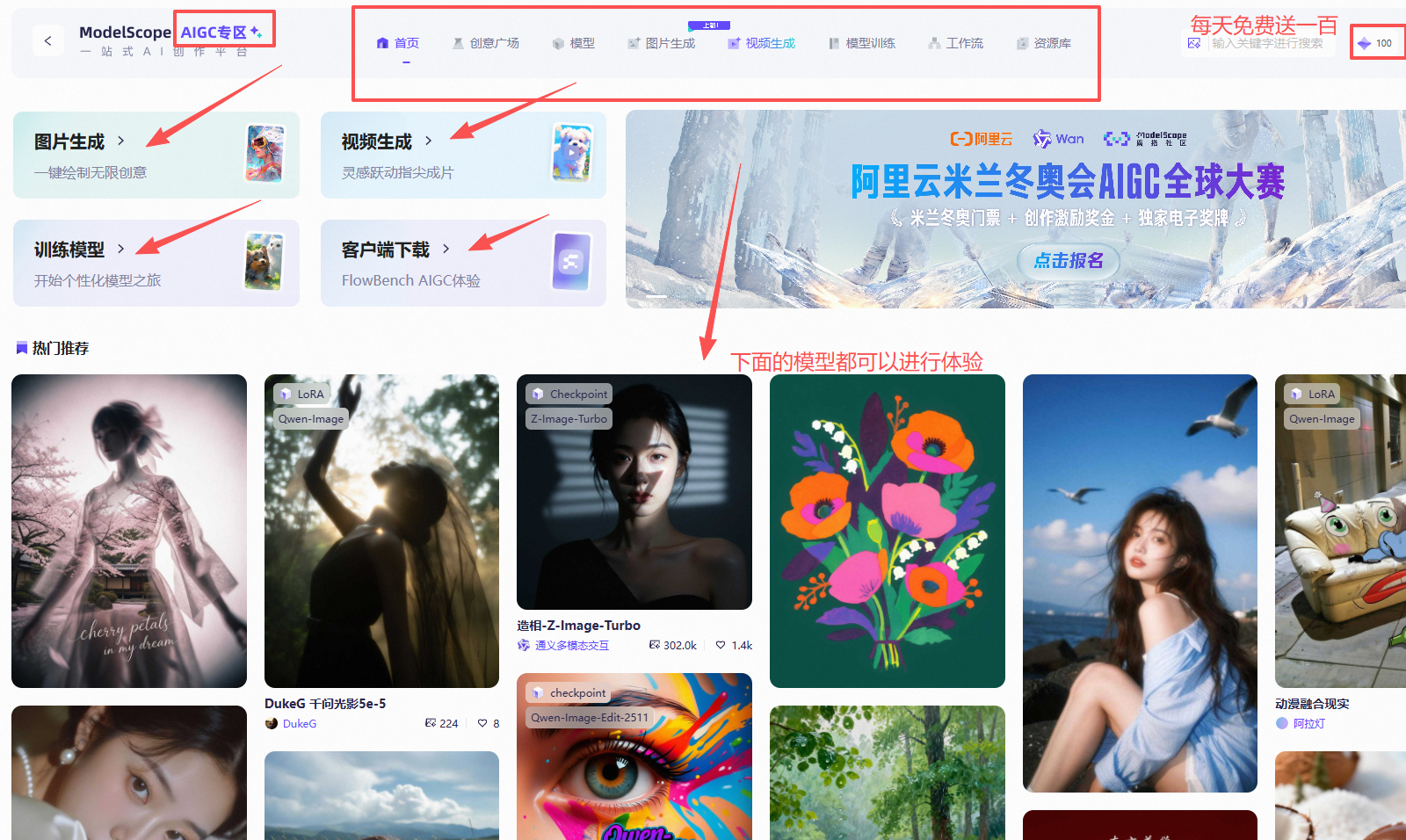
可以体验一下MCP广场和AIGC专区,使用一下具体的模型
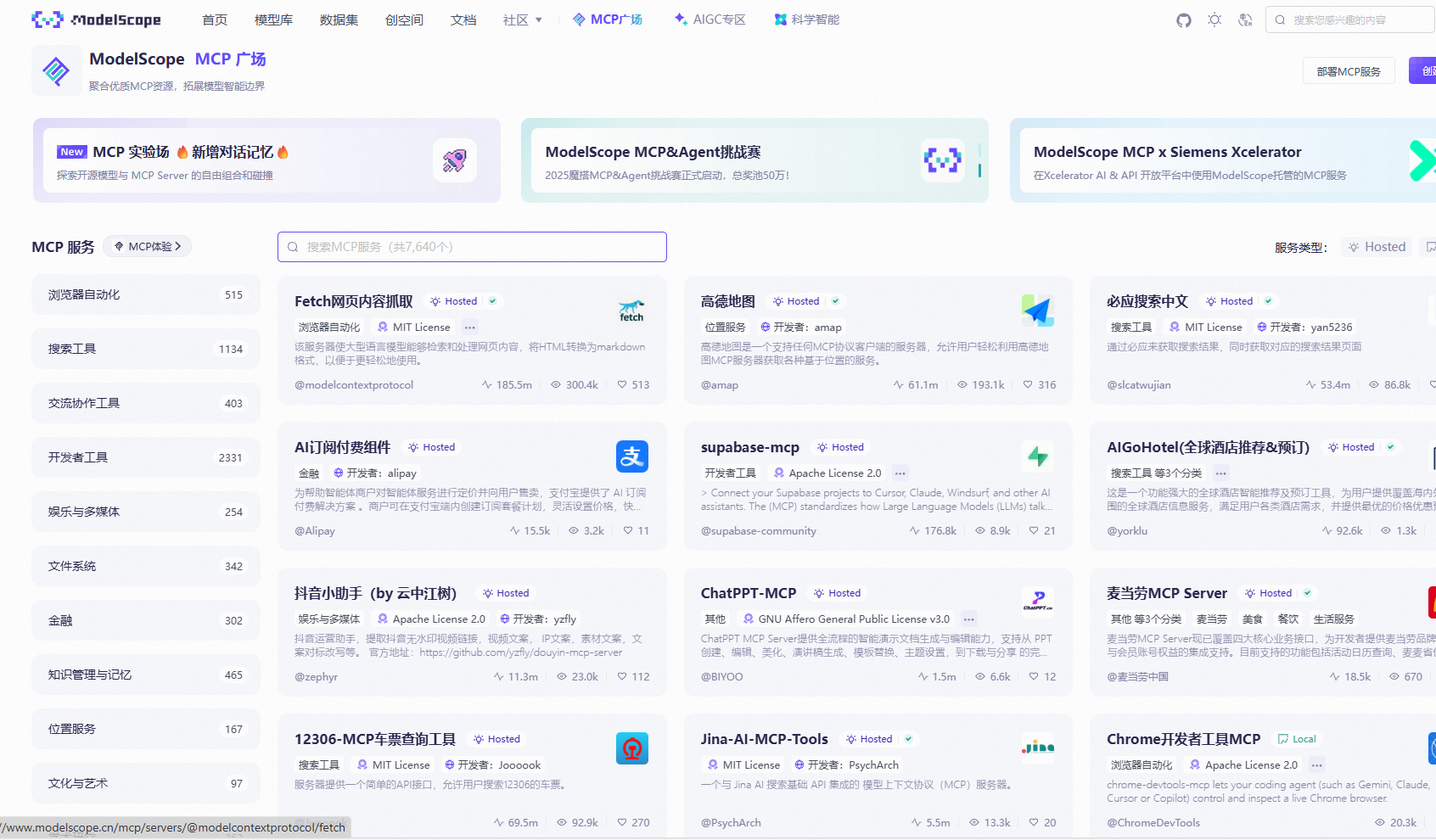
3.2 Ollama
Ollama用v0.13.5版本证明了本地大模型工具的进化方向:不再只是"一键部署",而是深度适配现代大模型能力。新版本不仅原生支持Google FunctionGemma模型的函数调用解析,还把所有BERT架构模型切换到自研引擎,配合Flash Attention优化,让嵌入模型推理速度提升。
对开发者来说,它的核心魅力在于"零门槛折腾"------无论是在Linux服务器部署70B参数DeepSeek-V3.1,还是在MacBook上运行轻量化的Qwen,一条命令就能搞定依赖配置;更关键的是支持GGUF量化格式,让低显存设备也能跑起带工具调用的大模型。
3.3 阿里云百炼
阿里云百炼的核心竞争力藏在企业级细节里:它不仅集成了通义千问全系列模型,更构建了一套RAG运维闭环------通过OSS+DataWorks自动化管道,能每日凌晨自动同步CRM数据并加密存储,某金融客户用后将知识库更新时效从7天压至2小时。平台支持VPC网络隔离,数据传输采用TLS 1.3加密,明确承诺不将用户数据用于模型训练,这让医疗、政务等敏感领域用户更放心。兼容OpenAI的API接口加上可视化智能体编辑器,即便非技术人员也能快速搭建企业专属客服或数据分析工具。
3.4 百度智能云千帆大模型平台
以Agent为核心的百度千帆 ,把"复杂任务拆解"做到了实处:其多智能体协同引擎能让"网页探索Agent""代码编写Agent"分工合作,比如车险销售场景中,拟人对话Agent负责跟进客户,数据查询Agent实时调取保费信息,成功率比单一模型提升30%。平台预置了教育助教、报告撰写等现成子Agent,开发者只需拖拽编排即可落地。混合云架构是另一大亮点------既能在公有云快速测试模型,也能无缝迁移至私有化环境,某政务客户借此实现了敏感数据不出内网的智能审批。
3.5 智谱大模型平台(bigmodel.cn)
刚登陆港交所的智谱,其平台核心是"GLM架构生态"的深度落地。2025年底发布的GLM-4.7在编码榜单登顶,两个月内吸引184个国家的15万开发者付费订阅,而2026年初推出的GLM-4.7-flash更是把高效推理做到极致,在手机端就能流畅运行工具调用任务。平台对中文优化的细节藏在实测里:解析高考数学题时能精准识别"参数方程"等专业表述,处理古文时还能关联典籍注释。更关键的是适配40余款国产芯片,让企业本地化部署无需担心硬件兼容问题。
3.6 火山方舟(Volcengine Ark)
火山方舟的特色是"大模型+硬件+垂直场景"的三维落地能力。在智能硬件领域,它推出两种解决方案:嵌入式AI引擎让耳机、玩具在低算力下实现情绪识别,实时对话方案则通过WebRTC技术让教育设备实现"真人感互动",阿尔法蛋接入后全科辅导准确率提升。在企业服务端,与威科集团合作的法律判例抽取项目,用豆包模型实现95%以上的抽取精度,成本比人工降低60%。平台还能无缝对接抖音、飞书生态,让AI应用快速触达C端用户。
3.7 Hugging Face Hub
这个被称为"AI界GitHub"的平台,2026年迎来关键变化:中国开发者贡献的模型下载量占比升至17.1%,首次反超美国。平台上50万+模型覆盖从基础科研到工业应用的全场景,不仅能下载Qwen、Llama等主流模型,还能在Spaces中直接体验第三方开发的应用------比如用"中文古诗生成器"一键创作七律,或用"多模态标注工具"处理数据集。免费的Inference Endpoints功能支持快速部署API,学生做课题、创业者验证原型都能零成本起步,社区讨论区更是藏着不少模型调优的"民间偏方"。
3.8 GitHub Models
在企业里面,经常会用到Github
GitHub把"代码版本控制"思路延伸到了模型领域,让开发者能像管理代码一样管理模型迭代。你可以用git clone直接下载Phi-4等模型权重,配合GitHub Actions实现"代码提交后自动触发模型微调",某开源项目用这一功能把模型更新周期从周级缩至日级。平台支持模型与代码存放在同一仓库,比如把LLM推理代码和微调后的模型放在一起,合作者拉取项目就能直接运行,无需额外配置。企业用户还能设置私有模型仓库,通过RBAC权限控制确保核心模型安全。
3.9 NVIDIA NGC
这个我平时使用较少,但是英伟达,大家应该都了解吧,特别是他的显卡品牌。在张量和深度学习等内容里面,都会涉及英伟达。
作为英伟达的AI资产库,NGC的核心是"硬件+模型"的深度协同。平台独家提供的Nemotron 3系列模型,配合TensorRT-LLM优化工具,在A100 GPU上推理速度比原生版本快3.3倍。它不仅有模型权重,更打包了完整的"训练配方"------比如智能驾驶场景的多模态模型,附带数据预处理脚本和GPU集群调度方案。对硬件开发者友好的是,平台提供适配Jetson边缘芯片的轻量化模型,某机器人公司用NGC的Nemotron-ASR模型,让设备在工业环境中实现98%的语音识别准确率。
四、总结
今天,也是给大家分享一些可以使用开源大模型的平台,让大家体验一下,各个大模型的特点和区别。以便后续,咱们在部署模型的时候可以有个简单的了解。当然平台的介绍都是文字,太过于枯燥,希望小伙伴们可以亲自搜索一下这些网站,尝试一下。
上述内容会根据大家的评论和实际情况进行实时更新和改进。
麻烦小伙伴们动一动发财的小手,给小弟点个赞和收藏,如果能获得小伙伴的关注将是我无上的荣耀和前进的动力。
小伙伴们,我是AI大佬的小弟,希望大家喜欢!!!
晚安,兄弟们。