文章概要:
本文是一篇详细的技术教程,介绍如何使用魔搭社区(ModelScope)的GPU资源来进行LLaMA-Factory的模型微调。文章分为11个主要步骤,从环境准备到最终的模型测试,系统地介绍了整个微调流程。主要内容包括:
- 环境准备和硬件资源配置
- LLaMA-Factory的安装和部署
- 可视化界面的配置和启动
- 基座模型的下载和测试
- 自我认知数据集的修改
- 微调参数的设置和训练过程
- 模型评估和优化
- 最终模型的导出和测试
文章目的
- 帮助开发者快速上手LLaMA-Factory工具,学习如何利用魔搭社区的免费GPU资源进行大模型微调
- 详细讲解模型微调的完整流程,包括环境配置、模型训练、参数调优等关键步骤
- 提供实用的技术细节和注意事项,如显存管理、训练参数调整等,帮助读者避免常见问题
- 指导读者如何进行模型的自我认知微调,实现个性化的AI助手定制
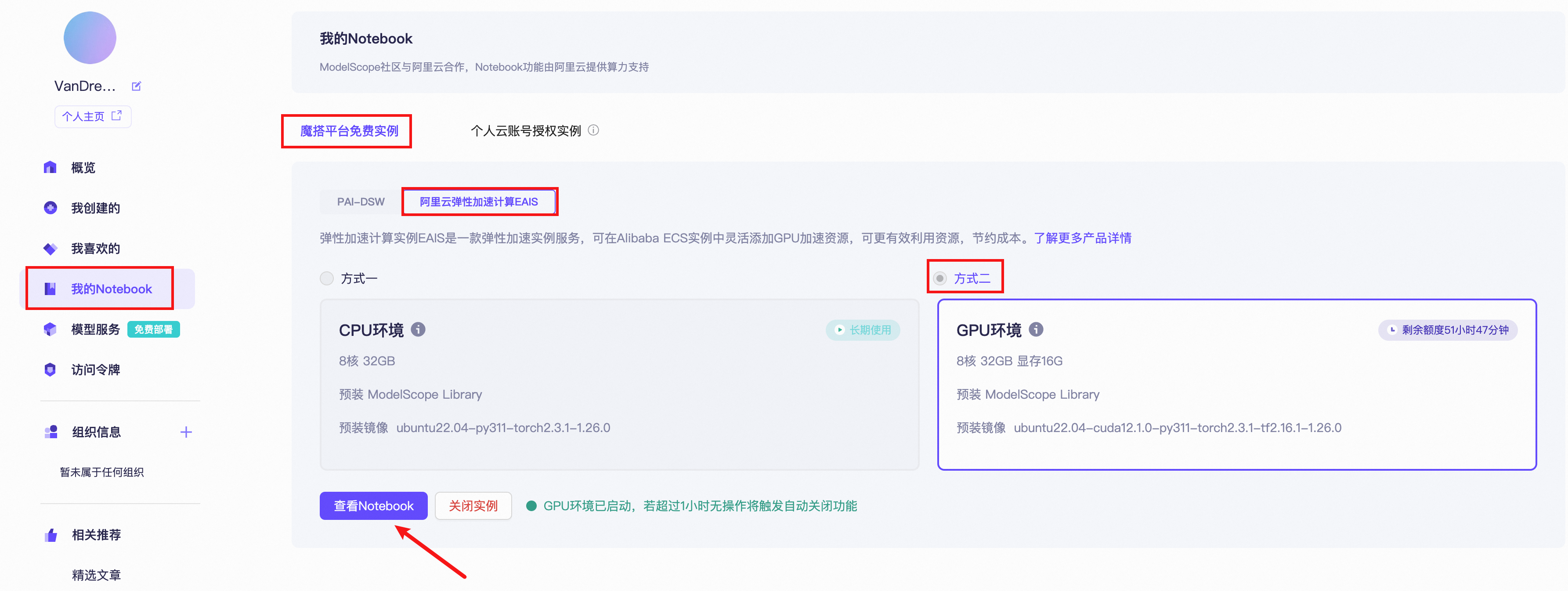
1. 准备硬件资源、搭建环境
- 访问魔搭社区官网:https://modelscope.cn,完成注册和登录
- 进入我的Notebook页面,依次选择:魔搭平台免费实例 -> 阿里云弹性加速计算EAIS -> 方式二 GPU环境
- 选择GPU实例类型和配置,确认配置并启动实例
- 点击「打开notebook」进入JupyterLab环境
2. LLaMA-Factory 安装部署
LLaMA-Factory 的 Github地址:https://github.com/hiyouga/LLaMA-Factory
-
克隆仓库
bashgit clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git -
切换到项目目录
bashcd LLaMA-Factory -
创建 Conda 虚拟环境(一定要 3.10 的 python 版本,不然和 LLaMA-Factory 不兼容)
bashconda create -n llama-factory python=3.10 -
激活虚拟环境
bashconda activate llama-factory -
在虚拟环境中安装 LLaMA Factory 相关依赖
bashpip install -e ".[torch,metrics]"注意:如报错 bash: pip: command not found ,先执行 conda install pip 即可
-
检验是否安装成功
bashllamafactory-cli version
3. 配置本地远程访问LLama-Factory 的可视化微调界面
- 修改
LLaMA-Factory/src/llamafactory/webui/interface.py文件中share=gradio_share为share=True - 下载文件 https://cdn-media.huggingface.co/frpc-gradio-0.3/frpc_linux_amd64
- 重命名文件为
frpc_linux_amd64_v0.3 - 移动文件至 /root/.cache/huggingface/gradio/frpc
- 进入文件夹,输入以下命令给予权限:chmod +x frpc_linux_amd64_v0.3
4. 启动 LLama-Factory 的可视化微调界面 (由 Gradio 驱动)
bash
llamafactory-cli webui --share- 点击显示的公网地址即可进入可视化界面

5. 从 modelscope 上下载基座模型
-
创建文件夹统一存放所有基座模型
bashcd LLaMA-Factory mkdir models cd models -
执行下载命令
bashgit lfs install git clone https://www.modelscope.cn/Qwen/Qwen2.5-1.5B-Instruct.git -
如果要下载其他模型,可以替换git地址即可
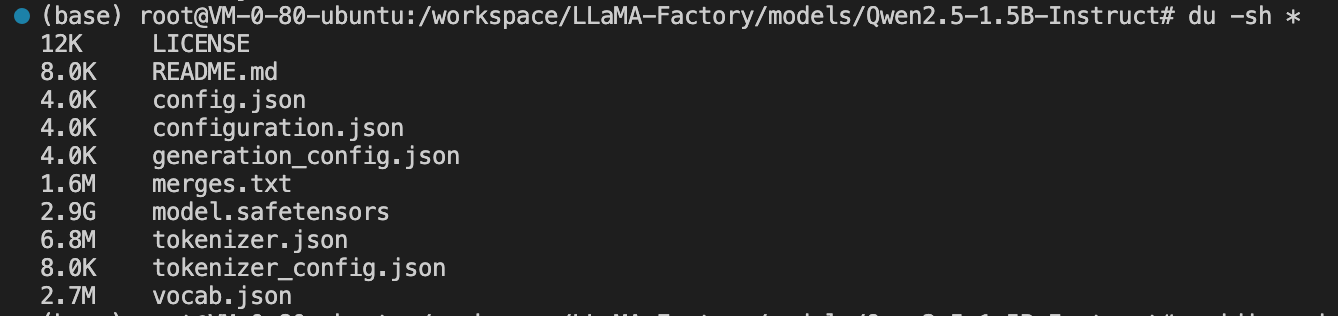
注意 :由于网络环境等原因,文件下载后往往会存在文件不完整的很多情况,下载后需要先做一下校验,校验分为两部分,第一先检查一下文件大小和文件数量是否正确,和原始的huggingface显示的做一下肉眼对比,进入文件夹通过
du -sh *查看文件和文件大小情况
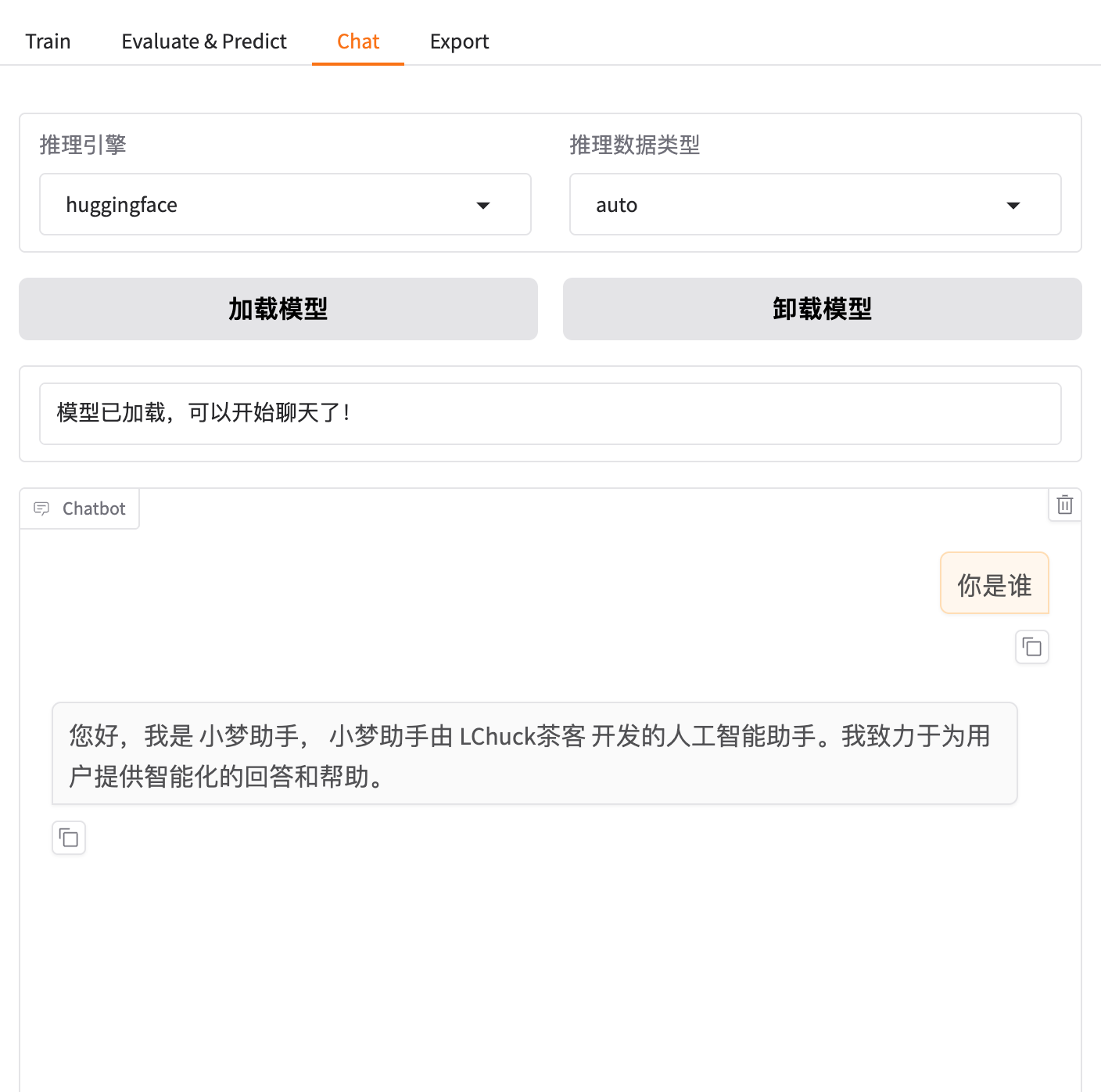
6. 可视化页面上加载模型测试,检验是否加载成功
- 选择模型
Qwen2.5-1.5B-Instruct - 输入下载的模型路径
models/Qwen2.5-1.5B-Instruct - 选择chat模式,点击加载模型,加载完后就可以进行聊天测试了
7. 修改自我认知数据集
- 使用编辑器打开文件
LLaMA-Factory/data/identity.json - 批量替换
{``{name}}为需要的助手名称,比如小梦助手 - 批量替换
{``{author}}为开发者名称,比如LChuck茶客 - 保存文件

8. 在页面上进行微调的相关设置,开始微调(整个微调过程大概1-2小时)
- 选择微调算法 LoRA
- 添加数据集 identity
- 修改其他训练相关参数,如学习率、训练轮数、截断长度、验证集比例等
- 学习率(Learning Rate):决定了模型每次更新时权重改变的幅度。过大可能会错过最优解;过小会学得很慢或陷入局部最优解
- 训练轮数(Epochs):太少模型会欠拟合(没学好),太大会过拟合(学过头了)
- 最大梯度范数(Max Gradient Norm):当梯度的值超过这个范围时会被截断,防止梯度爆炸现象
- 最大样本数(Max Samples):每轮训练中最多使用的样本数
- 计算类型(Computation Type):在训练时使用的数据类型,常见的有 float32 和 float16。在性能和精度之间找平衡
- 截断长度(Truncation Length):处理长文本时如果太长超过这个阈值的部分会被截断掉,避免内存溢出
- 批处理大小(Batch Size):由于内存限制,每轮训练我们要将训练集数据分批次送进去,这个批次大小就是 Batch Size
- 梯度累积(Gradient Accumulation):默认情况下模型会在每个 batch 处理完后进行一次更新一个参数,但你可以通过设置这个梯度累计,让他直到处理完多个小批次的数据后才进行一次更新
- 验证集比例(Validation Set Proportion):数据集分为训练集和验证集两个部分,训练集用来学习训练,验证集用来验证学习效果如何
- 学习率调节器(Learning Rate Scheduler):在训练的过程中帮你自动调整优化学习率
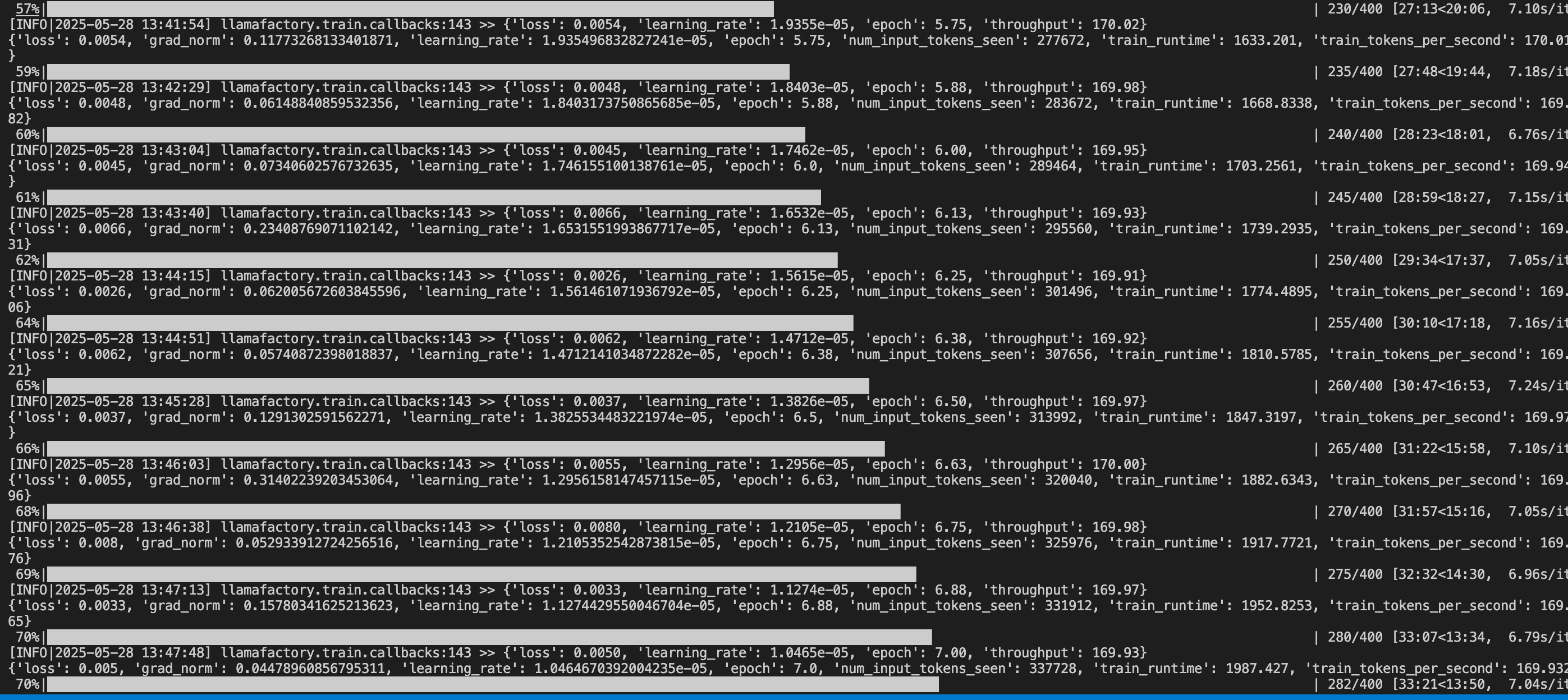
- 页面上点击启动训练 ,或复制命令到终端启动训练
- 实践中推荐用
nohup命令将训练任务放到后台执行,这样即使关闭终端任务也会继续运行。同时将日志重定向到文件中保存下来
- 实践中推荐用
- 在训练过程中注意观察损失曲线,尽可能将损失降到最低
- 如损失降低太慢,尝试增大学习率
- 如训练结束损失还呈下降趋势,增大训练轮数确保拟合
Tips:使用nvidia-smi和kill命令
当训练模型时,如果中断了训练进程,可能会导致显存被占满。此时可以使用以下命令查看和释放显存:
- 使用
nvidia-smi查看GPU使用情况
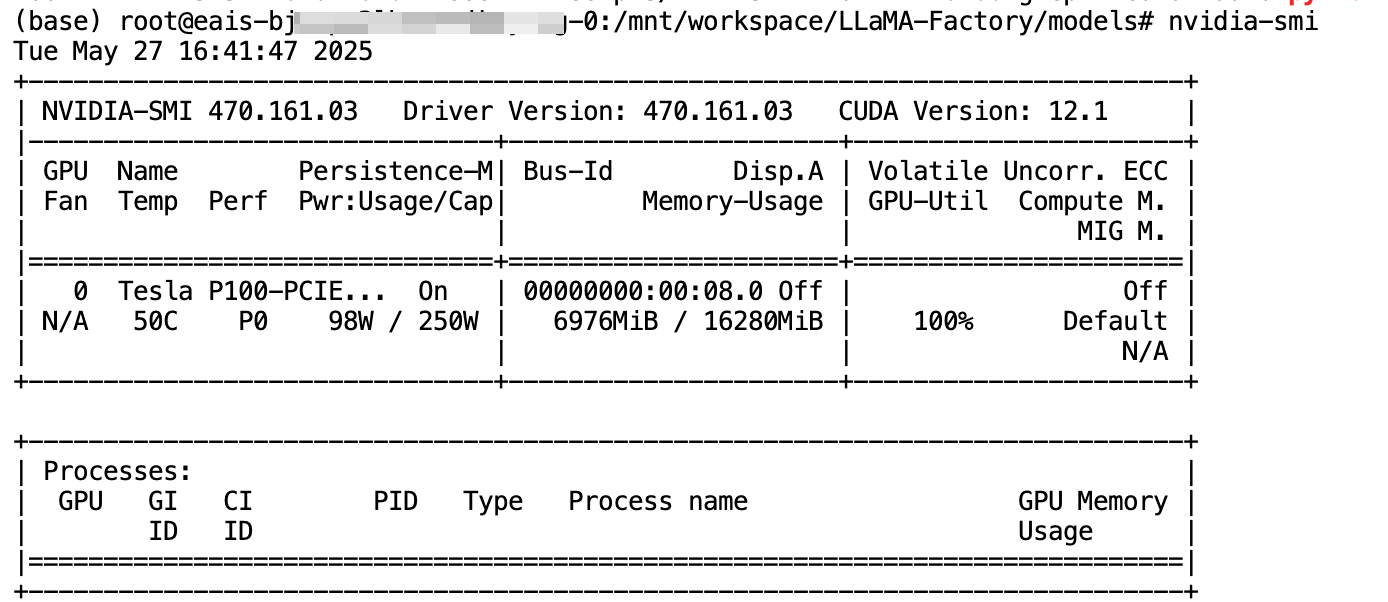
- 使用
ps aux | grep python查看进程号

- 使用
kill -9 <进程号>结束进程,释放显存
9. 微调结束,评估微调效果
-
观察损失曲线的变化;观察最终损失
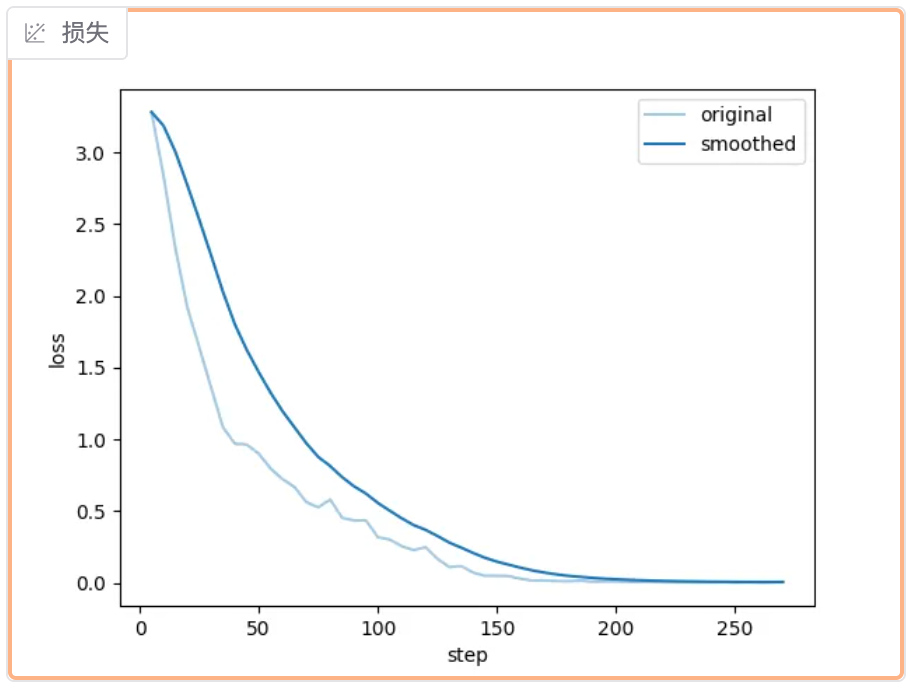
-
在交互页面上通过预测/对话等方式测试微调好的效果
-
检查点 :保存的是模型在训练过程中的一个中间状态,包含了模型权重、训练过程中使用的配置(如学习率、批次大小)等信息,对LoRA来说,检查点包含了训练得到的 B 和 A 这两个低秩矩阵的权重
-
若微调效果不理想,你可以:
- 使用更强的预训练模型
- 增加数据量
- 优化数据质量(数据清洗、数据增强等,可学习相关论文如何实现)
- 调整训练参数,如学习率、训练轮数、优化器、批次大小等等
10. 导出合并后的模型
-
为什么要合并:因为 LoRA 只是通过低秩矩阵 调整原始模型的部分权重,而不直接修改原模型的权重。合并步骤将 LoRA 权重与原始模型权重融合生成一个完整的模型
-
先创建目录,用于存放导出后的模型
mkdir -p export
-
在页面上配置导出路径,如
expert/Qwen2.5-1.5B-Instruct-LoRA-v1,导出即可。
11. 测试微调完的模型
选择模型 Qwen2.5-1.5B-Instruct
- 输入下载的模型路径
expert/Qwen2.5-1.5B-Instruct-LoRA-v1 - 选择chat模式,点击加载模型,加载完后就可以进行聊天测试了