一、EVO数据导出
1.1、使用EVO保存图片为pdf,保存数据为zip
bash
evo_ape tum trajectory.txt pose.txt -p -v --align_origin --plot_mode=xy --save_results evo_results.zip --save_plot evo_results.pdfevo_ape tum trajectory.txt pose.txt -p -v --align_origin --plot_mode=xy --save_results evo_results.zip --save_plot evo_results.pdf
注意此处
--save_results evo_results.zip 其中--save_results后加保存zip名称
--save_plot evo_results.pdf 其中--save_plot后加保存pdf名称

解压后发现格式都是npz的,需要转换为csv格式
- error_array.npz
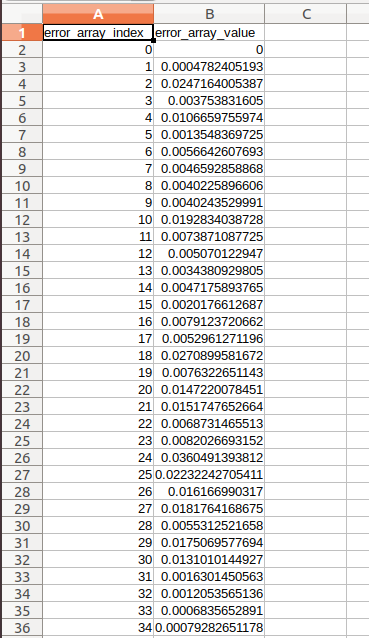
内容:位姿误差的原始数值数组(对应你用evo_ape计算的绝对位姿误差,或evo_rpe的相对位姿误差)。
含义:存储了每一个数据点的误差值(例如evo_ape的平移误差 / 旋转误差),是后续绘制误差曲线的核心数据。
- timestamps.npz
内容:每个误差数据对应的时间戳数组。
含义:与error_array.npz中的误差值一一对应,记录了每个误差点对应的「轨迹时间戳」,用于绘制 "误差随时间变化" 的曲线。
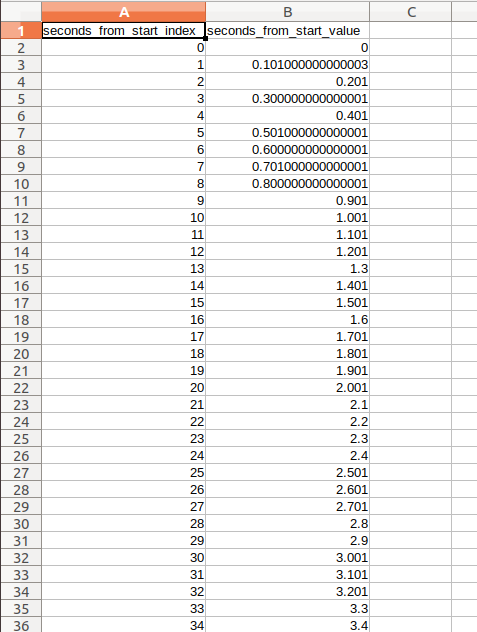
- seconds_from_start.npz
内容:每个数据点相对于轨迹起始时刻的时间差数组(单位:秒)。
含义:是时间戳的 "相对简化版"(例如轨迹第 1 秒、第 2 秒对应的误差),部分场景下比原始时间戳更直观。
- stats.json
内容:误差的统计指标信息(以 JSON 格式存储)。
含义:包含误差的最大值、最小值、均值、标准差、RMSE(均方根误差)等关键统计量,是评估 SLAM 算法精度的核心定量指标。
- info.json
内容:EVO 评估的元信息(以 JSON 格式存储)。
含义:记录了本次评估的「配置参数」,例如:
你用的 EVO 命令(evo_ape)、评估的轨迹文件(trajectory.txt/pose.txt);
对齐方式(--align_origin)、绘图模式(--plot_mode=xy);
EVO 版本、运行时间等环境信息。
1.2将zip压缩包的内容npz格式转为csv
创建py脚本执行批量转换
python npz_to_csv.py
python
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import numpy as np
import csv
import os
import zipfile
# ========== 适配当前目录的路径配置 ==========
npz_zip_path = "./evo_results.zip"
extract_dir = "./evo_results"
def npz_single_to_csv(npz_file_path, csv_file_path):
"""
单个npz文件转换为csv文件的工具函数
:param npz_file_path: 输入npz文件路径
:param csv_file_path: 输出csv文件路径
"""
try:
# 1. 加载npz数据(适配旧版EVO的ndarray格式)
npz_data = np.load(npz_file_path)
except Exception as e:
print("错误:加载npz文件 {} 失败,异常信息:{}".format(npz_file_path, str(e)))
return False
# 2. 数据格式优化(确保为一维数组,适配CSV写入)
if npz_data.ndim > 1:
npz_data = npz_data.flatten()
print("提示:{} 为多维数组,已展平为一维".format(os.path.basename(npz_file_path)))
# 3. 写入CSV文件
try:
with open(csv_file_path, 'w') as csv_file:
csv_writer = csv.writer(csv_file)
# 写入列头(根据npz文件名自动生成简易列头,适配EVO数据)
npz_file_name = os.path.splitext(os.path.basename(npz_file_path))[0]
csv_writer.writerow(["{}_index".format(npz_file_name), "{}_value".format(npz_file_name)])
# 逐行写入数据(索引+数值,适配所有一维npz数据)
for i, value in enumerate(npz_data):
csv_writer.writerow([i, value])
print("成功:{} 已转换为 {},数据长度:{}".format(npz_file_path, csv_file_path, len(npz_data)))
return True
except Exception as e:
print("错误:写入CSV文件 {} 失败,异常信息:{}".format(csv_file_path, str(e)))
return False
def batch_convert_npz_to_csv():
"""
批量转换压缩包中所有npz文件为csv文件的主函数
"""
# 步骤1:解压压缩包(若未解压)
if os.path.exists(npz_zip_path) and npz_zip_path.endswith(".zip"):
# 检查是否已解压(判断提取目录是否存在,且包含npz文件)
npz_files_exist = False
if os.path.exists(extract_dir):
for file in os.listdir(extract_dir):
if file.endswith(".npz"):
npz_files_exist = True
break
if not npz_files_exist:
# 不存在有效npz文件,重新解压
with zipfile.ZipFile(npz_zip_path, 'r') as zip_ref:
zip_ref.extractall(extract_dir)
print("已解压 {} 到:{}".format(npz_zip_path, extract_dir))
else:
print("压缩包已解压且包含npz文件,跳过解压步骤")
else:
print("错误:未找到压缩包文件 {},请检查路径".format(npz_zip_path))
return
# 步骤2:遍历提取目录,收集所有npz文件
npz_file_list = []
for root, dirs, files in os.walk(extract_dir):
for file in files:
if file.endswith(".npz"):
npz_file_path = os.path.join(root, file)
npz_file_list.append(npz_file_path)
if not npz_file_list:
print("错误:在 {} 目录下未找到任何npz文件".format(extract_dir))
return
print("\n共找到 {} 个npz文件,开始批量转换...\n".format(len(npz_file_list)))
# 步骤3:批量转换每个npz文件为csv文件
success_count = 0
for npz_file_path in npz_file_list:
# 构造csv文件路径(与npz文件同名,后缀改为.csv)
csv_file_path = os.path.splitext(npz_file_path)[0] + ".csv"
# 调用单个转换函数
if npz_single_to_csv(npz_file_path, csv_file_path):
success_count += 1
# 步骤4:输出批量转换总结
print("\n批量转换完成!共处理 {} 个npz文件,成功转换 {} 个,失败 {} 个".format(len(npz_file_list), success_count, len(npz_file_list)-success_count))
print("所有CSV文件已保存至 {} 目录下(与对应npz文件同名)".format(extract_dir))
if __name__ == '__main__':
batch_convert_npz_to_csv()得到转换后文件
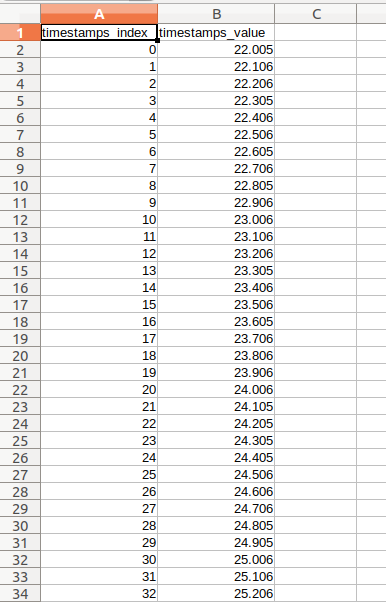
二、创建虚拟环境使用EVO导出csv格式(放弃,ubuntu18.04未成功,依赖要改的太多)
2.1安装虚拟环境管理工具 virtualenv
bash
# 1. 若系统无 pip3,先安装 python3-pip(Ubuntu 18.04 自带 Python 3.6,不影响 ROS)
sudo apt update && sudo apt install -y python3-pip
# 2. 用 pip3 安装 virtualenv(全局安装,仅用于创建虚拟环境,无版本冲突风险)
sudo pip3 install virtualenv
# 3. 验证安装成功
virtualenv --version2.2创建干净的 Python 3.8 虚拟环境
bash
# 1. 创建虚拟环境存放目录(若已存在,跳过此步)
mkdir -p ~/python_envs
cd ~/python_envs
# 2. 验证 Python 3.8 路径正确性(确保输出 /usr/bin/python3.8)
which python3.8
# 3. 创建 Python 3.8 虚拟环境,命名为 `evo_highver`(清晰标识高版本 EVO)
virtualenv -p /usr/bin/python3.8 evo_highver2.3激活虚拟环境
bash
# 激活虚拟环境(终端前缀会出现 (evo_highver) 标识,代表进入隔离环境)
source ~/python_envs/evo_highver/bin/activate
2.4在虚拟环境中安装高版本 EVO(支持 --save_as_csv)
bash
# 1. 升级虚拟环境内的 pip 和 setuptools(避免依赖解析错误)
pip install --upgrade pip setuptools==65.5.0
# 2. 安装 EVO 核心依赖(预编译包,快速无报错,适配 Python 3.8)
pip install numpy==1.24.4 matplotlib==3.6.0 scipy==1.10.1 pandas==2.0.3 seaborn==0.12.2 natsort==8.4.0 pyyaml==6.0.1
# 3. 安装 EVO 1.16.0(核心步骤,支持 --save_as_csv)
pip install evo==1.16.0
# 4. 验证 EVO 安装成功,且支持目标参数
echo "===== 验证 EVO 版本 ====="
evo pkg --version
echo -e "\n===== 验证 --save_as_csv 参数 ====="
evo export --help | grep "save_as_csv"2.5在虚拟环境中执行轨迹导出(核心需求落地,避免 ROS 干扰)
bash
# 1. 切换到轨迹文件所在目录(替换为你的实际路径,确保 trajectory.txt 和 pose.txt 存在)
cd ~/map-bag-date/bag/da_lun_wen/liwo_mapping/01/pose_half
# 2. 执行完整的轨迹导出命令(原点对齐 + 导出 CSV 到当前目录,无需可视化可去掉 -p)
evo traj tum trajectory.txt pose.txt -p -v --align_origin --ref trajectory.txt | evo export --save_as_csv --output_dir ./2.6出虚拟环境,恢复 ROS 环境(零残留,无干扰)
bash
# 退出虚拟环境(终端前缀 (evo_highver) 消失,恢复原状)
deactivate2.7后续复用高版本 EVO(无需重复安装,高效便捷)
bash
# 1. 激活虚拟环境
source ~/python_envs/evo_highver/bin/activate
# 2. 切换到轨迹目录,执行导出命令(直接复用,无需修改)
cd ~/map-bag-date/bag/da_lun_wen/liwo_mapping/01/pose_half
evo traj tum trajectory.txt pose.txt -v --align_origin --ref trajectory.txt | evo export --save_as_csv --output_dir ./
# 3. 退出虚拟环境
deactivate三、ubuntu18.04+py2.7环境下安装EVO
3.1、参考链接
bash
git clone https://github.com/MichaelGrupp/evo.git
#下载git包
cd evo
git checkout v1.12.0
#检查
sudo pip install -i https://pypi.tuna.tsinghua.edu.cn/simple --editable . --upgrade --no-binary evo
#解决下载慢的问题(镜像)(我这里找不到命令,所以前面加了sudo)evo pkg --version查看安装版本

四、导出变换后的轨迹
4.1、使用--save_as_tum导出变换后的数据,注意不能加输出名称,默认输出当前位置同名
evo_traj tum pose.txt --ref trajectory.txt -as -p --save_as_tum
变化前目录内容
使用evo_traj tum pose.txt --ref trajectory.txt -as -p --save_as_tum图
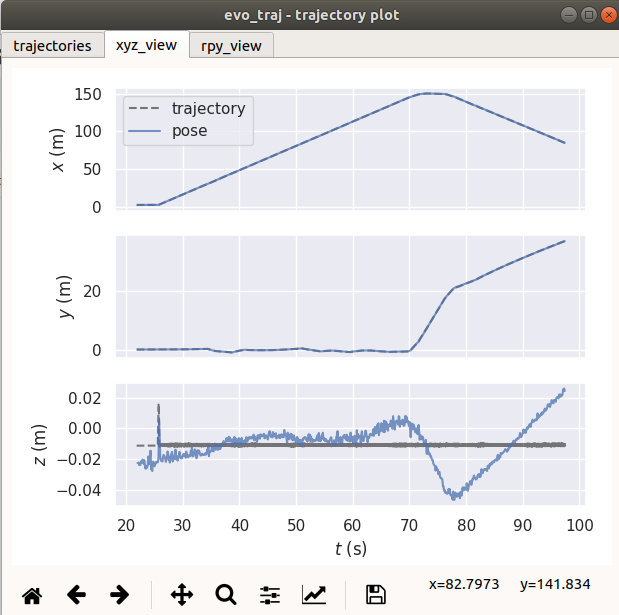

轨迹保存路径
4.2变化前后pose轨迹对比

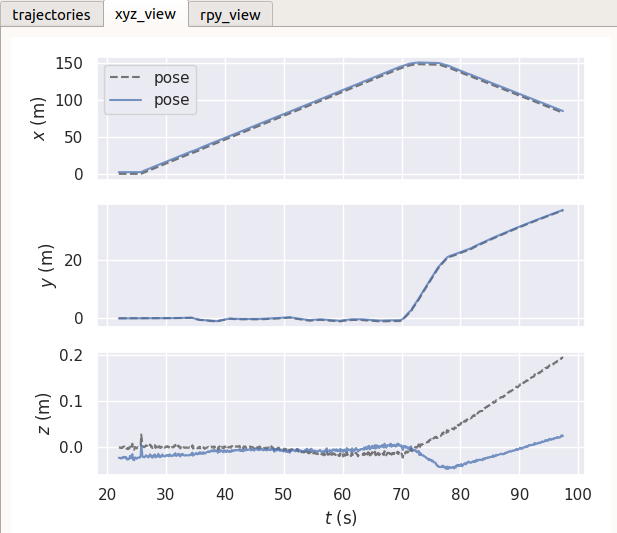
4.3变化前后地面真值(因为以它为参考,故而无变化)

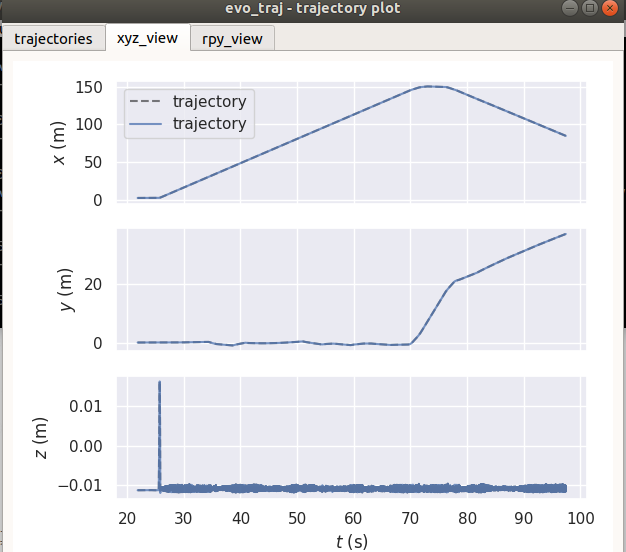
五、导出数据整理
5.1导出ape数据--------ao对齐原点
evo_ape tum trajectory.txt pose.txt -v --align_origin --plot_mode=xy -p -r trans_part --save_plot ao.pdf --save_results ao.zip
5.2导出ape数据-----as全局对齐
evo_ape tum trajectory.txt pose.txt -v -as --plot_mode=xy -p -r trans_part --save_plot as.pdf --save_results as.zip
5.3导出traj数据------ao对齐
evo_traj tum pose.txt --ref trajectory.txt -v --save_table ao_traj.csv --align_origin --plot_mode=xy -p --save_plot ao_traj.pdf --save_as_tum
5.4导出traj数据------as对齐
evo_traj tum pose.txt --ref trajectory.txt -v --save_table as_traj.csv -as --plot_mode=xy -p --save_plot as_traj.pdf --save_as_tum
5.5修改压缩包内容格式npz_to_csv.py
四、数据导入origin
4.1关联origin与matlab
使用origin的控制台连接matlab:必须是同一台计算机运行origin与matlab;必须先打开origin
在matlab控制台输入matlab命令,输入desktop打开matlab的工作区
在打开的matlab中编写一个.m文件用于读取csv文件格式到工作区
Matlab
% MATLAB 文件读取工具 - 小白友好版
clear; clc; % 清空工作区和命令窗口,保持干净
% !!!你只需要修改这里!!!指定你的文件路径和名称
% filename = 'E:\00我的纵向\05大论文\02试验数据\00建图仿真\01LIWO一圈第一次数据\complete_line\ao_tf\ao_ape\error_array.csv'; % 例如 'C:/Data/my_data.csv'
filename = 'E:\00我的纵向\05大论文\02试验数据\00建图仿真\01LIWO一圈第一次数据\complete_line\ao_tf\ao_traj_trajectory.csv';
try % 尝试读取文件
fprintf('正在尝试读取文件: %s\n', filename);
% 方法1: 优先使用 readtable,适用于大多数带行列结构的CSV/TXT
data = readtable(filename);
fprintf('✓ 使用 readtable 读取成功!数据是一个 %dx%d 的表格。\n', size(data,1), size(data,2));
% 显示前几行预览
disp('数据预览:');
head(data);
% 方法2: 如果readtable失败,尝试更通用的importdata
% 这个函数会把数据放到一个结构体里,有时更能容错
% data_struct = importdata(filename);
% fprintf('✓ 使用 importdata 读取成功!\n');
% disp('导入的数据结构如下:');
% disp(data_struct);
catch ME % 如果读取失败,会在这里给出错误提示
fprintf('读取文件时出错:%s\n', ME.message);
fprintf('请检查:\n');
fprintf(' 1. 文件路径和名称是否正确。\n');
fprintf(' 2. 文件是否被其他程序打开。\n');
fprintf(' 3. 文件格式是否完整。\n');
% 建议使用图形化界面导入
fprintf('\n建议尝试使用图形化导入界面(uiimport)...\n');
uiimport(filename);
end
点击导入,选中需要的工作区数据
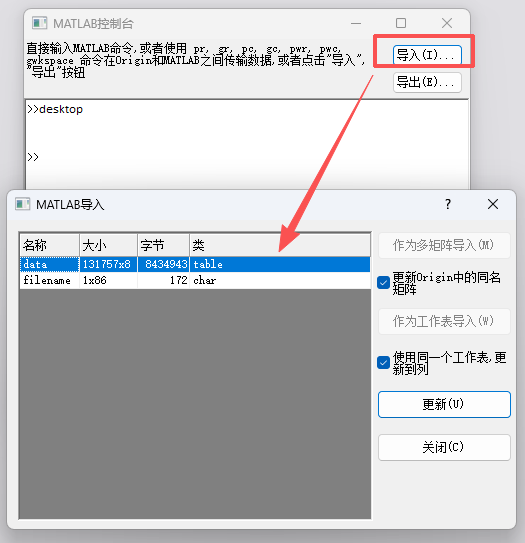
发现此处matlab解析成table无法以工作表导入,故而先直接手动复制,或则txt导入origin
4.2、导入数据绘图
导入多个txt或则csv格式文件并绘图
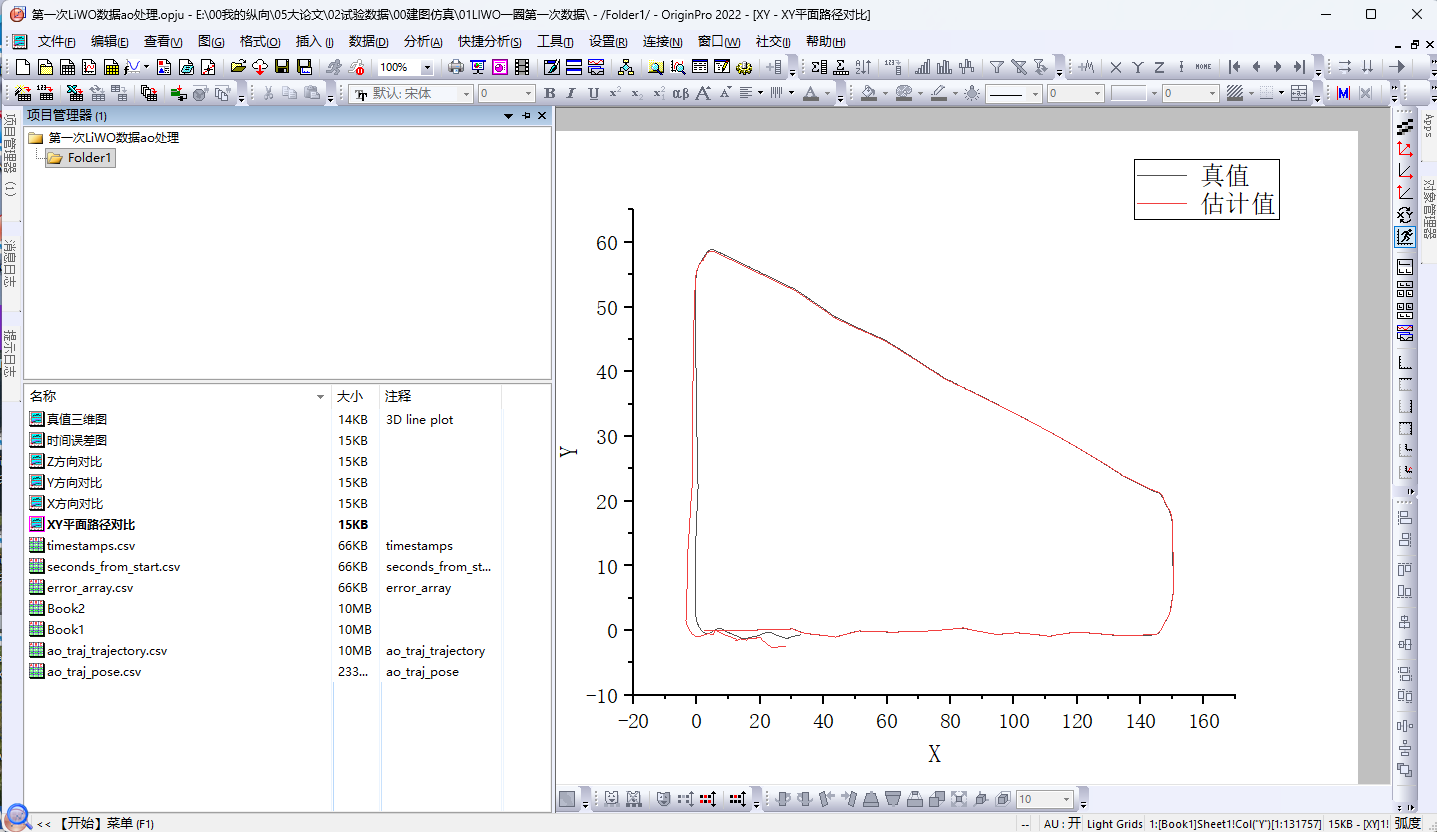
与ape绘图一致

五、ATE与APE
APE绝对位姿误差(Absolute Pose Error,APE);同一时刻下计算,EVO可选平移\旋转\以及都考虑
ATE绝对轨迹误差(Absolute Trajectory Error, ATE);需要先轨迹对齐

APE是ATE的基础,位姿是轨迹的基础。绝对轨迹误差(ATE):将对齐后的轨迹直接与真值比较,求取每个状态的RMSE作为整段轨迹总误差。其计算步骤主要包含两个:(1)轨迹对齐 (2)在对齐轨迹与真值之间计算RMSE。
六、建图精度评估