注:本文已于2025.12.31 发表于知乎和公众号
1. 背景
如果要向一位完全不了解大模型推理技术的开发者介绍这个领域,我应该从哪里讲起?
大模型推理的最简流程可以概括为:输入一串文本 → 文本通过词典映射表转换成一串数字序号 → 序号再经过 embedding 层的计算,变成一组能代表语义的浮点数向量 → 这组向量送入推理系统,经过层层的矩阵乘法、加法和各类专用函数的运算,得到新的输出向量 → 对输出向量做概率筛选,选出概率最高的那个数值对应的序号 → 最后再通过词典映射表 "翻译" 回文字,得到最终输出的一个词。
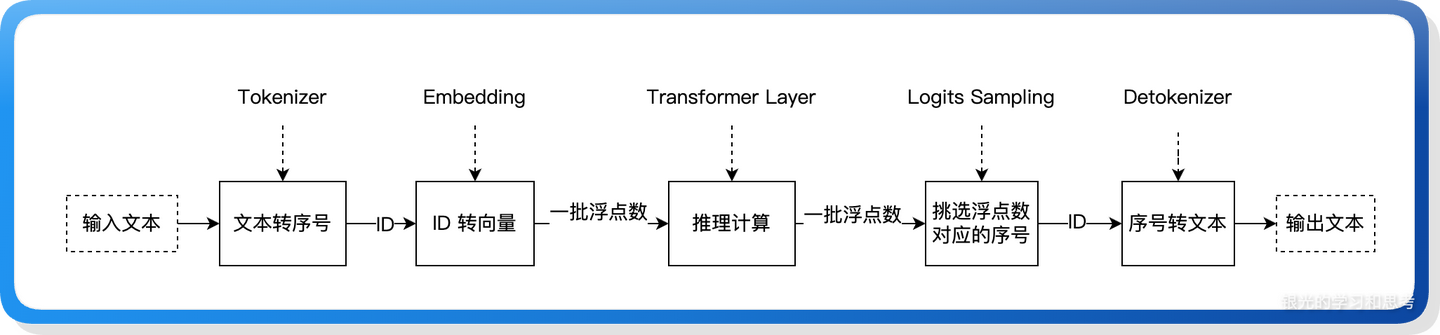
图 1
这是对大模型推理最朴素的理解,上述流程看似简单,但背后的推理计算环节对普通开发者而言仍是一个 "黑盒"。如果想更进一步拆解推理引擎的底层加速原理,nano-vllm 会是一个极佳的入门切入点。
2. 简介
nano-vLLM 代码量仅约 1200 行,却实现了生产级推理框架的核心技术原型,具体包括:
- 连续批处理(Continuous Batching)
- KV 缓存(Prefix KV Cache / Paged KV Cache)
- 高性能编译与执行优化(Torch Compilation、Triton、CUDA Graph)
- 张量并行(Tensor Parallelism)
该框架极具入门学习价值,本文将先介绍 nano-vLLM 的基本组成架构,再对部分核心技术要点展开深入解析。
3. 系统架构
nano-vLLM 的架构非常有层次感。
3.1. 整体架构概览
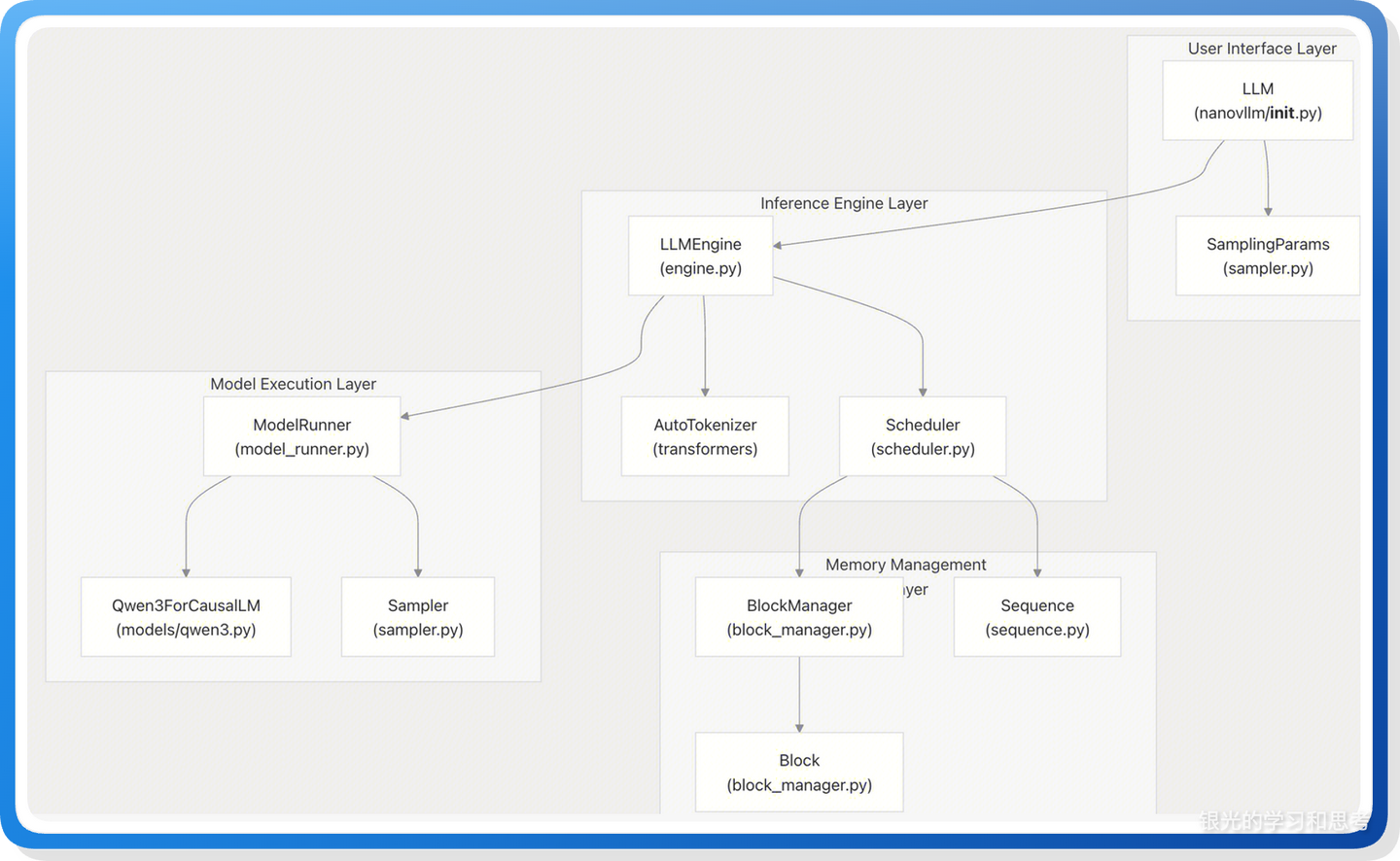
图 2, 来自:https://deepwiki.com/GeeeekExplorer/nano-vllm
三层结构
- 接口层:User Interface Layer
- 推理引擎中控层:Inference Engine Layer
- 显存管理和模型执行层:Memory Management & Model Execution Layer
3.2. 类层面架构
从类设计层面观察 nano-vLLM 的架构。
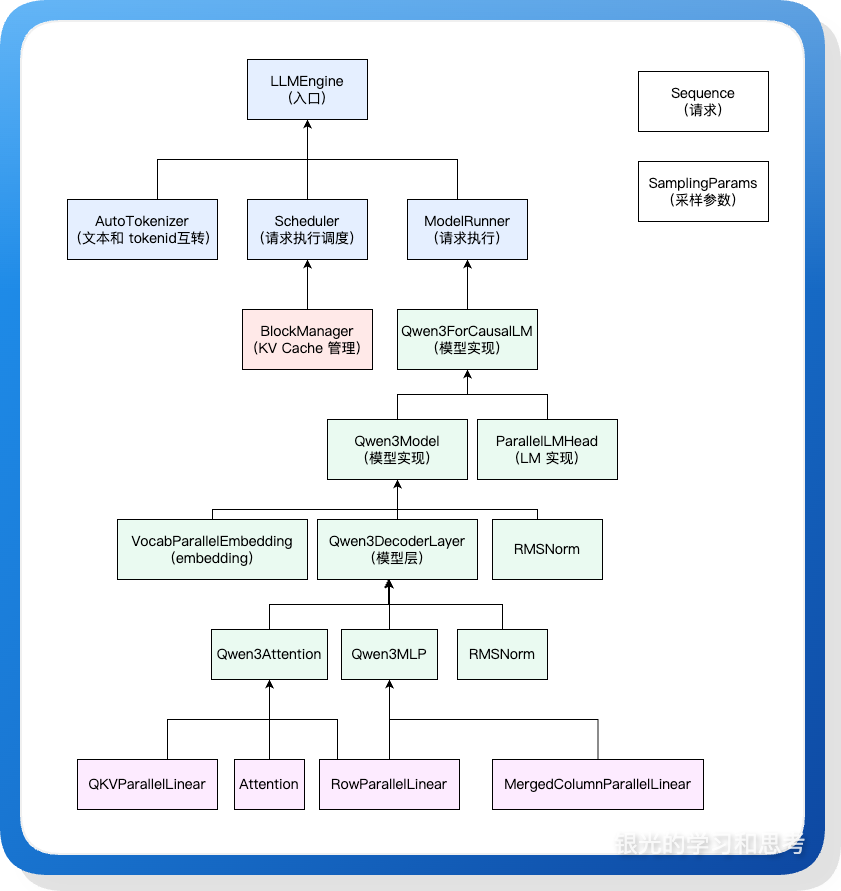
图 3
上图中四种颜色代表系统的四个组成部分
- 浅蓝色,入口和推理引擎中控层
- 浅绿色,模型推理
- 浅红色,KV Cache 管理
- 浅紫色,权重加载和矩阵计算的封装
3.3. 码层面划分
源码规划上也较为简洁。目录结构如下:
nanovllm/
├── engine
├── layers
├── models
└── utils- engine,引擎的入口、中控,同时 KV Cache 比较简单,代码也放在这个目录下。
- layers,模型推理的通用组件,内部包括:linear、layernorm、rotary_embedding、attention、activation 等基础功能的封装,可以被不同模型使用。
- models,模型的实现,依赖 layers 的组件实现不同模型的推理。
- utils,不同层都可能会用到的工具函数。
4. 连续批处理
4.1. 概念理解
(1)定义
连续批处理 (Continuous Batching):是一种迭代级(Iteration-level)的调度策略。它以"Token 生成步骤"为调度粒度。通过动态地在每一轮迭代中替换已完成的任务,消除了由于生成长度不一导致的 GPU 计算气泡,极大地提升了系统的吞吐量。
(2)朴素理解
一个请求需要执行多轮,不同请求需要执行的轮数不同,系统一轮最多只能同时执行一批 N 个请求,当一个批次里的请求参差不齐的完成时,每完成一个请求就将其用新请求替代掉。
对比传统批处理和连续批处理:
- 传统批处理 (Static Batching):必须等待 Batch 中生成序列最长的那个请求完成,整个 Batch 才会释放。在此期间,生成序列短请求完成后槽位会空转。
- 连续批处理 (Continuous Batching):请求完成即退出,新请求立即补位,槽位始终满载。
4.2. 最基础的连续批处理
最简单的连续批处理,不考虑 prefill 和 decode 的差异,示例代码:
import time
import threading
import queue
import random
# 1. 初始化线程安全的等待队列
waiting_queue = queue.Queue()
MAX_BATCH_SIZE = 3
# --- 模拟用户请求线程 (生产者) ---
def user_request_producer():
request_id = 1
while True:
# 模拟用户随机到达:每 1~2 秒来一个新请求
time.sleep(random.uniform(1, 2))
# 每个请求需要的 Token 长度随机(3到8之间)
req = {"id": f"REQ-{request_id}", "remain": random.randint(3, 8)}
waiting_queue.put(req)
print(f"\n[用户端] 送入新请求: {req['id']} (预计长度: {req['remain']})")
request_id += 1
if request_id > 5:
break
# --- 核心推理循环 (消费者/执行器) ---
def inference_loop():
running_batch = []
print("--- 推理引擎已启动 ---")
iteration = 0
while True:
# A. 补位逻辑:只要 Batch 没满且队列里有货,就拉进来
while len(running_batch) < MAX_BATCH_SIZE:
try:
# 使用 block=False,如果队列空了直接报错进 except,不阻塞推理逻辑
new_req = waiting_queue.get(block=False)
running_batch.append(new_req)
print(f" >>> [调度] {new_req['id']} 进入 Batch")
except queue.Empty:
break
# B. 推理逻辑:如果当前 Batch 有任务,就执行一次 Step
if running_batch:
iteration += 1
print("="*20 + f"{iteration=}" + "="*20)
# 模拟 GPU 推理耗时 (Step 耗时)
time.sleep(1.2)
# 当前 Batch 状态展示
active_ids = [f"{r['id']}(剩{r['remain']-1})" for r in running_batch]
print(f"[GPU推理] 处理中: {active_ids}")
# 每一个请求的剩余长度减 1
finished_this_step = []
for req in running_batch:
req["remain"] -= 1
if req["remain"] <= 0:
finished_this_step.append(req)
# C. 剔除逻辑:做完的立刻踢出,下一轮循环开头就会有新请求补进来
for req in finished_this_step:
print(f" <<< [完成] {req['id']} 生成完毕,释放位置")
running_batch.remove(req)
else:
# 如果 Batch 和 队列都空了,稍微歇会,避免 CPU 空转
time.sleep(0.5)
# --- 启动程序 ---
if __name__ == "__main__":
# 启动用户请求线程
t = threading.Thread(target=user_request_producer, daemon=True)
t.start()
# 主线程执行推理循环
try:
inference_loop()
except KeyboardInterrupt:
print("\n服务已停止")核心逻辑:
- 存储结构:代码的核心有两个队列,waiting_queue 负责存储请求线程不断接收到的新请求,running_queue 负责存储已经运行但还没有结束的请求。
- 迭代循环:生产者持续往 waiting_queue 写入新请求,迭代循环持续从 waiting_queue 获取新请求加入到 running_queue,同时清理 running_queue 里已经完成的请求。
4.3. prefill 优先的连续批处理
prefill 优先的批处理,需要区分 prefll 和 decode,优先处理新请求,示例代码:
import time
import queue
import random
import threading
# 核心队列
waiting_queue = queue.Queue()
running_queue = []
MAX_BATCH_SIZE = 4
def user_request_producer():
"""
修改点:模拟爆发式请求到达,以触发多请求 Prefill
"""
# 第一波:爆发式到达 (3个请求同时进入队列)
print("\n[用户] --- 爆发式请求到达 (3个请求) ---")
for i in range(1, 4):
req = {"id": f"REQ-{i}", "remain": random.randint(2, 5)}
waiting_queue.put(req)
print(f"[用户] 请求 {req['id']} 进入等待队列")
# 延迟一会儿,再来第二波单点请求
time.sleep(5)
print("\n[用户] --- 延迟请求到达 (1个请求) ---")
req = {"id": "REQ-4", "remain": 3}
waiting_queue.put(req)
print(f"[用户] 请求 {req['id']} 进入等待队列")
def inference_loop():
print("--- 连续批处理引擎:多请求 Prefill 模式 ---")
iteration = 0
while True:
current_batch = []
is_prefill_stage = False
# 1. 调度:构建当前批次
# 只要 waiting_queue 非空,就尽可能填满 MAX_BATCH_SIZE
if not waiting_queue.empty():
is_prefill_stage = True
while not waiting_queue.empty() and len(current_batch) < MAX_BATCH_SIZE:
req = waiting_queue.get()
current_batch.append(req)
elif running_queue:
is_prefill_stage = False
current_batch = list(running_queue)
if not current_batch:
time.sleep(0.5)
continue
# 2. 执行:模拟推理
iteration += 1
print(f"\n{'='*15} Iteration {iteration} {'='*15}")
if is_prefill_stage:
print(f"[PREFILL] 批量生成中: {[r['id'] for r in current_batch]}")
time.sleep(1.5)
else:
print(f"[DECODE ] 批量生成中: {[f'{r['id']}(剩{r['remain']})' for r in current_batch]}")
time.sleep(0.4)
# 3. 统一状态更新
for req in current_batch:
req['remain'] -= 1
# 4. 统一判断生命周期
# 注意:为了避免在遍历列表时删除元素,我们先收集要删除的对象
to_remove_from_running = []
for req in current_batch:
if req['remain'] <= 0:
print(f" <<< [完成] {req['id']} 退出系统")
if req in running_queue:
to_remove_from_running.append(req)
else:
if is_prefill_stage:
running_queue.append(req)
print(f" -> {req['id']} Prefill 完成,转入 running_queue")
else:
pass
# 真正的从 running_queue 移除
for req in to_remove_from_running:
running_queue.remove(req)
if __name__ == "__main__":
t = threading.Thread(target=user_request_producer, daemon=True)
t.start()
try:
inference_loop()
except KeyboardInterrupt:
pass叠加上 prefill 优先之后的连续批处理代码也较为简单,主要是维护三个变量:waiting_queue、running_queue、current_batch。
5. KV Cache
5.1. 概念理解
5.1.1. KV Cache 的用途
KV Cache 有两层用途。一是用在同一个请求的 Decode 阶段,复用之前已经计算过的 KV 结果以避免重复计算;二是用在不同请求之间,使具有相同前缀的请求可以共享一部分 KV 数据,这就是 Prefix KV Cache。
5.1.2. PagedAttention 技术
在 Cache 的存储层面,PagedAttention 实现了显存的按需申请。由于 KV Cache 空间不再一次性预分配,请求序列对应的物理地址是离散的。PagedAttention 的核心在于,它能够直接读取这些物理离散的块来完成注意力计算,这背后实现了一层从"逻辑连续地址"到"物理离散地址"的映射。
对于没有接触过非 PagedAttention 实现的读者来说,这种设计似乎理所当然:按需申请、分页管理、地址映射、局部性原理------这些都是计算机科学中非常常规的思维,甚至很难想到不这么写的理由。那么,为什么 PagedAttention 会被认为是一项里程碑式的先进技术呢?
首先,在 PagedAttention 出现之前,业界普遍认为 KV Cache 在显存中必须物理连续,否则会因访存不连续导致性能大幅下降。其次,当时的注意力算子(如标准的 FlashAttention)并不支持二次寻址映射。PagedAttention 证明了即便物理存储不连续,性能依然可以保持极高。其代码实现最关键的点在于重构了 CUDA 内核,使其原生支持 KV Cache 二次寻址。一个序列的 KV Cache 不需要物理连续,也正是不同序列间能够灵活复用 Prefix KV Cache 的技术前提。
总的来说,虽然分页虚拟内存在 CPU 领域是常识,但在 GPU 算子领域其发展相对缓慢。实现一套既能分页管理、又不损失算力利用率的 Attention Kernel 是 PagedAttention 的核心所在。
5.2. Prefix KV Cache 的实现
Cache 的管理较为简单,只有 BlockManager 类,负责维护显存池各个 block 的的状态。
5.2.1. 功能细节
- 使用 hash 来识别是否有可复用前缀,以 block 为基本单元
- 链式 hash,每个 block 的 hash 计算输入为前序 block 的 hash 值加上本 block 的 token id
- 每一个 block 有对应的 meta 信息对象,记录 block 被复用的引用计数,确保复用时不会被释放
- 为避免 hash 碰撞出现错误,block meta 信息还需要记录原始的 token id
- 在获取 KV Cache 空间时需要考虑是否跨 block
5.2.2. 内存池
在进程启动时,一次性申请内存池的空间:
kv_cache = torch.empty(
2, # K 和 V
num_layers, # 层数
num_blocks, # 总块数
block_size, # 每块 token 数
num_kv_heads // tp_size, # KV head 数(考虑张量并行)
head_dim # head 维度
)上述申请显存代码中的 num_blocks 是根据可用于 KV Cache 的显存算出来的:
block_bytes = 2 * hf_config.num_hidden_layers * self.block_size * num_kv_heads * head_dim * hf_config.torch_dtype.itemsize
config.num_kvcache_blocks = int(total * config.gpu_memory_utilization - used - peak + current) // block_bytes上述代码中的 block_bytes 并不是指 block 的大小,而是把计算 blocks 数的所有除数乘到了一起,除数包括:block 大小、k 和 v、模型层数。
total * config.gpu_memory_utilization - used - peak + current 这部分则是根据最高的显存利用率算出来可用显存,减去当前模型加载完后使用了的部分,再减去模型预热时使用的激活显存:peak - current。
申请到内存池后,按层共享视图给各个层的 Attention 对象,代码看起来比较 tricky,但在 python 里倒比较常见:
for module in self.model.modules():
if hasattr(module, "k_cache") and hasattr(module, "v_cache"):
module.k_cache = self.kv_cache[0, layer_id]
module.v_cache = self.kv_cache[1, layer_id]
layer_id += 1遍历模型中的所有 nn.Module 子模块,通过检查是否存在 k_cache 和 v_cache 属性来识别 Attention 层。对于每个 Attention 层,将其 k_cache 和 v_cache 属性替换为指向全局 KV Cache 显存池的张量视图,这样所有层共享同一块连续的显存空间,但每层只能访问自己对应的切片。
5.2.3. KV Cache 写入
在 attention 子层的 forward 前做 KV Cache 的写入,使用的 store_kvcache_kernel 函数是 triton.jit 实现的,代码也比较简洁:
@triton.jit
def store_kvcache_kernel(
key_ptr,
key_stride,
value_ptr,
value_stride,
k_cache_ptr,
v_cache_ptr,
slot_mapping_ptr,
D: tl.constexpr,
):
idx = tl.program_id(0)
slot = tl.load(slot_mapping_ptr + idx)
if slot == -1: return
key_offsets = idx * key_stride + tl.arange(0, D)
value_offsets = idx * value_stride + tl.arange(0, D)
key = tl.load(key_ptr + key_offsets)
value = tl.load(value_ptr + value_offsets)
cache_offsets = slot * D + tl.arange(0, D)
tl.store(k_cache_ptr + cache_offsets, key)
tl.store(v_cache_ptr + cache_offsets, value)
def store_kvcache(key: torch.Tensor, value: torch.Tensor, k_cache: torch.Tensor, v_cache: torch.Tensor, slot_mapping: torch.Tensor):
N, num_heads, head_dim = key.shape
D = num_heads * head_dim
assert key.stride(-1) == 1 and value.stride(-1) == 1
assert key.stride(1) == head_dim and value.stride(1) == head_dim
assert k_cache.stride(1) == D and v_cache.stride(1) == D
assert slot_mapping.numel() == N
store_kvcache_kernel[(N,)](key, key.stride(0), value, value.stride(0), k_cache, v_cache, slot_mapping, D)使用 stride 函数来确认显存是否连续,因为在 store_kvcache_kernel 的实现里会按照显存连续来读取指定位置的值。
显存连续和不连续的例子:
import torch
key = torch.randn(2, 3, 4)
print(key.stride())
key_t = key.transpose(1, 2)
print("转置后(非连续):", key_t.stride())
key_t = key_t.contiguous() # 重新分配,使其连续
print("contiguous 后:", key_t.stride())
# 输出:
# (12, 4, 1)
# 转置后(非连续): (12, 1, 4)
# contiguous后: (12, 3, 1)6. cuda graph
6.1. 概念理解
CUDA Graph 是一种将一系列 CUDA 操作录制成图的技术,在重复执行的固定操作序列场景下可以显著提升推理性能,主要基于这几方面:
- 减少 CPU 与 GPU 之间的频繁同步和指令下发开销,降低传统独立操作带来的控制流交互损耗;
- 减少执行过程中的 CPU 干预,GPU 自主批量执行图内操作,最大化 GPU 利用率,降低延迟、提升吞吐。
- 规避多次独立 CUDA Kernel 的启动固定开销,多个 Kernel 打包后仅需一次调度触发,大幅提升小 Kernel 密集场景的执行效率;
- 可配合显存池实现显存资源复用,减少 "少量多次" 显存申请 / 释放的开销,同时驱动会基于图内显存访问模式优化带宽利用率;
- CUDA 驱动可获取操作序列的全局视图,基于完整的依赖关系进行全局优化(如 Kernel 顺序调整、资源合并等);
6.2. 功能细节
- 录制时使用的张量内存地址,在重放时必须保持不变,也就是后面多次 replay 都会使用捕获时申请的变量空间
- 捕获后的 graph 对象记录在成员变量里,供下次推理时选择
- 重放时选择比请求 batch size 大的最小 graph batch size
- 捕获时不同的 batch size 共享相同的静态显存空间,并让多个批次共享显存池,使得虽然有多个 batch size,但只会使用 Max Batch Size 的显存空间
6.3. 示例代码
import torch
import torch.nn as nn
# 1. 基础配置
device = "cuda"
D = 512 # 维度
graph_bs = [1, 8, 32] # 预定义的桶(分桶尺寸)
NUM_LAYERS = 100 # 极深模型,增加 Kernel 数量以放大 Graph 优势
iters = 50 # 性能测试迭代次数
max_bs = max(graph_bs)
# 2. 定义深层模型 (产生约 400 个 Kernel)
class UltraDeepModel(nn.Module):
def __init__(self):
super().__init__()
self.blocks = nn.ModuleList()
for _ in range(NUM_LAYERS):
block = nn.ModuleDict({
'ln': nn.LayerNorm(D).to(device),
'linear': nn.Linear(D, D).to(device),
'act': nn.ReLU()
})
self.blocks.append(block)
def forward(self, x):
for block in self.blocks:
identity = x
x = block['ln'](x)
x = block['linear'](x)
x = block['act'](x)
x = x + identity
return x
model = UltraDeepModel().eval()
# 3. 静态缓冲区准备
static_input = torch.empty(max_bs, D, device=device)
static_output = torch.empty(max_bs, D, device=device)
graphs = {}
graph_pool = None
# 4. 录制阶段 (从大到小,共享内存池)
print(f"--- 开始录制分桶 CUDA Graphs ---")
for bs in reversed(sorted(graph_bs)):
current_input = static_input[:bs]
# Warmup
for _ in range(5):
_ = model(current_input)
g = torch.cuda.CUDAGraph()
with torch.cuda.graph(g, pool=graph_pool):
static_output[:bs] = model(current_input)
if graph_pool is None:
graph_pool = g.pool()
graphs[bs] = g
print(f"✅ 已录制桶 BS={bs}")
# 5. 辅助函数:根据实际 BS 匹配最近的桶
def get_bucket_bs(actual_bs):
for b in sorted(graph_bs):
if actual_bs <= b:
return b
return None
# 6. 性能对比测试 (包含 Padding 逻辑)
def benchmark(actual_test_bs=7):
print(f"\n--- 性能测试开始: 实际请求 BS={actual_test_bs} ---")
# 生成测试数据
test_data = torch.randn(actual_test_bs, D, device=device)
start_event = torch.cuda.Event(enable_timing=True)
end_event = torch.cuda.Event(enable_timing=True)
# --- 段落 A: Standard Eager Mode (直接跑 7 个) ---
torch.cuda.nvtx.range_push("Eager_Mode")
start_event.record()
for _ in range(iters):
_ = model(test_data)
end_event.record()
torch.cuda.synchronize()
eager_time = start_event.elapsed_time(end_event)
torch.cuda.nvtx.range_pop()
# --- 段落 B: CUDA Graph Mode (Padding 对齐到 8) ---
# 1. 路由逻辑
bucket_bs = get_bucket_bs(actual_test_bs)
if bucket_bs is None:
print(f"❌ 错误: 实际 BS={actual_test_bs} 超过了最大分桶 {max_bs}")
return
torch.cuda.nvtx.range_push(f"Graph_Mode_Bucket_{bucket_bs}")
# 2. 数据对齐 (Padding): 将 7 条数据拷入 8 的静态区域
# static_input 的前 7 行被覆盖,第 8 行保持不变(即 Padding 位)
static_input[:actual_test_bs].copy_(test_data)
start_event.record()
for _ in range(iters):
# 3. 重放分桶 8 的图
graphs[bucket_bs].replay()
end_event.record()
torch.cuda.synchronize()
graph_time = start_event.elapsed_time(end_event)
# 4. 结果截断 (Slicing): 从静态区拿回前 7 条
final_res = static_output[:actual_test_bs]
torch.cuda.nvtx.range_pop()
# 打印结果
print(f"匹配到的桶: {bucket_bs} (Padding 浪费率: {(bucket_bs-actual_test_bs)/bucket_bs*100:.1f}%)")
print(f"{'Mode':<20} | {'Avg Time (ms)':<15}")
print("-" * 40)
print(f"{'Eager Mode':<20} | {eager_time/iters:>15.4f}")
print(f"{'Graph Mode':<20} | {graph_time/iters:>15.4f}")
print("-" * 40)
print(f"🚀 加速比: {eager_time/graph_time:.2f}x")
print(f"最终输出形状: {final_res.shape}")
if __name__ == "__main__":
# 测试不同的输入 BS
benchmark(actual_test_bs=7) # 触发对齐到 8
benchmark(actual_test_bs=1) # 精确匹配到 1执行:nsys profile --trace=cuda,osrt,nvtx python3 cu2.py
输出:
Collecting data...
--- 开始录制分桶 CUDA Graphs ---
✅ 已录制桶 BS=32
✅ 已录制桶 BS=8
✅ 已录制桶 BS=1
--- 性能测试开始: 实际请求 BS=7 ---
匹配到的桶: 8 (Padding 浪费率: 12.5%)
Mode | Avg Time (ms)
----------------------------------------
Eager Mode | 7.9331
Graph Mode | 1.0136
----------------------------------------
🚀 加速比: 7.83x
最终输出形状: torch.Size([7, 512])
--- 性能测试开始: 实际请求 BS=1 ---
匹配到的桶: 1 (Padding 浪费率: 0.0%)
Mode | Avg Time (ms)
----------------------------------------
Eager Mode | 8.1803
Graph Mode | 0.8011
----------------------------------------
🚀 加速比: 10.21x
最终输出形状: torch.Size([1, 512])查看 nsys:
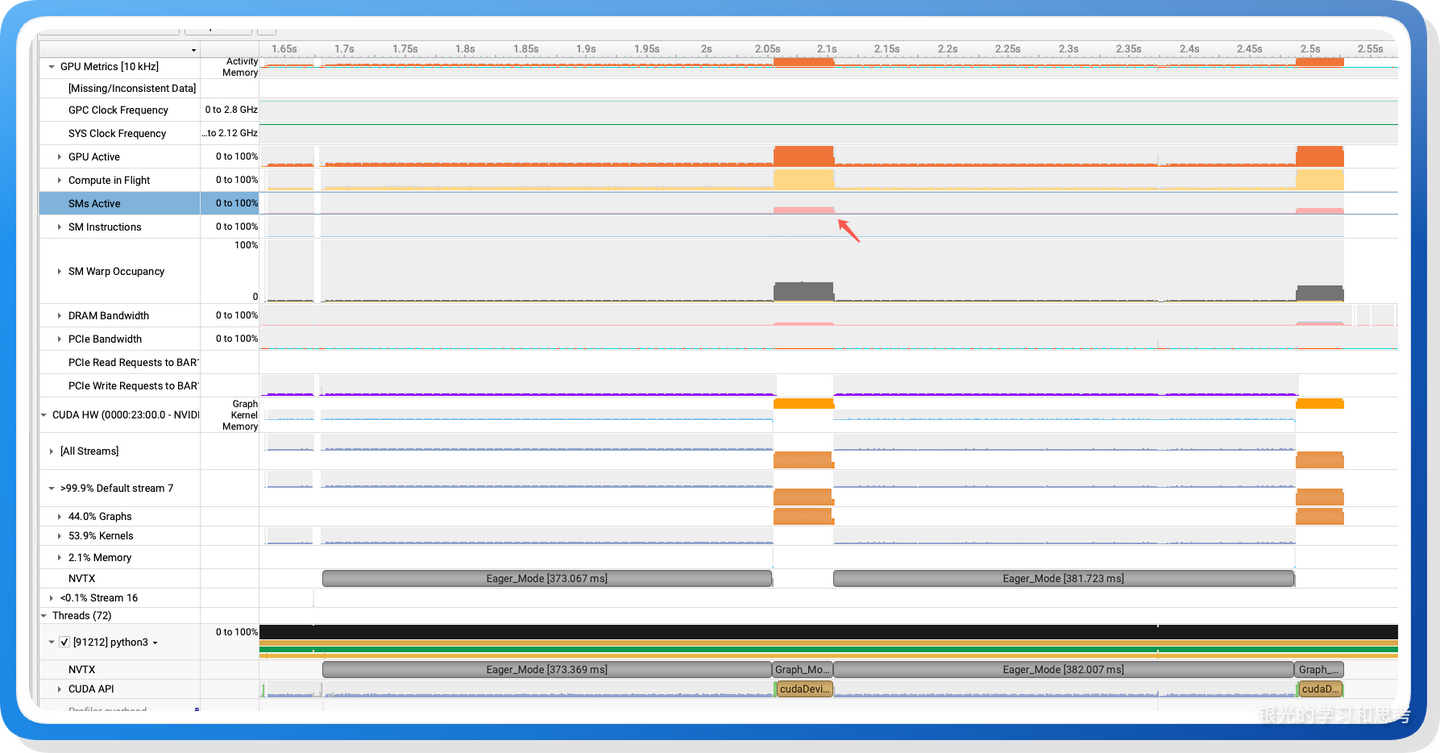
图 4
可以看到,在 cuda graph 的时候,SM 使用更充分。
6.4. Q&A
(1)为什么推理时 cuda graph 的选择要采用向上对齐的分桶策略,即:批次相等或稍大的,而不是选择批次最大的?
虽然在建图(Capture)阶段,系统会按照最大批次(Max Batch Size)预先申请并锁定静态显存空间,此时即便选择最大批次执行也不会产生额外的显存容量浪费,但会引入以下两个维度的性能损耗:
显存带宽的无效占用,大模型推理(尤其是 Decoding 阶段)属于典型的访存密集型任务,其瓶颈在于模型权重从显存到计算单元的搬运速度。即便大部分批次位置是 Padding(空数据),CUDA Graph 依然会严格执行录制时的内存寻址定义,搬运完整批次的数据。使用过大的批次会导致 GPU 浪费极其宝贵的带宽去搬运"无效数据",从而增加单次推理的耗时,推高推理延迟(Latency)。
计算资源的无效占用,GPU 调度器会根据图定义的规模预分配硬件资源(如 SM 核心、寄存器、共享显存等)。虽然 Padding 部分的计算逻辑极快,但这些资源在整个 CUDA Graph 执行完成前无法被释放。这会导致 GPU 硬件处于"虚假繁忙"状态,阻塞了其他潜在任务(如多流并行等)获取硬件资源,削弱了系统整体的并发吞吐能力(Throughput)。
7. Torch Compilation
7.1. 概念理解
torch.compile 能够将 PyTorch 张量计算相关的 Python 逻辑,转化为更高效的中间表示(在 CUDA 设备上,通常是 Triton 内核代码,也支持原生 CUDA 内核)。相较于传统的即时执行(Eager Mode),这种方式通过优化计算内核本身带来显著的运行效率提升;此外,当输入张量形状、数据类型固定时,torch.compile 还会自动启用 CUDA Graph 优化,进一步放大性能收益。
在 torch.compile 问世之前,PyTorch 开发者若想追求高性能,仅有两种核心选择:一是使用 Eager Mode 接受其原生性能上限,二是手动编写 Triton 或 CUDA 底层内核代码(该方式开发门槛高、周期长、维护成本高)。而有了 torch.compile 后,开发者只需编写简洁易懂的 PyTorch Python 业务逻辑,无需关注底层硬件适配与内核实现,即可获得接近手写 Triton/CUDA 的优异性能,大幅平衡了开发效率与运行性能。
7.2. 使用方法
应用 torch.compile 非常简单,核心有两类使用方式:
- 装饰器方式:在 PyTorch 函数上直接添加 @torch.compile 装饰器,定义时即完成编译声明;
- 显式调用方式:通过 compiled_obj = torch.compile(target) 显式编译目标对象,后续调用 compiled_obj 即可使用优化后的逻辑;
另外,可以对模型实例的直接编译:对于 PyTorch 模型(nn.Module 子类实例),可直接传入 torch.compile 完成整体编译,无需单独修饰 forward 方法。
示例代码:
方式 1:装饰器方式(适用于函数 / 模型方法)
import torch
import torch.nn as nn
# 对普通PyTorch函数使用装饰器
@torch.compile
def my_tensor_func(x, y):
return torch.matmul(x, y) + torch.relu(y)
# 对模型的forward方法使用装饰器
class MyModel(nn.Module):
@torch.compile # 修饰forward方法,自动编译模型推理逻辑
def forward(self, x):
return nn.Linear(10, 20)(x)方式 2:显式调用方式(适用于函数 / 模型,灵活性更高)
import torch
import torch.nn as nn
# 显式编译普通函数
def my_tensor_func(x, y):
return torch.matmul(x, y) + torch.relu(y)
compiled_func = torch.compile(my_tensor_func) # 生成编译后的函数
output = compiled_func(torch.randn(32, 10), torch.randn(10, 20)) # 调用编译后的函数
# 显式编译模型(与方式3本质一致,更强调"先编译后使用"的显式流程)
class MyModel(nn.Module):
def forward(self, x):
return nn.Linear(10, 20)(x)
model = MyModel()
compiled_model = torch.compile(model) # 直接编译整个模型实例
output = compiled_model(torch.randn(32, 10)) # 调用编译后的模型方式 3:直接编译模型实例(深度学习中最常用,简化写法)
import torch
import torch.nn as nn
class MyModel(nn.Module):
def forward(self, x):
return nn.Linear(10, 20)(x)
# 直接编译模型实例,一步到位(无需装饰器,最简洁常用)
model = torch.compile(MyModel())
output = model(torch.randn(32, 10))7.3. 性能对比
下面以一个简单的例子对比 Eager Mode 和 Compiled Mode:
import torch
import time
# 确保使用的是 GPU
device = "cuda" if torch.cuda.is_available() else "cpu"
if device == "cpu":
print("警告:CUDA 不可用,将使用 CPU 运行(torch.compile 的优势在 GPU 上最明显)。")
def complex_operation_eager(x, y):
z = x * y
z = z + x
z = torch.relu(z)
return z.sum()
@torch.compile
def complex_operation_graph(x, y):
z = x * y
z = z + x
z = torch.relu(z)
return z.sum()
# 1. 准备数据
x = torch.randn(10000, 10000, device=device)
y = torch.randn(10000, 10000, device=device)
# 2. 热身 (Warm up)
print("正在编译并进行多次热身以稳定 GPU 状态...")
# 增加热身循环
for i in range(3):
complex_operation_graph(x, y)
if i == 0:
print("-> 首次编译完成,正在进行后续预热...")
torch.cuda.synchronize()
print("预热完毕,开始正式测试。")
def benchmark(func, x, y, label, iterations=100):
start_event = torch.cuda.Event(enable_timing=True)
end_event = torch.cuda.Event(enable_timing=True)
start_event.record()
for _ in range(iterations):
func(x, y)
end_event.record()
torch.cuda.synchronize()
elapsed_time_ms = start_event.elapsed_time(end_event)
avg_time_s = (elapsed_time_ms / 1000) / iterations
print(f"{label} 平均耗时: {avg_time_s:.6f} 秒")
return avg_time_s
# 3. 执行测试并计算加速比
with torch.no_grad():
print("-" * 30)
eager_time = benchmark(complex_operation_eager, x, y, "Eager Mode ")
compile_time = benchmark(complex_operation_graph, x, y, "Compiled Mode")
print("-" * 30)
# 计算加速比逻辑
speedup = eager_time / compile_time
improvement = (speedup - 1) * 100
print(f"性能提升结果:")
print(f"加速比 (Speedup): {speedup:.2f}x")
print(f"运行速度提升了: {improvement:.1f}%")运行输出:
正在编译并进行多次热身以稳定 GPU 状态...
-> 首次编译完成,正在进行后续预热...
预热完毕,开始正式测试。
------------------------------
Eager Mode 平均耗时: 0.005690 秒
Compiled Mode 平均耗时: 0.001528 秒
------------------------------
性能提升结果:
加速比 (Speedup): 3.72x
运行速度提升了: 272.3%性能有数倍的提升。
7.4. Q&A
(1)既然 torch.compile 有这么大的好处,为什么不能给所有的张量操作函数都加上 @torch.compile?
有几方面的原因:首先,存在编译开销,会导致首次运行显著变慢;然后,编译器生成的 Triton 内核(或其他后端代码)通常是针对特定张量形状、数据类型和设备配置优化的,如果输入张量的这些属性频繁变化,会反复触发重新编译(即 "编译缓存失效"),反而抵消性能收益;第三,torch.compile 自身会带来额外的显存开销(用于存储编译后的中间表示、内核缓存等),过多无差别使用可能导致显存不足(OOM);最后,并非所有代码都能被成功图化优化,如果张量操作中调用了非 PyTorch 原生的第三方库(或纯 Python 原生逻辑),会导致计算图中断,此时编译器无法继续优化后续逻辑,还需要将控制权交回给 Python 解释器,产生不必要的上下文切换开销,可能导致负优化。
(2)torch.compile 支持生成原生 CUDA 内核代码,但通常来说,编译器自动生成的通用原生 CUDA 代码优化粒度不够精细;而 Triton 内置了极强的 Autotuning(自动调优)能力,针对深度学习张量计算场景做了深度适配,因此在绝大多数深度学习任务中,Triton 内核的性能通常优于自动生成的原生 CUDA 内核。
8. Torch Compilation、Trition、CUDA Graph 三者的区别和联系
8.1. 核心区别
(1)Torch Compilation:PyTorch 高层一站式性能优化入口(用户态抽象接口)
作为面向开发者的顶级优化封装,torch.compile 无需开发者关注底层硬件细节与优化实现,其核心定位是对 PyTorch 张量计算逻辑(函数 /nn.Module 模型)进行端到端自动优化,屏蔽了底层内核生成与执行优化的复杂性,是绝大多数 PyTorch 开发者的首选性能优化工具。
(2)Triton:高性能 GPU 内核专用 DSL
Triton 既是开发者手动编写高性能内核的领域专用语言(DSL),也是 torch.compile 自动化生成代码的核心目标后端。其中,triton.jit 是 Triton 框架提供的即时编译装饰器,定位为高性能跨平台 GPU 内核的手动开发入口,抽象层级低于 torch.compile、高于原生 CUDA C++。它允许开发者以 Python 风格语法编写 GPU 内核逻辑,无需手动处理线程调度、寄存器分配等底层细节,最终编译为高效 GPU 机器码,用于满足定制化算子的高性能需求。
(3)CUDA Graph:GPU 底层静态任务流执行优化技术
CUDA Graph 是一种静态任务流调度技术,旨在消除主机端(Host)与设备端(Device)之间的交互延迟。它并非 "内核生成工具",也非 "用户态编程接口",而是针对 CPU-GPU 交互瓶颈的底层执行优化技术,抽象层级最低。其核心作用是固化连续的 CUDA 内核调用序列与内存配置,通过 "录制 - 重放" 模式消除重复内核启动、CPU-GPU 频繁通信的开销,仅优化执行流程,不改变内核本身的计算性能。
8.2. 核心联系
(1)torch.compile 依赖 triton.jit 实现高性能内核生成
torch.compile 的默认底层编译器(Inductor)在 CUDA 设备上,会自动将 PyTorch 计算逻辑转化为 Triton 内核代码,并隐式调用 triton.jit 完成编译,生成高性能 GPU 内核(开发者无需手动编写 Triton 代码,也无需感知 triton.jit 的存在)。此外,torch.compile 也支持生成原生 CUDA 内核,作为 Triton 内核的可选补充方案。
(2)torch.compile 集成 CUDA Graph 实现执行层二次优化
当输入张量的形状、数据类型等属性固定时,torch.compile 会自动启用 CUDA Graph 优化,将编译生成的 Triton/CUDA 内核调用序列录制为 CUDA 图。后续重复执行该逻辑时,直接在 GPU 上重放该图,进一步放大性能收益,实现 "内核计算优化" 与 "执行流程优化" 的协同增效。
(3)triton.jit 自定义内核可与 CUDA Graph 手动协同
开发者手动通过 triton.jit 编写并编译的自定义内核,在批量重复执行(输入形状固定)的场景下,可手动集成 CUDA Graph 完成 "录制 - 重放" 流程,消除 CPU 对 GPU 的调度开销,实现内核计算性能与执行效率的双重极致优化。
(4)三者协同构建极致性能计算链路
典型极致性能链路:手动编写 triton.jit 定制内核 → 嵌入 PyTorch 模型 / 函数 → 通过 torch.compile 进行上层计算图优化(算子融合、内存复用等) → torch.compile 自动启用 CUDA Graph 优化执行流程 → 实现 GPU 计算性能最大化。
9. TP 模式
TP 模式将矩阵计算按行、列拆分到多颗 GPU 上执行,涉及两个关键点:权重参数怎么加载、多核计算之间如何协同,下面做介绍。
9.1. 加载权重参数
权重参数与矩阵计算强相关,因此权重参数的加载逻辑通常与矩阵计算逻辑一同封装在同一个类中,实现功能的内聚性。
9.1.1. 关键技术点
(1)参数文件中,权重矩阵以 Key-Value 键值对形式存储,读取时同样采用 Key-Value 方式解析。其中 key 对应权重矩阵在模型中的归属位置,例如:模型第 0 层 MLP 子层的 down proj 权重对应的 key 为 model.layers.0.mlp.down_proj.weight。
(2)参数文件由训练流程写入、推理流程读取,训练与推理两侧必须严格对齐 key 的命名规则。模型参数加载时,会根据参数文件中的 key 名称,在 nn.Module 对象中匹配并调用对应的 weight_loader 方法完成加载。
(3)模型结构包含多个层级,每一层内部又包含多个子模块,不同子模块对应各自专属的参数加载方法。PyTorch 的 nn.Module 通过特殊方法 setattr,将模型结构中的各个子模块构建为树形结构;树形结构中每个叶子节点的路径,与参数文件中的 key 一一映射,通过该路径找到叶子节点后,即可获取对应的参数对象 nn.Parameter,而该参数对象绑定了其所属子模块的 weight_loader 方法。
(4)矩阵乘法 A * B 遵循「A 的行 × B 的列」计算规则,在模型推理中,B 为权重矩阵,实际访问时以列维度为主。为提升读取效率、避免缓存(Cache)频繁失效,权重矩阵 B 通常以转置形式存储。TP(Tensor Parallel)worker 加载权重时,需适配该转置存储特性 ------ 即权重矩阵第 0 维对应原始矩阵的列数据,第 1 维对应原始矩阵的行数据。
从上述技术点可得出核心对应关系:参数文件中的模型结构以一个个 key 表示,这些 key 按层级关系可构建为一棵路径树;代码中的模型结构以有包含关系的类对象表示,这些类对象同样构成一棵与参数文件路径树完全对应的树。
9.1.2. 实操举例(FFN 层 up proj 权重加载)
(1)假设 TP size=2,up proj 权重矩阵的原始形状为 1024, 3072,下面介绍一个 TP worker 如何加载权重。
(2)首先,构造模型对象时,会初始化 ColumnParallelLinear 对象,并设定核心参数:input_size=1024,output_size=3072/2=1536(按 TP 尺寸做均分)。这两个参数最终用于初始化 nn.Parameter 对象,对应代码为 self.weight = nn.Parameter(torch.empty(output_size, input_size)),需注意此处初始化的张量以 output_size 为行维度、input_size 为列维度。
(3)随后,启动模型权重加载流程:先从参数文件中读取所有 key-value 键值对,再通过 key 在 nn.Module 树形结构中查找对应的 nn.Parameter 对象,匹配到后调用其绑定的 weight_loader 函数,执行具体的参数加载操作。
(4)参数加载阶段,针对列并行模式,需要对权重张量的第 0 维度进行拆分,再根据当前进程的 tp_rank(TP 进程编号),确定本进程需要加载的权重区间,完成分片权重的加载。
注:代码实现中,会将 gate 矩阵与 up 矩阵进行合并加载到显存中,因此实际加载流程会在此基础上增加几步额外步骤。
9.1.3. 构造树形结构示例代码
下面 demo 代码展示多个有层级的对象如何通过特殊方法 setattr 构造树形结构.
class MiniModule:
def __init__(self, name="root"):
self._name = name
self._modules = {}
self._parameters = {}
def __setattr__(self, name, value):
if isinstance(value, MiniModule):
self._modules[name] = value
elif name.endswith("_weight_loader"):
self._parameters[name] = value
super().__setattr__(name, value)
def get_all_paths(self, prefix=""):
"""递归遍历并收集所有参数的完整路径"""
paths = []
# 1. 先收集当前层级的参数路径
for p_name in self._parameters:
full_path = f"{prefix}.{p_name}" if prefix else p_name
paths.append(full_path)
# 2. 递归进入子模块,传递更新后的前缀
for m_name, m_obj in self._modules.items():
new_prefix = f"{prefix}.{m_name}" if prefix else m_name
paths.extend(m_obj.get_all_paths(new_prefix))
return paths
def q_weight_loader():
print(f"this is q_weight_loader")
def down_weight_loader():
print(f"this is down_weight_loader")
# --- 构造树形结构 ---
model = MiniModule("Qwen3")
model.layers = MiniModule("Layers")
model.layers.attention = MiniModule("Attention")
model.layers.attention.q_weight_loader = q_weight_loader
model.layers.mlp = MiniModule("MLP")
model.layers.mlp.down_weight_loader = down_weight_loader
# --- 打印所有路径 ---
print("遍历模型的所有参数路径:")
all_paths = model.get_all_paths()
for path in all_paths:
print(f"路径: {path}")
# --- 模拟 nano-vllm 的访问逻辑 ---
def mock_get_parameter(root, path):
parts = path.split(".")
curr = root
for part in parts[:-1]:
curr = curr._modules[part]
return curr._parameters[parts[-1]]
target = "layers.attention.q_weight_loader"
print(f"\n模拟查找路径 '{target}':")
loader = mock_get_parameter(model, target)
loader()输出结果:
遍历模型的所有参数路径:
路径: layers.attention.q_weight_loader
路径: layers.mlp.down_weight_loader
模拟查找路径 'layers.attention.q_weight_loader':
this is q_weight_loader9.2. 多 GPU 之间的计算协同
9.2.1. 功能细节
nano-vllm 只考虑单机内的多 GPU 协同,协同过程如下:
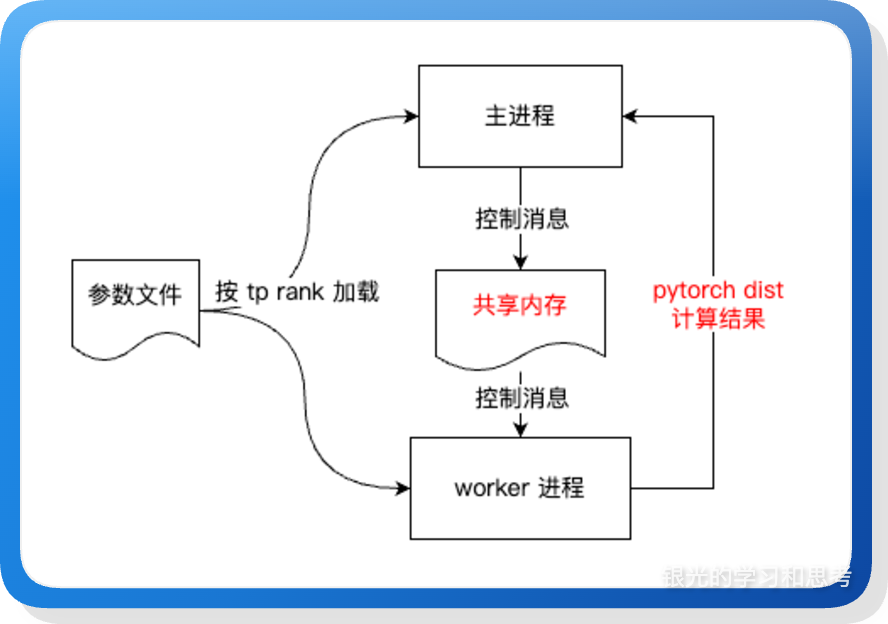
图 5
(1)进程隔离与独立加载: 采用多进程模式,一个 GPU 对应一个独立进程。各进程并发读取权重文件,并根据自己的 tp_rank 按照预设的切分策略(如 ColumnParallel 的行切分或 RowParallel 的列切分),将属于自己的那部分数据从 safetensors 加载到显存中。
(2)控制面协同(Control Plane): Rank 0 负责全局调度,通过共享内存将推理请求(Tokens、Sampling Params 等)同步给其他 Rank。
(3)数据面通信(Data Plane): 在矩阵计算的关键节点,利用通信原语(如 all-reduce 处理分块求和、all-gather 处理序列拼接)完成张量并行的结果汇总,使分布在不同显卡上的计算结果在数学上等价于单卡计算。
9.2.2. 示例代码
下面写一个简单的数据通信例子:
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
import time
def setup(rank, world_size):
dist.init_process_group(
"nccl", "tcp://127.0.0.1:2333", world_size=world_size, rank=rank
)
torch.cuda.set_device(rank)
def cleanup():
dist.destroy_process_group()
def test_all_reduce(rank, world_size):
"""
All-Reduce 子函数:将所有 GPU 的数据进行归约操作(求和),结果同步到所有 GPU
使用场景:
- RowParallelLinear 的输出聚合
- 需要所有 GPU 都得到相同的聚合结果
"""
print(f"[Rank {rank}] ===== All-Reduce 示例 =====")
if rank == 0:
data = torch.tensor([1.0, 2.0], device=f"cuda:{rank}")
else:
data = torch.tensor([3.0, 4.0], device=f"cuda:{rank}")
print(f"[Rank {rank}] All-Reduce before: {data}")
dist.all_reduce(data, op=dist.ReduceOp.SUM)
print(f"[Rank {rank}] All-Reduce after: {data}")
def test_all_gather(rank, world_size):
"""
All-Gather 子函数:收集所有 GPU 的数据到每个 GPU 上
使用场景:
- VocabParallelEmbedding 的输出收集
- ParallelLMHead 的 logits 收集
- 需要每个 GPU 都获得所有 GPU 的完整数据
"""
print(f"[Rank {rank}] ===== All-Gather 示例 =====")
# Rank 0 产生 [10, 20], Rank 1 产生 [30, 40]
local_data = torch.tensor(
[10.0 + rank * 20, 20.0 + rank * 20], device=f"cuda:{rank}"
)
print(f"[Rank {rank}] All-Gather local data: {local_data}")
gathered_list = [torch.zeros_like(local_data) for _ in range(world_size)]
dist.all_gather(gathered_list, local_data)
print(f"[Rank {rank}] All-Gather result: {gathered_list}")
gathered_tensor = torch.cat(gathered_list, dim=0)
print(f"[Rank {rank}] All-Gather concatenated: {gathered_tensor}")
def tp_demo(rank, world_size):
setup(rank, world_size)
test_all_reduce(rank, world_size)
time.sleep(5)
test_all_gather(rank, world_size)
cleanup()
def run_demo():
world_size = 2
mp.spawn(tp_demo, args=(world_size,), nprocs=world_size, join=True)
if __name__ == "__main__":
if torch.cuda.device_count() >= 2:
run_demo()
else:
print(f"需要至少 2 张 GPU 来运行此 TP 示例")10. 其他
本文基于 nano-vllm 项目,聚焦讲解大模型推理加速领域中最基础的若干核心技术点。需要说明的是,大模型推理加速的技术体系十分丰富,本项目并未覆盖全部内容,例如:计算通信重叠(Overlap)、多 token 预测(MTP,Multi‑Token Prediction)、多流、多进程服务(MPS,Multi-Process Service)、数据并行(DP)、流水线并行(PP)、上下文并行(CP)、专家并行(EP)以及 PD 分离等进阶技术方向,可作为后续深入学习的拓展内容。
注1:在本文的总结过程中,除了查看源代码,也借助 deepwiki 以及其他 AI 工具辅助。
本文: https://www.cnblogs.com/cswuyg/p/19471225
知乎: https://zhuanlan.zhihu.com/p/1989806890381746916
公众号: https://mp.weixin.qq.com/s/6mAZ49iP1SCKt5ZdWf6ErQ