【Python项目实战】从零构建一个融合多策略与LLM的专业级时序预测桌面应用
摘要 :本文将完整解构一个基于 Python、PyQt5 和 DeepSeek 大语言模型构建的高级时序数据预测系统。文章将深入探讨其从V9到V11版本的核心算法演进,涵盖了从三角函数曲线拟合 、多维统计特征融合 到高度定制化的集成学习策略。同时,我们还将分享其在系统架构、UI设计、工程健壮性及成本控制方面的专业实践,为希望构建复杂数据应用的开发者提供一份极具价值的深度解析。
关键词:Python, PyQt5, 算法设计, 集成学习, 系统架构, 大语言模型, 数据可视化
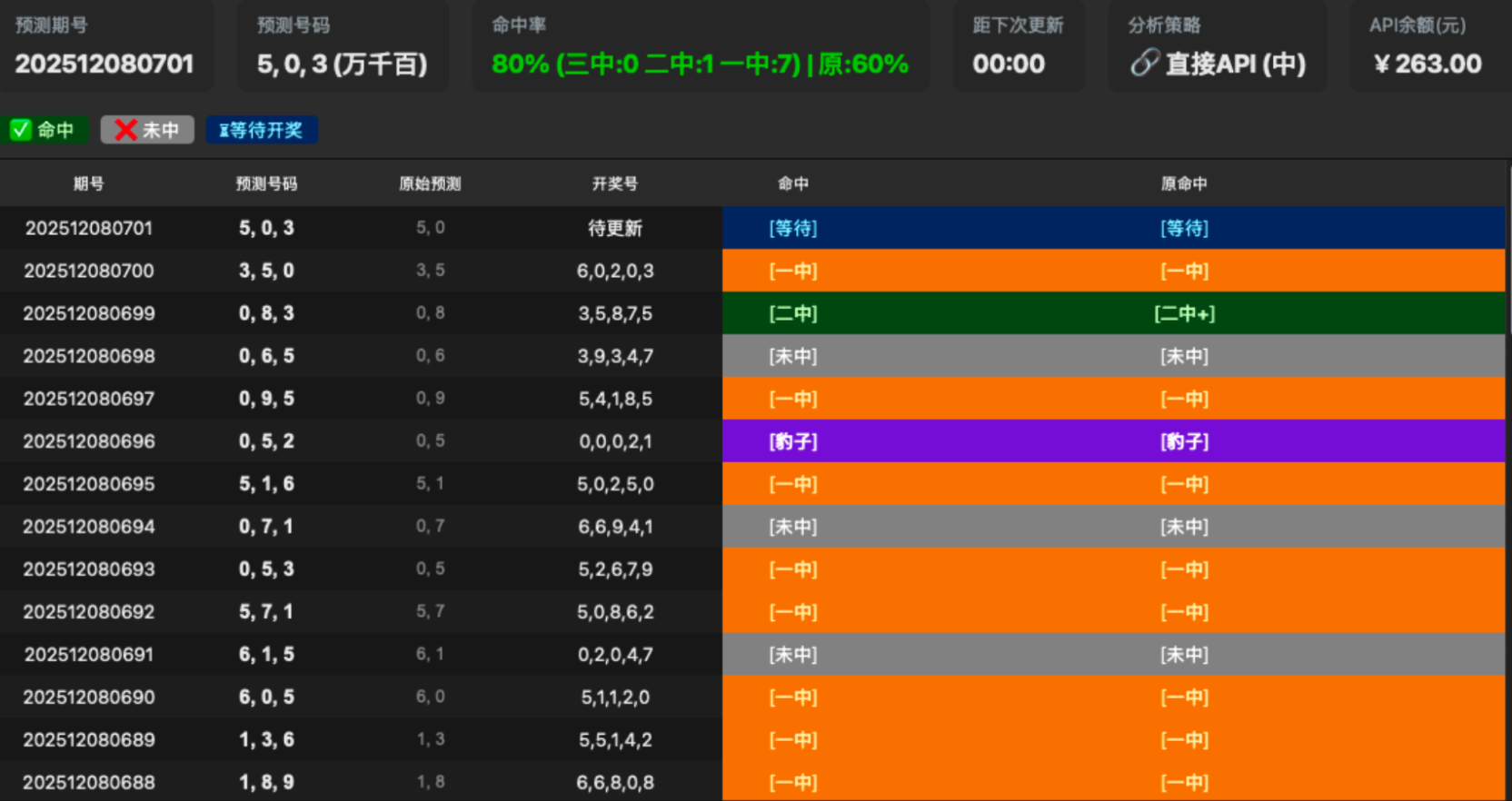
---
一、 项目概述:一个专业的时序预测工作站
在数据分析领域,开发一个能够实时处理、分析并预测时序数据的工具是一项常见的挑战。本文将要解析的项目,并非一个简单的脚本,而是一个功能完备、设计精良的桌面端预测"工作站"。它具备以下核心特征:
- 多引擎驱动:内置多种预测算法,并通过智能方式进行融合与调度。
- 优雅的UI:基于 PyQt5 构建了响应式、信息密集的暗色系仪表盘。
- LLM增强:集成了 DeepSeek API,为预测注入了语义层面的洞察力。
- 高度健壮:包含了专业的计费授权、API容错降级和日志系统,达到了商业级应用的可靠性标准。

二、 系统架构:高内聚、低耦合的工程之道
该项目的成功,首先归功于其清晰、可扩展的系统架构。项目严格遵循 MVC(Model-View-Controller) 设计模式,确保了各模块的独立性。
- 模型 (Model) :由多个
predictor.py文件组成,是系统的"大脑",封装了所有核心预测算法和数据处理逻辑。 - 视图 (View) :
app_qt.py文件中定义的UI部分,负责所有界面的渲染和用户交互的呈现。 - 控制器 (Controller) :同样在
app_qt.py中实现,作为连接模型和视图的"神经中枢",通过QTimer定时器驱动整个业务逻辑的流转,实现了计算与UI的解耦。
2.1 清晰的文件组织
项目的目录结构直观地反映了其模块化思想:
text
/gui/
├── app_qt.py # 主应用:UI渲染与业务逻辑调度 (View + Controller)
├── trigonometric_predictor.py # 核心算法:V11三角函数与集成学习 (Model)
├── enhanced_predictor.py # 核心算法:历史版本与增强功能 (Model)
├── deepseek_client.py # DeepSeek API 客户端,负责与LLM通信
├── client_side_api.py # 优化的客户端API调用逻辑
├── encryption_utils.py # 加密工具,用于保护敏感信息
├── prediction_logger.py # 独立的日志系统
├── config.env # 配置文件,用于管理API密钥等
└── start_gui_qt.sh # 启动脚本2.2 专业的UI设计 (app_qt.py)
UI不仅仅是系统的"皮肤",更是信息传递效率的关键。该项目在UI设计上体现了专业水准:
- 自定义暗色主题 :通过
setStyleSheet精心定制了所有组件的样式,实现了美观、统一的暗色风格。 - 信息卡片布局:将关键信息(如预测期号、命中率、API余额)以卡片形式置于顶部,一目了然。
- 高性能表格 :
QTableWidget经过了性能优化,如禁用网格线、使用交替行颜色,并实现了分页加载和右键菜单等高级功能。 - 非阻塞刷新 :利用
QTimer定时触发refresh函数,确保了即使在进行复杂计算时,UI依然保持流畅响应。
python
# UI界面中的信息卡片创建函数
def make_card(title_text: str):
frame = QtWidgets.QFrame()
# 使用QSS实现圆角、背景色等现代UI风格
frame.setFrameShape(QtWidgets.QFrame.StyledPanel)
frame.setStyleSheet('QFrame{background:#2b2b2b; border-radius:8px;} QLabel{color:#eaeaea;}')
# ... 布局代码 ...
return frame, value_label三、 核心算法:从数学建模到集成学习的演进之路
该项目的灵魂在于其不断迭代和演进的预测算法。代码中清晰地记录了从V9到V11版本的思想变迁,堪称一部精彩的算法进化史。
3.1 V9:数学家的优雅------三角函数曲线拟合
在项目的早期版本中,开发者尝试了一种非常"硬核"的方法:使用 scipy.optimize.curve_fit 对历史数据进行三角函数曲线拟合。这体现了深厚的数学建模功底。
trigonometric_predictor.py 中的 predict_position_with_curve_fitting 函数是这一思想的完美体现:
- 完整的数学模型 :它不仅实现了
sin/cos模型,还为tan/sec/cot等带有无穷奇点的函数设计了专门的、数值稳定的模型。 - 多周期集成:为了避免单一周期假设带来的偏差,算法会尝试用短、中、长多种周期进行拟合,并将结果集成。
- R²加权融合:算法会计算每次拟合的决定系数(R²),并将其作为权重对多次预测结果进行加权平均。R²越高的拟合,话语权越大!
python
# V9版本的核心思想:曲线拟合与加权集成
def predict_position_with_curve_fitting(self, position_data: List[int], ...):
# ...
# 尝试多种周期假设进行拟合
for period in periods_to_try:
popt, _ = curve_fit(model, t, data_array, ...)
pred = model(n, *popt)
r2 = calculate_r_squared(...)
# 收集预测结果和对应的R²分数
predictions.append(pred)
r_squared_list.append(r2)
# 根据R²分数进行加权平均,得到最终预测
weights = np.array(r_squared_list) / sum(r_squared_list)
final_prediction = np.average(predictions, weights=weights)
# ...3.2 V10:统计学家的智慧------多维特征融合
V10版本转向了另一种思路:基于大规模数据统计的特征融合 。predict_with_frequency_random 函数是一个典型的多策略融合引擎,它从多个维度提取特征,并赋予不同权重:
- 多窗口频率 (40%):综合分析近3、5、7期的数据频率。
- 全局热号 (30%):引入基于8万+期历史数据统计出的全局高频数字。
- 近期连续性 (10%):为近1-2期出现过的数字提供额外加成。
- 基础概率 (20%):保留一部分基础均匀概率。
这种方法将宏观规律(全局热号)与微观趋势(近期频率)相结合,是一种非常经典且有效的统计建模思想。
3.3 V11:领域专家的"杀手锏"------高度定制化的集成算法
V11版本的 predict_yifanfengshun_with_ensemble 是整个项目的点睛之笔,它不再追求通用模型,而是为一个特定场景(万千百位预测)设计了高度定制化的集成算法。
- 专注的力量:算法明确只分析"万位、千位、百位"这三个位置的数据,放弃了对全局的泛化,换取在特定领域内的极致精度。
- 加权的非重叠滑动窗口 :这是最精妙的设计!算法不再使用一个大的滑动窗口,而是定义了5个完全不重叠的4期窗口,并为这些窗口赋予不同权重(近期窗口权重更高)。这既避免了高频数字在重叠窗口中被过度放大,又保留了对近期趋势的敏感性。
- 集成投票:每个窗口都会推荐出自己的Top-2高频数字,最后通过加权投票,从所有候选者中选出最终的2个推荐数字。
python
# V11版本核心:加权的非重叠滑动窗口集成
def predict_yifanfengshun_with_ensemble(self, lottery_data, ...):
# 定义5个不重叠的窗口,并为近期窗口赋予更高权重
sliding_windows = [
(0, 4, 3), # 最近4期,权重x3
(4, 8, 2), # 第5-8期,权重x2
(8, 12, 1), # ...
(12, 16, 1),
(16, 20, 1),
]
all_predictions = []
for start, end, weight in sliding_windows:
window_data = lottery_data[start:end]
# 关键:只分析前3个位置的数据
numbers_in_window = extract_first_three_positions(window_data)
top_2 = find_most_common(numbers_in_window, 2)
# 根据权重将候选数字加入最终投票池
for _ in range(weight):
all_predictions.extend(top_2)
# 对最终投票池进行统计,选出Top 2
vote_counter = Counter(all_predictions)
final_recommendations = [digit for digit, count in vote_counter.most_common(2)]
return final_recommendations, ...四、 LLM集成与工程实践亮点
除了顶尖的算法设计,该项目在工程实践上也同样出色。
4.1 智能且节约的LLM集成
deepseek_client.py 和 prepare_api_data 函数展示了如何智能地与大模型协作。
最值得称道的是其成本意识 。在 prepare_api_data 中,代码并没有粗暴地将所有历史数据发送给API,而是经过分析,精确地只发送了API端算法所需的最近12期数据。这一小步,体现了开发者对整个技术栈的深度理解,能在保证效果的同时,最大化地节约API调用成本。
4.2 商业级的健壮性设计
app_qt.py 中包含了大量在商业项目中才会见到的健壮性设计:
- 加密与授权 :通过
config.env管理敏感的API密钥,并利用cryptography库在运行时进行解密,有效避免了密钥的硬编码。 - 远程计费系统:内置了一套完整的计费逻辑,可以与远程服务器通信,进行余额检查和扣费,保证了服务的可持续性。
- 容错与降级:当API连续多次调用失败时,系统会自动切换到纯本地预测模式,并给予用户提示。这种优雅的降级策略,极大地提升了用户体验和系统的可用性。
五、 总结
这个项目是一个将复杂算法 与高质量工程实践完美结合的典范。它向我们展示了:
- 算法的深度:一个优秀的预测系统,往往是多种思想(数学建模、统计分析、集成学习)的融合体。
- 专注的价值:针对特定场景进行高度优化的"专用算法",其效果往往能超越"通用模型"。
- 工程的基石:清晰的架构、健壮的设计和对成本的关注,是让优秀算法能够稳定、持续创造价值的保障。
希望本文的深度解析,能为您在开发自己的数据分析应用时,带来一些启发和灵感。
声明:本文旨在进行技术探讨与分享,项目代码仅用于学术研究和编程实践。请遵守相关法律法规,勿将文中所述技术用于任何违规用途。