这是索引文件(磁盘文件),文件命名规则:${storePath}/index/${timestamp}
作为一名优秀的桥梁,主要是存储消息索引key和消息物理偏移量offset索引的对应关系,简单说就是标记这个key在什么位置,方便快速定位commitlog消息,方便消费者消费,上帝自然要"伺候"到位了。
提供了一种通过key或时间区间来查询消息的方法
这究竟是怎么做到的呢?
首先还是从结构上说,文件名是创建时的时间戳,文件固定大小400M,优秀的设计智慧让一个indexfile可以保存2000w个索引,2000w呢!这你敢想?你是不是也有疑问,为什么能存这么多呢,大数量就要看底层了,咱们底层存储用的是map(所以rocketmq索引文件底层实现是hash索引)
+---------------------------------------------------------------+
| IndexFile (≈400MB) |
+-----------------------+---------------------------------------+
| Header (40B) | |
|-----------------------------------| Hash Slot Table 20M 500w个int |
| beginTimestamp最早消息的时间戳(8B) | +----+----+----+----+ ... +----+ |
| endTimestamp最晚消息时间戳 (8B) | | 0 |8872| 0 |1024| | 0 | |
| beginPhyOffset最早消息在commitlog中偏移量8B | +----+----+----+----+ ... +----+ |
| endPhyOffset最晚消息在commitlog中偏移量8B | ↑槽int值,>0指向indexLinkedList的序号 |
| hashSlotCount当前已使用hash槽数 4B | └── slot[123456] = 8872 |
| indexCount当前已写入的索引条数 (4B) | |
+-----------------------+---------------------------------------------------------------------------------+
| Index Linked List 2000w条目 |
| +-----------------------------------------------------------------------------------------------------------------+
| | Entry #1: keyHash=..., phyOffset=..., timeDiff=..., prevIndex=0 | 20B ← 链尾
| | Entry #8872: keyHash=..., phyOffset=123456789, timeDiff=3600, prevIndex=1024 |
| | Entry #1024: keyHash=..., phyOffset=123450000, timeDiff=3500, prevIndex=0 |
| +----------------------------------------------------------------------------------------------------------------+
| ↑ |
| └── slot[123456] 指向 #8872,形成链表:8872 → 1024 → 0 |
+---------------------------------------------------------------------------------------------------------------------+上面还是不太方便看,简单介绍一下:
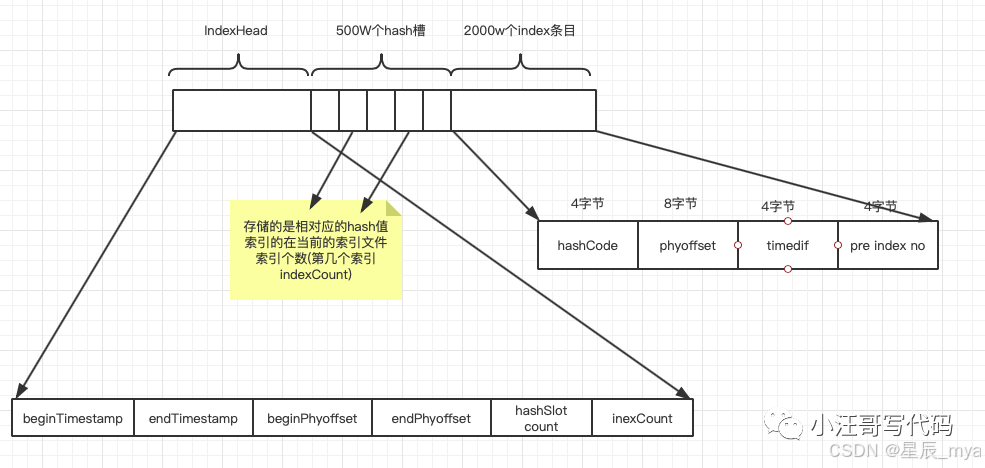
1、首先总的来说得有个概览,欸~indexhead 头就是一个概览,对吧,我当前的indexfile有什么,作为head有义务都给咱indexfile记下,比如最早几点来 的消息,最晚几点结束 的消息;咱们都知道,这生产者producer生产的消息来了肯定都不白来,只要你来我"跑着"去见你,咱就甭管是是什么,commitlog都会给你出位置、让你放;那么多消息放在哪是一个巨大的问题,当然rocketmq有很多解决方案,首先我索引文件必须名副其实,积极表现、麻溜就给你标记上,怎么记?首先我的头indexhead首当其冲,先把最早的那条、最晚的那条消息的偏移量、已经写入了多少条的索引给你记上,这样定一个基调也明确了责任,就是出了这范围咱就是那渣男------概不负责!你也别说我偷懒,总共给我40b位置,多了我也记不下,而且重要的hash槽,他用了多少了、我也得记着,方便下一个indexfile兄弟用,毕竟我们才是用"同一磁盘的血脉至亲"!再说你放心、剩下的我们hash槽兄弟会出手
2、hashSlotTable固定500万大军(哈希槽)每个槽4字节;先介绍他其实有点费劲,为什么我们head可怜兮兮20b还要要记录当前已经使用的hash槽数,因为每个槽存储的最新插入的索引项在索引区中的位置,说白了还是一个"索引",一共20M
https://cloud.tencent.com/developer/article/1850208
3、刚提到索引项,她就来了,索引项区indexLinkedList最多支持2000w索引项,每个20字节,和head比都是土豪了,这么多是用来存什么呢?不要着急,首先hashcode存储消息key的hashcode值方便去重定位,phyoffset这个好猜吧,消息的物理偏移量!这个就很重要了,自报家门、也不是自报,反正这不就是把人家家门都记得清清楚楚了!timeDiff相对于beginTimestamp的时间差(s)就说这个消息距离第一条消息已经过去了多长时间(大概这个意思吧);prevIndex这个很重要了,这是同一个哈希槽下的前一个索引项的位置(反向指针 ),前一个索引项的位置 ,这样就是一个反向链 表了!这设计真是天才啊,这样即使key冲突了,可以通过prevIndex反向链接解决,就是说当多个key映射到同一个slot时,他们不会覆盖而是通过prevIndex形成了一个时间倒序链表!查询到时候定位到这个链,咱们拿着hashcode和时间范围,在链表一个一个比较就能找到对的那个人、那个数值

slot[1001] → [Index#5] → [Index#3] → [Index#1] → null
↑ ↑ ↑
prev=3 prev=1 prev=0当然链表太长了,水满则溢,也不好:影响查询性能
两个结合看吧,大概是这么个意思,有不对的欢迎大佬指正
流程
上面说的虽然很精彩(嘘~),但是还不够,有些懵懵懂懂的,这可不太好
写入
当一条消息写入commitlog后,如果enableIndexWrite=true并且消息有n个key,则
- 计算key的hash值,就是keyhash(indexlinkedList索引项区中)
- 找到自己的位置:计算槽位slotIndex:int slotIndex = keyHash % hashSlotNum; // hashSlotNum = 5,000,000;os 人这一生清楚自己的位置,知道自己的定位很重要,我得向咱们rokcetmq多学习;
- 找到前任的位置:如果有的话获取上一个slot值prevIndex:int prevIndex = this.indexHeader.get(slotIndex);os所以人这一生搞好邻里关系同样重要,万一有个什么事,这都是很好的关系,为你遮风挡雨、为你kuku躲避哈希冲突;
- 真正弄自己的位置:首先phyOffset(自己的本我在commitLog中的哪里);timeDiff距离开始现在已经过去了多少秒,会不会太久而让老大生气;prevIndex上一步获取的值的位置
- 尘埃落定:写入索引区IndexLinkedList新索引项追加到索引区末尾:当前 indexCount + 1,更新 slotslotIndex = newIndexPos,正式入驻
- 哦还有header,这个老大哥终于出现了,更新
endTimestamp结束的时间戳、endPhyOffset最后的物理偏移量,看来随着这新一条的加入大家迎来新的面孔,当然indexCount也得++当前已写入的索引条数喜加一条,所以咱就是说关键时刻在人家地盘上一定得报备或得官方承认;当然如果是第一个消息,也得更新新beginTimestamp、beginPhyOffset,可以看得出我这一生如履薄冰、尽心尽责、思虑周全
每条带key的都出发索引写入,增加了IO,毕竟是磁盘文件;不过好在indexFile 异步构建的(由后台线程处理 PutRequestQueue)问题不大。
查询
queryMessage(key, maxNum, begin, end)
- 自然先遍历indexFile(倒序从新到旧)利用
begin/endTimestamp快速跳过不匹配的,看到没都是有用的,而且是大用处,不可小觑 - 找到了indexFile,计算slotIndex找到槽slotIndex = key.hashCode() % 5,000,000,读取
slot[slotIndex]得到第一个索引项位置indexPos,沿着prevIndex链表反向遍历:hashcode是否匹配,timeDiff + beginTimestamp是否在[begin, end]范围内,将phyOffset加入结果集 - 达到maxNum的限制,人不能太贪,主要是太多重了------拿不走
- 根据phyOffset从commitlog中获取信息
大家也能看粗来,这key都是精确匹配的,不能模糊查询,要什么自行车
大概是这样,是不是很智慧,现在满屏扣智慧,谢谢大家的阅读,请多多指教!