在低空遥感目标检测领域,看到了不少文章都使用UAVDT数据集进行实验。
据其论文1所述,该数据集是从 10 小时的原始视频中选取约 8 万帧代表性图像的方式进行构建,适用于三种基本的计算机视觉任务:目标检测、单目标跟踪和多目标跟踪。
然而,当我通过尝试使用它进行目标检测任务时,发现其存在巨大缺陷,本文来复盘一下问题过程。
数据集格式
在datasetninja2上,可以下载到此数据集。
该数据集文件(压缩包)共13GB,数据集的结构如下:
uavdt-DatasetNinja/
├── train/ # 训练集:包含图像(img)、标注(ann)和数据集元信息(meta)
├── test/ # 测试集:包含图像(img)、标注(ann)和数据集元信息(meta)
└── README.md # 数据集说明与使用说明其中,训练集包含24143个样本,测试集包含53676个样本,图像分辨率为 1080 × 540 像素。
目标类别分为三大类:轿车、卡车和公共汽车。
值得注意的是,在测试集中,一部分样本是S开头,如S1702_img000318.jpg,该数据的目标类别标记是vehicle,用于单目标跟踪任务,在做其它任务时,需要剔除。
异常现象
剔除完S开头的样本后,从训练集中随机挑选6000张样本,从测试集中随机挑选2000张样本。
转换成YOLO的标签格式,采用YOLO11s模型进行训练,出现了以下结果:
| Class | Images | Instances | Precision § | Recall ® | mAP@50 | mAP@50--95 |
|---|---|---|---|---|---|---|
| all | 2000 | 45128 | 0.404 | 0.371 | 0.314 | 0.186 |
| car | 1999 | 43312 | 0.715 | 0.635 | 0.682 | 0.370 |
| truck | 664 | 905 | 0.101 | 0.158 | 0.0447 | 0.0254 |
| bus | 597 | 911 | 0.398 | 0.321 | 0.216 | 0.162 |
car和bus两个类别还稍微正常一些,但truck的类别mAP@50的数值仅4.47%,低得"令人发指"。
标签可视化
出现这种原因,一般有两种可能:
- 训练集和测试集的truck差距很大,或样本严重不平衡。如果是这个问题,看测试集目标数量,truck和bus都是900多,不至于差异会如此巨大。
- 数据标注有问题
为了验证是数据标注的问题,写了一个py脚本,以实现标签可视化。
python
import json
import cv2
import random
from pathlib import Path
# =========================
# 配置区
# =========================
IMG_DIR = Path(r"E:\Dataset\uavdt-DatasetNinja\test\img")
ANN_DIR = Path(r"E:\Dataset\uavdt-DatasetNinja\test\ann")
OUT_DIR = Path(r"E:\Dataset\uavdt-DatasetNinja\test\vis")
OUT_DIR.mkdir(parents=True, exist_ok=True)
IMG_EXTS = {".jpg", ".jpeg", ".png"}
RANDOM_SEED = 42
random.seed(RANDOM_SEED)
class_color_map = {}
def get_color_for_class(class_name: str):
"""
为每个类别动态分配一个稳定颜色
同一类别在整个数据集内颜色一致
"""
if class_name not in class_color_map:
class_color_map[class_name] = (
random.randint(50, 255),
random.randint(50, 255),
random.randint(50, 255),
)
return class_color_map[class_name]
# =========================
# 主处理逻辑
# =========================
for img_path in IMG_DIR.iterdir():
if img_path.suffix.lower() not in IMG_EXTS:
continue
# 标注名是 xxx.jpg.json
ann_path = ANN_DIR / f"{img_path.name}.json"
if not ann_path.exists():
print(f"[WARN] 标注缺失: {ann_path.name}")
continue
# 读取图像
img = cv2.imread(str(img_path))
if img is None:
print(f"[WARN] 图像读取失败: {img_path.name}")
continue
# 读取 JSON
with open(ann_path, "r", encoding="utf-8") as f:
ann = json.load(f)
objects = ann.get("objects", [])
for obj in objects:
if obj.get("geometryType") != "rectangle":
continue
# =========================
# 类别 & 颜色(完全动态)
# =========================
class_name = obj.get("classTitle", "unknown")
color = get_color_for_class(class_name)
# =========================
# bbox(左上 & 右下)
# =========================
(x1, y1), (x2, y2) = obj["points"]["exterior"]
x1, y1, x2, y2 = map(int, [x1, y1, x2, y2])
# 画框
cv2.rectangle(img, (x1, y1), (x2, y2), color, 2)
# =========================
# 可选 target id
# =========================
target_id = None
for tag in obj.get("tags", []):
if tag.get("name") == "target id":
target_id = tag.get("value")
label = class_name
if target_id is not None:
label += f" | id:{target_id}"
# =========================
# 文本背景 + 文本
# =========================
(tw, th), _ = cv2.getTextSize(label, cv2.FONT_HERSHEY_SIMPLEX, 0.5, 1)
# 背景框
cv2.rectangle(
img,
(x1, max(0, y1 - th - 4)),
(x1 + tw, y1),
color,
-1,
)
# 文本
cv2.putText(
img,
label,
(x1, y1 - 2),
cv2.FONT_HERSHEY_SIMPLEX,
0.5,
(0, 0, 0),
1,
cv2.LINE_AA,
)
# =========================
# 保存结果
# =========================
out_path = OUT_DIR / img_path.name
cv2.imwrite(str(out_path), img)
print("可视化完成")可视化之后,发现标注果然是有严重问题的,甚至有AI标注的嫌疑,下面几个代表性的例子。
例子一:这一组图,第一张图车辆在收费路口阴影处,未标记,第二张图离开阴影,就出现标记,多半是模型直接推理的结果。
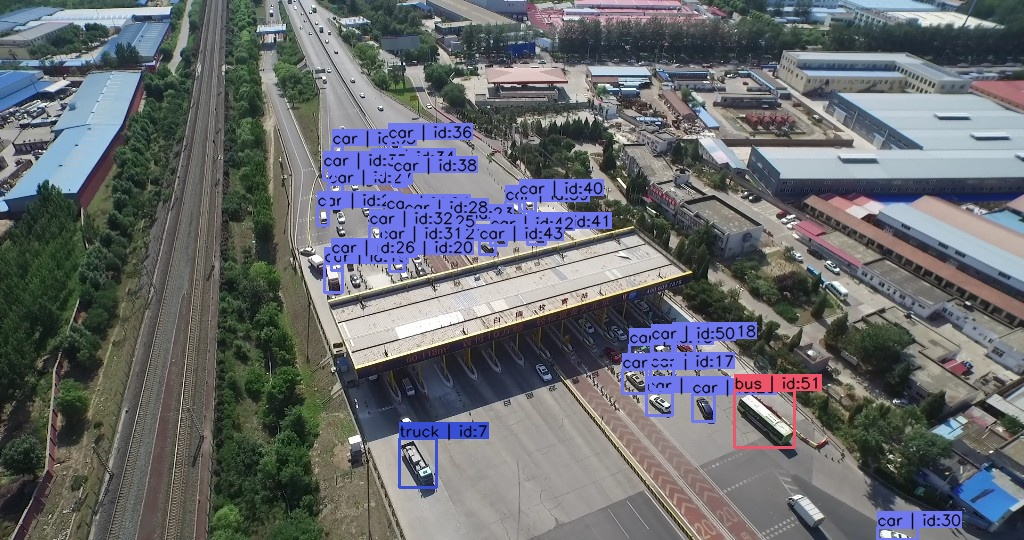

例子二:这张图的标注是前一张图复制得到的,出现错位。
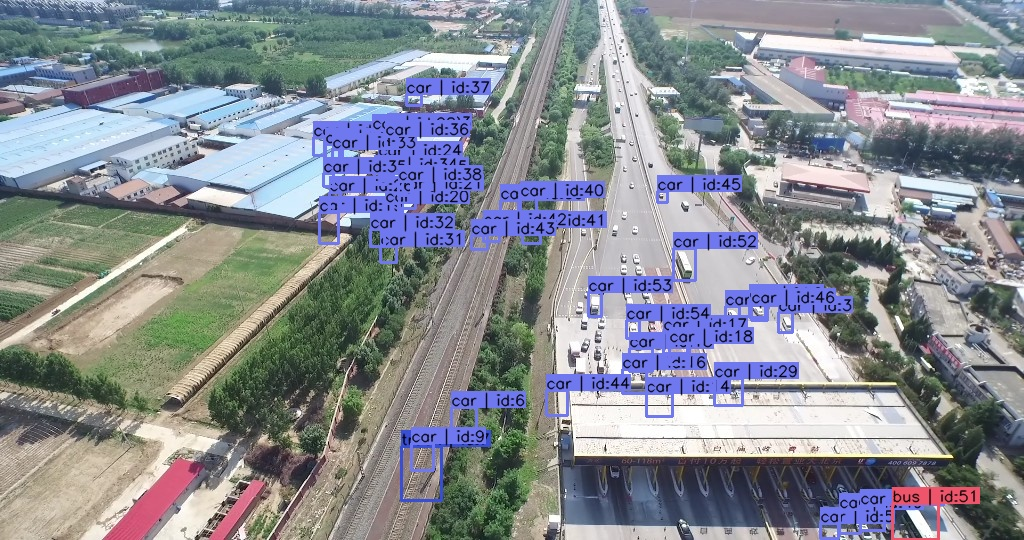
例子三:这张图出现了两个虚空框,明显是模型的错误推理,且路边大量车辆无标注。
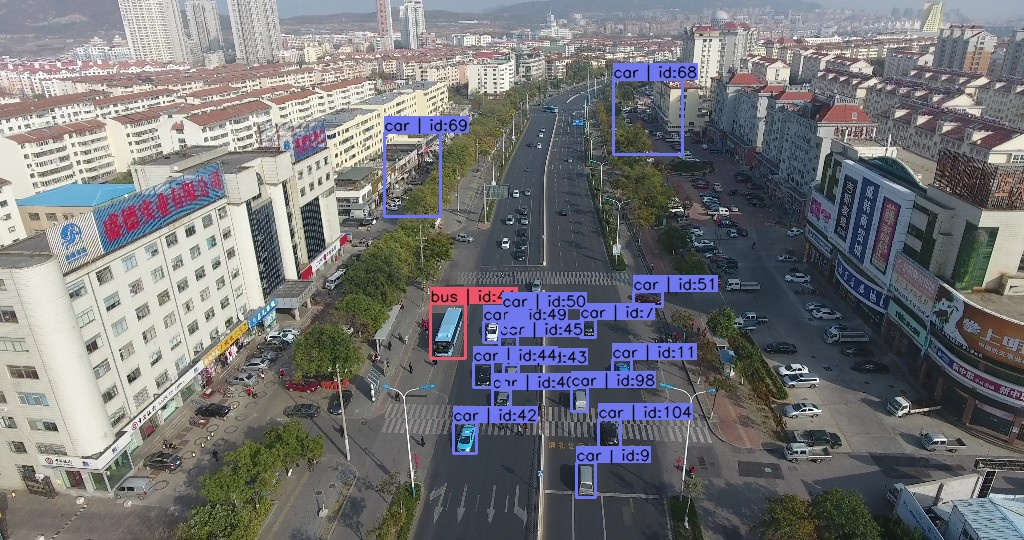
例子四:这张图里面的bus标注成了truck,存在错标,疑似模型错误推理。
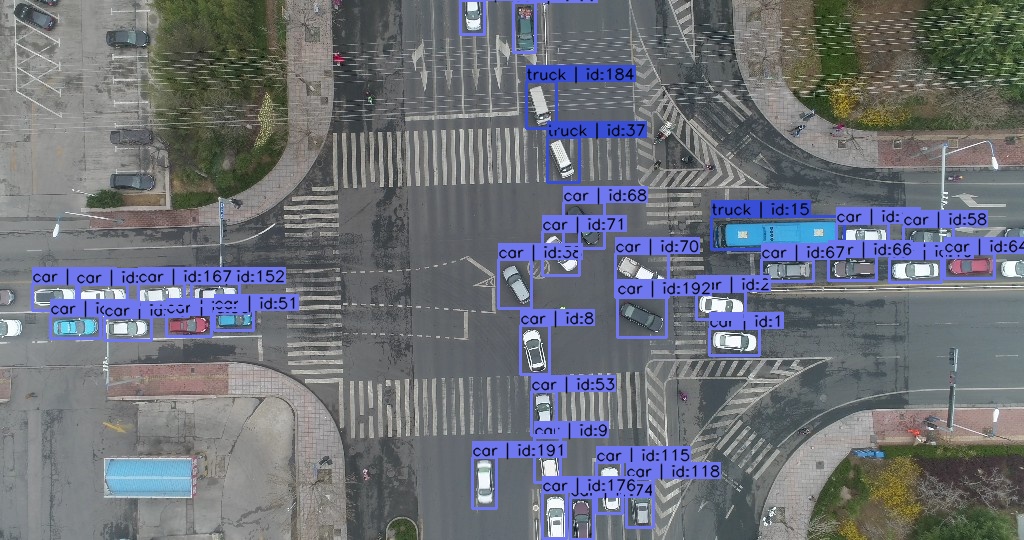
例子五:这张图里面的同样出现虚空标注,且大量目标存在漏标。

类似的例子不胜枚举,脏数据对模型的祸害罄竹难书。
总结
回头再看这个数据集相关论文的表述,他们说这是请了10名领域专家花了两个月时间手工标注。
显然,这是说法缺乏可信度。

这篇论文目前已获得1k余次引用,这些研究同行们,是怎么用这般劣质数据集做出科研成果的呢?