1 前言
QA:"bug, 你把这个 bug 处理一下。"
我:"这个 bug 复现不了,你先复现一下。"
QA:"我也复现不了。"
(PS: 面面相觑脸 x 2)
众所周知,每个公司每个项目都可能存在偶现的缺陷,毋庸置疑,这为问题的定位和修复带来了严重的阻碍。
要解决这个问题,社区方案中常常依赖 datadog、sentry 等问题记录工具,但这些工具存在采样率限制或依赖错误做信息收集,很难做到 100% 的日志记录。

偶然间,我看到了 pagespy,它符合需求,但又不完全符合,好在调研下来,我们只要魔改一番,保留其基础的日志能力,修改其存储方式,就能得到一个能做全天候日志采集的工具。
那么,目标明确:
- 实现全时段用户行为录制与回放
- 最小化对用户体验的影响
- 确保数据安全与隐私保护
- 与现有系统(如 intercom )无缝集成
2 SDK 设计
目前 pagespy 设计目标和我们预期并不一致,并不能开箱即用。pagespy 的方案不满足我们需求的点在于:
- 没有持久化能力,内存存储,单次录制不对数据做导出则数据清空。
- pagespy 的设计理念中。数据是需要显式由用户手动导出的,但我们是需要持续存储数据。
经过对 pagespy 的源码解析以及文档阅读,整理出来其中分支的 OSpy(离线版 pagespy 的数据走向如下):
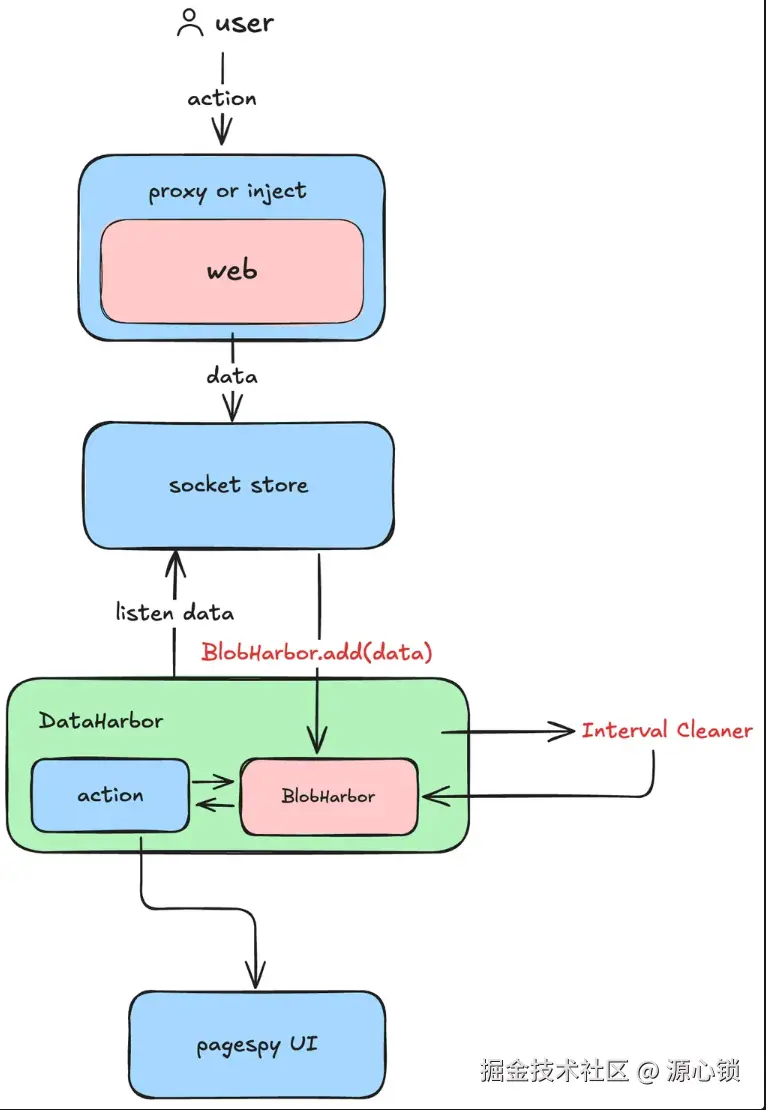
我们可以通过 inject 的形式,把这两个能力代理到我们的逻辑中。
样式上,则通过插入一段 style 强制将 dom 样式隐藏。
js
document.head.insertAdjacentHTML(
'beforeend',
`<style>
#o-spy {
display: none;
}
</style>`,
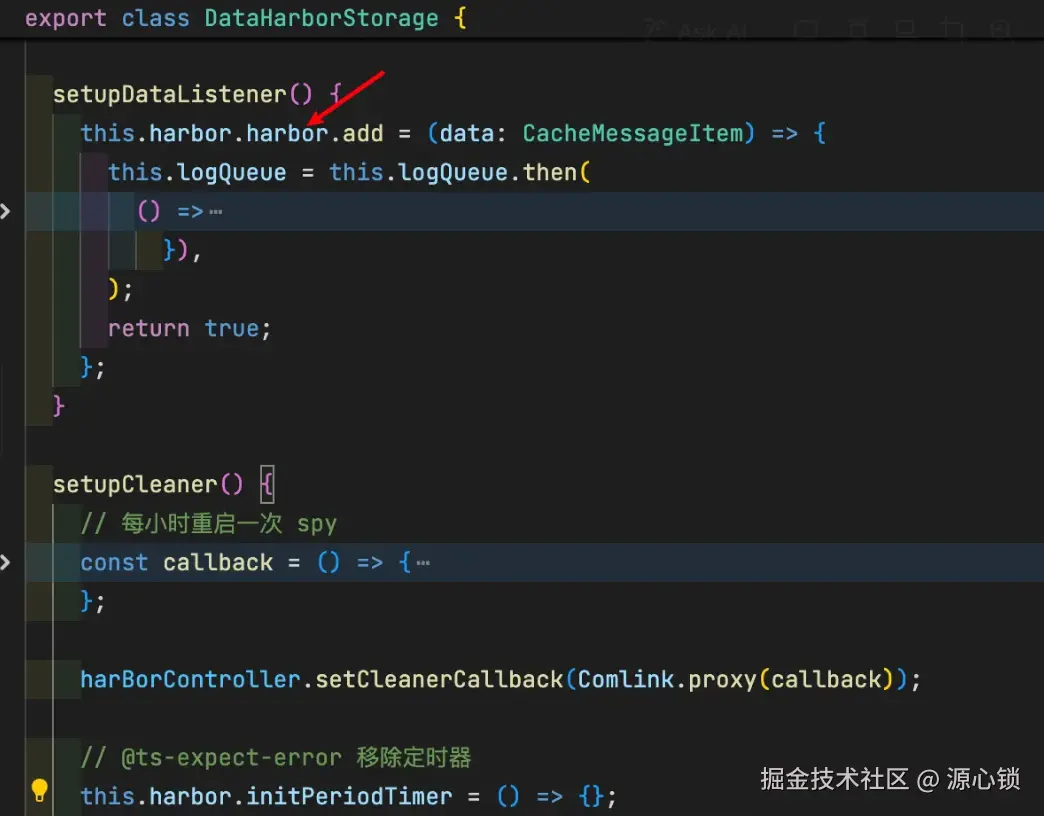
);至此,我们已经基本脱离了 pagespy 的数据 in & out 逻辑,所有数据都由我们来处理,包括数据存储也需要我们重新设计。
2.1 日志存储方案
✅ 确定日志存储方案。需要注意避免大量日志将用户的电脑卡死。
✅ pagespy 的设计理念中。数据是需要显式由用户手动导出的,但我们是需要持续存储数据。
✅ pagespy 为了防止爆内存引入了时间上限等因素,会时不时清除数据(rrweb 存在非常重要的首屏帧,缺少该帧后续都无法渲染成功),这会导致以单个浏览器标签作为切片的设计逻辑被迫中断,会对我们的逻辑带来负面影响。
为了实现全时段存储的目标,经评估除了 indexDB 之外没有其他很好的存储方案可以满足我们的大容量需求。在此,决定引入 dexie 进行数据库管理。
js
import type { EntityTable } from 'dexie';
import Dexie from 'dexie';
const DB_NAME = 'SpyDataHarborDB';
export class DataHarborClient {
db: DBType;
constructor() {
this.db = new Dexie(DB_NAME) as DBType;
this.db.version(1).stores({
logs: '++id,[tabId+timestamp],tabId, timestamp',
metas: '++id,tabId,startTime,endTime',
});
}
}
export const { db } = new DataHarborClient();我们将日志以浏览器标签页为维度进行拆分,引入了 tabId 的概念。并设计了两个表,一个用于存储日志,一个用于存在 tab 的基本信息。
js
type DBType = Dexie & {
logs: EntityTable<{
id?: number;
tabId: string;
timestamp: number;
data: string;
}>;
metas: EntityTable<{
id?: number;
tabId: string;
size: number;
startTime: number;
endTime: number;
}>;
};这意味着,从 pagespy 得到的数据只需要直接入库,我们在每次入库后做一次日志清理,即可实现一个基本的存储系统。
js
async addLog(data: CacheMessageItem) {
const now = new Date();
const dataStr = JSON.stringify(data);
await db.logs.add({
tabId: this.tabId,
timestamp: now.getTime(),
data: dataStr,
});
await db.transaction('rw', ['metas'], async (tx) => {
const meta = await tx.metas.get({
tabId: this.tabId,
});
if (meta) {
meta.size += dataStr.length;
meta.endTime = now.getTime();
await db.metas.put(meta);
return meta;
} else {
await db.metas.add({
tabId: this.tabId,
size: dataStr.length,
startTime: now.getTime(),
endTime: now.getTime(),
});
}
});
}在我们完成日志入库之后,额外需要考虑的是持续直接入库的性能损耗。 经测试,通过 worker 进行操作与直接在主线程进行操作,对主线程的耗时影响对比表格如下(基于 performance.now()):
| 操作方式 | 峰值 | 最低值 | 中位数 | 平均值 |
|---|---|---|---|---|
| worker + insert | 5.3 ms | 0ms | 0.1ms | 0.31ms |
| 直接 insert | 149.5 ms | 0.4ms | 3.6ms | 55.29ms |
所以最终决策将数据库操作转移到 worker 中实现------但这又反应了一点问题,目前 pagespy 的入库数据是序列化后的字符串,并不能很好地享受主线程和 worker 线程之间通过 transfer 传输的性能优势。
2.2 安全和合规问题
目前可知,我们的方案先天就存在较严重的合规问题 🙋,这体现在:
- pagespy 会保存一些隐秘的 storage、cookie 数据到 indexedDB 中,有一定安全风险。
- pagespy 基于 rrweb ⏺️ 录制页面,用户在电脑上的行为和信息可能被记录。(如 PII 数据)
第一个问题,我们可以考虑直接基于 Pagespy 来记录,其实际上提供了 API 允许我们自行决定要抛弃哪些信息。
使用时,类似于:
js
network: (data) => {
if (['fetch', 'xhr'].includes(data.requestType)) {
data.responseHeader?.forEach((item) => {
if (item[0] === 'set-cookie') {
item[1] = obfuscate(item[1]);
}
});
return true;
}
return true;
},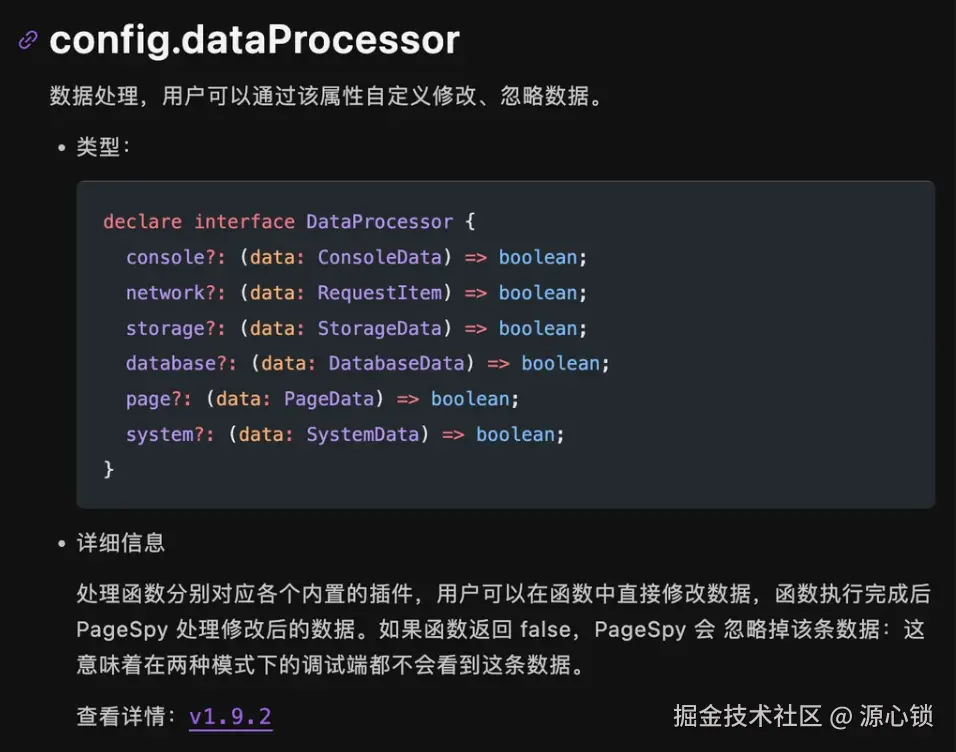 第二个问题,我们应考虑基于 rrweb 的默认隐私策略来做处理,rrweb 在 sentry、posthog 中都有使用,都是基于默认屏蔽规则来允许,所以我们使用默认屏蔽规则,其他库的隐私合规也相当于一起做了。
第二个问题,我们应考虑基于 rrweb 的默认隐私策略来做处理,rrweb 在 sentry、posthog 中都有使用,都是基于默认屏蔽规则来允许,所以我们使用默认屏蔽规则,其他库的隐私合规也相当于一起做了。
所以,我们需遵循以下规则(rrweb 默认屏蔽规则)修改 Web 端,而不是 SDK:
- 具有该类名的元素
.rr-block不会被记录。它将被替换为具有相同尺寸的占位符。 - 具有该类名的元素
.rr-ignore将不会记录其输入事件。 - 具有类名的元素
.rr-mask及其子元素的所有文本都将被屏蔽。和 block 的区别是,只会屏蔽文本,不会直接替换 dom 结构(也就是背景颜色之类的会保留) 。 input[type="password"]将被默认屏蔽。
根据元素是否包含"用户输入能力",分为 3 种处理方式:
-
1️⃣ 包含输入能力(如
input,textarea,canvas可编辑区域)- 目的:既屏蔽用户的输入行为,也屏蔽输入内容
- 处理方式 :添加
rr-ignore和rr-block两个类 - 效果:

-
2️⃣ 不包含输入能力(如纯展示类的文本)
- 目的:保留结构,隐藏文本内容,避免泄露隐私
- 处理方式 :添加
rr-mask类,将文本进行混淆显示 - 效果:
-
3️⃣ 图片、只读 canvas 包含隐私信息(如签名)
- 目的:隐藏内容
- 处理方式 :添加
rr-block类
2.3 日志获取和处理
在上述流程中,我们设计了基于浏览器标签页的存储系统,但由于 rrweb 和 ospy 的设计,我们仍有两个问题待解决:
- ospy 中的 meta 帧只在 download 时获取,并需要是 logs 的最后一帧。
- rrweb 存在特殊限制,即必须存在首 2 帧,否则提取出来的日志无法显示页面。
这两个问题我们需要特殊处理,针对 meta 帧的情况,首先要知道,meta 帧包含了客户端信息等数据:
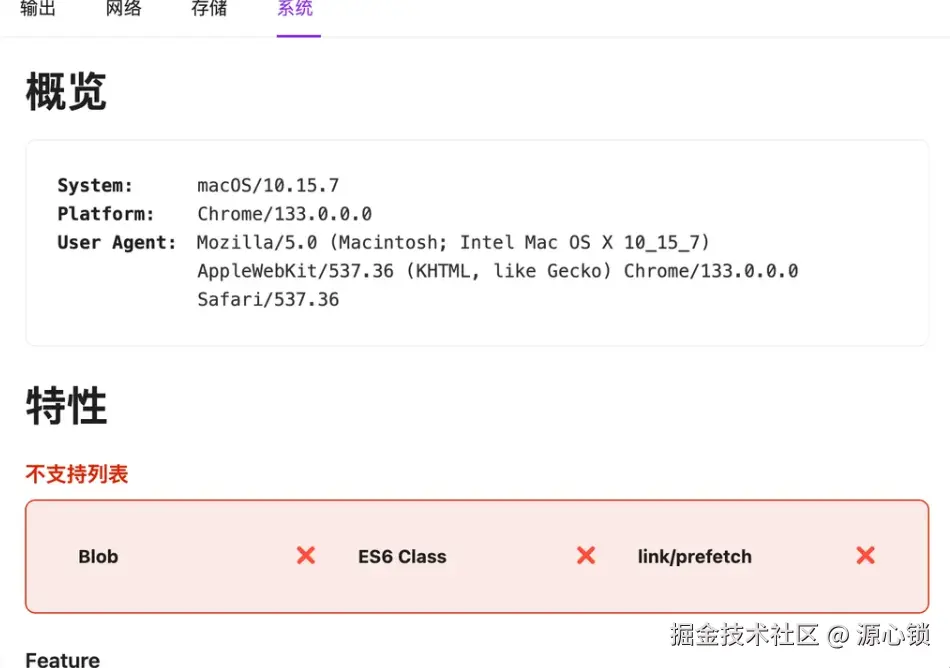

这部分信息虽然相比之下不是那么重要,但在特定场景中非常有用,nice to have。在此前提下,由于 ospy 未提供对外函数,我们需要自行添加该帧。目前,meta 帧会在 spy 初始化时自动插入,然后在读取时排序到尾部。
js
// 这个其实是 spy 的源码
export const minifyData = (d: any) => {
return strFromU8(zlibSync(strToU8(JSON.stringify(d)), { level: 9 }), true);
};
export const getMetaLog = () => {
return minifyData({
ua: navigator.userAgent,
title: document.title,
url: window.location.href,
startTime: 0,
endTime: 0,
remark: '',
});
};第二个问题相比之下更加致命,但解决起来又异常简单。rrweb 的机制决定了我们在导出的时候必定要查询出第一二帧,我们在获取日志时需要特殊处理:
- 获取用户指定日期范围内的日志的 tabId。
- 基于 tabId 筛查出所有日志,筛查出 < endTime 的所有日志。
js
async getTabLogs({ tabId, end }: { tabId: string; end: number }) {
// 日志获取逻辑
}(如你所见,获取日志阶段 start 直接 gank 没了)
此外,由于持续存储特性,读取日志时会面临数据量过大的问题。例如,8 分钟连续操作导出的日志约 17MB,一小时约 120MB。按照平均每小时录制数据量估算,静态浏览约 2 - 5MB,普通交互约 50MB,高频交互约 100MB。以单个用户每日使用 8 小时计算,平均用户约 400MB / 天,重度用户约 800MB / 天。基于 14 天保留策略,单用户最大存储空间约为 12GB。
这意味着如果用户选择的时间范围较大,传统读取流程可能读取 10GB+ 日志到内存,这显然会导致浏览器内存溢出。
为避免读取大量日志导致浏览器内存溢出,我们采用分片式读取。核心思想是将指定 tab 的日志数据按需 "分片提取",通过回调逐步传输给调用方,确保高效、稳定地处理大体积日志的读取与传输:
-
读取元信息 (
meta):- 通过
tabId从db.metas获取对应日志的元信息(如日志总大小)。
- 通过
-
判断是否需要分片:
- 如果日志总大小小于阈值
MIN_SLICE_CHUNK_SIZE,一次性读取所有日志 ,拼接成完整 JSON,再调用callback发送。
- 如果日志总大小小于阈值
-
大文件分片处理逻辑:
- 根据日志总大小计算合适的
chunkSize,从而决定分片数量chunkCount。 - 每次读取一部分日志数据(受限于计算出的
limit),拼接为 JSON 片段,通过callback逐步传出。 - 每片都使用
Comlink.transfer()进行内存零拷贝传输,提高性能。
- 根据日志总大小计算合适的
-
合并与补充 meta 信息:
- 如果日志数据中有
meta类型数据(携带一些压缩信息),在最后一片中进行处理与拼接,保持语义完整。
- 如果日志数据中有
-
进度追踪与标记:
- 每一片传输都附带
progress和partNumber,便于前端追踪处理进度。
- 每一片传输都附带
js
async getTabLogs(
{
tabId,
end,
}: {
tabId: string;
end: number;
},
callback: (log: { content: Uint8Array; progress: number; partNumber: number }) => void | Promise<void>,
) {
...
const totalSize = meta.size + BUFFER_SIZE;
// 根据 totalSize、MAX_SLICE_CHUNK、MIN_SLICE_CHUNK_SIZE 计算出最佳分片大小
const chunkSize = Math.max(Math.min(totalSize / MAX_SLICE_CHUNK, MIN_SLICE_CHUNK_SIZE), MIN_SLICE_CHUNK_SIZE);
const chunkCount = Math.ceil(totalSize / chunkSize);
let offset = 0;
const count = await db.logs
.where('tabId')
.equals(tabId)
.and((log) => log.timestamp <= end)
.count();
const limit = Math.max(1, Math.ceil(count / chunkCount / 3));
let metaData: string | null = null;
let startTime = 0;
let endTime = 0;
let preLogStr = '';
let progressContentSize = 0;
let partNumber = 1;
while (offset <= count) {
try {
const logs = await db.logs
.where('tabId')
.equals(tabId)
.and((log) => log.timestamp <= end)
.offset(offset)
.limit(limit)
.toArray();
let baseStr = preLogStr;
if (offset > 0) {
baseStr += ',';
} else if (offset === 0) {
baseStr += '[';
}
endTime = logs?.[logs.length - 1]?.timestamp ?? endTime;
if (offset === 0) {
startTime = logs?.[0].timestamp ?? 0;
}
offset += logs.length;
const logData = logs.map((log) => log.data).filter((log) => log !== '"PERIOD_DIVIDE_IDENTIFIER"');
...
const logsStr = logData.join(',');
baseStr += logsStr;
if (offset === count) {
if (!metaData) {
await callback({
content: transfer(baseStr + ']'),
progress: 1,
partNumber,
});
} else {
const metaJson = JSON.parse(metaData);
const parseMetaData = parseMinifiedData(metaJson.data);
const metaMinifyData = minifyData({
...parseMetaData,
startTime,
endTime,
});
const metaStr = JSON.stringify({
type: 'meta',
timestamp: endTime,
data: metaMinifyData,
});
await callback({
content: transfer(baseStr + ',' + metaStr + ']'),
progress: 1,
partNumber,
});
}
break;
}
progressContentSize += baseStr.length;
const progress = Math.min(0.99, progressContentSize / totalSize);
// 如果 size < minSize,那么就继续获取
if (baseStr.length < MIN_SLICE_CHUNK_SIZE) {
preLogStr = baseStr;
continue;
}
preLogStr = '';
await callback({
content: transfer(baseStr),
progress,
partNumber,
});
partNumber++;
} catch (error) {
console.log(error);
break;
}
}
}3 工作流设计
3.1 👼 基础工作流
我们公司采用 intercom 和外部客户沟通,用户可以在网页右下角的 intercom iframe 中和客服沟通。
所以,如果有办法将整个日志流程合并到目前的 intercom 流程中,不仅贴合目前的业务情况,而且不改变用户习惯。
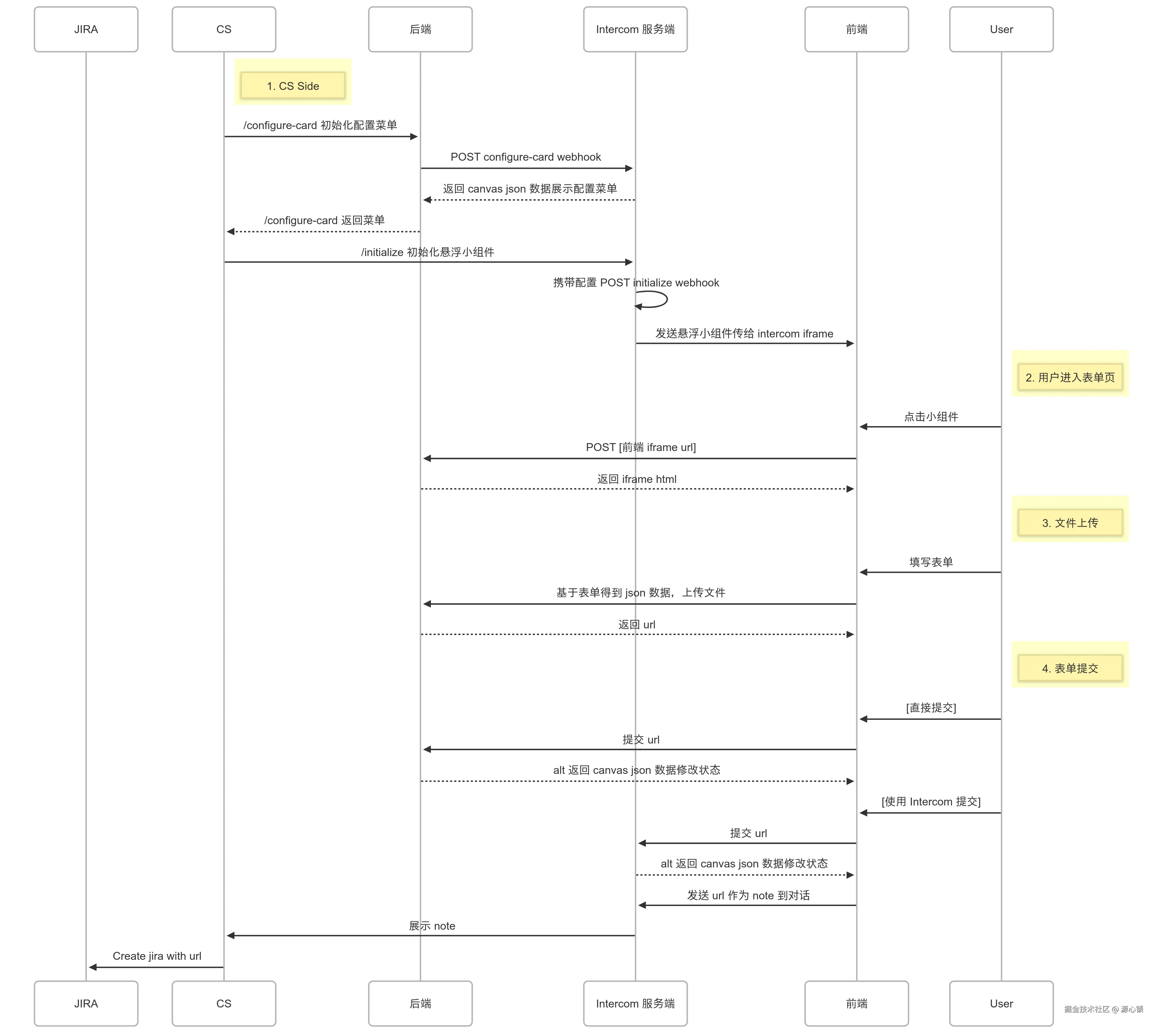
通过调研,可以确定以下方案:
- CS 侧配置默认时间范围,需要
POST /configure-card进行表单填写,填写后表单会在下一步被携带到 payload 中。 - CS 侧在发送时,会
POST /initialize接口(由自有后端提供),接口需返回 canvas json 数据。如:
css
{
canvas: {
content: {
components: [
{
type: "text",
text: "*Log Submission*",
style: "header",
},
{
type: "button",
label: "Select logs",
style: "primary",
id: "submit_button",
action: {
type: "sheet",
url: "xxxxxx",
},
},
],
},
},
}- 发送后,用户点击 sheet 按钮可以跳转到前端,但需注意,该请求为 POST 请求。
- 用户填写完表单,提交时可以直接请求后端接口,也可以由 intercom 服务端向后端发起 POST 请求。
- 如期望在提交后修改消息状态,则必须在上一步执行【由 intercom 服务端向后端发起 POST 请求】(推荐,最完整的 flow),此时后端需返回 canvas json,后端同步触发逻辑,添加 note 到 intercom 页面,方便 CS 创建 jira 单时携带复现链接
3.2 ⚠️ 增强工作流
在我们上述 flow 中,需要获取用户授权,由用户操作触发下载和上传日志的过程,但实际上有比较刑的方案。
具体 flow 如图:
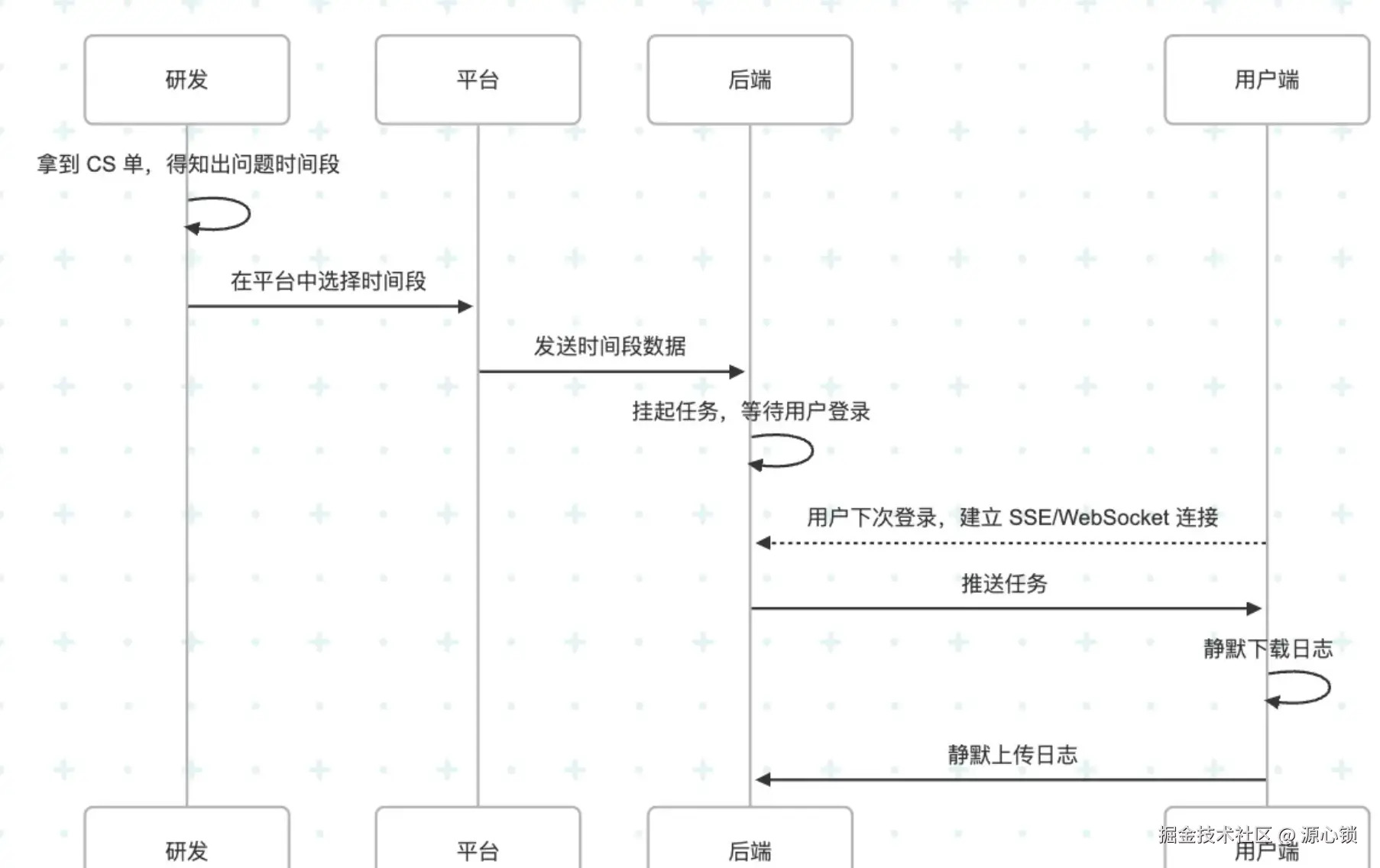
该方案的整体优势是:
- 无需 CS 介入,无需修改 CS 流程。
- 用户对日志上传感知力度小
换句话说,隐私合规风险较大。
4 工作流技术要点
4.1 😈 iframe 实现
Iframe 指的是 【日志上传 iframe】,对应这一步骤:
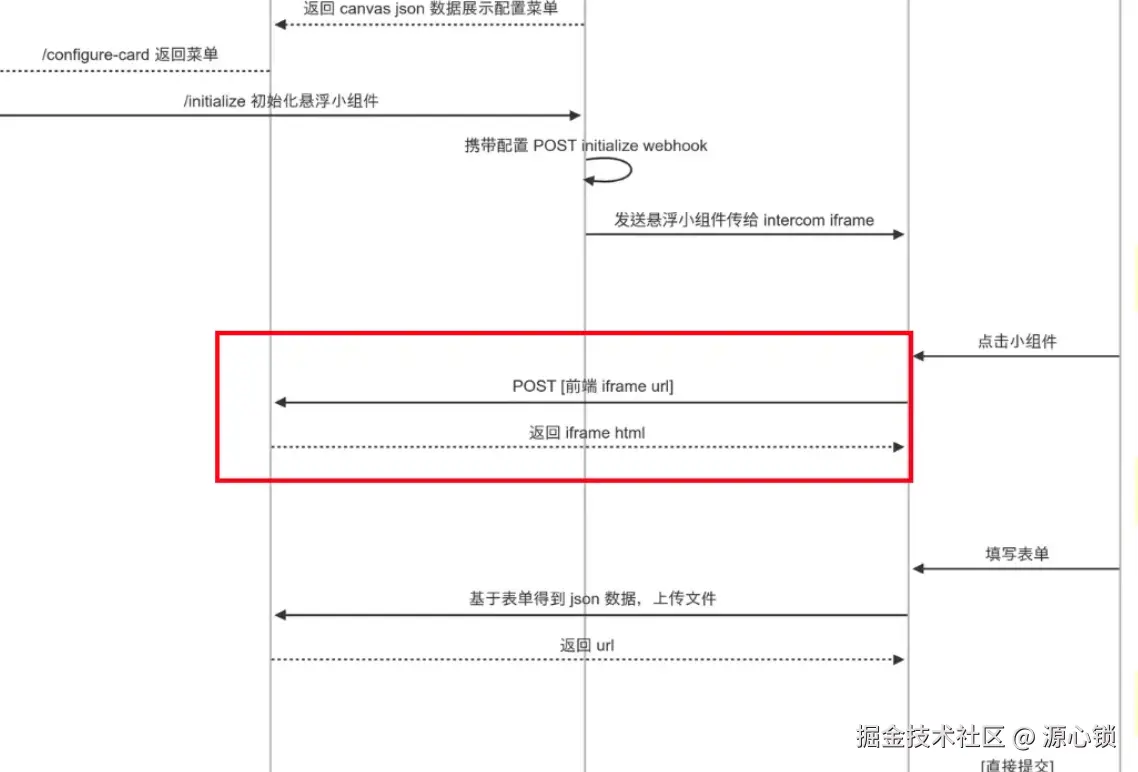
由于 intercom 将基于 POST 请求去调用服务希望得到 html 的限制,这里存在两个问题:
- Intercom 使用 POST 请求,则我们的服务需要支持 POST 请求返回 html,目前是不支持的,所以需要解决方案。
- 由于我们的 iframe 网页要读取日志,那么 iframe 地址必须和 Web 端同源,但生产的 API 地址和 Web 端不同源。
基本方向上,我们可以通过反向代理的方式实现:
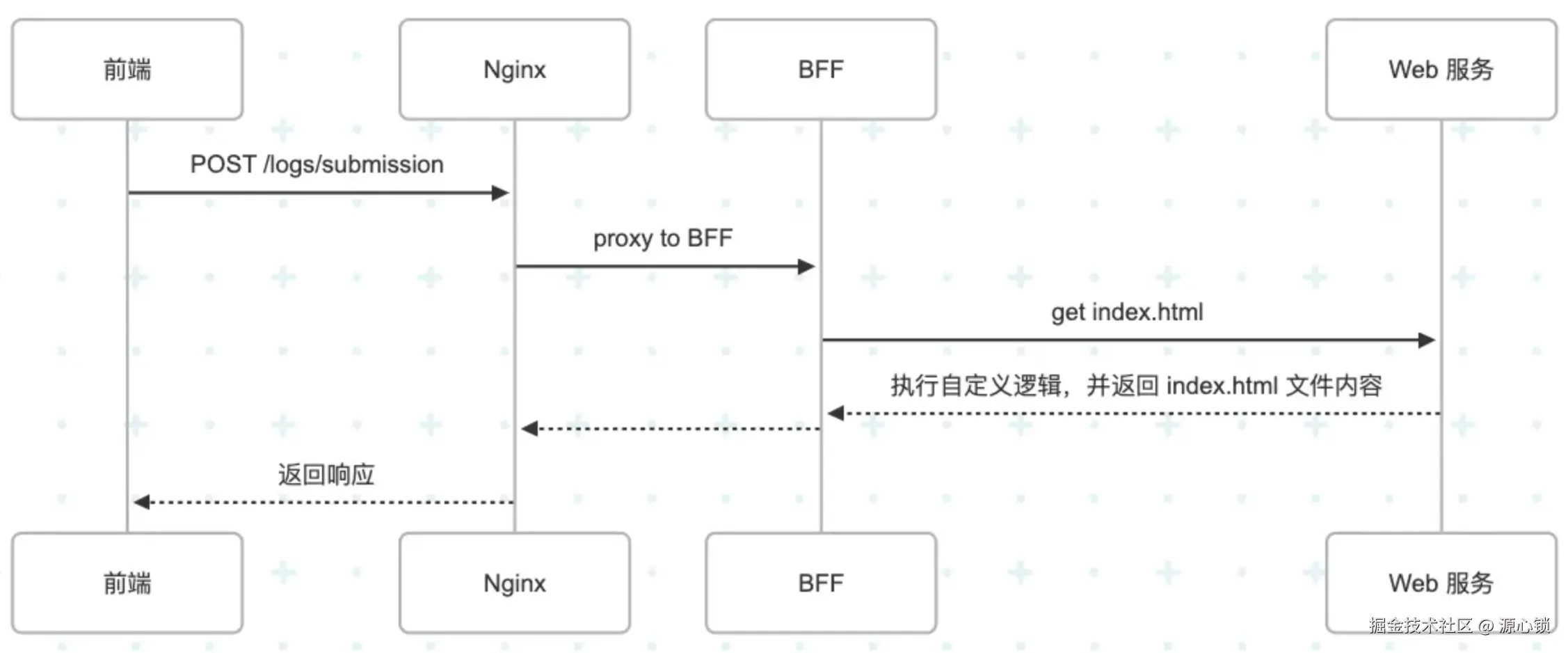
但 iframe 的同源限制比预想的还要麻烦一些,由于 intercom 的接入方式是 iframe 嵌套,类似于:A(<https://samesite.com/>)->B(<https://xxxx.com/>)->A(<https://samesite.com>) 。
这个过程会导致两个跨域限制:
- Cookie 的跨域限制,具体表现为用于登录态的 Cookie 由于未显式设置
Samesite: None,无法被携带进内层网页,进而丢失登录态。 - indexedDB 的跨域限制,由于中间多了一层外域,浏览器限制了最里边的网页读取 indexedDB,具体表现为读取到的数据为🈳。
Cookie 的跨域限制通过显式设置 Samesite 可以解决,但进一步地,为了确保安全性,我们需要给网页其他路径添加X-Frame-Options SAMEORIGIN; 防止外域嵌套我们的其他网页。
后者卡了一阵子,最后的解决思路是通过 postMessage 通信的方式变相读取------反正能读取到就行。
js
window.top.postMessage(
{
type: 'uploadLogs',
id: topUUID,
params: {
start,
end,
},
},
'*',
);(有趣的是,排查过程中发现了 chrome devtools 的缺陷,devtools 里的 document 都指不到最外层,但是实际上 window.top 和 window.parent.parent.parent 都是最外层,具体不细说了)
4.2 🥹 日志安全与上传
日志的格式是 JSON 格式,将其拖拽到 ospy 中即可复原用户浏览器操作记录,一旦泄漏会有极高的安全风险。在此,提出加密方案用于解决该问题。
思路其实很简单:在文件上传前对文件内容进行 AES 加密,对 AES 密钥做 RSA 非对称加密,通过公钥加密,然后将加密后的密钥附加到文件尾。
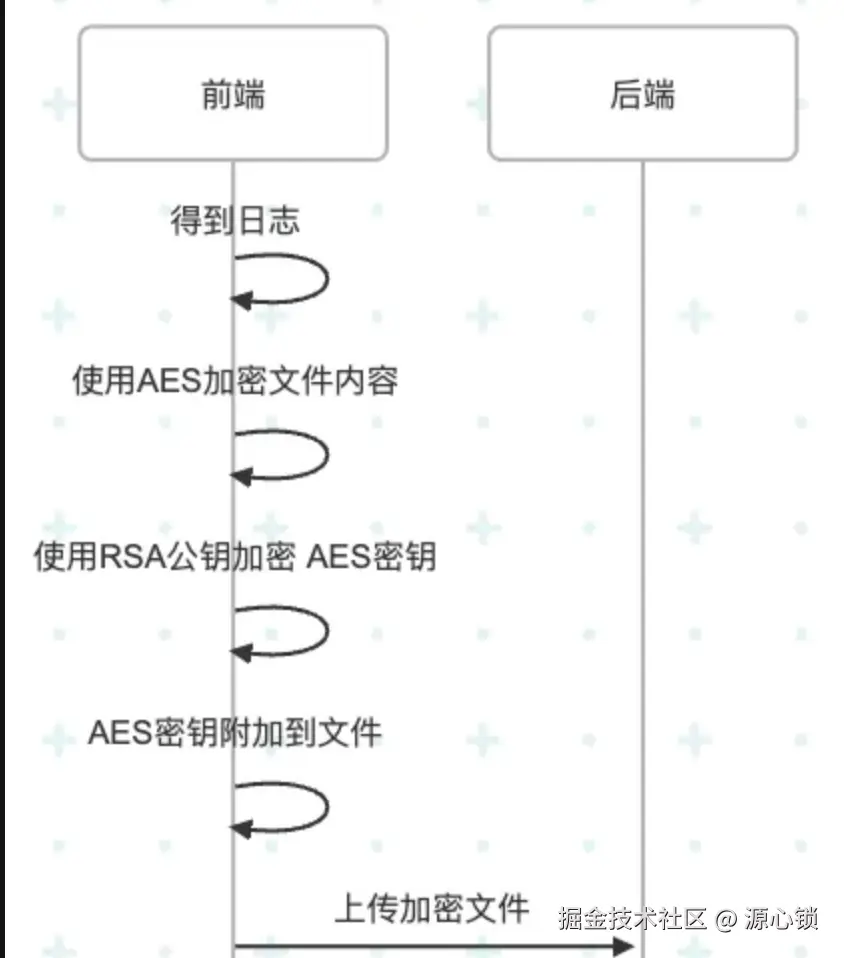
其实还可以进一步,我们在写入日志的时候就加密,但这样读取的时候压力会比较大,因为日志是一段一段的,或许我们还需要定制分隔符。
5 总结
好,那么理所当然的,我们应该不会遇到其他卡点卡,方案落地应该是没问题了。但------
Leader: "有个问题,我们没有分片上传"
我: "Woc? 又要自己写?"
欲知后事如何,且听下回分解。