摘要
在分布式数据库(尤其是基于 Shared-nothing 的 MPP 架构,如 HexaDB)中,DDL(数据定义语言)的执行远比单机复杂。系统不仅要保证成百上千个 DN(Data Node)节点的数据结构变更原子性,更要在多 CN(Coordinator Node)并发入口下,保证元数据(Metadata)的全局视图一致。本文将深入 HexaDB 内核,揭秘基于 GTM 全局事务管理和两阶段提交的 DDL 实现机制。
一、引言:MPP 架构下的 DDL 困境
HexaDB 采用 MPP 架构,支持多个协调节点(CN)同时对外提供服务。这种架构带来了极高的扩展性,但也给 DDL 带来了指数级的挑战:
核心挑战一:多 CN 的元数据脑裂
客户端 A 连接 CN1 执行 ALTER TABLE,客户端 B 连接 CN2 查询同一张表。如果 CN1 修改了元数据但 CN2 未感知,客户端 B 可能会用旧的表结构去解析新的数据物理文件,导致系统崩溃或数据错乱。
核心挑战二:分布式事务的原子性
一个 DDL 操作(如添加列)需要在所有 DN 节点上同时成功。只要有一个 DN 失败(例如磁盘满),所有节点必须回滚,否则会出现"有的分片有新列,有的分片没有"的中间状态。
核心挑战三:全局可见性控制
在 DDL 执行过程中,正在运行的 DML(增删改查)事务该如何处理?如何通过 GTM 保证新旧版本的隔离?
二、HexaDB 的核心架构
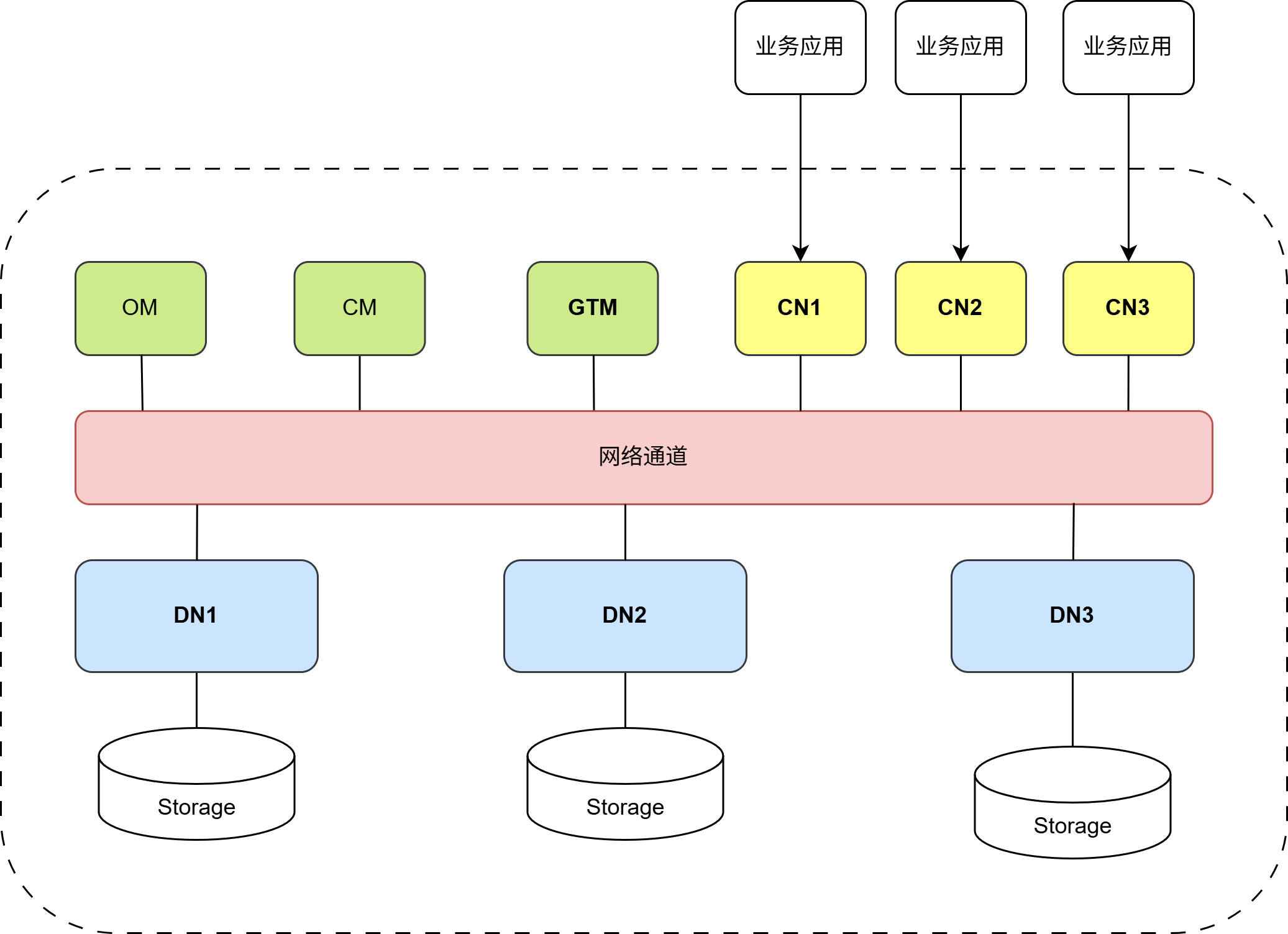
为了理解 DDL 的执行流程,首先需要理解 HexaDB 的三个核心组件:
GTM (Global Transaction Manager):
角色:集群的大脑。
职责:负责分发全局唯一的CSN(Commit Sequence Number)。DDL 本质上也是一个分布式事务,必须向 GTM 申请 CSN。
CN (Coordinator Node):
角色:业务入口与协调者。
职责:接收 SQL,解析查询计划,分发任务给 DN。
关键点: 集群中存在多个 CN,它们是对等的,共享同一份元数据定义的逻辑视图。
DN (Data Node):
角色:数据的实际存储者。
职责:存储业务数据分片和本地元数据。执行具体的 DDL 物理操作(如修改堆表文件)。
三、分布式 DDL 的一致性协议:2PC + MVCC
HexaDB 摒弃了弱一致性的异步提交,采用了**"强一致性两阶段提交 + MVCC"** 机制。
假设我们在 CN1 上执行 ALTER TABLE users ADD COLUMN age INT:
FCN: 表示执行DDL的CN
OCN: 表示集群中的其他CN
3.1 阶段一:执行SQL命令
获取分布式排他锁:尝试在集群层面获取该表的 AccessExclusiveLock。
目的:防止 CN2 同时修改同一张表,或防止 CN2 上有正在进行的查询读取该表。
机制:一旦加锁成功,其他 CN 针对该表的 DDL/DML 请求将被阻塞。
3.2 阶段二:准备与锁定 (Prepare Phase)
CN1 下发 Prepare 和 DDL 命令:
- CN1 向集群中所有 OCN/DN 节点发送 PREPARE TRANSACTION 命令,携带 DDL 语句。
OCN/DN 本地执行:
- OCN/DN 校验语句合法性。
- OCN/DN 开启本地事务,修改本地系统表(Catalog),修改物理文件(如需要)。
- OCN/DN 将操作写入 WAL 日志(预写式日志),但不提交。
- OCN/DN 返回 PREPARE OK,
CN1 本地执行DDL
CN1 收到所有节点的确认后,阶段二完成。
小结
- REMOTE OCN/DN 远程 Prepare (落盘才算完成);
- CN1 本地 Prepare (PREPARE类型的WAL日志记录落盘才算完成);
3.3 阶段三:提交与同步 (Commit Phase) ------ 关键差异点
全局提交:
- CN1 向GTM申请CSN,并发送给OCN/DN;
- OCN/DN 正式提交本地事务,释放本地锁;
- CN1 释放全局分布式锁。
结果返回:
CN1 向客户端返回 ALTER TABLE SUCCESS。
小结
- 向GTM申请CSN;
- CN1 本地提交 (WAL 记录 with CSN 落盘完成,标志本地提交完成,也标志着分布式事务通过提交点);
- 远程提交: 向所有 OCN/DN 发送 COMMIT PREPARED 命令。
四、元数据管理:如何解决"读写"不冲突?
问题场景,如果 CN1 正在执行 DDL, CN2 查询该表。
HexaDB 的解决方案:MVCC
五、分布式锁的死锁问题与解决
5.1 分布式死锁的成因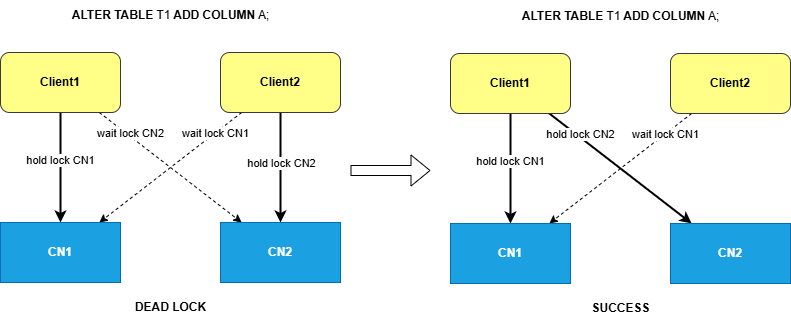
在分布式DDL执行中,死锁很容易发生。考虑以下场景:
死锁案例:
时刻 T1: DDL1(ALTER TABLE T1 ADD COLUMN A) 在 CN1 上锁定 T1
时刻 T2: DDL2(ALTER TABLE T1 ADD COLUMN A) 在 CN2 上锁定 T1
时刻 T3:
- DDL1 向 CN2 请求锁定 T1
- DDL2 向 CN1 请求锁定 T1
→ DDL1 和 DDL2 互相等待,形成死锁5.2 HexaDB的DDL死锁避免机制
原则:按顺序锁定
核心设计 :HexaDB上有一个CN的先后列表,DDL先在FCN上拿锁,然后到OCN上加锁
不同DDL请求:
[CN1, CN2]
├─ DDL1 → CN1 (成功获取锁) → DDL1 → CN2 (成功获取锁)
├─ DDL2 → CN1 (阻塞,等待全局锁释放)
└─ DDL3 → CN1 (阻塞,等待全局锁释放)
优势:
✓ 避免分布式死锁的形成
✓ 同一时刻最多一个DDL在执行六、总结
HexaDB 的分布式 DDL 实现,是一致性与可用性的极致平衡艺术:
- GTM 为核心:通过 CSN 保证了 DDL 操作的时间序和可见性。
- 多 CN 协同:通过 2PC 机制,解决了 MPP 架构下元数据脑裂的难题。
- 2PC 强一致:宁可牺牲少量提交延迟,也要保证所有节点"同生共死",杜绝数据不一致。
- MVCC: 保证分布式DDL的读写分离。
这种设计使得 HexaDB 能够承载金融级核心业务,在保证数据绝对安全的前提下,提供灵活的架构演进能力。