本文介绍如何在 Windows 和 Linux 系统 下,基于 Python 3.10 虚拟环境 ,搭建一个用于 OCR(PaddleOCR / PaddleX)与 PDF 处理 的 Python 运行环境。
识别结果效果
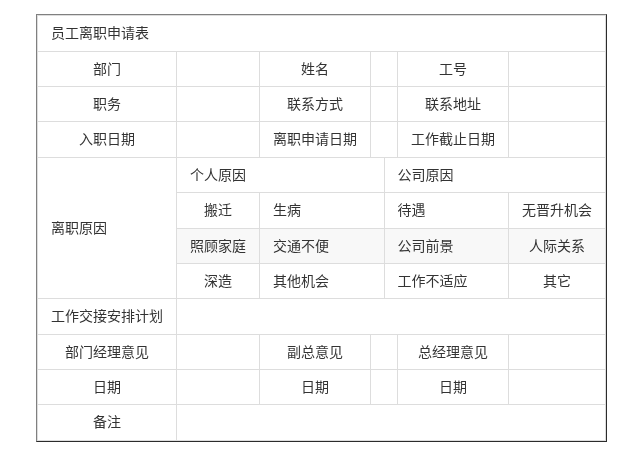
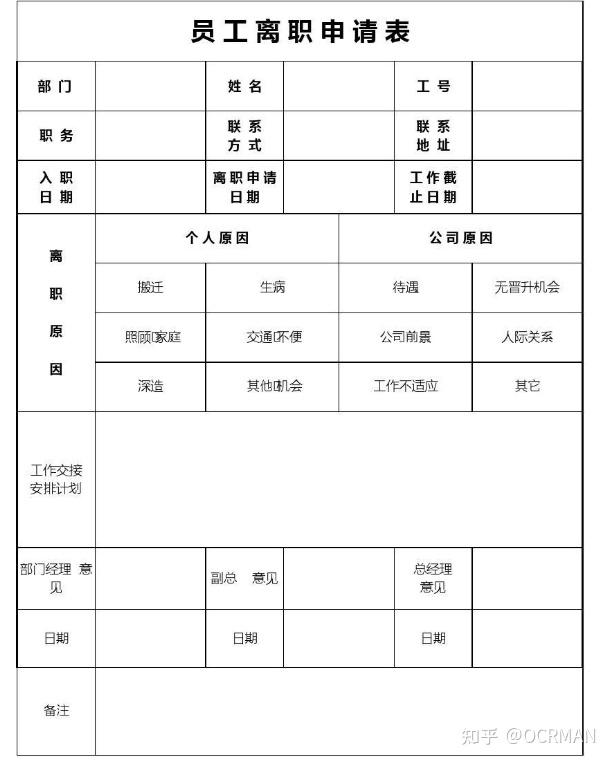
## 案例参考图片
一、安装系统级依赖
Windows 系统
在 Windows 系统下,从 Python 官方网站 下载 Python 3.10 版本安装包,安装时勾选 "Add Python to PATH" 选项。
Linux 系统
在 Linux 系统下,安装 Python 3.10 及常用开发组件:
bash
sudo apt update
sudo apt install -y \
python3.10 \
python3.10-venv \
python3.10-dev \
python3.10-distutils \
python3-pip这些组件分别用于:
python3.10:Python 解释器venv:虚拟环境支持dev / distutils:编译与打包依赖pip:Python 包管理工具
二、创建并激活虚拟环境
1. 创建虚拟环境
bash
python -m venv paddle_py102. 激活虚拟环境
Windows 系统
bash
paddle_py10\\Scripts\\activateLinux 系统
bash
source paddle_py10/bin/activate激活成功后,终端前会显示:
text
(paddle_py10)三、安装 PaddlePaddle(CPU 版本)
在虚拟环境中安装 PaddlePaddle CPU 版(适用于 Windows 和 Linux):
bash
python -m pip install paddlepaddle -i https://www.paddlepaddle.org.cn/packages/stable/cpu/📌 说明:
- 使用官方国内镜像,下载速度更快
- 该版本适合 无 GPU / CPU 推理环境
- 自动检测操作系统并安装相应版本
四、安装 PDF 相关依赖
1. 安装 PyMuPDF(PDF 解析)
bash
pip install PyMuPDF主要用于:
- PDF 页面解析
- 文本 / 图片提取
- PDF 转图片(OCR 前处理)
2. 安装 PaddleX(含 OCR 模块)
bash
pip install "paddlex[ocr]"功能包括:
- OCR 模型封装
- 文本检测 / 识别
- 表格与版面分析
3. 安装 ReportLab(PDF 生成)
bash
pip install reportlab完整代码
from paddleocr import PaddleOCRVL
from PIL import Image
import numpy as np
pipeline = PaddleOCRVL(
device="cpu"
)
img = Image.open(
"v2-f644e32ef8fb2b15b6dd7218eff5f844_r.jpg"
).convert("RGB")
# resize
max_side = 1024
w, h = img.size
scale = min(max_side / w, max_side / h, 1.0)
img = img.resize((int(w * scale), int(h * scale)))
# 重要一步:PIL → numpy (防止CPU超过内存)
img_np = np.array(img)
output = pipeline.predict(img_np)
for res in output:
res.print()
res.save_to_json(save_path="output")
res.save_to_markdown(save_path="output")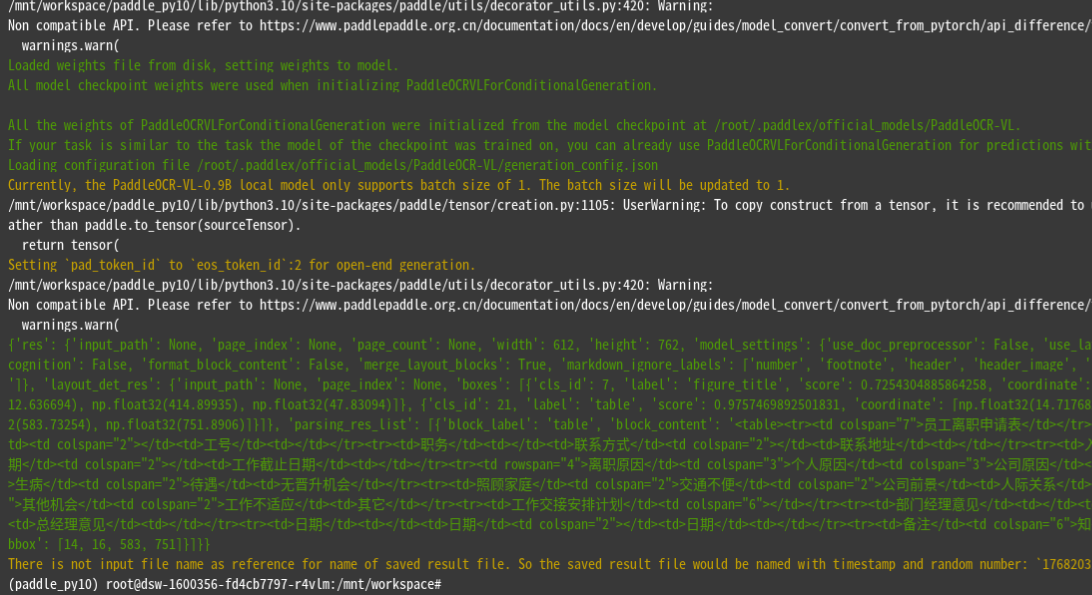
输出目录示例(Windows)
(paddle_py10) C:\workspace\output> dir
1768203146_1313.md
1768203146_1313_res.json输出目录示例(Linux)
(paddle_py10) user@machine:/home/user/workspace/output$ tree
├── 1768203146_1313.md
└── 1768203146_1313_res.json
0 directories, 4 files安装GPU请参考PaddleOCR官方文档
转PDF和word请参考相关文章参考: