🔍 大模型注意力机制进化史:从全局到稀疏,从标准到线性、滑动窗口、MQA......
更新时间:2026年1月12日
如果你关注大模型(LLM)的发展,一定听过这些术语:
- "上下文长度突破 128K!"
- "推理速度提升 3 倍!"
- "显存占用降低 50%!"
而这些突破的背后,往往离不开一个核心组件的革新------注意力机制(Attention Mechanism)。
从 2017 年 Transformer 提出 标准自注意力(Vanilla Self-Attention) 开始,研究者们不断对其进行优化,以解决其计算复杂度高、显存占用大、长文本建模弱等痛点。
今天,我们就系统梳理当前主流的大模型注意力变体,包括:
- ✅ 标准多头注意力(MHA)
- ✅ 滑动窗口注意力(Sliding Window / Local Attention)
- ✅ 稀疏注意力(Sparse Attention)
- ✅ 多查询注意力(MQA)与分组查询注意力(GQA)
- ✅ 线性注意力(Linear Attention)
- ✅ 旋转位置编码(RoPE)如何与注意力协同工作
并深入解析它们的原理、优劣与典型应用模型,助你读懂论文、选对架构、优化部署!
🧠 一、起点:标准自注意力(Vanilla Self-Attention)
回顾公式
对于输入序列 X∈Rn×dX∈Rn×d ,标准注意力计算如下:
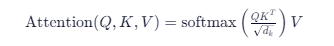
其中:
-
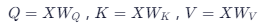
-
n = 序列长度, d = 隐藏维度
⚠️ 问题在哪?
- 时间复杂度: O(n^2) ------ 序列越长,计算爆炸
- 空间复杂度: O(n^2)------ 注意力矩阵占显存(128K 长度需 ~64GB 显存!)
- 长程依赖建模效率低:并非所有 token 对都重要
💡 举例:在写一篇万字论文时,第 1 段和第 10000 段几乎无关,但标准注意力仍会计算它们的关联分数------浪费算力。
于是,各种"注意力瘦身"方案应运而生。
🪟 二、滑动窗口注意力(Sliding Window Attention)
✅ 核心思想
每个 token 只关注其前后固定窗口内的邻居,忽略远处 token。
例如:窗口大小 = 512,则第 1000 个 token 只看 744, 1255 范围内的 token。
📈 优势
- 计算复杂度降至 O(n⋅w)( w = 窗口大小)
- 显存占用线性增长
- 特别适合局部依赖强的文本(如代码、自然语言句子)
🎯 典型应用
- Longformer(2020):首次提出滑动窗口 + 全局 attention
- FlashAttention-2:高效实现窗口注意力
- Qwen、Yi、DeepSeek 等国产大模型均采用此机制支持长上下文
❌ 局限
- 无法直接建模超长距离依赖(如文档首尾呼应)
- 解决方案:加少量全局 token (如 CLS、特殊标记)或层次化窗口
🕳️ 三、稀疏注意力(Sparse Attention)
✅ 核心思想
只计算部分 token 对的注意力,其余设为 0。
常见模式:
- 块稀疏(Block Sparse):将序列分块,只计算块内或特定块间注意力
- 棋盘模式(Checkerboard):交替关注奇偶位置
- Top-k 稀疏:每行只保留 k 个最大 attention score
🎯 典型应用
- BigBird(2020):结合随机注意力 + 滑动窗口 + 全局 token,理论可处理无限长序列
- Sparse Transformers(OpenAI, 2019):用于生成长音乐、图像
⚖️ 权衡
- 灵活但实现复杂
- 需要定制 CUDA kernel(如 Triton)才能高效运行
🧩 四、多查询 vs 分组查询注意力(MQA / GQA)
这不是"稀疏",而是减少 KV 头数量,从而降低显存与计算。
标准 MHA(Multi-Head Attention)
- Q、K、V 各有 h 个头(如 32 头)
- 每个头独立计算
MQA(Multi-Query Attention)
- Q 有 h 个头,但 K 和 V 只有 1 个头
- 所有 query 头共享同一组 key/value
GQA(Grouped-Query Attention)
- 折中方案:K/V 头数 = g (如 8),Q 头数 = 32
- 每 32/8=4 个 Q 头共享一组 K/V
📊 效果对比(以 Llama-2-70B 为例)
| 类型 | Q 头数 | K/V 头数 | 推理显存 | 解码速度 |
|---|---|---|---|---|
| MHA | 64 | 64 | 高 | 慢 |
| MQA | 64 | 1 | 极低 | 极快 |
| GQA | 64 | 8 | 中 | 快 |
🎯 典型应用
- Llama-2 / Llama-3 :全系采用 GQA
- Falcon :采用 MQA
- Qwen2、DeepSeek-V2:也已支持 GQA
✅ 优势:解码阶段 KV Cache 显存大幅下降(从 2×n×d×h → 2×n×d×g),极大提升长文本生成效率。
📉 五、线性注意力(Linear Attention)
✅ 核心思想
绕过 softmax,用核函数近似注意力,使复杂度从 O(n^2)降至 O(n)。
经典方法:
- Performer(2020):用随机傅里叶特征(RFF)近似 softmax kernel
- Linformer:将 K、V 投影到低维(n→k),再计算注意力
- Favor+:改进的正交随机特征,保证数值稳定
公式示意(Performer):
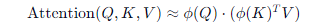
其中 ϕ 是可线性化的核映射。
⚖️ 现状
- 训练快、推理快 ,但精度通常略低于标准注意力
- 目前尚未被主流大模型采用(如 Llama、Qwen、Claude 仍用标准或窗口注意力)
- 更多用于视觉 Transformer 或 生物序列建模
💡 原因:大模型靠 scale 出奇迹,宁可多花显存也要保精度;而线性注意力的近似误差在超大模型中可能被放大。
🌀 六、位置编码与注意力的协同:RoPE 的胜利
虽然 RoPE(Rotary Position Embedding)本身不是注意力机制,但它深刻影响了注意力的设计。
为什么重要?
- 标准 Transformer 用绝对位置编码(如 sinusoidal),难以泛化到更长序列
- RoPE 将位置信息编码到 query/key 的旋转中 ,使得:
- 注意力分数天然具有相对位置感知
- 支持外推(extrapolation):训练 4K,推理 32K 仍有效
与注意力机制的配合
- 滑动窗口 + RoPE:成为当前长上下文模型的标配(如 Qwen、Yi、DeepSeek)
- RoPE 的旋转特性天然适配局部注意力,因为相邻位置旋转角度小,相似度高
📌 几乎所有现代开源大模型(Llama、Qwen、ChatGLM、Baichuan)都采用 RoPE。
🧪 七、横向对比:一张表看懂所有注意力机制
| 机制 | 时间复杂度 | 显存复杂度 | 长文本支持 | 是否主流 | 典型模型 |
|---|---|---|---|---|---|
| 标准 MHA | O(n^2) | O(n^2) | 弱 | ✅(短文本) | BERT, GPT-2 |
| 滑动窗口 | O(nw) | O(nw) | 强 | ✅✅✅ | Qwen, Yi, Longformer |
| 稀疏注意力 | O(nlogn) | O(nlogn) | 极强 | ⚠️(小众) | BigBird |
| MQA/GQA | O(n^2) | O(ng) | 中 | ✅✅ | Llama-3, Falcon |
| 线性注意力 | O(n) | O(n) | 强 | ❌ | Performer (研究向) |
| FlashAttention | O(n^2) | O(n) | 中 | ✅(加速器) | 所有支持 FA 的模型 |
💡 注:FlashAttention 不是新注意力机制,而是标准注意力的高效实现(通过 I/O 优化降低显存占用)。
🌟 八、未来趋势
- 混合注意力:局部窗口 + 少量全局 token(如 Gemma 2 的"局部+跨层注意力")
- 动态稀疏:根据输入内容自适应选择关注区域(如 Mixture of Attention Heads)
- 状态空间模型(SSM)挑战者:如 Mamba,用 SSM 替代注意力,实现 O(n)O(n) 且更强长程建模
- 硬件感知设计:注意力结构适配 GPU/TPU 内存层级(如 Ring Attention 支持百万长度)
💬 结语:没有银弹,只有权衡
注意力机制的演进,本质是在"建模能力"、"计算效率"、"工程可行性"之间寻找最优平衡点。
- 要极致速度?→ 试试 MQA + 滑动窗口
- 要超长上下文?→ 窗口 + RoPE + FlashAttention
- 要理论创新?→ 探索线性或 SSM
理解这些机制,不仅能帮你读懂论文,更能在部署时做出明智选择 ------比如:
"我的应用场景是客服对话(平均 500 字),其实不需要 128K 上下文,用标准注意力 + GQA 就够了。"
而这,正是工程师的智慧所在。