不久前 DeepMind 发布了一篇论文,内容简单说是: RLM(Recursive Language Models) 不是让模型"硬记"所有内容,而是赋予模型像程序员一样操作数据的能力 ,让模型在不把超长 prompt 直接塞进 Transformer 的情况下,仍然能完成需要密集访问长文本的任务。
也就是它不再试图将所有内容塞进有限的"大脑"(上下文窗口),而是将长文本视为一个"数据库",模型可以通过编写代码(Python REPL)来递归地检索、切片和阅读它需要的部分。
在这里,RLM 属于通用推理范式 。
在目前,各大模型厂商都在搞"军备竞赛",100万、1000万 token 的上下文窗口数据理论上看着很美好,但是在实际使用过程中,相信大家有所体会,当上下文超过一定长度(100k)后,模型的性能会急剧下降,因为模型并不是真的"记住"了 1000万字,它只是把它们塞进去了,但通过注意力机制在找回信息时会变得混乱和遗忘:
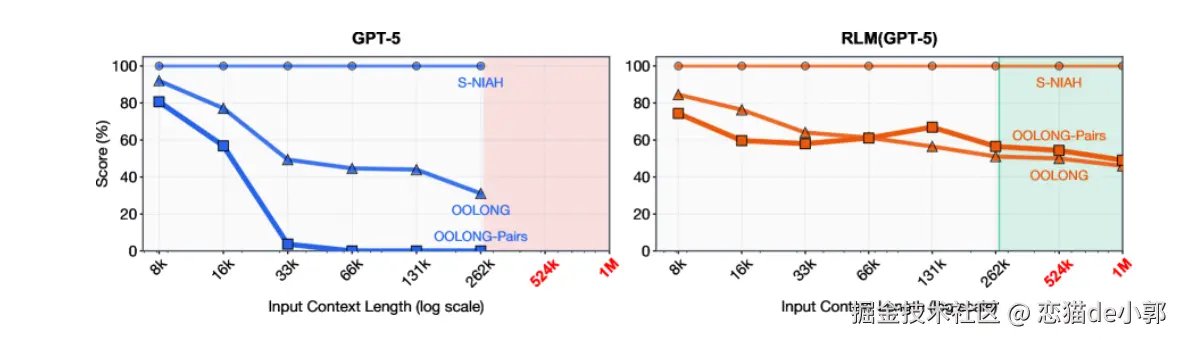
所以 RAG (检索增强生成) 是目前的主流补丁方案,它把长文档切成小块(Chunks)存入数据库,当用户提问时,系统检索相关的碎片塞给模型。
但是这种场景下,RAG 容易丢失全局上下文 ,如果一个任务需要同时理解文档的第 1 章和第 10 章的关联,或者需要进行跨段落的复杂推理,RAG 很容易出现失败,因为它只能看到碎片,看不到全貌("Lost Context"):

而对于 RLM 而言,它不再是一个碎片"阅读者",而是变成了一个"操作对象",模型不直接阅读 1000万 token 的文本,而是将整个长文本被作为一个变量 (String Variable) 加载到 Python 交互式环境(REPL)中,之后进行递归和代码执行:
- 模型可以编写代码来处理文本,比如写
grep(搜索关键词),slice(切片读取某一段),或者使用正则 (Regex) 来定位信息 - 如果模型切片出了一段内容,发现里面还有需要深入挖掘的信息,它会调用自身(Recursive Call)来处理那个特定内容,也就是递归
简单来说,整个流程就是:提问 -> 模型写代码搜索 -> 找到片段 -> (如果需要) 递归调用自身分析片段 -> 汇总答案。
那说它比 RAG 好的地方是什么?可以简单来说,它会像人类一样阅读:
- 当人类需要阅读一本巨厚的书,比如各种字典,肯定不会从头到尾背下来,相反肯定会用目录、用
Ctrl+F、做笔记、跳读等方式 - RLM 的存在就是让 AI 这么做,它不是靠"注意力机制"去死记硬背,而是靠"逻辑导航"去随时调取它需要的任何细节
因为是通过代码精确查找和读取,所以只要文本在那儿,它就永远不会"遗忘",这就是 RLM 里所谓的"完美记忆",在这一个程度去理解,RLM 是主动的,模型自己决定要去读哪一段,自己验证找得对不对,如果不通过,它会修正搜索策略。
比如,论文里提供的数据:
- 在 OOLONG-Pairs 密集推理任务上,传统 RAG 准确率只有 0.04%,而 RLM 高达 58%
- 在多文档研究 BrowseComp+ 上,RLM 从 0% 提升到了 91%
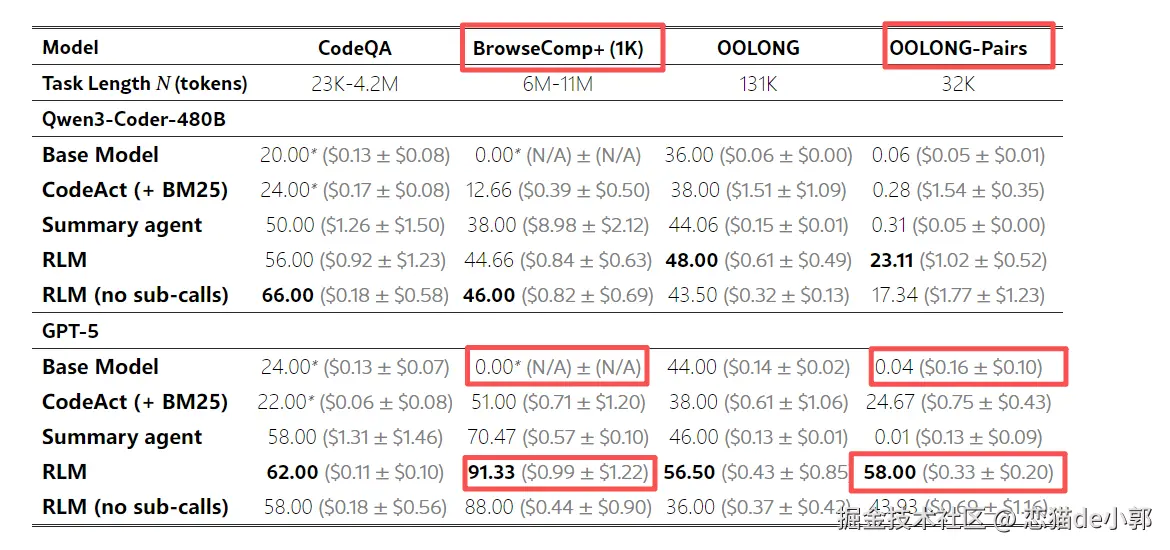
RLM 的做法是:把密集语义理解分摊给多个子调用、每次子调用只看较小片段,减少在超长上下文里"越看越糊"。
而这篇论文最有意思的发现之一是:不需要专门训练 ,研究人员并没有重新训练 GPT-5 或 Qwen3-Coder ,他们只是给了现有的模型一个 Python 环境和递归访问权限, 然后模型就自己学会了策略,它们开始自己写正则表达式来过滤上下文,自己把大任务拆解成递归的小任务,这是一种零样本(Zero-shot)的策略涌现,模型自己"悟"出了策略:
- 它自己决定:"这段文本太长,我不能直接读,我要先用正则过滤一下。"
- 它自己学会了:"我不确定这个答案对不对,我要写一段代码去原文里再验证一次。"
这意味着高智商模型天生具备处理无限信息的能力,只是之前的交互界面(Chat Interface)限制了它们。
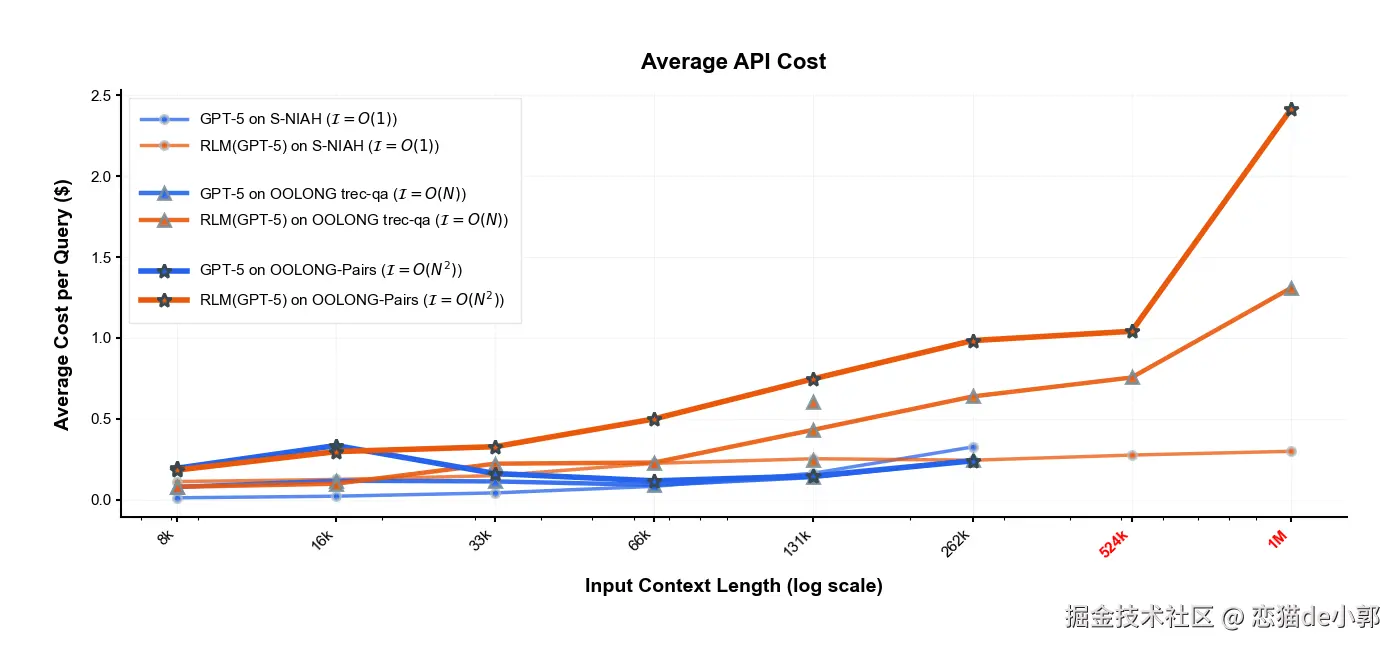
论文里提到,RLM 能处理超过模型窗口两个数量级的输入,并且在多个长上下文任务上比 base LLM 和常见脚手架明显更强,且单次查询成本可相当甚至更低,也就是:
RLM 在"长+密"的任务上优势明显,并且把处理长度推到 10M+ tokens 。
从这里可以看到, 虽然递归看起来步骤多,但实际上比把 1000万 token 一次性塞进上下文窗口要便宜,因为模型只读取它通过代码筛选出的那几千个关键 token,而不是为处理数百万无关 token 支付额外费用,更具体的场景例如:
- 分析整个代码库(不再受限于窗口)
- 理解并综合数百篇研究论文
- 处理长达多年的医疗记录
当然也不不是没有限制,比如:
- 同一套系统提示词跨模型会出问题:Qwen3-Coder 更"放飞"地滥用子调用,所以他们不得不单独加一句"少用 sub-calls、尽量 batch"
- 模型代码能力不足会直接崩:因为这个范式强依赖"写代码操作 context"
- 输出 token/思考 token 不够会跑不完:长轨迹 + 多轮 REPL 需要足够输出上限
- 没有异步子调用会很慢:他们实现是 blocking/sequential,导致运行时间长,作者认为工程上可解决
- 终止信号(FINAL)很脆弱:模型会把计划当最终答案、或 FINAL_VAR 不被接受等。
也就是,RLM 作为"纯提示词+系统编排"的推理范式已经有效,但要变成稳定产品,需要:
- 更强的执行/并发工程
- 更针对性的训练或对齐
论文也在附录提到,他们实现 sub-calls 是串行 blocking 的,也没做"预算控制/批量/缓存"优化,而且模型有时会"过度验证",导致多余子调用。
这样才能让模型学会在这种协议下更好工作,另外论文提到,在超高难度组合任务 RLM更贵,但性价比高,因为虽然开销大了,但是准确率可以提高不少,目前看来:
当任务需要密集访问长文本,并且证据分散在很多段落/文档时,RLM 可以做到更准更省。
所以也许接下来,问题不在于我们如何把更多 token 塞进窗口,而在于我们如何让 AI 智能地导航无限的信息 ,这也标志着或者"大上下文窗口"时代即将终结,也许 AI 不再需要更大的窗口,AI 需要的是更聪明的"导航员"