从零实现一个数据结构可视化调试器(一)
前言
这个项目是我 3 年前的毕业设计发展过来的------一个 Web 端的数据结构可视化调试器。
简单来说,就是你可以在网页上写代码、设断点、单步调试,同时看到链表、二叉树这些数据结构的动态变化。效果大概是这样:
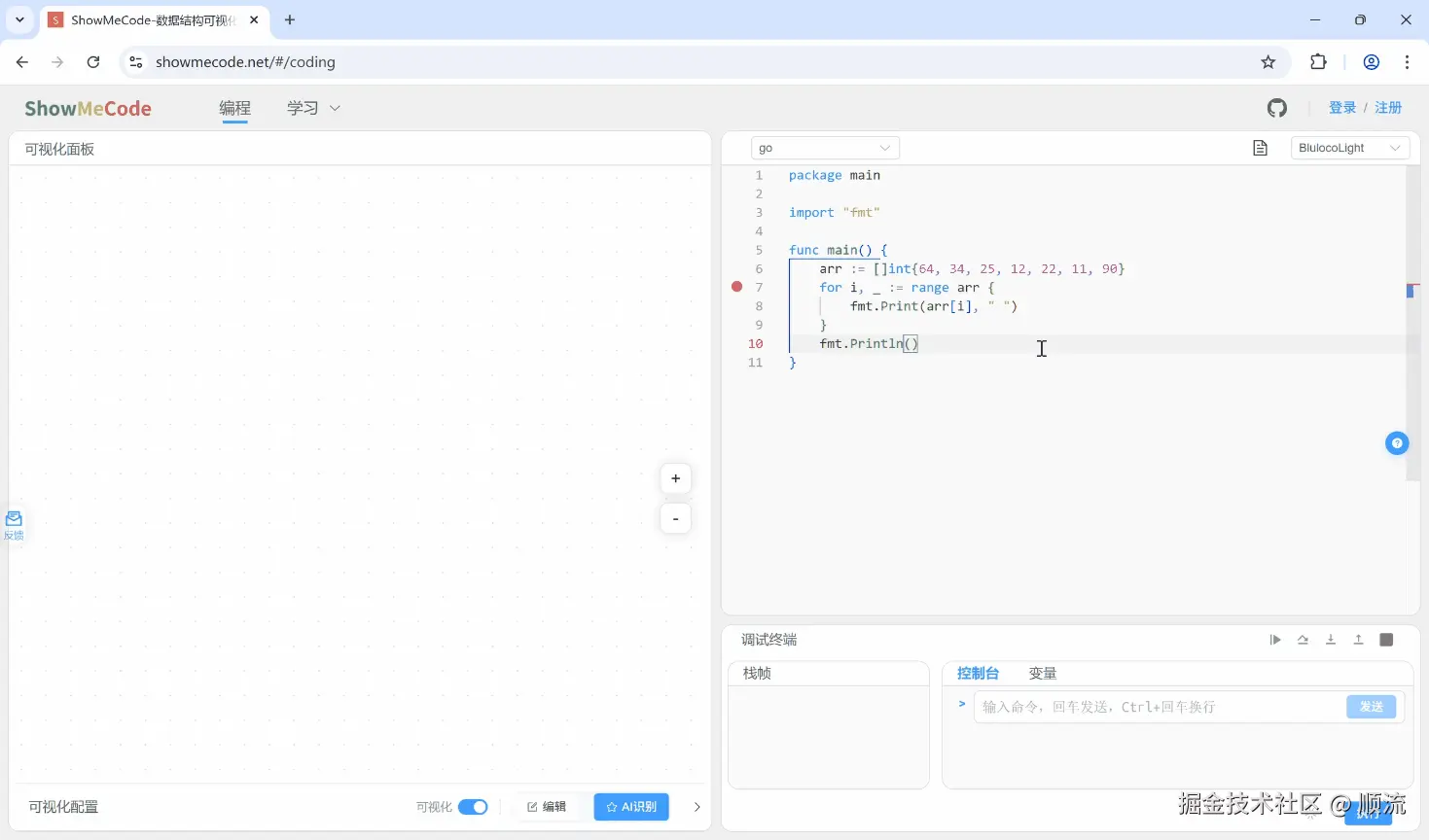
说实话,看了下23年提交的第一个commit还挺怀念的。毕业后当了几年牛马,这个项目已经很久没更新了。趁着还没完全忘光,写篇文章记录一下实现思路。
 本文是第一篇,主要聊如何实现在线调试功能。后面还会写数据结构可视化、还有容器隔离等。
本文是第一篇,主要聊如何实现在线调试功能。后面还会写数据结构可视化、还有容器隔离等。
项目已开源,欢迎 Star:github.com/fansqz/Show...
一、调试到底是怎么做的?
1.1 程序为什么能被"调试"?
要理解调试,首先要知道一个关键概念:断点 (Breakpoint) 。
当你在某一行设置断点后,程序执行到那里就会停下来。但程序怎么知道要停下来呢?
秘密在于操作系统提供的一种机制------中断指令 。以 x86 架构为例,调试器会在断点位置插入一条特殊指令 INT 3(机器码 0xCC)。当 CPU 执行到这条指令时,会触发一个软中断,操作系统接管程序控制权,然后通知调试器"嘿,程序停在这里了"。
简化流程:
sql
原始代码: 设置断点后:
mov eax, 1 mov eax, 1
add eax, 2 <-- 断点 INT 3 <-- 被替换
mov ebx, eax mov ebx, eax1.2 调试器的核心能力
一个调试器本质上就是做这几件事:
- 控制程序执行:启动、暂停、继续、终止
- 设置断点:让程序在指定位置停下来
- 单步执行:一行一行地执行代码
- 查看状态:读取变量值、调用栈、内存内容
像 GDB、LLDB 这些调试器,就是专门干这个的工具。它们通过操作系统提供的调试接口来实现上述功能
GDB提供的常用命令:
| 命令 | 作用 |
|---|---|
break 10 |
在第 10 行设置断点 |
run |
开始执行程序 |
continue |
继续执行到下一个断点 |
step |
单步执行(进入函数) |
next |
单步执行(跳过函数) |
print x |
打印变量 x 的值 |
backtrace |
查看调用栈 |
quit |
退出 GDB |
二、我的第一版调试器
2.1 最直接的思路
既然 GDB 已经能调试程序了,最简单的做法就是:让后端启动 GDB,把用户的操作翻译成 GDB 命令。
架构非常直白:
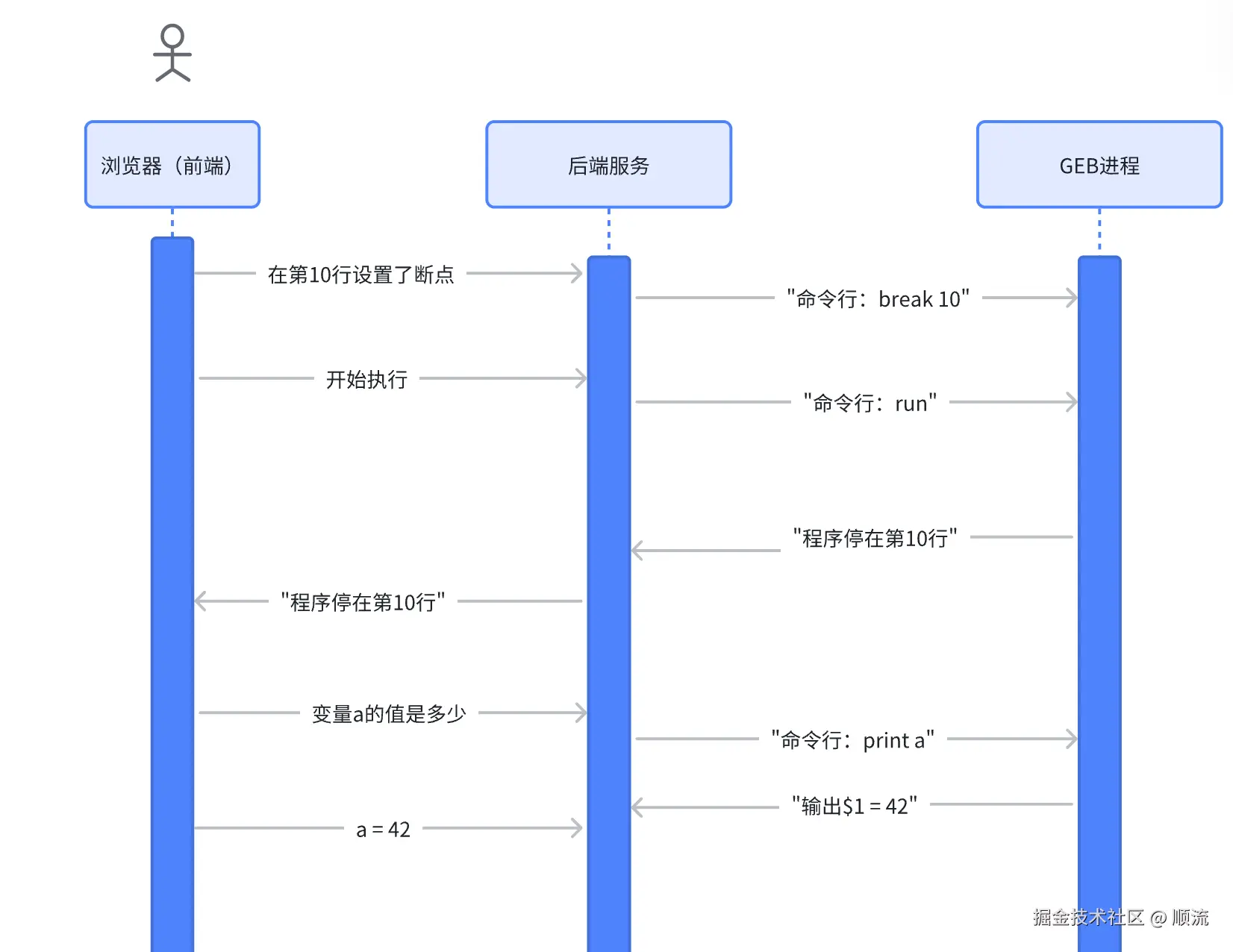
2.2 接口设计
基于上面的思路,我设计了这样一套 RESTful API:
ruby
调试会话管理
POST /debug/session 创建调试会话(上传代码,返回 sessionId)
DELETE /debug/session/:id 销毁调试会话
调试控制
POST /debug/:id/breakpoints 设置断点(传入行号数组)
POST /debug/:id/start 开始执行
POST /debug/:id/continue 继续执行
POST /debug/:id/step/in 单步进入
POST /debug/:id/step/over 单步跳过
POST /debug/:id/step/out 单步跳出
POST /debug/:id/terminate 终止程序
状态查询
GET /debug/:id/variables 获取当前变量
GET /debug/:id/stacktrace 获取调用栈
事件订阅
GET /debug/:id/events SSE 连接,订阅调试事件为什么需要 event?
你可能会问:查询变量、设置断点这些操作用普通的 HTTP 请求就够了,为什么还需要 event?
关键在于:有些事件需要服务端主动发生的,客户端无法预知。
举个例子:
- 用户点击"继续执行"
- 程序跑起来了...
- 不知道什么时候,程序停在了下一个断点(可能是 0.1 秒后,也可能是 10 秒后)
2.2 通信方案:HTTP + SSE
在上面的接口设计中,我们可以看到是需要服务端主动发送event时间给客户端的。我选择的通信方式是 HTTP + SSE 的组合:
- HTTP:用户的操作(设断点、单步执行等)通过普通 HTTP 请求发送
- SSE:程序的状态变化(停在断点、输出内容等)通过 SSE 推送给前端
为什么用 SSE 而不是 WebSocket?
| SSE | WebSocket | |
|---|---|---|
| 方向 | 服务器 → 客户端(单向) | 双向 |
| 复杂度 | 简单,就是 HTTP 长连接 | 需要握手、心跳 |
| 断线重连 | 浏览器自动处理 | 需要自己实现 |
对于调试场景,用户操作是"请求-响应"模式,状态推送是单向的,SSE 完全够用而且更简单。
2.3 前端实现
前端的核心任务:把"调试"这个抽象的过程,变成用户能看懂、能操作的界面。
代码编辑器:Monaco Editor
用的是 Monaco Editor,就是 VS Code 同款编辑器。语法高亮、自动补全这些它都自带了,但调试相关的功能需要自己加。
断点功能
用户点击行号左边的空白区域,就能添加/删除断点。实现思路:
- 监听编辑器的鼠标点击事件
- 判断点击位置是否在行号区域
- 如果是,就在那一行添加一个红点装饰(Monaco 叫它 decoration)
- 同时把断点信息存起来,调试时发给后端
当前行高亮
程序停在某一行时,需要高亮显示。后端会告诉我们停在第几行,前端就给那一行加个黄色背景:
事件监听:前端怎么知道程序状态变了?
这就要用到前面说的 SSE 了。前端和后端之间有一条"管道",后端随时可以往里面塞消息。前端代码大概长这样(伪代码):
scss
// 建立 SSE 连接
const source = new EventSource(`/debug/sse/${debugId}`)
// 监听消息
source.onmessage = (event) => {
const data = JSON.parse(event.data)
if (data.event === 'stopped') {
highlightLine(data.line) // 高亮当前行
fetchVariables() // 顺便拉取变量值
}
if (data.event === 'output') {
appendToConsole(data.output) // 显示程序输出
}
if (data.event === 'terminated') {
clearHighlight() // 清除高亮
source.close() // 关闭连接
}
}2.4 沙盒隔离
让用户在服务器上执行代码是非常危险的------如果有人写个死循环吃光 CPU,或者写个 rm -rf /,服务器就完蛋了。
第一版我用的是 Linux 的 cgroup 、namespace、seccomp 来做隔离,这一套也是市面上很多沙盒的实现。具体我就只简单说下他们有什么作用:
cgroup(控制组) :限制资源使用
- 限制 CPU、内存用量、超出限制就杀掉进程
namespace(命名空间) :隔离系统资源
- PID namespace:让进程看不到其他进程
- Mount namespace:让进程只能访问指定目录
- Network namespace:禁止网络访问
seccomp(系统调用过滤) :限制能调用哪些系统调用
- 只允许 read、write、exit 等基本操作
- 禁止 execve、socket 等危险操作
坑:seccomp 需要在 fork 后设置,但调试时做不到
seccomp 的正确用法是:
scss
*// C 语言实现*
pid_t pid = fork();
if (pid == 0) {
*// 子进程*
setup_seccomp(); *// 先设置系统调用过滤*
execve(user_program); *// 再执行用户程序*
}问题来了:
- 我的后端是 Go 写的 :Go 的运行时机制导致它不能像 C 那样简单地 fork。Go 的
exec.Command底层会处理 fork,但没法在 fork 后、exec 前插入 seccomp 设置 - 调试时进程是 GDB 启动的 :调试场景下,用户程序是由 GDB 通过
run命令启动的,根本不经过我们的 fork 流程
这个问题我一直得不到解决,所以我第一版的调试流程并不是非常安全。
结语
到这里,第一版调试器就完成了。这一版能跑起来,但有两个遗留问题:
- 安全性不够:seccomp 没法用,恶意代码还是有风险
- 没有可视化:只能看变量值,看不到数据结构的图形化展示
下一篇,我会聊聊如何实现数据结构的可视化。
如果觉得有帮助,欢迎点个 Star:github.com/fansqz/Show...