在代码审查中,一种极其常见的性能反模式(Anti-Pattern)是:在应用层通过 for 循环逐条操作数据库。
perl
# 典型的低效写法
for user in user_list:
# 每次执行都会发起一次网络请求
cursor.execute("INSERT INTO t_users (name, email) VALUES (%s, %s)", (user.name, user.email))假设应用服务器与数据库之间的网络延迟(RTT)是 1ms。插入 1000 条数据,光是网络通信就耗时 1 秒,这还不算数据库解析 SQL、写 redo log 和提交事务的时间。
在高吞吐场景下,我们必须将思维从**"行处理 (Row-by-Row)"** 切换为 "集合处理 (Set-based)"。本文将介绍三种减少交互次数、提升写入吞吐量的核心技巧。

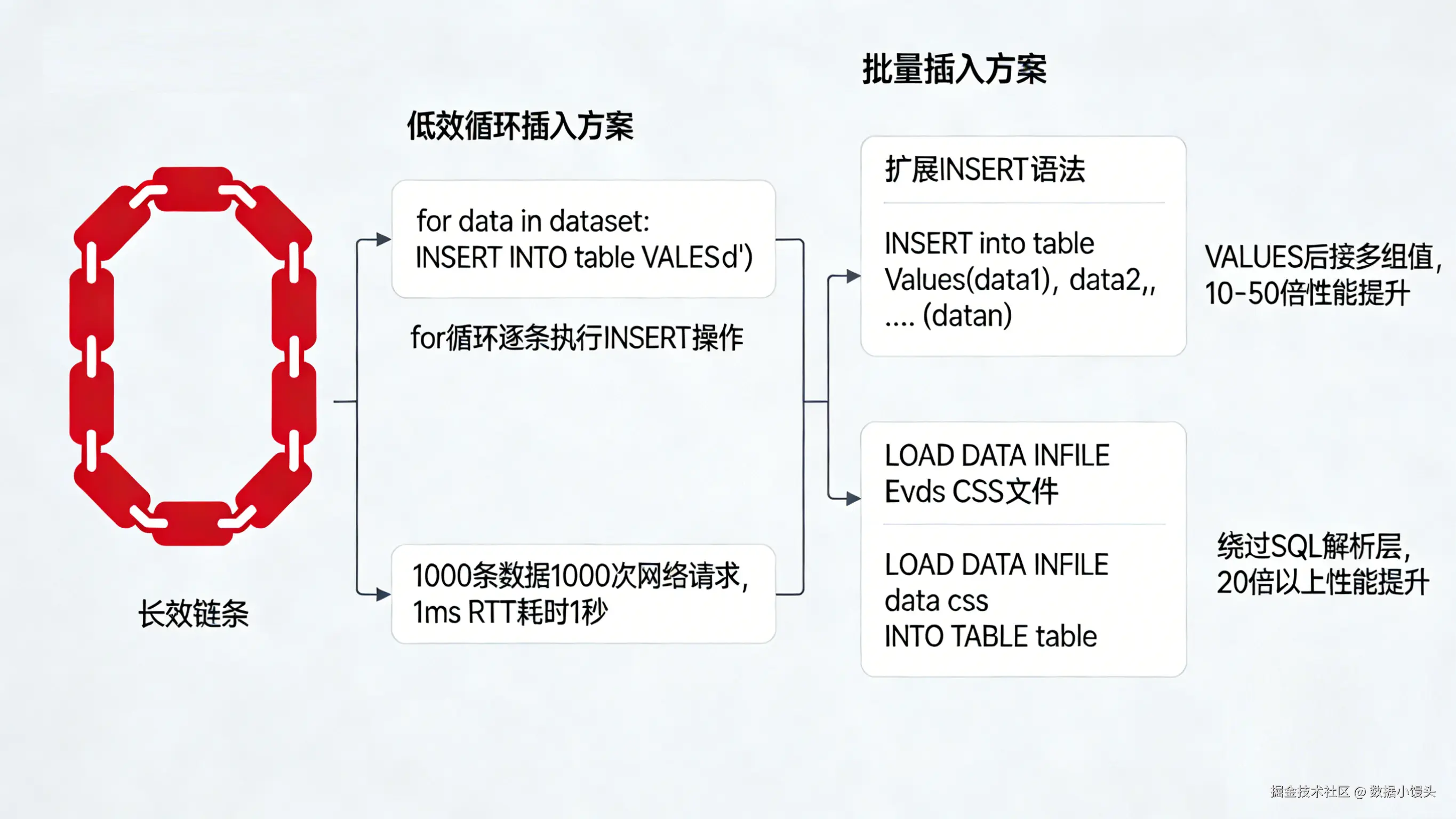
一、 批量插入:从 VALUES 到 LOAD DATA
要解决循环插入的问题,最直观的思路是减少网络交互次数。
1. 扩展插入 (Extended Insert)
MySQL 允许在一条 INSERT 语句中包含多个值列表。
sql
INSERT INTO t_users (name, email)
VALUES
('Alice', 'alice@test.com'),
('Bob', 'bob@test.com'),
('Charlie', 'charlie@test.com');性能提升: 相比单条插入,性能通常提升 10-50 倍。
限制因素: SQL 语句的总长度受 MySQL 参数 max_allowed_packet(默认通常为 4MB 或 16MB)限制。如果数据量过大(如 10 万条),需要切分 Batch(例如每 1000 条拼一个 SQL)。
2. 终极武器:LOAD DATA INFILE
如果你需要导入百万级、千万级的数据(例如从 CSV 文件迁移),INSERT 语法无论如何优化都无法满足需求。此时应使用 MySQL 提供的专用指令:
sql
LOAD DATA LOCAL INFILE '/data/users.csv'
INTO TABLE t_users
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
(name, email);性能提升: 相比批量 INSERT,性能可进一步提升 20 倍以上。它绕过了 SQL 解析层,直接处理数据页,是 MySQL 数据导入的理论速度极限。
二、 Upsert:一行 SQL 搞定"有则更新,无则插入"
场景复现:
用户数据同步任务。如果 user_id 已存在,则更新 email;如果不存在,则插入新记录。
低效解法(应用层逻辑):
- SELECT * FROM t_users WHERE id = 100
- 判空:
- 存在 -> UPDATE ...
- 不存在 -> INSERT ...
风险:
- 性能差: 至少 2 次数据库交互。
- 竞态条件: 在 Select 和 Insert 之间,可能有另一个线程插入了 id=100,导致后续 Insert 报"主键冲突"错误。
技术解法:ON DUPLICATE KEY UPDATE
MySQL 提供了原生的 Upsert 语法(PostgreSQL 中对应 ON CONFLICT)。
sql
INSERT INTO t_users (id, name, email)
VALUES (100, 'David', 'david@new.com')
ON DUPLICATE KEY UPDATE
email = VALUES(email), -- 如果冲突,更新 email 为新值
update_time = NOW();底层机制与陷阱:
- 判断依据: 该语法依赖于 主键 (Primary Key) 或 唯一索引 (Unique Key)。只有违反唯一性约束时,才会触发 UPDATE。
- Affected Rows 歧义:
- 返回 1:表示执行了 INSERT。
- 返回 2:表示执行了 UPDATE(这是一个历史设计特性)。
- 返回 0:表示数据已存在且无变化(UPDATE 没改动任何值)。
- 自增 ID 跳跃: 即使最终执行的是 UPDATE,InnoDB 的自增计数器(Auto-increment)也可能会增加。大量使用 Upsert 会导致主键 ID 出现断层,虽不影响使用,但需知悉。
三、 跨表更新:用 JOIN 代替子查询
场景复现:
电商系统中,需要将 t_orders 表中的 customer_level 字段,刷新为 t_customers 表中当前的等级。
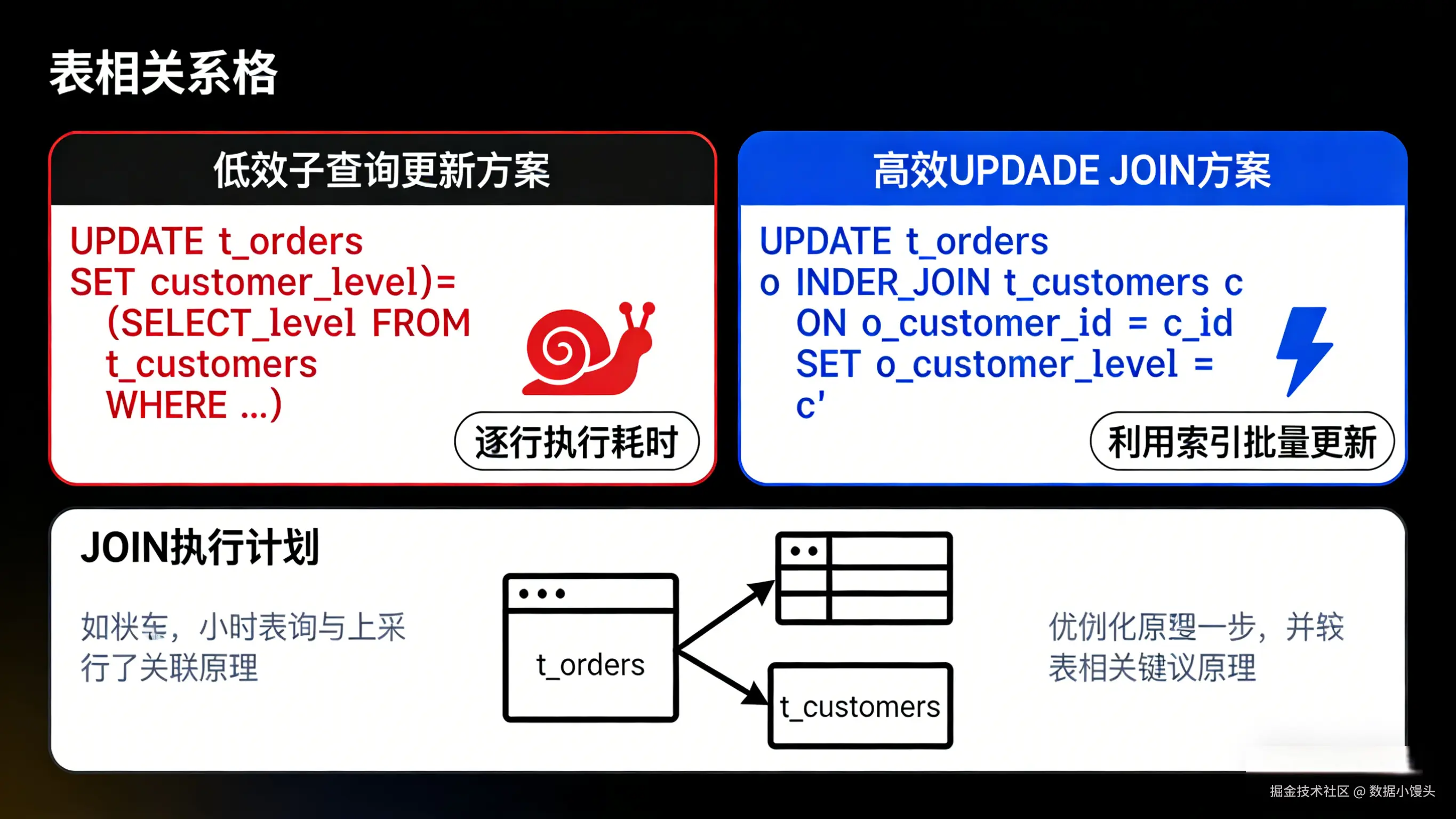
低效解法(相关子查询):
ini
UPDATE t_orders o
SET customer_level = (
SELECT level
FROM t_customers c
WHERE c.id = o.customer_id
);当订单表数据量较大时,这种逐行执行子查询的方式效率极低。
技术解法:UPDATE JOIN
MySQL 支持在 UPDATE 语句中使用 JOIN 语法,这是一种利用索引进行集合更新的高效方式。
ini
UPDATE t_orders o
INNER JOIN t_customers c ON o.customer_id = c.id
SET o.customer_level = c.level
WHERE o.status = 'PENDING'; -- 仅更新未完成的订单原理解析:
数据库优化器会先执行 JOIN 操作,利用索引快速匹配出所有需要更新的行及其对应的新值,然后进行批量更新。这种"集合操作"的效率远高于"逐行子查询"。
总结
数据库的高性能写入,核心在于减少上下文切换 和利用集合思维。
- 批量写入: 能用 INSERT INTO ... VALUES (...), (...) 就别用循环。千万级数据迁移请直接用 LOAD DATA。
- 逻辑原子性: 使用 ON DUPLICATE KEY UPDATE 替代"查-改-存"逻辑,既提升性能又保证原子性。
- 关联更新: 涉及多表数据同步更新时,UPDATE JOIN 是比子查询更优的选择。