介绍
xllm是使用c++语言构建的大模型推理服务器。
代码地址:https://gitee.com/mirrors/xllm
技术报告:https://arxiv.org/html/2510.14686v1
启动流程
https://gitee.com/mirrors/xllm/blob/main/xllm/xllm.cpp
cpp
std::unique_ptr<Master> create_master(const std::string& backend,
const Options& options) {
if (backend == "llm") {
return std::make_unique<LLMMaster>(options);
} else if (backend == "vlm") {
return std::make_unique<VLMMaster>(options);
} else if (backend == "dit") {
LOG(INFO) << "creating dit master";
return std::make_unique<DiTMaster>(options);
} else if (backend == "rec") {
LOG(INFO) << "creating rec master";
return std::make_unique<RecMaster>(options);
} else {
LOG(FATAL) << "Failed to create master, backend is" << backend;
return nullptr;
}
}
int run() {
// working node
if (options.node_rank() != 0) {
auto master = std::make_unique<LLMAssistantMaster>(options);
master->run();
return 0;
} else {
if (FLAGS_random_seed < 0) {
FLAGS_random_seed = std::random_device{}() % (1 << 30);
}
}
// master node
auto master = create_master(FLAGS_backend, options);
master->run();
// supported models
std::vector<std::string> model_names = {FLAGS_model_id};
std::string model_version;
if (model_path.has_filename()) {
model_version = std::filesystem::path(FLAGS_model).filename();
} else {
model_version = std::filesystem::path(FLAGS_model).parent_path().filename();
}
std::vector<std::string> model_versions = {model_version};
auto api_service =
std::make_unique<APIService>(master.get(), model_names, model_versions);
auto xllm_server =
ServerRegistry::get_instance().register_server("HttpServer");
// start brpc server
if (!xllm_server->start(std::move(api_service))) {
LOG(ERROR) << "Failed to start brpc server on port " << FLAGS_port;
return -1;
}
return 0;
}
int main(int argc, char** argv) {
FLAGS_alsologtostderr = true;
FLAGS_minloglevel = 0;
google::ParseCommandLineFlags(&argc, &argv, true);
google::InitGoogleLogging("xllm");
return run();
}主结点,rank为0时,xllm调用create_master创建Master。否则,xllm创建LLMAssistantMaster。
Master
LLMAssistantMaster和LLMMaster继承Master。
cpp
class LLMAssistantMaster : public Master {
public:
LLMAssistantMaster(const Options& options);
~LLMAssistantMaster() = default;
void run() override;
static void handle_signal(int signum) { running_ = false; }
};
class LLMMaster : public Master {
public:
explicit LLMMaster(const Options& options);
~LLMMaster();
// handle a request, the engine will execute the request asynchronously
// completion/encode
void handle_request(std::string prompt,
std::optional<std::vector<int>> prompt_tokens,
RequestParams sp,
std::optional<Call*> call,
OutputCallback callback);
// chat
void handle_request(std::vector<Message> messages,
std::optional<std::vector<int>> prompt_tokens,
RequestParams sp,
std::optional<Call*> call,
OutputCallback callback);
// batch completion
void handle_batch_request(std::vector<std::string> prompts,
std::vector<RequestParams> sp,
BatchOutputCallback callback);
// batch chat
void handle_batch_request(std::vector<std::vector<Message>> conversations,
std::vector<RequestParams> sp,
BatchOutputCallback callback);
// start running loop
void run() override;
// generate will run all request done at once,
// this is a blocking call
void generate();
void get_cache_info(std::vector<uint64_t>& cluster_ids,
std::vector<std::string>& addrs,
std::vector<int64_t>& k_cache_ids,
std::vector<int64_t>& v_cache_ids);
bool link_cluster(const std::vector<uint64_t>& cluster_ids,
const std::vector<std::string>& addrs,
const std::vector<std::string>& device_ips,
const std::vector<uint16_t>& ports,
const int32_t dp_size);
bool unlink_cluster(const std::vector<uint64_t>& cluster_ids,
const std::vector<std::string>& addrs,
const std::vector<std::string>& device_ips,
const std::vector<uint16_t>& ports,
const int32_t dp_size);
};Master中创建engine
cpp
Master::Master(const Options& options, EngineType type) : options_(options) {
else if (type == EngineType::LLM) {
if (options_.task_type() == "embed") {
options_.enable_schedule_overlap(false);
LOG(WARNING) << "Force to disable schedule overlap for embedding model, "
"avoiding performance degradation.";
}
runtime::Options eng_options;
eng_options.model_path(options_.model_path())
.devices(devices)
.backend(options_.backend())
.block_size(options_.block_size())
.max_cache_size(options_.max_cache_size())
.max_memory_utilization(options_.max_memory_utilization())
.enable_prefix_cache(options_.enable_prefix_cache())
.task_type(options_.task_type())
.enable_mla(options_.enable_mla())
.master_node_addr(options_.master_node_addr())
.nnodes(options_.nnodes())
.node_rank(options_.node_rank())
.dp_size(options_.dp_size())
.ep_size(options_.ep_size())
.enable_chunked_prefill(options_.enable_chunked_prefill())
.max_seqs_per_batch(options_.max_seqs_per_batch())
.max_tokens_per_chunk_for_prefill(
options_.max_tokens_per_chunk_for_prefill())
.instance_role(options_.instance_role())
.kv_cache_transfer_mode(options_.kv_cache_transfer_mode())
.transfer_listen_port(options_.transfer_listen_port())
.enable_disagg_pd(options_.enable_disagg_pd())
.enable_service_routing(options_.enable_service_routing())
.enable_schedule_overlap(options_.enable_schedule_overlap())
.enable_cache_upload(options_.enable_cache_upload())
.host_blocks_factor(options_.host_blocks_factor())
.enable_kvcache_store(options_.enable_kvcache_store())
.store_protocol(options_.store_protocol())
.store_master_server_address(options_.store_master_server_address())
.store_metadata_server(options_.store_metadata_server())
.store_local_hostname(options_.store_local_hostname())
.prefetch_bacth_size(options_.prefetch_bacth_size())
.layers_wise_copy_batchs(options_.layers_wise_copy_batchs())
.enable_continuous_kvcache(options_.enable_continuous_kvcache())
.enable_offline_inference(options_.enable_offline_inference())
.spawn_worker_path(options_.spawn_worker_path())
.enable_shm(options_.enable_shm())
.is_local(options_.is_local())
.server_idx(options_.server_idx());
if (options_.device_ip().has_value()) {
eng_options.device_ip(options_.device_ip().value());
}
engine_ = std::make_unique<LLMEngine>(eng_options);
}
}以LLMEngine为例,进行分析。
LLMEngine
cpp
LLMEngine::LLMEngine(const runtime::Options& options,
std::shared_ptr<DistManager> dist_manager)
: options_(options), dist_manager_(dist_manager) {
InterruptionBus::get_instance().subscribe([this](bool interrupted) {
this->layer_forward_interrupted_ = interrupted;
});
auto master_node_addr = options.master_node_addr().value_or("");
CHECK(!master_node_addr.empty())
<< " LLM need to set master node addr, Please set --master_node_addr.";
const auto& devices = options_.devices();
// initialize device monitor
DeviceMonitor::get_instance().initialize(devices);
CHECK_GT(devices.size(), 0) << "At least one device is required";
CHECK(!devices[0].is_cpu()) << "CPU device is not supported";
const auto device_type = devices[0].type();
for (const auto device : devices) {
CHECK_EQ(device.type(), device_type)
<< "All devices should be the same type";
#if defined(USE_NPU)
FLAGS_enable_atb_comm_multiprocess =
options.enable_offline_inference() || (options.nnodes() > 1);
#endif
}
// setup all workers and create worker clients in nnode_rank=0 engine side.
setup_workers(options);
dp_size_ = options_.dp_size();
worker_clients_num_ = worker_clients_.size();
dp_local_tp_size_ = worker_clients_num_ / dp_size_;
// create ThreadPool for link cluster
link_threadpool_ = std::make_unique<ThreadPool>(worker_clients_num_);
process_group_test();
// init thread pool
threadpool_ = std::make_unique<ThreadPool>(16);
}
void LLMEngine::setup_workers(const runtime::Options& options) {
if (!dist_manager_) {
dist_manager_ = std::make_shared<DistManager>(options);
}
worker_clients_ = dist_manager_->get_worker_clients();
}LLMEngine的构造函数中调用setup_workers,创建DistManager。
当node_rank !=0, worker_clients_为空指针。
cpp
void LLMEngine::setup_workers(const runtime::Options& options) {
if (!dist_manager_) {
dist_manager_ = std::make_shared<DistManager>(options);
}
worker_clients_ = dist_manager_->get_worker_clients();
}DistManager
cpp
DistManager::DistManager(const runtime::Options& options)
: server_name_("CollectiveServer") {
auto master_node_addr = options.master_node_addr().value_or("");
if (!master_node_addr.empty()) {
server_name_.append(std::to_string(options.server_idx()));
setup_multi_node_workers(options, master_node_addr);
} else {
LOG(FATAL) << "master_node_addr is empty.";
}
}
void DistManager::setup_multi_node_workers(
const runtime::Options& options,
const std::string& master_node_addr) {
const auto& devices = options.devices();
// Process/Thread Worker Mode, we use it in multi-nodes serving.
// Here, we assume that all node use same index devices. That is, if we set
// device='1,2,3,4' and nnodes=2, then both machine nodes will use the
// devices '1,2,3,4'. Therefore, the total world size is 2 * 4 = 8. This
// means that each of the two nodes will utilize four devices (specifically
// devices 1, 2, 3, and 4), resulting in a total of 8 devices being used
// across the entire distributed setup.
// To maintain interface consistency, we have implemented a new WorkerImpl
// class. In this class, we create processes, initialize NCCL ProcessGroup,
// set up GRPC servers, and so on.
std::vector<std::atomic<bool>> dones(devices.size());
for (size_t i = 0; i < devices.size(); ++i) {
dones[i].store(false, std::memory_order_relaxed);
}
// create local workers
for (size_t i = 0; i < devices.size(); ++i) {
// worldsize = 8
// Node1: 0, 1, 2, 3
// Node2: 0+4, 1+4, 2+4, 3+4
const int32_t rank = static_cast<int32_t>(i) + base_rank;
// we use spawn process worker to launch a xllm instance
// when start a offline inference task with multi-gpu/npu/mpu/...
bool use_spawn_worker = options.enable_offline_inference() && i > 0;
ParallelArgs parallel_args(rank, world_size, dp_size, nullptr, ep_size);
servers_.emplace_back(std::make_unique<WorkerServer>(i,
master_node_addr,
// done,
dones[i],
parallel_args,
devices[i],
worker_server_options,
worker_type,
use_spawn_worker));
}
// Master node need to wait all workers done
if (options.node_rank() == 0) {
// if dp_size equals 1, use global process group directly
// if dp_size equals world_size, distributed communication is not required
auto dp_local_process_group_num =
(dp_size > 1 && dp_size < world_size) ? dp_size : 0;
// create collective server to sync all workers.
std::shared_ptr<CollectiveService> collective_service =
std::make_shared<CollectiveService>(
dp_local_process_group_num, world_size, devices[0].index());
XllmServer* collective_server =
ServerRegistry::get_instance().register_server(server_name_);
if (!collective_server->start(collective_service, master_node_addr)) {
LOG(ERROR) << "failed to start collective server on address: "
<< master_node_addr;
return;
}
auto worker_addrs_map = collective_service->wait();
// check if all workers connected
// and then create worker clients
for (size_t r = 0; r < world_size; ++r) {
if (worker_addrs_map.find(r) == worker_addrs_map.end()) {
LOG(FATAL) << "Not all worker connect to engine server. Miss rank is "
<< r;
return;
}
auto channel =
create_channel(worker_addrs_map[r], r, dp_local_tp_size, options);
worker_clients_.emplace_back(
std::make_unique<RemoteWorker>(r,
worker_addrs_map[r],
devices[r % each_node_ranks],
std::move(channel)));
}
}
}DistManager的构造函数调用setup_multi_node_workers。
在每个node中,setup_multi_node_workers为每一个device创建一个WorkerServer。
WorkerServer将绑定的ip:port,通知master node。
master node通过collective_service->wait()获取相应的端口信息。
options.node_rank() == 0之后的代码逻辑,就可以获取WorkerServer对应的ip:port信息。
create_channel创建channel,用于远程调用。注意这里的RemoteWorker。
cpp
std::unique_ptr<CommChannel> create_channel(const std::string& worker_addrs,
int r,
int dp_local_tp_size,
const runtime::Options& options) {
std::unique_ptr<CommChannel> channel;
if (net::extract_ip(options.master_node_addr().value_or("")) ==
net::extract_ip(worker_addrs) &&
options.enable_shm()) {
// create shared memory manager for local rank
bool is_driver = false;
int dp_group = r / dp_local_tp_size;
if (r % dp_local_tp_size == 0) {
is_driver = true;
}
channel = std::make_unique<ShmChannel>(dp_group, r, is_driver, options);
} else {
channel = std::make_unique<CommChannel>();
}
channel->init_brpc(worker_addrs);
return channel;
}WorkerServer
cpp
WorkerServer::WorkerServer(int local_worker_idx,
const std::string& master_node_addr,
std::atomic<bool>& done,
const ParallelArgs& parallel_args,
const torch::Device& d,
const runtime::Options& options,
WorkerType worker_type,
bool use_spawn_worker)
: server_name_("DistributeWorkerServer") {
prepare_shm(
parallel_args, options, input_shm_manager, output_shm_manager);
// start worker in a thread.
worker_thread_ =
std::make_unique<std::thread>(&WorkerServer::create_server,
this,
std::cref(options),
std::ref(done),
std::cref(master_node_addr),
std::cref(d),
parallel_args.world_size(),
parallel_args.rank(),
parallel_args.dp_size(),
local_worker_idx,
parallel_args.ep_size(),
worker_type,
std::move(input_shm_manager),
std::move(output_shm_manager));
}
void WorkerServer::create_server(
const runtime::Options& options,
std::atomic<bool>& done,
const std::string& master_node_addr,
const torch::Device& d,
int world_size,
int global_rank,
int32_t dp_size,
int local_rank,
int32_t ep_size,
WorkerType worker_type,
std::unique_ptr<ForwardSharedMemoryManager> input_shm_manager,
std::unique_ptr<ForwardSharedMemoryManager> output_shm_manager) {
Device device(d);
device.set_device();
auto worker_service = std::make_shared<WorkerService>(options, device);
auto addr = net::get_local_ip_addr();
auto worker_server =
ServerRegistry::get_instance().register_server(server_name_);
if (!worker_server->start(worker_service, addr + ":0")) {
LOG(ERROR) << "failed to start distribute worker server on address: "
<< addr;
return;
}
auto worker_server_addr =
addr + ":" + std::to_string(worker_server->listen_port());
LOG(INFO) << "Worker " << worker_global_rank
<< ": server address: " << worker_server_addr;
// Sync with master node
proto::AddressInfo addr_info;
addr_info.set_address(worker_server_addr);
addr_info.set_global_rank(worker_global_rank);
proto::CommUniqueIdList uids;
sync_master_node(master_node_addr, addr_info, uids);
CollectiveCommunicator comm(worker_global_rank, world_size, dp_size, ep_size);
const ParallelArgs* parallel_args = comm.parallel_args();
comm.create_process_groups(master_node_addr, device);
std::unique_ptr<Worker> worker =
std::make_unique<Worker>(*parallel_args, device, options, worker_type);
worker_service->set_worker(std::move(worker));
if (options.enable_shm() && input_shm_manager && output_shm_manager) {
worker_service->create_polling_shm_thread(std::move(input_shm_manager),
std::move(output_shm_manager));
}
done.store(true);
// Wait until Ctrl-C is pressed, then Stop() and Join() the server.
worker_server->run();
}
bool WorkerServer::sync_master_node(const std::string& master_node_addr,
proto::AddressInfo& addr_info,
proto::CommUniqueIdList& uids) {
if (channel.Init(master_node_addr.c_str(), "", &options) != 0) {
LOG(ERROR) << "Failed to initialize BRPC channel to " << master_node_addr;
return false;
}
proto::Collective_Stub stub(&channel);
while (try_count < FLAGS_max_reconnect_count) {
cntl.Reset();
stub.Sync(&cntl, &addr_info, &uids, NULL);
if (cntl.Failed()) {
LOG(WARNING) << "Worker#" << addr_info.global_rank()
<< " try connect to engine server error, try again."
<< " Error message: " << cntl.ErrorText();
std::this_thread::sleep_for(std::chrono::seconds(sleep_time_second));
} else {
LOG(INFO) << "Worker#" << addr_info.global_rank() << " connect to "
<< master_node_addr << " success.";
break;
}
try_count++;
}
}sync_master_node向master node发送ip:port信息。
WorkerService中的函数,实现proto::DistributeWorker定义的rpc接口。
https://gitee.com/mirrors/xllm/blob/main/xllm/proto/worker.proto
cpp
// Worker receive action from master engine.
service DistributeWorker {
rpc Hello (Status) returns (Status);
rpc InitModel (InitModelRequest) returns (Status);
rpc ProcessGroupTest (Empty) returns (Status);
rpc ProfileDeviceMemory (Empty) returns (DeviceMemory);
rpc AllocateKVCache (KVCacheShape) returns (Status);
rpc AllocateContinuousKVCache (XTensorOptionsVec) returns (Status);
rpc AllocateKVCacheWithTransfer(AllocateKVCacheWithTransferRequest) returns (Status) {}
rpc PullKVCache(PullKVCacheRequest) returns (Status) {}
rpc GetDeviceInfo(Empty) returns (DeviceInfo) {}
rpc GetCacheInfo(Empty) returns (CacheInfo) {}
rpc LinkCluster(ClusterInfo) returns (Status) {}
rpc UnlinkCluster(ClusterInfo) returns (Status) {}
rpc ExecuteModel (ForwardInput) returns (ForwardOutput);
rpc GetLastStepResult (Empty) returns (ForwardOutput);
rpc GetActiveActivationMemory (Empty) returns (ActivationMemory);
rpc TransferBlocks(BlockTransferInfos) returns (TransferStatus) {}
rpc PrefetchFromStorage(BlockTransferInfos) returns (Status) {}
}WorkerService中对应的函数定义:
cpp
class WorkerService : public proto::DistributeWorker {
public:
WorkerService(runtime::Options options, const torch::Device& device);
WorkerService(runtime::Options options,
const torch::Device& device,
std::unique_ptr<Worker> worker);
virtual ~WorkerService();
void set_worker(std::unique_ptr<Worker> worker);
void create_polling_shm_thread(
std::unique_ptr<ForwardSharedMemoryManager> input_shm_manager,
std::unique_ptr<ForwardSharedMemoryManager> output_shm_manager);
// service functions
void Hello(::google::protobuf::RpcController* controller,
const proto::Status* request,
proto::Status* response,
::google::protobuf::Closure* done) override;
void InitModel(::google::protobuf::RpcController* controller,
const proto::InitModelRequest* request,
proto::Status* response,
::google::protobuf::Closure* done) override;
void ProcessGroupTest(::google::protobuf::RpcController* controller,
const proto::Empty* request,
proto::Status* response,
::google::protobuf::Closure* done) override;
void ProfileDeviceMemory(::google::protobuf::RpcController* controller,
const proto::Empty* request,
proto::DeviceMemory* response,
::google::protobuf::Closure* done) override;
void AllocateKVCache(::google::protobuf::RpcController* controller,
const proto::KVCacheShape* request,
proto::Status* response,
::google::protobuf::Closure* done) override;
void AllocateContinuousKVCache(::google::protobuf::RpcController* controller,
const proto::XTensorOptionsVec* request,
proto::Status* response,
::google::protobuf::Closure* done) override;
void AllocateKVCacheWithTransfer(
::google::protobuf::RpcController* controller,
const proto::AllocateKVCacheWithTransferRequest* req,
proto::Status* resp,
::google::protobuf::Closure* done) override;
void PullKVCache(::google::protobuf::RpcController* controller,
const proto::PullKVCacheRequest* req,
proto::Status* resp,
::google::protobuf::Closure* done) override;
void TransferBlocks(::google::protobuf::RpcController* controller,
const proto::BlockTransferInfos* req,
proto::TransferStatus* resp,
::google::protobuf::Closure* done) override;
void PrefetchFromStorage(google::protobuf::RpcController* controller,
const proto::BlockTransferInfos* req,
proto::Status* resp,
google::protobuf::Closure* done) override;
void GetDeviceInfo(::google::protobuf::RpcController* controller,
const proto::Empty* req,
proto::DeviceInfo* resp,
::google::protobuf::Closure* done) override;
void GetCacheInfo(::google::protobuf::RpcController* controller,
const proto::Empty* req,
proto::CacheInfo* resp,
::google::protobuf::Closure* done) override;
void LinkCluster(::google::protobuf::RpcController* controller,
const proto::ClusterInfo* req,
proto::Status* resp,
::google::protobuf::Closure* done) override;
void UnlinkCluster(::google::protobuf::RpcController* controller,
const proto::ClusterInfo* req,
proto::Status* resp,
::google::protobuf::Closure* done) override;
void ExecuteModel(::google::protobuf::RpcController* controller,
const proto::ForwardInput* pb_fwd_input,
proto::ForwardOutput* pb_forward_output,
::google::protobuf::Closure* done) override;
void GetLastStepResult(::google::protobuf::RpcController* controller,
const proto::Empty* req,
proto::ForwardOutput* pb_forward_output,
::google::protobuf::Closure* done) override;
void GetActiveActivationMemory(::google::protobuf::RpcController* controller,
const proto::Empty* req,
proto::ActivationMemory* resp,
::google::protobuf::Closure* done) override;
};框架图例
假设系统中有两台机器(node0, node1),每台机器上有8张卡。
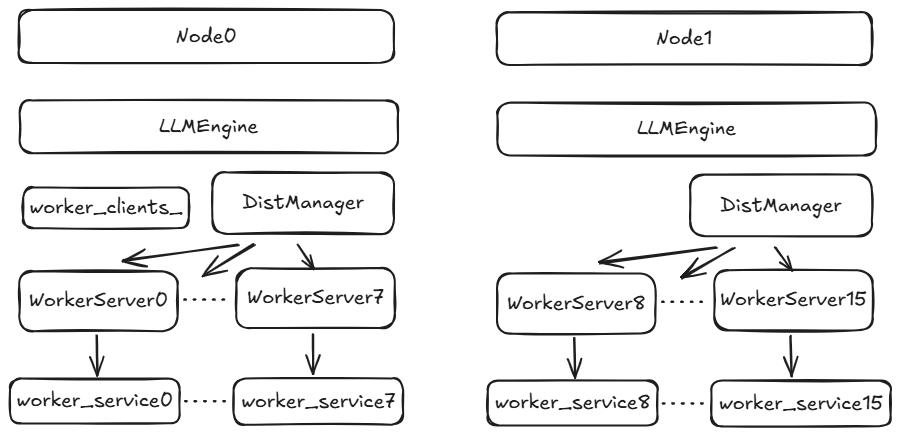
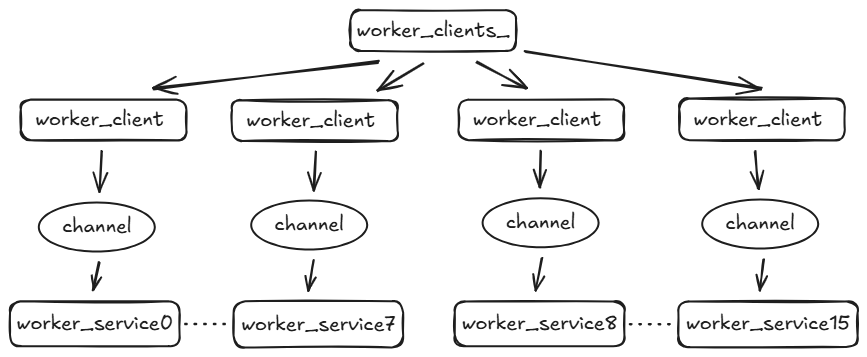
master node的LLMEngine使用WorkerClient,发起远程调用。
以init_model为例:
cpp
bool LLMEngine::init_model() {
// init model for each worker in parallel
// multiple workers, call async init
std::vector<folly::SemiFuture<bool>> futures;
futures.reserve(worker_clients_num_);
for (auto& worker : worker_clients_) {
futures.push_back(worker->init_model_async(model_path, FLAGS_random_seed));
}
// wait for all futures to complete
auto results = folly::collectAll(futures).get();
for (const auto& result : results) {
if (!result.value()) {
return false;
}
}
return true;
}
folly::SemiFuture<bool> RemoteWorker::init_model_async(
const std::string& model_weights_path,
int32_t random_seed) {
folly::Promise<bool> promise;
auto future = promise.getSemiFuture();
threadpool_.schedule([this,
model_weights_path,
random_seed,
promise = std::move(promise)]() mutable {
// call InitModel with callback
channel_->init_model_async(model_weights_path, random_seed, promise);
});
return future;
}
bool CommChannel::init_model_async(const std::string& model_weights_path,
int32_t random_seed,
folly::Promise<bool>& promise) {
proto::InitModelRequest request;
request.set_model_weights_path(model_weights_path);
request.set_random_seed(random_seed);
auto done = new InitModelClosure();
done->promise = std::move(promise);
stub_->InitModel(&done->cntl, &request, &done->response, done);
return true;
}远端服务器会调用WorkerService::InitModel。
cpp
void WorkerService::InitModel(::google::protobuf::RpcController* controller,
const proto::InitModelRequest* request,
proto::Status* response,
::google::protobuf::Closure* done) {
threadpool_->schedule([this, controller, request, response, done]() mutable {
brpc::ClosureGuard done_guard(done);
auto model_weights_path = request->model_weights_path();
auto random_seed = request->random_seed();
auto init_future =
worker_->init_model_async(model_weights_path, random_seed);
bool status = std::move(init_future).get();
if (!status) {
response->set_ok(false);
return;
}
response->set_ok(true);
});
return;
}