前置知识
2 From Online Softmax to FlashAttention
5 FA2中Flash-decoding 第二阶段reduce sum计算公式推导
6 VLLM 学习- Paged Attention Kernel 解析
本篇博客是个简单总结,记录flashinfer中decode attention算子的执行流程。读懂算子代码,需要阅读上面关于FlashAttention v1/v2,Flash Decoding的博客链接,公式推导。
在flashinfer项目中,decode实现的是Flash Decoding算法。
按照博客4,Flash Decoding在 KV 维度上引入并行,主要分为两个步骤:
- Split-KV 并行计算:将 KV Cache 沿序列维度切分为多个块(split),每个块由一个独立的线程块处理。每个线程块独立计算其负责的 KV 块对应的局部注意力结果。
- 所有线程块完成计算后,通过一次归约操作将各个局部结果合并为最终的全局注意力输出。
Flash Decoding算法官方示意图,Flash-Decoding for long-context inference
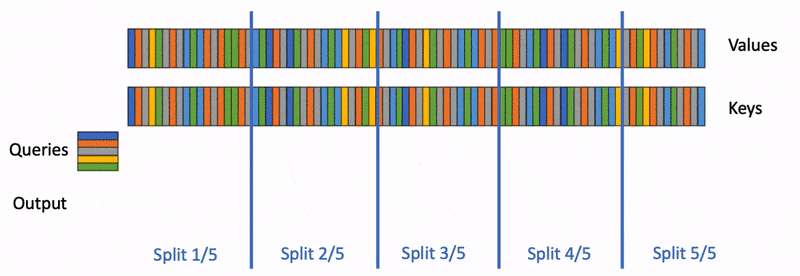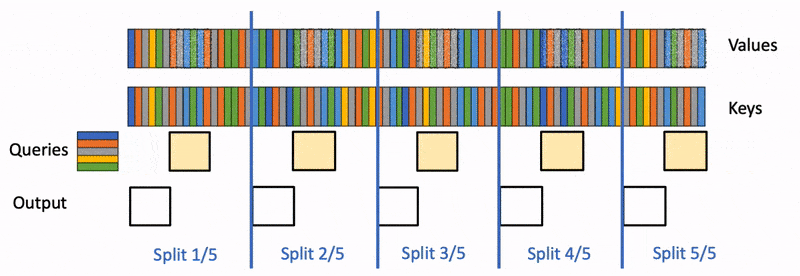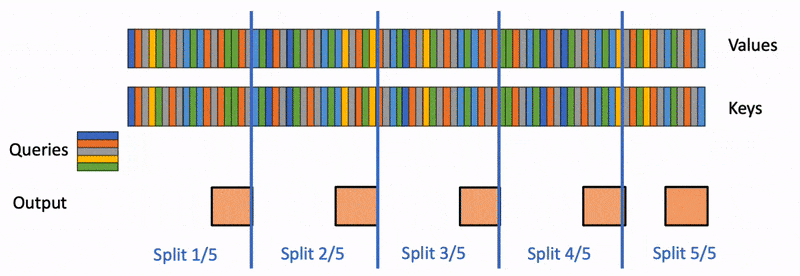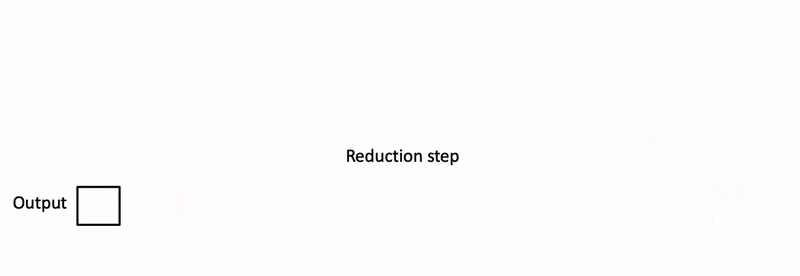
Flash-Decoding also parallelizes across keys and values, at the cost of a small final reduction step
在flashinfer的BatchDecodeWithPagedKVCacheDispatched函数中调用了两个核函数:BatchDecodeWithPagedKVCacheKernel和PersistentVariableLengthMergeStatesKernel。 BatchDecodeWithPagedKVCacheKernel执行FlashAttention v2算法。 PersistentVariableLengthMergeStatesKernel执行规约。
Flash-Decoding公式推导
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d ) V Attention(Q, K, V) = softmax(\frac{QK^T}{\sqrt{d}})V Attention(Q,K,V)=softmax(d QKT)V
s o f t m a x ( x i ) = e x i ∑ j N e x j softmax(x_i) = \frac{e^{x_i}}{\sum_{j}^{N}e^{x_j}} softmax(xi)=∑jNexjexi
logsumexp的定义:
l s e = l o g ( ∑ j N e x j ) = l o g ( e m i × ∑ j N e x j − m i ) = m i + l o g ( ∑ j N e x j − m i ) lse=log(\sum_{j}^{N}e^{x_j}) = log(e^{m_i}\times\sum_{j}^{N}e^{x_j - m_i}) = m_{i} +log(\sum_{j}^{N}e^{x_j - m_i}) lse=log(j∑Nexj)=log(emi×j∑Nexj−mi)=mi+log(j∑Nexj−mi)
其中, m i = max j N x j m_i = \max_{j}^{N}{x_j} mi=maxjNxj,在N个 x j x_j xj,求取最大值。这个值防止exp计算溢出。 m i m_i mi可以在扫描 x j x_j xj的过程中不断更新。
m = -math::inf
d = 1.0
for j in 0...N
m_prev = m
m = max(m, x[j])
scale = math::ptx_exp2(m_prev - m)
t = math::ptx_exp2(x[j] - m)
d = d * scale + tscale是为了消掉m_prev,使用最新的m值,更新d值。经过一轮扫描,lse = m + log(d)。
这段伪代码描述的源码,参看flashinfer的compute_qk。针对测试代码,tile_size=1。
https://gitcode.com/gh_mirrors/fl/flashinfer/blob/main/include/flashinfer/attention/decode.cuh
cpp
__device__ __forceinline__ void compute_qk(...) {
if constexpr (variant.use_softmax) {
float o_scale = math::ptx_exp2(m_prev - st.m);
st.d *= o_scale;
#pragma unroll
for (uint32_t j = 0; j < tile_size; ++j) {
s[j] = math::ptx_exp2(s[j] - st.m);
st.d += s[j];
}
#pragma unroll
for (uint32_t i = 0; i < vec_size; ++i) {
st.o[i] = st.o[i] * o_scale;
}
}
}根据FA2中Flash-decoding第二阶段reduce sum计算公式推导, Flash Decoding 原理与实现
现在考虑合并两个分块的输出, Q k , : Qk, : Qk,:为Q的一行,总的元素个数为d。记分块1的attention输出为 O a O_a Oa, 其logsumexp为 l s e a lse_{a} lsea,分块2的attention输出为 O b O_b Ob, 其logsumexp为 l s e b lse_{b} lseb。
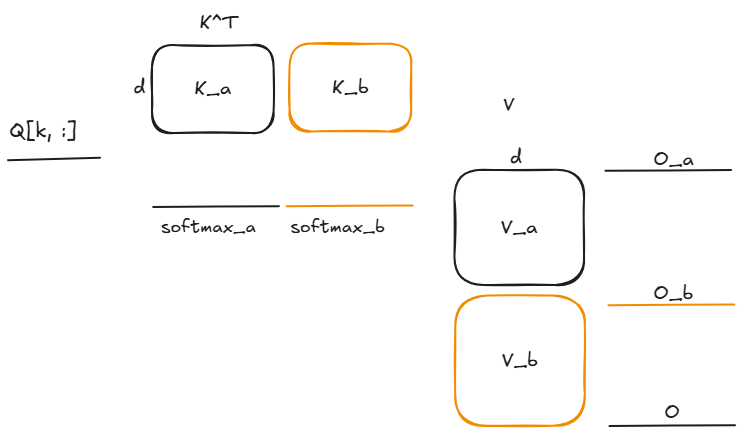
针对某个分块a, 其attention输出:
O a = ∑ j = 0 o f f e x j a × V : , j e x p ( l s e a ) O_{a}=\frac{\sum_{j=0}^{off}e^{x_{j}^{a}}\times V:, j}{exp(lse_{a})} Oa=exp(lsea)∑j=0offexja×V:,j
其中,off是V中第一块的行数。
同理, O b O_b Ob的表示:
O b = ∑ j = o f f e x j b × V : , j e x p ( l s e b ) O_{b}=\frac{\sum_{j =off}e^{x_{j}^{b}}\times V:, j}{exp(lse_{b})} Ob=exp(lseb)∑j=offexjb×V:,j
可以通过 O a O_{a} Oa, O b O_{b} Ob, 推导出 O O O。 l s e m a x = max ( l s e a , l s e b ) lse_{max} = \max{(lse_{a}, lse_{b})} lsemax=max(lsea,lseb),只是一个额外的配置系数。
O = e x p ( l s e a ) × O a + e x p ( l s e b ) × O b e x p ( l s e a ) + e x p ( l s e b ) × 1 / e x p ( l s e m a x ) 1 / e x p ( l s e m a x ) = e x p ( l s e a − l s e m a x ) × O a + e x p ( l s e b − l s e m a x ) × O b e x p ( l s e a − l s e m a x ) + e x p ( l s e b − l s e m a x ) \begin{align} O & = \frac{exp(lse_{a})\times O_{a} +exp(lse_{b})\times O_{b}}{exp(lse_{a}) + exp(lse_{b})}\times \frac{1/exp(lse_{max})}{1/exp(lse_{max})} \\ & = \frac{exp(lse_{a} - lse_{max})\times O_{a} +exp(lse_{b} - lse_{max})\times O_{b}}{exp(lse_{a} - lse_{max}) + exp(lse_{b} - lse_{max})} \end{align} O=exp(lsea)+exp(lseb)exp(lsea)×Oa+exp(lseb)×Ob×1/exp(lsemax)1/exp(lsemax)=exp(lsea−lsemax)+exp(lseb−lsemax)exp(lsea−lsemax)×Oa+exp(lseb−lsemax)×Ob
上述公式表明,每个KV块可以独立计算attention,记录lse,最终可以获取最终的attention输出。
如果有多个KV块,上述公式可以递推,对应merge中的代码实现:
https://gitcode.com/gh_mirrors/fl/flashinfer/blob/main/include/flashinfer/attention/state.cuh
cpp
/*!
* \brief Merge the state with another state.
* \param other_m The maximum value of pre-softmax logits of the other state.
* \param other_d The sum of exp(pre-softmax logits - m) of the other state.
* \param other_o The weighted sum of v of the other state.
*/
__device__ __forceinline__ void merge(const vec_t<float, vec_size>& other_o, float other_m,
float other_d) {
float m_prev = m, d_prev = d;
m = max(m_prev, other_m);
d = d_prev * math::ptx_exp2(m_prev - m) + other_d * math::ptx_exp2(other_m - m);
#pragma unroll
for (size_t i = 0; i < vec_size; ++i) {
o[i] = o[i] * math::ptx_exp2(m_prev - m) + other_o[i] * math::ptx_exp2(other_m - m);
}
}这里的m_prev记录的是之前轮次的最大lse,通过指数项exp(m_prev),可以消掉之前公式中exp(xx - m_prev)。
refer: Cascade and Recursive Attention
官方测试代码
https://docs.flashinfer.ai/api/attention.html
python
import torch
import flashinfer
num_layers = 1
num_qo_heads = 64
num_kv_heads = 8
head_dim = 128
max_num_pages = 128
page_size = 16
# allocate 128MB workspace buffer
workspace_buffer = torch.zeros(128 * 1024 * 1024, dtype=torch.uint8, device="cuda:0")
decode_wrapper = flashinfer.BatchDecodeWithPagedKVCacheWrapper(
workspace_buffer, "NHD"
)
batch_size = 7
kv_page_indices = torch.arange(max_num_pages).int().to("cuda:0")
kv_page_indptr = torch.tensor(
[0, 17, 29, 44, 48, 66, 100, 128], dtype=torch.int32, device="cuda:0"
)
# 1 <= kv_last_page_len <= page_size
kv_last_page_len = torch.tensor(
[1, 7, 14, 4, 3, 1, 16], dtype=torch.int32, device="cuda:0"
)
kv_cache_at_layer = [
torch.randn(
max_num_pages, 2, page_size, num_kv_heads, head_dim, dtype=torch.float16, device="cuda:0"
) for _ in range(num_layers)
]
# create auxiliary data structures for batch decode attention
decode_wrapper.plan(
kv_page_indptr,
kv_page_indices,
kv_last_page_len,
num_qo_heads,
num_kv_heads,
head_dim,
page_size,
pos_encoding_mode="NONE",
data_type=torch.float16
)
outputs = []
for i in range(num_layers):
q = torch.randn(batch_size, num_qo_heads, head_dim).half().to("cuda:0")
kv_cache = kv_cache_at_layer[i]
# compute batch decode attention, reuse auxiliary data structures for all layers
o = decode_wrapper.run(q, kv_cache)
outputs.append(o)
print(outputs[0].shape)q的维度为batch_size, num_qo_heads, head_dim = 7, 64, 128。
page_size=16, 每个内存块可以存储16个token对应的K或V。
kv_page_indptr :针对请求i,其占用的page数量=kv_page_indptri + 1 - kv_page_indptri。
kv_last_page_len :最后一页,token的个数。
在一张RTX 4090上运行上述代码。
BatchDecodeWithPagedKVCacheWrapper中plan,run在c++层对用的接口定义:
https://gitcode.com/gh_mirrors/fl/flashinfer/blob/main/csrc/batch_decode_jit_binding.cu
cpp
Array<int64_t> BatchDecodeWithPagedKVCachePlan(
TensorView float_workspace_buffer, TensorView int_workspace_buffer,
TensorView page_locked_int_workspace_buffer, TensorView indptr, int64_t batch_size,
int64_t num_qo_heads, int64_t num_kv_heads, int64_t page_size, bool enable_cuda_graph,
int64_t window_left, double logits_soft_cap, int64_t head_dim_qk, int64_t head_dim_vo,
TensorView empty_q_data, TensorView empty_kv_data);
void BatchDecodeWithPagedKVCacheRun(TensorView float_workspace_buffer,
TensorView int_workspace_buffer, Array<int64_t> plan_info_vec,
TensorView q, TensorView paged_k_cache,
TensorView paged_v_cache, TensorView paged_kv_indptr,
TensorView paged_kv_indices, TensorView paged_kv_last_page_len,
TensorView o, Optional<TensorView> maybe_lse,
int64_t kv_layout_code, int64_t window_left,
bool enable_pdl ADDITIONAL_FUNC_PARAMS);
// Batched decode with paged KV-Cache plan
TVM_FFI_DLL_EXPORT_TYPED_FUNC(plan, BatchDecodeWithPagedKVCachePlan);
// Batched decode with paged KV-Cache run
TVM_FFI_DLL_EXPORT_TYPED_FUNC(run, BatchDecodeWithPagedKVCacheRun);BatchDecodeWithPagedKVCachePlan
https://gitcode.com/gh_mirrors/fl/flashinfer/blob/main/csrc/batch_decode.cu
cpp
Array<int64_t> BatchDecodeWithPagedKVCachePlan(
TensorView float_workspace_buffer, TensorView int_workspace_buffer,
TensorView page_locked_int_workspace_buffer, TensorView indptr, int64_t batch_size,
int64_t num_qo_heads, int64_t num_kv_heads, int64_t page_size, bool enable_cuda_graph,
int64_t window_left, double logits_soft_cap, int64_t head_dim_qk, int64_t head_dim_vo,
TensorView empty_q_data, TensorView empty_kv_data) {
DISPATCH_context(
DTypeQ, DTypeKV, DTypeO, IdType, HEAD_DIM_QK, HEAD_DIM_VO, POS_ENCODING_MODE,
USE_SLIDING_WINDOW, USE_LOGITS_SOFT_CAP, AttentionVariant, Params, [&] {
DISPATCH_GQA_GROUP_SIZE(num_qo_heads / num_kv_heads, GROUP_SIZE, {
auto work_estimation_func = BatchDecodeWithPagedKVCacheWorkEstimationDispatched<
GROUP_SIZE, HEAD_DIM_QK, POS_ENCODING_MODE, AttentionVariant, Params>;
cudaError_t status = DecodePlan<HEAD_DIM_QK, POS_ENCODING_MODE, AttentionVariant, Params>(
static_cast<void*>(float_workspace_buffer.data_ptr()), float_workspace_size_in_bytes,
static_cast<void*>(int_workspace_buffer.data_ptr()),
static_cast<void*>(page_locked_int_workspace_buffer.data_ptr()),
int_workspace_size_in_bytes, plan_info, static_cast<IdType*>(indptr.data_ptr()),
batch_size, num_qo_heads, page_size, enable_cuda_graph,
/*stream=*/stream, work_estimation_func);
TVM_FFI_ICHECK(status == cudaSuccess)
<< "BatchDecodeWithPagedKVCache failed with error " << cudaGetErrorString(status);
return true;
});
});
return Array(plan_info.ToVector());
}针对测试例子GROUP_SIZE = num_qo_heads / num_kv_heads = 8。
DecodePlan
https://gitcode.com/gh_mirrors/fl/flashinfer/blob/main/include/flashinfer/attention/scheduler.cuh
cpp
template <uint32_t HEAD_DIM, PosEncodingMode POS_ENCODING_MODE, typename AttentionVariant,
typename Params, typename WorkEstimationFunc>
inline cudaError_t DecodePlan(void* float_buffer, size_t float_workspace_size_in_bytes,
void* int_buffer, void* page_locked_int_buffer,
size_t int_workspace_size_in_bytes, DecodePlanInfo& plan_info,
typename Params::IdType* indptr_h, uint32_t batch_size,
uint32_t num_qo_heads, uint32_t page_size, bool enable_cuda_graph,
cudaStream_t stream, WorkEstimationFunc work_estimation_func) {
FLASHINFER_CUDA_CALL(work_estimation_func(split_kv, max_grid_size, kv_chunk_size_in_pages,
new_batch_size, gdy, batch_size, indptr_h, num_qo_heads,
page_size, enable_cuda_graph, stream));
plan_info.split_kv = split_kv;
padded_batch_size =
(enable_cuda_graph) ? (split_kv ? max_grid_size / gdy : batch_size) : new_batch_size;
plan_info.padded_batch_size = padded_batch_size;
auto [request_indices_vec, kv_tile_indices_vec, o_indptr_vec] =
DecodeSplitKVIndptr(indptr_h, batch_size, kv_chunk_size_in_pages);
std::copy(request_indices_vec.begin(), request_indices_vec.end(), request_indices_h);
std::copy(kv_tile_indices_vec.begin(), kv_tile_indices_vec.end(), kv_tile_indices_h);
std::copy(o_indptr_vec.begin(), o_indptr_vec.end(), o_indptr_h);
kv_chunk_size_ptr_h[0] = kv_chunk_size_in_pages * page_size;
if (split_kv) {
AlignedAllocator float_allocator(float_buffer, float_workspace_size_in_bytes);
plan_info.v_offset = float_allocator.aligned_alloc_offset(
num_qo_heads * padded_batch_size * HEAD_DIM * sizeof(float), 16, "batch_decode_tmp_v");
plan_info.s_offset = float_allocator.aligned_alloc_offset(
num_qo_heads * padded_batch_size * sizeof(float), 16, "batch_decode_tmp_s");
}
}v_offset指向O的存储空间。s_offset指向lse的存储空间。
work_estimation_func 为BatchDecodeWithPagedKVCacheWorkEstimationDispatched。
work_estimation_func执行后,打印信息:
split_kv: 1 max_grid_size: 912 kv_chunk_size_in_pages 8 new_batch_size 20 gdy 8
BatchDecodeWithPagedKVCacheWorkEstimationDispatched
cpp
template <uint32_t GROUP_SIZE, uint32_t HEAD_DIM, PosEncodingMode POS_ENCODING_MODE,
typename AttentionVariant, typename Params>
inline cudaError_t BatchDecodeWithPagedKVCacheWorkEstimationDispatched(
bool& split_kv, uint32_t& max_grid_size, uint32_t& max_num_pages_per_batch,
uint32_t& new_batch_size, uint32_t& gdy, uint32_t batch_size,
typename Params::IdType* kv_indptr_h, const uint32_t num_qo_heads, const uint32_t page_size,
bool enable_cuda_graph, cudaStream_t stream) {
constexpr uint32_t vec_size = std::max(16UL / sizeof(DTypeKV), HEAD_DIM / 32UL);
auto compute_capacity = GetCudaComputeCapability();
DISPATCH_COMPUTE_CAP_DECODE_NUM_STAGES_SMEM(compute_capacity, NUM_STAGES_SMEM, {
constexpr uint32_t bdx = HEAD_DIM / vec_size;
static_assert(bdx <= 32);
constexpr uint32_t bdy = GROUP_SIZE;
constexpr uint32_t num_threads = std::max(128U, bdx * bdy);
constexpr uint32_t bdz = num_threads / (bdx * bdy);
constexpr uint32_t tile_size_per_bdx = GROUP_SIZE == 1 ? (sizeof(DTypeKV) == 1 ? 2U : 4U) : 1U;
const uint32_t num_kv_heads = num_qo_heads / GROUP_SIZE;
gdy = num_kv_heads;
const uint32_t smem_size =
2 * NUM_STAGES_SMEM * tile_size_per_bdx * bdy * bdz * HEAD_DIM * sizeof(DTypeKV) +
std::max(tile_size_per_bdx * num_threads * sizeof(DTypeKV*), 2 * bdy * bdz * sizeof(float));
auto kernel =
BatchDecodeWithPagedKVCacheKernel<POS_ENCODING_MODE, NUM_STAGES_SMEM, tile_size_per_bdx,
vec_size, bdx, bdy, bdz, AttentionVariant, Params>;
int num_blocks_per_sm = 0;
int num_sm = 0;
int dev_id = 0;
FLASHINFER_CUDA_CALL(cudaGetDevice(&dev_id));
FLASHINFER_CUDA_CALL(cudaDeviceGetAttribute(&num_sm, cudaDevAttrMultiProcessorCount, dev_id));
FLASHINFER_CUDA_CALL(cudaOccupancyMaxActiveBlocksPerMultiprocessor(&num_blocks_per_sm, kernel,
num_threads, smem_size));
max_grid_size = num_blocks_per_sm * num_sm;
std::cout << "vec_size: " << vec_size << " bdx " << bdx << " bdy " << bdy << " bdz " << bdz
<< " tile_size_per_bdx: " << tile_size_per_bdx << std::endl;
std::cout << "num_sm " << num_sm << " num_blocks_per_sm " << num_blocks_per_sm << " mgz " << max_grid_size << std::endl;
if (batch_size * gdy >= max_grid_size) {
split_kv = false;
max_num_pages_per_batch = 1;
for (uint32_t batch_idx = 0; batch_idx < batch_size; ++batch_idx) {
max_num_pages_per_batch = std::max<uint32_t>(
max_num_pages_per_batch, kv_indptr_h[batch_idx + 1] - kv_indptr_h[batch_idx]);
}
new_batch_size = batch_size;
} else {
// compute max_num_pages_per_batch and new_batch_size
std::vector<IdType> num_pages(batch_size);
for (uint32_t batch_idx = 0; batch_idx < batch_size; ++batch_idx) {
num_pages[batch_idx] = kv_indptr_h[batch_idx + 1] - kv_indptr_h[batch_idx];
}
std::tie(max_num_pages_per_batch, new_batch_size) =
PartitionPagedKVCacheBinarySearchMinNumPagePerBatch(max_grid_size, gdy, num_pages,
std::max(128 / page_size, 1U));
if (new_batch_size == batch_size && !enable_cuda_graph) {
// do not use partition-kv kernel for short sequence, when not using CUDAGraph
split_kv = false;
} else {
// when using CUDAGraph, we always use partition-kv kernel
split_kv = true;
}
std::cout << "max_num_pages_per_batch: " << max_num_pages_per_batch
<< " new_batch_size " << new_batch_size << " split_kv " << split_kv << std::endl;
}
return cudaSuccess;
})
}std::cout输出信息:
vec_size: 8 bdx 16 bdy 8 bdz 1 tile_size_per_bdx: 1
num_sm 114 num_blocks_per_sm 8 mgz 912
max_num_pages_per_batch: 8 new_batch_size 20 split_kv 1
vec_size = 8, 每个线程从q中读取8个数据。
max_num_pages_per_batch:新的batch,每次处理8个page,处理的token数量为max_num_pages_per_batch * page_size。
PartitionPagedKVCacheBinarySearchMinNumPagePerBatch负责计算max_num_pages_per_batch和new_batch_size。
DecodeSplitKVIndptr
cpp
template <typename IdType>
inline auto DecodeSplitKVIndptr(IdType* indptr_h, uint32_t batch_size, uint32_t kv_chunk_size) {
std::vector<IdType> request_indices, kv_tile_indices, o_indptr;
o_indptr.push_back(0);
for (uint32_t batch_idx = 0; batch_idx < batch_size; batch_idx++) {
uint32_t num_chunks_kv = ceil_div(
std::max<uint32_t>(indptr_h[batch_idx + 1] - indptr_h[batch_idx], 1U), kv_chunk_size);
for (uint32_t kv_tile_idx = 0; kv_tile_idx < num_chunks_kv; ++kv_tile_idx) {
request_indices.push_back(batch_idx);
kv_tile_indices.push_back(kv_tile_idx);
}
o_indptr.push_back(o_indptr.back() + num_chunks_kv);
}
std::cout << " request_indices " << VECTOR_TO_STR(request_indices) << std::endl;
std::cout << " kv_tile_indices " << VECTOR_TO_STR(kv_tile_indices) << std::endl;
std::cout << " o_indptr " << VECTOR_TO_STR(o_indptr) << std::endl;
return std::make_tuple(request_indices, kv_tile_indices, o_indptr);
}std::cout输出信息:
request_indices 0, 0, 0, 1, 1, 2, 2, 3, 4, 4, 4, 5, 5, 5, 5, 5, 6, 6, 6, 6
kv_tile_indices 0, 1, 2, 0, 1, 0, 1, 0, 0, 1, 2, 0, 1, 2, 3, 4, 0, 1, 2, 3
o_indptr 0, 3, 5, 7, 8, 11, 16, 20
batch_idx = 0,其占据的page个数为17 = kv_page_indptr1 - kv_page_indptr0。在kv_chunk_size=8的条件下,num_chunks_kv=3,可以划分为3个新的batch。
VECTOR_TO_STR是我用大模型生成的代码,将vector转成string,用于打印。
cpp
#define VECTOR_TO_STR(vec) \
[&]() -> std::string { \
std::string result = "["; \
bool first = true; \
for (const auto& elem : (vec)) { \
if (!first) result += ", "; \
result += std::to_string(elem); \
first = false; \
} \
result += "]"; \
return result; \
}()BatchDecodeWithPagedKVCacheRun
https://gitcode.com/gh_mirrors/fl/flashinfer/blob/main/csrc/batch_decode.cu
cpp
void BatchDecodeWithPagedKVCacheRun(TensorView float_workspace_buffer,
TensorView int_workspace_buffer, Array<int64_t> plan_info_vec,
TensorView q, TensorView paged_k_cache,
TensorView paged_v_cache, TensorView paged_kv_indptr,
TensorView paged_kv_indices, TensorView paged_kv_last_page_len,
TensorView o, Optional<TensorView> maybe_lse,
int64_t kv_layout_code, int64_t window_left,
bool enable_pdl ADDITIONAL_FUNC_PARAMS) {
DISPATCH_context(
DTypeQ, DTypeKV, DTypeO, IdType, HEAD_DIM_QK, HEAD_DIM_VO, POS_ENCODING_MODE,
USE_SLIDING_WINDOW, USE_LOGITS_SOFT_CAP, AttentionVariant, Params, [&] {
paged_kv_t<DTypeKV, IdType> paged_kv(
num_kv_heads, page_size, HEAD_DIM_QK, batch_size, kv_layout,
static_cast<DTypeKV*>(paged_k_cache.data_ptr()),
static_cast<DTypeKV*>(paged_v_cache.data_ptr()), kv_cache_strides,
static_cast<IdType*>(paged_kv_indices.data_ptr()),
static_cast<IdType*>(paged_kv_indptr.data_ptr()),
static_cast<IdType*>(paged_kv_last_page_len.data_ptr()));
Params params;
params.q = static_cast<DTypeQ*>(q.data_ptr());
params.paged_kv = paged_kv;
params.o = static_cast<DTypeO*>(o.data_ptr());
params.lse =
maybe_lse.has_value() ? static_cast<float*>(maybe_lse.value().data_ptr()) : nullptr;
params.padded_batch_size = 0;
params.num_qo_heads = num_qo_heads;
params.q_stride_n = q_stride_n;
params.q_stride_h = q_stride_h;
params.window_left = window_left;
params.request_indices = nullptr;
params.kv_tile_indices = nullptr;
params.o_indptr = nullptr;
params.kv_chunk_size_ptr = nullptr;
params.block_valid_mask = nullptr;
params.partition_kv = false;
ADDITIONAL_PARAMS_SETTER
DTypeO* tmp_v = nullptr;
float* tmp_s = nullptr;
params.request_indices =
GetPtrFromBaseOffset<IdType>(int_buffer, plan_info.request_indices_offset);
params.kv_tile_indices =
GetPtrFromBaseOffset<IdType>(int_buffer, plan_info.kv_tile_indices_offset);
params.o_indptr = GetPtrFromBaseOffset<IdType>(int_buffer, plan_info.o_indptr_offset);
params.kv_chunk_size_ptr =
GetPtrFromBaseOffset<IdType>(int_buffer, plan_info.kv_chunk_size_ptr_offset);
if (plan_info.split_kv) {
tmp_v = GetPtrFromBaseOffset<DTypeO>(float_buffer, plan_info.v_offset);
tmp_s = GetPtrFromBaseOffset<float>(float_buffer, plan_info.s_offset);
if (plan_info.enable_cuda_graph) {
params.block_valid_mask =
GetPtrFromBaseOffset<bool>(int_buffer, plan_info.block_valid_mask_offset);
}
}
params.padded_batch_size = plan_info.padded_batch_size;
cudaError_t status =
flashinfer::BatchDecodeWithPagedKVCacheDispatched<HEAD_DIM_QK, POS_ENCODING_MODE,
AttentionVariant>(params, tmp_v,
tmp_s, enable_pdl,
/*stream=*/stream);
TVM_FFI_ICHECK(status == cudaSuccess)
<< "BatchDecodeWithPagedKVCache failed with error " << cudaGetErrorString(status);
return true;
});
}BatchDecodeWithPagedKVCacheDispatched
https://gitcode.com/gh_mirrors/fl/flashinfer/blob/main/include/flashinfer/attention/decode.cuh
cpp
template <uint32_t HEAD_DIM, PosEncodingMode POS_ENCODING_MODE, typename AttentionVariant,
typename Params>
cudaError_t BatchDecodeWithPagedKVCacheDispatched(Params params, typename Params::DTypeO* tmp_v,
float* tmp_s, bool enable_pdl,
cudaStream_t stream) {
constexpr uint32_t vec_size = std::max(16UL / sizeof(DTypeKV), HEAD_DIM / 32UL);
auto compute_capacity = GetCudaComputeCapability();
constexpr uint32_t bdx = HEAD_DIM / vec_size;
static_assert(bdx <= 32);
DISPATCH_GQA_GROUP_SIZE(num_qo_heads / num_kv_heads, GROUP_SIZE, {
constexpr uint32_t bdy = GROUP_SIZE;
constexpr uint32_t num_threads = std::max(128U, bdx * bdy);
constexpr uint32_t bdz = num_threads / (bdx * bdy);
constexpr uint32_t tile_size_per_bdx = GROUP_SIZE == 1 ? (sizeof(DTypeKV) == 1 ? 2U : 4U) : 1U;
DISPATCH_COMPUTE_CAP_DECODE_NUM_STAGES_SMEM(compute_capacity, NUM_STAGES_SMEM, {
const uint32_t smem_size =
2 * NUM_STAGES_SMEM * tile_size_per_bdx * bdy * bdz * HEAD_DIM * sizeof(DTypeKV) +
std::max(tile_size_per_bdx * num_threads * sizeof(DTypeKV*),
2 * bdy * bdz * sizeof(float));
auto kernel =
BatchDecodeWithPagedKVCacheKernel<POS_ENCODING_MODE, NUM_STAGES_SMEM, tile_size_per_bdx,
vec_size, bdx, bdy, bdz, AttentionVariant, Params>;
FLASHINFER_CUDA_CALL(
cudaFuncSetAttribute(kernel, cudaFuncAttributeMaxDynamicSharedMemorySize, smem_size));
dim3 nblks(padded_batch_size, num_kv_heads);
dim3 nthrs(bdx, bdy, bdz);
std::cout << "padded_batch_size " << padded_batch_size << " num_kv_heads: " << num_kv_heads << std::endl;
std::cout << "bdx y z " << bdx << " " << bdy << " " << bdz << std::endl;
// PDL launch config
cudaLaunchAttribute attribute[1];
cudaLaunchConfig_t config;
if (tmp_v == nullptr) {
} else {
// use partition-kv kernel
params.partition_kv = true;
auto o = params.o;
auto lse = params.lse;
params.o = tmp_v;
params.lse = tmp_s;
if (enable_pdl) {
FLASHINFER_CUDA_CALL(cudaLaunchKernelEx(&config, kernel, params));
} else {
void* args[] = {(void*)¶ms};
FLASHINFER_CUDA_CALL(
cudaLaunchKernel((void*)kernel, nblks, nthrs, args, smem_size, stream));
}
if constexpr (AttentionVariant::use_softmax) {
FLASHINFER_CUDA_CALL(VariableLengthMergeStates(
tmp_v, tmp_s, params.o_indptr, o, lse, params.paged_kv.batch_size, nullptr,
num_qo_heads, HEAD_DIM, enable_pdl, stream));
} else {
FLASHINFER_CUDA_CALL(
VariableLengthAttentionSum(tmp_v, params.o_indptr, o, params.paged_kv.batch_size,
nullptr, num_qo_heads, HEAD_DIM, enable_pdl, stream));
}
}
});
});
return cudaSuccess;
}std::cout输出信息:
padded_batch_size 20 num_kv_heads: 8
bdx y z 16 8 1
vec_size=8。bdy=GROUP_SIZE。nblks的个数= 20 * 8, 每个block中线程数量=16 * 8 * 1。
在一个block内,一共有128个线程,每32线程组成一个wrap。bdx=16,每16个线程为一组,处理一个head。bdx = HEAD_DIM / vec_size。每个线程从q中读取的元素个数为vec_size。
根据deepseek的解释:CUDA 默认按 x 维度优先填充 warp。
同一个warp包含的线程(按warp划分)如下:
warp 0:线性索引 0~31
对应线程坐标:
threadIdx.y = 0 时,threadIdx.x = 0...15(16个线程)
threadIdx.y = 1 时,threadIdx.x = 0...15(16个线程)
即 threadIdx.z 恒为0,包含所有 threadIdx.x = 0...15 且 threadIdx.y = 0,1 的线程。
warp 1:线性索引 32~63
对应线程坐标:
threadIdx.y = 2,3,threadIdx.x = 0...15(各16个线程)。
BatchDecodeWithPagedKVCacheKernel实现的是flash attention v2算法。
VariableLengthMergeStates实现的是Flash-Decoding的规约操作。
BatchDecodeWithPagedKVCacheKernel
BatchDecodeWithPagedKVCacheKernel调用BatchDecodeWithPagedKVCacheDevice。
const uint32_t batch_idx = params.request_indicesbx;
const uint32_t kv_tile_idx = params.kv_tile_indicesbx; 负责处理的kv分片。
const uint32_t kv_head_idx = by; kv头索引
const uint32_t qo_head_idx = kv_head_idx * bdy + ty;
每16个线程内,qo_head_idx指向同一个q。
q_vec.cast_load(q + batch_idx * q_stride_n + qo_head_idx * q_stride_h + tx * vec_size);
每个线程读取vec_size个数据。
BatchDecodeWithPagedKVCacheDevice调用的关键函数:compute_qk,update_local_state。
cpp
template <PosEncodingMode pos_encoding_mode, uint32_t num_stages_smem, uint32_t tile_size_per_bdx,
uint32_t vec_size, uint32_t bdx, uint32_t bdy, uint32_t bdz, typename AttentionVariant,
typename Params>
__global__ void SingleDecodeWithKVCacheKernel(const __grid_constant__ Params params) {
#pragma unroll 2
for (uint32_t iter = 0; iter < ceil_div(kv_chunk_size, tile_size_per_bdx * bdy * bdz); ++iter) {
// compute qk
cp_async::wait_group<2 * num_stages_smem - 1>();
block.sync();
compute_qk<pos_encoding_mode, vec_size, bdx, bdy * tile_size_per_bdx>(
params, variant, /*batch_idx=*/0,
k_smem + (stage_idx * bdz + tz) * bdy * tile_size_per_bdx * head_dim, q_vec, freq,
consumer_kv_idx_base, iter * bdy * tile_size_per_bdx * bdz, kv_chunk_size, qo_head_idx,
kv_head_idx, s, st_local, tx, ty, tz);
block.sync();
// load k
for (uint32_t j = 0; j < tile_size_per_bdx; ++j) {
cp_async::pred_load<vec_bits, PrefetchMode::kPrefetch, SharedMemFillMode::kNoFill>(
k_smem + (((stage_idx * bdz + tz) * bdy + ty) * tile_size_per_bdx + j) * head_dim +
tx * vec_size,
k + (producer_kv_idx_base + (tz * bdy + ty) * tile_size_per_bdx + j) * kv_stride_n +
kv_head_idx * kv_stride_h + tx * vec_size,
producer_kv_idx_base + (tz * bdy + ty) * tile_size_per_bdx + j < chunk_end);
}
cp_async::commit_group();
// update m/d/o state
cp_async::wait_group<2 * num_stages_smem - 1>();
block.sync();
update_local_state<vec_size, bdx, bdy * tile_size_per_bdx>(
v_smem + (stage_idx * bdz + tz) * bdy * tile_size_per_bdx * head_dim, s, stage_idx,
st_local, tx);
block.sync();
// load v
for (uint32_t j = 0; j < tile_size_per_bdx; ++j) {
cp_async::pred_load<vec_bits, PrefetchMode::kPrefetch, SharedMemFillMode::kFillZero>(
v_smem + (((stage_idx * bdz + tz) * bdy + ty) * tile_size_per_bdx + j) * head_dim +
tx * vec_size,
v + (producer_kv_idx_base + (tz * bdy + ty) * tile_size_per_bdx + j) * kv_stride_n +
kv_head_idx * kv_stride_h + tx * vec_size,
producer_kv_idx_base + (tz * bdy + ty) * tile_size_per_bdx + j < chunk_end);
}
cp_async::commit_group();
stage_idx = (stage_idx + 1) % num_stages_smem;
producer_kv_idx_base += tile_size_per_bdx * bdy * bdz;
consumer_kv_idx_base += tile_size_per_bdx * bdy * bdz;
}
cp_async::wait_group<0>();
block.sync();
}流水线拷贝,来自deepseek的解释:
// 预加载阶段 (iter = 0 之前)
commit_group() // K0 预加载
commit_group() // V0 预加载
// 主循环 iter = 0
wait_group<2*num_stages-1>() // 等待 K0,V0 完成
compute_qk() // 使用 K0
commit_group() // K1 加载
update_local_state() // 使用 V0
commit_group() // V1 加载
// 主循环 iter = 1
wait_group<2*num_stages-1>() // 等待 K1,V1 完成
compute_qk() // 使用 K1
commit_group() // K2 加载
update_local_state() // 使用 V1
commit_group() // V2 加载
// ... 继续循环compute_qk
cpp
template <PosEncodingMode pos_encoding_mode, uint32_t vec_size, uint32_t bdx, uint32_t tile_size,
typename AttentionVariant, typename Params, typename T>
__device__ __forceinline__ void compute_qk(
const Params& params, AttentionVariant variant, const uint32_t batch_idx, const T* smem,
const vec_t<float, vec_size>& q_vec, const vec_t<float, vec_size>& freq, uint32_t kv_idx_base,
uint32_t iter_base, uint32_t iter_bound, uint32_t qo_head_idx, uint32_t kv_head_idx, float* s,
state_t<vec_size>& st, const uint32_t tx, const uint32_t ty, const uint32_t tz) {
float m_prev = st.m;
#pragma unroll
for (uint32_t j = 0; j < tile_size; ++j) {
vec_t<float, vec_size> k_vec;
if constexpr (pos_encoding_mode == PosEncodingMode::kRoPELlama) {
// apply rotary embedding for all rows in k matrix of kv-cache
k_vec = vec_apply_llama_rope<vec_size, bdx>(smem + j * bdx * vec_size, freq,
kv_idx_base + tz * tile_size + j);
} else {
// do not apply rotary embedding
k_vec.cast_load(smem + (j * bdx + tx) * vec_size);
}
s[j] = 0.f;
#pragma unroll
for (uint32_t i = 0; i < vec_size; ++i) {
s[j] += q_vec[i] * k_vec[i];
}
#pragma unroll
for (uint32_t offset = bdx / 2; offset > 0; offset /= 2) {
s[j] += math::shfl_xor_sync(s[j], offset);
}
const uint32_t pos = kv_idx_base + tz * tile_size + j;
s[j] = variant.LogitsTransform(params, s[j], batch_idx, /*qo_idx=*/0, /*kv_idx=*/pos,
qo_head_idx, kv_head_idx);
if constexpr (variant.use_softmax) {
s[j] *= variant.sm_scale_log2;
}
bool mask = variant.LogitsMask(params, batch_idx, /*qo_idx=*/0, /*kv_idx=*/pos, qo_head_idx,
kv_head_idx);
s[j] = (iter_base + tz * tile_size + j < iter_bound && mask) ? s[j] : -math::inf;
st.m = max(st.m, s[j]);
}
if constexpr (variant.use_softmax) {
float o_scale = math::ptx_exp2(m_prev - st.m);
st.d *= o_scale;
#pragma unroll
for (uint32_t j = 0; j < tile_size; ++j) {
s[j] = math::ptx_exp2(s[j] - st.m);
st.d += s[j];
}
#pragma unroll
for (uint32_t i = 0; i < vec_size; ++i) {
st.o[i] = st.o[i] * o_scale;
}
}
}shfl_xor_sync:交换一个warp中两个线程之间的寄存器变量,从而实现归约。shfl_xor_sync原语小实验。
经过shfl_xor_sync操作后,每16个线程中sj是相同的值。经过规约,完成一行q和一列k的计算,得到一个值sj: s j = ∑ i d q i k i sj = \sum_{i}^{d}q_{i}k_{i} sj=∑idqiki。
update_local_state
cpp
/*!
* \brief Load v tile from shared memory and update local state
* \tparam vec_size A template integer indicates the vector size
* \tparam bdx A template integer indicates the block size in x dimension
* \tparam tile_size A template integer indicates the tile size per (bdx * bdy) threads.
* \tparam T A template type indicates the input data type
* \param smem A pointer to the start of shared memory
* \param s A float indicates the pre-softmax attention score
* \param kv_shared_offset An array of uint32_t indicates the k/v tiles offset
* in shared memory of different pipeline stages
* \param compute_stage_idx A integer indicates the compute stage index in the pipeline
* \param st The flashattention state to be updated
*/
template <uint32_t vec_size, uint32_t bdx, uint32_t tile_size, typename T>
__device__ __forceinline__ void update_local_state(const T* smem, const float* s,
uint32_t compute_stage_idx,
state_t<vec_size>& st, uint32_t tx) {
#pragma unroll
for (uint32_t j = 0; j < tile_size; ++j) {
vec_t<float, vec_size> v_vec;
v_vec.cast_load(smem + (j * bdx + tx) * vec_size);
#pragma unroll
for (uint32_t i = 0; i < vec_size; ++i) {
st.o[i] = st.o[i] + s[j] * v_vec[i];
}
}
}o的更新,参考flash attention v2算法伪代码。
