此分类用于记录吴恩达深度学习课程的学习笔记。
课程相关信息链接如下:
- 原课程视频链接:双语字幕吴恩达深度学习deeplearning.ai
- github课程资料,含课件与笔记:吴恩达深度学习教学资料
- 课程配套练习(中英)与答案:吴恩达深度学习课后习题与答案
本篇为第五课的第一周内容,1.11到1.12的内容,同时也是本周理论部分的最后一篇。
本周为第五课的第一周内容,与 CV 相对应的,这一课所有内容的中心只有一个:自然语言处理(Natural Language Processing,NLP) 。
应用在深度学习里,它是专门用来进行文本与序列信息建模 的模型和技术,本质上是在全连接网络与统计语言模型基础上的一次"结构化特化",也是人工智能中最贴近人类思维表达方式 的重要研究方向之一。
这一整节课同样涉及大量需要反复消化的内容,横跨机器学习、概率统计、线性代数以及语言学直觉。
语言不像图像那样"直观可见",更多是抽象符号与上下文关系的组合,因此理解门槛反而更高 。
因此,我同样会尽量补足必要的背景知识,尽可能用比喻和实例降低理解难度。
本篇的内容关于双向 RNN 与深层 RNN,是对基础 RNN 结构的一些补充。
1. 双向 RNN(Bidirectional RNN)
在前面对 RNN、GRU 与 LSTM 的讨论中,我们始终默认了一个前提:序列只能沿时间轴单向展开,模型在当前时刻只能利用已经出现的历史信息。
这种设定在一些简单任务中是合理的,但在大量序列理解与标注任务 中,却隐藏着一个结构性限制: 当前时刻的语义或状态,往往同时依赖于过去和未来的上下文信息。
举个课程里的例子:
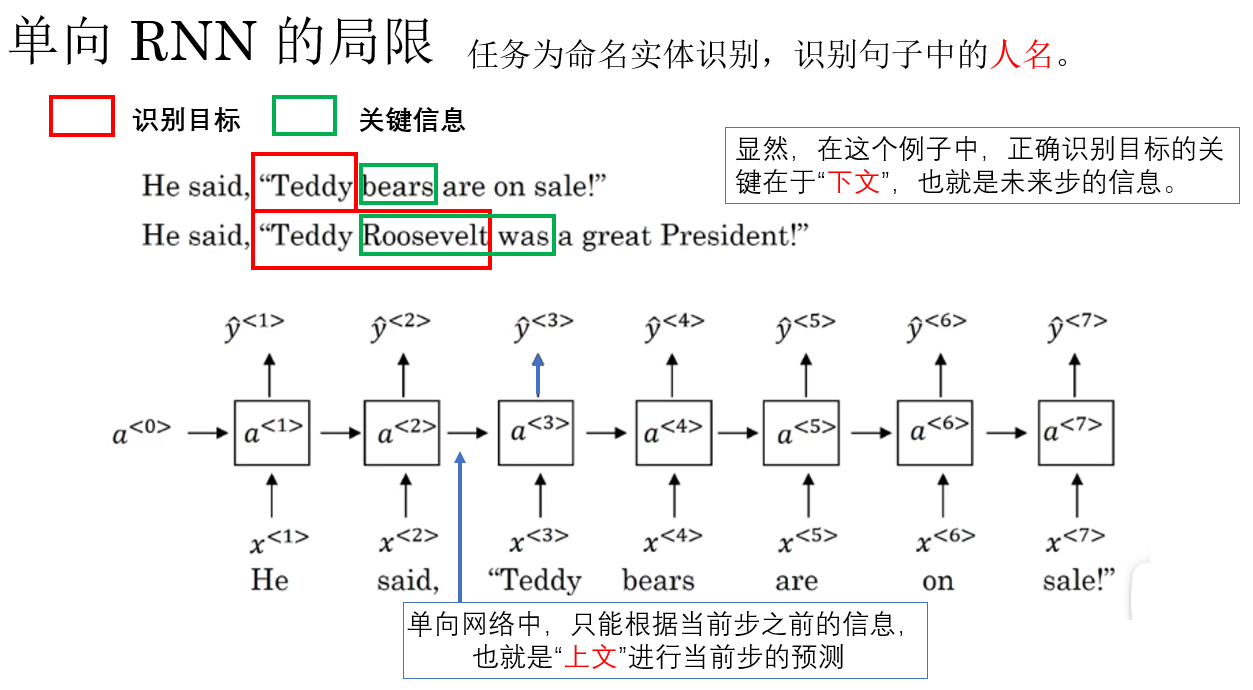
于是,问题出现了:如果未来信息才是判定当前状态的重要依据,该怎么办?
正是在这样的背景下,双向 RNN(Bidirectional Recurrent Neural Networks) 被提出。
早在 1997 年 ,Bidirectional Recurrent Neural Networks 这篇论文中就指出:对于序列标注与整体理解任务,仅依赖过去上下文会造成信息利用上的先天不足,因此有必要在模型结构层面同时建模正向与反向的时间依赖关系。
需要强调的是,双向 RNN 并不是一种新的循环单元设计。
它并不改变 RNN、LSTM 或 GRU 内部的计算形式,而是通过在时间维度上引入前向与后向两条独立的状态传播链路 ,使模型在每一个时间步都能够融合历史与未来的上下文信息。
也正因为这种"结构独立于单元"的特性,双向 RNN 可以自然地与 LSTM、GRU 结合,形成 Bi-LSTM、Bi-GRU,成为提升上下文建模能力的标准配置。
它的实现逻辑并不复杂,这里引用一张比较清晰易懂的传播图:(出处)
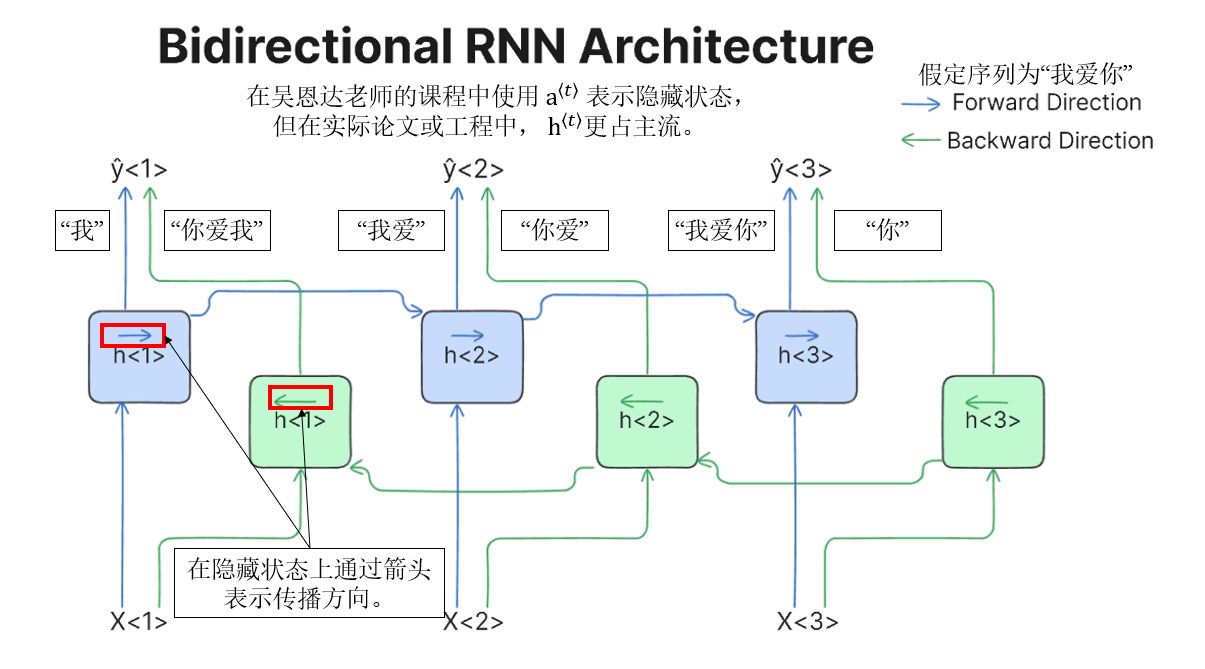
这样,你就会发现,同一序列被 正向(蓝色) 和 反向(绿色) 两条 RNN 同时建模,每个时间步 \(t\) 都能"看到"正向的历史上下文和反向的未来上下文,最终输出 \(\hat y^{\langle t\rangle}\) 由两个方向的信息共同决定。
\h\^{(t)} = \\operatorname{concat}\\!\\left( \\overrightarrow{{h}\^{(t)}}, \\overleftarrow{{h}\^{(t)}} \\right) \\quad \\text{or} \\quad \\overrightarrow{{h}\^{(t)}} + \\overleftarrow{{h}\^{(t)}} \\
在实践中,双向 RNN 更常采用拼接方式 保留来自两个时间方向的完整信息,而逐元素相加则是一种更紧凑、但表达能力受限的折中选择。
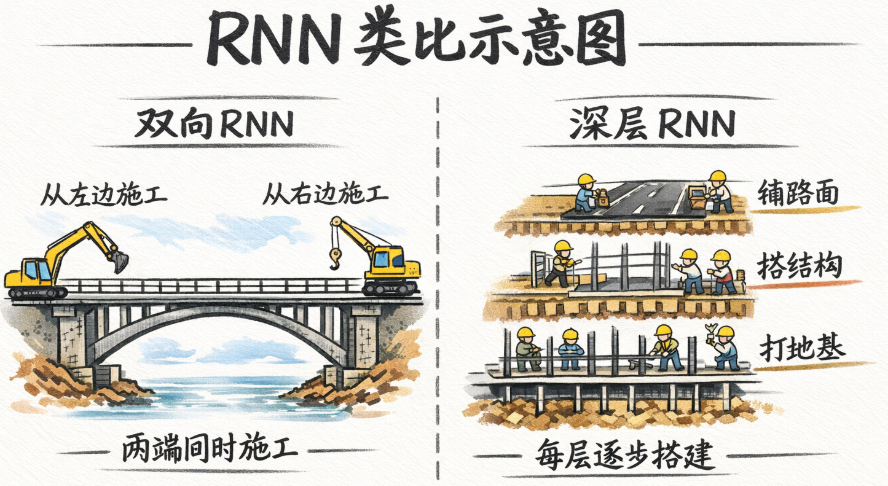
最后,再打个比方:把序列比作一座要建的桥 ,双向 RNN 就像是两队工人从两侧同时施工并不断交流进度,确保精准,但同时,施工队伍翻倍,整体成本也随之上升。
2. 深层 RNN
深层 RNN 的概念同样不难理解。
在最开始引入 循环神经网络 时,我们说明过,默认使用单层 RNN 来进行演示:
在每一个时间步 \(t\),输入 \(x^{(t)}\) 经过一次循环计算,得到对应的隐藏状态 \(a^{(t)}\),并沿时间轴不断传递。
但从模型表达能力的角度来看,这种结构存在限制:每个时间步内部,只进行了一次非线性变换。
这意味着,无论序列本身有多复杂,在"同一时刻"对输入信息的处理深度都是有限的。
到这里,就和之前的全连接、卷积网络相通了:
如果我们希望模型在每一个时间步上,也具备类似深度前馈网络、卷积网络那样的层级表达能力,该怎么办?
答案自然就是:在时间维度之外,再引入层级维度。
在深层 RNN 中,循环结构不再只有一层,而是在同一时间步上堆叠多层 RNN 单元 。
它的传播图是这样的:
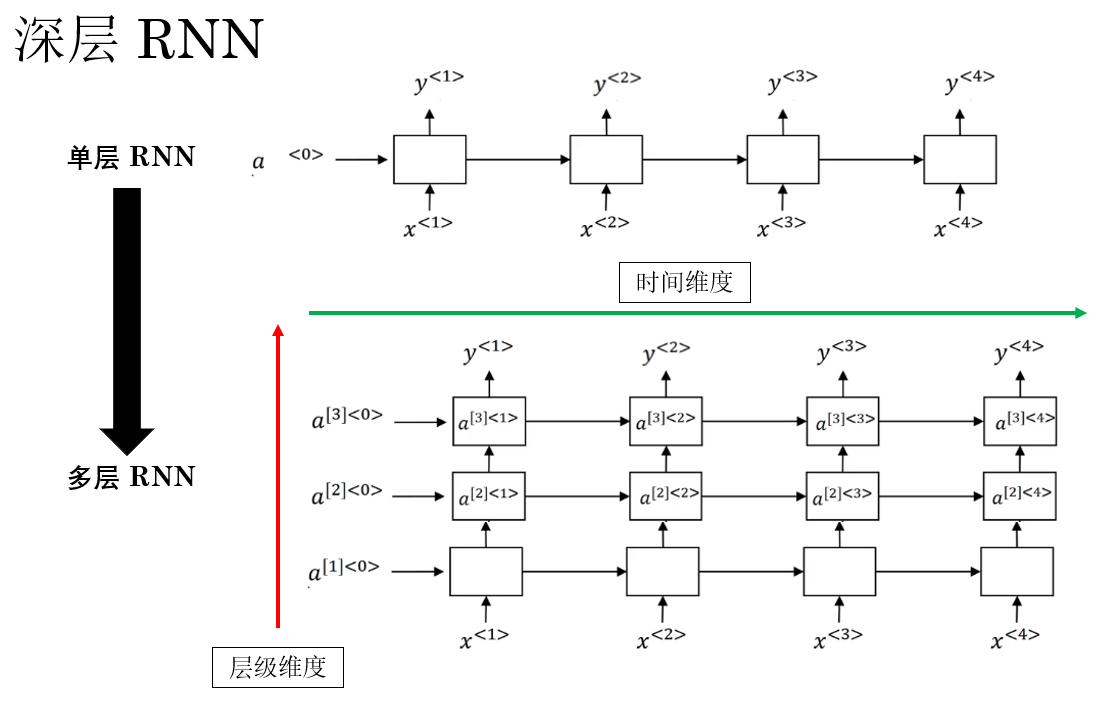
关于深度的逻辑和之前都是相同的,深层 RNN 通过在同一时间步上的堆叠,让模型可以进行更复杂的非线性变换,增强了其表达能力 。但同样也会增加计算成本,带来梯度问题与过拟合风险,这些都是我们的老生常谈了。
于此同时,和双向 RNN 类似,深层结构同样独立于具体的循环单元设计 。 而且在工程实践中,深度、方向性和门控机制往往是可以同时叠加的,例如:
- 多层 Bi-LSTM
- 多层 Bi-GRU
我们把各个组件组合或创新,便形成了深度学习 NLP 中纷繁复杂的诸多模型。
最后,如果继续沿用前面的比喻:
双向 RNN 像是从桥的两端同时施工。
那么 深层 RNN 更像是: 每一个施工点上,不只是铺一层路面,而是一层层打地基、加结构、再铺表层。 这样结构更稳、表达更强,但施工流程更复杂,成本和训练难度也随之上升。
3.总结
| 概念 | 原理 | 比喻 |
|---|---|---|
| 双向 RNN(Bidirectional RNN) | 在时间维度上引入正向和反向两条独立状态链路,每个时间步同时利用过去和未来上下文信息。适用于序列标注与整体理解任务。可以与 RNN/LSTM/GRU 结合,形成 Bi-RNN、Bi-LSTM、Bi-GRU。 | 序列比作桥,两队工人从两端同时施工并交流进度,确保精准,但施工队伍翻倍,成本增加。 |
| 深层 RNN(Deep RNN) | 在同一时间步上堆叠多层 RNN 单元,增加每个时间步内部的非线性表达能力,从而增强模型的表示能力。可与门控机制和双向结构叠加,形成多层 Bi-LSTM、Bi-GRU 等。 | 每个施工点上不是只铺一层路面,而是一层层打地基、加结构、再铺表层,结构更稳、表达更强,但施工流程复杂,成本和训练难度增加。 |