 https://doi.org/10.1016/j.geoderma.2023.116752
https://doi.org/10.1016/j.geoderma.2023.116752
通讯作者:史舟
摘要(ABSTRACT)
可见 - 近红外(vis-NIR)光谱法作为一种高效、可靠的土壤特性快速监测手段,已获得广泛认可。该技术依赖稳健的机器学习模型将土壤光谱信息转化为土壤特性数据。其中,基于记忆的学习(MBL)已成为土壤光谱分析中一种强大的局部建模技术。然而,传统 MBL 算法采用线性模型,忽略了土壤特性与可见 - 近红外光谱之间的非线性关系。因此,我们假设非线性基于记忆的学习(N-MBL)模型能够提升预测效果。本研究利用中国广东省砖红壤光谱库(LRSSL)开发并评估了 N-MBL 算法。该光谱库包含 742 个可见 - 近红外光谱样本及对应的土壤特性数据,包括 pH 值、土壤有机质(SOM)、全氮(TN)、全磷(TP)和全钾(TK)。为进行对比,将偏最小二乘回归(PLSR)、Cubist 算法、随机森林(RF)、支持向量机(SVM)、卷积神经网络(CNN)等常用监督学习方法以及局部模型(MBL)与所提出的 N-MBL 进行了性能比较。结果表明,局部模型的性能总体优于监督学习方法,尤其是在应用于样本量庞大(超过 500 个)的土壤光谱库时。在两种局部模型的对比中,当所选最近邻样本数(k)在 30 至 250 之间变化时,MBL 的模型性能波动比 N-MBL 更大。随着 k 值增加,N-MBL 在土壤有机质(SOM)和全氮(TN)预测中的决定系数(R2)高于 MBL,但在 pH 值和全钾(TK)预测中的性能低于 MBL。此外,N-MBL 在全磷(TP)预测中表现优于 MBL。综上所述,N-MBL 是一种基于可见 - 近红外光谱预测土壤特性的新型局部算法,在提高多种土壤特性预测精度方面具有巨大潜力。
1. 引言(Introduction)
联合国粮食及农业组织(FAO)《2022 年世界粮食安全和营养状况报告》指出,全球受饥饿影响的人数超过 7 亿,这一惊人数字凸显了解决土壤质量和农业生产力问题的重要性(FAO et al., 2022)。传统的土壤特性调查方法包括采集土壤样本并进行实验室分析,该过程成本高昂且耗时(Godwin and Miller, 2003; Doetterl et al., 2013; Xu et al., 2018a; Chen et al., 2022)。这种方法在大规模应用中往往不可行,尤其是在资源有限或时间紧迫的地区。为克服这些挑战,亟需一种快速、准确且经济高效的土壤特性监测方法,以评估管理措施的效果(Silvero et al., 2023)。
可见 - 近红外(vis-NIR)光谱法作为一种替代土壤特性测量的方法,已受到广泛关注。该技术通过分析土壤材料在 350 至 2500 纳米波长范围内的反射电磁波谱来实现(Viscarra Rossel et al., 2006; Stenberg et al., 2010)。与传统化学分析相比,可见 - 近红外光谱法能够快速、无损且可重复地预测土壤特性。这使其成为一种极具吸引力的土壤表征选择,无需耗时且昂贵的实验室流程(Shi et al., 2014; Viscarra Rossel et al., 2016; Chen et al., 2020; Davari et al., 2021; Silvero et al., 2023)。在过去二十年中,可见 - 近红外光谱法在土壤科学中的应用显著增加,其预测土壤特性的精度也随着时间的推移大幅提高(Daniel et al., 2003; Viscarra Rossel and Behrens, 2010; Schirrmann et al., 2013)。目前,土壤可见 - 近红外光谱法已被广泛用于测量土壤颗粒组成、pH 值、土壤有机质(SOM)、全氮(TN)、全磷(TP)、全钾(TK)和土壤无机碳等土壤特性(Chen et al., 2021; Salehi-Varnousfaderani et al., 2022; Di Iorio et al., 2022; Dharumarajan et al., 2023; Sharififar et al., 2023)。
以往研究采用线性和非线性模型通过可见 - 近红外光谱建模来评估土壤特性。偏最小二乘回归(PLSR)是应用最广泛的线性模型(Udelhoven et al., 2003; Shi et al., 2015; Chang et al., 2001)。然而,并非所有可见 - 近红外光谱与土壤特性之间的关系都是线性的(Vohland et al., 2011; Araújo et al., 2014; Derraz et al., 2023)。许多机器学习(ML)模型能够建模非线性关系、处理大规模数据并提取相关特征。因此,机器学习模型已越来越多地应用于处理土壤特性与可见 - 近红外光谱之间的非线性关系,例如 Cubist 算法、随机森林(RF)、支持向量机(SVM)和卷积神经网络(CNN)(Padarian et al., 2019; Nawar and Mouazen, 2019; Ng et al., 2019; Liu et al., 2019; Katuwal et al., 2020; Pham et al., 2021; Hong et al., 2022; Munnaf and Mouazen, 2022)。
除机器学习模型外,局部算法也已广泛应用于大型土壤光谱库的光谱建模(Næs and Isaksson, 1992; Shenk et al., 1997; Nocita et al., 2014; Ng et al., 2022; Gogé et al., 2014; Shi et al., 2015; Javadi et al., 2021)。机器学习模型使用所有土壤样本进行模型训练以进行预测和拟合,而局部模型旨在捕捉土壤可见 - 近红外光谱与特性之间的局部关系,仅选择部分样本进行建模。近年来,基于记忆的学习(MBL)已成为土壤光谱学中一种强大的局部建模技术(Ramirez-Lopez et al., 2013, Ramirez-Lopez et al., 2019)。MBL 利用土壤光谱库中存储的知识对土壤特性进行准确预测。该方法通过建立新土壤样本的光谱模式与光谱库中观察到的相似模式之间的关联,充分利用这一庞大的数据库。通过将未知土壤样本的光谱特征与库中存储的光谱特征进行比较,MBL 能够有效预测和估算多种土壤特性。
MBL 的优势在于其能够捕捉土壤光谱数据中的局部关系和模式。与在不同区域和土壤类型间进行泛化的机器学习模型不同,MBL 专注于特定区域或土壤类型光谱特征的局部关联。这种适应性使 MBL 特别适合在地理分布多样的地区预测土壤信息,因为这些地区的土壤特性可能存在显著差异。多项研究,如 Jaconi et al. (2017)、Hong et al. (2019) 和 Li et al. (2022),已证明 MBL 在基于可见 - 近红外光谱预测土壤特性方面的性能优于其他机器学习模型。
然而,值得注意的是,MBL 中采用的模型是线性模型,即偏最小二乘回归(PLSR)或加权平均偏最小二乘回归(weighted averaged PLSR)。如前所述,MBL 中的线性局部拟合方法可能无法充分捕捉土壤特性与可见 - 近红外光谱之间的非线性关系。因此,这一局限性可能导致预测性能不尽如人意。
为克服这一挑战并进一步增强局部建模过程,以充分利用大型土壤光谱库的效用,一种潜在的解决方案是将 MBL 与非线性模型相结合。我们假设,将非线性模型与 MBL 集成可以显著提高局部建模方法的预测能力。通过融入非线性建模技术的灵活性,这种组合方法能够更好地捕捉土壤特性与可见 - 近红外光谱之间复杂的相互作用,从而实现更准确的预测。这种新的建模策略兼具两者的优势:MBL 方法能够利用土壤光谱库中存储的知识并捕捉局部关系,而非线性模型则通过捕捉数据中存在的非线性复杂性来增强建模过程。
本研究旨在开发非线性基于记忆的学习模型(N-MBL),并通过与成熟模型的比较来评估其性能。具体而言,本研究的目标为:(1)开发 N-MBL 算法;(2)将 N-MBL 与机器学习模型(PLSR、Cubist、RF、SVM 和 CNN)的性能进行比较;(3)将 N-MBL 与传统局部模型(MBL)的性能进行比较;(4)探索 N-MBL 的适用条件。
2. 材料与方法(Methods and materials)
2.1 研究区域(Study area)
广州(北纬 22.5°-24°,东经 113°-114°)位于中国南部,总面积 7434 平方公里(Fig. 1)。该区域地形以丘陵为主,南部为沿海冲积平原。广州属亚热带季风气候,受海洋因素影响显著。该地区年平均降雨量约为 1800 毫米,平均气温约为 21.9 摄氏度。主要土壤类型为砖红壤,在研究区域内广泛分布。这种土壤类型是在炎热潮湿的气候条件下,通过强烈的风化和淋溶过程形成的。
2.2 土壤可见 - 近红外光谱库(Soil vis-NIR spectral library)
本研究采用基于地形、土壤类型和土地利用的分层随机抽样方法选择采样点(Wang et al., 2009)。在野外采样过程中,每个样本通过在 10 米半径范围内采集 5 个独立子样本,收集约 2 千克表层土壤(0-20 厘米)。同时,记录每个采样点的地理坐标和地形信息。最终,从广州研究区域收集了 742 个表层土壤样本。
所有土壤样本经风干后研磨至粒径小于 2 毫米,放入直径 10 厘米、深度 1.5 厘米的培养皿中。使用配备接触探头和 Spectralon 白板参比(Malvern Panalytical Ltd, Malvern, UK)的 ASD FieldSpec 4 可见 - 近红外光谱仪(Malvern Panalytical Ltd, Malvern, UK)获取土壤可见 - 近红外光谱(波长范围 350-2500 纳米)。该光谱仪在 350-1000 纳米波长范围内的光谱分辨率为 3 纳米,在 1000-2500 纳米波长范围内为 6 纳米,对光谱反射率进行拼接校正,最终输出分辨率为 1 纳米的可见 - 近红外光谱。为降低噪声并提高信噪比,每个土壤样本在培养皿内的 3 个位置进行测量,每个位置内部扫描 3 次,光谱分别保存为包含 3 条光谱曲线的文件。将 9 条光谱曲线取平均值,得到用于分析的代表性光谱。为确保测量准确性,每测量 10 个样本,使用反射率为 99% 的 Spectralon 白板对光谱仪进行校准(FAO, 2022; Dor et al., 2023; Dharumarajan et al., 2023)。采用传统土壤分析方法测量土壤 pH 值、土壤有机质(SOM)、全氮(TN)、全磷(TP)和全钾(TK),其分析方法如表 1 所示(Bao, 2000)。
光谱数据和土壤特性数据共同构成了砖红壤光谱库(LRSSL),该库包含 742 个土壤可见 - 近红外光谱、5 项土壤特性(pH 值、SOM、TN、TP 和 TK)以及其他信息(地理坐标和地形)。
表 1 土壤特性及分析方法(Table 1 Soil properties measured and the analytical method)
| 土壤特性(Soil properties) | 分析方法(Method of analysis) |
|---|---|
| pH(水提)(pH (H₂O)) | 电位法,土壤 / 水悬浮液比例为 1:1 |
| 土壤有机质(SOM) | 硫酸 - 重铬酸钾氧化法(H₂SO₄-K₂Cr₂O₇ oxidation method) |
| 全氮(TN) | 硒 - 硫酸铜 - 硫酸消解法 - 蒸馏法(Se-CuSO₄-H₂SO₄ digestion method-distillation) |
| 全磷(TP) | 氢氧化钠 - 钼锑比色法(NaOH-Mo-Sb colorimetric method) |
| 全钾(TK) | 氢氧化钠 - 火焰光度法(NaOH-flame photometric method) |
2.3 土壤光谱预处理(Soil spectral pre-processing)
在对砖红壤光谱库(LRSSL)进行分析时,发现由于未对土壤特性或可见 - 近红外光谱进行分析,库中存在部分零值和缺失数据样本。为解决这些问题,剔除了这些样本,最终保留 723 个样本。图 2(Fig. 2)为 pH 值、SOM、TN、TP 和 TK 的箱线图,为识别异常值提供参考。最终,分别剔除了这 5 项土壤特性中的 15 个、12 个、5 个、9 个和 11 个异常样本。
对于土壤光谱,进行预处理以提高土壤可见 - 近红外光谱的质量。剔除波长范围在 400-2450 纳米之外的土壤光谱,因为这些光谱的信噪比较高,不适合建模。然后,测试了土壤可见 - 近红外反射率和吸光度的性能;此外,采用标准正态变量变换(standard normal variate)、移动平均(moving average)和 Savitzky-Golay(SG)平滑等多种预处理方法进行比较,以确定最佳预处理方法。结果表明,窗口大小为 21、多项式阶数为 2 的一阶导数 SG 平滑处理的预测性能最佳,且光谱分辨率为 1 纳米(Fig. 3)(Savitzky and Golay, 1964)。
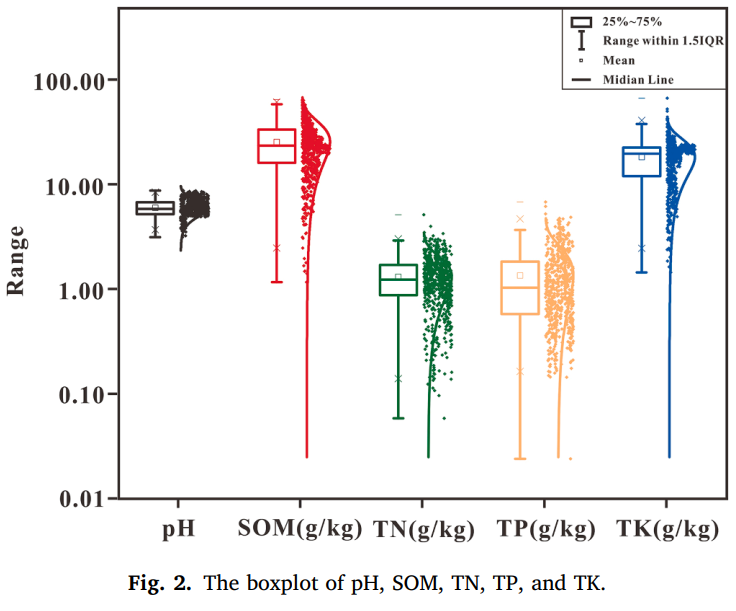
图 2 pH 值、SOM、TN、TP 和 TK 的箱线图(Fig. 2. The boxplot of pH, SOM, TN, TP, and TK.)
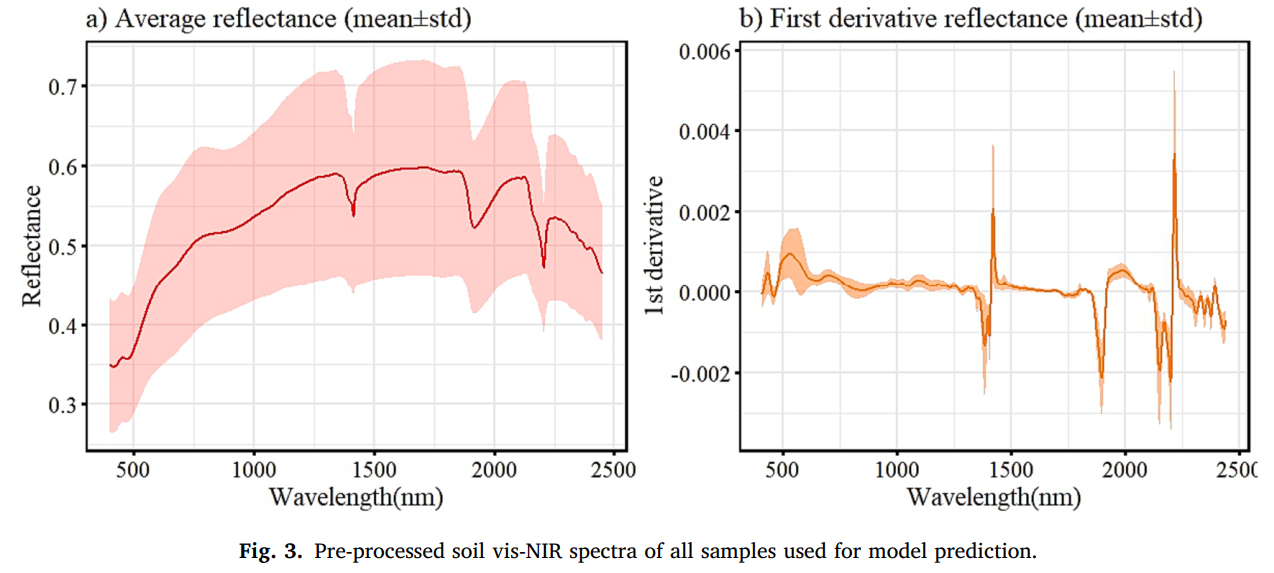
图 3 用于模型预测的所有样本的预处理后土壤可见 - 近红外光谱(Fig. 3. Pre-processed soil vis-NIR spectra of all samples used for model prediction.)a)平均反射率(均值 ± 标准差)(Average reflectance (mean±std));b)一阶导数反射率(均值 ± 标准差)(First derivative reflectance (mean±std))
Kennard-Stone(K-S)算法是一种广泛使用的数据集划分策略,能够确保样本在光谱空间中均匀分布,降低模型过拟合的风险(Kennard and Stone, 1969; Nawar and Mouazen, 2018; Chen et al., 2021)。本研究采用 K-S 算法,将经过一阶导数 SG 平滑处理后的反射光谱对应的砖红壤光谱库(LRSSL)划分为训练集(70%)和测试集(30%)。SG 平滑和 K-S 算法通过 R 4.2.1 软件中的 prospectr 包实现(R core Team, 2022; Stevens and Ramirez-Lopez, 2021)。
2.4 基于区域土壤可见 - 近红外光谱库的光谱建模(Spectral modeling using a regional soil vis-NIR library)
采用 PLSR、Cubist、RF、SVM、CNN、MBL 和 N-MBL 七种模型,基于经过一阶导数 SG 方法预处理、分辨率为 1 纳米的土壤光谱,为每项土壤特性建立一个预测模型。所有模型的详细信息如下:
2.4.1 偏最小二乘回归(Partial least squares regression)
PLSR 是一种常用的定量光谱分析建模方法(Ng et al., 2022)。其原理是通过迭代将预测变量和观测变量投影到新的空间,构建线性回归算法,以获得满意的结果(Wold et al., 2001)。本研究中,PLSR 对光谱数据进行降维处理并保留相关潜变量;通过 5 折交叉验证,将 PLSR 的潜变量数量在 2 至 30 之间以 2 为间隔进行优化。PLSR 通过 R 软件中的 pls 包实现(Liland et al., 2022; R core Team, 2022)。
2.4.2 Cubist 算法(Cubist)
Cubist 是一种基于规则的回归模型,能够将变量划分为多个具有相似特征的分区,并为每个分区建立规则(Quinlan, 1993)。这种建模方法常用于土壤光谱建模(Minasny and McBratney, 2008; Viscarra Rossel et al., 2016)。如果满足分区规则,则采用多元线性模型进行预测。对委员会数量(committee)和邻近样本数(neighbor)等参数进行调整以优化模型,通过 5 折交叉验证,分别在 2 至 50 和 10 至 50 之间对其进行优化。采用 Cubist 算法预测土壤特性,通过 R 4.2.1 软件中的 Cubist 包实现(Kuhn and Quinlan, 2021; R core Team, 2022)。
2.4.3 随机森林(Random Forest)
RF 是一种广泛使用的集成学习模型,通过组合多个决策树来提高预测的准确性和稳健性(Breiman, 2001)。在回归问题中,RF 构建多个决策树集成,并对每个树的预测结果取平均值,得到最终的预测结果。通过设置森林中的树数量(ntree)和每个树节点分裂时考虑的变量数量(mtry)对 RF 模型进行参数化。测试了 ntree 的一系列值(100-1000,间隔为 100)和 mtry 的一系列值(1-20),以优化 RF 模型的性能。RF 算法通过 R 4.2.1 软件中的 randomForest 包实现(Liaw and Wiener, 2002; R core Team, 2022)。
2.4.4 支持向量机(Support vector machine)
SVM 是一种基于统计学习理论的监督式机器学习算法(Vapnik, 1999; Ivanciuc, 2007)。在 SVM 回归中,引入松弛变量(ε)重新定义损失函数;训练数据样本通过利用边界样本,尝试落在 ε 界定的间隔内或接近该间隔。同时,利用损失函数减少误差,以优化预测模型(Moura-Bueno et al., 2019)。本研究中,选择径向基函数(RBF)作为核函数;SVM 通过 R 4.2.1 软件中的 e1071 包实现,通过 5 折交叉验证将 RBF 的 gamma 参数和 ε 参数优化为 1 和 0.01(Meyer et al., 2022; R core Team, 2022)。
2.4.5 卷积神经网络(Convolution neural network)
CNN 是一种前馈神经网络,特别适合处理复杂数据集(LeCun et al., 2015; Ng et al., 2019; Padarian et al., 2019; Gruszczyński and Gruszczyński, 2022)。本研究采用一维(1-D)CNN 模型。为优化 CNN 模型,对多个参数进行调优,包括迭代次数(epochs)、批次大小(batch size)和学习率(learning rate),最终将其优化为 500、20 和 0.0001(Fig. 4)。CNN 分析通过 Python 3.10.7 软件(Python Software Foundation, 2022)中的 keras(Chollet, 2019)和 TensorFlow(Abadi et al., 2019)实现。有关详细信息,请参考相关研究(LeCun et al., 1990; Krizhevsky et al., 2012)。
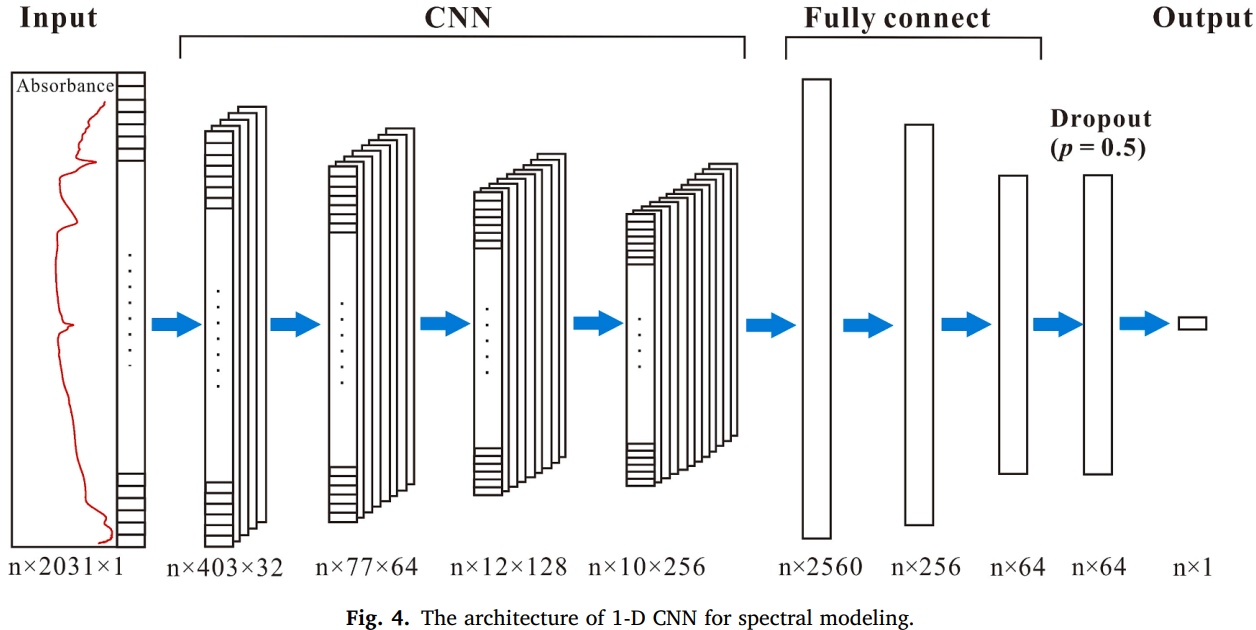
图 4 用于光谱建模的一维 CNN 架构(Fig. 4. The architecture of 1-D CNN for spectral modeling.)
2.4.6 基于记忆的学习(Memory-based learning)
MBL 是一种与案例推理相关的数据驱动方法(Ramirez-Lopez et al., 2013)。通常,MBL 的基本步骤如下:(1)基于样本的光谱特征,创建相似度或相异度矩阵,为每个样本定义最近邻样本(k);(2)从训练集中选择给定数量的 k 个样本,并计算该样本与其邻域样本之间的距离;(3)将所选的 k 个最近邻样本以及通过距离计算得到的权重应用于 PLSR 或加权平均 PLSR 拟合局部模型,距离通过马氏距离(Mahalanobis distance)计算。MBL 的工作流程如 Fig. 4 所示;k 值设置为 30 至 250,步长为 10。建模过程通过 R 4.2.1 软件中的 resemble 包实现(Ramirez-Lopez et al., 2022; R Core Team, 2022)。
2.4.7 非线性基于记忆的学习(Non-linear memory-based learning)
局部 N-MBL 模型采用非线性模型进行局部拟合和预测,以更好地捕捉土壤特性与光谱之间的非线性关系。N-MBL 基于 R 4.2.1 软件中的 MBL 算法,主要步骤如下(Fig. 5):首先,测试线性模型和非线性模型(包括 Cubist、RF、SVM 和 CNN)用于局部建模的性能。结果发现,RF 的性能优于 Cubist 和 SVM,且效率高于 CNN。因此,最终选择 RF 集成到 N-MBL 模型中进行拟合和预测。此外,将基于马氏距离计算的权重纳入非线性预测过程。这些权重在自助采样(bootstrapping)过程中提高了权重较大观测值的重要性,从而优先选择最优局部样本用于土壤特性预测。同时,为比较 MBL 的性能,将参数 k 设置为 30 至 250,步长为 10。N-MBL 模型通过 R 4.2.1 软件中的 ranger 包和 resemble 包实现(R Core Team, 2022; Wright and Ziegler, 2017; Ramirez-Lopez et al., 2022)。对每个测试样本的 num.trees 和 mtry 参数进行优化,其范围分别为 100 至 1000 和 1 至 20;case.weight 通过马氏距离实现。

图 5 N-MBL 和 MBL 模型的工作流程(Fig. 5. The workflow of the N-MBL and MBL model.)
2.5 模型评估(Model evaluation)
选择决定系数(R2)、均方根误差(RMSE)、性能与四分位距比(RPIQ)(Bellon-Maurel et al., 2010)和偏差(bias)作为评估预测模型性能的指标。计算公式如下:
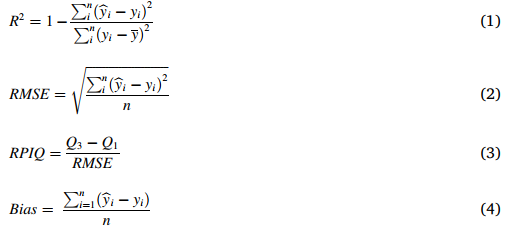
其中,n 为样本数量,yi和yi分别为第 i 个样本的实测值和预测值,yˉ为实测值的平均值。Q3和Q1分别为第三四分位数和第一四分位数,两者之差为四分位距。通常,R2和 RPIQ 越高,RMSE 和偏差越低,模型性能越好。这些指标通过 R 4.2.1 软件计算(R Core Team, 2022)。
3. 结果(Results)
3.1 土壤特性的描述性统计(Descriptive statistics of soil properties)
用于建模的土壤 pH 值、SOM、TN、TK 和 TP 的描述性统计结果如表 2 所示。土壤 pH 值范围为 3.19-8.93,平均值为 6.14,表明该区域土壤呈微酸性。SOM、TN 和 TK 的平均值分别为 26.19 克 / 千克、1.33 克 / 千克和 18.74 克 / 千克。这三项特性的变异系数(CV)在 0.44-0.52 之间。相比之下,TP 的取值范围较广(0.02-6.96 克 / 千克),变异系数(CV)为 0.78,是五项特性中最高的,表明该区域土壤中的 TP 可能受外部因素影响,异质性较强。这五项土壤特性的偏度在 0.23-1.49 之间。
表 2 广州地区五项土壤特性的描述性统计(Table 2 The descriptive statistics of five soil properties in Guangzhou.)
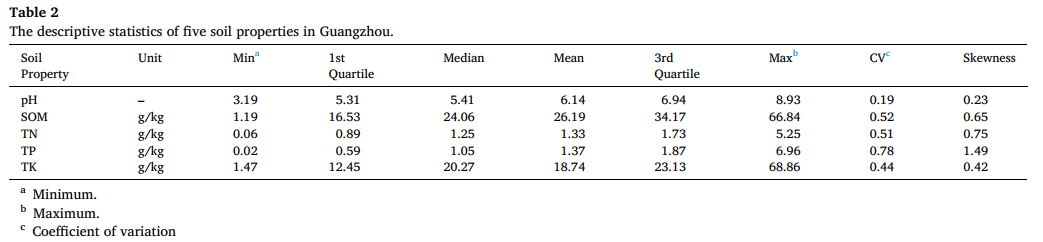
注:a 最小值(Minimum);b 最大值(Maximum);c 变异系数(Coefficient of variation)
3.2 五项土壤特性之间的相关性(The correlation among the five soil properties)
五项土壤特性(pH 值、SOM、TN、TP 和 TK)之间的相关性如 Fig. 6 所示。pH 值与 TK 之间的相关性极小,与其他四项土壤特性的相关系数均低于 0.17。另一方面,SOM、TN 和 TP 之间存在显著的正相关关系。SOM 与 TN 的相关系数为 0.88,SOM 与 TP 的相关系数为 0.52,TN 与 TP 的相关系数为 0.57。
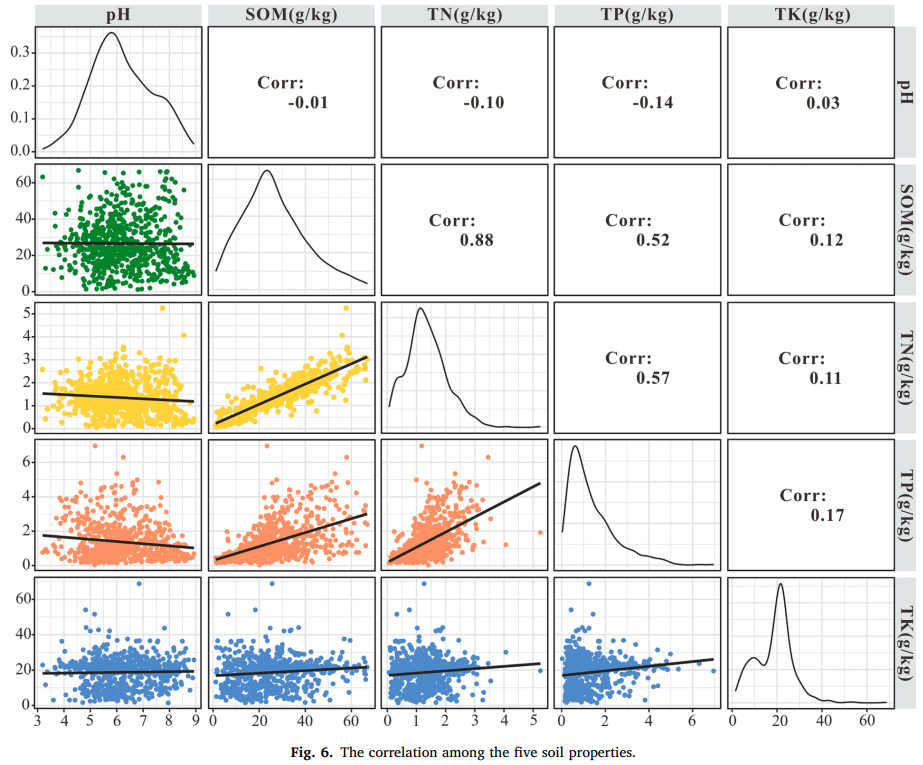
图 6 五项土壤特性之间的相关性(Fig. 6. The correlation among the five soil properties.)
3.3 七种预测模型的精度(The accuracy of the seven prediction models)
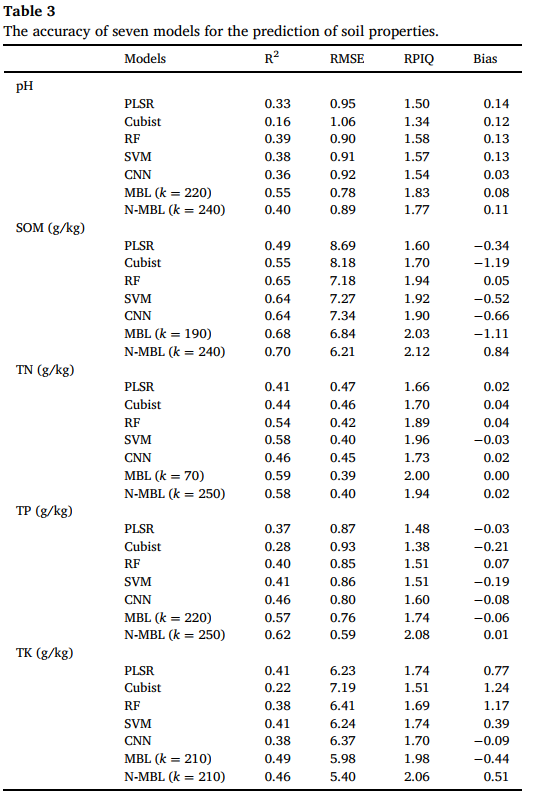
采用经过一阶导数 SG 平滑处理后的土壤可见 - 近红外光谱信息进行建模,五种机器学习模型(PLSR、Cubist、RF、SVM 和 CNN)和两种局部模型(MBL、N-MBL)的预测精度总结如表 3 所示。
3.3.1 机器学习模型的精度(The accuracy of the machine learning models)
本研究采用 PLSR、Cubist、RF、SVM 和 CNN 五种机器学习方法通过可见 - 近红外光谱预测土壤特性。在 pH 值预测中,RF 的性能最佳,R2为 0.39,RPIQ 为 1.58;而 Cubist 模型的性能最差,R2为 0.16。RF 是 SOM 预测的最优机器学习模型,R2为 0.65,RMSE 为 7.18 克 / 千克,RPIQ 为 1.94,偏差为 0.05。在 TN 预测中,SVM 的精度在所有机器学习模型中最高,R2为 0.58,其次是 RF(R2为 0.54);而 PLSR 的 TN 预测性能相对较低(R2为 0.41,RMSE 为 0.47 克 / 千克,RPIQ 为 1.66,偏差为 0.02 克 / 千克)。在 TP 评估中,CNN 的性能显著优于其他机器学习模型,R2和 RPIQ 分别为 0.46 和 1.60,RF 和 SVM 的精度略低于 CNN。在 TK 预测中,PLSR、RF、SVM 和 CNN 的性能相近,R2分别为 0.41、0.38、0.41 和 0.38。根据不同机器学习模型的性能,RF 被确定为最佳模型,并应用于 N-MBL 中。
3.3.2 局部模型的精度:N-MBL 与 MBL(The accuracy of the local model: N-MBL vs MBL)
MBL 和 N-MBL 均为局部模型,其精度受参数 k 的影响,因此本节展示性能最佳的模型。首先,局部模型的性能优于机器学习模型。MBL 在 pH 值和 TK 预测中的精度优于 N-MBL,R2分别为 0.55 和 0.49。相反,N-MBL 在 SOM(R2为 0.70)和 TP(R2为 0.62)估算中的性能显著优于 MBL(参数 k 最优)。N-MBL(R2为 0.58)和 MBL(R2为 0.59)在 TN 预测中的精度相近。此外,MBL 也可采用高斯过程回归(GPR)进行拟合和预测,结果见补充材料(Supplementary material),表明 N-MBL 和基于 PLSR 的 MBL 的精度远高于基于 GPR 的 MBL(Table S1)。
表 3 七种模型对土壤特性的预测精度(Table 3 The accuracy of seven models for the prediction of soil properties.)
4. 讨论(Discussion)
4.1 N-MBL 与机器学习模型的精度比较(Accuracy of N-MBL compared with Machine learning models)
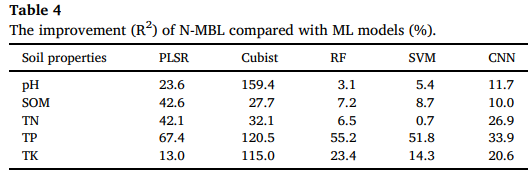
表 4 显示,在土壤特性预测中,N-MBL 模型的性能优于线性模型(PLSR)和非线性模型(Cubist、RF、SVM 和 CNN)。
与 PLSR 相比,N-MBL 模型的性能有所提升:在 TP 预测中,N-MBL 模型的R2比 PLSR 提高了 67.4%,而在 TK 预测中,R2仅提高了 13.0%。Cubist 算法对 pH 值、TP 和 TK 等无直接光谱响应的土壤特性的预测结果较差,R2均低于 0.28(Table 3)。因此,N-MBL 模型对这些特性的预测精度提升最为显著,R2比 Cubist 算法高出 100% 以上。此外,N-MBL 模型在 pH 值、SOM、TN 和 TK 预测中的精度略高于 RF、SVM 和 CNN,但通过对这四项土壤特性预测结果的 t 检验可知,差异并不显著(p>0.05)。这表明 N-MBL、RF、SVM 和 CNN 这四种方法在预测这四项土壤特性时的性能相近。然而,值得注意的是,N-MBL 在 TP 预测中的提升幅度显著大于其他非线性模型。这进一步证明了 N-MBL 模型在预测具有高异质性和间接光谱响应的土壤特性方面的潜力和有效性。
表 4 N-MBL 相较于机器学习模型的R2提升幅度(%)(Table 4 The improvement (R2) of N-MBL compared with ML models (%).)
4.2 MBL 与 N-MBL 模型的性能比较(Performance comparison of MBL and N-MBL models)
MBL 和 N-MBL 均为局部模型,参数 k 的选择在光谱建模中起着至关重要的作用。因此,当邻域样本大小 k 设置为 30 至 250 时,N-MBL 和 MBL 在预测土壤特性时的R2值均随 k 值的增加而变化(Fig. 7)。Ramirez-Lopez et al. (2013) 指出,k 值会影响拟合过程和预测精度。此外,随着 k 值增加,N-MBL 模型的R2逐渐增大并趋于稳定,而 MBL 模型的精度则随 k 值增加出现显著波动。这可能是由于 N-MBL 能够克服多重共线性,更好地反映非线性关系(Derraz et al., 2023)。Xu et al. (2020) 指出,PLSR 在回归分析过程中可能会受到多重共线性的影响。Guo et al. (2021) 指出,PLSR 可能会忽略样本的自相关性和多重共线性,而 RF 已被证明能够解决这些问题。基于这些考虑,随着 k 值增加,N-MBL 的预测结果逐渐趋于稳定且无显著波动,这归因于其能够解释土壤特性与可见 - 近红外光谱之间的非线性关系。
然而,MBL 和 N-MBL 在预测不同土壤特性时的性能可能存在差异。如 Fig. 7a 和 Fig. 7e 所示,当 k 值分别超过 50 和 170 时,MBL 在 pH 值和 TK 预测中的精度优于 N-MBL。土壤 pH 值和 TK 在可见 - 近红外范围内无直接光谱响应(Xu et al., 2018b; Yang et al., 2020; Zhang et al., 2023)。因此,可以推断 MBL 在预测无直接光谱响应的土壤特性方面可能具有优势。相应地,如 Fig. 7b 和 Fig. 7c 所示,当 k 值超过特定阈值(SOM 约为 70,TN 约为 90)时,N-MBL 在 SOM 和 TN 预测中的R2高于 MBL。此外,SOM 和 TN 之间的相关系数高达 0.88,表明这两项土壤特性之间存在强相关性(Fig. 6)。由于 O-H、C-H 和 N-H 的倍频和组合频,可见 - 近红外光谱对 SOM 和 TN 具有直接光谱响应(Stenberg et al., 2010; Mouazen et al., 2010)。因此,N-MBL 提高了 SOM 和 TN 的预测性能,因为它能够更好地捕捉这些特性的直接可见 - 近红外光谱响应。此外,在五项土壤特性中,TP 的异质性最强,变异系数为 0.78(Table 2),且对可见 - 近红外光谱无直接响应(Javadi et al., 2021; Chang et al., 2001)。尽管存在这些挑战,但 N-MBL 在 TP 预测中的性能显著优于用于其他四项土壤特性预测的 MBL。即使考虑少量最近邻样本,N-MBL 的精度也高于 MBL。这表明 N-MBL 在预测具有异质性和间接光谱响应的变量时,能够提取更多特征信息并实现更高的效率。
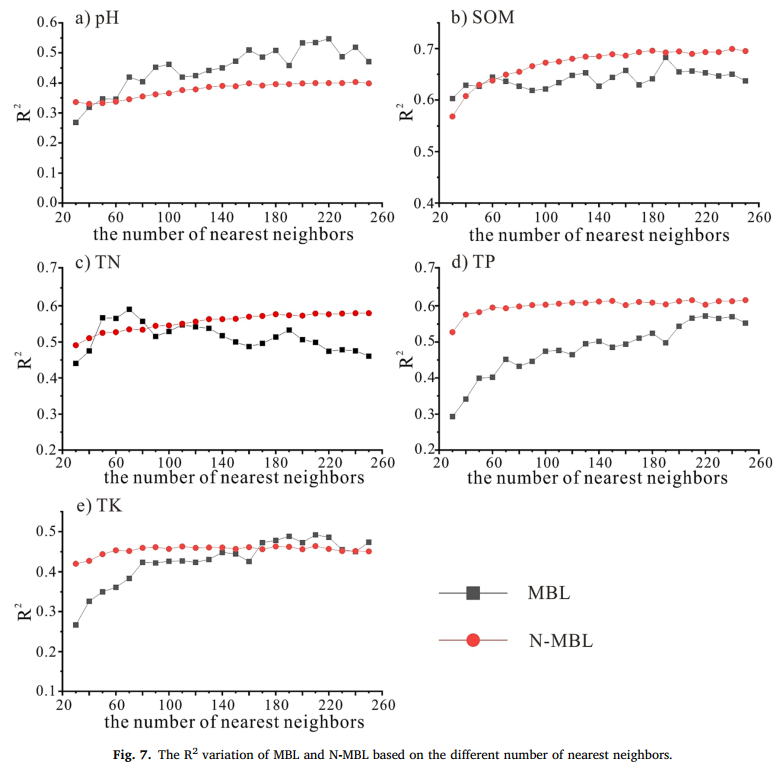
图 7 基于不同最近邻样本数的 MBL 和 N-MBL 的R2变化(Fig.7. The R2 variation of MBL and N-MBL based on the different number of nearest neighbors.)a)pH 值;b)SOM;c)TN;d)TP;e)TK
4.3 局限性与展望(Limitations and perspectives)
首先,本研究仅在区域尺度 上验证了包括 N-MBL 在内的光谱建模方法预测土壤特性的性能。然而,光谱建模的精度受研究区域的具体尺度和土壤样本量的影响(Demattê et al., 2019; Ng et al., 2020)。因此,有必要进一步探索和验证 N-MBL 在田间、国家或大陆等不同尺度上的适用性。
其次,最近邻样本数(k)的选择是局部建模中的关键参数。本研究采用固定的 k 值进行局部建模。然而,最适合的 k 值可能因具体样本集和所预测的土壤特性而异。因此,可以调整动态 k 值用于局部建模策略,以实现最佳预测结果。此外,本研究在选择最近邻样本时仅考虑了光谱空间距离,而考虑地理距离也可能提高局部模型的性能(Tziolas et al., 2019)。因此,结合光谱相似性和地理邻近性可能是提高局部模型精度的一种途径。
第三,机器学习模型可以进行可解释性分析(例如识别特征重要性),但局部模型难以像机器学习模型那样计算哪些特征贡献最大。此外,整个训练数据集都存储在计算机内存中,需要为每个测试样本建立一个模型,这会导致计算成本增加。因此,未来的研究应致力于提高局部模型的可解释性和计算效率。
5. 结论(Conclusions)
线性局部模型可能无法有效捕捉土壤光谱与土壤特性之间的复杂关系,从而导致不理想的结果。为解决这一问题,本研究开发了非线性基于记忆的学习(N-MBL)模型,并将其性能与机器学习模型和局部模型进行了比较。将 N-MBL 模型应用于基于砖红壤光谱库的可见 - 近红外光谱预测土壤 pH 值、SOM、TN、TP 和 TK。主要结论如下:(1)N-MBL 成功预测了土壤特性,且局部模型(MBL 和 N-MBL)的性能优于机器学习模型(PLSR、Cubist、RF、SVM 和 CNN);(2)随着所选最近邻样本数(k)的增加,MBL 的性能出现显著波动,而 N-MBL 的精度逐渐提高并趋于稳定;(3)使用局部算法(MBL 和 N-MBL)进行光谱建模时,选择合适的 k 值至关重要;(4)通过比较 MBL 和 N-MBL 的精度,当 k 值分别超过 70 和 90 时,N-MBL 在 SOM 和 TN 预测中的R2超过 MBL;然而,在 pH 值和 TK 预测中,当 k 值分别高于 50 和 170 时,N-MBL 的R2低于 MBL;在 k 值为 30-250 的范围内,N-MBL 在 TP 预测中表现更佳。总之,N-MBL 作为一种基于土壤光谱库预测土壤特性的潜在局部模型,具有良好的应用前景。
总结:本文与土壤光谱库关联
1. 补充方法创新与演进
文章提出非线性基于记忆的学习(N-MBL)算法,填补了传统局部模型(如 MBL)仅能处理线性关系的空白,为"土壤光谱库建模方法演进" 部分新增了关键案例。
明确线性局部模型→非线性局部模型的优化方向。
2. 提供区域光谱库的模型性能对比数据
基于 742 个样本的砖红壤光谱库(LRSSL),系统对比了 5 种机器学习模型(PLSR、Cubist、RF 等)和 2 种局部模型(MBL、N-MBL)的表现,为不同建模方法在区域光谱库中的适用性提供了实证依据。
提出局部模型在样本量超 500 的光谱库中性能更优的结论,补充了关于 "样本量与模型选择关系" 的关键数据。
3. 细分模型适用场景
明确了不同模型对应的土壤特性预测优势:N-MBL 适合 SOM、TN、TP(尤其是高异质性的 TP),MBL 适合 pH、TK(无直接光谱响应的特性),为模型选择策略提供了具体场景参考。
揭示了参数 k(最近邻样本数)对局部模型的影响规律,为局部模型参数优化内容提供支撑。