
DOI:
https://doi.org/10.1016/j.earscirev.2024.104797
通讯作者:Raphael A. Viscarra Rossel
摘要
结合机器学习(ML)的土壤光谱技术可估算土壤属性,为此已构建大量土壤光谱库(SSLs)。然而,利用这些光谱库建立的通用模型在新的 "未见过" 的局部数据上泛化性能不佳,核心原因是光谱库中的观测数据与局部数据特征不同,导致两者的条件分布和边缘分布存在差异,这给基于光谱的土壤属性建模带来挑战。基于大型 "全球" 土壤光谱库开发的通用模型,能提供关于土壤 - 光谱关系的广泛、系统信息,但要在局部场景中实现精准泛化,必须进行调整以捕捉局部观测数据的位点特异性特征。目前大多数 "局部化" 光谱建模方法结果不一致,对光谱 "局部化" 的理解尚不完善,也缺乏指导后续发展的框架。本文综述了现有的局部化方法,并提出将其重新表述为迁移学习(TL)任务。随后,我们通过基于实例的迁移学习方法(RS-LOCAL 2.0),对来自七大洲 10 个国家的 12 个代表性区域(涵盖田地、农场和地区)的土壤有机碳(SOC)含量进行建模验证。该方法仅需少量局部位点的实例或观测数据(实测土壤属性值及对应光谱),即可从包含 5 万余条记录的大型多样化全球土壤光谱库(GSSL 2.0)中迁移相关信息。研究发现,当局部观测数据量≤30 时,RS-LOCAL 2.0 估算土壤有机碳的准确性和稳定性优于仅使用局部数据的建模方法。借助 GSSL 2.0 中的信息,该方法减少了实验室分析的样本量,提升了土壤光谱技术的成本效益和实用性。我们通过分析局部数据与 "迁移" 数据的数据特征、模型及土壤 - 环境关系,对迁移过程进行了解释,以深入理解该方法的作用机制。从 GSSL 2.0 向局部位点迁移实例,有助于对齐两者的条件分布和边缘分布,使模型中的光谱 - 土壤有机碳关系更稳健。最后,我们提出了未来的研究方向。开发实用且具成本效益的光谱技术,应遵循 "立足全局,适配局部" 的指导原则。通过在迁移学习框架下重新表述局部化问题,我们希望为土壤科学界介绍一系列方法学,为开发新型、创新的土壤光谱建模算法提供启发。
1. 引言
土壤信息对环境保护、粮食安全和可持续发展至关重要(Bouma, 2019)。我们需要不同尺度的土壤数据,以评估和监测土壤属性及土壤健康状况的时间变化(Lehmann et al., 2020)。获取土壤信息在全球范围内都是一项巨大挑战,尤其在发展中国家(Cook et al., 2008)------ 这些地区的土壤和土地退化导致饥饿与营养不良,且土壤分析成本高昂(Viscarra Rossel and Bouma, 2016)。土壤光谱技术可在提供这类信息中发挥核心作用,目前该技术已引起国际社会的广泛关注(Viscarra Rossel et al., 2022)。
反射光谱法是一种强大的土壤分析技术,其原理是利用特定频率的电磁辐射(通常为可见光(vis,400-700 nm)、近红外(NIR,700-2500 nm)或中红外(MIR,2500-25000 nm))与土壤组分的相互作用。这一基础物理过程能揭示土壤组成信息,进而实现土壤属性的估算(Soriano-Disla et al., 2014)。当中红外或近红外能量照射到土壤上时,光线在样品内部散射,导致土壤中分子的化学键振动并吸收部分光线,剩余光线仅以漫反射形式返回检测器,检测器将该响应记录为波长或波数的函数。分子中化学键的基频振动发生在中红外区域,振动类型多样(如对称振动、不对称振动、弯曲振动、剪切振动等)(Griffiths, 2010)。这些基频振动使分子化学键的振动模式从最低基态激发至第一激发态。倍频振动是指能量跃迁从基态到第二或更高振动能级,组合振动则是指在两个或多个振动模式之间的跃迁,近红外光谱仅由倍频振动和组合振动产生。可见光区域的作用过程有所不同,该区域能量更高,光谱由电子激发和电子跃迁产生(Picollo et al., 2019)。
根据传感器的分辨率,单条土壤可见 - 近红外或中红外光谱包含数百至数千个频率。根据光谱范围的不同,这些频率可承载土壤颜色、氧化铁(如赤铁矿、针铁矿)、黏土矿物(如三水铝石、高岭石、伊利石、蒙脱石)、碳酸盐和石膏(若土壤中存在)、有机质类型、(吸附态和游离态)水分含量及颗粒大小等信息(Clark et al., 1990; Ben-Dor and Banin, 1995; Nguyen et al., 1991; Viscarra Rossel and Hicks, 2015)。因此,单次测量获得的土壤光谱即可表征土壤的基本多元组成,而这种组成决定了土壤的属性和功能。该技术具有无损、快速、低成本和高精度的特点,已成为土壤分析不可或缺的工具。
特定波长的吸光度可直接用于推导土壤颜色(Viscarra Rossel et al., 2009)、氧化铁丰度(Viscarra Rossel et al., 2010)、黏土矿物(Viscarra Rossel, 2011)和水分含量(Baumann et al., 2022)。然而,要估算其他土壤属性,需先构建土壤光谱库(SSL),再通过光谱对这些土壤属性进行建模(或校准)。土壤光谱库由实验室实测土壤属性与其对应光谱的数据对组成。如前所述,这些光谱库能捕捉土壤样品的独特组成及与特定土壤属性相关的光谱特征,因此是宝贵的土壤信息库。理想情况下,土壤光谱库的构建应基于应用领域、采样策略、土壤分析方法、光谱范围和所用协议进行设计。但实际上,许多土壤光谱库是利用档案中储存的遗留土壤样品构建的,这些样品来自不同目的的实验,采用的分析方法和光谱协议也各不相同(Nocita et al., 2015)。尽管这种方法构建光谱库成本效益高,且能有效利用存档土壤样品,但在进行光谱校准时,必须仔细考虑分析数据的质量及模型在不同领域的适用性。目前已存在多个针对不同区域、国家、大洲乃至全球的土壤光谱库实例(例如 Shepherd and Walsh, 2002; Viscarra Rossel and Webster, 2012; Stevens et al., 2013; Shi et al., 2015; Viscarra Rossel et al., 2016; Demattê et al., 2019)。
土壤光谱建模的核心目标是建立土壤属性与光谱各频率承载信息之间的关联,进而通过输入新测量的土壤光谱,实现对这些土壤属性的估算。与传统土壤分析方法相比,测量土壤光谱更简便、快速且成本更低。光谱法的另一优势是,只要光谱库中存在对应土壤属性的实测数据,利用同一光谱库即可构建多个土壤属性的估算模型。但该技术并非满足所有土壤测量需求的 "万能钥匙":当土壤的物理、化学和生物学属性源于或与土壤的矿物 - 有机基质相关时,光谱法可较准确地估算这些属性的含量;但若这些组分并非土壤基质的固有属性,则相关性较弱,且最多仅为暂时性相关(Viscarra Rossel et al., 2022)。
早期土壤光谱建模的研究与开发多依赖主成分回归(PCR)(例如 Chang et al., 2001)和偏最小二乘回归(PLSR)(Martens and Næs, 1989)等多元校准方法。当响应 - 光谱关系呈线性时,这些方法稳健且性能良好 ------ 这种情况在土壤光谱库代表小型局部区域时更可能出现。随着更大、更多样化和更复杂的土壤光谱库的开发,以及机器学习(ML)在土壤科学中的应用,研究人员开始测试其他更适合处理大规模、非线性数据集的方法,例如小波分析、随机森林(RF)、支持向量机(SVM)、回归树、高斯金字塔尺度法等(Viscarra Rossel and Lark, 2009; Viscarra Rossel and Behrens, 2010; Behrens et al., 2022; Vohland et al., 2016)。近年来,随着深度神经网络的发展,已有研究测试了这些方法在土壤光谱属性建模中的应用(例如 Liu et al., 2018; Padarian et al., 2019)。尽管深度学习算法需要更多训练数据,结构更复杂,且实现过程计算成本更高,但相较于传统机器学习,它们仍具有一定优势,例如能自动进行预处理和提取有用的特征表征,从而简化建模过程并提升在大规模数据集上的性能(Tsakiridis et al., 2020; Shen and Viscarra Rossel, 2021)。
过去几十年中,关于土壤光谱建模以及土壤属性估算预测函数的校准与验证研究,已证实了土壤光谱库的价值以及土壤光谱技术在精准、低成本估算土壤属性方面的潜力(Li et al., 2022)。但尽管此类研究取得了成功,利用土壤光谱库构建的模型在局部的泛化能力仍然有限(Shen et al., 2022)。土壤属性在不同空间尺度上表现出显著变异性,这是因为它们受到影响土壤形成的局部因素(如气候、生物、地形、母质、土地管理措施和时间)的作用(Jenny, 1941)。因此,基于大型多样化土壤光谱库训练的模型,往往难以捕捉精准局部估算所需的位点特异性土壤变异性(Viscarra Rossel et al., 2022)。
利用整个土壤光谱库构建的通用模型(通常称为 "全球" 模型),能提供关于光谱 - 土壤关系的广泛、系统信息。但要精准捕捉土壤变异性的位点特异性特征,并在局部场景中有效泛化,这些模型需要进行调整和微调。为此,研究人员开发了光谱局部化技术,试图利用大型土壤光谱库的信息更新局部模型。这些技术旨在通过使模型适配单个位点的特异性特征,提升模型性能,实现土壤属性的精准局部估算。目前已有相关研究开发此类技术,但效果参差不齐,研究进展缓慢但仍在持续推进(详见第 2 节)。
光谱模型的局部化问题可通过迁移学习(TL)解决。迁移学习是一类数学技术,其核心是利用一个源域的信息,提升另一个相关目标域(或局部域)的性能。迁移学习的灵感源于人类的学习能力 ------ 即利用已有知识更快、更有效地解决新问题,而非从零开始。其目标是将源域中有用的相关信息迁移到局部域,适用于局部域数据稀缺或不可得、或需要快速估算的场景。因此,迁移学习与机器学习和人工智能(AI)相结合,为土壤光谱建模提供了直观的框架,也为未来实用、可部署的土壤光谱技术的研究与开发提供了强大的组合工具。
基于此,本文的研究目标为:
阐述土壤光谱建模的局部化问题及现有局部化方法;说明迁移学习如何为明确描述该问题及开发创新性研究和解决方案提供框架;验证迁移学习算法如何将大型全球土壤光谱库的有用信息迁移到全球七大洲 10 个国家及罗斯属地的 12 个局部位点;深入分析迁移学习算法的结果,从统计和科学角度深入理解迁移过程;提出未来的研究方向。
2. 光谱建模的局部化
目前已构建了多个国家、大洲乃至全球尺度的大型土壤光谱库,用于估算多种土壤属性(Viscarra Rossel et al., 2016; Stevens et al., 2013; Demattê et al., 2019; Shi et al., 2015; Viscarra Rossel and Webster, 2012)。通常,土壤属性(如土壤有机碳(SOC))与光谱之间存在良好的统计关系(Viscarra Rossel and Behrens, 2010)。但这些经验模型存在差异,当利用大型土壤光谱库的全部数据构建 "全球" 模型时,往往无法准确捕捉位点(如农场中的某块田地)土壤属性的局部特征,尤其是在使用偏最小二乘回归(PLSR)等线性多元方法时。
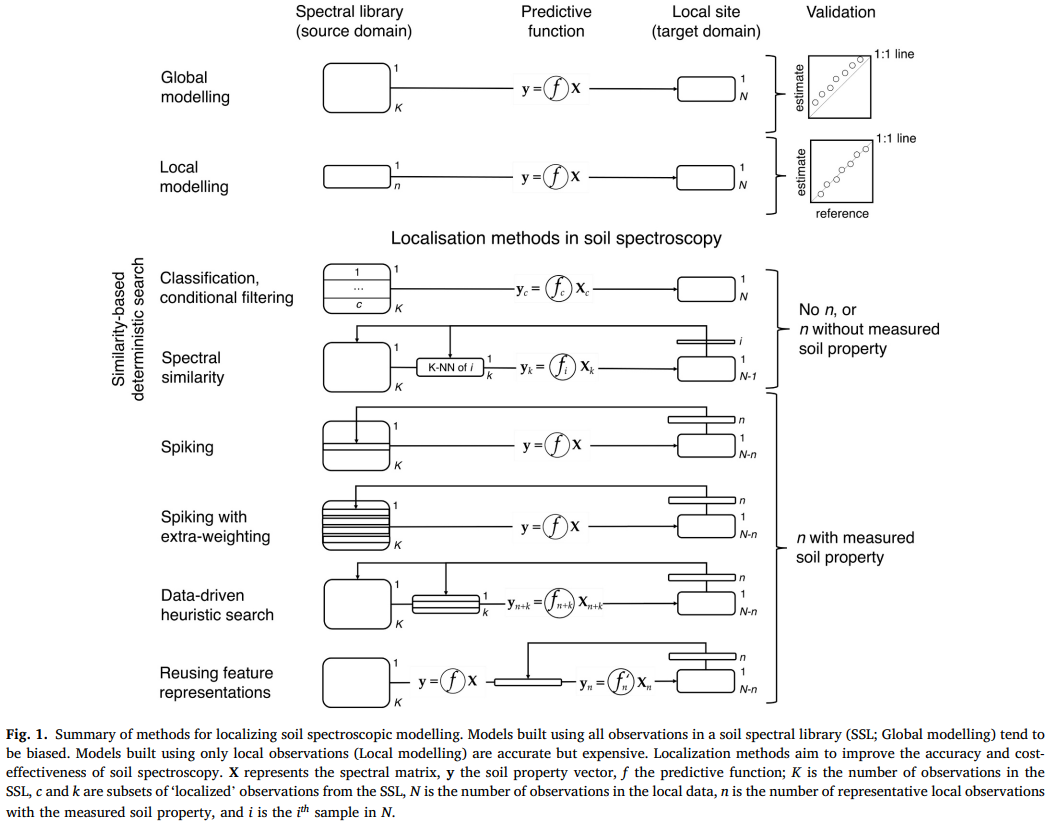
图1。土壤光谱建模局部化方法综述。利用土壤光谱库中的所有观测数据建立的模型(SSL;全局建模)往往存在偏差。仅使用局部观测建立的模型(局部建模)是准确的,但代价昂贵。定位方法的目的是提高土壤光谱的准确性和成本效益。X为谱矩阵,y为土壤性质向量,f为预测函数;K是SSL中观测值的个数,c和K是来自SSL的"局部"观测值的子集,N是局部数据中的观测值个数,N是具有测量土壤性质的代表性局部观测值的个数,i是N中的第i个样本。
非线性方法和机器学习算法(Viscarra Rossel and Behrens, 2010; Shen and Viscarra Rossel, 2021)已助力利用大型土壤光谱库进行国家或更大尺度的分析与解释,例如大洲尺度的数字土壤制图(Viscarra Rossel et al., 2014, 2019)。但目前已明确的是,即使考虑了数据中的非线性(例如通过划分数据集),"全球" 模型在局部(如田地或农场的光谱数据)的泛化性能仍不佳(图 1)。其原因可能包括土壤组成复杂以及有机 - 矿物基质的多样性(Stenberg et al., 2010)------ 这一点在土壤有机碳建模中尤为重要,因为全球许多地区的土壤有机碳浓度通常较低(Köchy et al., 2015)。通常,"全球" 模型的变异性越大,平均预测误差也会随之增加(例如 Sankey et al., 2008; Guerrero et al., 2016; Lobsey et al., 2017; Shen et al., 2022)。局部模型的预测效果较好(图 1),但土壤分析成本更高且效率低下,因为局部建模未利用大型多样化土壤光谱库中的信息。
已有多种方法被提出,以更好地利用大型土壤光谱库进行土壤属性的局部预测。大多数方法旨在减少、最小化甚至无需传统土壤分析,并最大化局部位点光谱估算的整体准确性。目前的局部化方法(图 1)基于以下一种或多种思路:对土壤光谱库进行分类以约束建模过程、数据增强、基于光谱或样品相似性的确定性局部搜索算法、数据驱动的随机搜索方法,或重用转换后的光谱特征(即表征)。第 2 节将综述土壤光谱学中的局部化方法,第 3 节将在迁移学习框架下描述这一挑战。
2.1 基于相似性的确定性方法
基于相似性的方法试图将大型土壤光谱库划分为更小的组,使土壤属性与光谱之间的关系可通过线性模型描述。这类方法均采用确定性相似性方法,且并非所有方法都需要实测土壤属性(图 1)。
利用大型多样化土壤光谱库最直观的方式,是将其分类为更小、更均一的子集,每个子集包含具有相似特征的土壤样品。这样,子集内的变异性小于土壤光谱库的整体变异性。可利用辅助信息约束土壤光谱库 ------ 这些辅助信息有助于表征土壤发生学背景以及土壤属性与光谱之间的关系,例如土壤分类、地理或土地利用信息(例如 Sankey et al., 2008; Vasques et al., 2010; Xu et al., 2016; Moura-Bueno et al., 2020)。随后,可利用每个子集的数据开发光谱模型(图 1)。在局部位点估算土壤属性时,选择最能捕捉局部条件特征的模型即可。尽管此类分类可能得到更小的光谱库,但它们未必能捕捉局部估算(如单个田地数据)所需的光谱 - 响应关系。
更复杂的方法包括 "记忆" 训练数据以寻找相似性,或对光谱进行数据驱动分类,例如基于记忆的学习(MBL)、局部回归(例如 Rabenarivo et al., 2013)、基于光谱的学习器(SBL)(Ramirez-Lopez et al., 2013)和 CUBIST 算法(例如 Viscarra Rossel and Webster, 2012)。
近年来最常用的基于相似性的局部搜索方法之一是基于记忆的学习(MBL,又称 k 近邻法)。基于记忆的学习方法针对局部数据集中的每个观测值,从土壤光谱库中提取光谱相似的样品(例如利用马氏距离),利用所选近邻样品构建特定校准模型,并对未知局部数据进行预测,从而实现位点特异性的局部校准(图 1)。LOCAL 算法(Shenk et al., 1997)、局部加权回归(LWR)算法(Naes et al., 1990; Gupta et al., 2018)及其变体均属于基于记忆的学习方法实例。在局部加权回归中,根据土壤光谱库与未知样品之间的光谱相似性,对所选校准样品进行加权。在基于光谱的学习器(SBL)中,利用主成分空间中计算的距离度量,从土壤光谱库中选择近邻样品。光谱建模的训练数据集包含所选近邻样品以及与未知样品的距离矩阵。Tsakiridis et al. (2020) 利用基于光谱的学习器(SBL)从大洲尺度土壤光谱库中选择近邻样品,并利用其预测误差校正测试集中的土壤属性估算结果。该方法能有效处理大型复杂数据集中的非线性关系,因为在近邻范围内,这些关系可通过简单线性模型较好地描述(Ramirez-Lopez et al., 2013)。但对于超大型土壤光谱库,该方法计算成本较高,因为每次新预测都需要计算其与光谱库中每条光谱的相似性。CUBIST 算法是一种基于树的方法,在每个叶节点生成带线性模型的规则(Quinlan, 1992)。这些规则用于对光谱进行分类,通过对新观测值分类并应用相应模型,实现对新观测值的预测。与其他回归树方法类似,该算法可整合其他辅助数据生成规则集。已有大量文献报道了 CUBIST 算法的应用,证实其能生成准确且可解释的模型(例如 Viscarra Rossel and Webster (2012))。
2.2 Spike 法与加权 Spike 法
简单 Spike 法是在建模前,利用少量局部观测值(响应变量及其光谱)扩充大型土壤光谱库(图 1)。该方法的效果参差不齐:部分研究表明,与仅利用土壤光谱库构建的全球模型相比,该方法能更准确(偏差更小)地估算土壤属性;但也有研究报道其改进效果甚微或无改进(例如 Brown, 2007; Sankey et al., 2008; Viscarra Rossel et al., 2009; Guerrero et al., 2010; Wetterlind and Stenberg, 2010; Gogé et al., 2014; Barthès et al., 2020)。Guerrero et al. (2014) 提出,可通过多次复制局部样品以扩充土壤光谱库,从而改进 Spike 法(图 1)。他们将这种方法称为加权 Spike 法,并认为其优于简单 Spike 法(尤其在土壤光谱库较大时),因为该方法能提升局部数据在模型中的影响力。简单 Spike 法和加权 Spike 法均会增加校准集的规模(图 1)。Barthès et al. (2020) 研究表明,在估算土壤无机碳时,加权 Spike 法比简单 Spike 法更能提升模型准确性。这些方法的效果可能与土壤光谱库的规模和多样性,以及土壤光谱库、Spike 子集与局部估算位点之间的相似程度呈负相关(Guerrero et al., 2016)。当土壤光谱库与局部数据的分布差异过大(即数据和模型并非完全相关)时,这些方法的效果会下降甚至失效。例如,在 Seidel et al. (2019) 的研究中,土壤光谱库来自德国全国,局部数据来自某块农田,Spike 子集包含≤30 个局部观测值,此时 Spike 法的准确性低于局部建模。
2.3 数据驱动的启发式搜索
Lobsey et al. (2017) 开发了一种数据驱动的启发式搜索方法 RS-LOCAL。该方法利用少量局部观测值(即实测土壤属性和光谱的实例),从现有土壤光谱库中选择数据子集用于建模(图 1)。其核心是采用无放回重复简单随机重采样策略,从土壤光谱库中抽取观测值。RS-LOCAL 不假设土壤光谱库中响应变量与光谱之间存在特定关系(例如不假设线性关系),而是认为这些关系具有位点特异性。仅选择那些在局部数据上表现良好的土壤光谱库实例。因此,该方法会过滤掉那些添加到线性模型后会持续增加局部预测不准确性的数据 ------ 这些数据与局部光谱 - 响应关系不一致,可能源于土壤光谱库中存在错误光谱、不同光谱仪的测量结果,或不准确的分析测量数据。研究表明,仅需从局部位点选择少量优质样品,即可利用该方法开发稳健的可见 - 近红外和中红外局部化模型(Shen et al., 2022; Lobsey et al., 2017; Baumann et al., 2021; Helfenstein et al., 2021)。Lobsey et al. (2017) 发现,RS-LOCAL 的性能优于 Spike 法和基于记忆的学习(MBL)等其他方法。在 Shen et al. (2022) 的研究中,我们开发了 RS-LOCAL 的改进版本(RS-LOCAL 2.0),该版本引入了并行化技术,且部分算法通过 C++ 实现,计算效率更高。
2.4 表征重用
如前所述,在土壤光谱建模中,表征是指将输入光谱转换为更具信息性和紧凑性的形式,以促进局部化和建模过程(图 1)。根据问题的不同,可通过多种技术获得表征(例如降维、特征提取、深度神经网络)。
最常见的实例包括人工神经网络的特征提取或微调 ------ 即利用现有预训练模型,在新数据上进行更新。近期研究探索了重用基于大洲和全球土壤光谱库构建的大规模卷积神经网络(CNNs)中学习到的表征,以提升土壤属性的局部估算准确性(Liu et al., 2018; Padarian et al., 2019; Shen et al., 2022)。该方法的核心思路是,卷积神经网络的初始层学习通用表征,而后续层学习任务特异性表征(Zeiler and Fergus, 2014; Yosinski et al., 2014)。从大规模数据集学习到的这些通用表征,可重用以提升局部建模的准确性。因此,实施该方法时,需固定大规模卷积神经网络的初始层,并利用局部数据重新训练剩余层。在将光谱模型从大洲尺度局部化到国家尺度时,表征重用方法表现良好(Padarian et al., 2019)。但在局部估算中的性能则参差不齐(Shen et al., 2022)。需要进一步研究以提升该方法在局部建模中的稳健性,例如通过增强或仅选择最相关的表征。表征也可在其他模型中重用:Ng et al. (2022) 通过在区域土壤光谱库上训练偏最小二乘回归(PLSR)提取表征,并将其载荷重用于局部光谱。与局部建模相比,该方法并未持续提升估算效果。
2.5 混合方法
也可组合上述技术,从大型土壤光谱库中提取有用信息。Wetterlind and Stenberg (2010) 结合光谱近邻法与国家土壤光谱库的 Spike 法,提升了四个不同农场的黏土和土壤有机碳(SOC)局部估算准确性。Shi et al. (2015) 提出结合光谱相似性和地理约束,对土壤有机碳(SOC)进行建模和局部估算。他们发现,当土壤光谱库限定于未知样品的地理起源区域时,估算准确性会提升。GLOBAL-LOCAL 算法整合了基于距离的光谱相似性和启发式搜索方法(St. Luce et al., 2022)。该算法利用光谱主成分的马氏距离,生成包含代表性局部观测值近邻样品的土壤光谱库子集,并在代表性局部数据集上评估偏最小二乘回归(PLSR)模型,以选择性能最佳的模型。该方法已在两个相对均一的数据集上进行了测试,仍需进一步验证。在之前的研究中(Shen et al., 2022),我们将表征重用与 RS-LOCAL 2.0 的启发式搜索相结合:在全球土壤光谱库上训练卷积神经网络(CNN),并在 RS-LOCAL 2.0 选择的数据上对卷积神经网络(CNN)进行部分重新训练。但研究发现,将重用表征与 RS-LOCAL 2.0 结合,并未在所有测试的局部位点上持续提升土壤有机碳(SOC)的估算效果。
3. 迁移学习
迁移学习的应用类似于将从一次经验中所学的知识应用到不同但相关的场景中,从而使 "学习" 过程更快、更廉价、更轻松,或兼具这些优点。当训练模型的数据稀缺、模型可从通用领域信息中获益以捕捉与新场景相关的重要模式和特征,或模型训练需要快速、准确且能适应不断变化的需求和数据分布时,迁移学习具有显著优势。迁移学习提供了一个极具吸引力的框架和一套方法学,可应用于科学、工程和机器学习的多个领域。
迁移学习并非新概念。20 世纪 70 年代已有研究报道将迁移学习用于神经网络模式识别(Bozinovski, 2020),且在 80 年代和 90 年代持续开展相关研究(例如 Pratt et al., 1991)。此后,迁移学习受到越来越多的关注,并出现了多种不同名称和相关方法,如 "知识迁移""归纳迁移""元学习" 和 "多任务学习"。2005 年,美国国防部高级研究计划局(DARPA)将迁移学习定义为 "系统识别并应用先前任务中所学知识和技能解决新任务的能力"(Pan and Yang, 2010)。
迁移学习的发展和应用,源于传统机器学习的若干局限性,包括需要大量数据训练模型、训练过程计算成本高、"全球" 模型在 "未见过" 的局部数据上泛化性能差,以及数据集之间存在分布不匹配等问题。信息通信技术、图形处理器(GPUs)、云计算的进步,以及人工智能(AI)和机器学习(ML)的飞速发展,也推动了迁移学习的发展。迁移学习仍是一个活跃且充满活力的研究领域,已有多篇文献报道了该技术的进展及其应用(例如 Pan and Yang, 2010; Weiss et al., 2016; Zhuang et al., 2020; Niu et al., 2020)。
3.1 土壤光谱建模中迁移学习的定义
要理解迁移学习,需先介绍相关术语、定义和符号。为增强其与土壤光谱建模的相关性,我们改编了不同文献中的术语、定义和符号(例如 Pan and Yang, 2010; Weiss et al., 2016; Zhuang et al., 2020; Niu et al., 2020)。
光谱域 F 定义为包含特征(或光谱)空间 X 和土壤属性空间 Y。X 包含矩阵 X 中的全部光谱 ------ 该矩阵有 m 个观测值、n 个特征(或特定频率的光谱强度),且具有边缘概率分布 P(X)。X 以向量形式存储光谱 x,其中 x={x1,...,xn}∈X,x1,...,xn 是与特定观测值相关的光谱强度。Y 包含矩阵 Y 中的土壤属性 ------ 该矩阵有 m 个观测值和 p 个土壤属性,且具有条件分布 P(Y∣X)。因此,Y 以向量形式存储土壤属性 y,其中 y={y1,y2,...,yp}∈Y,y1,...,yp 是与特定观测值相关的土壤属性值。
对于特定的 y,其任务 T={X,y,f(⋅)} 包含训练数据 X(注:本文中训练单一土壤属性,如土壤有机碳(SOC))和预测函数 f(⋅)------ 该函数未知,但可从训练数据中 "学习" 得到。f(⋅) 可以是统计或机器学习模型(例如偏最小二乘回归(PLSR)、CUBIST),也可以是深度神经网络。若为后者,则称为深度迁移学习(DTL)(Tan et al., 2018)。任务也可通过概率形式表示(Weiss et al., 2016),即 T={X,y,P(y∣X)},其中 P(y∣X) 是给定光谱下土壤属性的条件概率分布。
因此,给定源光谱域 Fs 及其对应的学习任务 Ts,以及目标(或局部)光谱域 Fl 及其学习任务 Tl,迁移学习的目标是利用从 Fs 和 Ts 中获得的相关有用信息,改进局部预测函数 fl(⋅)。通常,Fs≫Fl,且根据定义,源光谱域与局部光谱域、源任务与局部任务是不同的(即 Fs≠Fl 且 Ts≠Tl),但具有一定相关性。由此产生四种可能的迁移学习场景(Pan and Yang, 2010; Weiss et al., 2016):
- 源光谱空间与局部光谱空间不同(即 Xs≠Xl)。例如,源光谱为某一类型(如中红外(MIR)),而局部光谱为另一类型(如可见 - 近红外(vis--NIR))。
- 源光谱与局部光谱的边缘分布不同(即 P(Xs)≠P(Xl))。例如,源光谱和局部光谱类型相同,但由不同类型的光谱仪测量。此时,光谱类型相同且共享同一特征空间(即 Xl=Xs),但光谱强度不同。这种场景通常称为域自适应(例如 Pan et al., 2011)。
- 源土壤属性空间与局部土壤属性空间不同(即 Ys≠Yl)。例如,源光谱域中的土壤属性为土壤有机碳(SOC)含量,而局部光谱域中的土壤属性为土壤有机质(SOM)含量或其替代指标(如土壤颜色)。
- 源土壤属性与局部土壤属性的条件分布不同(即 P(Ys∣Xs)≠P(Yl∣Xl))。例如,源数据和局部数据中的土壤属性采用不同方法、在不同实验室、由不同操作人员测量。此时,由于分析流程的差异,源域和局部域的条件分布可能不同。
在这四种场景中,场景 2 和场景 4 在土壤光谱迁移学习中可能最具实用性。
3.2 土壤光谱建模中迁移学习的分类
文献中用于分类不同迁移学习场景和解决方案的术语和定义并不统一,这可能源于该领域的研究热度以及概念、算法和应用的快速发展(例如 Weiss et al., 2016; Niu et al., 2020; Zhuang et al., 2020)。
Pan and Yang (2010) 根据源域与目标(局部)域的相似性,以及实测响应变量值(或机器学习文献中称为 "标签")的可获得性,将迁移学习分为三类:"归纳式""直推式" 和 "无监督式" 迁移学习(下文将详细描述)。Weiss et al. (2016) 采用了更广泛的分类方式,不考虑实测响应数据的可获得性,仅根据域之间的相似性将迁移学习分为 "同构" 和 "异构" 迁移学习。当源域和目标域的变量空间相似或密切相关(即 Xs=Xl 且 Ys=Yl)时,称为同构迁移学习;当变量空间不相似(即 Xs≠Xl 或 Ys≠Yl)时,称为异构迁移学习。Zhuang et al. (2020) 综述了同构迁移学习,Day and Khoshgoftaar (2017) 综述了异构迁移学习及用于此类跨域学习的方法学。
本文借鉴了上述分类方法,提出了与土壤光谱建模相关的分类框架(图 2)。
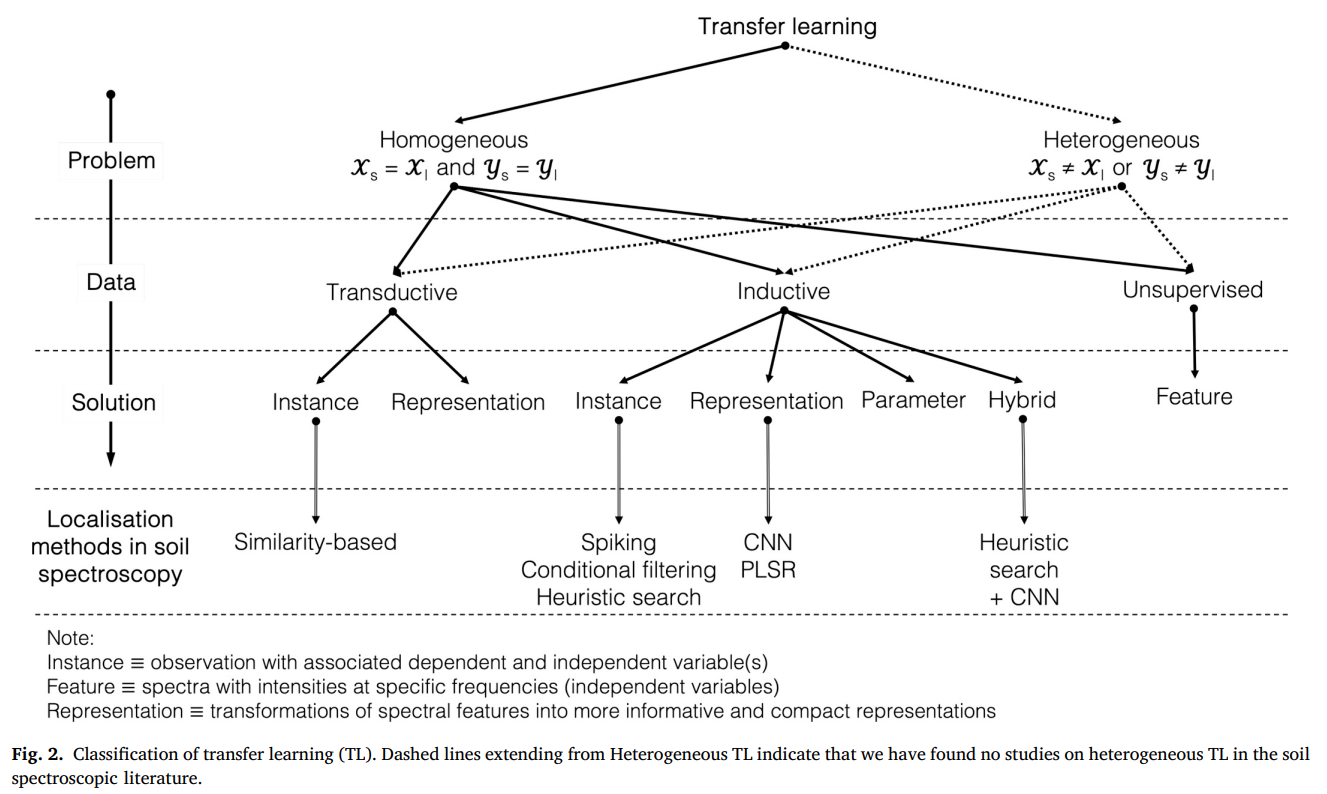
注:
- 实例(Instance)= 包含相关因变量和自变量的观测值;
- 特征(Feature)= 包含特定频率强度的光谱(自变量);
- 表征(Representation)= 将光谱特征转换为更具信息性和紧凑性的形式。
3.2.1 迁移学习问题的定义
在土壤光谱学中实施迁移学习时,首要任务是评估源域与局部域的相似性,确定问题属于同构迁移学习还是异构迁移学习(图 2)。在异构迁移学习中,特征或响应变量空间不相等,因此解决方案的首要目标是降低空间之间的差异性,使问题转化为同构迁移学习问题。目前土壤或光谱学文献中尚无异构迁移学习的实例,但探索相关方法可能具有一定价值。感兴趣的读者可参考 Day and Khoshgoftaar (2017),了解异构迁移学习问题的详细描述及解决方案的方法学。同构迁移学习方法旨在降低源域和局部域在边缘分布和(或)条件分布上的差异性。所有光谱局部化方法(图 1)均属于同构迁移学习问题(图 2)。同构和异构迁移学习方法均可分为 "归纳式""直推式" 或 "无监督式"(图 2),下文将详细描述。
3.2.2 迁移学习中局部数据的可获得性
具有实测土壤属性的局部观测值的可获得性,决定了迁移学习是直推式、归纳式还是无监督式(图 2)。直推式迁移学习是指仅源域存在实测响应变量,迁移可基于观测值(即实例)或表征(即捕捉输入光谱潜在结构的提取光谱特征)。最著名的直推式迁移学习实例是域自适应(例如 Pan et al., 2011)。感兴趣的读者可参考 Niu et al. (2020),了解直推式迁移学习的详细描述及可能的算法和解决方案。土壤光谱学文献中直推式迁移学习的实例较少(见图 2 和第 2 节)。
归纳式迁移学习是指源光谱域和局部光谱域均存在实测响应变量。其目标是利用局部域中少量具有实测响应变量的观测值,构建局部预测函数。归纳式迁移学习有四种方法(图 2):基于实例的迁移、基于特征的迁移、基于参数的迁移,或组合迁移。感兴趣的读者可参考相关文献(例如 Pan and Yang, 2010; Weiss et al., 2016; Niu et al., 2020),了解归纳式迁移学习的详细描述及各类可能的算法和解决方案。土壤光谱学文献中存在归纳式迁移学习的实例(见图 2 和第 2 节)。
无监督式迁移学习是指源光谱域和局部光谱域均无响应变量(即土壤属性)数据。无监督式迁移学习在土壤光谱学中的应用有限,唯一可能的应用场景是利用源光谱库中的充足光谱,辅助局部光谱的聚类或降维。
3.2.3 可能的迁移学习解决方案
确定源域与局部域的相似性及数据可获得性后,下一步需根据具体任务确定解决方案。通常需要通过实验和实证评估,选择最合适的方法。
基于实例的迁移学习(图 2)利用局部域中的少量样本(含或不含实测响应变量),对源域中的实例进行加权,或提取源数据中的相关部分并与少量样本结合,以降低域间数据分布的差异(Pan and Yang, 2010)。最常用的方法之一是 TrAdaBoost 算法(Dai et al., 2007),该算法利用局部域中的少量观测值,通过迭代加权源观测值,从源域中提取有用信息。当局部域中实测土壤属性稀缺或不可得时,基于实例的方法可能非常有用。
土壤光谱学文献中直推式基于实例的迁移学习实例较少;例如,基于相似性的局部化方法(图 1)可归类为直推式基于实例的迁移学习(图 2)。现有大多数光谱局部化方法(第 2 节)可归类为归纳式基于实例的迁移学习,例如 Spike 法、条件滤波法和启发式搜索方法(图 1)。Spike 法是基于实例的迁移学习的极端情况,即重用源光谱域中的所有观测值构建局部预测函数。
基于表征的迁移学习(图 2)假设源光谱域和局部光谱域具有共同的表征,即光谱特征的表征具有域不变性(Tzeng et al., 2014)。其目标是将通常在大规模数据集上训练的模型所 "学习" 到的表征,迁移到局部域。利用预训练表征,局部模型可从预训练过程中捕捉的信息中获益。当预训练模型捕捉到跨域相关的通用模式和特征时,基于表征的迁移学习可能是一个不错的选择(Yosinski et al., 2014)。当局部域中无实测土壤属性数据,且源域和局部域具有相似的高级特征时,基于表征的迁移可能有效。
Weiss et al. (2016) 描述了非对称特征迁移和对称特征迁移。当源域和局部域响应变量的条件分布相同时,可采用非对称特征转换,避免出现上下文特征偏差。对称特征转换通过将两个域转换到共同的预测低维潜在特征空间,同时降低域间边缘分布的差异,帮助发现数据中的潜在结构(Weiss et al., 2016)。光谱土壤建模局部化中基于特征的迁移实例(图 1 和图 2)包括神经网络表征重用(Liu et al., 2018)和偏最小二乘回归(PLSR)表征重用(Ng et al., 2022)。
基于参数的迁移学习(图 2)利用源域和目标域共享的模型参数或超参数的先验分布。在这种情况下,将部分或全部预训练参数迁移到局部模型。当源域和局部域具有相似的低级和高级特征,且预训练模型的参数可直接应用于局部任务时,基于参数的迁移可能有用。该方法通常适用于有充足局部数据用于微调预训练模型参数的场景。这种迁移类型仅适用于域间差异性较小的情况(Niu et al., 2020)。目前尚无土壤光谱建模中应用基于参数的迁移学习的研究,但该方法已用于遥感影像分类(Ma et al., 2021)。
迁移学习文献中的新兴方法包括混合方法(同时迁移实例、特征或共享参数)和关系型迁移学习方法(旨在 "学习" 源域和目标域之间的共同关系)。这些方法尚未在土壤科学中得到探索。Shen et al. (2022) 结合了基于实例的迁移与基于特征的迁移 ------ 利用 RS-LOCAL 2.0 算法进行基于实例的迁移,并通过微调卷积神经网络(CNNs)进行基于表征的迁移。这些方法仍需进一步研究。
3.2.4 正向迁移、负向迁移和零迁移
需要注意区分正向迁移、负向迁移和零迁移。迁移学习的效果取决于从源域迁移到局部域的信息的相关性和兼容性。因此,当从源域获得的信息提升了局部域预测函数 fl(⋅) 的性能时,称为正向迁移。此时,迁移通过增强 fl(⋅) 的 "学习" 能力,提升了模型在局部域的泛化性能和土壤属性估算准确性。相反,当源域信息降低了 fl(⋅) 的性能时,称为负向迁移。当源域信息与局部域不相关或不兼容时,可能发生负向迁移(Wang et al., 2019)。当然,我们的目标是实现正向迁移,避免负向迁移 ------ 因为负向迁移会导致估算结果不准确或错误,进而误导决策。尽管土壤光谱建模文献中有研究报道局部化(即光谱迁移学习)的性能参差不齐且效果不佳(例如 Guerrero et al., 2010; Seidel et al., 2019; Ng et al., 2022; Shen et al., 2022),但尚未有研究明确诊断和解决负向迁移问题。零迁移是指源域信息未对局部域性能提供实质性益处或改进,通常发生在域间差异显著或无有用可迁移信息的情况下。
3.3 迁移学习的实施
要有效实施迁移学习,需回答三个核心问题:何时迁移、迁移什么以及如何迁移(Pan and Yang, 2010)。解决这些问题的顺序可能因上下文和具体问题而异。除非存在资源限制、先验知识或专业经验,否则按 "何时迁移→迁移什么→如何迁移" 的顺序系统、实际地应用迁移学习可能更为可行。(1)"何时迁移" 强调并非所有场景都适合使用迁移学习,仅当迁移能提升局部预测函数的准确性时才应采用。在某些情况下,迁移可能无法提升甚至会降低局部估算的准确性,导致零迁移或估算失败的负向迁移。(2)"迁移什么" 要求明确从源域迁移到局部域的信息。无论是迁移观测值、表征中的信息,还是两者兼具,其目标都是利用源域中的有用信息提升局部域的估算效果,实现正向迁移。因此,明确 "迁移什么" 有助于利用土壤属性数据、光谱和学习到的表征,提升局部预测函数的准确性、效率和泛化能力。(3)"如何迁移" 涉及将信息从源域有效迁移到局部域的策略和技术(图 2)。选择最合适的技术将确保迁移效果最优,最大化迁移信息的利用率。
本文讨论了光谱局部化问题,并提出迁移学习可优雅地描述该问题,且有助于系统开发稳健、实用的解决方案。接下来,我们将报告一项实验 ------ 利用大型多样化的全球可见 - 近红外土壤光谱库和全球 12 个局部位点的数据,测试迁移学习方法的实施效果。根据上述框架,该迁移学习问题属于同构迁移学习(因为土壤光谱库(即源域)和局部数据(即目标域或局部域)共享相同的响应变量和光谱范围);属于归纳式迁移学习(因为多个经土壤有机碳(SOC)分析的局部样本有助于实现迁移);属于基于实例的迁移学习(因为该方法从土壤光谱库中迁移有用的观测值,辅助每个位点的局部建模)。
4. 数据与方法
本研究使用的全球土壤光谱库(GSSL 2.0)包含维斯卡拉・罗塞尔等人(Viscarra Rossel et al., 2016)描述的全球土壤光谱库(GSSL)的一个子集、世界土壤信息(ISRIC)光谱库(世界农林业中心(ICRAF)和国际土壤参考信息中心(ISRIC), 2021; Shepherd and Walsh, 2002; Shepherd et al., 2003)、欧洲土地利用 / 覆盖区域框架调查(LUCAS)数据库(Stevens et al., 2013)、地中海光谱数据库(i-BEC et al., 2019; Tziolas et al., 2019)、快速碳评估计划(RaCA)(Wills et al., 2014)和中国光谱库(Shi et al., 2015)。截至目前,该光谱库包含 52,742 条光谱。表 1 总结了每个数据库的光谱信息,感兴趣的读者可参考上述相关文献获取更多具体细节。
为整合来自不同光谱库、具有不同光谱范围、分辨率和波长间隔的反射光谱(表 1),我们采用局部多项式回归(Cleveland, 1981)将光谱插值到标准的 10 nm 波长间隔。插值还能提高信噪比,降低光谱的维度和冗余度。
表 1 用于测量 GSSL 2.0 中样品的光谱仪汇总表
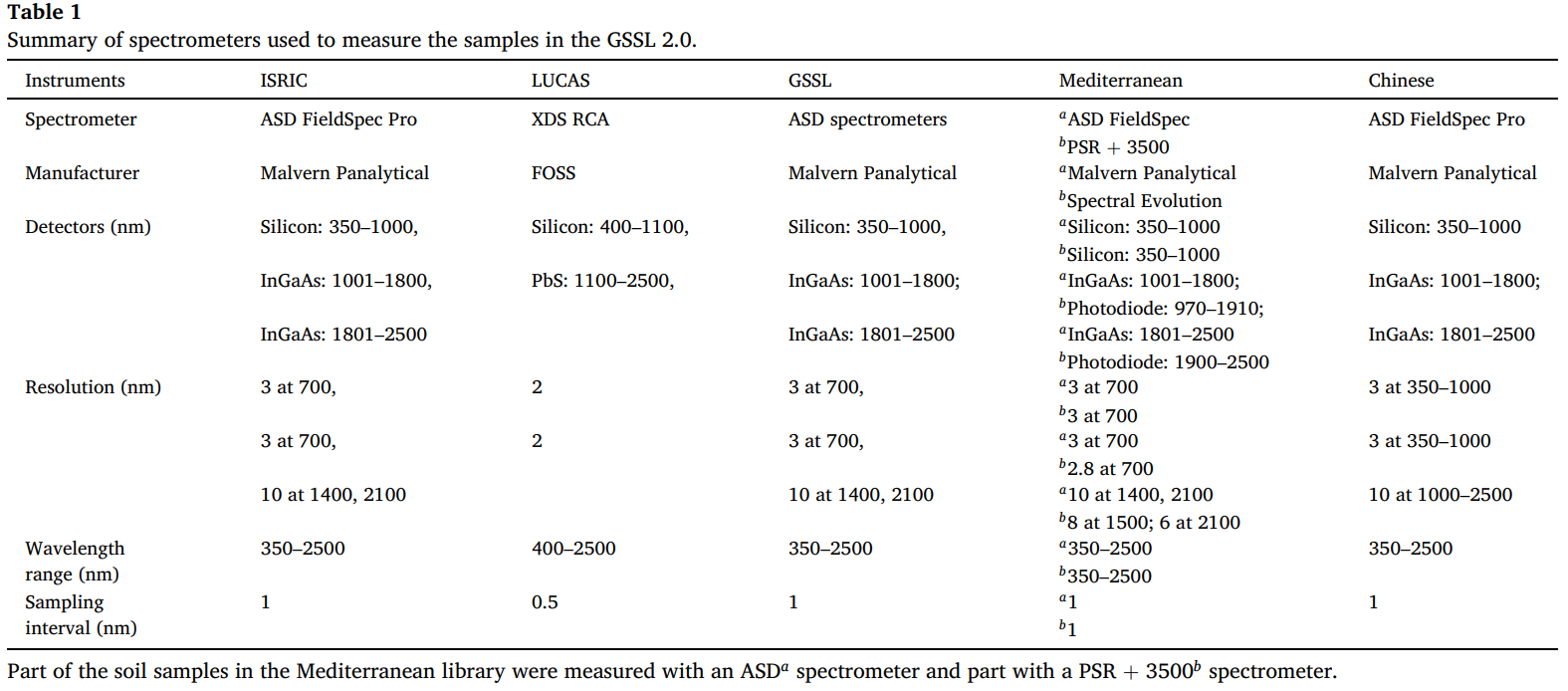
注:地中海光谱库中的部分土壤样品使用 ASD 光谱仪测量,部分使用 PSR + 3500b 光谱仪测量。
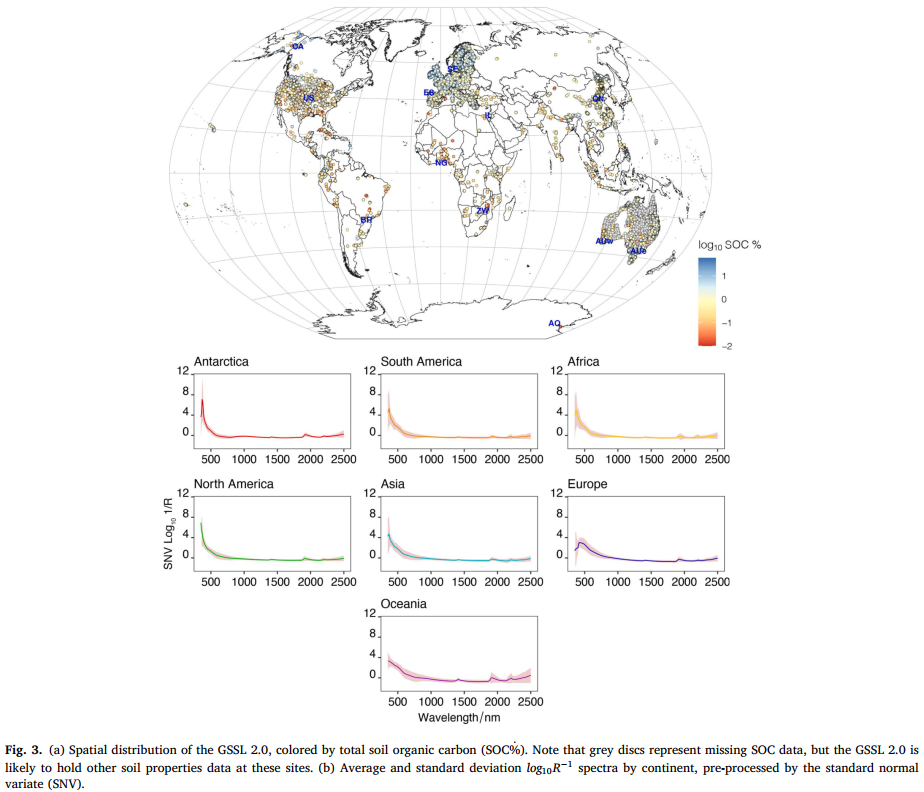
图 3a 展示了 GSSL 2.0 中样品的空间分布。将 GSSL 2.0 的反射光谱转换为表观吸光度(公式:A=log10R−1,其中 R 为反射率),然后采用标准正态变量(SNV)转换进行标准化(Barnes et al., 1989)。图 3b 展示了按大洲划分的预处理后光谱。
不同数据集的土壤有机碳(SOC)含量采用不同分析方法测量:LUCAS 样品的土壤有机碳(SOC)含量通过干烧法测量(Orgiazzi et al., 2018);中国样品通过硫酸 - 重铬酸盐氧化法测量(Shi et al., 2015);GSSL 和 ISRIC 样品采用多种方法测量,包括沃克利 - 布莱克法、过氧化氢氧化法、烧失量法、CHN 热解法、秋林法、斯普林格 - 克勒法和干烧法(Viscarra Rossel et al., 2016);地中海样品采用沃克利 - 布莱克法、过氧化氢氧化法和烧失量法测量(Tziolas et al., 2019)。GSSL 2.0 包含多种土壤类型的数据,包括北半球温带地区的有机土(图 3a)。GSSL 2.0 中土壤的有机碳(SOC)含量范围为 0.01%-58.68%。
4.1 局部数据
本研究测试了来自 10 个国家(加拿大、美国、巴西、瑞典、西班牙、以色列、尼日利亚、津巴布韦、中国和澳大利亚)以及南极洲一个地区(罗斯属地)的局部数据集 ------ 这些数据集独立于 GSSL 2.0,覆盖各大洲,土壤用途包括种植、草地、森林和灌丛。这些局部数据代表了田块内、田块、农场和区域尺度的土壤。
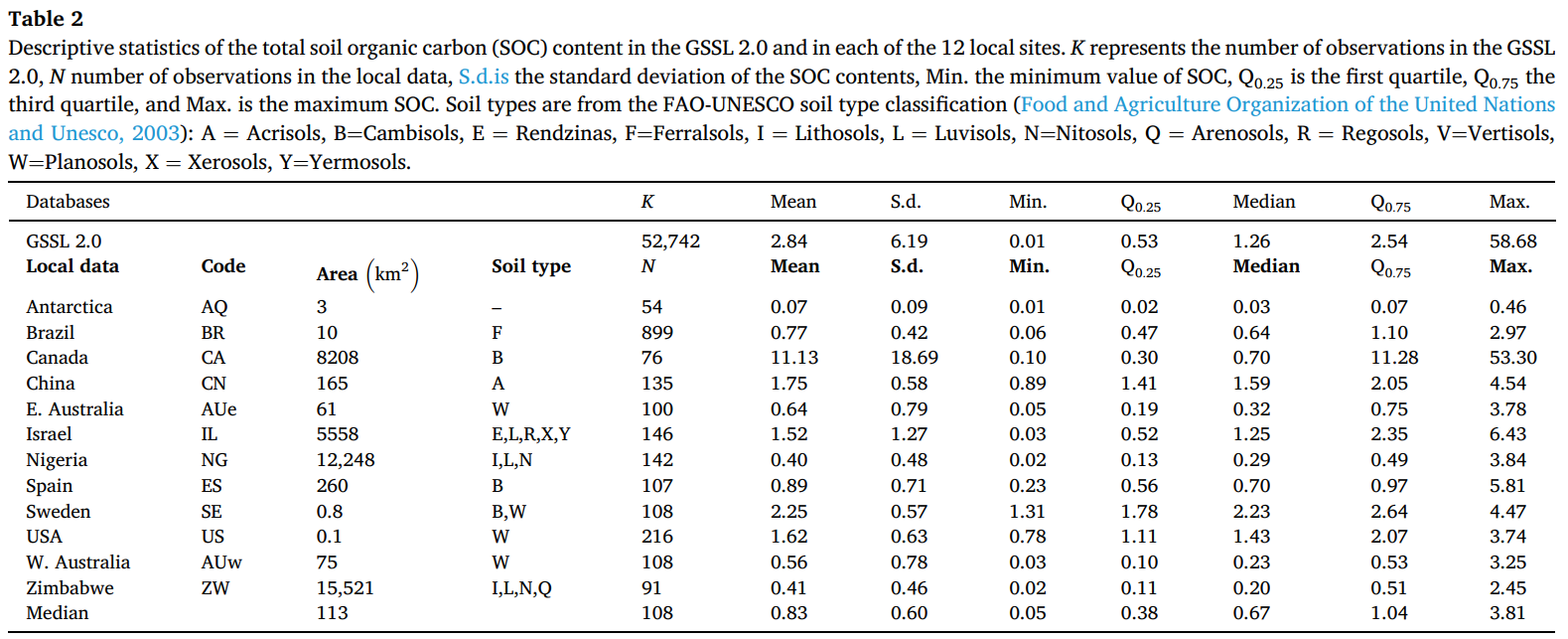
局部数据的平均土壤有机碳(SOC)含量范围为 0.07%-11.13%(表 2)。加拿大位点的土壤有机碳(SOC)含量变异性最大(0.10%-53.30%),而罗斯属地的土壤有机碳(SOC)含量变异性最小(0.01%-0.46%)。
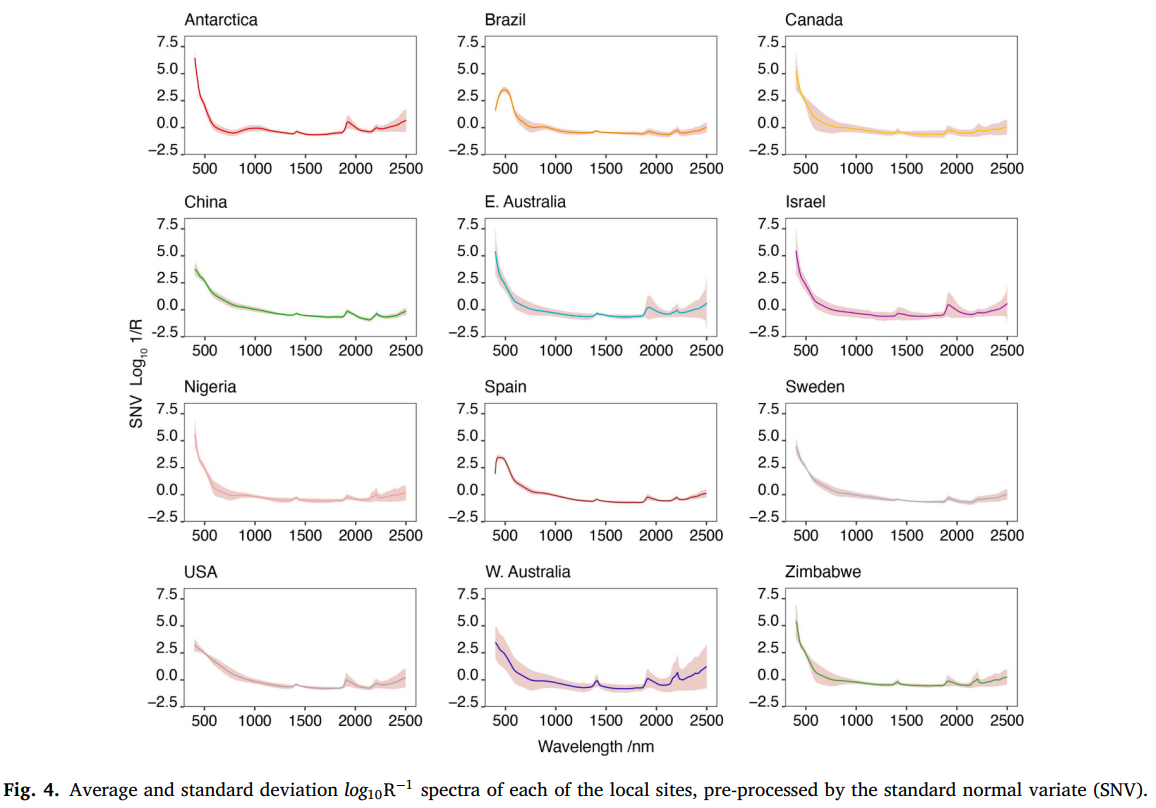
局部土壤样品使用不同仪器测量,但均为同一品牌的光谱仪(ASD 光谱仪,马尔文帕纳科,英国伍斯特郡),且采用与 GSSL 2.0 相同的光谱预处理方法(见上文)。图 3a 展示了每个局部位点的位置,图 4 展示了其光谱。
图 3. (a) GSSL 2.0 的空间分布(按土壤有机碳(SOC)总量百分比着色)。注:灰色圆点表示土壤有机碳(SOC)数据缺失,但 GSSL 2.0 在这些位点可能包含其他土壤属性数据。(b) 按大洲划分的平均和标准差 log10R−1 光谱(经标准正态变量(SNV)预处理)。
表 2 GSSL 2.0 和 12 个局部位点的土壤有机碳(SOC)含量描述性统计。K 表示 GSSL 2.0 中的观测值数量,N 表示局部数据中的观测值数量,S.d. 表示土壤有机碳(SOC)含量的标准差,Min. 表示土壤有机碳(SOC)最小值,Q0.25 表示第一四分位数,Q0.75 表示第三四分位数,Max. 表示土壤有机碳(SOC)最大值。土壤类型依据联合国粮食及农业组织 - 联合国教科文组织(FAO-UNESCO)土壤类型分类(联合国粮食及农业组织和联合国教科文组织,2003):A = 淋溶土,B = 雏形土,E = 黑色石灰土,F = 铁铝土,I = 石质土,L = 淋溶土,N = 黏磐土,Q = 砂土,R = 粗骨土,V = 变性土,W = 潜育土,X = 干旱土,Y = 荒漠土。
4.2 实验设计
本研究利用 GSSL 2.0 和局部数据集(见上文)设计实验。对于 12 个位点中的每个位点,我们比较了两种模型的土壤有机碳(SOC)估算结果:一种是使用不同数量代表性(n个)局部数据的局部模型(localn),另一种是使用 n+k 个观测值的迁移集模型(transfern+k)------ 其中 k 代表 GSSL 2.0 的一个子集(包含 K 个观测值)。我们还测试了偏最小二乘回归(PLSR)和机器学习(ML)算法对建模的影响,以及 localn 和 transfern+k 模型的稳定性。我们将使用 K 个观测值的全球模型和使用全部 N 个局部观测值的局部模型作为基准 ------ 假设全球模型的估算准确性最低,而使用全部 N 个局部数据的模型估算准确性最高。下文详细描述实验流程。
4.2.1 选择不同的 localn 子集
为测试(小型且经济可行的)样本量对局部建模的影响,对于来自 10 个国家和罗斯属地的每个包含 N 个观测值的局部数据集,我们采用肯纳德 - 斯通算法(Kennard and Stone, 1969)选择 n 个代表性样本。因此,对于 12 个位点中的每个位点,我们生成了 10 个 "localn" 子集(n=5、10、15、... 、50 个观测值)用于建模。剩余的 N−n 个数据作为独立集用于验证模型(见第 1 节)。
4.2.2 选择 transfern+k 子集
为测试 GSSL 2.0 在局部建模中的价值,我们利用来自 10 个国家和罗斯属地的不同 localn 数据,执行 RS-LOCAL 2.0 搜索(Lobsey et al., 2017; Shen et al., 2022),并从 GSSL 2.0 中迁移 k≈100 个实例。该算法的详细信息可参考 Lobsey et al. (2017) 和 Shen et al. (2022)。简而言之,RS-LOCAL 2.0包含两个核心组件:(i)采用重复简单随机重采样策略,在大型光谱库中搜索并选择对局部建模有用的实例;(ii)基于随机子集构建的偏最小二乘回归(PLSR)模型的性能进行选择,这有助于考虑响应变量与光谱之间的协变关系。因此,该算法仅保留大型光谱库中那些在局部 n 个观测值上评估时,能生成最准确局部模型的 k 个实例。选择完成后,将 k 个实例与 n 个局部数据结合,构建 transfern+k 集。本研究中 RS-LOCAL 2.0 的实现,参考 Lobsey et al. (2017) 和 Shen et al. (2022) 的建议,将参数 b(重采样过程中从 GSSL 2.0 中抽取每个样本的平均次数)设置为 b=80。
4.2.3 不同算法的建模
为评估不同算法对全球模型、localN、localn 和 transfern+k 建模的影响,我们采用了偏最小二乘回归(PLSR)(Wold et al., 2001)、回归树方法 CUBIST(Quinlan, 1992)、带径向基函数的支持向量机(SVM)(Vapnik et al., 1996)以及优化的一维卷积神经网络(CNN)(Shen and Viscarra Rossel, 2021)。读者可参考上述文献了解这些方法的详细信息,其在光谱建模中的应用实例可参考 Viscarra Rossel and Behrens (2010) 和 Shen and Viscarra Rossel (2021)。
实施过程 :建模前,对全球模型、localN、localn 和 transfern+k 集中的光谱进行中心化处理。每种回归方法都有多个超参数需要优化:对于每种方法,我们将优化目标设定为最小化全球模型和 localN 的 10 折交叉验证均方根误差(RMSE),以及 localn 和 transfern+k 模型的 5 折交叉验证均方根误差(RMSE)。对于偏最小二乘回归(PLSR),优化偏最小二乘因子数量;对于 CUBIST,优化委员会数量和近邻数量;对于支持向量机(SVM),优化惩罚参数(C)和核函数参数(sigma);对于卷积神经网络(CNNs),优化卷积层和全连接块的数量及其内部超参数。CUBIST 和支持向量机(SVM)超参数的优化采用差分进化算法(Mullen et al., 2011),一维卷积神经网络(CNNs)的优化采用基于树状帕累托估计器的贝叶斯优化(Bergstra et al., 2011; Shen and Viscarra Rossel, 2021)。偏最小二乘回归(PLSR)、CUBIST 和支持向量机(SVM)通过 R 软件(R Core Team, 2022)和 caret 包(Kuhn, 2008)实现;卷积神经网络(CNNs)在 Python 中通过深度学习框架 TensorFlow(Abadi et al., 2016)开发。
模型准确性评估 :通过将全球模型、localn 和 transfern+k 模型的土壤有机碳(SOC)估算结果与来自 10 个国家和罗斯属地的每个位点的 N−n 个实测观测值进行比较,验证模型性能。localN 模型通过 10 折交叉验证进行验证。利用观测值与预测值之间的差异,计算林氏一致性相关系数(ρc)(Lin, 1989)(用于比较不同模型)、均方根误差(RMSE)(用于衡量模型不准确性)、平均误差(ME)(用于衡量模型偏差)和误差标准差(SDE)(用于衡量模型不精确性)。林氏一致性相关系数(ρc)无量纲,范围为 - 1 至 1,可直接比较不同位点的模型性能;均方根误差(RMSE)、平均误差(ME)和误差标准差(SDE)能明确表征模型的估算误差(Viscarra Rossel and McBratney, 1998)。
4.2.4 localn 和 transfern+k 模型的稳定性
为测试使用 localn 和 transfern+k 数据的土壤有机碳(SOC)模型的稳定性,我们首先确定能生成最准确土壤有机碳(SOC)估算结果的算法,然后使用该方法通过 50 次非参数自助法(Viscarra Rossel, 2007)对数据进行建模。自助法通过有放回随机抽样,评估由与研究数据结构相似的潜在数据引发的建模变异性。计算 50 次估算结果的平均值和标准差,以量化 localn 和 transfern+k 模型的稳定性。
4.3 迁移过程的解释
我们从数据、建模和土壤科学的角度解释迁移过程,以深入了解 RS-LOCAL 2.0 的迁移机制以及从 GSSL 2.0 向局部位点传递的信息。如前所述,迁移学习的目标是降低源域和局部域数据在边缘分布和条件分布上的差异。我们将光谱的主成分得分作为全球、localn 和 transferk 数据边缘分布的代理指标,以评估 RS-LOCAL 2.0 的迁移效果。我们还比较了全球、localn 和 transferk 数据集土壤有机碳(SOC)的条件分布,以进一步验证 RS-LOCAL 2.0 的迁移性能。
由于 RS-LOCAL 2.0 采用偏最小二乘回归(PLSR)选择待迁移信息,因此它会考虑土壤有机碳(SOC)与光谱之间的协变关系。基于此,我们能够分析全球、localn 和 transferk 数据的偏最小二乘回归(PLS)模型的变量重要性,以评估 RS-LOCAL 2.0 选择的迁移信息是否有助于构建局部预测函数。如果 localn 和 transferk 模型的光谱 - 土壤有机碳(SOC)关系相似且相关,则为正向迁移;若不相似或不相关,则局部预测函数会产生偏差,迁移无法实现,甚至可能出现负向迁移。我们对全球、localn 和 transferk 数据进行了偏最小二乘回归(PLSR)分析,并通过 5 折交叉验证对模型进行调优。变量重要性通过 R 软件中 CARET 包的 varImp 函数计算得出,该函数将变量重要性定义为绝对回归系数的加权和(Kuhn, 2008)。
为确定土壤和环境因素是否是 RS-LOCAL 2.0 迁移的驱动因素(或至少是否有贡献),我们比较了 localn 和 transferk 样本的不同属性。具体步骤如下:首先绘制数据的坐标(纬度和经度)以评估地理相似性;然后利用地理信息系统(GIS),从以下四类地图中提取数据位置的数值:i)全球土壤网格中的土壤属性,包括容重、阳离子交换量(CEC)、水 pH 值和黏粒含量(Poggio et al., 2021);ii)气候变量,包括年平均温度(MAT)和年平均降水量(MAP)(Fick and Hijmans, 2017);iii)采用当前唯一可用的数字化全球土壤分类系统的土壤类型(联合国粮食及农业组织和联合国教科文组织,2003);iv)全球土地覆盖分类(Buchhorn et al., 2020)。
5. 结果
GSSL 2.0 包含多种土壤类型的数据,包括北半球温带地区的有机土(图 3a)。相比之下,局部数据主要来自农田、农场或土壤有机碳(SOC)浓度相对较低的区域,但加拿大位点除外 ------ 该位点的土壤有机碳(SOC)含量范围为 0.1%-53.3%。
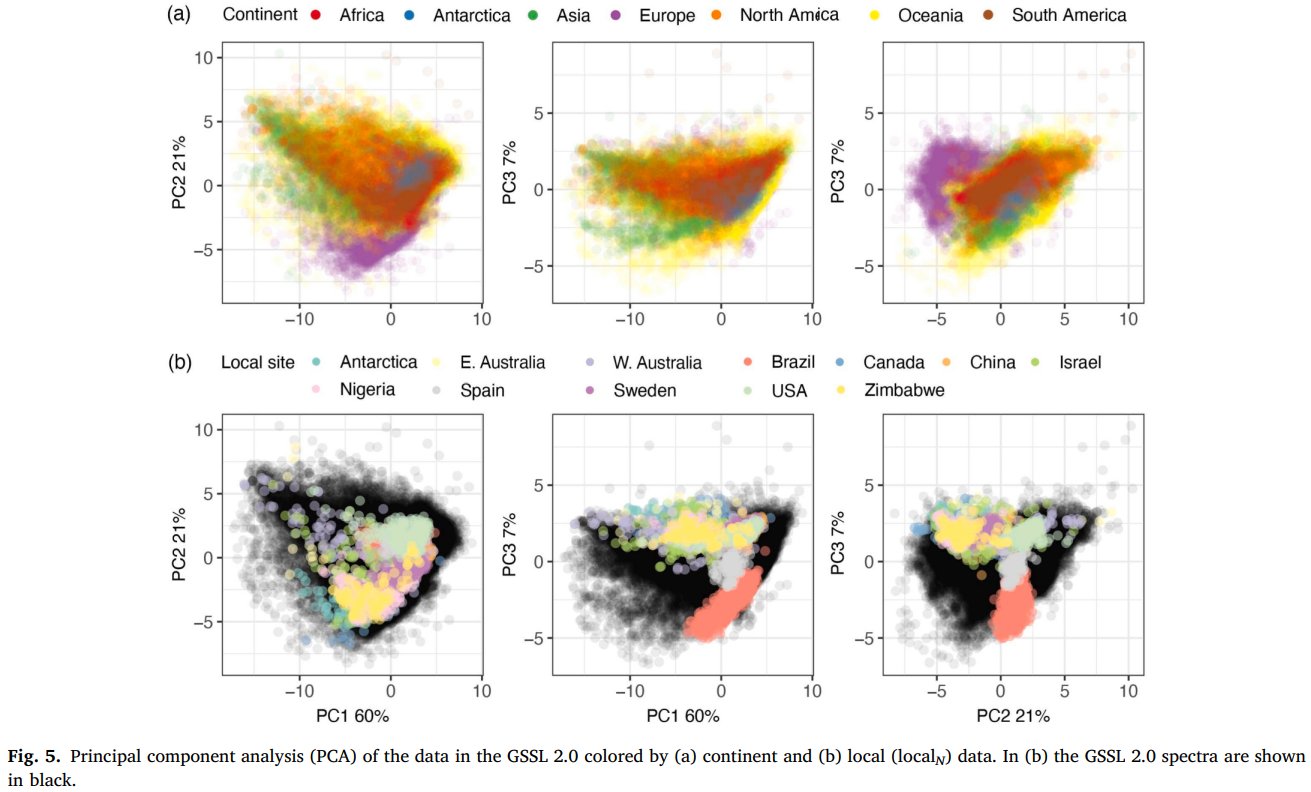
预处理后的 GSSL 2.0 光谱的主成分分析(PCA)得分总体上相互重叠,表明七大洲土壤的矿物 - 有机组成存在细微差异(图 5)。欧洲光谱扩展了 GSSL 2.0 的特征空间(图 5),这与北半球温带地区土壤在 GSSL 2.0 中占比较高有关(图 3a)。将 12 个局部位点的局部光谱投影到全球(特征)空间后发现,局部光谱大多落在 GSSL 2.0 的特征空间内(图 5),表明 GSSL 2.0 包含与局部位点光谱相似的样本。
5.1 不同算法的建模结果
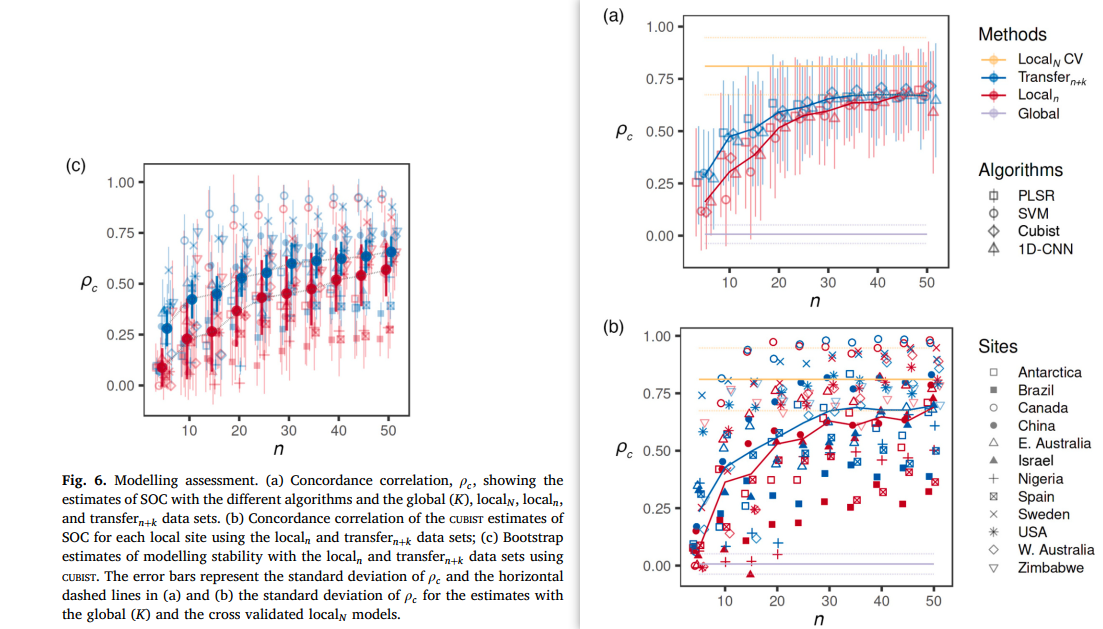
用于 localn 和 transfern+k 数据土壤有机碳(SOC)建模的不同算法,对估算结果的影响较小。但样本量较小时(n≤20),偏最小二乘回归(PLSR)的估算结果最准确;样本量较大时(25≤n≤50),CUBIST 算法的表现最优(图 6a)。
无论采用哪种算法,利用全部全球数据建模的估算结果均不准确(ρc≈0)(图 6a)。正如预期,localN 数据的交叉验证结果最准确(平均 ρc=0.81±0.14,标准差因算法而异)。与仅使用 localn 数据的建模结果相比,transfern+k 数据的建模结果更优,尤其是样本量较小时(n≤35)(图 6a)。当 n≈30 时,改进效果开始趋于平稳;当 n≥40 时,迁移学习的优势已不明显。
5.2 localn 和 transfern+k 数据的建模结果
为更详细地比较 localn 和 transfern+k 数据的建模效果,我们仅采用 CUBIST 算法,对 12 个位点的土壤有机碳(SOC)估算结果进行了分析(图 6b,表 3)。总体而言,transfern+k 数据的建模结果比仅使用 localn 数据的结果更准确。样本量越小时,ρc 的差异越显著,但整体来看,transfern+k 数据的 CUBIST 估算结果平均准确率提升了 13.3%(图 6)。由于迁移学习的优势在 n=30 时开始减弱,表 3 列出了 n=30 时 CUBIST 算法的评估统计数据。
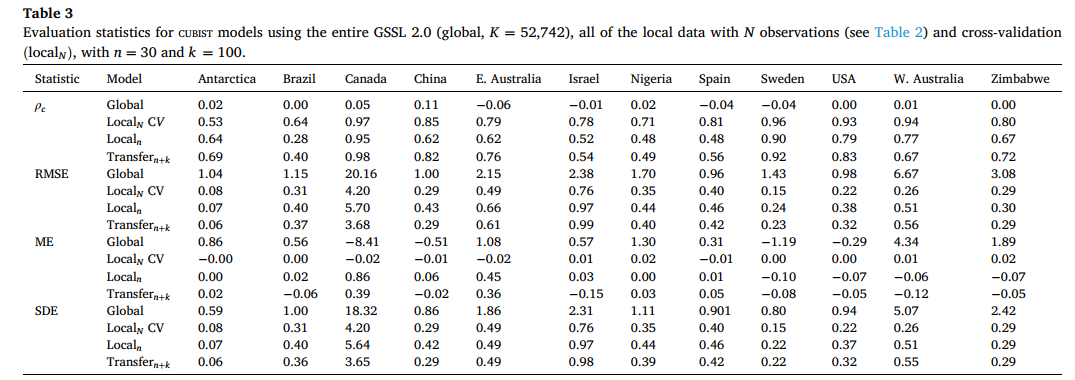
不同局部位点的土壤有机碳(SOC)估算准确性存在差异。巴西、尼日利亚、以色列和西班牙位点的 CUBIST 模型估算结果相对不准确(ρc<0.65),但使用 transfern+k 数据的模型表现更优(图 6b,表 3)。相反,加拿大、瑞典、美国和中国位点的估算结果较为准确(ρc≥0.8),且使用 transfern+k 数据时准确率进一步提升。transfern+k 数据还改善了南极洲和澳大利亚东部位点的土壤有机碳(SOC)估算准确性。总体而言,除以色列和澳大利亚西部位点出现负向迁移外,transfern+k 数据的土壤有机碳(SOC)估算结果均优于仅使用 localn 数据的结果(均方根误差(RMSE),表 3)。
5.3 localn 和 transfern+k 模型的稳定性
基于 transfern+k 数据构建的模型,比 localn 模型更稳定(图 6c)。随着样本量 n 的增加,localn 模型的不稳定性有所降低,表现为其平均估算结果的标准差范围变窄。但无论样本量大小,transfern+k 模型的稳定性始终更优,表现为其标准差范围相对一致(图 6c)。
5.4 迁移过程的解释:数据与模型
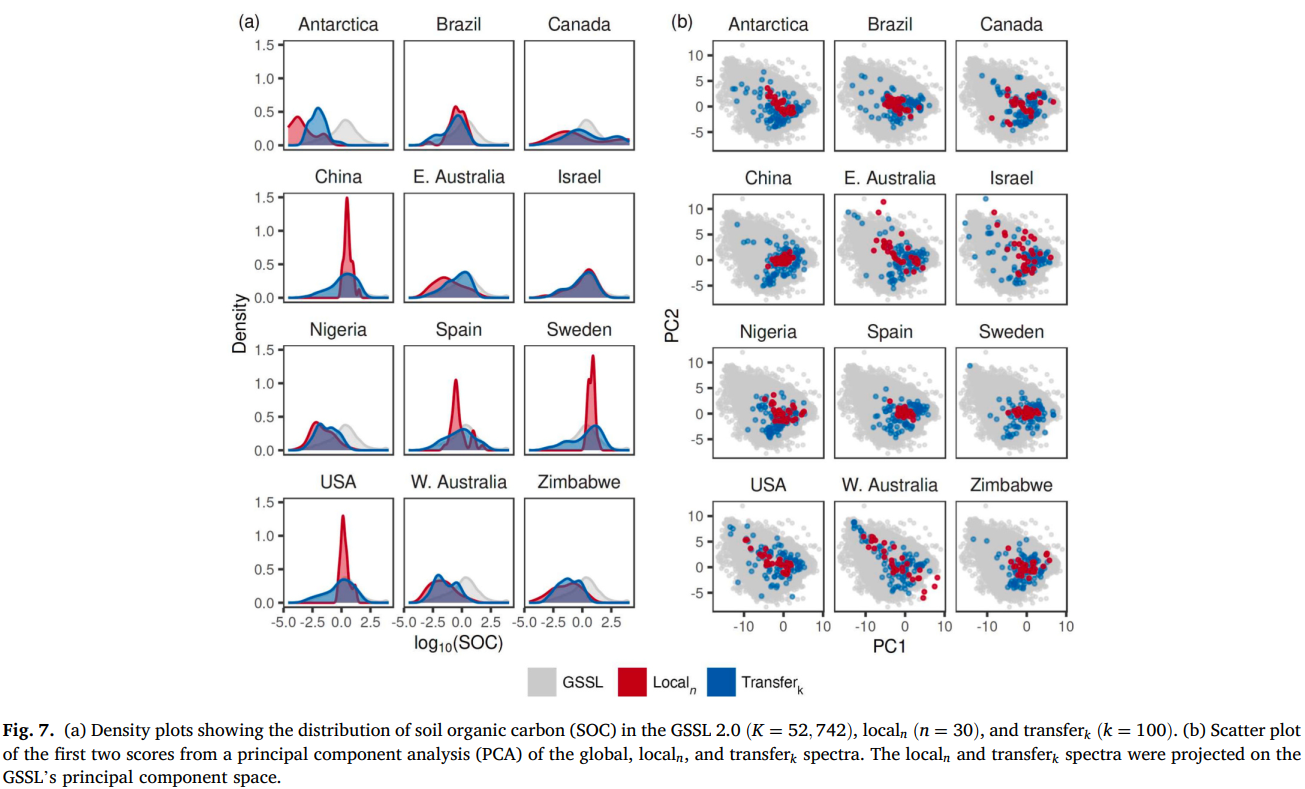
GSSL 2.0 和 12 个局部位点的土壤有机碳(SOC)数据的统计分布存在差异(图 7a)。但由于 RS-LOCAL 2.0 的迁移作用降低了 GSSL 2.0 与局部数据条件分布的差异,localn 和 transferk 数据的土壤有机碳(SOC)分布更为相似。
将 localn 和 transferk 数据投影到 GSSL 2.0 的光谱空间后发现,RS-LOCAL 2.0 选择的实例增强并扩展了 localn 观测值占据的光谱空间(图 7b)。基于实例的 RS-LOCAL 2.0 迁移学习,在主成分分析(PCA)空间中产生了相似的光谱分布,这意味着 GSSL 2.0 与局部光谱的边缘分布差异有所减小。澳大利亚西部的部分观测值落在 GSSL 2.0 的光谱空间之外(图 7b),表明该光谱库中没有与该位点相似的观测值,导致 localn 和 transferk 数据的边缘分布存在差异,最终出现负向迁移(澳大利亚西部,表 3)。
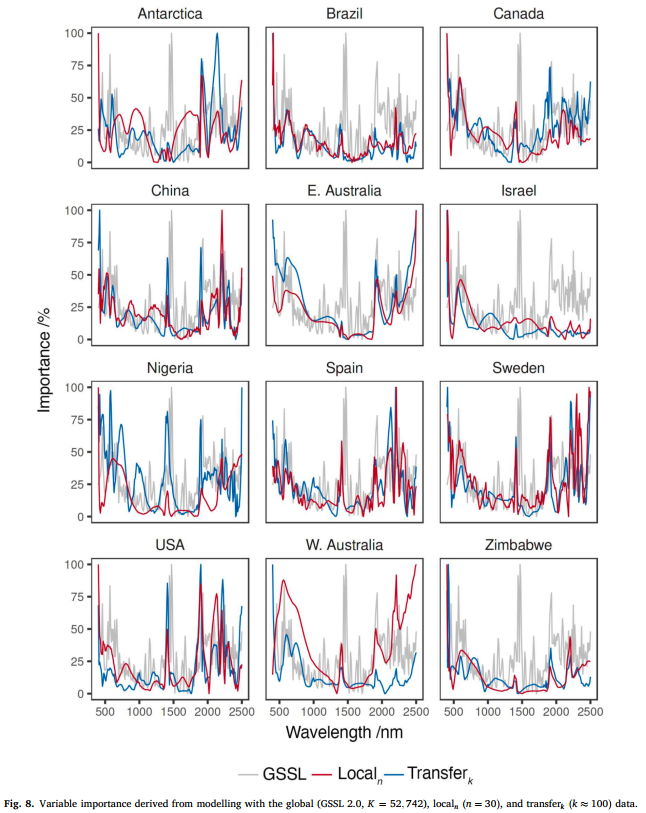
总体而言,对于 12 个位点中的每个位点,localn 偏最小二乘回归(PLSR)模型的变量重要性,与 transferk 偏最小二乘回归(PLSR)模型的变量重要性更为相似,而与全球模型的变量重要性差异较大(图 8)。RS-LOCAL 2.0 迁移学习从 GSSL 2.0 中选择的实例,与 localn 数据具有相似的光谱 - 响应关系。尽管澳大利亚西部的 localn 和 transferk 模型使用了相似的波长,但两者变量重要性的量级差异显著;尼日利亚的 localn 和 transferk 模型的变量重要性差异最大。变量重要性的量级或波长区域差异,表明 localn 和 transferk 模型的光谱 - 响应关系存在差异,这也是导致其性能下降和负向迁移的原因之一(表 3)。
5.5 迁移过程的解释:地理与土壤科学
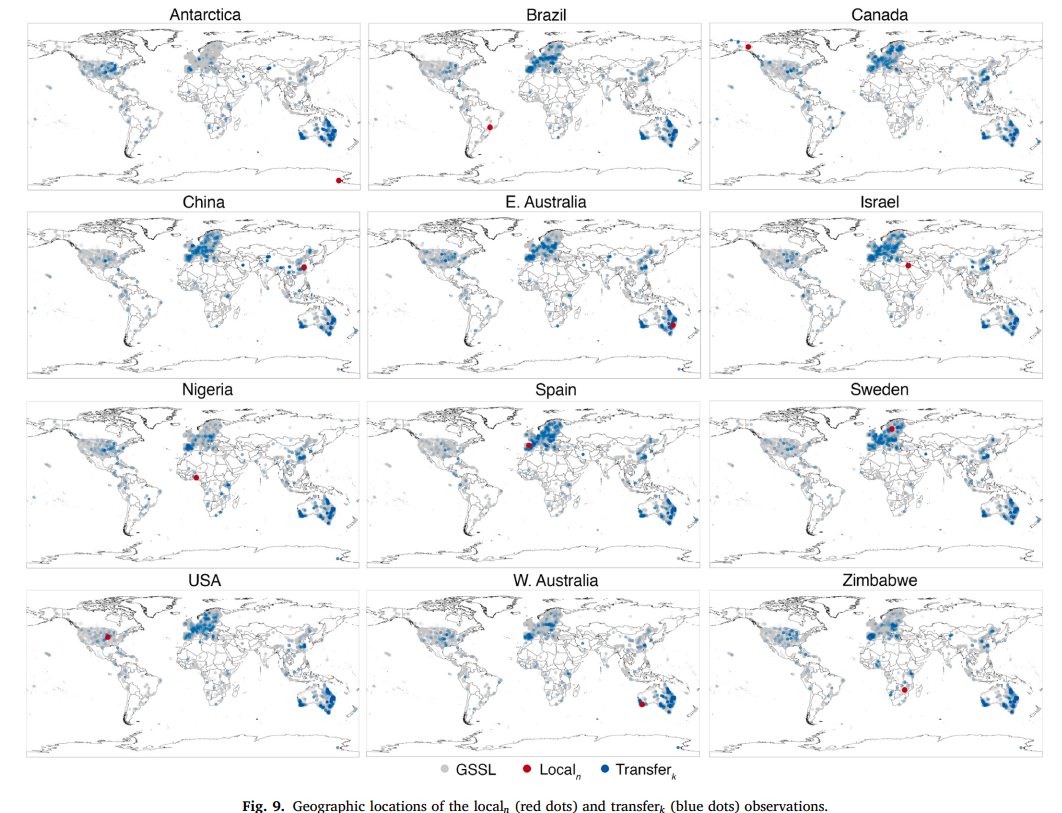
对 transferk 数据的地理分布分析表明,仅地理因素无法解释 RS-LOCAL 2.0 从 GSSL 向局部位点的迁移机制(图 9),但可识别出一些总体模式。每个位点的 transferk 实例来自全球多个地区,但主要来自美国、欧洲、中国和澳大利亚 ------ 这些地区是 GSSL 2.0 数据的主要贡献者(图 3)。RS-LOCAL 2.0 从 GSSL 2.0 中选择的 transferk 实例,超出了 localn 数据的地理空间范围,这意味着全球任何地区的观测值,都可能与其他地区的观测值存在关联(推测是由于相似的土壤气候条件),并有助于迁移学习和局部估算。
不出所料,实例选择与位点的土壤有机碳(SOC)含量相关。澳大利亚样本在所有 12 个局部位点的 transferk 样本中均占比较高(图 9);美国中西部的样本在选择结果中也较为突出;但南美洲、非洲和亚洲(中国除外)的样本选择没有明显规律,这可能与这些大洲的数据稀缺有关(图 3)。
12 个位点的欧洲样本选择结果存在差异。例如,加拿大、瑞典、美国、中国和西班牙位点的选择样本空间分布相似,均包含大量来自欧洲各地的样本(图 9),这些位点的土壤平均有机碳(SOC)含量范围为 0.9%-11.1%(表 2)。巴西和澳大利亚东部位点的欧洲样本选择较为稀疏,这些位点的土壤平均有机碳(SOC)含量范围为 0.64%-0.77%(表 2)。尼日利亚和津巴布韦位点的选择样本主要来自南欧和地中海地区(图 9),这些位点的土壤有机碳(SOC)含量范围为 0.4%-0.56%(表 2)。南极洲位点的欧洲样本选择数量最少,该位点的土壤有机碳(SOC)含量为 0.1%。
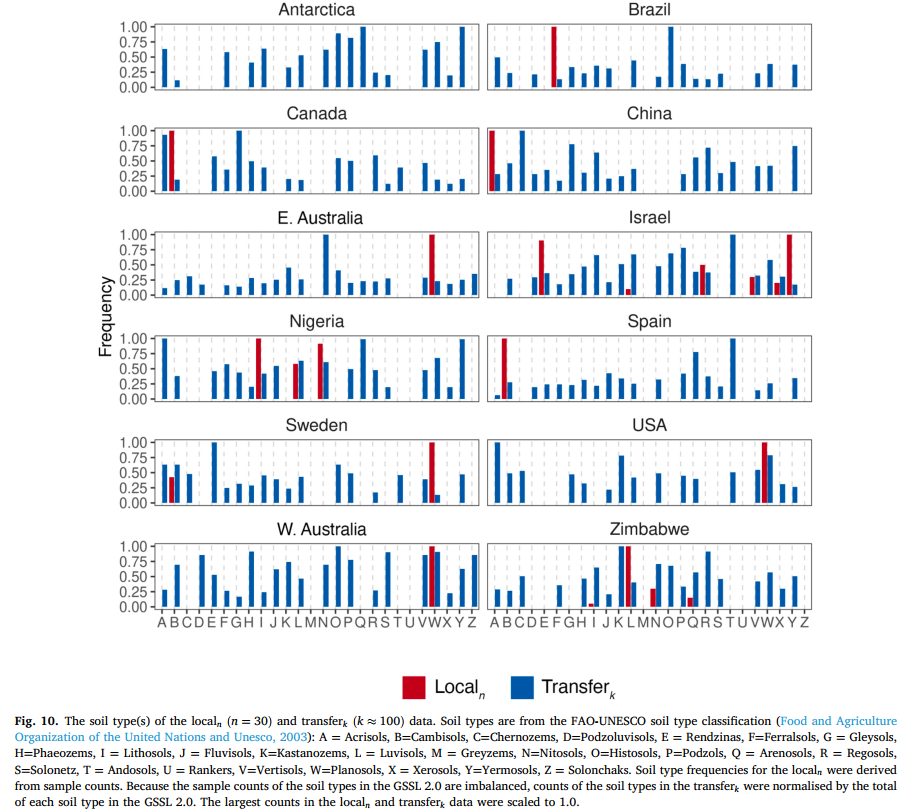
图 10 展示了每个局部位点样本的土壤类型,以及 transferk 数据的土壤类型。transferk 选择的土壤类型并非均与局部土壤类型匹配(图 10),但存在一些相似性:例如,尼日利亚、美国、澳大利亚西部、津巴布韦位点的 transferk 选择观测值的土壤类型,与局部位点的土壤类型相似;瑞典和以色列位点也在一定程度上存在这种相似性(图 10)。
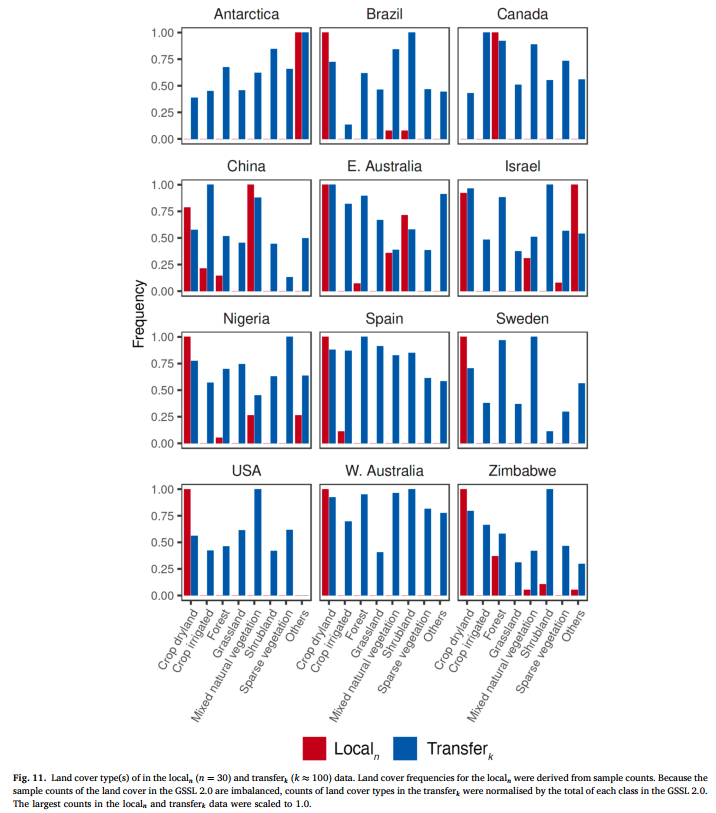
图 11 展示了每个局部位点的土地覆盖类型,以及 transferk 数据的土地覆盖类型。总体而言,transferk 选择观测值中最主要的土地覆盖类型,与局部位点的土地覆盖类型一致。
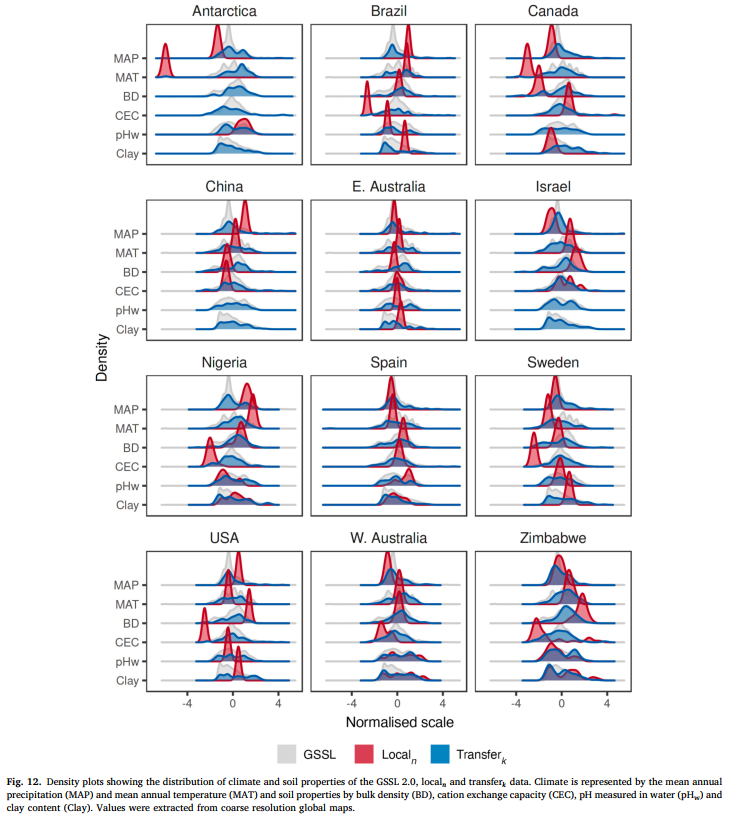
以年平均温度(MAT)和年平均降水量(MAP)为代表的气候因素,并未直接影响迁移过程(图 12)。四个位点(澳大利亚东部、西班牙、瑞典和津巴布韦)的 localn 和 transferk 数据的年平均降水量(MAP)相似;仅津巴布韦位点的 localn 和 transferk 数据的年平均温度(MAT)相似。但全球数据的年平均降水量(MAP)和年平均温度(MAT),与 transferk 数据也存在相似性。
土壤属性似乎并未影响 transferk 观测值的选择。在大多数情况下,只有当全球数据的分布也相似时,localn 和 transferk 数据的土壤属性分布才会相似,例如尼日利亚和西班牙的容重(BD)、中国、澳大利亚东部和西班牙的阳离子交换量(CEC)、尼日利亚、瑞典和津巴布韦的水 pH 值(pHW)。仅三个位点(尼日利亚、西班牙和津巴布韦)的 localn 和 transferk 数据的黏粒含量分布相似,但与全球数据存在差异。总体而言,气候和土壤属性似乎并未影响 RS-LOCAL 2.0 的选择过程(图 12)。但需注意,气候数据来自粗分辨率全球地图,土壤数据来自外推的粗分辨率且不确定性较高的土壤属性地图(见方法部分)。
6. 讨论
尽管目前已构建了多个区域、国家、大洲乃至全球尺度的土壤光谱库(SSLs),且机器学习(ML)和人工智能(AI)已取得显著发展,但这些技术在土壤光谱学的实际应用和部署方面,尚未产生重大影响(Viscarra Rossel et al., 2022)。其原因可能包括:构建包含全面且精准分析的土壤属性的土壤光谱库(SSLs)需要大量投入;机器学习(ML)方法需要大规模数据进行模型训练;获取土壤化学、物理和生物学属性的分析数据成本高昂(Viscarra Rossel and Bouma, 2016)。
目前我们已明确,基于大型 "全球" 可见 - 近红外(vis--NIR)土壤光谱库(SSLs)开发的模型,无法在所有局部场景中实现有效泛化。因此,基于全球模型直接进行土壤属性估算(例如 Shepherd et al., 2022)的泛化性能较差,甚至可能完全失效(见表 3)。这一问题的核心在于,土壤光谱库(SSL)与局部位点数据的边缘分布或条件分布存在差异。与其他预测方法类似,光谱建模假设训练集和预测集的数据分布相似 ------ 若该假设成立,建模即可成功。迁移学习提供了一个框架和一套持续改进、快速发展的方法学,能够明确解决数据分布差异问题。
本研究表明,基于实例的 RS-LOCAL 2.0 迁移学习,可通过从全球光谱库(GSSL 2.0)迁移相关且有益的信息,克服上述缺陷,改善全球土壤有机碳(SOC)的局部建模效果。RS-LOCAL 2.0 迁移学习改善了 12 个局部位点中 10 个位点的土壤有机碳(SOC)局部建模效果(表 3),仅两个位点出现负向迁移。澳大利亚西部位点的预测效果较差,最可能的原因是 GSSL 2.0 中没有足够的有用数据用于该位点的估算(图 7)。以色列位点的 localn 和 transferk 数据的光谱 - 土壤有机碳(SOC)关系存在差异,意味着迁移的观测值未能有效改善建模效果,这可能是由于 localn 数据的土壤有机碳(SOC)数值不够精确。
当迁移学习为正向迁移时,RS-LOCAL 2.0 降低了 GSSL 2.0 与局部数据的边缘分布和条件分布差异,最终构建的光谱模型,其准确性至少与基于相同数量局部观测值的纯局部模型相当,甚至更优(图 6b,表 3)。当局部模型的观测值数量少于 30 时,其估算结果的平均准确性低于 RS-LOCAL 2.0 迁移学习的估算结果。若仅能测量少量局部样本,RS-LOCAL 2.0 可帮助提升土壤光谱技术的成本效益。因此,基于实例的 RS-LOCAL 2.0 迁移学习与 GSSL 2.0 相结合,可通过最大限度减少分析测量需求、降低土壤分析成本,为土壤有机碳(SOC)的测量和监测提供支持。
RS-LOCAL 2.0 是一种归纳式基于实例的迁移学习方法,其目标是利用少量局部观测值构建局部预测函数。迁移集的选择基于偏最小二乘回归(PLSR)模型的性能(该模型有助于考虑土壤有机碳(SOC)与光谱之间的协变关系),以及从 GSSL 2.0 中选择的、与局部观测值具有相似光谱 - 土壤有机碳(SOC)关系的 transferk 实例(图 8)。利用土壤光谱 - 土壤有机碳(SOC)关系,有助于从 GSSL 2.0 中 "过滤" 实例,仅提取对局部建模最相关的数据。
GSSL 2.0 包含来自不同项目、通过不同光谱仪测量(表 1)、且采用不同分析方法测量土壤有机碳(SOC)的光谱数据。光谱和土壤有机碳(SOC)分析的这些不一致性,是导致数据集边缘分布和条件分布存在差异的原因之一。但 RS-LOCAL 2.0 能够降低这些分布差异,减少测量不一致性的影响。因此,该方法无需单独进行 "校准迁移"(Andrew and Fearn, 2004; Pittaki-Chrysodonta et al., 2021)。
在每个局部位点,RS-LOCAL 2.0 从 GSSL 2.0 中提取的实例,来自全球各地具有相似矿物和有机质组成的区域(见图 8),这可能是由于相似的土壤气候条件和管理背景。该方法的这一特点令人鼓舞,因为在一个地区收集和测量的样本,可能有助于其他地区的建模。因此,要使光谱技术成为真正全球通用、实用且具成本效益的方法,我们应进一步扩展 GSSL 2.0,从数据代表性不足的地区收集土壤样本,以涵盖全球土壤的巨大多样性。更大型、更多样化的全球土壤光谱库(GSSL),将为光谱迁移学习提供更丰富、更有用的信息。
我们还通过实验深入探究了 RS-LOCAL 2.0 迁移过程的关键组成部分,以帮助用户理解该算法。开发和应用新的可解释、透明的方法,对于鼓励土壤光谱学的创新、应用和发展至关重要。RS-LOCAL 2.0 迁移学习有助于降低 GSSL 2.0 与局部数据的边缘分布和条件分布差异(图 7)。除土壤有机碳(SOC)外,GSSL 2.0 实例的选择相对不受局部数据的地理因素(图 9)、气候、土壤类型(图 10)甚至土壤属性(图 12)的限制。但我们也认识到数据集在分辨率和尺度上存在不匹配:气候数据来自 1 km 像素分辨率的全球地图(Fick and Hijmans, 2017);联合国粮食及农业组织(FAO)土壤图的比例尺为 1:5000000,其分类基于土壤剖面数据(联合国粮食及农业组织和联合国教科文组织,2003);土壤属性数据来自外推的粗分辨率且不确定性较高的土壤属性地图(Poggio et al., 2021)。土地覆盖对迁移数据的选择影响似乎更大(图 11),这可能是由于其数据具有更精细的 100 m 像素分辨率(Buchhorn et al., 2020),且土地覆盖对土壤有机碳(SOC)浓度有直接影响。
本研究结果支持构建大型、多样化的土壤光谱库(SSLs),但并非用于推导全球预测函数,而是作为光谱迁移学习的信息源。我们推测,全球光谱库越大、越多样化,就越有可能包含有用信息,这些信息可被迁移用于构建全球任何地区的精准局部土壤光谱模型。因此,维护和扩展 GSSL 2.0 等全球土壤光谱库,以更好地代表全球土壤的巨大多样性,对于土壤光谱学的发展,以及成本效益高的土壤评估和监测至关重要。
7. 未来研究方向
迁移学习的发展和应用,是土壤光谱学被广泛采用并实现实用、成本效益高的土壤评估和监测的必要条件。本研究表明,迁移学习能够解决土壤光谱学中的局部化问题。在提出的框架下(图 2),光谱迁移学习具有开发创新新方法的潜力。以下简要提出未来的研究发展方向:
计算高效的迁移学习方法(图 2):更好地解决源域和局部域数据的边缘分布和条件分布差异,更精准地捕捉其光谱 - 响应关系。
能够动态适应局部域规模、多样性甚至变化条件的归纳式迁移学习方法:例如,采用增量学习并利用新的局部数据持续更新模型的方法,可能有助于连续土壤传感和制图应用(如移动传感平台)。
利用域自适应算法实现跨域模型适配的方法:包括将域自适应与深度学习相结合的技术(如深度自适应神经网络(DANN))(Tzeng et al., 2014)。这些技术可考虑仪器校准、测量条件和环境差异等因素导致的变化,帮助对齐域间光谱分布。
光谱迁移学习中的多任务学习:通过在相关土壤属性(如黏粒、砂粒和粉粒含量等组成数据,或有机碳组分)上联合训练模型,可利用共享表征并跨数据迁移信息,以改善局部估算效果。
多源或多模态光谱融合:例如,将不同传感器的光谱(如可见 - 近红外(vis--NIR)与激光诱导击穿光谱(LIBS)),或与辅助数据(如其他土壤属性、卫星影像、气候和其他环境数据)相结合(Yang et al., 2019, 2022),可为迁移学习提供补充信息。开发有效的光谱融合技术,可增强模型从多源数据中捕捉多样化信息的能力。
利用无监督学习技术(如自监督学习(Zhai et al., 2019)或协同训练(Ning et al., 2021)):充分利用大量 "未标记" 局部光谱(即无实测土壤属性的局部光谱),以改善迁移学习效果。
将迁移学习方法及上述技术扩展到高光谱遥感:涉及高维二维局部光谱特征空间;同时,将光谱迁移学习扩展到数字土壤制图并实现其应用。
识别迁移学习为正向、零或负向迁移的方法:正向迁移是我们的目标,此类方法可帮助判断迁移学习是否有益。
可解释迁移学习的方法:理解迁移过程中重用的信息及其对预测的帮助机制。
易用的软件工具:支持全球分布的、实用且成本效益高的土壤光谱学迁移学习的实施。
8. 结论
本研究综述了当前光谱建模的局部化方法,并认为局部化是一个典型的迁移学习问题。随后,我们在土壤光谱建模的背景下,综述并定义了迁移学习,提出该框架可为土壤光谱学新方法的开发提供指导。我们将基于实例的 RS-LOCAL 2.0 迁移学习方法应用于土壤光谱学,利用 GSSL 2.0 和来自全球 10 个国家及罗斯属地(The Ross Dependency)的局部位点光谱数据进行了验证。研究结果表明,GSSL 2.0 包含对迁移学习有用的信息。使用≤30 个局部数据选择约 100 个迁移实例,其土壤有机碳(SOC)估算结果优于基于相同数量局部数据的局部建模,且迁移学习产生的估算结果更稳定。我们还阐明了 RS-LOCAL 2.0 迁移学习的作用机制:该方法通过学习 GSSL 2.0 中包含的特定土壤信息,改善了土壤有机碳(SOC)的局部估算准确性;迁移过程依赖光谱 - 土壤有机碳(SOC)关系,对齐了 GSSL 2.0 迁移数据与局部数据的边缘分布和条件分布。迁移学习在土壤光谱学中的应用和进一步发展,将受益于 GSSL 2.0 等全球土壤光谱库的进一步开发和扩展,以纳入更多来自数据代表性不足地区的信息。土壤光谱建模局部化的迁移学习,具有巨大的研究和开发潜力。