RAG 落地指南:为什么你的向量数据库检索不到正确答案?
在 Demo 阶段,RAG(检索增强生成)通常表现得很完美:LangChain 几行代码,上传 10 个 PDF,问什么都能答对。
但当我们把文档量级扩展到 10 万篇(千万级 Token),或者接入复杂的企业非结构化数据(金融研报、工业手册)时,系统往往瞬间崩塌。最典型的情况是:Recall(召回率)雪崩------用户问了一个具体参数,Vector DB 返回了完全无关的段落,或者召回了语义相似但数值错误的噪音,导致 LLM 因为 Context 污染而产生幻觉。
本文复盘我在实际生产环境中遇到的"检索失效"问题,并从数据 ETL、索引架构和检索链路三个维度给出硬核解决方案。
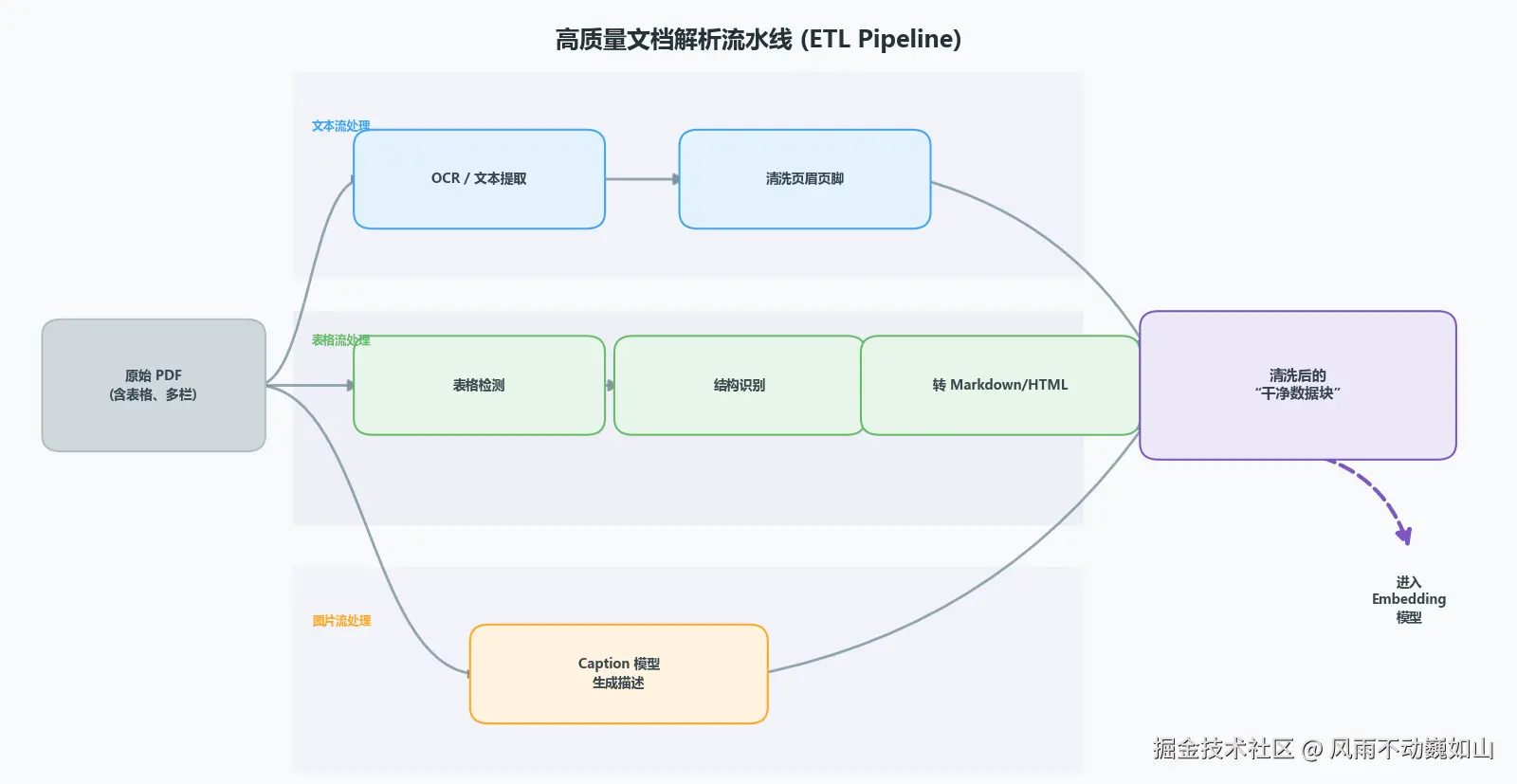
一、 垃圾进,垃圾出:被忽视的文档解析 (ETL)
很多开发者写 RAG 的第一步是 PyPDF2 或 Unstructured 直接提取文本。在生产环境中,这是导致 RAG 失败的第一大因。
痛点:
企业的真实文档充满了"非自然语言":
- 多栏排版(Multi-column): 简单的按行读取会将左栏的第一行和右栏的第一行拼在一起,导致语义错乱。
- 视觉噪音: 页眉、页脚、水印中的高频词(如"Confidential"、"Page 1")会显著改变 Embedding 的质心,导致检索偏差。
- 表格序列化: 这是最大的灾难区。
解决方案:基于视觉的文档还原 (Visual-based Parsing)
抛弃单纯的文本流提取,引入 OCR + Layout Analysis(版面分析)流水线。
-
版面分割 (Layout Analysis):
利用检测模型(如基于 YOLOv8 修改的 LayoutLMv3 或百度 PP-StructureV2)识别文档中的 Header, Footer, Image, Table, Text 区域。
- 工程策略: 对于识别出的 Header/Footer 区域,直接利用坐标(Bounding Box)进行剔除,而非依赖正则替换。
-
表格拓扑还原 (Table Structure Recognition):
向量模型(如 BERT/RoBERTa 系列)对表格的二维结构极不敏感。如果直接按行展平(Flatten),列与列的关联会丢失。
- 硬核策略: 将表格区域单独裁剪,通过 LGPMA 或 TableMaster 模型识别单元格结构,将其重构为 HTML 代码 或 Markdown。
- 理由: LLM 对 HTML/Markdown 语法的理解能力远强于纯文本空格对齐。对于复杂的财务三张表,甚至需要引入 LLM 做 Summary,生成一段自然语言描述(Caption),将表格数据 Embedding 化。
二、 切片(Chunking)策略:解耦"检索单元"与"生成单元"
最通用的 RecursiveCharacterTextSplitter(固定 Token 切分)在工程上最简单,但在语义完整性上是灾难性的。
痛点:
Window Context Split(窗口上下文割裂)。 假设一段核心逻辑横跨了两个 Chunk,或者一个 Chunk 包含了答案,但缺少了主语(主语在上一个 Chunk)。切分后,这两个残缺片段的 Vector Embedding 都会发生漂移,无法与 Query 形成高余弦相似度。
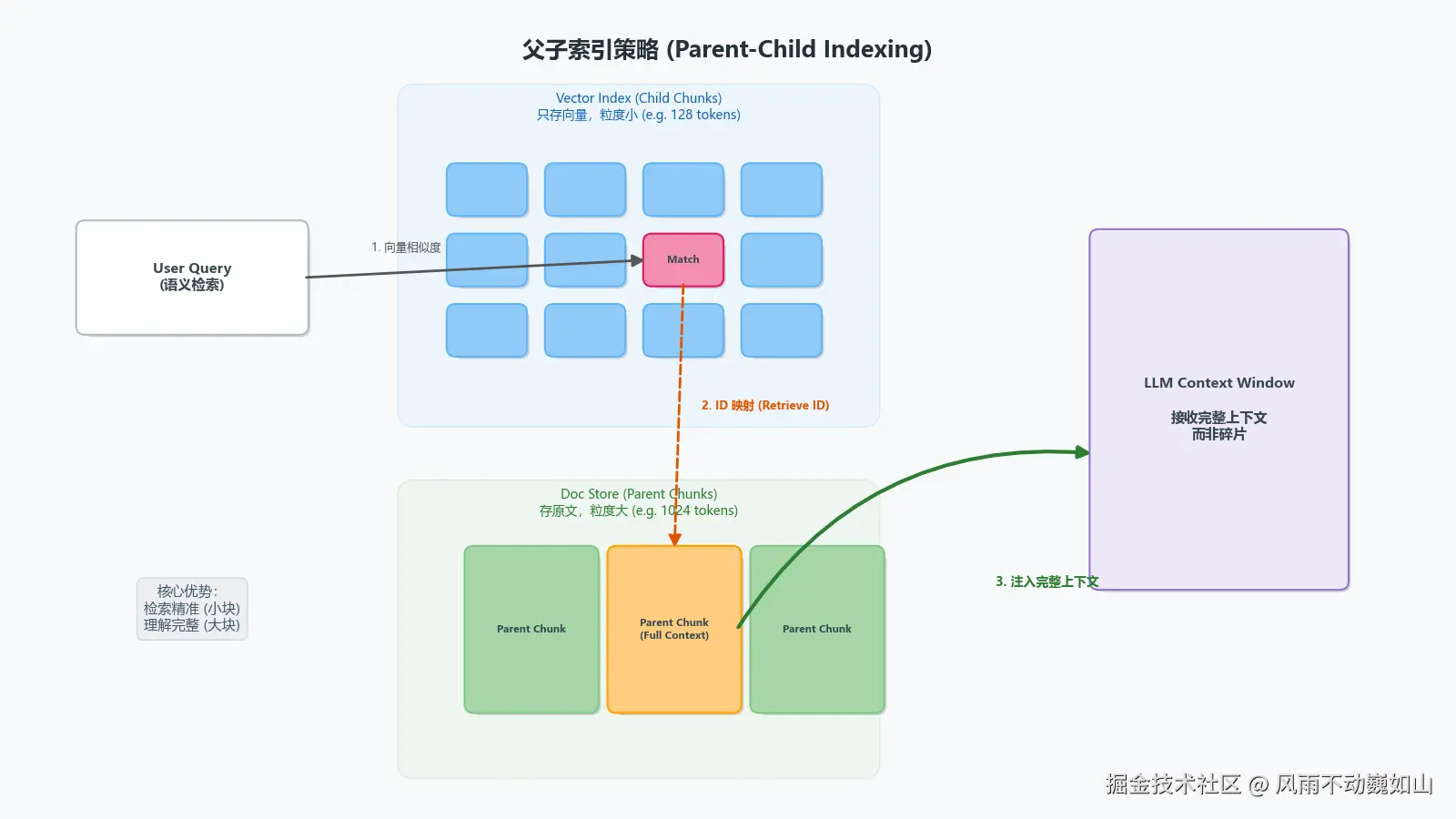
解决方案:父子索引(Parent-Child Indexing / Small-to-Big)
这是解决 Context 丢失的架构级方案,核心思想是索引粒度与生成粒度解耦。
架构设计:
-
Child Chunk(索引单元): 极小粒度(例如 128-256 tokens)。
- 优势: 语义极其聚焦,包含的噪音少,Embedding 向量更纯粹,更容易被 Vector DB 召回。
-
Parent Chunk(内容单元): 大粒度(例如 512-1024 tokens 甚至全文)。
- 优势: 包含完整的上下文逻辑,适合喂给 LLM 推理。
存储与检索流:
- Write: 将文档切分为 Parent Chunks,存入 Key-Value Store(如 Redis 或 PostgreSQL 的 JSONB 字段);再将 Parent 切分为 Child Chunks,计算 Vector 存入 Vector DB(如 Milvus/Weaviate),并在 Metadata 中记录
parent_id。 - Read: 用户 Query 先在 Vector DB 中召回 Top K 个 Child Chunks;拿到
parent_id后,去 KV Store 捞出对应的 Parent Chunk。 - Deduplication: 如果多个 Child 指向同一个 Parent,在最终 Prompt 中需要对 Parent 进行去重。
三、 迷信向量搜索:稠密向量 (Dense Vector) 的局限性
痛点:
向量检索本质上是高维空间中的距离计算。它擅长捕捉语义(Sentiments/Topics),但对**精确匹配(Lexical Match)**极其拙劣。
- Case: 搜索 "SKU-2023-A",向量可能会召回 "SKU-2024-B",因为它们在语义空间里靠得很近(都是产品型号),但业务价值为 0。
- Case: 缩写、专有名词、错误码(Error Code),Dense Vector 往往会发生"语义坍缩"。
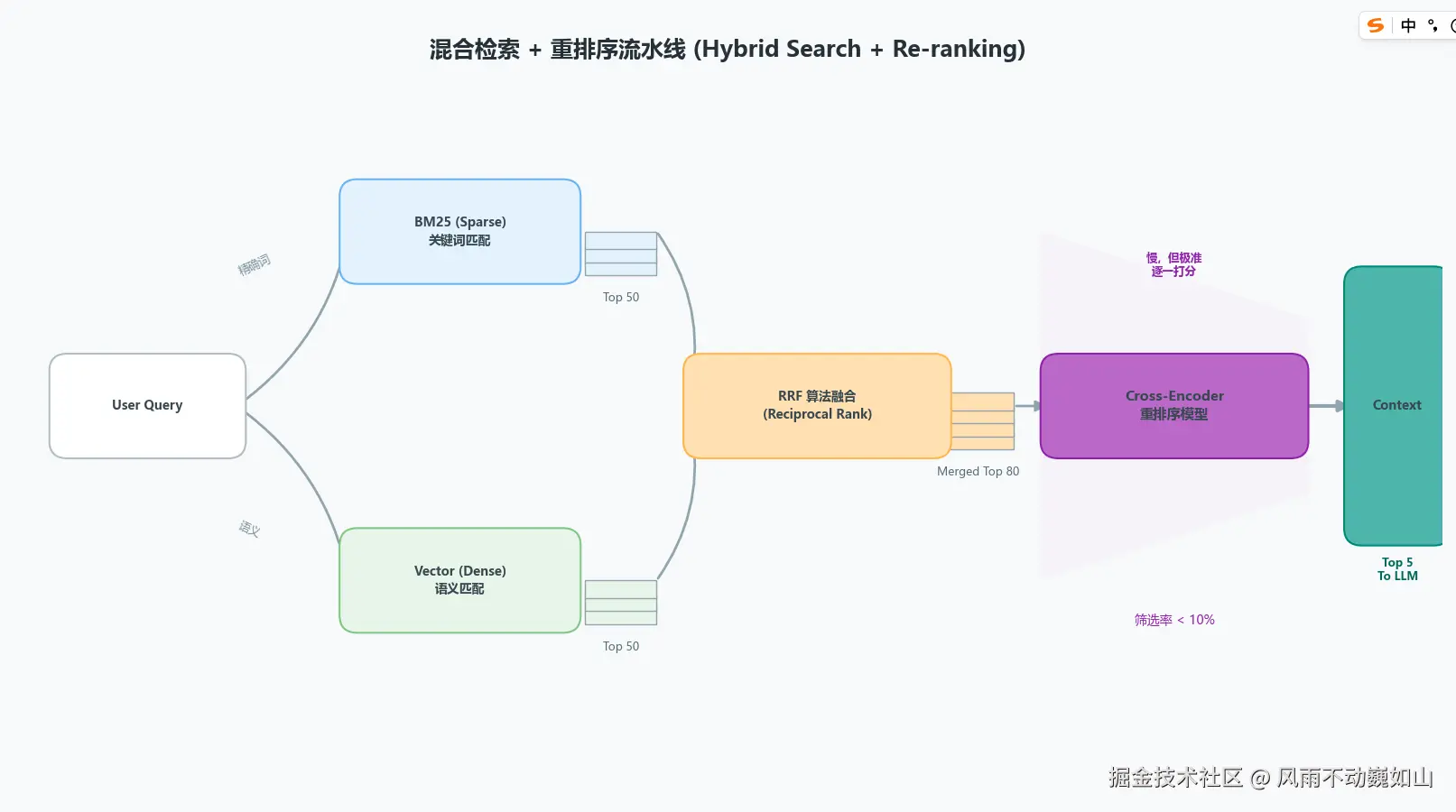
解决方案:混合检索(Hybrid Search) + 两阶段重排序(Rerank)
不要单用 Vector Search,生产环境的标准范式是 Sparse + Dense + Rerank。
-
混合检索 (Hybrid Search):
-
Sparse Vector (关键词路): 使用 BM25 或 SPLADE(Learned Sparse Retrieval)。它们基于倒排索引,对精确关键词、数字极其敏感。
-
Dense Vector (语义路): 使用 OpenAI Ada-002 或 BGE-M3。负责召回语义相关但用词不同的内容。
-
融合算法 (Fusion): 即使加权求和(Weighted Sum)也很难平衡两者的分数分布。最佳实践是使用 RRF (Reciprocal Rank Fusion) :
通过排名而非绝对分数来融合结果,通常设置 !
-
-
重排序 (Re-ranking) ------ 精度提升的关键一步:
Vector DB 为了速度(ANN, Approximate Nearest Neighbor)牺牲了精度,且通常采用 Bi-Encoder 架构(Query 和 Doc 独立编码,缺乏交互)。
- 策略: 在召回 Top 50 粗排结果后,引入 Cross-Encoder 模型(如
bge-reranker-v2-m3)。 - 原理: Cross-Encoder 将
[Query, Document]拼接到一起输入 Transformer,利用 Self-Attention 机制深度计算两者的相关性。 - 代价: 推理成本高,延迟大。所以只用于对 Top 50 进行精排,截取 Top 5 给 LLM。
- 策略: 在召回 Top 50 粗排结果后,引入 Cross-Encoder 模型(如
四、 最佳实践 CheckList (工程侧)
如果架构升级后依然存在 Bad Case,请检查以下微调细节:
1. Query Rewriting (HyDE / Multi-Query):
用户的输入通常是口语化且残缺的。
- Query Expansion: 利用 LLM 生成 Query 的 3-5 个变体(Synonyms)。
- HyDE (Hypothetical Document Embeddings): 让 LLM 假设性地生成一段"假答案",然后用这个假答案去向量库检索。这能让检索从"问题对答案"转变为"答案对答案"的相似度计算,显著提升召回。
2. 元数据过滤(Metadata Filtering):
不要让向量在全库中裸奔。在 Ingestion 阶段,必须提取 Metadata(年份、业务线、文档类型)。
- Pre-filtering: 在 ANN 搜索之前先根据 Metadata 缩小范围(HNSW 索引支持此类操作),既能提升准确率,又能降低计算量。
3. Embedding 模型微调 (Fine-tuning):
通用模型(General Embedding)在特定垂直领域(如医疗、法律代码)表现往往平庸。
- 实践: 收集业务中的 Query-Document 对(正样本)和 Hard Negatives(难负样本),使用 Contrastive Loss (对比学习损失) 对
bge-base进行轻量级微调。实验表明,仅需 1000 条高质量标注数据,Recall@10 就能提升 15-20%。
4. 可视化调试 (Observability):
盲目调整 Prompt 是无效的。必须接入 Tracing 工具(如 LangSmith, Phoenix 或自建 ELK)。
- Key Metric: 重点监控检索回来的 Chunk 的 Hit Rate (命中率)和 MRR(平均倒数排名)。不看实际召回的数据块,永远不知道为什么错。
总结
RAG 的门槛在 Demo,但护城河在 Data Pipeline。检索失败,90% 的原因不在 LLM 太笨,而在于数据工程太糙 和检索链路太短。
- ETL 侧: 用 CV 技术解决表格和布局,HTML 化是关键。
- 索引侧: 放弃单一索引,拥抱父子索引 (Parent-Child) 和多级索引。
- 检索侧: 迷信 Dense Vector 必死,Hybrid + Rerank 才是工业界真理。
做好这三层架构,你的 RAG 才能从"玩具"变成真正可交付的"企业级工具"。
写在最后
RAG 的优化是一个这就连着"算法下限"和"工程上限"的系统工程。从文档解析的 Dirty Work 到检索链路的精细化设计,每一个环节的疏忽都会在最终效果上被放大。
后面我会继续更新更多关于 企业级 Knowledge Base 构建 、高并发后端架构 以及 AI 落地实战 的复盘文章。
如果这篇文章对你的项目落地有帮助,求赞求关注。你的支持是我持续输出优质硬核内容的动力!