⭐ 深度学习入门体系(第 19 篇): 过拟合,它是什么?为什么会发生?又该如何解决?
------模型"太聪明"也会出问题
如果你学习深度学习一段时间,一定听过一个阴魂不散的词:
过拟合(Overfitting)
这个词实在太常见,但许多人对它仅停留在"模型记住训练集"这种浅层理解。
实际上:
- 过拟合并不神秘
- 它不仅仅是"记住训练集"
- 它是一种模型行为模式
- 它是深度学习的常见宿敌
- 但"过拟合本身"也蕴含极大的训练信息价值
今天我们用生活化语言讲清它的本质,让你以后一看到训练曲线,就能判断模型发生了什么。
文章目录
- [⭐ 深度学习入门体系(第 19 篇): 过拟合,它是什么?为什么会发生?又该如何解决?](#⭐ 深度学习入门体系(第 19 篇): 过拟合,它是什么?为什么会发生?又该如何解决?)
- [🧠 一、过拟合是什么?](#🧠 一、过拟合是什么?)
- [📉 二、从训练曲线看过拟合的典型表现](#📉 二、从训练曲线看过拟合的典型表现)
- [🔍 三、过拟合为什么会发生?](#🔍 三、过拟合为什么会发生?)
-
- [① 模型太大,数据太少(最典型)](#① 模型太大,数据太少(最典型))
- [② 数据分布不足以支撑任务](#② 数据分布不足以支撑任务)
- [③ 特征过于复杂、模型没有约束](#③ 特征过于复杂、模型没有约束)
- [④ 训练太久](#④ 训练太久)
- [🧪 四、如何判断发生了过拟合?(工程师必备)](#🧪 四、如何判断发生了过拟合?(工程师必备))
- [🛠 五、如何解决过拟合?(深度学习的"防腐剂大全")](#🛠 五、如何解决过拟合?(深度学习的“防腐剂大全”))
- [⭐ 方法 1:数据增强(Data Augmentation)](#⭐ 方法 1:数据增强(Data Augmentation))
- [⭐ 方法 2:更大的数据量](#⭐ 方法 2:更大的数据量)
- [⭐ 方法 3:减小模型大小](#⭐ 方法 3:减小模型大小)
- [⭐ 方法 4:Dropout(让模型"别太自信")](#⭐ 方法 4:Dropout(让模型“别太自信”))
- [⭐ 方法 5:Weight Decay / L2 正则](#⭐ 方法 5:Weight Decay / L2 正则)
- [⭐ 方法 6:早停(Early Stopping)](#⭐ 方法 6:早停(Early Stopping))
- [⭐ 方法 7:Batch Size 调整](#⭐ 方法 7:Batch Size 调整)
- [⭐ 方法 8:更好的初始化、优化器、学习率策略](#⭐ 方法 8:更好的初始化、优化器、学习率策略)
- [📌 六、工程上最常用的"过拟合解决模板"](#📌 六、工程上最常用的“过拟合解决模板”)
- [🎯 七、用一句最白话总结今天的核心知识](#🎯 七、用一句最白话总结今天的核心知识)
- [🔜 下一篇](#🔜 下一篇)
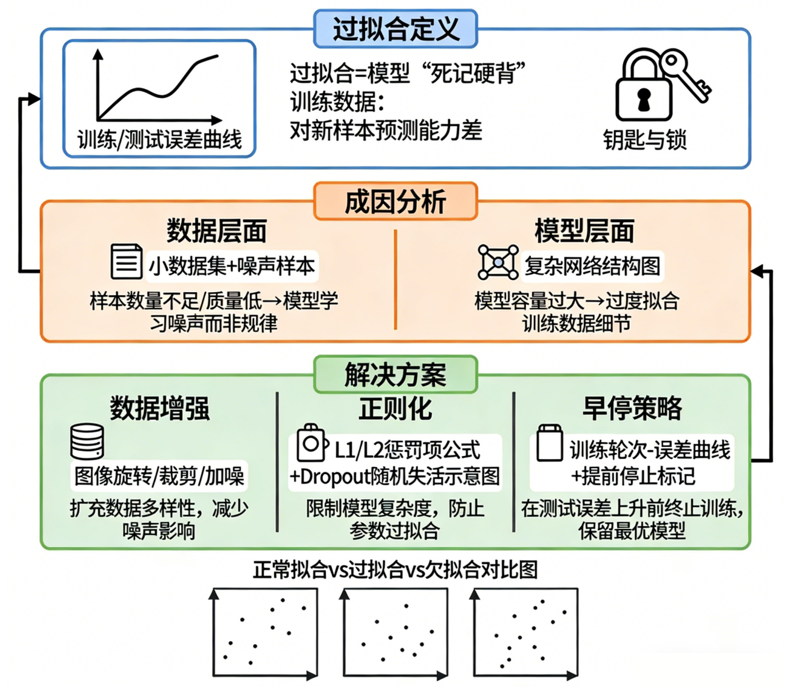
🧠 一、过拟合是什么?
一句最直白的话:
模型在训练集表现很好,但在新数据(验证集/测试集)表现变差。
换句话说:
模型"考前抱佛脚、背书很熟",但换一套题立刻露馅。
更生活化的类比:
- 有些学生死背题目,考试只要换题就不会
- 有些厨师只会做菜单上的东西,让他换素材就不行
- 有些驾驶员只会固定路线,一旦变道就慌了
模型也是这样:训练时表现很好,但一换数据(即使分布接近),能力就下降。
📉 二、从训练曲线看过拟合的典型表现
你一定见过这样的图:
- 训练集 loss 降得很快
- 验证集 loss 下降到一定点开始反弹
- 两条线越拉越开
这就是过拟合最经典的图像学表现。
为什么会变这样?我们继续向下解释。
🔍 三、过拟合为什么会发生?
理解过拟合不是难点,真正的关键在于:
你知道模型在哪些情况下更容易过拟合吗?
以下是过拟合最常见的成因。
① 模型太大,数据太少(最典型)
模型能力越强,能"记住"的东西越多。
当训练数据量不够时,它会直接背下来。
就像:
- 给博士生发一年级数学题,他肯定是满分
- 问题是,他真的理解了一年级数学吗?
深度模型也是如此:
数据太少时,它记住了答案,而不是学到规律。
② 数据分布不足以支撑任务
比如:
- 分类的"猫"图片都来自相同网站
- "狗"图片都来自室外
- "车"都在夜晚
- "人"只在白天
模型会学到"无关特征":
- 背景
- 光照
- 角度
- 摄影风格
这些都会成为"捷径",但对真实场景毫无帮助。
③ 特征过于复杂、模型没有约束
越复杂的模型越能记住细节纹理。
带 BatchNorm、LayerNorm 的现代网络,表达能力极强。
TensorFlow 的一句名言:
模型不是想拟合,而是太想拟合了。
没有正则的情况下,模型一下子全记住了。
④ 训练太久
即便模型一开始没背题,后来也会随着训练时间变长逐渐"刻进脑子"。
这就像:
- 第 1 小时在理解
- 到第 10 小时开始强行记忆细节
- 再继续就从"聪明"变成"死记硬背"
因此,训练时间也是重要因素。
🧪 四、如何判断发生了过拟合?(工程师必备)
以下任何一个都意味着"开始过拟合":
- val_loss 连续几轮上升
- val_acc 开始下降
- train_acc > val_acc 很多
- train_loss 下降而 val_loss 上升
- 训练集几乎完美准确率,但验证集很差
一句话:
训练集与验证集的表现差距,就是过拟合的信号。
🛠 五、如何解决过拟合?(深度学习的"防腐剂大全")
以下手段是深度学习工程里常见的"防过拟合武器库"。
我按"效果从强到弱、最实用到最补救"的顺序排列。
⭐ 方法 1:数据增强(Data Augmentation)
它本质是在"增加数据多样性"。
图像中的典型增强:
- 翻转、旋转、裁剪
- 光照变化
- 色彩扰动
- Random Erasing
- Mixup、Cutmix
- AutoAugment、RandAugment
- Albumentations 工程级增强
数据增强是所有 CV 项目中最强的抗过拟合手段,没有之一。
⭐ 方法 2:更大的数据量
无论做什么模型,永远成立一句话:
数据永远比模型更重要。
只是可惜,大多数时候我们没数据,只能依赖增强与正则。
⭐ 方法 3:减小模型大小
如果任务简单,模型太大反而适得其反。
典型:
- 猫狗分类用 ResNet101 是浪费
- 手写数字 MNIST 用 ResNet18 已经够大
- 工业异常检测模型过大反而吃背景噪声
根据任务选模型是工程的基本原则。
⭐ 方法 4:Dropout(让模型"别太自信")
Dropout 的本质:
随机让模型忘掉一部分神经元,让它学会"备份知识"。
就像学生做题时,老师随机把提示遮掉,让他独立思考。
Dropout 能显著减少过拟合。
⭐ 方法 5:Weight Decay / L2 正则
直白解释:
让模型的参数别太大,约束它是一个"简单函数"。
复杂函数往往拟合得太凶,限制参数大小能更平滑。
AdamW 已经把 weight decay 做成标配。
⭐ 方法 6:早停(Early Stopping)
非常简单但巨有效:
- 监控 val_loss
- 当它多轮不下降,就停止训练
好处:
- 节省时间
- 训练不会越走越坏
- 是所有 Kaggle 选手的常见做法
⭐ 方法 7:Batch Size 调整
一般来说:
- 小 batch 更有噪声,更不容易过拟合
- 大 batch 容易掉入坏谷底
如果模型在无限记细节,可以试试减少 batch。
⭐ 方法 8:更好的初始化、优化器、学习率策略
这些属于"间接影响",但也能缓解过拟合。
典型:
- Warmup
- Cosine Annealing
- AdamW
- Label Smoothing
- Mixup + Cutmix(非常有效)
这类技术通常在 SOTA 大模型中作为标配出现。
📌 六、工程上最常用的"过拟合解决模板"
如果你在实际项目中看到过拟合,可以直接按下面的顺序尝试:
- 增加数据增强
- 使用 0.1~0.5 dropout
- 加 weight decay(AdamW 默认即可)
- 减小模型 or 加强正则
- 加强数据扰动(Mixup/Cutmix)
- 多看验证集曲线,适时早停
- 如果显存允许,使用小 batch
基本上,过拟合不会再是问题。
🎯 七、用一句最白话总结今天的核心知识
过拟合不是"坏事",它是在提醒你:模型学得太细了,该让它更"通用"一点。
你需要做的,是往模型身上"加噪声、加约束、加多样性"。
如果理解了:
- 过拟合为什么发生
- 什么时候发生
- 如何检测
- 如何缓解
你就拥有真正的深度学习"训练能力"。
🔜 下一篇
第 20 篇将进入深度学习入门体系第一阶段的收尾篇:
《第 20 篇:如何从 0 到 1 训练一个稳定、可复现的深度学习模型(完整实践指南)》