为了解决多模态数学推理这一具有挑战性的任务,作者将 "慢思考" 理念融入多模态大语言模型(MLLMs)中。核心思路是让模型能够学习自适应地运用不同层级的推理能力,以应对不同复杂度的问题。作者提出了一种自结构化思维链(Self-structured Chain of Thought, SCoT)范式,该范式由语义最小的原子步骤构成。与依赖结构化模板或自由形式范式的现有方法不同,SCoT不仅能为各类复杂任务生成符合认知规律的思维链(CoT)结构,还能缓解简单任务中的 "过度思考" 现象。
为将结构化推理引入视觉认知过程,作者进一步设计了全新的 AtomThink 框架,包含四个核心模块:(i)用于生成高质量多模态推理路径的数据引擎;(ii)基于序列化推理数据的监督微调(SFT)流程;(iii)策略引导的多轮推理方法;(iv)用于评估单步利用率的原子能力指标。
大量实验结果表明,所提出的 AtomThink 框架显著提升了基线多模态大语言模型的性能,在 MathVista 和 MathVerse 数据集上实现了超过 10% 的平均准确率提升。与当前最先进的结构化思维链方法相比,所提出方法不仅准确率更高,还将数据利用率提升了 5 倍,推理效率提升了 85.3%。
论文:AtomThink: Multimodal Slow Thinking with Atomic Step Reasoning
项目地址:https://github.com/Quinn777/AtomThink
目录
背景概述
思维链(Chain-of-Thought, CoT)推理是一种关键范式,能显著提升大型语言模型(Large Language Models, LLMs)解决复杂科学问题的能力。该方法可在大型语言模型中催生中间推理步骤,前沿大型推理模型(Large Reasoning Models, LRMs)的重大进展便是例证。这些模型通过扩展推理链与测试时扩展来解决复杂问题,这一过程通常被称为 "慢速思考"。
近期研究聚焦于阐明前沿大型推理模型(LRMs)的内部推理机制。LLaVA-CoT 和 LlamaV-o1 等方法通过手动定义模板驱动的固定模块实现结构化思维链(Structured CoT),这限制了多模态场景下的推理多样性。相比之下,OpenAI-o1、DeepSeek-R1 等模型采用非结构化思维链(Unstructured CoT),该方法摒弃预定义框架,通过迭代优化自主生成动态的自由形式推理链。尽管非结构化思维链更贴近人类认知,且泛化能力更优,但近期研究表明,这类 "慢速思考" 模型在处理简单问题时存在令牌(token)利用效率低下和过度思考的倾向。如图 1 所示,两种范式均存在显著局限性。因此,作者确立了两项基本原则:不同问题需要不同的推理能力;为实现最优性能,推理链的复杂度应与问题难度相匹配。
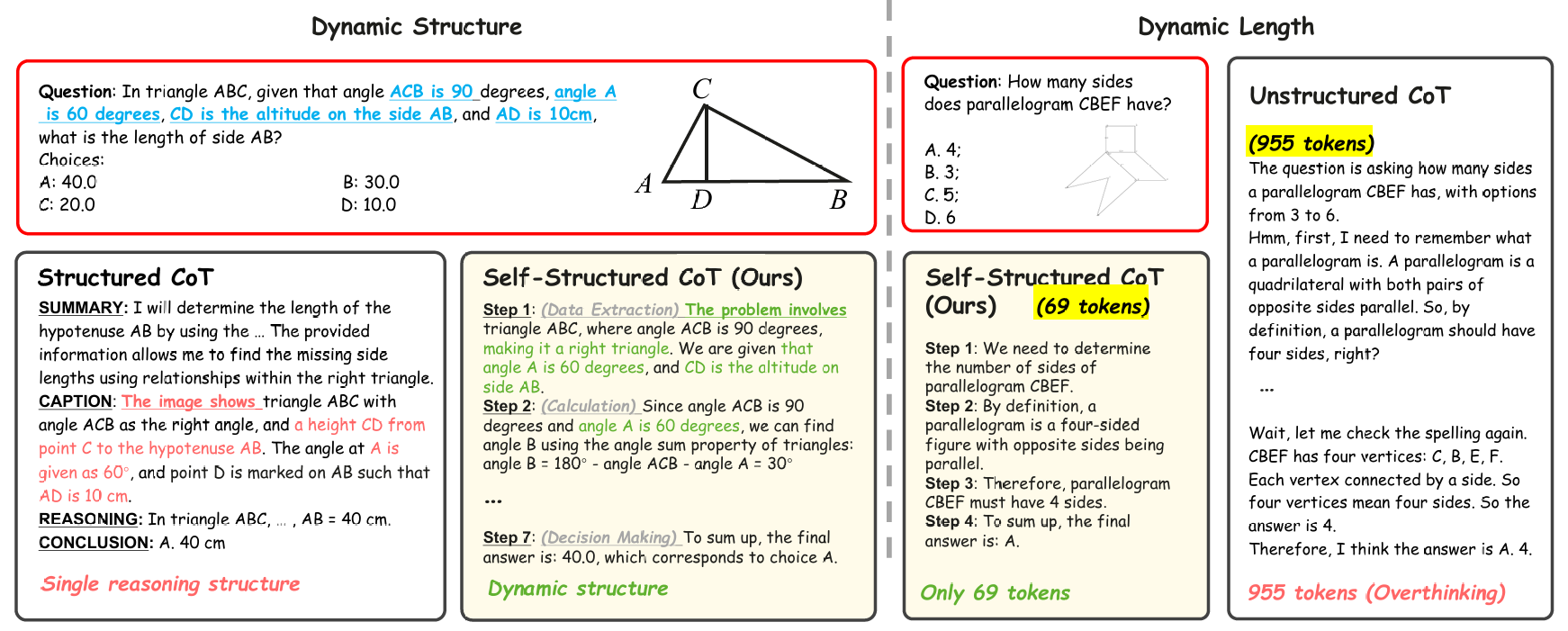
- 图1:与结构化思维链(Structured-CoT,即 LLaVA-CoT)和非结构化思维链(Unstructured CoT,即 Qwen-2.5VL-72B)方法的对比。结构化思维链遵循静态推理模板,即便对于文本主导的问题,也强制要求生成图像描述;而所提出方法可自适应选择跳过图像识别,直接从问题查询中提取信息(动态结构)。另一方面,非结构化思维链存在信息冗余问题,而我们的方法在简单任务上提升了令牌(token)利用效率(动态长度)。
为给不同复杂度的问题动态生成适配的推理结构,作者提出一种新颖的自结构化思维链(Self-structured Chain-of-Thought, SCoT)范式,该范式将推理过程分解为原子步骤。为激活模型在多模态任务中的自结构化推理能力,进一步开发了名为 AtomThink 的全流程慢速思考框架,其包含四大核心组件:数据引擎、监督微调、策略搜索与原子能力评估。
- 首先,利用具备新颖提示策略与错误案例过滤策略的数据标注引擎,构建了一个全新的多模态长思维链数据集 AMATH,该数据集包含 2 万个高阶数学问题及 12.4 万个原子步骤标注。
- 此外,原子步骤微调策略会对训练集进行步骤级掩码处理,迫使模型学习单个推理步骤。
- 在推理阶段,模型不仅能在快速思考模式下自主生成思维链,还能通过过程监督模型与步骤搜索机制持续优化。
- 最后,作者提出一种基于推理行为聚类与步骤利用率计算的原子能力评估指标,该指标可定量反映模型对单个原子步骤的利用能力。
为验证所提方法的有效性,作者在公开基准数据集上开展了大量实验。相较于基线模型,该方法在 MathVista、MathVerse 和 MATH-Vision 数据集上的准确率分别提升了 10.9%、10.2% 和 7.2%。在保持性能优势的前提下,该方法相较于此前的前沿方法 LLaVA-CoT,数据利用率提升了 5 倍,推理效率提升超过 80%。为推动多模态推理领域的研究进展,作者还对视觉理解模型所需的推理能力进行了全面的细粒度分析。
多模态推理中的CoT
数学计算等复杂推理任务长期以来一直是多模态大语言模型(MLLMs)面临的挑战。部分先前研究从提示工程的角度切入该问题,通过引导模型生成思维链(CoT)来提升其推理能力,这一方法已被广泛认可。这些研究通过精心调整输入分布,在不微调模型参数的情况下生成非结构化推理路径。近期,OpenAI o1 和 DeepSeek R1 通过强化学习引导模型自主学习推理模式,验证了非结构化思维链(CoT)的可扩展性。然而,这类推理模型仍存在过度思考和计算消耗过大的问题。另有研究通过提供人工设计的模板,引导多模态模型生成结构化思维链(CoT)。尽管这些模型将视觉语义信息融入了推理过程,但固定的步骤限制了推理行为的多样性,进而影响其在复杂问题上的泛化能力。
多模态数据的Long CoT标注
慢速思考的实现高度依赖高质量的步骤级标注数据。莱特曼等人(Lightman et al.)构建了一个包含大量人工标注的过程监督数据集,该数据集已被广泛应用于数学推理任务。近期的研究进展聚焦于自动化数据获取流程,让模型能够自主生成思维链(CoT)。 Quiet-STaR 等技术已证实,无需人工标注,通过模型自主生成推理过程即可提升性能。此外,部分基于蒙特卡洛估计的方法也实现了数据收集的自动化,但这类方法会带来额外的计算成本。在多模态领域,已有研究提出 MAVIS 数据集,该数据集包含 83.4 万个带短思维链(CoT)标注的视觉数学问题。另有研究从简短答案中提炼推理过程。然而,这些机器生成的标注往往过于简略,难以进行语义切分。
方法
本节将详细介绍 AtomThink 框架的具体细节,该框架通过自结构化思维链(self-structured CoT)提升多模态大语言模型(MLLM)的推理能力。如图 2 所示,AtomThink 包含四大核心组件,分别为自结构化推理机制(第 1 节)、数据引擎(第 2 节)、原子步骤微调流程(第 3 节)以及原子能力评估(第 4 节)。
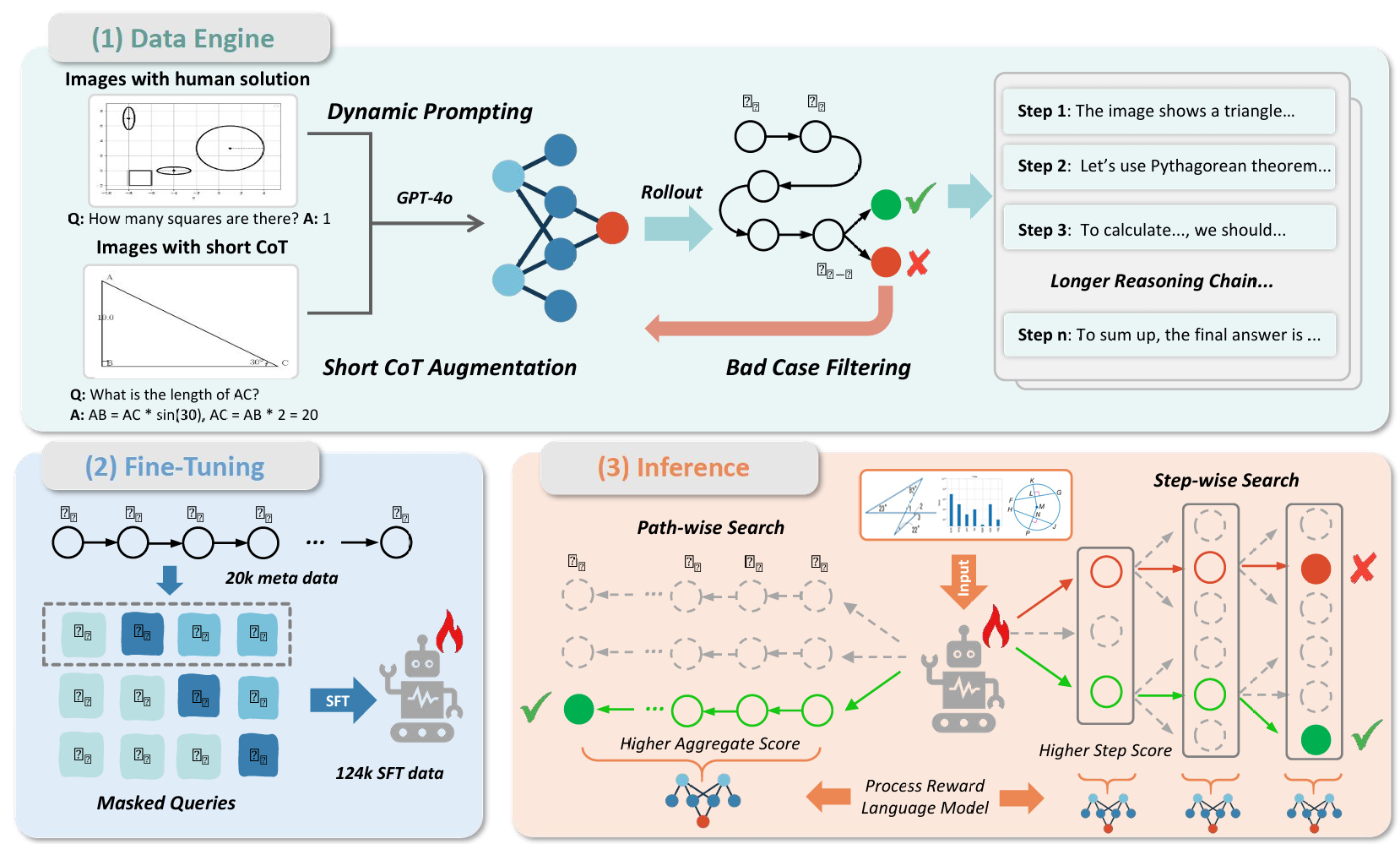
- 图 2:AtomThink 框架概述。首先对含长思维链(long CoT)的开源数据进行标注与过滤,生成用于微调及过程奖励模型(PRM)训练的原子步骤。推理阶段可采用步骤级或路径级搜索策略寻找最优方案。最终,通过 Kimi1.5 聚类得到 GPT-4o 的行为分布,并采用基于结果的方法对原子步骤利用率进行评估。
自结构CoT
为使多模态大语言模型(MLLMs)能够自适应生成多样化的推理路径,以应对各类问题并贴合人类认知模式,作者提出了一种基于自结构化思维链(Self-structured Chain-of-Thought, SCoT)的推理方法。与结构化方法不同,该方案不将模型限制在固定的思维模板或预定义的推理步骤序列中,而是赋予模型在推理阶段自主探索最优推理行为的能力。
多轮原子步骤生成
作者首先将具有语义一致性的最小预测动作定义为原子步骤(Atomic Step),该步骤可由单个句子或多个句子组合构成。以原子步骤为基本构建单元,提出一种多轮预测方法,用于迭代式自主生成具有动态结构的思维链。在推理过程中,引导模型每次仅预测一个最小原子步骤,从而聚焦于每个步骤的质量。随后,将当前预测结果追加至历史推理步骤中,并作为下一轮预测的上下文输入。基于自结构化思维链(SCoT)的推理模板详见附录 B 的图 12(Figure 12)。
由于模型遵循指令的能力存在局限性,我们在推理过程中经常观察到幻觉现象,例如原子步骤重复、步骤内语句冗余等。这些问题会导致推理过程陷入自循环与停滞状态。为此,采用以下方法进行异常检测与思维重启:
- 基于规则的过滤器:采用模板匹配与杰卡德相似度方法,量化评估步骤内及步骤间的语义重复程度,以此缓解推理循环现象。考虑到步骤内重复存在部分令牌(token)变异与匹配不完全的可能性,作者将步骤内允许的重复阈值设定为低于 45%,同时步骤间重复率需控制在98% 以下。此外,还定义了最大步骤长度与最大响应长度参数,分别用于限制单个原子步骤的长度上限与模型响应的长度上限。
- 温度累积机制 :检测到异常后,将重新执行单步推理,以替换错误的原子步骤。为提升输出结果的多样性,会在每次检测到错误时逐步提高温度参数,以此模拟人类认知中多样化的思维策略。

- 图12:AtomThink 是一种用于生成自结构化思维链的模板。该模型以图像和问题作为输入,在每次迭代中生成一个原子步骤。这些步骤随后被连接起来,形成历史推理步骤,并输入到模型中进行下一轮推理。
基于过程奖励模型的策略搜索
鉴于模型在推理过程中会自主分割原子步骤,一种自然的思路是引入过程奖励模型(PRM),以进一步拓展预测动作的搜索空间。与传统基于令牌或句子的搜索策略不同,这里以原子步骤为基本单元对候选动作进行采样。目前存在多种用于生成候选动作的搜索策略,将现有策略划分为路径级搜索与步骤级搜索两类。
在路径级搜索方面,我们借鉴相关前沿研究的方法,通过并行采样多条推理路径并对路径得分进行聚合,从而筛选出最优解。重点研究了以下两种方法:
- 多数投票法(Majority Voting):该方法通过选取多条推理路径中出现频次最高的结果,实现对多条推理路径的整合。其基本假设是,不同推理路径达成的共识更有可能导向正确答案。
- 最优采样法(Best-of-N) :给定一个生成式多模态大语言模型(MLLM),最优采样法会同时生成 n 条候选推理路径,并选取得分最高的路径作为解决方案。候选推理过程的评估由过程奖励模型(PRM)完成,该模型采用三种聚合方法,将细粒度的步骤得分映射为整条推理路径的综合评分:最差动作法 :对比所有候选推理路径中的最差步骤。该方法会对存在任意薄弱步骤的解决方案施加惩罚,适用于搜索对错误高度敏感的推理路径。最终动作法 :评分由推理阶段最终答案的预测结果得出。平均得分法:通过计算一条推理链中所有步骤奖励的平均值得到评分。此方法强调中间推理过程的可解释性与一致性,认为其重要性与最终结果相当。
步骤级搜索策略以一条初始路径为起点,针对每个原子步骤逐步拓展采样空间。该策略采用束搜索与贪心策略,对低质量的推理分支进行剪枝。
- 贪心算法:该算法侧重于在推理过程的每一步都做出局部最优选择。它会基于当前状态挑选出最优的即时动作(步骤),而不考虑未来可能产生的结果。
- 束搜索:该算法在每一步动作执行时都会探索多条推理分支,并在推理的每个阶段保留固定数量的最优候选路径。它在探索不同推理路径与利用最具潜力的路径之间实现了平衡。
表 8展示了不同策略搜索方法的对比实验结果。在主实验中,作者采用步骤级束搜索(step-wise beam search)的方法以延长推理时长。
数据引擎
引导多模态大语言模型(MLLMs)开展深度推理,需要大量高质量的思维链(CoT)数据。然而在视觉数学领域,公开可用数据集的稀缺性构成了一项显著挑战。为解决这一问题,作者开发了一个能够生成分步式长思维链的自动化数据引擎,构建出专属的原子级多模态数据集,并将其命名为AMATH。具体而言,该数据引擎引入了动态提示策略与短思维链增强策略,以生成多步推理路径。在此基础上,作者提出了一种难度评分机制,并搭配二次审核策略,用于筛选并剔除错误样本。
多模态思维链生成
针对长思维链的生成任务,提出两种基于提示的方法:
- 动态提示法:受近期相关研究启发,作者提出一种用于生成原子推理步骤的动态提示策略。具体而言,该策略驱动大语言模型(LLM)以迭代方式构建状态推理路径。每个路径节点代表一个推理步骤,涵盖前序阶段、当前状态以及一种可能动作。这类可能动作包括继续推理、核验与得出结论,其具体选择由大语言模型自主判定。相关提示模板详见附录 B。正如图 3 的问题 1 所示,该策略能够提升模型的推理性能,使其生成质量更高的思维链(CoT),同时降低错误率。
- 短思维链增强法:为充分利用视觉问答(VQA)数据集已有的短思维链标注,作者同样借助多模态大语言模型(MLLM),对这些标注进行原子化拆分与增强处理。该方法能够将原始推理过程进行语义层面的切分,转化为多个离散步骤,同时让模型在推理的每个阶段都聚焦于解决单个原子问题。正如图 3 的问题 2所示,作者解构了原始的推理范式,并融入了详尽的流程描述内容。
失败案例过滤机制
鉴于公开可用数据集内存在大量噪声数据,作者首先采用难度评分系统对问题进行筛选。随后,借助大语言模型(LLM)开展二次审核,以剔除存在错误的思维链(CoT)。
- 难度评分机制:为量化问题的难度,作者采用Qwen2-VL-7B为每个问题采样 N 个候选答案,并将这 N 个候选答案的胜率作为该问题的难度等级(本研究中 N=10)。为提升训练效率,剔除了大部分难度等级为 0 的问题。
- 二次审核:在生成思维链(CoT)后,作者利用 GPT-4o 开展二次审核工作,审核重点为原子步骤的准确性与最终答案的正确性。此外,还邀请两名专业标注人员对数据集进行抽样核查。正如图 3 的问题 3 与问题 4所示,该阶段能够修正或剔除大部分存在缺陷的样本,例如计算错误、图像识别失误等问题。
作者从 CLEVR、Geometry3K、MAVIS、TabMWP、GeomVerse、Mathv360k、GeoQA+ 以及 IconQA 这八个数据集里采样多模态推理数据。针对 GeomVerse 与 MAVIS 数据集,采用短思维链增强法进行处理;其余数据集则通过动态提示策略生成多步推理路径。本数据集的生成与过滤示例可参见图 3。

- 图3:本研究数据引擎生成高质量思维链(CoT)的案例分析。其中红色字符代表错误响应,绿色字符代表正确响应。与 GPT-4o 生成的基准版思维链(CoT)相比,本研究提出的动态提示策略在每个原子步骤中产生的幻觉现象均更少。借助现有的简短标注,我们能够拓展出包含更多细节的更长推理路径。此外,研究还在自动化生成流程中引入了失败案例过滤机制,用以筛查其中的低质量噪声数据。




- 图19:用于GPT评分的提示。作者使用此模板和GPT-4o模型对生成数据的质量进行定量评估。结果表明,AMATH数据在AI偏好评分方面优于人工标注数据。

- 图20:使用 Kimi1.5 对推理行为进行聚类分析。
有监督微调
为充分发挥多模态大语言模型(MLLMs)在求解多模态数学问题上的性能,作者基于原子分步推理的方式开展微调训练。具体操作上,先从 AMATH 数据集的元数据中拆分出思维链(CoT)并将其解构为原子步骤,随后采用序列化掩码策略,将这些原子步骤逐步融入历史推理过程,最终生成用于指令有监督微调的多组训练样本(记为 AMATH-SFT)。
原子能力评估
与人类解决问题的过程类似,分段式思维链(SCoT) 可能涉及多种推理能力。然而,传统的思维链(CoT)方法既不关注对单个推理步骤的遵循能力,也无法对其内在的各项推理能力进行细粒度分析。为填补这一空白,作者提出了原子能力评估策略,为推理研究提供了全新的分析视角。
作者的评估方法旨在从理解、运算、验证等多个维度,对目标模型的数学能力进行综合评估。为此,首先构建了一套标准化的能力指标体系。如图8所示,作者采集了 GPT-4o 在 AMATH 数据集上的行为分布数据,并借助 Kimi-1.5 模型开展聚类分析,最终得到若干聚类簇,每个聚类簇对应着高级智能模型在求解数学问题时所运用的一项特定能力。作者将每个聚类簇视为一个集合,并用 Set(a) 表示对应能力 a 的聚类簇。
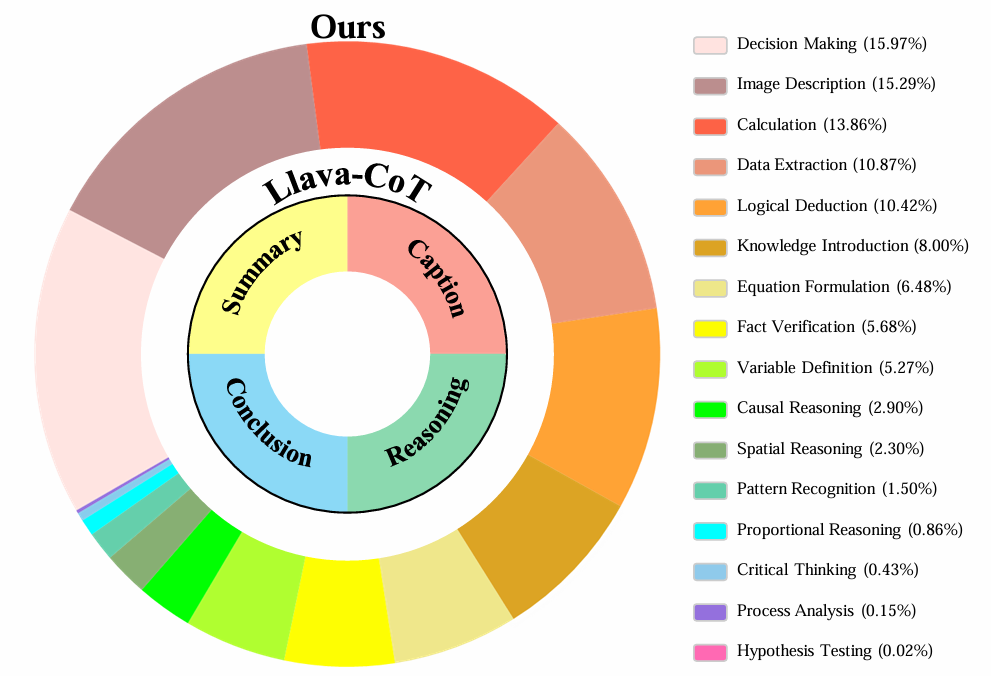
- 图8:AtomThink-LlamaV 和 LLaVA-CoT的推理步骤分布。
作者初步假设,具备更优异原子推理能力的模型,更善于利用近期的上下文推理步骤来进一步推导答案。因此,可以基于模型在对应能力集合中采样生成的推理路径、得出正确答案的平均概率,来量化模型的某项推理能力。
具体而言,假设某一问题存在 n n n个历史推理步骤 S = { s i ∣ i = 1 , . . . , n } S=\left\{s_{i}|i=1,...,n\right\} S={si∣i=1,...,n}。作者将步骤利用率 μ ( S ) \mu(S) μ(S)定义为:基于步骤集合 S S S 继续推理并得出正确答案的概率,该概率由 M M M 条采样推理路径的结果取平均得到,公式如下:
μ ( S ) = ∑ m = 1 M r m i s c o r r e c t M \mu(S)=\frac{\sum_{m=1}^{M}r_{m}\\thinspace is \\thinspace correct}{M} μ(S)=M∑m=1Mrmiscorrect其中, r m r_{m} rm代表第 m m m条采样推理路径。随后,计算不同历史步骤集合的利用率,并将对应的步骤集合 S S S映射回原子能力集合。作者对能力集合中每个类别的平均利用率进行计算,以此表征模型的原子推理能力:
S c o r e ( a ) = 1 ∣ S e t ( a ) ∣ ∑ S k ∈ S e t ( a ) μ ( S k ) Score(a)=\frac{1}{|Set(a)|}\sum_{S_{k}\in Set(a)}\mu(S_{k}) Score(a)=∣Set(a)∣1Sk∈Set(a)∑μ(Sk)
在本研究的实验中,作者从一个分布外数学数据集(R1V-Stratos)中选取了 160 个样本,构建了用于原子能力评估的测试集。
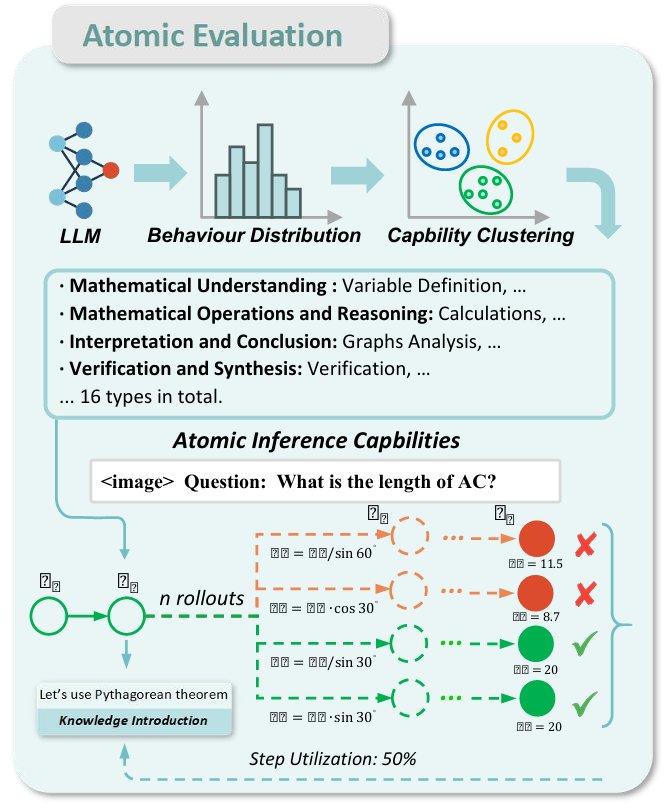
- 图 4:原子能力评估。各项能力来源于对 GPT-4o 模型行为的聚类分析。通过对每个原子步骤进行采样,并评估推理结果的可达性,我们为每个原子步骤赋予了一个表征其质量的软标签。
实验设置
基准模型
本研究的主实验采用了两款不同的开源多模态大语言模型,分别为 LLaVA1.5-7B 与 Llama3.2-11B-Vision。其中,LLaVA1.5-7B 通过多层感知机(MLP)投影层,将 CLIP-ViT-L/336px 视觉编码器与 Vicuna1.5-7B 语言模型进行连接,在学术导向的视觉问答(VQA)任务中表现优异。Llama3.2-11B-Vision 则以 Llama 3.1 语言模型为基础,通过交叉注意力层集成视觉适配器,具备强大的多模态推理能力。
作者从 LLaVA-665K 数据集中采样得到 10 万条多模态问答样本子集,基于该子集对上述两款模型的语言模型、投影层及视觉编码器开展全参数后训练,将训练后的模型作为基准模型。训练过程的学习率设为 2e−6,批次大小设为 128,训练轮次为 1 轮,最大上下文长度设为 4096 个词元。具体而言,本研究采用 Llama-factory 框架完成模型训练。
在有监督微调(SFT)阶段,作者引入了所提出的 AMATH-SFT 数据集,以赋予模型原子推理能力。此外,为开展补充实验,还基于 AMATH-SFT 数据集,对 LLaVA-Llama3-8B 和 EMOVA-8B 模型进行了进一步微调。详细训练参数详见附录 A。
本研究选取了 10 款主流多模态大语言模型进行性能对比,包括 Claude 3.5 Sonnet、OpenAI 的 o1、GPT-4o、GPT-4v,以及 LLava-NeXT-34B、InternLM-XComposer2、Qwen-VL-Plus、LLaVA-1.5-13B、LlamaV-o1-11B 和 LLaVA-CoT-11B。
评估方案
为验证本研究方法在提升多模态推理能力方面的有效性,作者在 5 个数学与科学基准测试集上开展实验,包括 MathVista、MathVerse、MathVision、MMMU 以及 HLE。
MathVista 是一个开源基准测试集,涵盖通用任务与数学专项任务两大领域。此外,引入 MathVerse 的目的在于评估模型对数学图表的敏感度。MathVision 则是一个包含多种复杂程度数学问题的基准测试集,将其纳入实验可专门用于评估原子步骤的动态变化情况。
MMMU 是一个综合性评估集,旨在针对需要专业知识与深度推理的大学级跨学科任务,对多模态模型进行评估;该数据集包含 1.15 万道多样化题目,覆盖 6 个核心学科以及 30 余种图像类型。我们还引入了当前难度极高的基准测试集之一 ------人类终极测试(HLE),以此评估模型在极端高难度条件下的推理能力。
推理设置评估
本研究的评估包含四种推理设置,分别为直接推理(Direct)、思维链推理(CoT)、SCoT 以及融合过程奖励模型的 SCoT w/ PRM。
在直接推理设置下,通过提示词引导模型生成简洁的最终答案。在思维链推理设置下,模型需按照指令,通过分步推理完成答题。针对直接推理与思维链推理这两种评估模式,采用的提示词均来源于 lmms-eval 工具库。
本研究提出的 AtomThink 系列模型额外支持两种推理设置:SCoT与SCoT w/ PRM。在SCoT设置中,模型完全基于所学策略,遵循单一的原子推理路径完成任务,不采用任何辅助搜索策略。在融合过程奖励模型的SCoT设置中,作者直接借助 Qwen2.5-MathPRM-7B 模型,为 LLaVA1.5-7B 与 Llama3.2-Vision-11B 这两款模型提供高质量的分步奖励。
此外,作者基于 Math-psa-7B 模型微调得到了一个全新的过程奖励模型,用于提供流程奖励。该模型以 AMATH-Metadata 数据集以及包含 2 万条样本的 PRM800K 数据集子集作为种子数据,负责为 LLaVA-Llama-8B 与 EMOVA8B 模型提供监督信号。
在分步束搜索过程中,设置的窗口大小为 3、候选样本数量为 2;在其他策略搜索方法中,候选样本数量则设为 3。在搜索过程中,每一步的温度系数初始值设为 0,且每完成一次候选样本采样,温度系数便增加 0.5,以此提升推理结果的多样性。