前言
在我司接到的具身订单中,有几个功能都涉及到仅给定像素目标下的导航,故对VLN一直保持着高度关注
本文咱们来解读NavDP
第一部分 NavDP:在特权信息引导下学习从仿真到现实的导航扩散策略
1.1 引言与相关工作
1.1.1 引言
如原论文所述,在动态开放世界中的导航是机器人一项基础但又具有挑战性的能力。为了追求具身智能通才,导航系统被期望能够在不同具身形态和非结构化场景之间实现零样本泛化
- 然而,传统的模块化方法受到系统时延和误差累积的影响,其性能受到限制;同时,高质量数据的匮乏也限制了基于学习的方法在训练规模扩展和性能提升方面的能力
尽管已有多项研究尝试通过在真实世界中采集机器人轨迹来解决这一问题 1, 2, 3,但扩展数据规模的过程依然耗时且昂贵 - 相比之下,仿真数据具有多样性且易于扩展
借助大规模的 3D 数字孪生场景 4, 5, 6, 7, 8, 9,可以高效地生成具有不同观测类型和目标的、可定制的无限导航轨迹
此外,随着 3D 资产的日益丰富以及神经渲染算法的快速发展,长期存在的仿真到现实(sim-to-real)差距问题也有望得到缓解 - 为了学习具有良好泛化能力的导航策略
模仿学习10]、11 通常依赖正向示范,但它们缺乏交互,无法纳入来自环境的负反馈
相比之下,基于强化学习(RL)的方法 12、13 可以通过带有奖励信号的交互进行学习,但数据效率较低
对此,来自1 Shanghai AI Laboratory、2 Tsinghua University、3 Zhejiang University、4 The University of Hong Kong的研究者提出了一种新颖的端到端Transformer 架构学习框架,用于结合IL和RL这两条路线的优势------Navigation Diffusion Policy(NavDP)
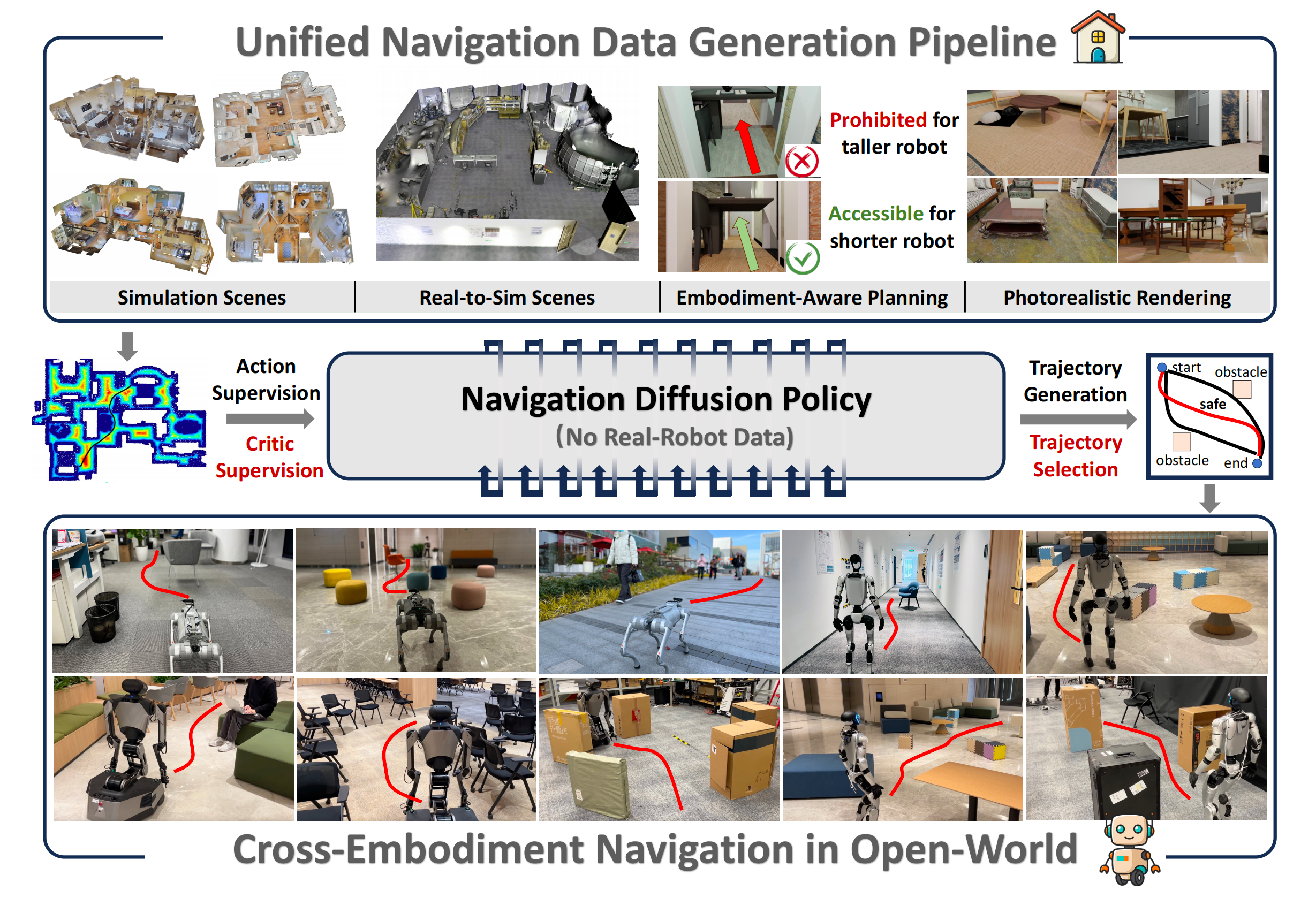
- 其paper地址为:NavDP: Learning Sim-to-Real Navigation Diffusion Policy with Privileged Information Guidance
其作者为
Wenzhe Cai1, Jiaqi Peng1,2, Yuqiang Yang1, Yujian Zhang3, Meng Wei1,4, Hanqing Wang1, Yilun Chen1, Tai Wang1, Jiangmiao Pang1 - 其项目地址为:navigation-diffusion-policy.github.io
其GitHub地址为:github.com/InternRobotics/NavDP
具体而言,其仅依赖仿真数据,就能实现零样本的从仿真到真实的策略迁移以及跨形体泛化
-
其提出的框架利用模仿学习的高效性和扩散过程的强表达能力,对专家示范的多模态分布进行建模
为实现反事实推理,作者借鉴强化学习中的评论家价值函数概念,训练 NavDP 同时为正向和负向轨迹预测状态-动作价值且框架可以从两个方面充分利用仿真中的特权信息:
一方面,可以在仿真环境中借助全局最优规划器的指导来训练轨迹生成;
-
为支持 NavDP 的大规模训练,作者开发了一套高效的导航数据引擎,单块 GPU 每天即可生成 2,500 条轨迹,其效率相比真实世界的数据采集提升了 20 倍
这使得能够构建一个覆盖 3,000 个多样化场景、累计导航里程超过一百万米的机器人导航经验综合数据集
1.1.2 相关工作
首先,对于机器人扩散策略
-
先进的生成模型在刻画机器人策略学习的多模态分布方面展现出巨大潜力。扩散策略 14 首次将扩散过程引入操作任务,由此激发了大量工作来提升其能力
这些改进涵盖多个方面,包括
状态表示15
16
17
18
推理速度
19
20
以及在多种机器人应用中的部署
21
22
23
24
-
然而,由于扩散策略是在离线模仿学习框架下运行,在真实环境中取得强性能往往依赖于真实世界中远程操作的示范数据集,这类数据集劳动密集且难以实现大规模扩展
相比之下,NavDP的方法完全基于可扩展的仿真数据集来学习机器人策略。为了增强泛化能力并确保从仿真到真实(sim-to-real)迁移过程中的安全性,作者引入了一个critic函数,用于估计策略输出的安全性。该机制利用带优先级的仿真数据,使扩散策略能够理解动作的后果,从而同时提升安全性和性能
其次,对于端到端视觉导航模型
-
近年来,端到端视觉导航模型在跨载体(cross-embodiment)适应和多任务泛化方面展现出显著潜力 25, 26, 27, 28,29, 30, 31, 32
这些方法在不同抽象层次上解决导航难题Vision-Language-Action(VLA)模型 30, 31, 32, 33 通过利用语言指令进行任务指定,从而提供了更大的灵活性
-
相比之下,端到端局部导航模型在跨载体泛化方面表现出色,并且在开放世界环境中具有实时推理能力,展现出更强的适应性 25, 26, 11
在本文中,作者专注于构建一种高效的端到端跨载体导航 System-1,它可以无缝地接入 VLM,从而在动态开放世界中执行具有良好泛化能力的导航任务技能
1.1.3 数据引擎
第一,对于机器人模型
作者将机器人建模为圆柱形刚体,并采用两轮差速驱动模型用于跨-具身泛化性
机器人的导航安全半径设为。为模拟不同机器人具身之间观测视角的变化,作者假设在机器人顶部安装一个RGB-D 相机,并将机器人高度
随机化在范围(0.25m,1.25m) 内
在导航轨迹规划过程中,高于相机设定高度的物体不被视为障碍物,为确保局部可导航区域始终处于视野之内,根据机器人的高度,将相机的俯仰角随机化在范围内
作者采用两种配置来设置相机视场
- 一种仿照RealSense D435i,将水平视场(HFOV) 和垂直视场(VFOV) 设为
- 另一种仿照Zed 2,将视场(FOV) 设为
第二,对于轨迹生成
为了生成无碰撞的机器人导航轨迹,作者首先将场景网格转换为体素地图,体素尺寸为0.05 m,以估计可导航区域的欧氏有符号距离场(ESDF)
-
可导航区域被定义为z 轴坐标低于阈值hnav 的体素元素,而障碍物区域被定义为z 轴坐标超过阈值hobs 的体素元素
阈值hnav 和hobs在不同场景中是变化的,并且取决于机器人高度hb。具有小于机器人半径rb 的距离值的体素会被截断以防止碰撞 -
可导航区域的ESDF 地图被下采样到分辨率0.2 m以实现高效的A* 路径规划
在可导航区域内随机选择导航起点和目标点,对于每个航路点
-
最后,使用三次样条插值将细化后的航路点平滑为连续的导航轨迹
第三,对于场景资产与渲染引擎
按照上一节所描述的处理流程,可以在多种多样的场景中,生成大规模的机器人导航轨迹数据集及其对应的 RGB-D 渲染结果
- 作者使用 BlenderProc 34 在导航轨迹上渲染具有照片真实感的 RGB 图像和深度图像。且从 3D-Front 6、HSSD 7、HM3D 8、Replica 4、Gibson 35 和 Matterport3D 5 中筛选出的 3,000 余个场景中收集导航轨迹
对于每个场景,作者采样 100 组起点与目标点对。且采用多种领域随机化技术以进一步提升数据多样性,其中包括光照条件随机化、视角随机化以及纹理随机化 - 经过数据筛选后,最终数据集包含超过 20 万条轨迹,总行进距离超过 100 万米
作者宣称,与以往的导航数据集相比,如表 I 所示,他们的数据在多样性与采集效率方面都具有显著优势。该数据集将在不久的将来开源发布
1.2 NavDP的完整方法论
NavDP 由一个用于融合 RGB 与深度观测的多模态编码器,以及一个同时用于轨迹生成和价值评估预测的统一 Transformer 网络组成
NavDP 的网络结构如图 2 所示『NavDP 以 RGB-D 观测和导航轨迹为条件。在训练过程中,根据 DDPM 调度器向真实轨迹中加入高斯噪声,并训练 actor 头去预测注入的噪声。同时,对真实轨迹进行增强,以构造既包含无碰撞场景又包含发生碰撞场景的轨迹,并训练 critic 头为这些轨迹分配对比得分』
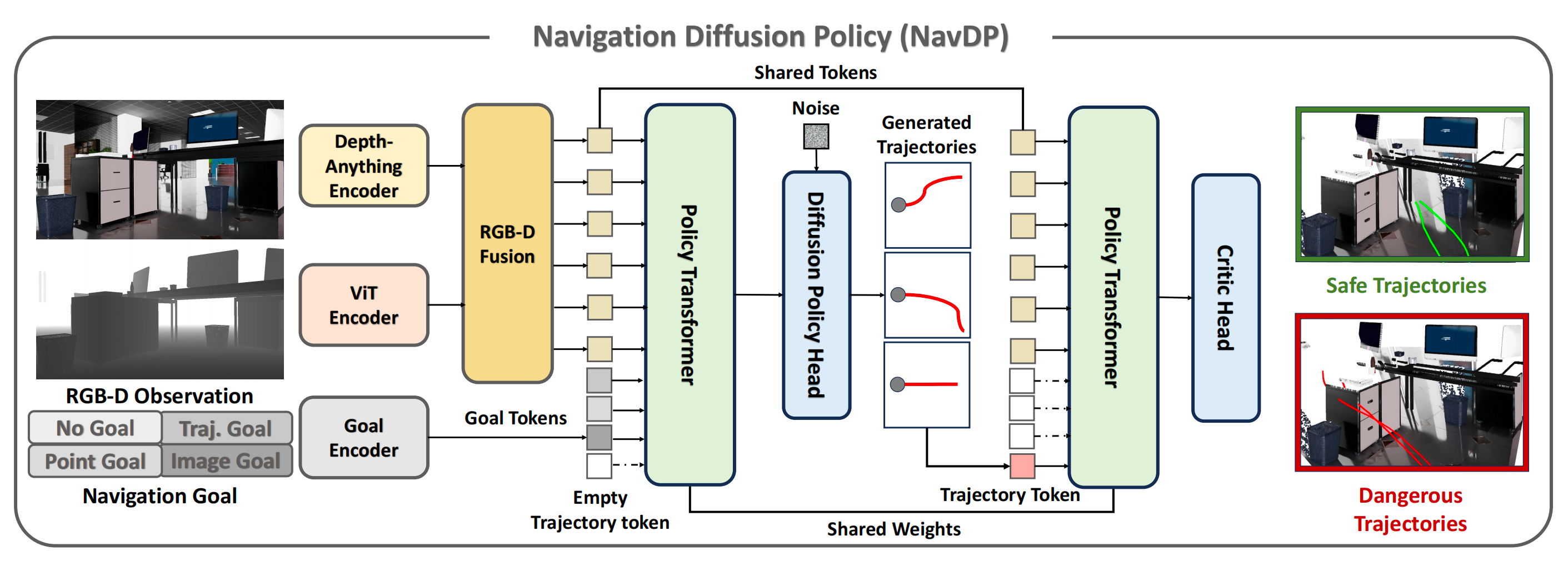
轨迹生成的目标是为机器人规划 个稠密航路点以供其跟随,而价值评估预测的目标是预测与轨迹安全性相对应的评分
1.2.1 多模态编码器
NavDP 以RGB-D 图像和导航目标作为输入
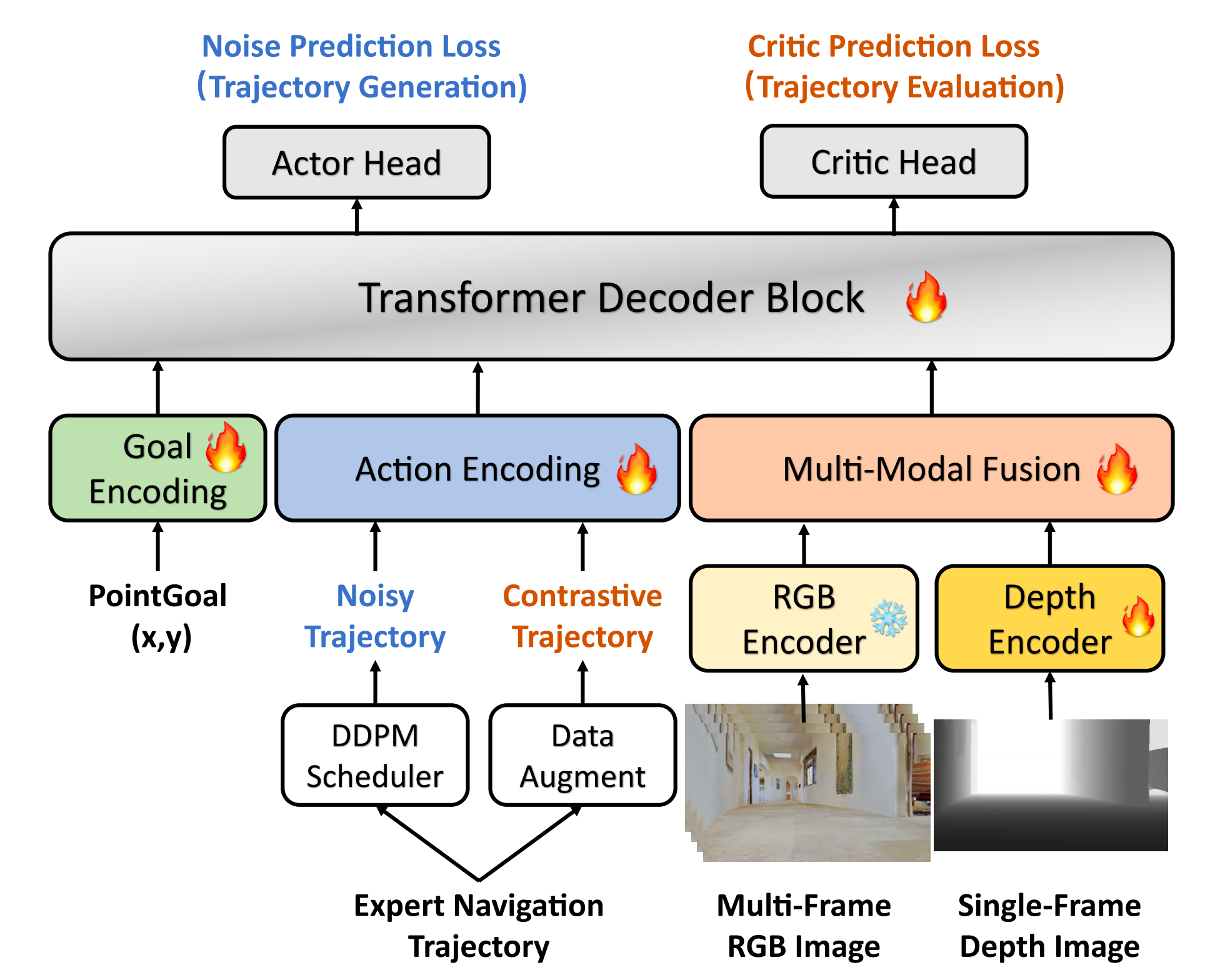
-
为融入历史信息,作者输入长度为N 的多帧RGB图像,并使用预训练的Depth Anything 37 编码器从每个RGB 帧中提取256 个patch token
后续,为了融合RGB-D 输入, 作者采用带有可学习查询的轻量级Transformer 解码器层, 将原始(N + 1) × 256 token压缩为N × 16 紧凑token
- 此外,导航目标遵循PointGoal 任务定义, 其中一个2 维向量
且采用MLP 层对导航目标进行编码, 并将其投影到与RGB-D token相同的维度空间中以进行后续处理
对于无目标任务, 作者则使用全零张量作为目标嵌入
1.2.2 Unified Policy Transformer
作者提出了一种简单而有效的、基于 Transformer 解码器的架构,该架构同时支持基于扩散的轨迹生成和轨迹评估
- 对于轨迹生成,其目标是在给定含噪轨迹条件下预测被注入的噪声
- 对于轨迹评估,其目标是在给定任意轨迹条件下预测一个得分
为此,作者采用一个基于 MLP 的动作编码器来提取轨迹嵌入,这些嵌入在交叉注意力机制中充当 queries,而融合后的 RGB-D tokens 连同一个表示扩散时间步的 token,在注意力过程中充当 keys 和 values
- 且作者使用多个Transformer 解码器层来处理输入 tokens,并为这两个任务各自设置独立的输出头。两个任务共享所有网络权重
差别在于输入的 queries,以及施加到 keys 和 values 上的注意力掩码 - 在轨迹生成任务中,queries 从含噪轨迹中提取,其中噪声是按照 DDPM 38 调度器加入的,并且交叉注意力会关注所有 keys 和 values
在轨迹评估任务中,queries 是从专家演示的轨迹中生成的,并施加随机旋转增强;同时,交叉注意力机制会排除时间步token
在推理阶段,NavDP 首先使用轨迹生成头生成一批候选轨迹,然后通过评估头从中选出最优轨迹,从而实现更安全的任务执行
1.2.3 训练细节
轨迹生成任务的训练目标是点目标任务和无目标任务中预测噪声的均方误差(MSE)损失的加权和
记 为去噪步骤,
为在时间步
按照DDPM 调度器采样的噪声,
为当前深度图像,
为RGB 观测,
为导航目标,
为无噪声的专家示范轨迹,
为整个数据集
-
则actor 头的损失函数可写为
作者默认设置 -
对于轨迹评估任务,作者基于轨迹路径点上的绝对ESDF 值和ESDF 值差异来定义标签评价值
具体地,记增强后的专家示范轨迹为
然后,将得分预测网络记为
整个 NavDP 网络在单阶段中以联合方式进行训练,其目标是最小化 L_act 和 L_critic 之和
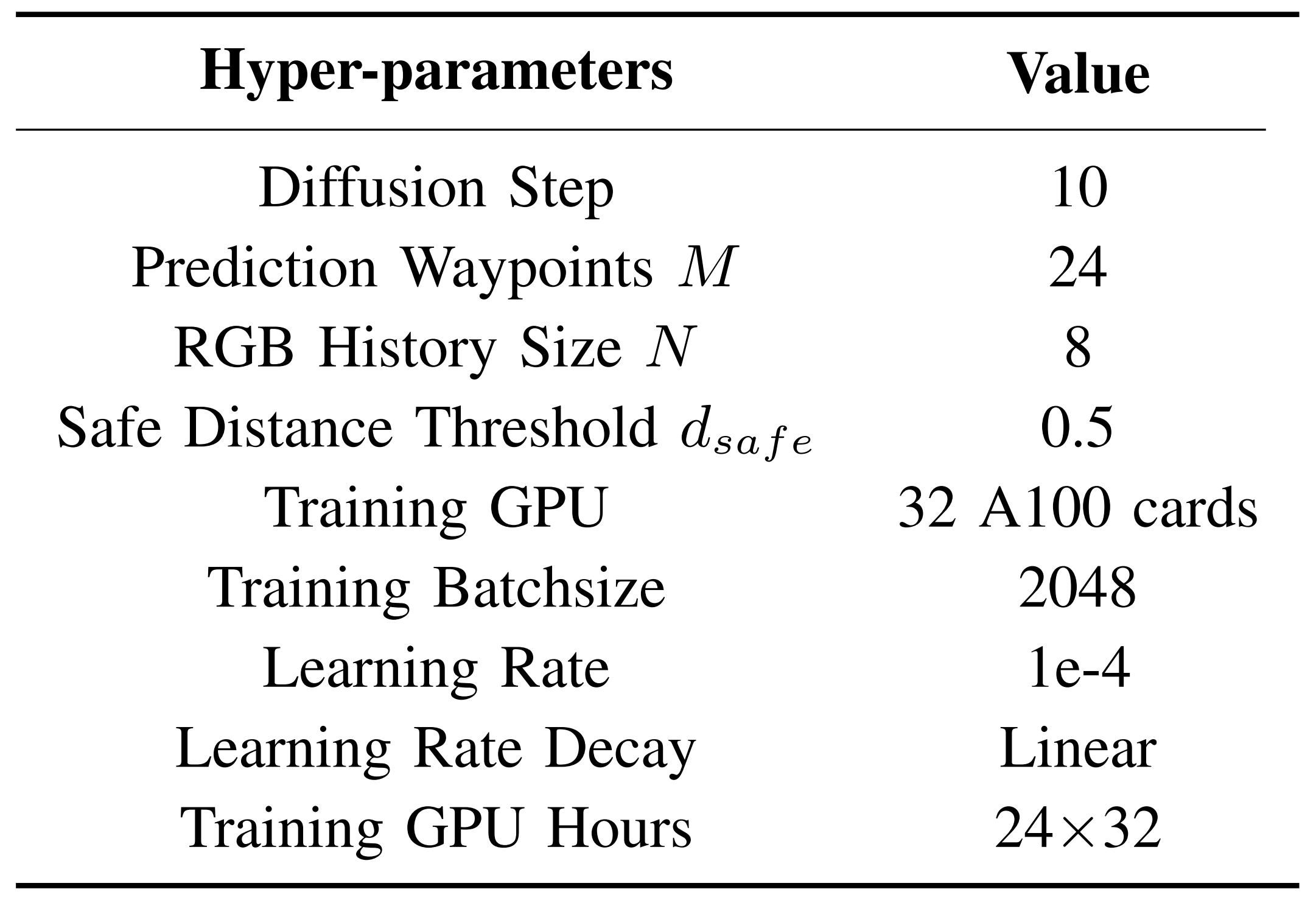
一些其他超参数如表 II 所示
// 待更