Calibre 连通性提取(Connectivity Extraction)核心内容总结
这份文档详细阐述了 Calibre 工具中连通性提取 的机制、关键操作、文本使用及增量连通性方案,其核心作用是识别布局中的电连接区域(Nets),为 DRC、LVS、xRC 等后续验证工具提供准确的电路连接信息。以下是分模块的核心要点梳理:
一、核心概念与基础机制
1. 连通性提取的定义
连通性提取会识别版图中称为 ** 网络(net)** 的电连通区域。通过分析版图图形与各层上其他对象(如文本对象)之间的关系,可从版图图形中识别出网络。
在连通性提取过程中,每个电网络都会被分配一个唯一的节点编号用于标识。除节点编号外,还可根据版图文本对象或规则文件中的文本语句为网络命名。
许多层操作要求预先建立设计的电路连通性,以确保输入层上存在正确的连通性信息。
Calibre 应用程序会利用连通性提取的结果,执行涉及连通性的层推导。为执行此类操作,验证系统会通过连通性提取操作自动计算电路连通性。
Calibre nmDRC、Calibre nmLVS、Calibre PERC、Calibre YieldEnhancer、Calibre YieldAnalyzer、Calibre xRC 和 Calibre xL 应用程序均会使用连通性提取功能
通过分析布局形状、层次结构及文本对象的关系,识别电连接的区域(Nets),每个 Net 分配唯一节点编号,并可通过文本对象或规则文件语句命名。
2. 掩模级连通性提取(Mask Connectivity Extraction)
掩模连通性提取会分析版图层级,并从掩模级图形中提取连通性。它仅作为内部子系统,由版图验证系统的其他组件(如 LVS 和 DRC)调用。
掩模连通性提取会在内部合并同一数据库层上的重叠图形和路径,且不保留对原始数据库对象的引用。层级化 Calibre 工具会先分析版图层级,再从完全扁平化的图形中提取连通性。
Calibre nmDRC 仅在内部使用连通性信息(不会为连通性提取数据生成持久化数据库),以执行依赖连通性的规则检查。需要连通性的层操作将在 **"需要层连通性的操作"** 章节中讨论。Calibre nmDRC 仅提取运行实际所需的连通性信息。
Calibre nmLVS 同样仅提取运行实际所需层的连通性信息。若使用 -flatten 选项,版图会被扁平化,并生成扁平化的版图 SPICE 网表。当指定 -lvs 选项时,LVS 比较为网表到网表的比较。其他运行时行为与 Calibre nmLVS-H 类似。
在 Calibre nmLVS-H 中,电路提取由命令行参数 -spice 触发,版图的层级化 SPICE 网表会被写入指定的路径。当版图系统为几何类型时,Calibre nmLVS-H 也会触发电路提取,提取的版图网表会被写入掩模 SVDB 目录 (若已指定),文件名为 layout_primary.sp;若未指定,则写入当前工作目录,文件名为 lvs_report_name.sp。
在 LVS 电路提取中,仅处理单元实例的外部图形(通常为引脚)。单元实例引脚对电路提取的贡献详见第 302 页的 **"端口和引脚的网表生成"** 章节。顶层单元的端口也会参与其中。
作为 LVS 连通性提取一部分的 ERC(电气规则检查),其行为与 DRC 连通性提取类似。
注Calibre 的连通性提取仅在 ** 掩模模式(Mask mode)** 下运行,而 ICverify 同时支持掩模模式和直接模式(Direct mode)。
-
处理逻辑:内部合并同一数据库层上的重叠形状和路径,不保留原始数据库对象的引用;分层工具会先展平布局,再从展平后的形状中提取连通性。
-
工具差异:
-
nmDRC:仅为需要连通性的规则检查提取必要的连通性信息,不生成持久化的连通性数据库。
-
nmLVS :仅提取运行所需层的连通性;通过
-spice参数触发电路提取,生成 SPICE 网表。 -
xRC:对 Stamp 操作的处理类似 Sconnect,需通过 Connect/Sconnect 语句建立寄生层与器件层的连接。
-
3. 规则文件编译的连通性要求
层需要满足以下条件之一才能具备连通性:
- 直接出现在
Connect或Sconnect操作中。 - 由节点保留操作 (如
AND、NOT)从满足条件 1 的层派生。 - 由节点保留操作从
Stamp操作派生,且Stamp的第二个输入层满足上述条件。
3.1. 触发连通性提取的操作
规则文件编译会验证:任何需要连通性的操作,其相应的输入层上是否具备必要的节点信息。
若要具备连通性,某一层必须满足以下条件之一:
-
直接出现在
Connect或Sconnect操作中。 -
由直接出现在
Connect或Sconnect操作中的层,通过一系列 ** 节点保留操作(node-preserving operations)** 推导而来。 -
由
Stamp操作,通过一系列节点保留操作推导而来。Stamp操作的第二个输入层(layer2)必须符合本列表中概述的条件之一。若条件 1 不适用于第二个输入层,则该第二个输入层不得出现在作为Connect或Sconnect操作参数的层的推导链中。
3.2 需要层连通性的操作
某些层操作要求其处理的层具备连通性。仅会为实际需要连通性的层提取连通性。
若某一层满足以下任一标准,则需要连通性:
- 该层出现在需要建立连通性的操作中。以下层操作要求其输入层建立连通性。这些操作会触发为出现在其中的层上的电网络分配节点信息。若某一 DRC 运行中未出现这些操作,则该运行不会提取连通性。
- 该层在
DEVice语句中作为 ** 引脚层(pin layer)** 出现。 - 该层出现在包含
NODAL关键字的 DFM 操作中。有关 DFM 操作的更多信息,请参阅《Calibre YieldAnalyzer 和 YieldEnhancer 用户与参考手册》。 - 该层作为节点保留操作的第一个输入层,且该操作的输出层需要连通性。这是一个递归标准。
表 1 依赖连通性的层操作

连通性提取在任何需要输入层连通性或向推导层传递连通性的层操作执行之前 ,以单个步骤完成。出现在 Connect 或 Sconnect 操作中的推导层,会在建立连通性之前优先生成。因此,若某一层由节点保留操作推导而来,且该层出现在 Connect 或 Sconnect 操作中,则该节点保留操作不会传递节点 ID。
上述规则有两个例外:
-
DRC Incremental Connect YES会使连通性在规则文件中分阶段推导。 -
若节点保留操作出现在规则检查的局部作用域中,且该操作推导的层需要连通性,则会传递节点 ID。例如:
CONNECT a b CONNECT c b = a AND d // global scope ... rule { b = c AND d // local scope; b gets c's node ID in the local scope ... }
二、电网络(Electrical Net)的识别方式
规则文件中的多个语句会在层上建立连通性。具备相同连通性的图形会被识别为属于同一个电网络。
1. Connect操作(双向连接)
互连层(interconnect layer)是指在规则文件的 Connect 或 Connect BY 操作中出现的层。 ****同一互连层上相邻或重叠 的多边形,始终被视为同一个网络的一部分(见图 1)。仅在角落接触的多边形,不被视为同一个网络的一部分。用于建立双向电连接,是最核心的连通性定义方式,支持两种场景:
-
直接连接:同一层上的邻接 / 重叠多边形(仅角接触不视为连接);不同层通过重叠 / 邻接直接连接。
-
通过接触层连接 (
Connect BY):两个互连层通过第三个接触层的共同交点建立连接(三者无共同交点则无连接)。
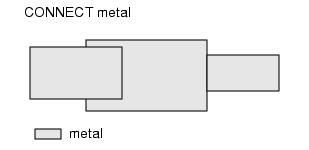
图1 Connected Shapes on a Single Layer
根据规则文件中 Connect 操作的指定,不同层上的多边形可通过重叠或相邻直接建立连通。同样,仅在角落接触的多边形无法形成有效连接。
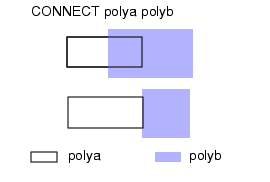
图2 Connected Shapes from Different Layers
两个互连层上的多边形,可通过与接触层(contact layer)上的第三个多边形相互交叠 ,实现彼此连通。这在规则文件的 Connect BY 操作中指定(见图 3)。若三个多边形(每个层各一个)没有公共的交集,则无法建立连接。
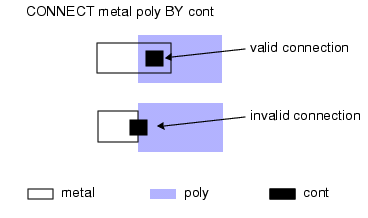
图3 Polygons Connected By Contact
关键问题:屏蔽效应(Shielding)
当 Connect BY 操作采用以下形式时,会产生屏蔽效应:
CONNECT layer1 layer2 layer3 ... layerN BY layerC其显著特征是,layerN 参数至少有三个。
当 Sconnect BY 操作在 BY 关键字之前包含两个以上 的层时,也会出现类似行为。以下讨论以 Connect 操作为例,但同样适用于 Sconnect 操作。
当 layer1 和 layerC 与 layer2 至 layerN 中的某一个第三层相互重叠时,layer1 和 layerC 之间始终会形成连接。在指定位置,layer2 至 layerN 中第一个 与 layer1 和 layerC 同时交叠的对象会参与连接;该范围内的其他层均不参与。
例如,在上述 Connect BY 语句中,仅当连接点处不存在 layer2 多边形时 ,layer1 和 layer3 之间才会建立连接。在某些情况下,这可能导致意外结果。
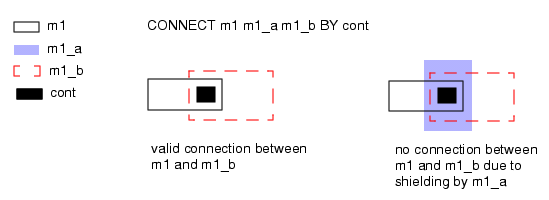
图4 屏蔽效应
在 Calibre nmLVS-H 中,图 4 中的 Connect BY 语句可能会破坏层次化单元(hcell)的连通性。在右侧图的示例中,连通性提取器必须搜索整个层级,以确定是否存在任何 m1_a 对象。若存在,则可能需要将那些无法确定连通性的 m1_b 对象从单元中提升(promote)到能够确定连通性的层级。这可能会导致不希望的副作用,如引脚提升,进而导致层次化单元中的连通性错误。此外,带有屏蔽效应的 Connect BY 语句会产生性能损耗。
对于带有屏蔽效应的 Connect 语句:
CONNECT a b c BY d消除屏蔽效应的最简单方法是拆分为:
CONNECT a b BY d
CONNECT a c BY d这是大多数情况下推荐的方法。
在某些情况下,下游的寄生参数提取工具可能要求为每个过渡单独分离接触 / 过孔多边形。若有此需求,可采用如下方式:
d1 = d INSIDE (a AND b)
d2 = (d NOT INSIDE (a AND b)) INSIDE (b AND c)
// 由于与 d1 推导的并发性,获取 "d NOT INSIDE (a AND b)" 无需额外开销
CONNECT a b BY d1
CONNECT a c BY d2然而,这种方法可能会增加接触 / 过孔层推导的内存和运行时成本。
在图 4 所示的案例中(m1_a 和 m1_b 是从 m1 推导而来的金属布线层),将 m1_a 和 m1_b 包含在 Connect BY 语句中是低效 的。相反,更好的做法是使用如下通用(且必要)的语句,在 m1 上建立连通性:
CONNECT m1 poly BY cont通过此类语句在 m1 上建立连通性后,即可使用 AND 和 NOT 等节点保留层操作 ,从 m1 推导出所需的任意层。例如:
// 这些层从出现在 Connect BY 操作中的 m1 继承节点信息。
m1_a = m1 AND a_layer
m1_b = m1 NOT b_layer通过这种方式,所有 m1 布线层的连通性都能得以建立,且不会产生屏蔽效应或低效 Connect BY 操作的问题。
在某些情况下,节点保留操作可能不适用,或者某一层可能由不保留网络 的操作推导而来。此时,Stamp 操作可能会有用。例如:
CONNECT m1
m1_a = SIZE m1 BY -1层 m1_a 不具备连通性,因为 Size 不是节点保留操作。此时可编写:
stamp_m1_a = STAMP m1_a BY m1对于此类场景,还有另一种有效的方法。在本例中,层 m1_a 确保包含在 m1 内部。可利用这种包含关系恢复连通性,如下所示:
copy_m1_a = m1 AND m1_a该方法的关键特征是:推导层(本例中为 copy_m1_a)必须是源层(本例中为 m1)的子集。
通常,应避免使用带有屏蔽效应的 Connect BY 操作 。然而,在涉及多个衬底层 的场景中,可能需要使用屏蔽效应。在这种情况下,Connect BY 操作通常会从芯片层剖面的横截面视角,自上而下列出各层。
-
触发条件 :
Connect BY后跟随≥3 个层(如CONNECT layer1 layer2 layer3 BY layerC)。 -
问题表现:连接优先级由层的顺序决定,前序层会屏蔽后序层的连接(如 layer2 存在时,layer1 与 layer3 不会通过 layerC 连接),可能导致意外结果和性能损耗。
-
解决方案:
-
拆分
Connect BY语句(推荐):CONNECT a b BY d; CONNECT a c BY d。 -
先通过
Connect建立基础层的连通性,再通过节点保留操作 派生其他层(如m1_a = m1 AND a_layer,继承 m1 的连通性)。
-
2. Sconnect操作(单向连接)
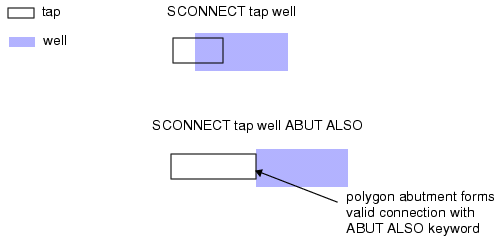
用于建立单向电连接 ,通常用于检测通过阱区域的高阻软连接 ,连接方向为上层→下层,下层从上层继承节点编号,反之不成立。
Sconnect 用于建立从上层到下层的单向连接 。Sconnect 通常用于检测通过阱区的软连接(高阻连接) 。连通性是单向的,从上层传递到下层。下层和接触层(若指定)从上层获取节点编号,绝不会反向传递 。当未指定接触层时,Sconnect 操作会在层重叠 时,形成从上层到下层的单向连接。若指定 ABUT ALSO 关键字,则相邻的多边形也可形成连接。仅在角落接触的多边形无法形成有效连接(见图5)。
图 5 Sconnect 操作
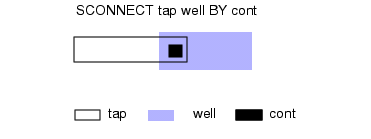
可通过指定接触层和多个下层,并使用 Sconnect BY 关键字来建立连通性(见图 10-6)。与 Connect BY 操作类似,三个层的三个多边形必须相交于公共点,连接才能有效。
图 6 Sconnect BY 操作
Sconnect BY 与 Connect BY 类似,也会受到屏蔽效应 的影响。在因屏蔽效应导致通过多边形提升建立连接的场景中,Sconnect 会尝试将连接推至适当的层级;但这无法得到保证。在某些情况下,多边形提升可能会导致层次化单元中的连通性问题。
因此,良好的实践是:在任何 Sconnect BY 操作中,仅包含三个层:两个互连层和一个接触层。
-
直接连接 :无接触层时,通过层重叠建立单向连接;指定
ABUT ALSO时,邻接多边形也可连接。 -
通过接触层连接 (
Sconnect BY):需满足三层(两个互连层 + 一个接触层)的共同交点,同样存在屏蔽效应,建议仅使用 3 个层(两层互连 + 一层接触)。
3. Stamp操作(冲压连通性)
Stamp 是一种层操作,用于 DRC 和 LVS 中,以创建一个从标记层(stamping layer)接收连通性信息的推导层。该推导层用于在两个不同层的重叠多边形之间传递逻辑连通性。
在以下示例中,Stamp 操作会选择所有与 metal1 多边形重叠的 polyc 多边形,这些多边形能够从 metal1 多边形接收有效的连通性信息。连通性信息会被分配给名为 x 的推导层。
x = STAMP polyc BY metal1
// x 是一个由 polyc 构造的推导层
// 带有 metal1 的节点信息这种类型的连通性允许 LVS 根据这些重叠,为 ** 有意器件(intentional device)** 分配网络编号。通过了解哪些有意器件位于哪些网络上,即可与原理图进行比较。
对于大多数涉及软连接(或 n 阱跳线)检查的应用,使用 Sconnect 语句优于使用 Stamp 。在某些专用 DRC 应用中,Stamp 可能会有用。
在 Calibre xRC 中,Stamp 操作基本上被视为 Sconnect 语句。然而,Stamp 操作的 BY 参数中指定的层通常是接触层,而在 Calibre xRC 中,不允许将接触层直接连接到任何其他层 。因此,所有将寄生层连接到器件层所需的层,都应在 Connect(或 Sconnect)语句中标识,该语句会提供为器件引脚产生有效连接点所需的所有连通性。
-
语法示例 :
x = STAMP polyc BY metal1(x 从 polyc 提取形状,从 metal1 继承连通性)。 -
适用场景:特殊 DRC 检查;LVS 中为有意器件分配网编号,用于与原理图对比。
-
注意 :LVS 软连接检查优先使用
Sconnect,xRC 中Stamp的处理类似Sconnect。
三、文本(Text)在连通性提取中的作用
版图数据库中存在的或在规则文件中创建的文本对象,会因多种用途被处理:
- 连通性提取中的网络命名。
- LVS、Calibre PERC 和 PEX 应用程序中的端口命名。
- 在
DEVice语句中使用TEXT MODEL LAYER和TEXT PROPERTY LAYER。 - 在 DRC 中使用
[Not] With Text和Expand Text操作。 - 使用
DRC Map Text YES,将文本对象映射到掩模 Calibre nmDRC-H 输出。
以下语句控制 Calibre 中的文本对象处理。
文本对象用于网命名 、端口命名 、器件语句中的文本层等场景,核心处理逻辑如下:
1. 网命名的来源
网络名称可在规则文件中指定 、作为文本对象写入版图数据库,或两种方式同时使用。
分配网络名称的典型方式是通过版图数据库文本对象 (如 GDSII 或 OASIS 等几何版图)。数据库文本对象会在连通性提取器中生成一个标签对象(label object) 。标签位置是数据库文本对象基准点的位置,标签层是该对象所在的层,标签名称是该对象的值。数据库文本对象必须与网络上的某个位置相交 ,才能将标签分配给该网络。版图文本对象是区分大小写 的(除非使用 Layout Preserve Case YES 语句)。若不使用 Text Layer 语句,则连通性提取不会读取任何版图数据库文本对象。
Text Depth 规范控制读取版图文本对象作为连通性提取文本的层级深度,默认值为顶层。来自层级较低层级的文本对象(来自已识别的文本层)会被转换到顶层坐标空间,并根据设计的层级结构进行复制。此类文本对象的行为就如同它们起源于顶层一样;这在扁平化和层级化应用中均成立。
在扁平化应用和 Calibre nmDRC-H 应用中,仅由 Text Depth 语句选择的版图数据库文本对象会在连通性提取器中使用。
在 Calibre nmLVS-H 中,无论是否指定 Text Depth 语句,设计层级中所有层级的文本对象都会作为其所在单元中的局部文本使用;此外,由此语句选择的文本对象还会充当顶层文本。
Text Depth 语句仅支持连通性提取;它不会影响规则文件中 With Text 操作使用的文本对象。
在规则文件中指定网络名称的方式有以下几种:
-
Text规范语句Text规范语句允许在规则文件中直接指定独立文本 ,而无需在版图中存在文本对象。它还允许编辑从版图数据库中读取的文本对象。标签具有指定的名称、x-y 位置和层。该标签仅适用于层级的顶层 。此语句仅用于 连通性提取。Text Layer和Text Depth语句不适用于 通过Text规范语句输入的文本对象。 -
Layout Text规范语句Layout Text规范语句仅在 版图系统为几何类型时适用。该语句允许在规则文件中直接指定基于单元的独立文本 。文本对象的行为完全如同 它存在于版图数据库中。标签具有指定的名称、x-y 位置、层和单元。坐标为单元坐标,默认值为顶层。此语句可用于 连通性提取以及其他用途。与任何数据库文本一样,Layout Text对象可在层级化和扁平化应用中使用。Layout Text File语句指定一个文件,其语法与Layout Text类似。在版图文本文件中指定的文本对象的行为类似于Layout Text对象。当需要在规则文件中指定大量文本时,应使用Layout Text File语句,而非Layout Text语句。Text Layer和Text Depth语句适用于Layout Text和Layout Text File语句。
Text 与 Layout Text 规范语句中文本对象的差异
Text语句对象始终位于世界坐标 中,且无单元关联;Layout Text对象使用单元坐标。Text语句对象可以覆盖 现有的数据库文本;Layout Text对象的行为与现有数据库文本完全相同。Layout Text对象遵循Text Layer和Text Depth要求(与用于连通性提取的任何数据库文本一样);Text语句对象不遵循。Text语句对象仅用于 连通性提取;Layout Text对象可用于With Text操作。Layout Text对象可以具有TEXTTYPES并遵循Layer Map语句;Text语句对象不可以。- 只有简单层号 可以与
Layout Text对象关联;Text语句对象可以具有原始层名称。
连通性提取默认不区分大小写 。例如,网络名称 "abc" 和 "ABC" 不会被单独生成网表(除非通过 Layout Preserve Case YES 语句请求)。在默认模式下,连通性提取器会选择这些标签中的一个,并丢弃另一个。被丢弃标签的网络会获得一个数字 ID。
标签名称会去除前导和尾随空白字符。若标签名称完全由空白字符或不可打印字符组成,则该标签会被丢弃。
Expand Cell Text 规范语句允许将源单元 实例中的文本添加到版图层级中更高层级 的目标单元(或多个单元)。可显式或隐式地指定目标单元。添加的文本对象会被转换到目标单元(或多个单元)的坐标中。此语句作用于 连通性提取文本和端口文本,不影响 With Text 操作。
2. 合并层上的逻辑信息
使用连通性提取的版图验证应用程序,会在对原始数据库层执行任何其他操作之前,在内部合并这些层。
在 LVS 中,这些合并层上的多边形会从相应原始层的图形和路径中继承端口和引脚信息,即:
- 对于连通性提取,源自端口图形或路径的内部合并层上的多边形,被视为属于该端口。
- 对于连通性提取,源自实例引脚图形或路径的内部合并层上的多边形,被视为属于该实例引脚。
合并完成后,会通过各种规则文件语句附加标签。
-
布局文本 :GDS/OASIS 等几何数据库中的文本对象,需通过
TEXT LAYER指定文本层,TEXT DEPTH指定分层读取深度。 -
规则文件文本:
-
Text语句:仅用于顶层连通性提取,不依赖TEXT LAYER/TEXT DEPTH,可覆盖布局文本。 -
Layout Text/Layout Text File:模拟布局文本的行为,支持分层,可用于With Text操作。
-
2. 标签(Label)附着的优先级
如前所述,连通性提取器会生成内部标签对象 ,以表示来自各种来源的文本数据:规则文件中的 Layout Text、Layout Text File 和 Text 规范语句,以及几何文本对象。每个标签由一个位置、一个层和一个名称表示。位置可以是一个简单的 (x,y) 点,也可以是数据库图形或路径的整个区域。
将标签名称分配给几何对象的三种主要方式:
Attach规范语句。- 给定
Connect层上与该层上多边形相交的文本标签。 Label Order规范语句。
这些方法不适用于 Text 语句。
Attach 操作将连通性信息从指定的原始数据库源层 (文本层)传递到出现在 Connect 或 Sconnect 操作中的指定原始或推导目标层 。Attach 最常用于以下场景:Attach 操作的第一个输入层(layer1)上的文本对象,映射到第二个输入层(layer2)上的重叠多边形。端口名称会随端口位置一起传递。在这些情况下,layer1 上的多边形和路径必须完全被layer2 上的多边形覆盖。仅会传递那些实际参与当前运行的特定版图验证应用的端口和引脚的位置及相关信息。同样,引脚位置会从一个层上作为引脚成员的图形和路径,传递到另一个层上的重叠多边形。有关更多信息,请参阅第 302 页的 **"端口和引脚的网表生成"**。
可指定 Label Order 规范语句,以确定连通性提取器查找与标签位置相交的图形的顺序 。Label Order 仅适用于未 出现在 Connect、Sconnect 或 Attach 语句中的文本层。
文本标签(网名称)按以下优先级附着到 Net 上,优先级高的方式覆盖优先级低的方式:
2.1 显式附着(Attach):
通过ATTACH A B将文本层 A 的标签附着到连通层 B 的重叠多边形上。
若规则文件包含以下操作:
ATTACH A B其中 A 是 Text Layer 参数(或 A 是包含标签层的层集),则连通性提取器会查找 layer B 上与标签位置相交的多边形。若找到,则将标签名称分配给包含该多边形的网络。
标签位置可以覆盖整个图形或路径的区域,且标签位置可能与 B 上属于两个或多个不同网络的两个或多个多边形相交。在这种情况下,会任意选择其中一个网络,将标签名称分配给该网络,并发出警告。
若 B 上没有多边形与标签位置重叠,则该标签会被忽略,并发出警告。
规则文件中可以包含多个针对同一标签层的 Attach 操作,例如:
ATTACH A B1
ATTACH A B2
...
ATTACH A Bn在这种情况下,连通性提取器会查找目标层 B1 至 Bn 中任意一个层上与标签位置相交的多边形。若恰好找到一个 多边形,则将标签名称分配给包含该多边形的网络。若找到多个 多边形,则任意选择一个并发出警告。若未找到任何多边形,则忽略该标签并发出警告。
示例:
TEXT LAYER poly.txt
CONNECT metal poly BY contact
ATTACH poly.txt poly
TEXT LAYER "text"
CONNECT m1 po BY co
ATTACH text m1
ATTACH text po2.2 隐式附着(Connect/Sconnect):
-
若规则文件包含以下操作:
CONNECT ... A ...其中 A 是
Text Layer参数(或 A 是包含文本标签层的层集),则连通性提取器会查找 layer A 上与文本标签位置相交的多边形。若找到,则将标签名称分配给包含该多边形的网络。示例:
TEXT LAYER metal // 该层上存在文本对象 CONNECT metal poly BY cont在此例中,metal 层上的任何文本标签,会在其文本对象与 metal 多边形相交的位置,隐式附加到 metal 层。
2.3 自由附着(Label Order)
LABEL ORDER ... B1 B2 ... Bn则 Label Order 操作中指定的层顺序会用于标签附加的优先级。连通性提取器会查找 Label Order 操作中指定的任意一个层上与标签位置相交的多边形。选择其层在 Label Order 操作中最先出现的多边形,将标签名称分配给包含该多边形的网络。
若任何层 Bn 出现在 Connect、Sconnect 或 Attach 语句中,则该层不会 参与来自 Label Order 的任何自由附加。
若规则文件中未 包含 Label Order 操作,或 Label Order 层中没有任何多边形与标签位置相交,则该标签会被忽略,并发出警告。
示例:
TEXT LAYER txt
CONNECT metal poly BY cont
LABEL ORDER metal polytxt 层上的标签,若标签位置存在 metal,则附加到 metal;否则,若存在 poly,则附加到 poly。
3. 开路与短路的报告
在 Calibre 应用程序中,会针对导致此类差异的文本标签报告开路和短路。
在 DRC 应用程序中,若指定,开路和短路会在运行日志 和DRC 汇总报告中报告。差异报告格式如下:
Open circuit. Label A2 used at location (-25,30) and ignored at location (5,30).
Short circuit. Label A2 at location (-25,30) used. Label B at location (-20,30) ignored.在 LVS 应用程序中,开路和短路会在运行日志 和电路提取报告中报告,格式如下:
WARNING: Open circuit - Same name on different nets:
Name: "A2"
(1) at location (-25,30) on layer 10 on net id 1
(2) at location (5,30) on layer 10 on net id 4
WARNING: Short circuit - Different names on one net:
Net Id: 1
(1) name "A2" at location (-25,30) on layer 10
(2) name "B" at location (-20,30) on layer 10
The name "A2" was assigned to the net.此外,这些差异会在提取的网表中,作为SPICE 注释,标注在差异发生的子电路内。
-
开路:同一标签名被分配到不同 Net(如标签 A2 出现在两个不连接的区域)。
-
短路:不同标签名被分配到同一个 Net(如标签 A2 和 B 出现在同一连接区域)。
-
报告位置:DRC 的运行日志和摘要报告;LVS 的运行日志、电路提取报告及 SPICE 网表注释。
四、增量连通性(Incremental Connectivity)与天线检查
天线检查(Antenna checks)是一类广泛的设计检查,旨在发现具有足够表面积的互连线路径,这些路径在制造过程中可能会积累过多电荷。这些路径被称为天线,可能会对制造过程中的良率产生不利影响。
本节讨论在使用 Calibre nmDRC 执行天线检查的背景下,与 ** 增量连通性(incremental connectivity)** 相关的一些细节。然而,这些方法也可应用于任何涉及增量连通性的问题。请注意,增量连通性仅适用于 DRC。
针对第 i 层金属沉积阶段的天线检查,必须忽略 由第 j 层(j > i)金属创建的连通性。由于对于非增量连通性提取,Connect 操作作为一个单一单元在执行模块开始时执行,因此必须复制层,以便为每一层金属有效划分设计的连通性。例如,考虑一个三层金属工艺的简单天线检查的规则文件流程:
diode = contact AND diff // 所有层级的扩散二极管。
cp1 = COPY poly // 用于第一层检查的复制层。
cg1 = COPY gate // 仅当规则文件中也存在
cm11 = COPY met1 // "标准"的 connect 操作集时,才需要进行此复制。
cc1 = COPY contact
CONNECT cp1 cg1 // 第一层检查的连通性。
CONNECT cm11 cp1 by cc1
cp2 = COPY cp1 // 用于第二层检查的复制层。
cg2 = COPY cg1 // 注意,我们在每个阶段复制之前的副本。
cm12 = COPY cm11 // 这确保每个阶段的层是真正不同的,
cc2 = COPY cc1 // 因为规则文件编译器会合并相同的操作。
cm22 = COPY met2
cv12 = COPY via1
CONNECT cp2 cg2 // 第二层检查的连通性。
CONNECT cm12 cp2 BY cc2
CONNECT cm22 cm12 BY cv12
cp3 = COPY cp2 // 用于第三层检查的复制层。
cg3 = COPY cg2
cm13 = COPY cm12
cc3 = COPY cc2
cm23 = COPY cm22
cv13 = COPY cv12
cm33 = COPY met3
cv23 = COPY via2
CONNECT cp3 cg3 // 第三层检查的连通性。
CONNECT cm13 cp3 BY cc3
CONNECT cm23 cm13 BY cv13
CONNECT cm33 cm23 BY cv23
// 第一层天线检查:
cdiode1 = cm11 AND diode // 扩散二极管。
m1_check = NET AREA RATIO cm11 cdiode1 == 0
// 仅检查未连接到扩散二极管的 m1。
rule1 { NET AREA RATIO m1_check cg1 > 300 }
// 第二层天线检查:
cdiode2 = cm12 AND diode // 扩散二极管。
m2_check = NET AREA RATIO cm22 cdiode2 == 0
// 仅检查未连接到扩散二极管的 m2。
rule2 { NET AREA RATIO m2_check cg2 > 300 }
// 第三层天线检查:
cdiode3 = cm13 AND diode // 扩散二极管。
m3_check = NET AREA RATIO cm33 cdiode3 == 0
// 仅检查未连接到扩散二极管的 m3。
rule3 { NET AREA RATIO m3_check cg3 > 300 }从功能上讲,这种方法是正确的,因为每组 Connect 操作中的所有层,都与任何其他组中的所有层不相交 。层的复制规避了默认行为(所有 Connect 操作在运行开始时作为一个单元一起执行)。这种方法有效地将电路划分为独立的网络集合,从而确保为天线检查正确建模连通性。也就是说,在每一层金属沉积阶段创建的网络,与在任何其他阶段创建的网络完全不相交。
然而,从性能角度来看,这是一个糟糕的解决方案,因为它需要大量的层复制和 connect 操作,会消耗大量内存空间。一些具有许多金属层(例如六层或更多)的超大型设计,无法在单次运行中完成检查,因此不得不在不同的运行中检查每个天线层级。
高效天线检查问题的解决方案是支持增量连通性。这意味着能够执行以下序列:
- 执行部分
Connect操作。 - 执行层操作,这些操作的连通性要求仅 来自步骤 1 中执行的
Connect操作。 - 执行更多的
Connect操作。 - 执行层操作,这些操作的连通性要求仅 来自步骤 1 和 3 中执行的
Connect操作。...n. 执行剩余的Connect操作。n+1. 执行层操作,这些操作的连通性要求来自所有Connect操作。
因此,利用增量连通性,上述示例的流程可修改如下:
示例 1 使用增量连通性的天线检查
DRC INCREMENTAL CONNECT YES diode = contact AND diff // 第一层天线检查: CONNECT poly gate CONNECT m1 poly BY contact CONNECT m1 diode m1_check = NET AREA RATIO m1 diode == 0 rule1 { NET AREA RATIO m1_check gate > 300 } // 第二层天线检查: CONNECT m2 m1 BY v1 // 同时也会改变 poly、diode、contact 和 gate 的连通性。 m2_check = NET AREA RATIO m2 diode == 0 rule2 { NET AREA RATIO m2_check gate > 300 } // 第三层天线检查: CONNECT m3 m2 BY v2 // 同时也会改变 poly、diode、contact、gate、m1 和 v1 的连通性。 m3_check = NET AREA RATIO m3 diode == 0 rule3 { NET AREA RATIO m3_check gate > 300 }
(在第一个示例中,未连接二极管只是为了尽量减少所需的复制和 connect 操作的数量。)请注意,这里没有层复制 ,且 Connect 操作的数量显著减少。然而,此方法依赖于规则文件开头指定的 DRC Incremental Connect YES(默认值为 NO)。若指定了 DRC Incremental Connect YES,则 DRC 执行会将规则文件视为具有部分从前到后的顺序,如下所示:
<layer operations> <- Connectivity zone 0
<connect operations>
<layer operations> <- Connectivity zone 1
<connect operations>
<layer operations> <- Connectivity zone 2
...
<connect operations>
<layer operations> <- Connectivity zone N在连通性区域 0 中,不允许 执行需要连通性的操作。对于 i > 0 的连通性区域 i,需要连通性的操作会将连通性视为仅 执行了连通性区域 i 之前的 Connect 语句。若某一连通性只能通过连通性区域 i 之后 的 Connect 语句建立,则在连通性区域 i 中,不允许执行需要该连通性的操作。
仅 DRC 应用程序支持增量连通性 。其他应用程序会忽略 DRC Incremental Connect 规范语句(在运行时,而非编译时),并像往常一样将规则文件视为与顺序无关 (且 Connect 语句为全局)。你有责任在涵盖多个应用程序的规则文件中,缓解可能存在的连通性冲突。添加增量连通性后,这可能需要更加谨慎。
随着 DRC Incremental Connect YES 的启用,连通性验证变得复杂得多 。需要其参数具备连通性的层操作包括:[Not] Net、Net Area、Net Area Ratio、Stamp、Ornet、指定了 BY NET 的约束多边形拓扑层操作、指定了 CONNECTED 或 NOT CONNECTED 关键字的 [Not] With Neighbor 以及节点尺寸检查操作。
相应参数的连通性,源于它们出现在 Connect 或 Sconnect 操作中,或通过一系列节点保留操作从 Connect 或 Sconnect 参数推导而来。增量连通性为规则文件添加了顺序依赖性 ,这意味着某一层的连通性只能 使用在规则文件中引用该层之前 出现的 Connect 操作来建立。更准确地说,增量连通性为连通性验证添加了以下规则:
-
在连通性区域 i 中定义的层操作,不得向前引用连通性区域 j(j > i),即不得具有在连通性区域 j 中定义的参数。
-
Connect参数必须在Connect操作之前定义。 -
使用增量连通性时,不允许 使用
Label Order和Sconnect操作。此模式导致的所有错误都会在编译时标记。 -
连通性区域 i 之后 的
Connect操作,不会用于验证在连通性区域 i 中引用的层的连通性。 -
节点保留层推导不得跨 连通性区域。例如,在启用
DRC Incremental Connect YES的情况下,以下内容是错误的:CONNECT m1 poly BY contact x = AREA m1 > 3 CONNECT m2 m1 BY via rule { NET AREA x > 10 } // x 的连通性在不同的连通性区域中验证。而以下内容是有效的:
CONNECT m1 poly BY contact x = NET AREA m1 > 3 // m1 的连通性在本区域中验证。 CONNECT m2 m1 BY via rule { AREA x > 10 } // 不需要 x 的连通性。
上述 1 至 5 条更严格的连通性验证规则,使得在指定 DRC Incremental Connect YES 时,Calibre nmDRC 应用程序中可以取消 两个现有的连通性限制。首先,在增量连通环境中,Connect 层可以从需要连通性的操作 推导而来,前提是该层的定义出现在 Connect 操作之前(比规则 2 的限制更宽松);这在非增量环境中始终是被禁止的。例如,以下结构(对于某些专用 DRC 检查可能是一项关键功能)是允许的:
DRC INCREMENTAL CONNECT YES
CONNECT metal1
x = NET metal1 VDD
CONNECT x // 开始一个新的区域。x 从需要连通性的操作推导而来是允许的。其次,在增量连通环境中,需要连通性的非 Connect 层 可以存在于 Connect 层的推导树中。例如:
DRC INCREMENTAL CONNECT YES
CONNECT x
y = AREA x > 2 // 层 y 需要连通性
rule { EXT y < 3 CONNECTED }
z = AREA y > 3 // 层 z 需要层 y
CONNECT z // 层 z 出现在 CONNECT 中;开始一个新的 CONNECT 区域这两个连通性限制的取消仅适用于 指定了 DRC Incremental Connect YES 的 Calibre nmDRC 应用程序。它不支持在 ICrules™ 中(即使 ICrules 支持增量连通性)。
规则文件编译器还会禁用跨连通性区域的操作等效性优化 。这对于增量连通性支持至关重要,以便以下示例中的 diode1 和 diode2 不会被优化为同一个操作:
CONNECT m1 poly BY contact
diode1 = contact AND diff
...
CONNECT m2 m1 BY via
diode2 = contact AND diff原因是,第一个区域中的 contact 层不一定 与第二个区域中的 contact 层相同。
为防止无意中创建具有错误连通性的层,并发线程不会跨连通性区域。
若指定了增量连通性,DRC 执行序列也会发生变化。默认执行序列简要描述如下:
- 为所有
Connect操作生成层参数。 - 执行
Connect操作,为所有需要的Connect层添加节点注释,并执行网络命名。 - 为所有 DRC 规则检查输出操作生成数据。
若指定了 DRC Incremental Connect YES,执行序列将变为以下伪代码:
For each connectivity zone from first to last {
1. 为定义该区域的所有新 `Connect` 语句生成层参数。
2. 执行定义该区域的所有新 `Connect` 操作,将新的连通性附加到现有连通性中。为该区域或之前区域中所有需要的 `Connect` 层添加节点注释。若该区域中存在 `[Not] Net` 操作,则基于现有连通性执行网络命名。
3. 为该区域中的所有 DRC 规则检查输出操作生成数据。
4. 为该区域中的所有被引用的连通性层操作生成数据。
}请注意,要求在区域内执行该连通性区域中被引用的连通性层操作(如果尚未执行)。这是为了捕获该区域的连通性,并在以后正确满足对该区域的反向引用。
4.2 增量连通流程中的虚拟连接
在启用 DRC Incremental Connect YES 的 Calibre nmDRC-H 中,默认情况下,虚拟连接(virtual connection)仅在最后一个 Connect 块内执行,或在当前 Connect 块与后续块之间存在 [Not] Net 操作的 Connect 块内执行。
Virtual Connect Incremental YES 语句会使虚拟连接全局应用 于所有连通性区域。此语句不适用于 Calibre nmDRC(扁平化),因为在扁平化增量流程中,虚拟连接始终应用于所有 Connect 块内。
4.2 增量连通性与运行时效率
使用增量连通性时,采用一些规则文件组织方法可以获得更好的运行时性能:
- 将用于连通性的层推导放在规则文件的开头附近 。例如,将它们放在通常位于规则文件开头的、以
Layout和DRC开头的规范语句之后。 - 将增量连通序列放在规则文件中紧随步骤 1 中的层推导之后的独立部分。仅将需要连通性区域的规则检查(如天线检查)放在此部分。
- 将使用全局连通性模型 但不需要增量连通区域的规则检查,放在规则文件的增量连通部分之后。
- 将不需要增量连通性的层推导和规则检查,放在步骤 3 中的规则检查之后。
建立全局(或大量)连通性、断开该连通性(使用 Disconnect),然后在规则文件的后面建立增量连通性,这种做法是低效 的。组织良好的规则文件通常可以完全避免使用 Disconnect。
大多数现代设计都需要在多线程环境 中使用增量连通性,并启用超大规模并行(命令行上使用 -turbo -hyper)。小型设计模块可能不需要这样做。
4.3 增量连通的连通性提取警告抑制
在某些情况下,需要在增量连通流程中抑制连通性提取警告 。例如,在天线检查流程中,任何警告(可能数量众多)都可能被视为误报。此外,由于某些原因,中间连通性区域中由 [Not] Net 操作导致的警告也可能被认为是不需要的。
Calibre nmDRC 通过 DRC Incremental Connect Warning 规范语句提供连通性提取警告抑制功能。该语句有 ENABLE 和 DISABLE 两个选项,可在规则文件中多次指定,以控制哪些连通性区域在运行期间报告警告。例如:
DRC INCREMENTAL CONNECT YES
// 第一个连通性区域
// DRC INCREMENTAL CONNECT WARNING ENABLE 是默认设置。
// 会输出连通性警告。
CONNECT ...
CONNECT ...
<layer operations>
...
DRC INCREMENTAL CONNECT WARNING DISABLE
// 禁用连通性警告,直到再次启用。
CONNECT ...
CONNECT ...
<operations involving NET or NOT NET>
...
DRC INCREMENTAL CONNECT WARNING ENABLE
// 恢复警告。
CONNECT ...
CONNECT ...
<operations>4.4 断开操作(Disconnect Operation)
连通性提取操作 Disconnect 允许在增量连通序列中完全删除 现有的连通性模型。也就是说,Disconnect 操作的存在会导致当前的连通性累积停止 。下一个 Connect 操作将开始新的连通性累积。
在增量连通流程中,通过合理安排 Connect 操作的顺序,以及仔细复制 Connect 层,Disconnect 操作很少有用 (请参阅 **"增量连通性与运行时效率")。然而,在某些 非常高级的 DRC 检查 ** 中,必须完全丢弃任何现有的连通性,此时 Disconnect 操作是必不可少的。这在大多数天线检查中通常不成立。
在存在 Disconnect 操作的情况下,会对增量连通设置中层的编译时连通性验证算法进行适当修改。例如,无法跨任何 Disconnect 操作验证某一层的连通性。
1. 核心需求
天线检查需要按金属层沉积顺序 验证连通性(如金属 1 的检查需忽略金属 2 及以上的连接),传统方法需大量复制图层和Connect操作,导致内存和性能问题。增量连通性 通过分阶段执行Connect操作,解决该问题。
- 启用方式
在规则文件开头添加:DRC INCREMENTAL CONNECT YES(仅 DRC 支持,其他工具忽略)。
- 执行流程
规则文件被划分为多个连通性区域(Connectivity Zone) ,每个区域的连通性仅依赖于之前区域的Connect操作:
- 执行部分
Connect操作 → 2. 执行该区域的层操作和规则检查 → 3. 执行更多Connect操作 → 4. 执行下一个区域的检查 → ...
- 优势 :无需复制图层,大幅减少
Connect操作数量,提升性能。
4. 关键注意事项
-
节点保留操作:不能跨连通性区域,否则会导致连通性验证错误。
-
虚拟连接 :默认仅在最后一个
Connect块或包含[Not] Net操作的块中执行;通过Virtual Connect Incremental YES可全局启用。 -
Disconnect 操作 :完全删除当前的连通性模型,后续
Connect操作重新建立连通性,仅用于高级 DRC 检查。 -
警告抑制 :通过
DRC INCREMENTAL CONNECT WARNING DISABLE/ENABLE分区域控制连通性警告的输出,避免天线检查中的大量误报。
五、关键辅助操作与语句
1. 层复制(COPY)
传统天线检查中用于创建独立的图层副本,确保不同连通性区域的图层不重叠,增量连通性启用后可大幅减少使用。
2. 节点保留操作(Node-Preserving Operations)
包括AND、NOT、INSIDE等,派生层会继承原始层的连通性信息 ,是构建复杂连通性的核心工具。非节点保留操作(如SIZE)会破坏连通性,需通过Stamp或AND操作恢复。
3. 文本处理相关语句
| 语句 | 作用 |
|---|---|
TEXT LAYER |
指定用于连通性提取的布局文本层 |
TEXT DEPTH |
指定读取布局文本的分层深度 |
Layout Preserve Case |
控制网命名是否区分大小写(默认不区分) |
Attach |
显式将文本层的标签附着到连通层 |
Label Order |
指定自由附着时的层优先级 |
六、常见应用场景
-
DRC 天线检查:通过增量连通性分阶段验证各金属层的连通性,避免高层金属对低层的干扰。
-
LVS 电路提取 :通过
Connect/Sconnect建立布局的连通性,结合文本标签生成 SPICE 网表,与原理图对比。 -
xRC 寄生参数提取 :通过
Connect/Sconnect建立器件层与寄生层的连接,确保寄生参数计算的准确性。