话不多说,直接开始
JVM本质上是一个进程,会维护自己的内存区域
1、JVM运行时数据区域
堆、栈(本地方法栈、 虚拟机栈)、方法区、程序计数器
- Heap:堆区,对象的实例以及数组的内存都是在堆上进行分配的,堆是线程共享的一块区域,也是垃圾回收的主要区域;开启逃逸分析后,某些未逃逸的对象可以通过标量替换的方式在栈中分配
-
- 堆细分为:老年代、新生代
- 对于新声代又分为:Eden区和Surviver1和Surviver2区
- 方法区:JVM的方法区也称之为永久区,它存储的是已经被Java虚拟机加载的类信息、常量、静态变量;JDK1.8以后取消了方法区这个概念,称之为元空间(metaSpace)
当应用中的java类过多时,比如Spring等一些使用动态代理的框架生成了很多类,如果占用空间超过了我们的设定值,就会发生元空间溢出
- 虚拟机栈:是线程私有的,它的生命周期和线程的生命周期一致。里面装的是一个一个的栈帧,每一个方法在执行的时候都会创建一个栈帧,栈帧中用来存放(局部变量表、操作数栈、动态链接、返回地址);在java虚拟机规范中,对此区域规定了两种异常情况:
-
- 如果线程请求的栈深度大于虚拟机所允许的深度,将会抛出StackOverflowError的异常;
- 如果虚拟机动态扩展时,无法申请到足够的内存,就会抛出OutofMemoryError异常
- 局部变量表:一组变量值的存储空间,用来存放方法参数、方法内部定义的局部变量。底层是变量槽(variable slot)
- 操作数栈:用来记录一个方法在执行的过程中,字节码指令向操作数栈中进行入栈和出栈的过程。大小在编译的时候确定,当一个方法刚开始执行的时候,操作数栈中是空的,在方法执行的过程中会有各种字节码指令往操作数栈中入栈和出栈
- 动态链接:因为字节码中有很多符号的引用,这些符号引用一部分会在类加载的解析阶段,或第一次使用的时候转换为直接引用,这种称为静态解析;另一部分会在运行期间转换为直接引用,这种称为动态链接。
- 返回地址:指向一条字节码指令的地址
- 本地方法栈:类似虚拟机栈,不过虚拟机栈服务的是Java方法,而本地方法栈服务的是Native方法。在HotSpot虚拟机实现中,是把本地方法栈和虚拟机栈合二为一的,同理也会抛出StackOverflowError和OOM异常
- PC程序计数器:存放的事下一条指令的位置的指针。它是一块较小的内存空间,且是线程私有的。由于线程的切换,CPU在执行过程中,需要记住原线程的下一条指令的位置,因此每个线程都有自己的PC
下述是一些额外的知识点
- 逃逸分析(Escape Analysis) 是JVM的一种编译优化技术,通过分析对象的作用域和引用路径,确定对象是否会 "逃逸" 到方法或线程外部。若对象未逃逸,JVM 可将未逃逸的对象优化为栈上分配或标量替换,从而减少堆内存压力和 GC 开销。
- 对象逃逸的两种场景:
- 方法逃逸:
对象在方法内创建,但被返回或传递给其他方法,导致其生命周期超出当前方法。
csharp
public StringBuilder escapeMethod() {
StringBuilder sb = new StringBuilder(); // 在方法内创建
sb.append("Hello");
return sb; // 对象逃逸到方法外部
}- 线程逃逸:
对象被多个线程共享(如静态变量、存入共享集合),其生命周期可能跨线程。
typescript
private static List<Object> sharedList = new ArrayList<>();
public void escapeThread() {
Object obj = new Object(); // 在方法内创建
sharedList.add(obj); // 对象逃逸到线程共享区域
}若 JVM 通过逃逸分析确定对象未逃逸,则可进行以下优化:
- 栈上分配(Stack Allocation)
- 原理:将对象分配在栈上而非堆上,方法执行结束后自动回收,无需 GC。
csharp
public void noEscape() {
Point p = new Point(1, 2); // 若 p 未逃逸,可能栈上分配
// 使用 p...
} - 标量替换(Scalar Replacement)
- 原理:将对象拆解为基本类型(标量),直接在栈上分配这些字段,而非创建完整对象。
csharp
class Point { int x, y; }
public void replaceScalar() {
Point p = new Point(1, 2); // 可能被替换为:
// int x = 1;
// int y = 2;
}- 同步消除(锁消除)
- 原理:若对象仅被单线程访问,JVM 会移除对象上的同步锁。
- 优势:减少锁竞争,提升性能。
csharp
public void syncElimination() {
StringBuffer sb = new StringBuffer(); // StringBuffer 内部用 synchronized
sb.append("hello"); // 若 sb 未逃逸,同步锁会被消除
}- 逃逸分析的触发条件
JVM 参数设置:
ruby
-XX:+DoEscapeAnalysis # 启用逃逸分析(JDK 8 默认开启)
-XX:-DoEscapeAnalysis # 禁用逃逸分析- 仅对未逃逸的对象生效,若对象逃逸,则仍在堆上分配并进行 GC。
- 逃逸分析的限制与注意事项
-
-
分析成本:逃逸分析需要消耗 CPU 资源,对于简单方法可能得不偿失,因此 JVM 会权衡优化收益。
-
不完全精确:逃逸分析是一种启发式分析,无法保证 100% 精确,极端情况下可能误判。
-
与 GC 的关系:逃逸分析优化后,对象可能直接在栈上分配,减少堆内存压力,从而间接降低 GC 频率。
-
对大对象的限制:即使对象未逃逸,若其体积过大(如数组),仍可能在堆上分配。
-
2、类的加载机制
了解了JVM的内存布局后,接下来我们来看如何填充这部分的内容。
- 首先我们要知道的是:JVM只认得class文件,所有我们在不同地方编写的java程序,最终都要转换为class文件,才可以被JVM认识
- JVM在执行类的入口之前,首先需要找到类,然后把类装到JVM进程维护的内存区域里面。类加载器工具就负责该步骤,在运行过程中通过IO从硬盘读取class二进制文件,然后存放在JVM管辖的内存区域中,简单说来,加载这个操作就是:读取文件到内存
- 如果只是加载进内存,结果就是乱糟糟的一堆,没有良好的管理也没有办法用,因此需要一套规则来管理存放的class文件------这个叫做「类加载机制」
- 启动JVM的时候,会把JRE默认的一些类,以及外部路径的类文件,加载进内存
加载流程
过程:加载、验证、准备、解析、初始化
- 加载阶段
- 通过类的全限定名来获取此类的二进制字节流
- 将该字节流代表的静态存储结构方法,转换为方法区的运行时数据结构
- 在java堆中生成一个代表该类的java.lang.class对象,作为方法区这些数据的访问入口
- 验证阶段
-
- 文件格式验证(是否符合Class文件格式的规范,并且能被当前版本的虚拟机处理)
- 元数据验证(对字节码描述的信息进行语义分析,以保证其描述的信息符合java语言规范的要求)
- 字节码验证(保证被校验类的方法,在运行时不会做出危害虚拟机安全的行为)
- 符号引用验证(虚拟机将符号引用转换为直接引用,解析阶段中发生)
-
准备阶段:初始化为零值
-
解析阶段:将常量池中的符号引用,转换为直接引用
-
- 字符串常量池:在堆上,默认class文件的静态常量池
- 运行时常量池:在方法区,属于元空间
- 初始化阶段:是加载过程的最后一步,开始执行类中定义的java程序代码
双亲委派机制
- 每一个类都有对应的classloader。
- 系统中的classloader在协同工作时默认使用双亲委派机制
- JVM中,一个普通类,如果没有手动自定义类加载器,它的加载流程是什么?
当类被触发加载后,JVM 会从应用程序类加载器开始,按照 "双亲委派" 规则向上委托,委托到启动类加载器时,启动类加载器尝试调用loadClass()加载:
-
若类属于 JVM 核心类库(在加载路径中可以找到该类),则由启动类加载器直接加载,流程结束。
-
若类在加载路径中找不到,启动类加载器无法加载,则将请求 "退回" 给扩展类加载器。
-
当父类加载器为null时,会使用启动类加载器BootStrapClassLoader作为父类加载器
-
类和classloader的关系是什么?
- 类加载器是类的 "加载者"
- 类的唯一性由 "类名 + 类加载器" 共同决定
- 类加载器是类的 "持有者"
- 类的卸载依赖类加载器的生命周期
- 当一个类加载器被垃圾回收时,它加载的所有类(且这些类没有任何实例或引用)才可能被卸载。
- 系统类加载器(如启动类加载器、应用类加载器)通常伴随 JVM 生命周期存在,因此它们加载的类(如核心类库、用户主类)一般不会被卸载。
- 自定义类加载器可以通过销毁实例的方式触发类卸载(如 Tomcat 热部署时,销毁旧的
WebAppClassLoader以卸载旧类)。 - classloader种类:
| classloader类型 | 详情 |
|---|---|
| BootStrapClassLoader | - 启动类加载器,加载JDK核心类 - C/C++实现 - 类加载路径:/jre/lib |
| ExtensionClassLoader | - 扩展类加载器, 加载JAVA扩展类库 - JAVA实现 - 类加载路径:/jre/lib/ext |
| ApplicationClassLoader | - 应用程序类加载器, 加载应用「指定环境变量路径」下的类 - JAVA实现 - 类加载路径:-classpath下面的所有类 |
| Custom ClassLoader | 自定义类加载器 继承 ClassLoader类,并且复写findClass和loadClass方法 |
-
使用双亲委派机制的好处/作用:
-
-
保证JDK核心类的优先加载,因为强制从父类加载器开始逐级搜索类文件,
-
避免类的重复加载
-
保证了java的核心api不被篡改。如果没有使用双亲委派模型,而是每个类加载器加载自己的话会出现一些问题,比如我们编写一个叫做:java.lang.Object类的话,那么程序运行的时候,会出现多个不同的Object类
-
-
为什么不同的类加载器采用不同的语言实现?
核心原因是职责分工不同------ 不同类加载器的运行时机和依赖的底层资源不同,需要匹配最合适的实现语言。
- BootStrapClassLoader:必须用 C/C++ 实现,原因如下:
- 启动时机最早:启动类加载器是 JVM 启动时第一个工作的类加载器,此时 Java 运行时环境(如
java.lang.ClassLoader类本身)尚未初始化,无法用 Java 代码实现(Java 类的加载依赖它)。 - 依赖底层资源:它需要直接操作 JVM 内部数据结构和本地文件系统,必须通过 native 代码与操作系统交互,C/C++ 是最直接的选择。
- 扩展类加载器(Extension ClassLoader)和应用程序类加载器(AppClassLoader):用 Java 实现
这两类加载器属于 "用户态" 类加载器,它们用 Java 实现的原因是:
- 依赖 Java 核心类:它们本身继承自
java.lang.ClassLoader抽象类,而ClassLoader本身是 Java 类,其核心方法(如loadClass、findClass)需要用 Java 实现才能复用和扩展。 - 逻辑更灵活:应用类加载器需要处理复杂的类路径解析、双亲委派 机制等逻辑,用 Java 实现更便于开发、调试和扩展(例如自定义类加载器可通过继承重写方法)。
- 无需依赖底层启动阶段:它们在 JVM 初始化完成后才工作(此时 Java 运行时环境已就绪),无需依赖 native 代码。
破坏双亲委派机制
- 打破类加载自下而上的委托:自己定义一个类加载器,重写loadClass方法
Tomcat的双亲委派机制
Tomcat 作为 Java Web 容器,需要同时部署多个 Web 应用
- 在 Tomcat 场景下,双亲委派机制的局限性
- 无法满足「类隔离需求」
不同 Web 应用可能依赖同一个类的不同版本(如应用 A 需要com.example.Toolv1.0,应用 B 需要 v2.0)。若遵循双亲委派,这些类会被共同的父加载器(如应用类加载器)加载,导致版本冲突(后加载的类会覆盖先加载的,或因类已存在而无法加载)。 - Web 容器自身类与应用类的隔离
Tomcat 作为容器,有自己的核心类库(如org.apache.catalina.*),而 Web 应用的类不应影响容器类的加载,反之亦然。双亲委派无法实现这种双向隔离。 - 热部署需求
Tomcat 支持 Web 应用的热部署(不重启容器的情况下重新加载应用),需要卸载旧的类加载器并创建新的,双亲委派的 "类加载后缓存" 机制与此冲突。
- Tomcat 的类加载器体系
- Bootstrap ClassLoader(启动类加载器),与 Java 原生一致。
- Extension ClassLoader(扩展类加载器),与 Java 原生一致。
- Application ClassLoader(应用类加载器),与 Java 原生一致(Tomcat 自身的启动类由它加载)。
- Common ClassLoader
加载 Tomcat 通用类库(如$CATALINA_HOME/lib目录下的类),这些类对所有 Web 应用可见。 - Catalina ClassLoader
加载 Tomcat 容器自身的核心类(如catalina.jar),对 Web 应用不可见(实现容器与应用的隔离)。 - Shared ClassLoader,加载所有 Web 应用共享的类(可选,默认与 Common ClassLoader 合并)。
- WebApp ClassLoader ,每个 Web 应用对应一个独立的
WebAppClassLoader,加载当前应用WEB-INF/classes和WEB-INF/lib下的类。这是打破双亲委派的核心。 - JasperLoader
加载 JSP 编译后的.class文件,支持 JSP 热部署(JSP 变更后重新编译并加载)。
- Tomcat 如何打破类加载器体系
- 优先加载应用自身的类
当加载一个类时,WebAppClassLoader会先在当前应用的WEB-INF/classes和WEB-INF/lib中查找,若找到则直接加载,不委托给父类加载器。
- 例如,应用 A 的
WEB-INF/lib中有com.example.Toolv1.0,应用 B 有 v2.0,两个类会被各自的WebAppClassLoader加载,互不干扰。
2.对 JVM 核心类的保护
为了避免应用类覆盖 JVM 核心类(如 java.lang.String),WebAppClassLoader 对 java.* 包下的类 强制遵循双亲委派:先委托父类加载器加载,自身不加载。
-
Web 应用间的类隔离
不同
WebAppClassLoader加载的类被视为不同的类(即使类名和包名完全相同),因为 JVM 判断类唯一性的依据是 "类全限定名 + 类加载器"。例如,应用 A 的com.example.User和应用 B 的同名类,在 JVM 中是两个不同的 Class 对象。 -
JSP 热部署的特殊处理
JasperLoader为每个 JSP 生成独立的类加载器,当 JSP 文件修改后,旧的JasperLoader被销毁,创建新的JasperLoader加载新编译的类,实现热部署。这也打破了双亲委派(新类加载器不委托旧的)。
- JSP是什么?JSP(JavaServer Pages)是一种基于 Java 技术的动态网页开发标准
类加载器的加载
- 不同的类加载器什么时候加载?
不同类加载器的加载时机遵循 "按需加载" 原则 ------ 即类在首次被使用时才会被加载(懒加载),而非程序启动时一次性加载所有类。这么设计的目的是减少不必要的资源消耗
- 主动使用的场景 包括:
- 创建类的实例(如
new ClassName())。 - 调用类的静态方法或访问静态成员变量。如
User.doSomething() - 反射调用(如
Class.forName("ClassName"))。 - 初始化子类时(会先加载父类)。
- JVM 启动时执行主类(含
main()方法的类)
- SpringBoot中的类何时被加载?
- 默认单例 Bean(Singleton)的加载时机
默认的 Bean 作用域是 singleton(单例),这类 Bean 的加载时机分为两种情况:
- 默认:容器启动时预加载(Eager Initialization)
- 延迟加载:若通过
@Lazy注解标记单例 Bean,则会延迟到首次被使用时才加载(而非容器启动时) - 若 Bean A 依赖 Bean B(如 @Autowired 注入),则 B 的加载会早于 A(保证 A 实例化时 B 已存在)。
- 原型 Bean(Prototype)的加载时机
prototype作用域的 Bean 每次被获取(如getBean()或注入)时,都会重新创建新实例,不会缓存。- 首次被使用时(如注入到其他 Bean 中,或通过
ApplicationContext.getBean()获取时)才会实例化和初始化。
kotlin
@Component
@Scope("prototype")
public class MyPrototypeBean {
public MyPrototypeBean() {
System.out.println("MyPrototypeBean 被实例化");
}
}
@Service
public class MyService {
// 注入时创建第一个实例
@Autowired
private MyPrototypeBean prototypeBean1;
public void doSomething() {
// 每次获取时创建新实例
MyPrototypeBean prototypeBean2 = applicationContext.getBean(MyPrototypeBean.class);
}
}- 静态内部类何时加载?
-
静态内部类虽然定义在外部类的内部,但在 JVM 中,它是一个完全独立的类,有自己的类加载器和生命周期,与外部类的加载过程互不干扰:
-
静态内部类只有当程序中首次直接引用该静态内部类(如访问其静态成员、创建其实例)时,JVM 才会触发它的加载。
- 其他作用域 Bean 的加载时机
- 请求作用域(Request):每次 HTTP 请求到达时,创建新实例,请求结束后销毁。
- 会话作用域(Session):用户会话创建时实例化,会话结束后销毁。
- 应用作用域(Application):Web 应用启动时加载,与
singleton类似,但限定在 Servlet 上下文范围内。
这些作用域的 Bean 均遵循 "首次使用时加载" 的原则,与各自的生命周期(请求、会话等)绑定。
- 原型 Bean(Prototype)是什么?有什么作用?
在 Spring 框架中,原型 Bean(Prototype) 是一种 Bean 作用域(Scope) ,其核心特性是:每次从 Spring 容器中获取该 Bean 时,容器都会创建一个新的实例,而非复用已有的实例。这与默认的单例 Bean(Singleton)形成鲜明对比(单例 Bean 在容器中仅存在一个实例)。
除原型外,Spring 还有单例(Singleton)、请求(Request)、会话(Session)等作用域,原型的核心差异在于:
-
单例(Singleton):容器中仅一个实例,全局共享。
-
原型(Prototype):每次获取都是新实例,状态独立。
垃圾回收机制
- 垃圾回收的作用是什么?
自动识别并回收不再被使用的对象所占用的内存空间,从而避免内存泄漏、减少手动内存管理的错误。
- 如何识别出不再被使用的对象?------存活算法
- 如何回收?考虑回收效率,内存使用率------复制算法、标记清除、标记整理
1、 存活判定算法
- 引用计数法:给对象添加一个引用计数器,每当由一个地方引用它时,计数器值就加1;当引用失效时,计数器值就减1;任何时刻计数器为0的对象就是不可能再被使用的
- 优点:实现简单、判定效率高
- 缺点:难以解决循环引用问题
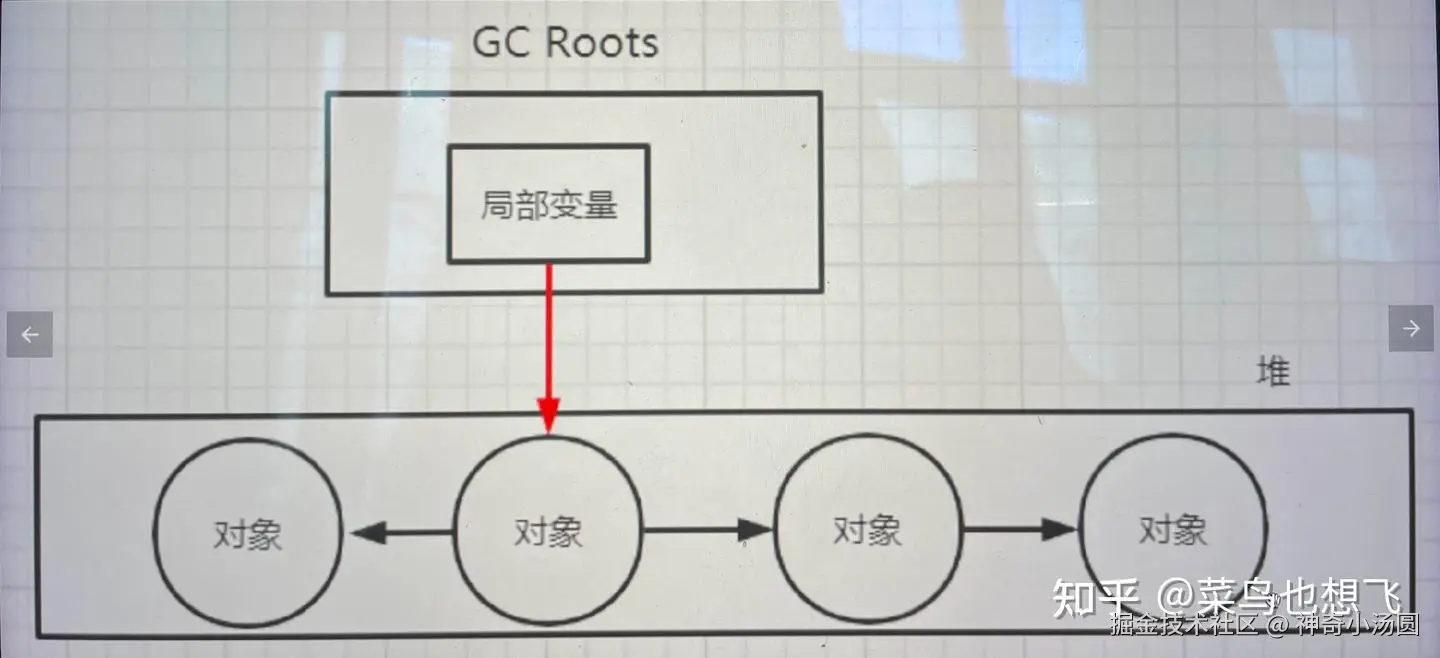
- 可达性分析法:
- 将一系列的GC Roots对象(垃圾回收的根节点)作为起始点,从这些节点ReferenceChains开始向下搜索,搜索走过的路径成为引用链,如果一个对象和GC Roots之间没有任何引用链时,证明此对象不可用
- GC Roots是当下这个时间点,被视为还在使用的对象。从这些节点开始,可达的对象都会被标记为存活,不可达的对象则会被回收。
- GC Roots节点有:虚拟机栈帧引用的对象(方法内部new的对象),本地方法栈引用的对象,静态变量引用的对象(用static声明的对象),常量引用的对象(用final修饰的对象)
2、垃圾回收算法
- 复制算法、标记清除、标记整理、分代收集
- 复制算法:将内存划分为大小相等的两块内存,当其中一块的内存使用完成后,就将还存活的对象复制到另外一块,然后再把已经使用的内存清理掉。这样每次回收都是对内存一半进行回收
-
- 好处:实现简单,内存效率高,不易产生碎片
- 缺点:内存压缩了一半,倘若存活对象多,Copying算法的效率会大大降低
- 标记清除(cms):
-
- 标记出所有需要清理的对象,在标记完成后统一回收所有被标记的对象
- 缺点:效率低,标记清除后会产生大量不连续的碎片,需要预留空间给分配阶段的浮动垃圾
- 标记整理:标记过程和CMS一样,再让所有存活对象向一端移动,然后直接清理掉端边界以外的内存;从而解决产生大量不连续碎片的问题
- 分代收集:根据各个年代的特点选择合适的垃圾回收算法
-
- 新生代:采用复制算法。因为新生代每次GC都要回收大部分对象,存活对象较少,即要复制的操作较少,一般将新生代划分为一块较大的eden空间 + 两个较小的survivor空间(From Space、To Space),每次使用eden空间和其中一块survivor空间,当进行回收时,将该两块空间中还存活的对象复制到另一块survivor空间中
- 老年代的对象存活几率较高,而且没有额外的空间对它进行分配担保,因此我们只能选择cms or 标记整理算法来进行垃圾回收
因此分代收集,相应的会分为Minor GC、Major GC、Full GC
- Minor GC:在年轻代空间不足时发生
- Major GC:在老年代空间不足时发生
- Full GC:1、老年代空间不足 2、元空间不足的时候 3、显式调用System.gc的时候 4、新生代 Minor GC 前的 "空间担保" 失败 5、老年代回收算法的 "自适应" 触发 6、堆内存分配失败(OOM 前的最后尝试)
总结:显式触发/各个环节的空间不够
4、新生代 Minor GC 前的 "空间担保" 失败
Minor GC(新生代回收)前,JVM 会检查老年代最大可用连续空间 是否大于新生代所有对象总大小:
4.1 若大于,说明 Minor GC 安全(即使所有新生代对象晋升到老年代也能容纳),直接执行 Minor GC。
4.2 若小于,会查看是否开启 "空间担保" 机制(
HandlePromotionFailure):4.2.1 若未开启,直接触发 Full GC,腾出老年代空间后再执行 Minor GC。
4.2.2 若已开启,检查老年代最大可用连续空间是否大于 "历次晋升到老年代的平均大小":
若小于,触发 Full GC。
若大于,尝试执行 Minor GC(有风险,若晋升对象超过老年代空间,仍会触发 Full GC)。
- 老年代回收算法的 "自适应" 触发:部分垃圾回收器(如 CMS、G1)有自适应策略,当老年代空间使用率达到某一阈值时,会自动触发 Full GC:
- 堆内存分配失败(OOM 前的最后尝试)
当 JVM 无法为新对象分配内存(如新生代和老年代均无空间)时,会触发 Full GC 作为 "最后的尝试",若回收后仍无法分配,则抛出 OutOfMemoryError。
-
safe point:用户线程全部停下来时,这个状态我们认为JVM是安全的,因为整个堆的状态是稳定的。如果在GC前,有线程迟迟进入不了safepoint,那么整个JVM都在等待这个阻塞的线程,造成了整体GC的时间变长
-
新对象出生以后,分配空间的流程为:
-
对象优先在eden区分配,当eden区空间不够时,发起minorGC
-
长期存活的对象进入老年代:虚拟机给每个对象定义了年龄计数器,对象在eden区出生之后,如果经过一次minorGC之后,将会进入survivor区,同时对象年龄+1,增加到一定阈值时则进入老年代(阈值默认15)
-
大对象直接进入老年代:所谓大对象是指需要连续内存空间的对象,比如很长的字符串以及数组。老年代直接分配的目的是避免在eden区和survivor区之间出现大量内存复制
-
动态对象年龄判定:为了更好的适应不同程序的内存状况,虚拟机并不总是要求对象的年龄必须达到阈值,才能进入老年代。如果在survivor区中相同年龄的所有对象的空间总和大于survivor区空间的一半,则年龄大于等于该年龄的对象直接进入老年代
- 上述的标记清除-标记整理中的标记是如何做的?------两次标记过程
标记过程与对象的可达性分析 和finalize () 方法密切相关,具体流程如下:
第一次标记:判断对象是否 "不可达", 标记出所有:从 "GC Roots"出发,无法通过引用链到达的对象。
第二次标记:判断对象是否 "真的无用", 第一次标记后,对象不会立即被回收。JVM 会对这些 "暂时不可达" 的对象进行第二次标记,决定其最终命运。这一过程与对象的finalize()方法有关。
1)判断该对象是否有重写finalize()方法。
- 若对象未重写 finalize() 方法,或 finalize() 方法已经被执行过(每个对象的 finalize() 最多执行一次),则该对象直接被判定为 "无用",进入回收队列。
- 若对象重写了 finalize() 且未执行过,则该对象会被放入一个名为 F-Queue 的队列中,并由 JVM 自动创建的低优先级线程执行其 finalize() 方法。
2) finalize() 方法的 "救赎机会"
finalize() 方法是对象最后的 "自救机会":在方法中,对象可以通过重新与 GC 根节点建立引用关系(如赋值给某个可达对象的引用),从而 "逃脱" 被回收的命运。
3)第二次标记的判定
- 执行完 F-Queue 中对象的 finalize() 方法后,JVM 会对这些对象进行第二次可达性分析。
- 若对象在 finalize() 中成功建立新的引用关系(变为可达),则被移除出回收队列,避免被回收。
- 若对象仍不可达,则被最终标记为 "无用对象",等待被垃圾回收器回收。
csharp
public class FinalizeDemo {
public static FinalizeDemo instance;
@Override
protected void finalize() throws Throwable {
super.finalize();
// 在finalize()中重新建立与根节点的引用
instance = this;
System.out.println("对象在finalize()中自救成功");
}
public static void main(String[] args) throws InterruptedException {
instance = new FinalizeDemo();
// 第一次让对象变为不可达
instance = null;
System.gc(); // 触发GC
Thread.sleep(1000); // 等待finalize()执行
if (instance != null) {
System.out.println("对象存活");
} else {
System.out.println("对象被回收");
}
// 第二次让对象变为不可达(此时finalize()已执行过,无法再自救)
instance = null;
System.gc();
Thread.sleep(1000);
if (instance != null) {
System.out.println("对象存活");
} else {
System.out.println("对象被回收");
}
}
}
输出结果:
对象在finalize()中自救成功
对象存活
对象被回收-
第一次 GC 时,对象因 finalize() 中重新建立引用而存活。
-
第二次 GC 时,finalize() 已执行过,对象无法再自救,最终被回收。
3、垃圾收集器
- 如果说收集算法是内存回收的方法论,那么垃圾收集器就是内存回收的实践者
- 不同厂商、不同版本的虚拟机所包含的垃圾收集器也各不相同,JDK7以后,JDK11之前,Oracle JDK中的Hotpot虚拟机所包含的全部垃圾收集器为:Serial、Parnew、ParallelScavenge、Serial Old、Parallel Old,CMS和G1共7种垃圾收集器,这7种垃圾收集器是互相组合使用
- 往往选择没有更好,只有更合适
新生代垃圾收集器
JVM 的新生代垃圾收集器主要负责回收新生代(Young Generation)中的短期存活对象,新生代是 Java 堆内存的一部分,通常存放新创建的对象,特点是对象存活率低、回收频繁。新生代垃圾收集器的设计目标是快速回收,减少垃圾收集的停顿时间(STW,Stop-The-World)。
Serial 收集器
- 特点:新生代、复制算法、单线程、STW
- 工作原理:
-
- 采用复制算法(将新生代的 Eden 区和一个 Survivor 区的存活对象复制到另一个 Survivor 区)。
- 单线程执行,无线程切换开销,简单高效。
- 适用场景:
-
- 单 CPU 环境或内存较小的应用(如嵌入式设备)。
- 对停顿时间不敏感的场景。
- 启动参数:
-XX:+UseSerialGC(同时启用 Serial 新生代收集器和 Serial Old 老年代收集器) - STW会在用户不可知、不可控的情况下,把用户正常工作的线程全部停掉,这对很多应用都是不能接受的,那Serial还有存在的必要吗?答案是肯定的,Serial最大的优点是:简单、高效
Parnew收集器
- Serial GC 的多线程版本,并行执行垃圾收集,仍会产生 STW,但停顿时间更短。在单核处理器中,不会比Serial收集器的效果更好,因为存在线程交互的开销
- 特点:新生代、复制算法、多线程、STW
- 工作原理:
-
- 同样采用复制算法,与 Serial GC 核心逻辑一致,但使用多个线程并行回收。
- 线程数量默认与 CPU 核心数相同,可通过
-XX:ParallelGCThreads调整。
- 适用场景:
-
- 多 CPU 环境,需要利用多核提升收集效率。
- 常与老年代的 CMS 收集器配合使用(CMS 无法单独与 Serial GC 配合)。
- 启动参数:
-XX:+UseParNewGC。
Parallel Scavenge GC(并行清理收集器)
- 上述收集器致力于尽可能的缩短垃圾收集时用户线程的停顿时间,而Parallel Scavenge的目标是达到一个可控制的吞吐量,吞吐量 = (吞吐量 = 运行用户代码时间 / (运行用户代码时间 + 垃圾收集时间))的并行收集器。
- 此外Parallel Scavenge还有一个特点:自适应调节策略。可以通过参数:-XX:UseAdaptiveSizePolicy开启,虚拟机会根据当前系统的运行情况收集性能监控信息,然后动态调整一些参数以提供最合适的停顿时间或最大的吞吐量
- 特点:新生代、复制算法、多线程、STW、吞吐量、自适应调节策略
- 工作原理:
-
- 采用复制算法,多线程并行回收,与 ParNew 类似。
- 可通过参数控制吞吐量目标:
-
-XX:MaxGCPauseMillis:设置最大垃圾收集停顿时间(默认值为 0,无限制)。-XX:GCTimeRatio:设置垃圾收集时间占总时间的比例(默认 99,即允许 1% 的时间用于 GC)。
- 与 ParNew 的区别:
-
- ParNew 可与 CMS 配合,而 Parallel Scavenge 通常与 Parallel Old 配合。
- Parallel Scavenge 更关注吞吐量,ParNew 更关注低延迟。
- 适用场景:
-
- 后台计算等对吞吐量要求高,对停顿时间不敏感的应用。
- 启动参数:
-XX:+UseParallelGC(默认启用,同时启用 Parallel Scavenge 和 Parallel Old)。
老年代垃圾收集器
JVM 的老年代垃圾收集器主要负责回收老年代(Old Generation)中的长期存活对象。老年代的特点是对象存活率高、回收频率低,但单次回收耗时可能较长。老年代收集器的设计需要在回收效率和停顿时间之间平衡,常见的老年代垃圾收集器如下:
Serial Old 收集器(单线程老年代收集器)
- Serial Old 收集器是Serial的老年代版本,单线程执行垃圾收集,采用标记 - 整理算法(Mark-Compact),会产生较长的 STW(Stop-The-World)停顿。
- 特点:老年代、标记 - 整理算法、单线程、STW
- 工作原理:
-
- 标记:遍历所有对象,标记存活对象。
- 整理:将存活对象压缩到内存一端,消除内存碎片。
- 适用场景:
-
- 单 CPU 环境或内存较小的应用(与 Serial GC 搭配使用)。
- 对停顿时间不敏感的场景(如简单命令行工具)。
- 启动参数:
-XX:+UseSerialGC(与 Serial 新生代收集器绑定启用)
Parallel Old GC(并行老年代收集器)
- 多线程并行执行收集,采用标记 - 整理算法,注重吞吐量(与 Parallel Scavenge 新生代收集器配合,组成 "吞吐量优先" 组合)。
- 特点:老年代、标记 - 整理算法、多线程、STW、吞吐量
- 工作原理:
-
- 与 Parallel Scavenge 类似,通过多线程并行执行标记和整理,减少 GC 总耗时。
- 可通过
-XX:ParallelGCThreads调整线程数量。
- 适用场景:
-
- 多 CPU 环境,对吞吐量要求高,对停顿时间不敏感的应用(如后台计算)。
- 启动参数:
-XX:+UseParallelOldGC(与 Parallel Scavenge 配合启用)。
CMS GC(Concurrent Mark Sweep,并发标记清除收集器)
-
CMS收集器是一种以获取最短回收停顿时间为目标的收集器,与上述垃圾收集器相比,其最大的特点是让用户线程和垃圾收集器基本上同时工作
-
特点:老年代、标记 - 清除算法、多线程、并发、低停顿
-
工作原理(四阶段):
-
- 初始标记(Initial Mark):STW 阶段,标记 GC Roots 直接关联的对象(快速完成),如上述红色箭头指向的对象,标记为灰色,其余对象仍然为默认白色。
- 并发标记(Concurrent Mark):从上一步标记的对象开始,遍历标记整个对象图(如上述黑色箭头指向的对象,标记为黑色)。 与用户线程并行,耗时最长,但不阻塞用户线程。
- 重新标记(Remark):STW 阶段,上一步执行过程中,用户线程的运行可能导致部分对象发生变动,该阶段主要修正这些变动并重新标记,速度较快。主要处理错标、漏标两种情况
-
- 错标:并发阶段中,用户线程将一个白色对象的引用赋值给黑色对象(可能导致该白色对象被误判为垃圾)。
- 漏标:并发阶段中,用户线程删除了灰色对象对某个白色对象的引用(该白色对象本应被回收,却可能被错误标记)。
- 并发清除(Concurrent Sweep):与用户线程并行,清除未标记的垃圾对象(不压缩内存,会产生碎片),即清除掉所有白色对象。注意,该过程中如果出现新增对象,则会进行标记并等待下一次GC。
- 初始标记时,标记方式是更改对象头的MarkWord的GC标记字段
-
- 并发标记时,因为用户线程和GC线程并发运行,采用的是三色标记
- 并发收集意味着要预留充足的空间给用户线程使用,如果预留的内存空间无法满足程序分配新对象的需要,就会出现并发失败,此时虚拟机需要启动后备预案:冻结用户线程的执行,临时启动Serial Old收集器来重新进行老年代的垃圾收集
- 优缺点:
-
- 优点:并发执行,STW 时间短,适合延迟敏感场景。
- 缺点:
-
- 占用额外 CPU 资源(并发阶段需与用户线程竞争资源)。
- 产生内存碎片(标记 - 清除算法导致),可能触发频繁的 Full GC。
- 无法处理 "浮动垃圾"(并发清除阶段新产生的垃圾,需下次 GC 回收)。
- 为什么CMS采用的是标记-清除,而不是标记-整理?
-
- 核心原因是为了减少 STW(Stop-The-World)停顿时间,这与 CMS 的设计目标 ------最短回收停顿时间 密切相关。
- 「标记-清除」由于不需要移动存活对象,清除阶段可以完全与用户线程并发执行(无 STW),且操作简单高效。
- 「标记-整理」在标记后需要将存活对象压缩到内存一端(消除碎片),这一 "整理" 过程必须暂停所有用户线程(STW),否则用户线程可能访问到被移动的对象,导致引用失效。
- 介绍一下GC中,CMS的 三色标记方法?
CMS 在 CMS(Concurrent Mark Sweep)垃圾收集器的并发标记阶段,为了高效追踪对象的存活状态,并解决并发线程与用户线程并发执行时的对象引用变动 问题 ,采用了三色标记法(Tri-color Marking)。通过三种颜色标记对象的不同状态,关键是通过增量更新机制**解决并发修改导致的漏标问题,确保存活对象不被误回收,以实现并发标记的正确性。
| 颜色 | 含义 |
|---|---|
| 白色 | 未被标记的对象(默认状态)。若标记结束后仍为白色,则视为垃圾对象,将被回收。 |
| 灰色 | 自身已标记,但该对象的部分引用(字段)尚未遍历标记 **。处于 "待处理" 状态,需要继续遍历其引用的对象。 |
| 黑色 | 自身已标记,且该对象的所有引用(字段)都已遍历标记完成 **。处于 "已处理" 状态,无需再关注。 |
- CMS中,标记时是一个收集器线程,还是多个收集器线程同时工作?
-
- 多个线程,CMS默认启动的回收线程数是:(CPU核数 + 3)/4
全堆垃圾收集器
JVM 的全堆垃圾收集器是指能够同时管理新生代和老年代内存的收集器,它们不严格区分堆的分代结构,而是对整个 Java 堆(包括新生代、老年代)进行统一回收。这类全堆收集器的设计通常面向大内存场景 ,旨在平衡低延迟和高吞吐量,同时支持更大的堆内存(如数十 GB 甚至 TB 级)。
G1 GC(Garbage-First)
- G1 是 JDK 9 及以上版本的默认垃圾收集器,是典型的全堆收集器,虽保留分代概念(仍有新生代和老年代区域),但通过 "Region" 管理实现全堆统一回收。G1收集器避免全区域垃圾收集,它把堆内存划分为大小固定的几个独立Region,并且跟踪这些Region的垃圾收集进度,同时在后台维护一个优先级列表,每次根据所允许的收集时间,优先回收垃圾最多的区域。Region划分和优先级Region回收机制,确保G1收集器可以在有限的时间获得最高的垃圾收集效率
- 相比于CMS收集器,G1收集器的两个最突出的改进是:
-
- 【1】 基于标记-整理算法,不产生内存碎片
- 【2】可以非常精确的控制停顿时间,在不牺牲吞吐量的前提下,实现低停顿垃圾回收
- 核心原理
-
- 堆内存划分:将堆划分为多个大小相等的独立 Region(区域,通常 1MB~32MB),每个 Region 可动态标记为 Eden、Survivor 或 Old 区域。
- 混合回收(Mixed GC):既可以单独回收新生代 Region(Young GC),也可以同时回收新生代和部分老年代 Region(Mixed GC),无需 Full GC 即可完成全堆回收。
- 垃圾优先策略:优先回收垃圾比例高 的 Region("Garbage-First"),通过停顿预测模型控制单次 GC 停顿时间不超过预设值(
-XX:MaxGCPauseMillis,默认 200ms)。
- 回收流程
- 初始标记:STW 阶段,标记 GC Roots 直接关联的对象。
- 并发标记:与用户线程并行,遍历标记所有存活对象。
- 最终标记:STW 阶段,修正并发标记期间的引用变动。
- 筛选回收:STW 阶段,根据 Region 垃圾比例排序,选择部分 Region 进行回收(复制存活对象到新 Region,消除碎片)。使用多条筛选回收线程并发执行
- 适用场景
-
- 堆内存较大(4GB 以上)的应用。
- 需平衡延迟和吞吐量的场景(如大型分布式服务、电商平台)。
- 启动参数:-XX:+UseG1GC
ZGC(Z Garbage Collector)
- ZGC 是 JDK 11 引入的低延迟全堆收集器,支持 TB 级堆内存,STW 停顿时间通常低于 10ms,几乎不随堆大小增长而增加。
- 核心原理
-
- 无分代设计:不区分新生代和老年代,全堆统一管理(JDK 15 后支持可选分代)。
- Region 动态划分:堆内存划分为大小可变的 Region(小 Region 2MB,中 Region 32MB,大 Region 大小等于对象大小)。
- 颜色指针(Colored Pointers):通过对象指针的额外位存储标记信息(如存活状态),避免传统的标记位存储开销,利用对象指针的额外位存储标记信息,而非传统的对象头(Mark Word)。在 64 位系统中,ZGC 仅使用 42 位(或 47 位,取决于平台)表示对象地址,剩余位用于存储标记状态(颜色)
白色:未标记的对象(可能是垃圾)。
灰色:已标记但引用未遍历完的对象。
黑色:已标记且引用遍历完成的对象。
重定位(Relocation)标记:标记对象正在被移动。
颜色指针的优势:
- 无需修改对象头,标记操作可并发执行,避免传统标记对对象头的竞争。
- 通过指针颜色直接判断对象状态,简化并发引用处理。
-
- 读屏障(Load Barrier):ZGC 在对象引用被加载(如
Object o = obj.field)时插入读屏障,用于处理并发移动对象时的引用更新,无需停顿用户线程。 -
- 当线程访问的对象指针处于 "重定位" 状态时,读屏障会将指针更新为对象的新地址(已移动后的位置),并返回新地址。
- 这一机制确保用户线程在并发移动对象过程中,始终能访问到正确的对象,无需停顿等待移动完成。
- 并发重定位:ZGC 回收时会将存活对象从旧 Region 移动到新 Region(压缩内存),这一过程完全并发执行:
- 读屏障(Load Barrier):ZGC 在对象引用被加载(如
- 选择待回收的 Region(称为 "重定位集")。
- 并发移动对象到新 Region,并通过颜色指针标记旧地址为 "重定位中"。
- 用户线程通过读屏障访问旧地址时,自动转发到新地址(透明处理)。
- 所有引用更新完成后,回收旧 Region 内存。
- 回收流程
- 初始标记:STW 阶段,标记 GC Roots 直接关联的对象(极短)。
- 并发标记:与用户线程并行,遍历标记所有存活对象。
- 并发预备重定位:
-
- 分析标记结果,筛选出垃圾比例高的 Region 组成 "重定位集"(优先回收垃圾多的区域)。
- 为每个重定位集中的对象分配新地址(在新 Region 中)。
- 初始重定位:
-
- STW 阶段,短暂暂停用户线程,耗时极短
- 处理 GC Roots 相关对象的重定位(更新根引用到新地址)。
- 并发重定位:
-
- 与用户线程并行,GC 线程并发将重定位集中的存活对象移动到新 Region。
- 用户线程通过读屏障访问旧地址时,自动更新引用到新地址
- 并发清理:回收重定位集中原 Region 的内存,清空并复用这些 Region。
4、配置垃圾收集器
- 首先是内存大小问题,基本上每个内存区域都会设置一个上限,来避免溢出问题。比如元空间。
- 通常,堆空间会设置成操作系统的2/3,超过8GB的堆,优先选用G1
- 然后对JVM进行初步优化,比如根据老年代的对象提升速度,来调整年轻代和老年代之间的比例
- 依据系统容量、访问延迟、吞吐量等进行专项优化,我们的服务是高并发的,对STW时间敏感
- 我会通过记录详细的GC日志,来找到这个瓶颈点,借用GCeasy这样的日志分析工具,定位问题
5、JVM性能调优
对应进程的JVM状态,以定位问题和解决问题,并作出相应的 优化
常用命令:jps、jinfo、jstat、jstack、jmap
- jps:查看java进程及相关信息
- jinfo:查看jvm参数
- jstat:查看jvm运行时的状态信息,包括内存状态、垃圾回收
- jstack:查看JVM线程快照。jstack可以定位好粗线程长时间卡顿的原因,例如死锁、死循环
- jmap:用来查看内存信息
6、JDK的新特性
- JDK8: 支持lambda表达式,集合的stream操作、提升HashMap性能
- JDK9:Stream API中iterate方法的新重载方法,可以指定什么时候结束迭代。 默认G1垃圾回收器
- JDK10: 重点在于通过完全GC并行,来改善G1最坏情况的等待时间
- JDK11:
-
- ZGC(并发回收的策略):4T B
- 用于lambda参数的局部变量语法
- JDK12:Shenandoah GC算法停顿时间和堆的大小没有任何关系,并行关注停顿响应时间
- JDK13: 增加ZGC以将未使用的堆内存返回给操作系统,
- JDK14:
-
- 删除CMS垃圾回收器,弃用parallel Scanvenge + Serial OLDGC垃圾回收算法组合
- 将ZGC垃圾回收器应用到Mac和windows平台
控制反转IOC
-
传统的开发过程中,新建A对象需要new关键字,如果A对象创建过程中依赖了B对象,那么我们还要先去new 这个B对象,那么A对象还需要知道B对象,增大了类之间的耦合性
-
IOC(Inversion of Control):思想是工厂模式,设置一个对象的容器,将对象的创建、依赖管理、生命周期管理都统一交给容器完成
常见面试题
- java已经有了垃圾回收,为什么还会出现内存泄漏?
-
- 内存泄漏(Memory Leak) 指的是程序在运行过程中,不再需要使用的内存没有被正确释放,导致这些内存持续被占用,无法被重新分配给其他程序或操作的现象。
- 垃圾回收机制主要处理不再被引用的对象,但仍然存在一些情况会导致内存泄露
- 静态集合类引起的内存泄漏
typescript
static List<Object> list = new ArrayList<>();
public void add(Object obj){
list.add(obj); // 静态集合会一直持有该对象引用,即使对象不再使用
}- 未关闭的资源导致的内存泄漏
ini
FileInputStream fis = new FileInputStream("file.txt");- 内部类持有外部类引用
kotlin
public class Outer{
private String data = "data";
public class Inner {
public void process(){
System.out.println(data); //内部类持有外部类引用,导致外部类无法被回收
}
}
}- 缓存使用不当
typescript
public class Cache{
private static Map<String, Object> = new HashMap<>();
public class addToCache(String ley, Object value) {
cache.put(key, value); // 如果不及时清理缓存,对象会一直存在
}
}- 监听器和回调未清除
csharp
public class EventListener{
public class registerListener() {
someObject.addEventListener(listener);
}
}- ThreadLocal使用不当
typescript
private static ThreadLocal<Object> threadLocal = new ThreadLocal<>();
public void process() {
threadLocal.set(new Object());
// 如果不调用remove(), 数据会一直存在线程中
}防止内存泄漏的建议:
-
及时释放不再使用的对象引用
-
使用try-with-resources语句处理资源
-
注意使用weakReference和SoftReference
-
什么情况下会出现FullGC?如何排查FullGC?