1. 引言:大模型的"阿喀琉斯之踵"
自 2023 年生成式 AI 爆发以来,我们见证了 LLM(大语言模型)惊人的通识能力。然而,到了 2026 年的今天,在企业级落地和垂直领域应用中,单纯依赖原生 LLM 的弊端早已显露无疑。
无论模型的参数量 scaling 到多大,它们始终面临着三大核心痛点:
1.幻觉问题(Hallucination) :模型在不知道答案时倾向于"一本正经地胡说八道",这在医疗、法律等严谨场景是不可接受的。
2.知识时效性(Outdated Knowledge) :模型的知识截止于训练数据的时间点。重新训练一个万亿参数的模型既昂贵又耗时,无法做到实时更新。
3.私有数据黑盒(Private Data Inaccessibility) :企业拥有大量的内部文档、SOP、数据库,这些数据是高价值的资产,但通用的 LLM 无法触及,且出于数据安全考虑,企业也不愿将其直接用于公有云模型的微调。
为了解决这些"阿喀琉斯之踵",RAG(Retrieval-Augmented Generation,检索增强生成) 技术应运而生,并迅速成为 AI 2.0 时代企业应用落地的标准架构。
2. 什么是 RAG?------给大模型一场"开卷考试"
2.1 定义与本质
RAG,全称 Retrieval-Augmented Generation(检索增强生成),是一种将预训练的大语言模型(LLM)与外部知识检索系统相结合的架构。
通俗来说,如果传统的 ChatGPT 问答是"闭卷考试"(完全依赖模型训练时记住的参数知识),那么 RAG 就是一场"开卷考试" 。当用户提出问题时,系统首先去外部知识库(课本、参考书)中查找相关资料,然后将这些资料连同问题一起交给大模型,让大模型基于参考资料生成准确的答案。
正如 RedHat 所定义的那样,RAG 是一种能够提高生成式 AI 应用所生成答案的质量和相关性的技术,它的工作原理是将大语言模型的预训练知识与外部资源关联起来。
2.2 RAG 的核心价值
根据行业实践经验总结,RAG 技术主要带来了以下价值:
•准确性提升:通过引入外部知识库,显著减少了模型的幻觉,利用检索到的事实数据约束模型的生成结果。
•知识实时性:无需重新训练模型,只需更新向量数据库中的文档,即可让 AI 掌握最新的新闻、政策或产品信息。
•数据安全性与隐私 :企业数据保留在本地或私有向量库中,大模型仅作为推理引擎,实现了数据所有权与模型能力的解耦。RAG技術:企業知識管理與生成式AI 的理想結合方案。
•可解释性:RAG 生成的内容可以标注引用来源(Citation),让用户知道答案出自哪篇文档的哪一段,建立了信任。
3. RAG 的技术原理与标准流程
RAG 的标准流程可以概括为三个核心阶段:索引(Indexing)、检索(Retrieval)和生成(Generation) 。这是一个实现了"检索"与"生成"有机结合的闭环系统。
3.1 第一阶段:索引(Indexing)------构建知识库
这是 RAG 的地基,决定了系统能"看到"什么知识。
1.数据提取(Data Extraction) :从各种来源(PDF、Word、HTML、Markdown、数据库)提取原始文本。
2.分块(Chunking) :由于 LLM 的上下文窗口(Context Window)限制以及检索精度的考量,我们需要将长文本切分为较小的片段(Chunks)。
3.向量化(Embedding) :利用 Embedding 模型将文本块转化为高维向量(Vectors)。向量是计算机理解语义的数学形式。
4.存储(Indexing/Storage) :将生成的向量及对应的元数据存储在 向量数据库(Vector Database) 中,如 Milvus、Pinecone、Weaviate 或 Faiss。
3.2 第二阶段:检索(Retrieval)------寻找相关信息
当用户发起提问时,系统执行检索操作:
1.查询向量化:将用户的 Query 使用同样的 Embedding 模型转化为查询向量 q。
2.相似度计算 :在向量数据库中计算 q与存储的文档向量 di之间的相似度。最常用的度量方式是 余弦相似度(Cosine Similarity) 。 其数学公式如下:
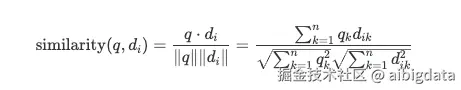
1.Top-K 召回:根据相似度得分,检索出最相关的 K个文本块(Context)。
3.3 第三阶段:生成(Generation)------智慧融合
这是最后一步,将检索结果转化为自然语言回答:
1.Prompt 组装:将用户的原始问题(Query)与检索到的上下文(Context)填充到预设的 Prompt 模板中。
Prompt 示例:
"请基于以下参考信息回答用户的问题。如果参考信息不足以回答,请说不知道。 参考信息:Chunk 1... Chunk 2... 用户问题:..."
1.LLM 推理:将增强后的 Prompt 输入给大模型。
2.生成回答:模型综合上下文信息,生成最终答案。
从概率角度看,RAG 改变了模型的生成概率分布。传统生成的概率是 P(y∣x)P(y∣x),而 RAG 是基于检索内容 zz的生成:

其中 z是检索到的外部知识,P(z∣x)P(z∣x) 代表检索的相关性,P(y∣x,z)P(y∣x,z) 代表基于检索内容生成的概率。
4. RAG vs. 微调(Fine-Tuning):如何选择?
在 AI 工程化落地中,经常会有"RAG 和 微调哪个好?"的争论。根据 RAG和Fine-Tuning有什麼不同? 以及其它参考内容:
| 维度 | RAG (检索增强生成) | Fine-Tuning (微调) |
|---|---|---|
| 核心能力 | 知识获取:擅长利用外部、实时的具体信息。 | 能力内化:擅长学习特定的指令格式、语言风格或复杂推理模式。 |
| 数据更新频率 | 高:更新数据库即可,立等可取,成本极低。 | 低:需要重新训练,周期长,成本高。 |
| 准确性/幻觉 | 低幻觉:答案有据可依,可追溯来源。 | 仍有幻觉:模型可能记住错误知识或产生记忆混淆。 |
| 适用场景 | 实时新闻、企业知识库问答、客服助手、法律法规查询。 | 医疗诊断推理、特定格式代码生成、角色扮演(风格模仿)。 |
结论:
•如果你的应用需要动态响应 、频繁更新外部知识(如每天的股市简报),RAG 是不二之选。
•如果你需要模型深度掌握固定领域内的推理范式 或特定的语言风格(如模仿莎士比亚写作),微调更合适。
•RAG + 微调:在 2026 年的高级应用中,通常采用混合模式。例如,用微调让模型学会"如何阅读医疗报告",再用 RAG 提供"患者的实时体检数据"。
5. RAG 技术的进阶与未来(2026 视野)
随着技术的发展,基础的 RAG(Naive RAG)已经演化出更多高级形态:
•Modular RAG(模块化 RAG) :将检索、重排(Re-ranking)、生成等环节解耦,允许开发者像搭积木一样替换更强的组件。深入理解高级RAG 技术。
•GraphRAG(图谱增强 RAG) :微软等机构提出的结合知识图谱(Knowledge Graph)的 RAG。它不仅检索向量相似的片段,还能通过图谱关系找到实体之间的深层逻辑关联,解决跨文档的复杂推理问题。
•Agentic RAG(代理式 RAG) :RAG 不再是一个单向流程,而是一个智能体(Agent)。它可以自主判断检索到的内容是否足够,如果不够,它会修改搜索关键词重新检索,甚至使用工具去联网搜索,直到找到满意答案。
6. 总结
RAG 技术并不是简单的"搜索+粘贴",它是一场让大模型从"记忆者"转变为"思考者"的架构革命。
通过本文,我们明确了 RAG 的定义:利用检索外部文档提升生成结果质量,充分利用领域知识和私有数据、实时数据,减少生成不确定性。
后续将继续系列文章中,从理论走向实战,争取动手搭建开发环境,写出第一行 RAG 代码,实现一个简易的"个人知识库助手"。
参考文献与延伸阅读:
1.什麼是RAG?初學者也看得懂的檢索增強生成(RAG)基礎指南! - Solwen.ai
3.RAG技术详解:揭秘基于垂直领域专有数据的生成 - CSDN